Статья 8. Предоставление первичных статистических данных и административных данных субъектам официального статистического учета
Статья 8. Предоставление первичных статистических данных и административных данных субъектам официального статистического учета
Информация об изменениях:
Федеральным законом от 2 июля 2013 г. N 171-ФЗ в часть 1 статьи 8 внесены изменения
1. Респонденты, за исключением респондентов, указанных в частях 2 и 3 настоящей статьи, обязаны безвозмездно предоставлять субъектам официального статистического учета первичные статистические данные и административные данные, необходимые для формирования официальной статистической информации, в том числе данные, содержащие сведения, составляющие государственную тайну, сведения, составляющие коммерческую тайну, сведения о налогоплательщиках, о персональных данных физических лиц и другую информацию, доступ к которой ограничен федеральными законами.
ГАРАНТ:
См. Положение об условиях предоставления в обязательном порядке первичных статистических данных и административных данных субъектам официального статистического учета, утвержденное постановлением Правительства РФ от 18 августа 2008 г. N 620
Информация об изменениях:
Федеральным законом от 2 июля 2013 г. N 171-ФЗ в часть 5 статьи 8 внесены изменения
5. Первичные статистические данные и административные данные, содержащие сведения, составляющие государственную тайну, сведения, составляющие коммерческую тайну, сведения о налогоплательщиках, о персональных данных физических лиц и другую информацию, доступ к которой ограничен федеральными законами, предоставляются в соответствии с законодательством Российской Федерации об этих категориях информации ограниченного доступа.
Информация об изменениях:
ГАРАНТ:
В 2021 году сведения, указанные в части 5.1, предоставляются держателями реестров акционеров акционерных обществ до 10 сентября 2021 г.
6. Юридические лица, имеющие обособленные подразделения, предоставляют субъектам официального статистического учета в установленном порядке первичные статистические данные как по юридическим лицам, так и по таким подразделениям.
Информация об изменениях:
Информация об изменениях:
ГАРАНТ:
В отношении субъектов малого предпринимательства положения части 7 (в редакции Федерального закона от 30 декабря 2020 г. N 500-ФЗ) применяются с 1 января 2022 г..
7. Первичные статистические данные, документированные по формам федерального статистического наблюдения, предоставляются респондентами, за исключением респондентов, указанных в части 2 настоящей статьи, субъектам официального статистического учета в форме электронного документа, подписанного электронной подписью, если иное не установлено федеральными законами. При этом вид электронной подписи определяется субъектами официального статистического учета самостоятельно, за исключением случаев, если требование об использовании конкретного вида электронной подписи предусмотрено федеральными законами, принятыми в соответствии с ними нормативными правовыми актами либо соглашением между участниками электронного взаимодействия. Респондентами, указанными в части 2 настоящей статьи, первичные статистические данные, документированные по формам федерального статистического наблюдения, могут предоставляться субъектам официального статистического учета на бумажных носителях или в электронном виде в соответствии с законодательством Российской Федерации.
8. Бланки утвержденных в установленном настоящим Федеральным законом порядке форм федерального статистического наблюдения и указания по их заполнению предоставляются респондентам субъектами официального статистического учета безвозмездно.
9. Условия предоставления в обязательном порядке первичных статистических данных и административных данных субъектам официального статистического учета определяются Правительством Российской Федерации, если иное не установлено федеральными законами.
Информация об изменениях:
Федеральным законом от 28 марта 2017 г. N 38-ФЗ часть 10 статьи 8 изложена в новой редакции
10. Респонденты обязаны безвозмездно предоставлять Банку России в установленном им порядке первичные статистические данные для осуществления Банком России в соответствии с Федеральным законом от 10 июля 2002 года N 86-ФЗ «О Центральном банке Российской Федерации (Банке России)» функции по составлению платежного баланса Российской Федерации, международной инвестиционной позиции Российской Федерации, статистики внешней торговли Российской Федерации услугами, внешнего долга Российской Федерации, международных резервов Российской Федерации, прямых инвестиций в Российскую Федерацию и прямых инвестиций из Российской Федерации за рубеж.
ГАРАНТ:
См. комментарии к статье 8 настоящего Федерального закона
Административная статистика

Административные правонарушения представляют собой одну из трех обширных отраслей правовой статистики. К ним относятся действия, посягающие на установленный общественный порядок и нормы права. Административная статистика ведет количественный учет проступков и предъявляемых по ним мер взыскания.

Мера опасности
Административные проступки не несут той общественной опасности и не имеют таких последствий, которыми характеризуются преступления. Следовательно, мера наказания преследует преимущественно воспитательную цель. Также учитывается характер правонарушения:
Объекты административно-правовой статистики включают в себя:
Органы юрисдикции
В России более тридцати органов, наделенных административной юрисдикцией:
Каждое ведомство ведет статистику административных правонарушений по разным видам деятельности. Например:

Виды ответственности
Характер причиненного ущерба определяет состав административного правонарушения:
Статистика административных наказаний включает следующие виды ответственности:
Статистика привлечения к административной ответственности включает и более суровые меры воздействия на правонарушителей:
Особенности назначения взысканий
Административная статистика показывает, что часто проверка выявляет не одно, а несколько проступков. Суд вправе наложить взыскание только за одно правонарушение или назначить отдельное наказание за каждое. Особенности процедуры:
Статистика дел об административных правонарушениях отмечает, что при нарушении разных норм закона суд или административная комиссия назначает самостоятельное наказание за каждый проступок.

Особые категории граждан
Административный кодекс выделяет несколько категорий лиц, которые освобождаются от определенных видов взыскания:
Штрафы ГИБДД
Административно-правовая статистика подразделяет взыскания на два вида – основные и дополнительные наказания.

Административная статистика показывает, что введение скидки привело к росту числа оплаченных штрафов. Около 60% нарушителей ПДД воспользовались 50% скидкой при оплате штрафных санкций.
Статистика административных правонарушений в Москве отмечает снижение количества ДТП на улицах столицы. Показатель снизился за последние пять лет в 2,5 раза. Количество аварий с пострадавшими уменьшилось на 24%. Установление камер фиксации помогло снизить количество угнанных машин в три раза. Административная статистика показывает, что Москва стала самым безопасным регионом в плане дорожного движения. Главная цель – снижение смертности на дорогах столицы.

