“История одного обмана” или “Требования к распределению в t-тесте”

Sep 15 · 10 min read
Почему все говорят, что для t-критерия нужны нормальные данные??
Последний год я прособеседовал несколько десятков аналитиков, и каждый раз при ответе на казалось бы простой вопрос я получал столько же простой, но неверный ответ.
Обычно я спрашивал примерно так: “В каких ситуациях (тип метрики, ее распределение) какой стат-тест будешь использовать?”.
Большинство аналитиков отвечало ( спойлер: неправильно 😩): “В случае нормального распределения у метрики стоит использовать t-test, в обратном случае — тест Манна-Уитни (U-критерий)”.
Если зайти на википедию, то у видим что она также врет (по крайней мере на момент написания статьи). Игнорирование факта, что это ложь, может принести вред бизнесу — об этим ниже есть специальный раздел.
Почему же многие думают иначе?
Хороший вопрос: откуда пошло заблуждение про нормальность выборок? Я решил поизучать его 🕵🏻♂️. Например, если мы откроем на вики английскую версию статьи про t-критерий, то во втором абзаце увидим правильные слова (под статистикой там подразумевается среднее по выборке) ❤:
Обратимся к оригинальной статье Стьюдента. Госсет (реальное имя Стьюдента) говорит, что в экспериментах всегда 2 неизвестные сущности — форма распределения и ее параметры (например, среднее). На малых выборках форму распределения понять сложно, поэтому Студент предполагает что лучше считать его нормальным. При этом, он использует формулу для доверительного интервала выборочного среднего (ЦПТ), и не говорит, что выборка обязательно должна быть из нормального распределения. Доказательство текущего нестрогого вида ЦПТ (через теорему Леви) появилось уже позже, возможно именно поэтому в статье вообще говорится про нормальность выборок.

