MAD, Bias и MAPE – Ключевые Показатели Эффективности для измерения точности прогноза продаж
Вы здесь

В этой статье я поделюсь методикой измерения точности прогноза продаж, которая применяется во многих западных компаниях и позволяет достаточно объективно оценить качество прогнозирования. В частности, данные показатели используются компанией Reckitt Benckiser, в которой я имел честь работать почти 6 лет.
Очевидно, что повышение точности прогнозирования и уменьшение ошибки прогноза улучшают многие бизнес-показатели цепи поставок, начиная от сервиса клиентов и уровня запасов, заканчивая более стабильной работой производства и более предсказуемой закупочной деятельностью. Это особенно актуально в условиях кризиса, когда эффективность становится, пожалуй, основным конкурентным преимуществом.
Именно поэтому описанные ниже показатели можно использовать как KPI функции Demand Planning так и KPI сотрудников, которые отвечают за подготовку прогноза продаж.
Так что же такое MAD, Bias и MAPE?
Bias (англ. – смещение) демонстрирует на сколько и в какую сторону прогноз продаж отклоняется от фактической потребности. Этот индикатор показывает, был ли прогноз оптимистичным или пессимистичным. То есть, отрицательное значение Bias говорит о том, что прогноз был завышен (реальная потребность оказалась ниже), и, наоборот, положительное значение о том, что прогноз был занижен. Цифровое значение показателя определяет величину отклонения (смещения).
MAD (Mean Absolute Deviation) – среднее абсолютное отклонение
n – количество периодов оценки
Это показатель можно также выразить в процентах:
MAPE (Mean Absolute Percentage Error)
n – количество периодов оценки
At – фактическая потребность за период времени t
Пример расчета MAD:
MAD, Bias и MAPE – Ключевые Показатели Эффективности для измерения точности прогноза продаж
Вы здесь

В этой статье я поделюсь методикой измерения точности прогноза продаж, которая применяется во многих западных компаниях и позволяет достаточно объективно оценить качество прогнозирования. В частности, данные показатели используются компанией Reckitt Benckiser, в которой я имел честь работать почти 6 лет.
Очевидно, что повышение точности прогнозирования и уменьшение ошибки прогноза улучшают многие бизнес-показатели цепи поставок, начиная от сервиса клиентов и уровня запасов, заканчивая более стабильной работой производства и более предсказуемой закупочной деятельностью. Это особенно актуально в условиях кризиса, когда эффективность становится, пожалуй, основным конкурентным преимуществом.
Именно поэтому описанные ниже показатели можно использовать как KPI функции Demand Planning так и KPI сотрудников, которые отвечают за подготовку прогноза продаж.
Так что же такое MAD, Bias и MAPE?
Bias (англ. – смещение) демонстрирует на сколько и в какую сторону прогноз продаж отклоняется от фактической потребности. Этот индикатор показывает, был ли прогноз оптимистичным или пессимистичным. То есть, отрицательное значение Bias говорит о том, что прогноз был завышен (реальная потребность оказалась ниже), и, наоборот, положительное значение о том, что прогноз был занижен. Цифровое значение показателя определяет величину отклонения (смещения).
MAD (Mean Absolute Deviation) – среднее абсолютное отклонение
n – количество периодов оценки
Это показатель можно также выразить в процентах:
MAPE (Mean Absolute Percentage Error)
n – количество периодов оценки
At – фактическая потребность за период времени t
Пример расчета MAD:
Анализ малых данных
КвазиНаучный блог Александра Дьяконова
Смещение (bias) и разброс (variance)
Сегодня дадим немного объяснений стандартных для машинного обучения понятий: смещение, разброс, переобучение и недообучение. Как всегда, всё объясним просто (но нужна будет математическая подготовка), на картинках, с примерами (в данном случае на модельных задачах). Все рисунки и эксперименты авторские, в конце, по традиции, изюминка – в чём при объяснении этих понятий Вас обманывают на курсах по ML и в учебниках;)

