Организация и модели памяти, адресация
Память – способность объекта обеспечивать хранение данных.
Все объекты, над которыми выполняются команды, как и сами команды, хранятся в памяти компьютера.
Способы адресации байтов
Существует прямой и обратный способы адресации байтов.
При обратном способе адресации байты адресуются слева направо, так что самый старший (левый) байт слова имеет наименьший адрес. 
Прямым способом называется противоположная система адресации. Компиляторы высокоуровневых языков поддерживают прямой способ адресации. 
Объект занимает целое слово. Поэтому для того, чтобы обратиться к нему в памяти, нужно указать адрес, по которому этот объект хранится.
Организация памяти
Физическая память, к которой микропроцессор имеет доступ по шине адреса, называется оперативной памятью ОП (или оперативным запоминающим устройством — ОЗУ).
Механизм управления памятью полностью аппаратный, т.е. программа сама не может сформировать физический адрес памяти на адресной шине.
Микропроцессор аппаратно поддерживает несколько моделей использования оперативной памяти:
Сегментация — механизм адресации, обеспечивающий существование нескольких независимых адресных пространств как в пределах одной задачи, так и в системе в целом для защиты задач от взаимного влияния.
Каждая программа в общем случае может состоять из любого количества сегментов, но непосредственный доступ она имеет только к 3 основным сегментам и к 3 дополнительным сегментам, обслуживаемых 6 сегментными регистрами. К основным сегментам относятся:
Регистры дополнительных сегментов ( ES, FS, GS ), предназначены для специального использования.
Для доступа к данным внутри сегмента обращение производится относительно начала сегмента линейно, т.е. начиная с 0 и заканчивая адресом, равным размеру сегмента. Для обращения к любому адресу в программе, компьютер складывает адрес в регистре сегмента и смещение — расположение требуемого адреса относительно начала сегмента. Например, первый байт в сегменте кодов имеет смещение 0, второй байт – 1 и так далее.
Таким образом, для обращения к конкретному физическому адресу ОЗУ необходимо определить адрес начала сегмента и смещение внутри сегмента.
Физический адрес принято записывать парой этих значений, разделенных двоеточием
сегмент : смещение
Плоская модель памяти предполагает, что задача состоит из одного сегмента, который, в свою очередь, разбит на страницы.
Достоинства:
В абсолютном большинстве современных 32(64)-разрядных операционных систем (для микропроцессоров Intel) используется плоская модель памяти.
Модели памяти
.MODEL модификатор МодельПамяти СоглашениеОВызовах
Параметр МодельПамяти является обязательным.
Основные модели памяти:
| Модель памяти | Адресация кода | Адресация данных | Операци- онная система | Чередование кода и данных |
| TINY | NEAR | NEAR | MS-DOS | Допустимо |
| SMALL | NEAR | NEAR | MS-DOS, Windows | Нет |
| MEDIUM | FAR | NEAR | MS-DOS, Windows | Нет |
| COMPACT | NEAR | FAR | MS-DOS, Windows | Нет |
| LARGE | FAR | FAR | MS-DOS, Windows | Нет |
| HUGE | FAR | FAR | MS-DOS, Windows | Нет |
| FLAT | NEAR | NEAR | Windows NT, Windows 2000, Windows XP, Windows Vista | Допустимо |
Модель tiny работает только в 16-разрядных приложениях MS-DOS. В этой модели все данные и код располагаются в одном физическом сегменте. Размер программного файла в этом случае не превышает 64 Кбайт.
Модель small поддерживает один сегмент кода и один сегмент данных. Данные и код при использовании этой модели адресуются как near (ближние).
Модель medium поддерживает несколько сегментов программного кода и один сегмент данных, при этом все ссылки в сегментах программного кода по умолчанию считаются дальними (far), а ссылки в сегменте данных — ближними (near).
Модель compact поддерживает несколько сегментов данных, в которых используется дальняя адресация данных (far), и один сегмент кода с ближней адресацией (near).
Модель large поддерживает несколько сегментов кода и несколько сегментов данных. По умолчанию все ссылки на код и данные считаются дальними (far).
Модель huge практически эквивалентна модели памяти large.
Желательно указывать тот тип процессора, который используется в машине, хотя это не является обязательным требованием. Операционная система автоматически инициализирует сегментные регистры при загрузке программы, поэтому модифицировать их нужно только в случае если требуется смешивать в одной программе 16-разрядный и 32-разрядный код. Адресация данных и кода является ближней ( near ), при этом все адреса и указатели являются 32-разрядными.
Параметр модификатор используется для определения типов сегментов и может принимать значения use16 (сегменты выбранной модели используются как 16-битные) или use32 (сегменты выбранной модели используются как 32-битные).
Параметр СоглашениеОВызовах используется для определения способа передачи параметров при вызове процедуры из других языков, в том числе и языков высокого уровня (C++, Pascal). Параметр может принимать следующие значения:
При разработке модулей на ассемблере, которые будут применяться в программах, написанных на языках высокого уровня, обращайте внимание на то, какие соглашения о вызовах поддерживает тот или иной язык. Используются при анализе интерфейса программ на ассемблере с программами на языках высокого уровня.
Адреса памяти: физические, виртуальные, логические, линейные, эффективные, гостевые
Мне периодически приходится объяснять разным людям некоторые аспекты архитектуры Intel® IA-32, в том числе замысловатость системы адресации данных в памяти, которая, похоже, реализовала почти все когда-то придуманные идеи. Я решил оформить развёрнутый ответ в этой статье. Надеюсь, что он будет полезен ещё кому-нибудь.