А вот статья про t-тест на русской википедии гласит, как показано слева (на момент написания статьи). Скорее всего, это неверный перевод с английской версии статьи — перепутали выборку и статистику. В тексте про критерий Уэлча (мы поговорим про него ниже) также допущена эта ошибка. BTW, в английской версии статьи про t-распределение (не про критерий) также допущена ошибка про нормальность данных. Источник номер раз — вики!
Карпов в своем курсе сказал, что в случае размера выборок меньше 30 данные должны быть нормальными. И, хотя при больших выборках сказано, что нормальность необязательна, а в блоке про ЦПТ отдельным шагом показано, что распределение может быть любым, все же это может быть источником №2. Но Карпову респект 💕.
На вполне достоверном сайте machinelearning.ru также неверно указано это требование ( источник №3). Известный русско-язычный блог про R — источник №4.
Ну и конечно я не ожидал оплошностей от основателей ExpF 😭 ( источник №5). В этой статье (на медиуме она кстати уже удалена), хотя посыл и выводы верные, есть следующие неточности:
А что же тогда должно быть нормальным?
Чтобы ответить на этот вопрос, давай поймем, как вообще работает t-критерий (критерий Стьюдента).
Большинство стат-тестов работает так — рассчитывает по выборке статистику (в узком смысле статистика это любая функция, которая переводит выборку в скаляр, например: среднее, максимальный элемент или средне-квадратичная ошибка) и сравнивает его с табличными значениями. Чтобы определить стат-значимость, нужно заранее понимать форму распределения этой статистики и уметь считать для каждой точки этого распределения соотвествующий p-value (площадь под графиком от точки до конца распределения ко всей площади ).
В случае стандартного нормального распределения статистики (среднее 0, дисперсия 1): p-value = 0.05 при z-статистике равной 1.96. T-критерий назван так потому, что использует t-распределение статистики. Отличие от z-теста в том, что t-распределение принимает еще 1 параметр — степень свободы.
Откуда взялось t-распределение в задаче оценки А/В-тестов??
Допустим наша метрика — доход с пользователя за период. Нас, как бизнес, в основном интересует среднее (ARPU) значение этой метрики, потому что именно оно участвует в бизнес-моделях и юнит-экономике. Так вот, значения поюзерной метрики (user revenue в нашем случае) — это выборка, а ее среднее (ARPU) — это как раз статистика. Что мы можем сказать о распределении ARPU?
Никакого условия на распределение самой метрики в ЦПТ нет, поэтому не стоит требовать нормальность от для входные данных z- и t-тестов.
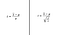
Как проверить, что мое распределение удовлетворяет требованиям
Как мы уже выяснили, нормальным должно быть распределение среднего значения метрики в группе. Стоп-стоп, что❓❓ Среднее это же одно число, какое распределение❗❓
Да, среднее — это случайная величина, посчитанная лишь по выборке от всех возможных пользователей. Если через какое-то время взять другую выборку (новые пользователи), или даже для тех же пользователей посчитать среднее еще раз, оно окажется отличным. Каждый раз оно семплируется из неизвестного распределения, и мы лишь делаем догадки о его форме в случае ЦПТ (и t-теста). Если мы не знаем, можем ли считать его нормальным, то можем оценить это по одной нашей выборке, превратив ее во много выборок и посчитав среднее для всех. Так мы получим распределение, предполагая, что оно примерное совпадает с распределением среднего генеральной совокупности. Этот метод и называется бутстрап, код для него слева в gist’е.
Во-вторых, ЦПТ это асимптотический метод, для формального равенства требуется бесконечно большая выборка, чего не встретишь в реальных задачах. Поэтому такая проблема может воспроизвестись на малых выборках (видимо именно это имел ввиду Карпов). Кстати, в той же статье Госсет поднимал вопрос о границах малой и большой выборок, чтобы считать среднее нормально распределенным.
Самое интересное в статье — это размеры выборок. Он брал 3000 измерений пальцев преступников. Далее делил их на 750 выборок по 4 элемента, внутри каждой выборки считал среднее и смотрел, как эти 750 значений распределены вокруг реального среднего (по всем 3000 измерениям). Нет, тут нет опечатки. Он правда использовал выборки по четыре юнита. Даже на таких выборках можно работать с t-критерием!
Важно найти, на каком размере выборок именно в твоих задачах и метриках распределение выборочного среднего становится похожим на нормальное. Скорость схождения к нормальному распределению описывается через неравенство Берри — Эссеена (расстояние убывает обратно-пропорционально корню из размера выборки). Так что если выборка не удовлетворяет требованиям t-теста и хочется увеличить ее размер, лучше сразу делать это на пару порядков.
Вред бизнесу 📉, или чем плохо U-критерий
Давай подробнее разберем, почему я считаю его почти неприменимым (точнее применимым лишь для небольшого типа задач). Во-первых, если ты хочешь один тест на все случаи в жизни, тебе стоит знать что на тех же нормальных данных он менее мощный чем t-критерий (правда несильно, на 5%). Это грозит бизнесу найти меньше возможностей.