Ниже обсудим несколько фундаментальных понятий машинного обучения. Первое – переобучение (overfitting) – явление, когда ошибка на тестовой выборке заметно больше ошибки на обучающей. Это главная проблема машинного обучения: если бы такого эффекта не было (ошибка на тесте примерно совпадала с ошибкой на обучении), то всё обучение сводилось бы к минимизации ошибки на тесте (т.н. эмпирическому риску).
Второе – недообучение (underfitting) – явление, когда ошибка на обучающей выборке достаточно большая, часто говорят «не удаётся настроиться на выборку». Такой странный термин объясняется тем, что недообучение при настройке алгоритмов итерационными методами (например, нейронных сетей методом обратного распространения) можно наблюдать, когда сделано слишком маленькое число итераций, т.е. «не успели обучиться».
Третье – сложность (complexity) модели алгоритмов (допускает множество формализаций) – оценивает, насколько разнообразно семейство алгоритмов в модели с точки зрения их функциональных свойств (например, способности настраиваться на выборки). Повышение сложности (т.е. использование более сложных моделей) решает проблему недообучения и вызывает переобучение.
Сначала опишем на примере, как проявляется проблема выбора сложности и почему возникает переобучение. Для начала рассмотрим задачу регрессии. Для простоты будем считать, что это регрессия от одного признака x. Целевая зависимость y(x) известна в конечном наборе точек. На рис. 1 показана выборка для зависимости вида y = sin(4x) + шум, на рис. 2 для зашумлённой пороговой зависимости.
 Рис. 1. Настройка полиномов различных степеней на обучающую выборку.
Рис. 1. Настройка полиномов различных степеней на обучающую выборку.  Рис. 2. Настройка полиномов различных степеней на обучающую выборку.
Рис. 2. Настройка полиномов различных степеней на обучающую выборку.
На рисунках показаны также решения указанных задач полиномиальной регрессией с разными степенями полиномов. Видно, что в обеих задачах полином первой степени явно плохо подходит для описания целевой зависимости, второй – достаточно хорошо её описывает, хотя ошибки есть и на обучающей выборке, седьмой – идеально проходит через точки обучающей выборки, но совсем не похож на «естественную функцию» и существенно отклоняется от целевой зависимости в остальных точках.
Если попробовать решить задачу полиномами различной степени, то мы получим рис. 3 (он построен для первой задачи, но во второй картина аналогичная). Видно, что с увеличением степени ошибка на обучающей выборке падает, а на тестовой (мы взяли очень мелкую сетку отрезка [0, 1]) – сначала падает, потом возрастает.
 Рис. 3. Зависимость ошибки на обучении и тесте от степени полинома.
Рис. 3. Зависимость ошибки на обучении и тесте от степени полинома.
Попробуем разобраться, в чём дело с теоретической точки зрения (сейчас немного математики). Наша целевая зависимость имеет вид

Мы строим алгоритм (в нашем случае полином фиксированной степени) a=a(x), посмотрим чему равно математическое ожидание квадрата отклонения ответа алгоритма от истинного значения:

Здесь важно понимать, как берутся матожидания (т.е., по сути, интегрирования) в приведённых выше формулах. Мы считаем, что обучающая выборка выбирается случайно из некоторого распределения, настроенный алгоритм тоже случаен, поскольку зависит от выборки, настройка алгоритма также может быть стохастической. Таким образом, матожидание берётся по всем данным (обучающим выборкам) и настройкам алгоритма, а сами формулы записываются в конкретной точке x:

При желании, можно проинтегрировать полученные формулы и по всем объектам (точнее, по какому-то распределению всех объектов) и получить уже смещение и разброс модели алгоритмов как таковой.
Разбросом (variance) мы назвали дисперсию ответов алгоритмов Da, а смещением (bias) – матожидание разности между истинным ответом и выданным алгоритмом: E(f – a). Мы получили, что ошибка раскладывается на три составляющие. Первая связана с шумом в самих данных, а вот две остальные связаны с используемой моделью алгоритмов. Понятно, что разброс характеризует разнообразие алгоритмов (из-за случайности обучающей выборки, в том числе шума, и стохастической природы настройки), а смещение – способность модели алгоритмов настраиваться на целевую зависимость. Проиллюстрируем это. На рис. 4-5 – показаны различные полиномы первой степени, они настроены на разных обучающих выборках. В точке x=0.5 ответы алгоритмов являются случайными величинами, они немного «разбросаны» (есть variance), а также они сильно смещены (есть bias) относительно правильного ответа (который, кстати, даже если нам и известен, то с точностью до шума).
 Рис. 4. Полиномы 1й степени, настроенные на разных обучающих выборках.
Рис. 4. Полиномы 1й степени, настроенные на разных обучающих выборках.  Рис. 5. Шум, разброс и смещение при настройках полиномов 1й степени.
Рис. 5. Шум, разброс и смещение при настройках полиномов 1й степени.
На рис. 6-7 изображены уже полиномы второй степени (настроенные на тех же выборках). В точке x=0.5 у них сильно меньше смещение и чуть меньше разброс. Видно, что они совсем неплохо описывают целевую зависимость во всех точках.
 Рис. 6. Полиномы 2й степени, настроенные на разных обучающих выборках.
Рис. 6. Полиномы 2й степени, настроенные на разных обучающих выборках.  Рис. 7. Шум, разброс и смещение при настройках полиномов 2й степени.
Рис. 7. Шум, разброс и смещение при настройках полиномов 2й степени.
 Рис. 8. Объяснение разброса и смещения на примере игры в дартс.
Рис. 8. Объяснение разброса и смещения на примере игры в дартс.
Ещё важный момент: спортсмен может повысить точность целясь выше/ниже/правее/левее, а для алгоритма нет таких понятий. Напомним, что разброс и смещение мы вводили в конкретной точке. Если изменить смещение в этой точке, то модель будет по-новому вести себя и в остальных. Если же усреднить смещение, точнее его квадрат, по всем точкам, то мы получим просто число (оно не указывает, как менять модель, чтобы уменьшить ошибку).
Теперь рассмотрим самую частую иллюстрацию, которую приводят при объяснении разброса и смещения, см. рис. 9. Она полностью согласуется с рис. 3. При увеличении сложности модели (например, степени полинома) ошибка на независимом контроле сначала падает, потом начинает увеличиваться. Обычно это связывают с уменьшением смещения (в сложных моделях очень много алгоритмов, поэтому наверняка найдутся те, которые хорошо описывают целевую зависимость) и увеличением разброса (в сложных моделях больше алгоритмов, а следовательно, и больше разброс).
 Рис. 9. Классическая иллюстрация изменения разброса и смещения.
Рис. 9. Классическая иллюстрация изменения разброса и смещения.
Для простых моделей характерно недообучение (они слишком простые, не могут описать целевую зависимость и имеют большое смещение), для сложных – переобучение (алгоритмов в модели слишком много, при настройке мы выбираем ту, которая хорошо описывает обучающую выборку, но из-за сильного разброса она может допускать большую ошибку на тесте).
Теперь рассмотрим задачу классификации. Отметим, что для неё тоже есть результат о разложении ошибки на шум, разброс и смещение. На рис. 10-12 показаны результаты экспериментов в задаче с двумя классами (стандартная задача «два полумесяца») и моделью k ближайших соседей (kNN) при разных k. Результат также согласуется с рис. 9, если учесть, что изображена точность, а не ошибка, и сложность алгоритма
1/k. Возникает вопрос, а почему так вводится сложность для kNN? Ведь при разных k эти алгоритмы
Всё очень просто: часто сложность как раз и логично формализовать как 1/variance. На рис. 11 показаны разделяющие поверхности метода 1NN для разных выборок, которые описывают одну и ту же целевую зависимость. Они очень сильно отличаются друг от друга. А разделяющие поверхности kNN при больших k, см. рис 12, различаются существенно меньше. И чем выше k, тем стабильней результат. В этом смысле это очень простые алгоритмы: то, как они разделяют классы, меньше зависит от исходных данных, т.е. по определению ответ алгоритма 9NN в каждой точке зависит от 9и ближайших соседей, а по факту он практически не меняется от выборки к выборке (при варьировании обучения).
 Рис. 10. Точность метода kNN при разных k на обучении и контроле.
Рис. 10. Точность метода kNN при разных k на обучении и контроле.  Рис. 11. Разделяющие поверхности 1NN для разных выборок (одинаково распределённых).
Рис. 11. Разделяющие поверхности 1NN для разных выборок (одинаково распределённых).  Рис. 12. Разделяющие поверхности 9NN для тех же выборок.
Рис. 12. Разделяющие поверхности 9NN для тех же выборок.
Теперь покажем, в чём не правы стандартные учебники и учебные курсы по машинному обучению. Проведём эксперименты по оцениванию разброса и смещения в модельных задачах. На рис. 13-14 приведены результаты для задачи с целевой зависимостью «ступенька», а на рис. 15-16 для задачи с целевой зависимостью «sin(4x)».
 Рис. 13. «Средние» полиномы различных степеней в задаче «ступенька».
Рис. 13. «Средние» полиномы различных степеней в задаче «ступенька».  Рис. 14. Ошибка при разных степенях полиномов в задаче «ступенька».
Рис. 14. Ошибка при разных степенях полиномов в задаче «ступенька».  Рис. 15. «Средние» полиномы различных степеней в задаче «синус».
Рис. 15. «Средние» полиномы различных степеней в задаче «синус».  Рис. 16. Ошибка при разных степенях полиномов в задаче «синус».
Рис. 16. Ошибка при разных степенях полиномов в задаче «синус».
Очевидно, что степень полинома – очень естественная мера сложности для полиномиальной регрессии. Но полученные рисунки немного отличаются от рис. 9:
Почему так происходит? Одна их причин в том, что «сложность модели», если мы хотим видеть красивые графики монотонных и унимодальных функций, правильнее определять для конкретных данных! Например, ступенчатая функция нечётная (с точностью до смещения) и для восстановления такой целевой зависимости лучше подходят полиномы с нечётной старшей степенью.
Кстати, если использовать полиномиальную регрессию с L2-регуляризацией, то на рис. 16 смещение начинает вести себя «по классике»: убывать при увеличении степени полинома.
П.С. Дальше возникают естественные вопросы: как найти оптимальную сложность модели, как решать задачу сложными моделями и не переобучаться (используют же нейросети). Но это тема для отдельного поста… Просьба к читателям – давать отклики в комментариях. Этот материал будет использован, в том числе, в рамках нового курса на ВМК МГУ, а также в книжке, которую автор уже и не надеется закончить… Поэтому любые замечания по формулировкам, корректности выводов и т.п. будут полезны. Удачи!
Что такое «ошибка выжившего»: примеры из жизни и бизнеса