Данные за 2017 год
Статистика административных правонарушений 2017 указывает на завершение около 7,2 млн. дел. Из них:
Статистика административной ответственности отмечает, что в 70% случаев были назначены штрафы. Общая сумма взысканий – 100 млрд. руб. Из них уплачено не более 11 млрд. руб. Средняя сумма штрафа:
Дополнительные взыскания в 2017 году:
Декриминализация статей
Статистика административных дел за 2017 год показывает, что декриминализация некоторых статей УК РФ дает положительные результаты. Например, статья о побоях была разделена на несколько частей. Теперь бытовое рукоприкладство перешло в административное право.
Какая статистика административных правонарушений в России? За 6 месяцев 2017 за побои к ответственности было привлечено более 50 тыс. человек. Из них:
Статистика административных дел фиксирует пятикратное увеличение количества граждан, наказанных за побои. В уголовном кодексе статья о побоях применяется при повторном рукоприкладстве. Естественно, наказание будет более суровым.
Малолетние правонарушители
По данным правоохранительных органов наблюдается снижение количества малолетних правонарушителей. За 6 месяцев 2017 года их число уменьшилось на 21%. Статистика административных правонарушений несовершеннолетних граждан показывает, что с 2008 года:
Административная статистика за 6 месяцев 2017 года зафиксировала около 20 тыс. правонарушителей подросткового возраста. Показатель почти на 5,5 тыс. меньше, чем в 2016 году. Правительство уделяет много внимания молодежной политике. Положительное влияние на профилактику детской преступности оказывает и расширение волонтерского движения.

Участие детей в наркоторговле
Административная статистика свидетельствует об увеличении доли участия несовершеннолетних лиц в торговле наркотиками. Дети из проблемных семей пытаются таким образом зарабатывать на жизнь. За подобные проступки детям грозит лишь административное наказание. В 2016 году прокуратура зафиксировала 6,29 тыс. преступлений, связанных с оборотом наркотических веществ. Раскрываемость составляет около 60 % дел.
Административный надзор
В целях снижения рецидивной преступности несколько лет назад был введен административный надзор. По статистике около 50% правонарушений совершают ранее судимые лица. Многие из них отсидели от 3 до 10 лет. Цели административного надзора:
В 2016 году на свободу было выпущено около 210 тыс. человек. Из них освобожденных 157 тыс. граждан полностью отбыли срок заключения. Статистика МВД по административным правонарушениям свидетельствует об установлении надзора в отношении 69 тыс. человек, что составляет 44% от количества освобожденных лиц.
Таможенная деятельность
Существенно возросла статистика по административным правонарушениям за 2017 год в сфере таможенного дела. Возбуждено более 119,3 тыс. дел. Прирост составил 48,5 %. Из них:
Административная статистика показывает, что значительная часть дел связана с нарушением таможенных правил:
Административная статистика отмечает, что по рассмотренным делам принято более 114,7 тыс. решений. Из них 83,9 тыс. решений вынесено должностными лицами, 30,7 тыс. – судом. Всего:
Статистика привлечения к административной ответственности в 2017 году показывает, что общая сумма взысканий составила около 157 млрд. руб. Решения по видам взысканий:

Пожарная безопасность
Статистика пожаров в административных зданиях несколько возросла. В 2017 году их количество увеличилось на 3,79% по сравнению с 2016. Сравнительные данные об объектах сгорания при пожарах:
| Объект | Количество пожаров | Число погибших | ||
| 2016 год | 2017 год | 2016 год | 2017 год | |
| Производственные здания | 2693 | 2795 | 122 | 59 |
| Складские помещения | 1336 | 1430 | 29 | 26 |
| Жилые здания | 97049 | 92929 | 8005 | 7201 |
| Общественные здания | 5613 | 5116 | 35 | 45 |
| Здания с/з назначения | 574 | 576 | 13 | 11 |
| Здания на этапе строительства | 812 | 712 | 39 | 16 |
Основные причины возгорания:
Отчетность в Росстат
Наказание за непредставление отчетности в статистику – административный штраф. Его размер:
Повторное правонарушение влечет за собой увеличение штрафа:
Уплата штрафа не освобождает нарушителя от необходимости сдавать отчетность в Росстат. Компания вправе оспорить наложенный на нее штраф. Однако придется доказать, что задержка произошла не по ее вине.
Ответственность за нарушение карантина по коронавирусу
К административным правонарушениям КоАП РФ относит также и пренебрежение гражданами условий карантина в период пандемии коронавируса. С 1 апреля в кодекс внесены изменения, по которым заметно усилены меры наказания, и суммы штрафов к нарушителям карантинных мер. Введена не только административная ответственность за нарушение карантина по коронавирусу, но и уголовная. Карантин установлен для следующих лиц:
Таким людям запрещено покидать свое жилье на протяжении карантина. В противном случае нарушителю грозит наказание. Мера ответственности зависит от статуса субъекта (ст.6.3 КоАП РФ):

При наличии серьезных последствий для окружающих людей правонарушителя могут привлечь к уголовной ответственности (ст.236 УК РФ):

По данным РИА Новости только 12 апреля в столице России было составлено 1358 протоколов за нарушение правил социальной дистанции по ст. 3.18.1 КОАП Москвы.
Больше о коронавирусе можно узнать в другой статье – https://vawilon.ru/statistika-koronavirusa/.
7 базовых статистических понятий, необходимых дата-сайентисту
Даже если вы хорошо программируете, но слабо ориентируетесь в статистике, вероятность выжить в Data Science очень низка.


У статистики есть несколько различных определений. Одно из самых простых и точных — это «наука о сборе и классификации цифровых данных». А если добавить к нему немного о программировании и машинном обучении, то получится неплохое описание основ Data Science.

В самом деле, в Data Science трудно найти область, где нет статистики в том или ином виде. Она нужна для:
Мы выбрали семь базовых концепций, без которых в Data Science точно не обойтись. К счастью, они не слишком сложны.