Во-вторых, сам тест не всегда робастен и точен относительно p-value (ошибки первого рода). Если распределение состоит из большого количества повторяющихся значений (и еще во многих кейсах), то это критерий сходит с ума и выдает весьма странные результаты.
В-третьих, есть важный момент, который кстати указали в своей статье ExpF (и Карпов на Матемаркетинге — выбросы могут быт неслучайны (это можно проверить на исторических данных), и в таком случае удалять их нельзя! Если удалить, можно посчитать положительным тест с отрицательным в реальности эффектом на средний чек. Например, предположим что у нас половина клиентов нам не платят, а верхний персентиль имеет средний чек в несколько миллионов. Если в таргетной группе мы сменим нижняя половина начнет нам приносить по 1 рубля, а в верхнем персентиле AOV упадет в несколько раз, то скорее всего средний доход упадет. При этом, при удалении верхнего персентиля как выбросы, мы получим положительный эффект в тесте.
Ну и главное — как объяснить бизнесу результаты критерия? Он сравнивает то, что сравнивает. Т.е. не среднее и не медиану, как многие думают, а ранги в объединенной выборке. Можно придумать примеры, когда эти ранги могут быть разнонаправленными со средними значениями. Какой в таком случае репортить аплифт? Это же касается и любых трансформаций данных, таких как логарифмирование, Бокс-Кокс и тд.
Кстати, многие используют непараметрические критерии в анализе, при этом считают sample size/MDE/мощность через формулу для t-теста. Так конечно же делать нельзя, ведь считать данные величины нужно способом, соответствующим используемому при анализе методу расчета значимости. Например, можно использовать бутстрап из библиотеки от facebook.
Другие вопросы касательно t-теста
В отличие от нормальности выборок, у t-критерия есть гораздо более важные требования к распределениям. Например, неравенство дисперсий в двух выборках (несоблюдения гомогенности). Давай наглядно продемонстрирую тебе.
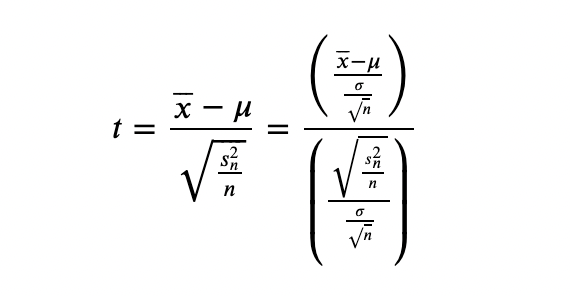
Для одной выборки t-критерий выглядит так, как показано на картинке в первой формуле. На самом деле это не совсем t-распределение, поскольку в классическом варианте оно обязует и числитель, и каждый член суммы в знаменателе (дисперсия — это сумма) иметь стандартное нормально распределение N(0,1). Чтобы его получить, во второй формуле мы делим и числитель, и знаменатель на фактор масштаба (обрати внимание, в нем используется неизвестный параметр дисперсии генеральной совокупности, а не выборочное SE, но это не важно).
Теперь рассмотрим кейс сравнения средних двух выборок. В общем случае после деления на фактор масштаба каждое из слагаемых в среднеквадратичном отклонении не стандартизируется, соотвественно распределение знаменателя уже не Хи-квадрат. И если в случае равных размеров выборки мы можем использовать pooled variance объединенной выборки (тем самым свести это к кейсу одной выборки), то при неравных дисперсиях и размеров выборки мы получаем проблему Беренца-Фишера, которая до недавнего времени считалась нерешаемой в строгом виде. Потом решение нашли, но оно малопопулярное и сложное и все используют способ, описанный ниже.
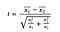
Надеюсь, ты и так это знаешь, но в зависимых выборках используется другая дисперсия (разностей для каждой пары).
Требования к распределениям в других тестах
На самом деле, в отличии от Стъюдента, некоторые статистические тесты действительно требуют нормальное распределение данных. Например, в проверке гомогенности дисперсий, которую упоминал в прошлом разделе📊. Используемый тут и в регрессиях F-тест требует нормальности. Как и t-тест, он также имеет непараметрические альтернативы (тест Левена и тест Бартлетта), которые также имеют свои недостатки. Требующая нормальности выборок ANOVA не так чувствительна к нарушению этого правила, но все же имеет слегка завышенный FPR в этом случае.
Как ты уже понял, существует правило ✍️: если распределение удовлетворяет условиям наиболее строгих параметрических тестов (кстати обычно они самые простые в вычислении и интерпретации), то лучше использовать именно их.
А требуется ли нормальность данных для регрессии?
Регрессия требует нормальности лишь для остатков, а это может выполняться при любом распределении зависимых и независимых переменных (более того, форма распределения никак не влияет на нормальность остатков) при условии выполнения других пунктов из теоремы Гаусса-Маркова. Проще можно объяснить это условие так — Y должен быть нормальным на каждом уровне X.
А вот дов-интервалы и стат-значимости коэффициентов регрессии можно посчитать только при нормальных выборках (об этом будет отдельная статья).
Напоследок, держи эту статью. И до скорых (возможно очень) встреч!
Что делать если распределение ненормальное
Непараметрическая статистика и подгонка распределения
Действительно ли большинство переменных имеют нормальное распределение? В рассмотренном примере использовался тот факт, что в повторных выборках равного объемы средние значения (роста людей) будут иметь t распределение (с определенным средним и дисперсией). Однако, это верно лишь, если рассматриваемая переменная (рост) имеет нормальное распределение, т.е. что распределение людей определенного роста нормально распределено.