При исполнении машинных инструкций считываются и записываются данные, которые могут находиться в нескольких местах: в регистрах самого процессора, в виде констант, закодированных в инструкции, а также в оперативной памяти. Если данные находятся в памяти, то их положение определяется некоторым числом — адресом. По ряду причин, которые, я надеюсь, станут понятными в процессе чтения этой статьи, исходный адрес, закодированный в инструкции, проходит через несколько преобразований.

На рисунке — сегментация и страничное преобразование адреса, как они выглядели 27 лет назад. Иллюстрация из Intel 80386 Programmers’s Reference Manual 1986 года. Забавно, что в описании рисунка есть аж две опечатки: «80306 Addressing Machanism». В наше время адрес подвергается более сложным преобразованиям, а иллюстрации больше не делают в псевдографике.
Начнём немного с конца — с цели всей цепочки преобразований.
Физический адрес
Эффективный адрес
Эффективный адрес — это начало пути. Он задаётся в аргументах индивидуальной машинной инструкции, и вычисляется из значений регистров, смещений и масштабирующих коэффициентов, заданных в ней явно или неявно.
Например, для инструкции (ассемблер в AT&T-нотации)
addl %eax, 0x11(%ebp, %edx, 8)
эффективный адрес операнда-назначения будет вычислен по формуле:
eff_addr = EBP + EDX * 8 + 0x11
Логический адрес
Здесь обычно у тех, кто столкнулся с этими понятиями впервые, голова начинает идти кругом. Несколько упростить (или усложнить) ситуацию помогает тот факт, что почти всегда выбор селектора (и связанного с ним сегмента) делается исходя из «смысла» доступа. По умолчанию, если в кодировке машинной инструкции не сказано иного, для получения адресов кода используются логические адреса с селектором CS, для данных — с DS, для стека — с SS.
Линейный адрес
Эффективный адрес — это смещение от начала сегмента — его базы. Если сложить базу и эффективный адрес, то получим число, называемое линейным адресом:
lin_addr = segment.base + eff_addr
Преобразование логический → линейный не всегда может быть успешным, так как при его исполнении проверяется несколько условий на свойства сегмента, записанных в полях его дескриптора. Например, проверяется выход за границы сегмента и права доступа.
Сегментация была модной на некотором этапе развития вычислительной техники. В настоящее она почти всюду была заменена другими механизмами, и используется только для специфических задач. Так, в режиме IA-32e (64-битном) только два сегмента могут иметь ненулевую базу. Для остальных четырёх в этом режиме всегда линейный адрес == эффективный.
Что такое виртуальный адрес?
В литературе и в документации других архитектур встречается ещё один термин — виртуальный адрес. Он не используется в документации Intel на IA-32, однако встречается, например, в описании Intel® Itanium, в котором сегментация не используется. Можно смело считать, что для IA-32 виртуальный == линейный.
В советской литературе по вычислительной технике этот вид адресов также именовался математическим.
Страничное преобразование
Однако общая идея всегда одна и та же: линейный адрес разбивается на несколько частей, каждая из которых служит индексом в одной из системных таблиц, хранящихся в памяти. Записи в таблицах — это адреса начала таблицы следующего уровня или, для последнего уровня — искомая информация о физическом адресе страницы в памяти и её свойствах. Самые младшие биты не преобразуются, а используются для адресации внутри найденной страницы. Например, для режима PAE с размером страниц 4 кбайт преобразование выглядит так:
В разных режимах процессора различается число и ёмкость этих таблиц. Преобразование может завершиться неудачей, если очередная таблица не содержит валидных данных, или права доступа, хранящиеся в последней из них, запрещают доступ к странице; например, при записи в регионы, помеченные как «только для чтения», или попытке чтения памяти ядра из непривилегированного процесса.
Гостевой физический
До введения возможностей аппаратной виртуализации в процессорах Intel страничное преобразование было последним в цепочке. Когда же на одной системе работают несколько виртуальных машин, то физические адреса, получаемые в каждой из них, приходится транслировать ещё один раз. Это можно делать программным образом, или же аппаратно, если процессор поддерживает функциональность EPT (англ. Extended Page Table). Адрес, раньше называвшийся физическим, был переименован в гостевой физический для того, чтобы отличать его от настоящего физического. Они связаны с помощью EPT-преобразования. Алгоритм последнего схож с ранее описанным страничным преобразованием: набор связанных таблиц с общим корнем, последний уровень которых определяет, существует ли физическая страница для указанной гостевой физической.
Полная картина
Я попытался собрать все преобразования адреса в одну иллюстрацию. В ней преобразования обозначены стрелками, типы адресов обведены в рамки.
Как уже было сказано выше, каждое из преобразований может вернуть ошибку для адресов, не имеющих представления в следующем по цепочке виде. Устранение подобных проблем — это задача операционных систем и мониторов виртуальных машин, реализующих абстракцию виртуальной памяти.
Заключение
Организация памяти
За последнюю неделю дважды объяснял людям как организована работа с памятью в х86, с целью чтобы не объяснять в третий раз написал эту статью.
И так, чтобы понять организацию памяти от вас потребуется знания некоторых базовых понятий, таких как регистры, стек и тд. Я по ходу попробую объяснить и это на пальцах, но очень кратко потому что это не тема для этой статьи. Итак начнем.