С некоторых пор утверждает, что он data scientist. В предыдущих сезонах выдавал себя за математика, звукорежиссёра, радиоведущего, переводчика, писателя. Кандидат наук, но не точных. Бесстрашно пишет о Data Science и программировании на Python.
1. Меры описательной статистики
Ключевые показатели, применяемые в описательной статистике (их ещё называют мерами или, если точнее, мерами центральной тенденции), — это:

Посмотрите это небольшое видео о среднем, медиане и моде на сайте Академии Хана — образовательного ресурса, который славится доходчивыми объяснениями. Там всё просто, на понятном русском языке.
Кроме трёх перечисленных, есть и другие статистические показатели — например, меры рассеяния. Главная из них — дисперсия, о ней ниже. Все они нужны, чтобы понять, какие перед нами данные и о чём именно они рассказывают.
2. Распределение
Внешняя форма данных, выраженная в мерах описательной статистики, даёт нам информацию об их характере. Это как в жизни: по фигуре, походке и одежде человека обычно можно догадаться о его поле, возрасте и даже профессии. В случае числовых данных мы догадываемся о распределении.
Термин пришёл из теории вероятностей, которая рассматривает любое событие в мире как имеющее ту или иную вероятность. Однородные события хоть и происходят с разной вероятностью, но подчиняются распределению, которое «раздаёт» им эти вероятности.
В Data Science распределение понимается обобщённо: это закон соответствия одной величины другой. Оно подсказывает нам, какой именно процесс может скрываться за данными, и то, насколько эти данные полны. Чуть подробнее об этом в нашей статье про математику для джунов.