Дополнительную информацию о нормальном распределении можно посмотреть в разделе Элементарные понятия статистики.
Объем выборки. Другим фактором, часто ограничивающим применимость критериев, основанных на предположении нормальности, является объем или размер выборки, доступной для анализа. До тех пор пока выборка достаточно большая (например, 100 или больше наблюдений), можно считать, что выборочное распределение нормально, даже если вы не уверены, что распределение переменной в популяции, действительно, является нормальным. Тем не менее, если выборка очень мала, то критерии, основанные на нормальности, следует использовать только при наличии уверенности, что переменная действительно имеет нормальное распределение. Однако нет способа проверить это предположение на малой выборке.
Краткий обзор непараметрических процедур
Различия между независимыми группами. Обычно, когда имеются две выборки (например, мужчины и женщины), которые вы хотите сравнить относительно среднего значения некоторой изучаемой переменной, вы используете t-критерий для независимых выборок (в модуле Основные статистики и таблицы). Непараметрическими альтернативами этому критерию являются: критерий серий Вальда-Вольфовица, U критерий Манна-Уитни и двухвыборочный критерий Колмогорова-Смирнова. Если вы имеете несколько групп, то можете использовать дисперсионный анализ (см. Дисперсионный анализ). Его непараметрическими аналогами являются: ранговый дисперсионный анализ Краскела-Уоллиса и медианный тест.
Различия между зависимыми группами. Если вы хотите сравнить две переменные, относящиеся к одной и той же выборке (например, математические успехи студентов в начале и в конце семестра), то обычно используется t-критерий для зависимых выборок (в модуле Основные статистики и таблицы. Альтернативными непараметрическими тестами являются: критерий знаков и критерий Вилкоксона парных сравнений. Если рассматриваемые переменные по природе своей категориальны или являются категоризованными (т.е. представлены в виде частот попавших в определенные категории), то подходящим будет критерий хи-квадрат Макнемара. Если рассматривается более двух переменных, относящихся к одной и той же выборке, то обычно используется дисперсионный анализ (ANOVA) с повторными измерениями. Альтернативным непараметрическим методом является ранговый дисперсионный анализ Фридмана или Q критерий Кохрена (последний применяется, например, если переменная измерена в номинальной шкале). Q критерий Кохрена используется также для оценки изменений частот (долей).
Зависимости между переменными. Для того, чтобы оценить зависимость (связь) между двумя переменными, обычно вычисляют коэффициент корреляции. Непараметрическими аналогами стандартного коэффициента корреляции Пирсона являются статистики Спирмена R, тау Кендалла и коэффициент Гамма (см. Непараметрические корреляции). Если две рассматриваемые переменные по природе своей категориальны, подходящими непараметрическими критериями для тестирования зависимости будут: Хи-квадрат, Фи коэффициент, точный критерий Фишера. Дополнительно доступен критерий зависимости между несколькими переменными так называемый коэффициент конкордации Кендалла. Этот тест часто используется для оценки согласованности мнений независимых экспертов (судей), в частности, баллов, выставленных одному и тому же субъекту.
Какой метод использовать
Нелегко дать простой совет, касающийся использования непараметрических процедур. Каждая непараметрическая процедура в модуле имеет свои достоинства и свои недостатки. Например, двухвыборочный критерий Колмогорова-Смирнова чувствителен не только к различию в положении двух распределений, например, к различиям средних, но также чувствителен и к форме распределения. Критерий Вилкоксона парных сравнений предполагает, что можно ранжировать различия между сравниваемыми наблюдениями. Если это не так, лучше использовать критерий знаков. В общем, если результат исследования является важным (например, оказывает ли людям помощь определенная очень дорогостоящая и болезненная терапия?), то всегда целесообразно применить различные непараметрические тесты. Возможно, результаты проверки (разными тестами) будут различны. В таком случае следует попытаться понять, почему разные тесты дали разные результаты. С другой стороны, непараметрические тесты имеют меньшую статистическую мощность (менее чувствительны), чем их параметрические конкуренты, и если важно обнаружить даже слабые отклонения (например, является ли данная пищевая добавка опасной для людей), следует особенно внимательно выбирать статистику критерия.
Большие массивы данных и непараметрические методы. Непараметрические методы наиболее приемлемы, когда объем выборок мал. Если данных много (например, n > 100), то не имеет смысла использовать непараметрические статистики. Глава Элементарные понятия статистики предлагает краткое ознакомление с центральной предельной теоремой. Главное здесь состоит в том, что когда выборки становятся очень большими, то выборочные средние подчиняются нормальному закону, даже если исходная переменная не является нормальной или измерена с погрешностью. Таким образом, параметрические методы, являющиеся более чувствительными (имеют большую статистическую мощность), всегда подходят для больших выборок. Большинство критериев значимости многих непараметрических статистик, описанных далее, основываются на асимптотической теории (больших выборок) поэтому соответствующие тесты часто не выполняются, если размер выборки становится слишком малым. Обратитесь к описаниям определенных критериев, чтобы узнать больше об их мощности и эффективности.
В некоторых исследовательских проектах можно сформулировать гипотезы относительно распределения рассматриваемой переменной. Например, переменные, значения которых определяются бесконечным числом независимых факторов, распределены по нормальному закону: можно предположить, что рост индивидуума является результатом воздействия многих независимых факторов, таких как различные генетические предрасположенности, болезни, перенесенные в раннем возрасте и т.д. Как следствие, рост имеет тенденцию к нормальному распределению в населении. С другой стороны, если наблюдаемые значения переменной являются результатом очень редких событий, то переменная будет иметь распределение Пуассона (которое иногда называется распределением редких событий). Например, несчастные случаи на производстве можно рассматривать как результат пересечения ряда неудачных событий (на житейском языке стечением маловероятных обстоятельств), поэтому их частота приближенно описывается распределением Пуассона. Эти и другие полезные распределения подробно описываются в соответствующих разделах.