Как известно программист, когда пишет программы работает не с физическим адресом, а только с логическим. И то если он программирует на ассемблере. В том же Си ячейки памяти от программиста уже скрыты указателями, для его же удобства, но если грубо говорить указатель это другое представление логического адреса памяти, а в Java и указателей нет, совсем плохой язык. Однако грамотному программисту не помешают знания о том как организована память хотя бы на общем уровне. Меня вообще очень огорчают программисты, которые не знают как работает машина, обычно это программисты Java и прочие php-парни, с квалификацией ниже плинтуса.
Так ладно, хватит о печальном, переходим к делу.
Рассмотрим адресное пространство программного режима 32 битного процессора (для 64 бит все по аналогии)
Адресное пространство этого режима будет состоять из 2^32 ячеек памяти пронумерованных от 0 и до 2^32-1.
Программист работает с этой памятью, если ему нужно определить переменную, он просто говорит ячейка памяти с адресом таким-то будет содержать такой-то тип данных, при этом сам програмист может и не знать какой номер у этой ячейки он просто напишет что-то вроде:
int data = 10;
компьютер поймет это так: нужно взять какую-то ячейку с номером стопицот и поместить в нее цело число 10. При том про адрес ячейки 18894 вы и не узнаете, он от вас будет скрыт.
Все бы хорошо, но возникает вопрос, а как компьютер ищет эту ячейку памяти, ведь память у нас может быть разная:
3 уровень кэша
2 уровень кэша
1 уровень кэша
основная память
жесткий диск
Это все разные памяти, но компьютер легко находит в какой из них лежит наша переменная int data.
Этот вопрос решается операционной системой совместно с процессором.
Вся дальнейшая статья будет посвящена разбору этого метода.
Архитектура х86 поддерживает стек.
Стек это непрерывная область оперативной памяти организованная по принципу стопки тарелок, вы не можете брать тарелки из середины стопки, можете только брать верхнюю и класть тарелку вы тоже можете только на верх стопки.
В процессоре для работы со стеком организованны специальные машинные коды, ассемблерные мнемоники которых выглядят так:
push operand
помещает операнд в стек
pop operand
изымает из вершины стека значение и помещает его в свой операнд
Стек в памяти растет сверху вниз, это значит что при добавлении значения в него адрес вершины стека уменьшается, а когда вы извлекаете из него, то адрес вершины стека увеличивается.
Теперь кратко рассмотрим что такое регистры.
Это ячейки памяти в самом процессоре. Это самый быстрый и самый дорогой тип памяти, когда процессор совершает какие-то операции со значением или с памятью, он берет эти значения непосредственно из регистров.
В процессоре есть несколько наборов логик, каждая из которых имеет свои машинные коды и свои наборы регистров.
Basic program registers (Основные программные регистры) Эти регистры используются всеми программами с их помощью выполняется обработка целочисленных данных.
Floating Point Unit registers (FPU) Эти регистры работают с данными представленными в формате с плавающей точкой.
Еще есть MMX и XMM registers эти регистры используются тогда, когда вам надо выполнить одну инструкцию над большим количеством операндов.
Рассмотрим подробнее основные программные регистры. К ним относятся восемь 32 битных регистров общего назначения: EAX, EBX, ECX, EDX, EBP, ESI, EDI, ESP
Для того чтобы поместить в регистр данные, или для того чтобы изъять из регистра в ячейку памяти данные используется команда mov:
mov eax, 10
загружает число 10 в регистр eax.
mov data, ebx
копирует число, содержащееся в регистре ebx в ячейку памяти data.
Регистр ESP содержит адрес вершины стека.
Кроме регистров общего назначения, к основным программным регистрам относят шесть 16битных сегментных регистров: CS, DS, SS, ES, FS, GS, EFLAGS, EIP
EFLAGS показывает биты, так называемые флаги, которые отражают состояние процессора или характеризуют ход выполнения предыдущих команд.
В регистре EIP содержится адрес следующей команды, которая будет выполнятся процессором.
Я не буду расписывать регистры FPU, так как они нам не понадобятся. Итак наше небольшое отступление про регистры и стек закончилось переходим обратно к организации памяти.
Как вы помните целью статьи является рассказ про преобразование логической памяти в физическую, на самом деле есть еще промежуточный этап и полная цепочка выглядит так:
линейный адрес=Базовый адрес сегмента(на картинке это начало сегмента) + смещение
Сегмент кода
Сегмент данных
Сегмент стека
Используемый сегмент стека задается значением регистра SS.
Смещение внутри этого сегмента представлено регистром ESP, который указывает на вершину стека, как вы помните.
Сегменты в памяти могут друг друга перекрывать, мало того базовый адрес всех сегментов может совпадать например в нуле. Такой вырожденный случай называется линейным представлением памяти. В современных системах, память как правило так организована.
Теперь рассмотрим определение базовых адресов сегмента, я писал что они содержаться в регистрах SS, DS, CS, но это не совсем так, в них содержится некий 16 битный селектор, который указывает на некий дескриптор сегментов, в котором уже хранится необходимый адрес. 
Так выглядит селектор, в тринадцати его битах содержится индекс дескриптора в таблице дескрипторов. Не хитро посчитать будет что 2^13 = 8192 это максимальное количество дескрипторов в таблице.
Вообще дескрипторных таблиц бывает два вида GDT и LDT Первая называется глобальная таблица дескрипторов, она в системе всегда только одна, ее начальный адрес, точнее адрес ее нулевого дескриптора хранится в 48 битном системном регистре GDTR. И с момента старта системы не меняется и в свопе не принимает участия.
А вот значения дескрипторов могут меняться. Если в селекторе бит TI равен нулю, тогда процессор просто идет в GDT ищет по индексу нужный дескриптор с помощью которого осуществляет доступ к этому сегменту.