Возможно, вы уже слышали про колокол нормального распределения, или гауссиану: она описывает процессы, где результат является суммой многих случайных величин, каждая из которых слабо зависит от другой и вносит сравнительно небольшой вклад.
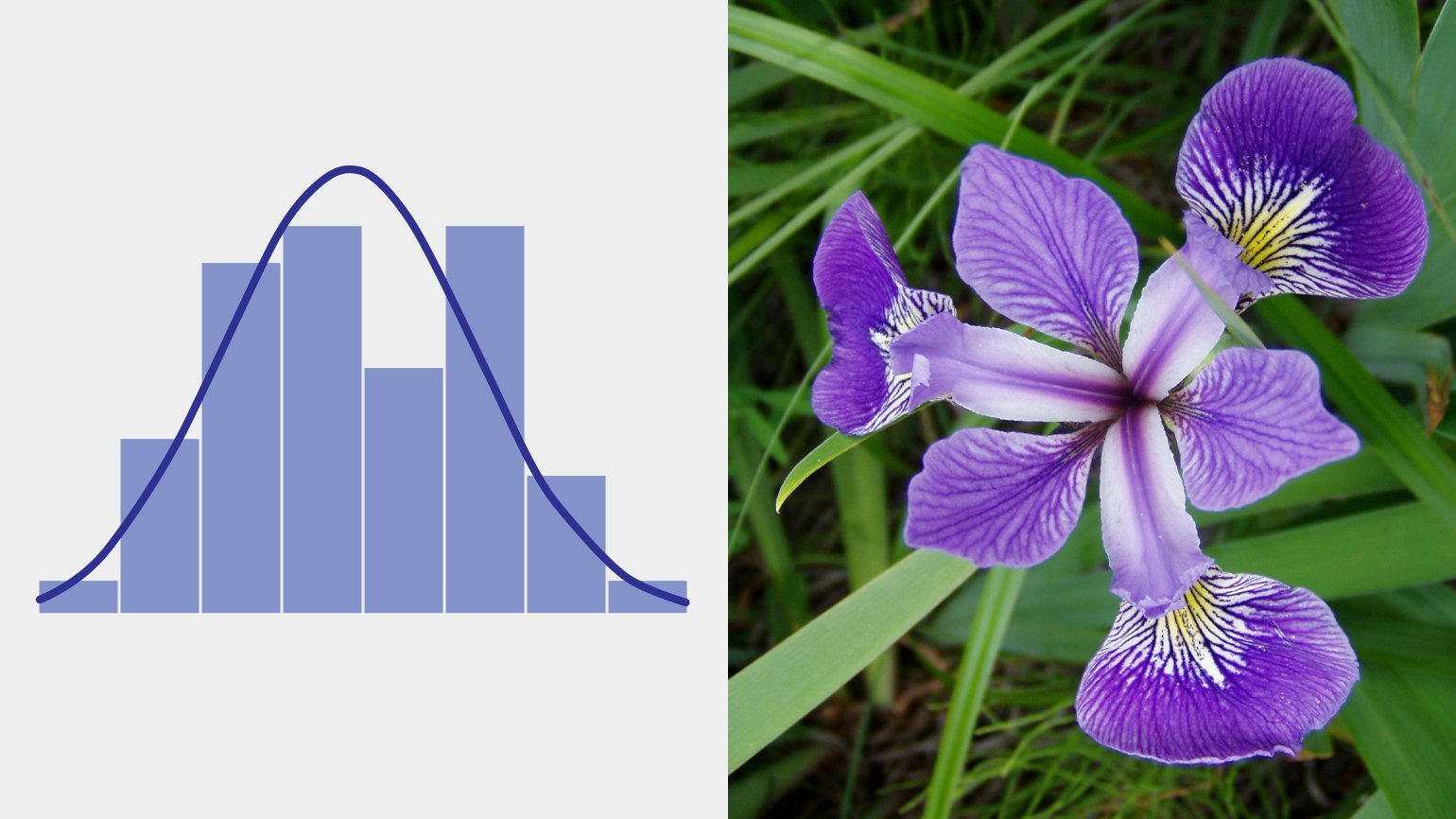
Величина ошибок измерения в физике, длина когтей, зубов и шерсти в биологии, объёмы речных стоков в гидрологии — все эти показатели имеют нормальное распределение. Это, пожалуй, самое распространённое в природе и не только в природе распределение, поэтому оно и названо нормальным.
Распределение Пуассона тоже часто встречается в работе дата-сайентистов и аналитиков: это число событий за какой-то промежуток времени — при условии, что события независимы друг от друга и имеют некоторый порог интенсивности.
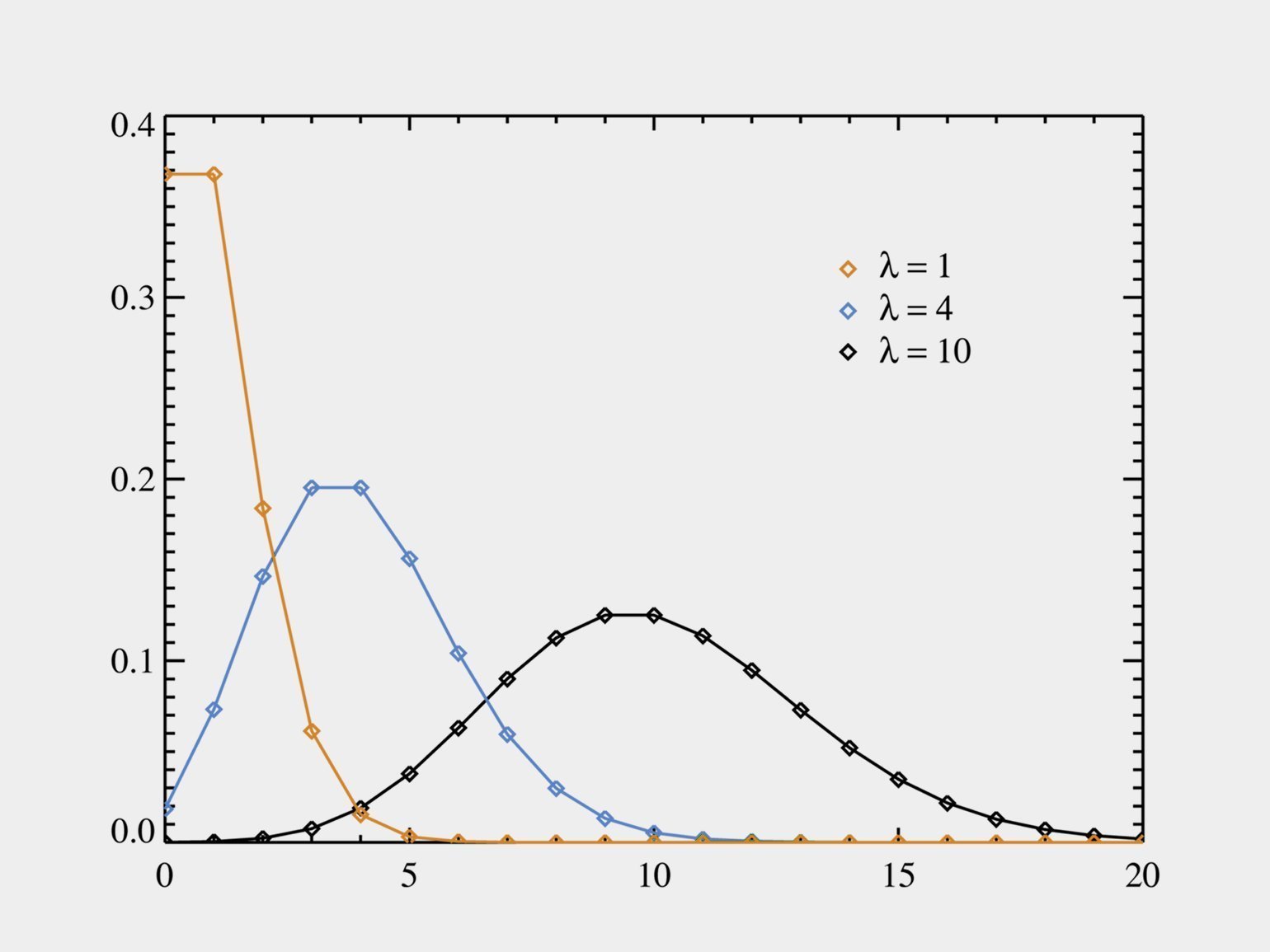
Это и число посетителей в торговом центре, и количество голов, забитых футбольной командой, и скорость роста колонии бактерий.
Существуют и другие распределения, в том числе довольно экзотические: Вигнера, Вейбулла, Коши. Они встречаются намного реже или преимущественно в каких-то специальных областях вроде квантовой физики. Тем не менее дата-сайентисту нужно знать графики, параметры и названия основных распределений, благо их не так много.
3. Семплирование
Предположим, вам требуется решить важную задачу: выяснить среднюю ширину морды домашних котов нашей страны. Прямой способ, то есть измерение всех домашних питомцев, невозможен по ряду объективных причин. Придётся ограничиться выборкой — взять какое-то число животных, измерить морды именно им и сделать выводы по итогам только этих исследований.