Гипотеза нормальности. Другим обычным приложением процедуры подгонки распределения является проверка гипотезы нормальности до того, как использовать какой-либо параметрический тест (см. выше).
Все права на материалы электронного учебника принадлежат компании StatSoft
Что делать, если ваши данные не являются нормальными?
Дата публикации Nov 2, 2018

Введение
ЭтоНеделя хэллоуинаМежду этими хитростями и удовольствиями мы, фанаты данных, смеемся над этим милым мемом в социальных сетях.

Вы думаете, что это шутка? Позвольте мне сказать вам, это не смешное дело. Это страшно, правда духа Хэллоуина!
Если мы не можем предположить, что большинство наших данных (делового, социального, экономического или научного происхождения) по крайней мере приблизительно «нормальны» (т. Е. Они получены гауссовым процессом или суммой нескольких таких процессов), то мы обречены!
Вот очень краткий список вещей, которые не будут действительны,
Всемогущее и вездесущее нормальное распределение
Давайте сделаем этот раздел коротким и приятным.
Нормальное (гауссовское) распределение является наиболее широко известным распределением вероятностей. Вот несколько ссылок на статьи, описывающие его мощь и широкую применимость,
Почему ученые данных любят гауссов?
Три основные причины, по которым распространение по Гауссу так популярно у инженеров по машинному обучению и…
towardsdatascience.com
Из-за его появления в различных областях иЦентральная предельная теорема(CLT), это распределение занимает центральное место в науке о данных и аналитике.
В теории вероятностей нормальное (или гауссово, или гауссово, или лапласово-гауссовское) распределение является очень распространенным непрерывным…
en.wikipedia.org
Так в чем проблема?
Это все неуклюжий, в чем проблема?
Проблема в том, что часто вы можете найти дистрибутив для вашего конкретного набора данных, который может не удовлетворять нормальности, то есть свойствам нормального дистрибутива. Но из-за чрезмерной зависимости от предположения о нормальности,Большинство структур бизнес-аналитики специально разработаны для работы с нормально распределенными наборами данных.,
Это почти укоренилось в нашем подсознании.
Допустим, вас просят обнаружить проверку, имеет ли смысл новый пакет данных из какого-либо процесса (инженерного или бизнес). По ‘придать смыслаВы имеете в виду, если новые данныепринадлежатт.е. если он находится в «ожидаемом диапазоне».
Что это за «ожидание»? Как определить количество?
Автоматически, как если бы это было направлено подсознательным двигателем, мы измеряем среднее значение и стандартное отклонение выборочного набора данных и продолжаем проверять, попадают ли новые данные в определенный диапазон стандартных отклонений.
Если нам нужно работать с доверительной вероятностью 95%, то мы будем рады видеть, что данные находятся в пределах 2 стандартных отклонений. Если нам нужно более строгое ограничение, мы проверяем 3 или 4 стандартных отклонения. Мы рассчитываемхолодный полярный континентальный воздухили мы следуемшесть Сигмруководящие принципы длям.д.(частей на миллион) уровень качества.