Пока все просто было, но если TI равен 1 тогда это означает что использоваться будет LDT. Таблиц этих много, но использоваться в данный момент будет та селектор которой загружен в системный регистр LDTR, который в отличии от GDTR может меняться.
Индекс селектора указывает на дескриптор, который указывает уже не на базовый адрес сегмента, а на память в котором хранится локальная таблица дескрипторов, точнее ее нулевой элемент. Ну а дальше все так же как и с GDT. Таким образом во время работы локальные таблицы могут создаваться и уничтожаться по мере необходимости. LDT не могут содержать дескрипторы на другие LDT.
Итак мы знаем как процессор добирается до дескриптора, а что содержится в этом дескрипторе посмотрим на картинке: 
Дескрипторы состоит из 8 байт.
Биты с 15-39 и 56-63 содержат линейный базовый адрес описываемым данным дескриптором сегмента. Напомню нашу формулу для нахождения линейного адреса:
линейный адрес = базовый адрес + смещение
[база; база+предел)
(база+предел; вершина]
Кстати интересно почему база и предел так рвано располагаются в дескрипторе. Дело в том что процессоры х86 развивались эволюционно и во времена 286х дескрипторы были по 8 бит всего, при этом старшие 2 байта были зарезервированы, ну а в последующих моделях процессоров с увеличением разрядности дескрипторы тоже выросли, но для сохранения обратной совместимости пришлось оставить структуру как есть.
Значение адреса «вершина» зависит от 54го D бита, если он равен 0, тогда вершина равна 0xFFF(64кб-1), если D бит равен 1, тогда вершина равна 0xFFFFFFFF (4Гб-1)
С 41-43 бит кодируется тип сегмента.
000 — сегмент данных, только считывание
001 — сегмент данных, считывание и запись
010 — сегмент стека, только считывание
011 — сегмент стека, считывание и запись
100 — сегмент кода, только выполнение
101- сегмент кода, считывание и выполнение
110 — подчиненный сегмент кода, только выполнение
111 — подчиненный сегмент кода, только выполнение и считывание
44 S бит если равен 1 тогда дескриптор описывает реальный сегмент оперативной памяти, иначе значение S бита равно 0.
Самым важным битом является 47-й P бит присутствия. Если бит равен 1 значит, что сегмент или локальная таблица дескрипторов загружена в оперативку, если этот бит равен 0, тогда это означает что данного сегмента в оперативке нет, он находится на жестком диске, случается прерывание, особый случай работы процессора запускается обработчик особого случая, который загружает нужный сегмент с жесткого диска в память, если P бит равен 0, тогда все поля дескриптора теряют смысл, и становятся свободными для сохранения в них служебной информации. После завершения работы обработчика, P бит устанавливается в значение 1, и производится повторное обращение к дескриптору, сегмент которого находится уже в памяти.
На этом заканчивается преобразование логического адреса в линейный, и я думаю на этом стоит прерваться. В следующий раз я расскажу вторую часть преобразования из линейного в физический.
А так же думаю стоит немного поговорить о передачи аргументов функции, и о размещении переменных в памяти, чтобы была какая-то связь с реальностью, потому размещение переменных в памяти это уже непосредственно, то с чем вам приходится сталкиваться в работе, а не просто какие-то теоретические измышления для системного программиста. Но без понимания, как устроена память невозможно понять как эти самые переменные хранятся в памяти.
В общем надеюсь было интересно и до новых встреч.
Анатомия RAM

У каждого компьютера есть ОЗУ, встроенное в процессор или находящееся на отдельной подключенной к системе плате — вычислительные устройства просто не смогли бы работать без оперативной памяти. ОЗУ — потрясающий образец прецизионного проектирования, однако несмотря на тонкость процессов изготовления, память ежегодно производится в огромных объёмах. В ней миллиарды транзисторов, но она потребляет только считанные ватты мощности. Учитывая большую важность памяти, стоит написать толковый анализ её анатомии.
Итак, давайте приготовимся к вскрытию, выкатим носилки и отправимся в анатомический театр. Настало время изучить все подробности каждой ячейки, из которых состоит современная память, и узнать, как она работает.
Зачем же ты, RAM-ео?
Процессорам требуется очень быстро получать доступ к данным и командам, чтобы программы выполнялись мгновенно. Кроме того, им нужно, чтобы при произвольных или неожиданных запросах не очень страдала скорость. Именно поэтому для компьютера так важно ОЗУ (RAM, сокращение от random-access memory — память с произвольным доступом).
Существует два основных типа RAM: статическая и динамическая, или сокращённо SRAM и DRAM.
Мы будем рассматривать только DRAM, потому что SRAM используется только внутри процессоров, таких как CPU или GPU. Так где же находится DRAM в наших компьютерах и как она работает?
Большинству людей знакома RAM, потому что несколько её планок находится рядом с CPU (центральным процессором, ЦП). Эту группу DRAM часто называют системной памятью, но лучше её называть памятью CPU, потому что она является основным накопителем рабочих данных и команд процессора.

Как видно на представленном изображении, DRAM находится на небольших платах, вставляемых в материнскую (системную) плату. Каждую плату обычно называют DIMM или UDIMM, что расшифровывается как dual inline memory module (двухсторонний модуль памяти) (U обозначает unbuffered (без буферизации)). Подробнее мы объясним это позже; пока только скажем, что это самая известная RAM любого компьютера.
Она не обязательно должна быть сверхбыстрой, но современным ПК для работы с большими приложениями и для обработки сотен процессов, выполняемых в фоновом режиме, требуется много памяти.