Но тут сразу же возникают вопросы:
Семплирование — это группа статистических методов и приёмов, отвечающих на эти вопросы. С помощью семплирования мы формируем нашу выборку так, чтобы она наилучшим образом отражала свойства генеральной совокупности — то есть свойства всех котов страны.

Иными словами, вы не можете измерить N первых попавшихся котов и обобщить результат для остальных. Выборка должна хорошо «сидеть» во всей популяции кошек, чтобы можно было делать обоснованные выводы. Такую выборку называют релевантной.
Кстати, статистика и котики — близнецы-братья. После выхода одноимённой книги Владимира Савельева мы говорим «статистика», а подразумеваем «котики», и наоборот. И смело рекомендуем эту книгу всем, кто дочитал до этого места.
В Data Science методы семплирования применяются при разработке, подготовке и оценке датасетов, чтобы они одновременно и были упорядоченными, и соответствовали реальности.
4. Смещение
Прочитайте нашу статью о создании простой модели машинного обучения. Она предсказывает город, в который вероятнее всего поедет турист, на основании его возраста, пола, места жительства, дохода и транспортных предпочтений. Такая рекомендательная система на минималках.
Смещение происходит, когда модель недооценивает или переоценивает какой-либо параметр. Представим, что модель из статьи выше отправляет всех краснодарцев в Париж — независимо от их дохода, предпочтений и других параметров. В этом случае мы скажем, что модель переоценивает значение параметра «Город проживания».
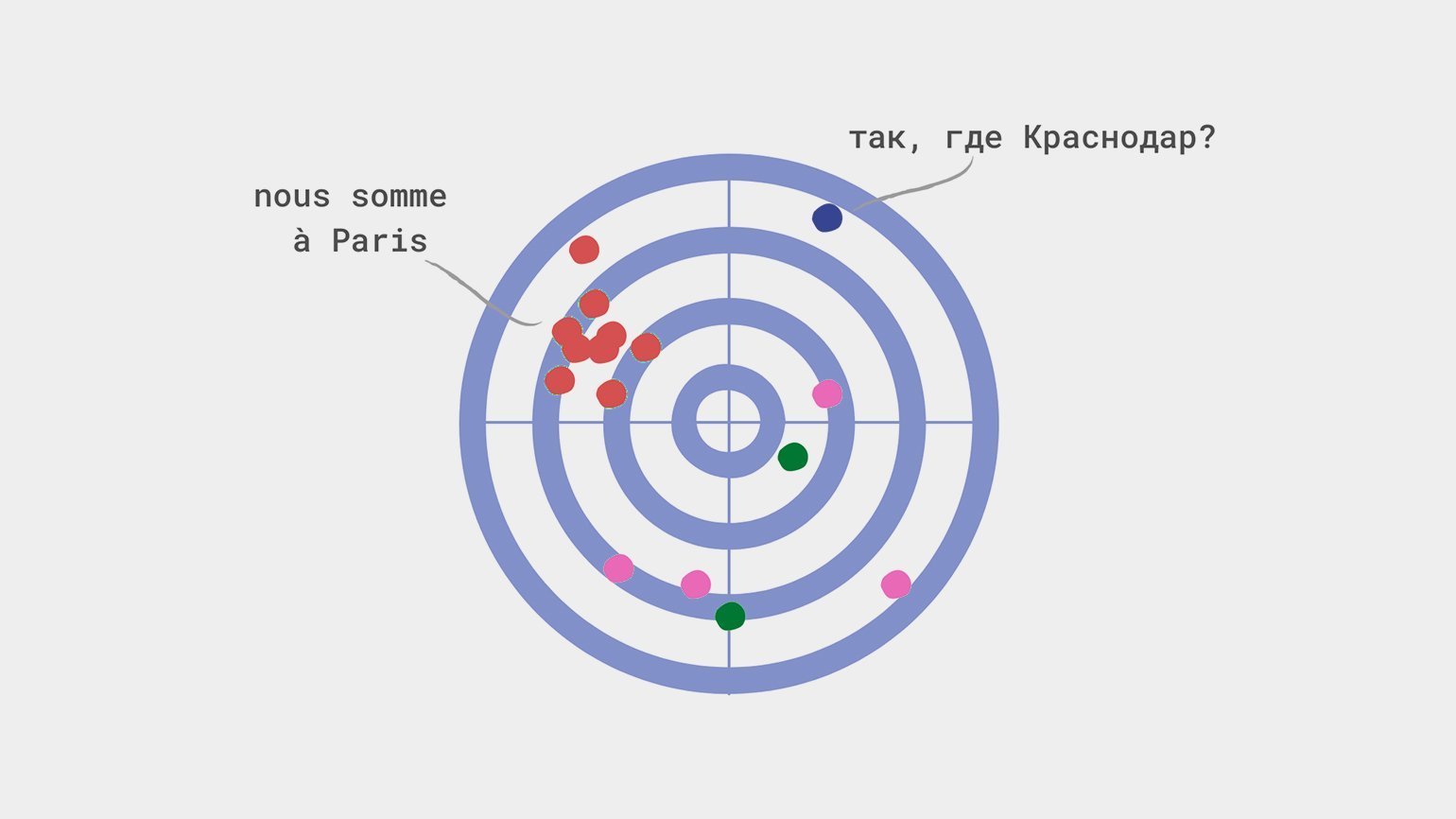
Чаще всего причиной смещения являются:
Когда мы неверно собираем данные, говорят о систематической ошибке отбора. Например, в прошлом веке многие считали, что во Вселенной больше голубых галактик, — впечатление возникало потому, что плёнка была более чувствительна к голубой части спектра.