Все эти расчеты основаны на неявном предположении, что данные о населении (НЕ выборка) следуют гауссовскому распределению, т.е. фундаментальный процесс, на основе которого были получены все данные (в прошлом и в настоящем), определяется шаблоном левая сторона.
Но что произойдет, если данные будут следовать шаблону с правой стороны?


Существует ли более универсальная граница, когда данные НЕ являются нормальными?
В конце дня нам все еще понадобитсяматематически обоснованная техника для количественной оценки нашей достоверностидаже если данные не нормальные. Это означает, что наши расчеты могут немного измениться, но мы все равно должны сказать что-то вроде этого:
«Вероятность наблюдения новой точки данных на определенном расстоянии от среднего значения такая-то и такая-то…»
Очевидно, что нам нужно искать более универсальную границу, чем заветные границы Гаусса 68–95–99,7 (что соответствует стандартному отклонению 1/2/3 от среднего значения).
К счастью, есть одна такая граница, называемая «граница Чебышева».
Что такое Чебышевский переплет и чем он полезен?
Неравенство Чебышева (также называемое неравенством Бинайме-Чебышева) гарантирует, чтодля широкого класса распределений вероятностей не более определенной доли значений может быть больше определенного расстояния от среднего,
В частности, не более1 /К²значений распределения может быть большеКстандартные отклонения от среднего значения (или эквивалентно, по крайней мере,1-1 / k²значения распределения находятся в пределахКстандартные отклонения от среднего значения).
Это относится к практически неограниченным типам вероятностных распределений и работает в гораздо более смягченном предположении, чем нормальность.
Даже если вы ничего не знаете о секретном процессе ваших данныхесть хороший шанс, что вы можете сказать следующее,
«Я уверен, что 75% всех данных должны находиться в пределах 2 стандартных отклонений от среднего»,
Я уверен, что 89% всех данных должны находиться в пределах 3 стандартных отклонений от среднего значения ».
Вот как это выглядит для произвольно выглядящего дистрибутива,

Как это применить?

Таблица выглядит следующим образом (здесь k обозначает много стандартных отклонений от среднего значения),

Видео демонстрация его применения здесь,
В чем подвох? Почему люди не используют эту «более универсальную» границу?
Очевидно, что выгода, глядя на таблицу или математическое определение.Правило Чебышева намного слабее, чем правило Гаусса, когда речь идет о границах данных.,
Следует1 / k²картина по сравнению сэкспоненциально падающийшаблон для нормального распределения.
Например, чтобы связать что-либо с достоверностью 95%, вам необходимо включить данные до 4,5 стандартных отклонений по сравнению только с 2 стандартными отклонениями (для нормальных значений).
Но он все равно может спасти тот день, когда данные не похожи на нормальное распределение.
есть что-нибудь получше?
Есть еще одна граница под названием «Чернофф Бунд«/Неравенство Хеффдингакоторый дает экспоненциально резкое распределение хвоста (по сравнению с 1 / k²) для сумм независимых случайных величин.
Это также может использоваться вместо гауссовского распределения, когда данные не выглядят нормально, но только тогда, когда мы имеем высокую степень уверенности в том, что основной процесс состоит из подпроцессов, которые полностью независимы друг от друга.
К сожалению, во многих социальных и бизнес-случаях окончательные данные являются результатом чрезвычайно сложного взаимодействия многих подпроцессов, которые могут иметь сильную взаимозависимость.
Резюме
В этой статье мы узнали о конкретном типе статистической границы, которая может быть применена к как можно более широкому распределению данных независимо от предположения о нормальности. Это удобно, когда мы очень мало знаем об истинном источнике данных и не можем предположить, что оно следует гауссовскому распределению. Граница следует степенному закону, а не экспоненциальному характеру (как гауссовский) и поэтому является более слабой Но это важный инструмент в вашем репертуаре для анализа любого произвольного типа распределения данных.