Ещё одним местом, где можно найти набор чипов памяти, обычно является графическая карта. Ей требуется сверхбыстрая DRAM, потому что при 3D-рендеринге выполняется огромное количество операций чтения и записи данных. Этот тип DRAM предназначен для несколько иного использования по сравнению с типом, применяемым в системной памяти.
Ниже вы видите GPU, окружённый двенадцатью небольшими пластинами — это чипы DRAM. Конкретно этот тип памяти называется GDDR5X, о нём мы поговорим позже.

Графическим картам не нужно столько же памяти, как CPU, но их объём всё равно достигает тысяч мегабайт.
Не каждому устройству в компьютере нужно так много: например, жёстким дискам достаточно небольшого количества RAM, в среднем по 256 МБ; они используются для группировки данных перед записью на диск.

На этих фотографиях мы видим платы HDD (слева) и SSD (справа), на которых отмечены чипы DRAM. Заметили, что чип всего один? 256 МБ сегодня не такой уж большой объём, поэтому вполне достаточно одного куска кремния.
Узнав, что каждый компонент или периферийное устройство, выполняющее обработку, требует RAM, вы сможете найти память во внутренностях любого ПК. На контроллерах SATA и PCI Express установлены небольшие чипы DRAM; у сетевых интерфейсов и звуковых карт они тоже есть, как и у принтеров со сканнерами.
Если память можно встретить везде, она может показаться немного скучной, но стоит вам погрузиться в её внутреннюю работу, то вся скука исчезнет!
Скальпель. Зажим. Электронный микроскоп.
У нас нет всевозможных инструментов, которые инженеры-электронщики используют для изучения своих полупроводниковых творений, поэтому мы не можем просто разобрать чип DRAM и продемонстрировать вам его внутренности. Однако такое оборудование есть у ребят из TechInsights, которые сделали этот снимок поверхности чипа:
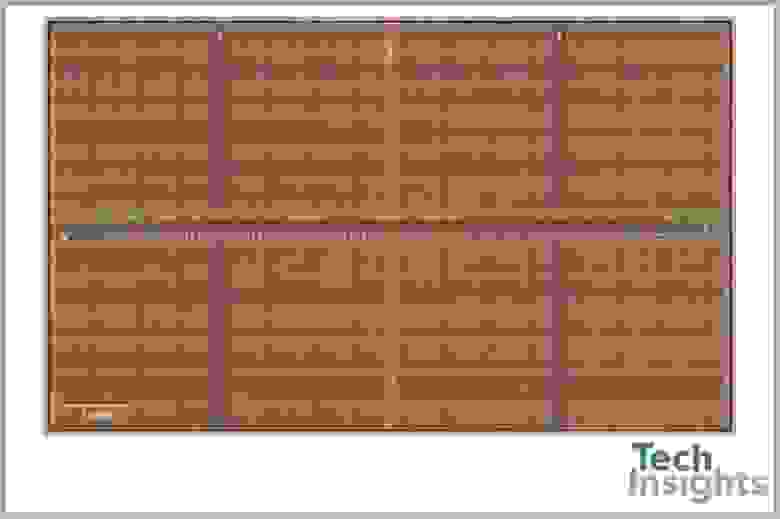
Если вы подумали, что это похоже на сельскохозяйственные поля, соединённые тропинками, то вы не так далеки от истины! Только вместо кукурузы или пшеницы поля DRAM в основном состоят из двух электронных компонентов:
Синими и зелёными линиями обозначены соединения, подающие напряжение на МОП-транзистор и конденсатор. Они используются для считывания и записи данных в ячейку, и первой всегда срабатывает вертикальная (разрядная) линия.
Канавочный конденсатор, по сути, используется в качестве сосуда для заполнения электрическим зарядом — его пустое/заполненное состояние даёт нам 1 бит данных: 0 — пустой, 1 — полный. Несмотря на предпринимаемые инженерами усилия, конденсаторы не способны хранить этот заряд вечно и со временем он утекает.
Это означает, что каждую ячейку памяти нужно постоянно обновлять по 15-30 раз в секунду, хотя сам этот процесс довольно быстр: для обновления набора ячеек требуется всего несколько наносекунд. К сожалению, в чипе DRAM множество ячеек, и во время их обновления считывание и запись в них невозможна.
К каждой линии подключено несколько ячеек:
Строго говоря, эта схема неидеальна, потому что для каждого столбца ячеек используется две разрядные линии — если бы мы изобразили всё, то схема бы стала слишком неразборчивой.
Полная строка ячеек памяти называется страницей, а длина её зависит от типа и конфигурации DRAM. Чем длиннее страница, тем больше в ней бит, но и тем большая электрическая мощность нужна для её работы; короткие страницы потребляют меньше мощности, но и содержат меньший объём данных.
Однако нужно учитывать и ещё один важный фактор. При считывании и записи на чип DRAM первым этапом процесса является активация всей страницы. Строка битов (состоящая из нулей и единиц) хранится в буфере строки, который по сути является набором усилителей считывания и защёлок, а не дополнительной памятью. Затем активируется соответствующий столбец для извлечения данных из этого буфера.
Если страница слишком мала, то чтобы успеть за запросами данных, строки нужно активировать чаще; и наоборот — большая страница предоставляет больше данных, поэтому активировать её можно реже. И даже несмотря на то, что длинная строка требует большей мощности и потенциально может быть менее стабильной, лучше стремиться к получению максимально длинных страниц.