Другая ошибка — ошибка меткого стрелка — происходит, когда мы вольно или невольно отбираем в выборку только схожие между собой данные, то есть фактически рисуем мишень вокруг места, куда попадём.
Причин, вызывающих смещение, так много, что Марк Твен заметил: «Существует три вида лжи: ложь, наглая ложь и статистика». Например:
Эти и другие ошибки смещения трудно выявить статистическими методами, поэтому нужно стараться избежать их до того, как вы начнёте сбор данных.
Если пить «Боржоми» уже поздно (датасет уже сформирован), обязательно спросите себя: «Не смещены ли мои данные?» — а они наверняка смещены, «Куда и почему они смещены?» и «Можно ли с этим жить?»
5. Дисперсия
Дисперсия — это величина, показывающая, как именно и насколько сильно разбросаны значения — например, предсказания модели машинного обучения или доход за рассматриваемый период. За точку, относительно которой эти значения разбросаны, берут истинное значение, целевую переменную или математическое ожидание, которое вычисляется теоретически и заранее.
Часто в качестве матожидания выступает обычное среднее арифметическое. Например, математическое ожидание количества очков при броске игрального кубика равно среднему арифметическому очков на всех гранях:
(1 + 2 + 3 + 4 + 5 + 6) / 6 = 21/6 = 3,5
Представьте себе тир, стрелка и мишень. Снайпер стреляет в стандартный круг, где попадание в центр даёт 10 баллов, в зависимости от удаления от центра количество баллов снижается, а крайние области дают всего 1 балл. Каждый выстрел стрелка — это случайное целое значение от 1 до 10.
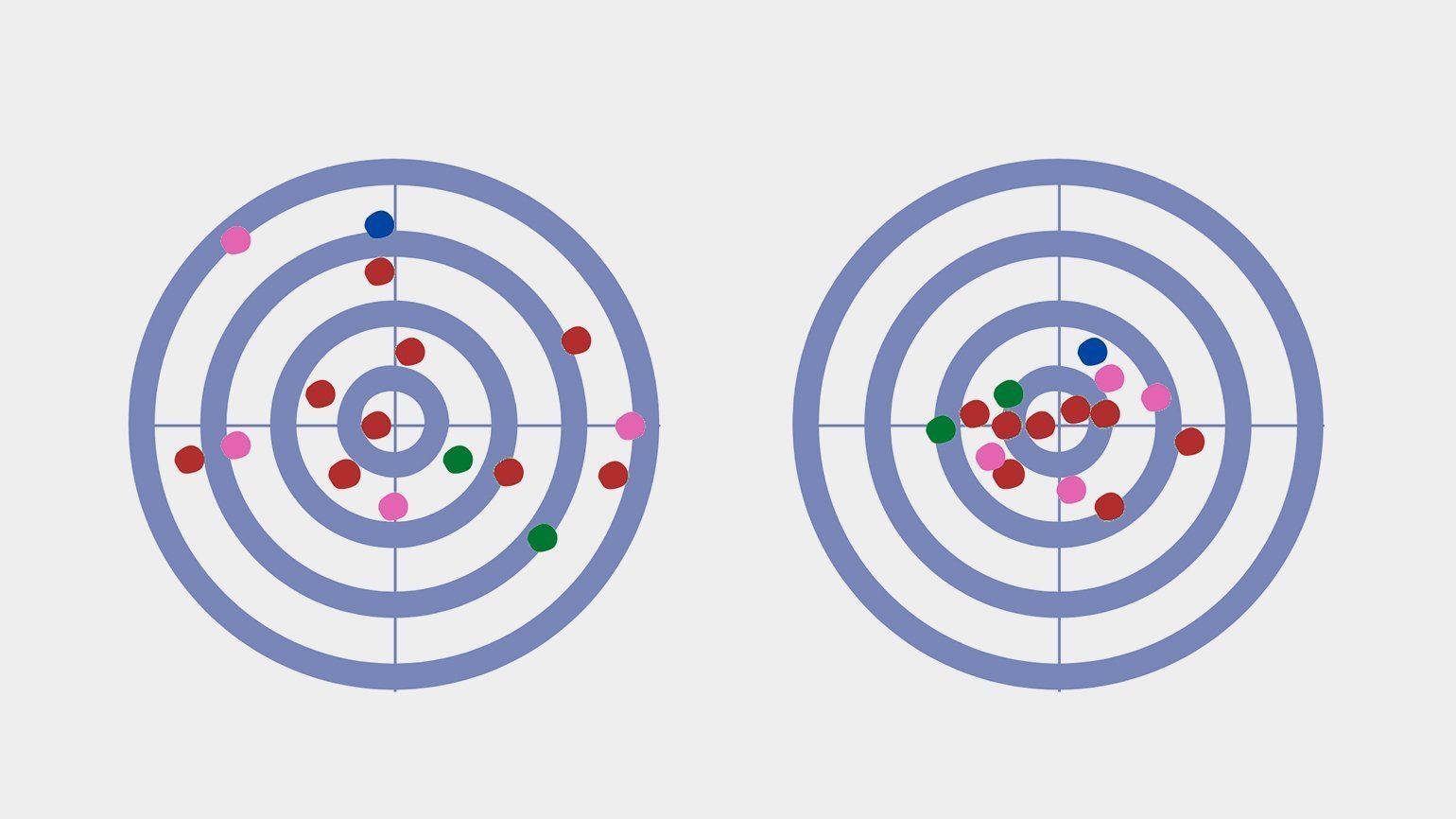
Изрешечённая пулями мишень — отличная иллюстрация распределения. Дисперсия здесь — величина, обратная кучности попаданий: хорошая кучность означает низкую дисперсию, и наоборот.
6. Дилемма (компромисс) смещения и дисперсии
Смещение и дисперсия вместе составляют итоговую ошибку предсказания модели машинного обучения. В идеальном мире и смещение маленькое, и дисперсия низкая. На практике это связано в дилемму: уменьшение одной из величин неизбежно приводит к росту другой.

Если не вдаваться в детали, обучение модели — это построение функции, график которой лучше всего ложится на точки из тренировочного набора данных.
Модель может нарисовать нам довольно сложную и заковыристую функцию, график, который хорошо охватывает все точки в тренировочных данных. Но если наложить этот график на новые точки (то есть дать функции новые данные), она сработает хуже — так и получается смещение.