Если собрать вместе набор страниц, то мы получим один банк памяти DRAM. Как и в случае страниц, размер и расположение строк и столбцов ячеек играют важную роль в количестве хранимых данных, скорости работы памяти, энергопотреблении и так далее.
Например, схема может состоять из 4 096 строк и 4 096 столбцов, при этом полный объём одного банка будет равен 16 777 216 битам или 2 мегабайтам. Но не у всех чипов DRAM банки имеют квадратную структуру, потому что длинные страницы лучше, чем короткие. Например, схема из 16 384 строк и 1 024 столбцов даст нам те же 2 мегабайта памяти, но каждая страница будет содержать в четыре раза больше памяти, чем в квадратной схеме.
Все страницы в банке соединены с системой адресации строк (то же относится и к столбцам) и они контролируются сигналами управления и адресами для каждой строки/столбца. Чем больше строк и столбцов в банке, тем больше битов должно использоваться в адресе.
Для банка размером 4 096 x 4 096 для каждой системы адресации требуется 12 бит, а для банка 16 384 x 1 024 потребуется 14 бит на адреса строк и 10 бит на адреса столбцов. Стоит заметить, что обе системы имеют суммарный размер 24 бита.
Если бы чип DRAM мог предоставлять доступ к одной странице за раз, то это было бы не особо удобно, поэтому в них упаковано несколько банков ячеек памяти. В зависимости от общего размера, чип может иметь 4, 8 или даже 16 банков — чаще всего используется 8 банков.
Все эти банки имеют общие шины команд, адресов и данных, что упрощает структуру системы памяти. Пока один банк занят работой с одной командой, другие банки могут продолжать выполнение своих операций.
Весь чип, содержащий все банки и шины, упакован в защитную оболочку и припаян к плате. Она содержит электропроводники, подающие питание для работы DRAM и сигналов команд, адресов и данных.

На фотографии выше показан чип DRAM (иногда называемый модулем), изготовленный компанией Samsung. Другими ведущими производителями являются Toshiba, Micron, SK Hynix и Nanya. Samsung — крупнейший производитель, он имеет приблизительно 40% мирового рынка памяти.
Каждый изготовитель DRAM использует собственную систему кодирования характеристик памяти; на фотографии показан чип на 1 гигабит, содержащий 8 банков по 128 мегабита, выстроенных в 16 384 строки и 8 192 столбца.
Выше по рангу
Компании-изготовители памяти берут несколько чипов DRAM и устанавливают их на одну плату, называемую DIMM. Хотя D расшифровывается как dual (двойная), это не значит, что на ней два набора чипов. Под двойным подразумевается количество электрических контактов в нижней части платы; то есть для работы с модулями используются обе стороны платы.
Сами DIMM имеют разный размер и количество чипов:

На фотографии сверху показана стандартная DIMM для настольного ПК, а под ней находится так называемая SO-DIMM (small outline, «DIMM малого профиля»). Маленький модуль предназначен для ПК малого форм-фактора, например, ноутбуков и компактных настольных компьютеров. Из-за малого пространства уменьшается количество используемых чипов, изменяется скорость работы памяти, и так далее.
Существует три основных причины для использования нескольких чипов памяти на DIMM:
То есть каждому DIMM, который устанавливается в компьютер с Ryzen, потребуется восемь модулей DRAM (8 чипов x 8 бит = 64 бита). Можно подумать, что графическая карта 5700 XT будет иметь 32 чипа памяти, но у неё их только 8. Что же это нам даёт?
В чипы памяти, предназначенные для графических карт, устанавливают больше банков, обычно 16 или 32, потому что для 3D-рендеринга необходим одновременный доступ к большому объёму данных.
Один ранг и два ранга
Множество модулей памяти, «заполняющих» шину данных контроллера памяти, называется рангом, и хотя к контроллеру можно подключить больше одного ранга, за раз он может получать данные только от одного ранга (потому что ранги используют одну шину данных). Это не вызывает проблем, потому что пока один ранг занимается ответом на переданную ему команду, другому рангу можно передать новый набор команд.
Платы DIMM могут иметь несколько рангов и это особенно полезно, когда вам нужно огромное количество памяти, но на материнской плате мало разъёмов под RAM.
Так называемые схемы с двумя (dual) или четырьмя (quad) рангами потенциально могут обеспечить большую производительность, чем одноранговые, но увеличение количества рангов быстро повышает нагрузку на электрическую систему. Большинство настольных ПК способно справиться только с одним-двумя рангами на один контроллер. Если системе нужно больше рангов, то лучше использовать DIMM с буферизацией: такие платы имеют дополнительный чип, облегчающий нагрузку на систему благодаря хранению команд и данных в течение нескольких циклов, прежде чем передать их дальше.

Множество модулей памяти Nanya и один буферный чип — классическая серверная RAM
Но не все ранги имеют размер 64 бита — используемые в серверах и рабочих станциях DIMM часто размером 72 бита, то есть на них есть дополнительный модуль DRAM. Этот дополнительный чип не обеспечивает повышение объёма или производительности; он используется для проверки и устранения ошибок (error checking and correcting, ECC).
Вы ведь помните, что всем процессорам для работы нужна память? В случае ECC RAM небольшому устройству, выполняющему работу, предоставлен собственный модуль.
Шина данных в такой памяти всё равно имеют ширину всего 64 бита, но надёжность хранения данных значительно повышается. Использование буферов и ECC только незначительно влияет на общую производительность, зато сильно повышает стоимость.
Жажда скорости
У всех DRAM есть центральный тактовый сигнал ввода-вывода (I/O, input/output) — напряжение, постоянно переключающееся между двумя уровнями; он используется для упорядочивания всего, что выполняется в чипе и шинах памяти.
Если бы мы вернулись назад в 1993 год, то смогли бы приобрести память типа SDRAM (synchronous, синхронная DRAM), которая упорядочивала все процессы с помощью периода переключения тактового сигнала из низкого в высокое состояние. Так как это происходит очень быстро, такая система обеспечивает очень точный способ определения времени выполнения событий. В те времена SDRAM имела тактовые сигналы ввода-вывода, обычно работавшие с частотой от 66 до 133 МГц, и за каждый такт сигнала в DRAM можно было передать одну команду. В свою очередь, чип за тот же промежуток времени мог передать 8 бит данных.
Быстрое развитие SDRAM, ведущей силой которого был Samsung, привело к созданию в 1998 году её нового типа. В нём передача данных синхронизировалась по повышению и падению напряжения тактового сигнала, то есть за каждый такт данные можно было дважды передать в DRAM и обратно.
Как же называлась эта восхитительная новая технология? Double data rate synchronous dynamic random access memory (синхронная динамическая память с произвольным доступом и удвоенной скоростью передачи данных). Обычно её просто называют DDR-SDRAM или для краткости DDR.
Память DDR быстро стала стандартом (из-за чего первоначальную версию SDRAM переименовали в single data rate SDRAM, SDR-DRAM) и в течение последующих 20 лет оставалась неотъемлемой частью всех компьютерных систем.
Прогресс технологий позволил усовершенствовать эту память, благодаря чему в 2003 году появилась DDR2, в 2007 году — DDR3, а в 2012 году — DDR4. Каждая новая версия обеспечивала повышение производительности благодаря ускорению тактового сигнала ввода-вывода, улучшению систем сигналов и снижению энергопотребления.
DDR2 внесла изменение, которое мы используем и сегодня: генератор тактовых сигналов ввода-вывода превратился в отдельную систему, время работы которой задавалось отдельным набором синхронизирующих сигналов, благодаря чему она стала в два раза быстрее. Это аналогично тому, как CPU используют для упорядочивания работы тактовый сигнал 100 МГц, хотя внутренние синхронизирующие сигналы работают в 30-40 раз быстрее.
DDR3 и DDR4 сделали шаг вперёд, увеличив скорость тактовых сигналов ввода-вывода в четыре раза, но во всех этих типах памяти шина данных для передачи/получения информации по-прежнему использовала только повышение и падение уровня сигнала ввода-вывода (т.е. удвоенную частоту передачи данных).
Сами чипы памяти не работают на огромных скоростях — на самом деле, они шевелятся довольно медленно. Частота передачи данных (измеряемая в миллионах передач в секунду — millions of transfers per second, MT/s) в современных DRAM настолько высока благодаря использованию в каждом чипе нескольких банков; если бы на каждый модуль приходился только один банк, всё работало бы чрезвычайно медленно.
| Тип DRAM | Обычная частота чипа | Тактовый сигнал ввода-вывода | Частота передачи данных |
| SDR | 100 МГц | 100 МГц | 100 MT/s |
| DDR | 100 МГц | 100 МГц | 200 MT/s |
| DDR2 | 200 МГц | 400 МГц | 800 MT/s |
| DDR3 | 200 МГц | 800 МГц | 1600 MT/s |
| DDR4 | 400 МГц | 1600 МГц | 3200 MT/s |
Каждая новая версия DRAM не обладает обратной совместимостью, то есть используемые для каждого типа DIMM имеют разные количества электрических контактов, разъёмы и вырезы, чтобы пользователь не мог вставить память DDR4 в разъём DDR-SDRAM.

Сверху вниз: DDR-SDRAM, DDR2, DDR3, DDR4
DRAM для графических плат изначально называлась SGRAM (synchronous graphics, синхронная графическая RAM). Этот тип RAM тоже подвергался усовершенствованиям, и сегодня его для понятности называют GDDR. Сейчас мы достигли версии 6, а для передачи данных используется система с учетверённой частотой, т.е. за тактовый цикл происходит 4 передачи.
| Тип DRAM | Обычная частота памяти | Тактовый сигнал ввода-вывода | Частота передачи данных |
| GDDR | 250 МГц | 250 МГц | 500 MT/s |
| GDDR2 | 500 МГц | 500 МГц | 1000 MT/s |
| GDDR3 | 800 МГц | 1600 МГц | 3200 MT/s |
| GDDR4 | 1000 МГц | 2000 МГц | 4000 MT/s |
| GDDR5 | 1500 МГц | 3000 МГц | 6000 MT/s |
| GDDR5X | 1250 МГц | 2500 МГц | 10000 MT/s |
| GDDR6 | 1750 МГц | 3500 МГц | 14000 MT/s |
Кроме более высокой частоты передачи, графическая DRAM обеспечивает дополнительные функции для ускорения передачи, например, возможность одновременного открытия двух страниц одного банка, работающие в DDR шины команд и адресов, а также чипы памяти с гораздо большими скоростями тактовых сигналов.
Какой же минус у всех этих продвинутых технологий? Стоимость и тепловыделение.
Один модуль GDDR6 примерно вдвое дороже аналогичного чипа DDR4, к тому же при полной скорости он становится довольно горячим — именно поэтому графическим картам с большим количеством сверхбыстрой RAM требуется активное охлаждение для защиты от перегрева чипов.
Скорость битов
Производительность DRAM обычно измеряется в количестве битов данных, передаваемых за секунду. Ранее в этой статье мы говорили, что используемая в качестве системной памяти DDR4 имеет чипы с 8-битной шириной шины, то есть каждый модуль может передавать до 8 бит за тактовый цикл.