С другой стороны, обучение на разных тренировочных наборах или даже разных датасетах с большой вероятностью даст разброс в предсказаниях, то есть высокую дисперсию.
Более сложные модели дают низкое смещение, но чувствительны к шуму и колебаниям в новых данных, поэтому их предсказания разбросаны. Если при обучении наш снайпер будет учитывать незначимые факторы (вроде цвета мишени или направления магнитного поля Земли), то в другом тире, с другой винтовкой или в другую погоду точность его стрельбы упадёт.
Простые модели, напротив, упускают важные параметры и «бьют кучно, но мимо». Как другой снайпер, не приученный обращать внимание на ветер и расстояние до мишени.
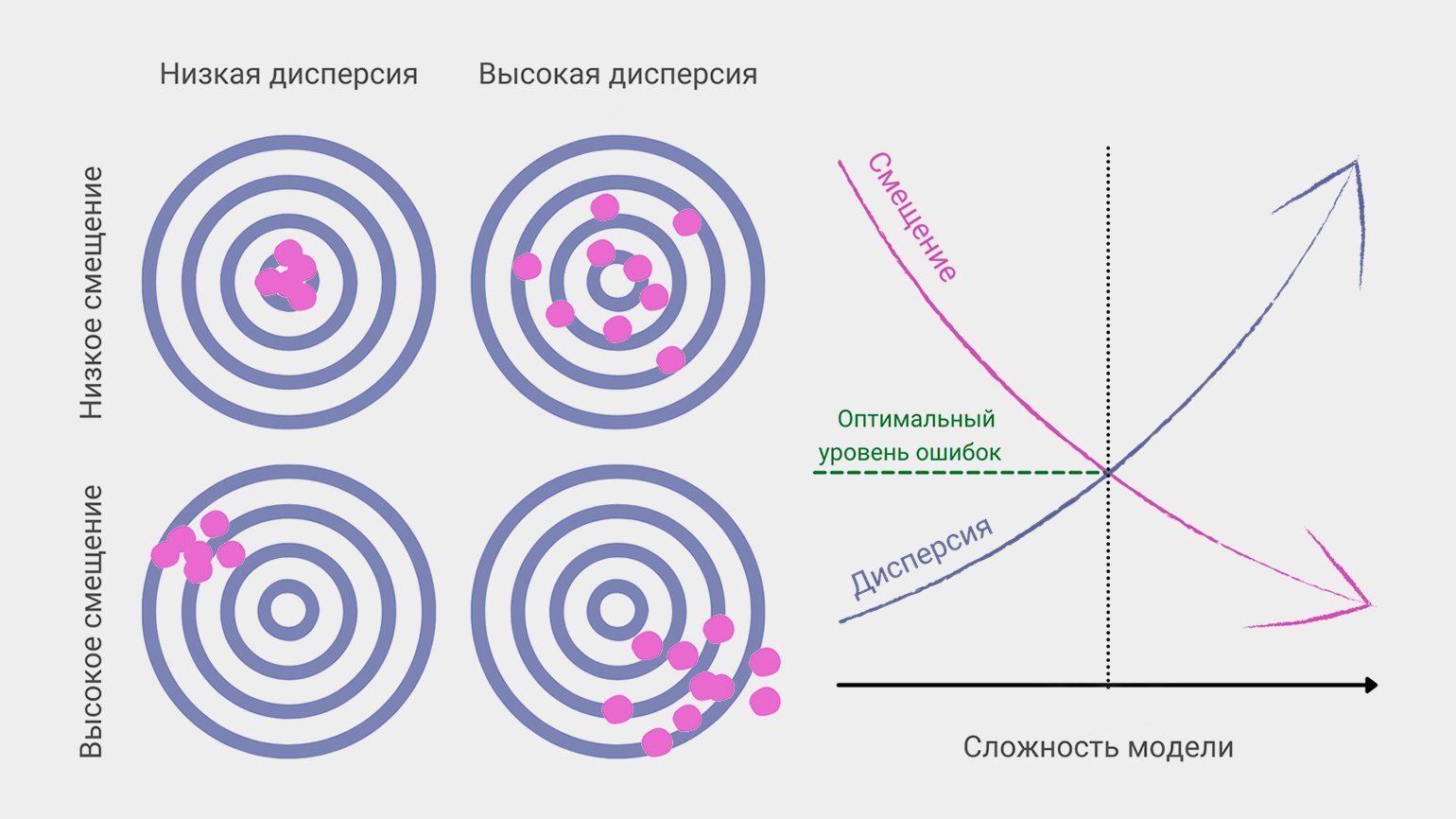
В процессе настройки модели машинного обучения дата-сайентист всегда ищет компромисс между смещением и дисперсией, чтобы уменьшить общую ошибку предсказания.
Кстати, эта дилемма встречается не только в статистике и машинном обучении, но и в обучении людей. В исследовании 2009 года утверждается, что люди используют эвристику «высокое смещение + низкая дисперсия»: мы заблуждаемся, зато очень уверенно.
Учтите это, если захотите сделать свой ИИ более похожим на человека.
7. Корреляция
Когда изменения одной величины сопутствуют изменениям другой, говорят о корреляции. Главное, что необходимо о ней знать: корреляция не означает причинно-следственную связь.
Линейная корреляция — это когда изменения одной величины пропорциональны изменениям другой. Она может быть:
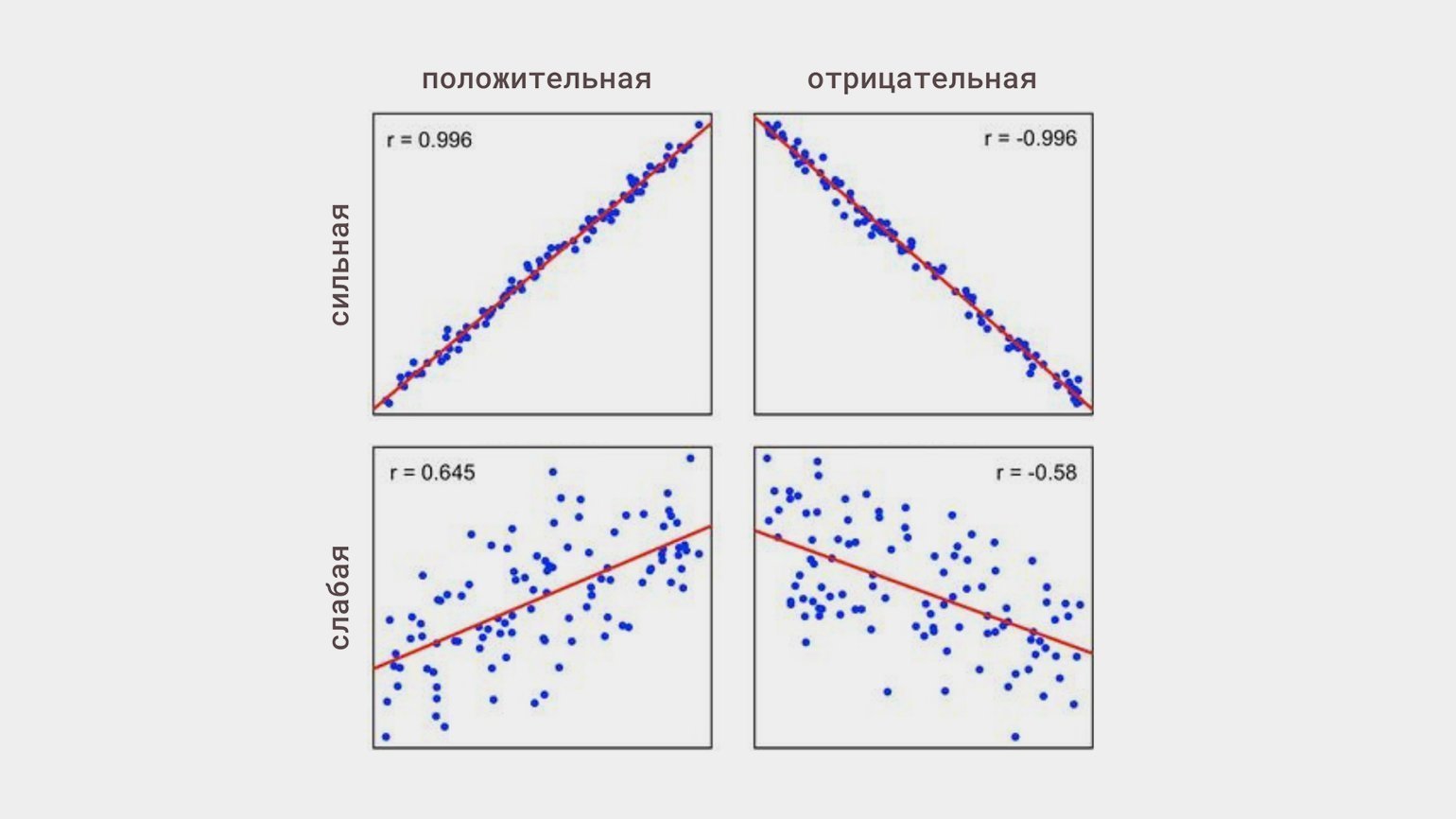