То есть если частота передачи данных равна 3200 MT/s, то пиковый результат равен 3200 x 8 = 25 600 Мбит в секунду или чуть больше 3 ГБ/с. Так как большинство DIMM имеет 8 чипов, потенциально можно получить 25 ГБ/с. Для GDDR6 с 8 модулями этот результат был бы равен 440 ГБ/с!
Обычно это значение называют полосой пропускания (bandwidth) памяти; оно является важным фактором, влияющим на производительность RAM. Однако это теоретическая величина, потому что все операции внутри чипа DRAM не происходят одновременно.
Чтобы разобраться в этом, давайте взглянем на показанное ниже изображение. Это очень упрощённое (и нереалистичное) представление того, что происходит, когда данные запрашиваются из памяти.
На первом этапе активируется страница DRAM, в которой содержатся требуемые данные. Для этого памяти сначала сообщается, какой требуется ранг, затем соответствующий модуль, а затем конкретный банк.
Чипу передаётся местоположение страницы данных (адрес строки), и он отвечает на это передачей целой страницы. На всё это требуется время и, что более важно, время нужно и для полной активации строки, чтобы гарантировать полную блокировку строки битов перед выполнением доступа к ней.
Затем определяется соответствующий столбец и извлекается единственный бит информации. Все типы DRAM передают данные пакетами, упаковывая информацию в единый блок, и пакет в современной памяти почти всегда равен 8 битам. То есть даже если за один тактовый цикл извлекается один бит, эти данные нельзя передать, пока из других банков не будет получено ещё 7 битов.
А если следующий требуемый бит данных находится на другой странице, то перед активацией следующей необходимо закрыть текущую открытую страницу (это процесс называется pre-charging). Всё это, разумеется, требует больше времени.
Все эти различные периоды между временем отправки команды и выполнением требуемого действия называются таймингами памяти или задержками. Чем ниже значение, тем выше общая производительность, ведь мы тратим меньше времени на ожидание завершения операций.
Некоторые из этих задержек имеют знакомые фанатам компьютеров названия:
| Название тайминга | Описание | Обычное значение в DDR4 |
| tRCD | Row-to-Column Delay: количество циклов между активацией строки и возможностью выбора столбца | 17 циклов |
| CL | CAS Latency: количество циклов между адресацией столбца и началом передачи пакет данных | 15 циклов |
| tRAS | Row Cycle Time: наименьшее количество циклов, в течение которого строка должна оставаться активной перед тем, как можно будет выполнить её pre-charging | 35 циклов |
| tRP | Row Precharge time: минимальное количество циклов, необходимое между активациями разных строк | 17 циклов |
Существует ещё много других таймингов и все их нужно тщательно настраивать, чтобы DRAM работала стабильно и не искажала данные, имея при этом оптимальную производительность. Как можно увидеть из таблицы, схема, демонстрирующая циклы в действии, должна быть намного шире!
Хотя при выполнении процессов часто приходится ждать, команды можно помещать в очереди и передавать, даже если память занята чем-то другим. Именно поэтому можно увидеть много модулей RAM там, где нам нужна производительность (системная память CPU и чипы на графических картах), и гораздо меньше модулей там, где они не так важны (в жёстких дисках).
Тайминги памяти можно настраивать — они не заданы жёстко в самой DRAM, потому что все команды поступают из контроллера памяти в процессоре, который использует эту память. Производители тестируют каждый изготавливаемый чип и те из них, которые соответствуют определённым скоростям при заданном наборе таймингов, группируются вместе и устанавливаются в DIMM. Затем тайминги сохраняются в небольшой чип, располагаемый на плате.

Даже памяти нужна память. Красным указано ПЗУ (read-only memory, ROM), в котором содержится информация SPD.
Процесс доступа к этой информации и её использования называется serial presence detect (SPD). Это отраслевой стандарт, позволяющий BIOS материнской платы узнать, на какие тайминги должны быть настроены все процессы.
Многие материнские платы позволяют пользователям изменять эти тайминги самостоятельно или для улучшения производительности, или для повышения стабильности платформы, но многие модули DRAM также поддерживают стандарт Extreme Memory Profile (XMP) компании Intel. Это просто дополнительная информация, хранящаяся в памяти SPD, которая сообщает BIOS: «Я могу работать с вот с такими нестандартными таймингами». Поэтому вместо самостоятельной возни с параметрами пользователь может настроить их одним нажатием мыши.
Спасибо за службу, RAM!
В отличие от других уроков анатомии, этот оказался не таким уж грязным — DIMM сложно разобрать и для изучения модулей нужны специализированные инструменты. Но внутри них таятся потрясающие подробности.
Возьмите в руку планку памяти DDR4-SDRAM на 8 ГБ из любого нового ПК: в ней упаковано почти 70 миллиардов конденсаторов и такое же количество транзисторов. Каждый из них хранит крошечную долю электрического заряда, а доступ к ним можно получить за считанные наносекунды.
Даже при повседневном использовании она может выполнять бесчисленное количество команд, и большинство из плат способны без малейших проблем работать многие годы. И всё это меньше чем за 30 долларов? Это просто завораживает.
DRAM продолжает совершенствоваться — уже скоро появится DDR5, каждый модуль которой обещает достичь уровня полосы пропускания, с трудом достижимый для двух полных DIMM типа DDR4. Сразу после появления она будет очень дорогой, но для серверов и профессиональных рабочих станций такой скачок скорости окажется очень полезным.