Статистическую связь между переменными исследуют с помощью корреляционного анализа. Его основная задача — оценить тесноту связи (это термин) между переменными, чтобы понять, какие переменные учитывать в модели, а какие нет.
И ещё раз, потому что действительно важно: корреляция ни в коем случае не означает причинно-следственную связь. Если два показателя скоррелированы, то далеко не факт, что они хоть как-то связаны.
Кстати, проект Spurious Correlations («Ложные корреляции») публикует графики корреляций между совершенно неожиданными статистическими показателями — например, количеством людей, утонувших в домашних бассейнах, и числом фильмов с участием Николаса Кейджа.
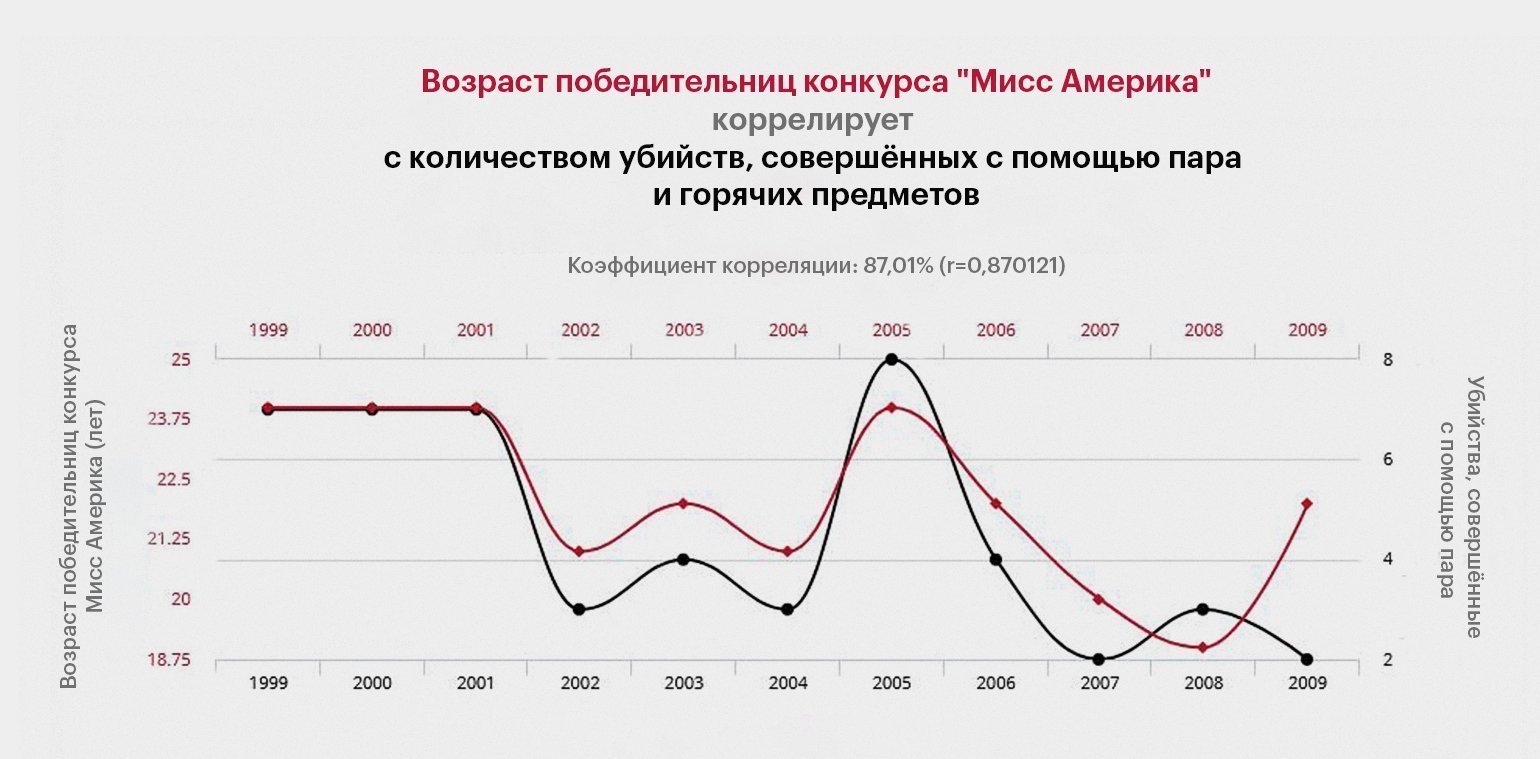
Имеет смысл время от времени заходить по этой ссылке с целью профилактики СПГС — синдрома поиска глубинной связи.
Заключение
Data Science — не просто комбинирование модных моделей в Jupyter-ноутбуке. Профессионалы в этой области глубоко понимают природу данных и то, как они могут помочь в принятии конкретных бизнес-решений.
Всё это изучалось в статистике задолго до того, как первый дата-сайентист набрал свой первый import pandas as pd. Статистика — фундамент всей современной науки о данных, включая машинное обучение, глубокие нейросети и даже искусственный интеллект.
В нашем курсе «Профессия Data Scientist» статистике уделено самое пристальное внимание. Вы не ударите в грязь лицом ни на тусовке статистиков, ни на настоящем DS-собеседовании. Приходите!