Что такое ошибка выжившего
Систематическая ошибка выжившего — это тип смещения выборки, возникающий, если при принятии решения человек опирается только на примеры «выживших» (тех, кто добился успеха), но не учитывает статистику по «погибшим» (тех, у кого не получилось прийти к такому же результату), поскольку данных по ним мало или они отсутствуют.
Подобные ошибки замечали еще древние греки. В трактате «О природе богов» Марк Туллий Цицерон (106 год до н. э. — 43 год до н. э.) рассказывает историю о философе и знаменитом «безбожнике» Диагоре Мелосском. Друг привел Диагора в храм на эгейском острове Самофракия и задал вопрос: «Вот ты считаешь, что боги пренебрегают людьми. Но разве ты не обратил внимания, как много [в храме] табличек с изображениями и с надписями, из которых следует, что они были пожертвованы по обету людьми, счастливо избежавшими гибели во время бури на море и благополучно прибывшими в гавань?»
«Так-то оно так, — ответил Диагор, — только здесь нет изображений тех, чьи корабли буря потопила, и они сами погибли в море».
Как ошибка выжившего искажает восприятие
Ошибка выжившего — это распространенное когнитивное искажение, в основе которого лежит непонимание причины и следствия. Человек находит закономерность в наборе данных, но не учитывает вероятность простого совпадения. Например, то, что некоторые основатели известных компаний бросили учебу в университете и стали успешны, является совпадением, поскольку не обязательно этот факт привел их к такому результату.
Самира Анохина, клинический психолог высшей категории, действительный член Российского психологического общества:
«С точки зрения психологии, когда мы говорим о феномене «ошибки выжившего», речь идет о двух процессах: перцепции (восприятии) и когниции (осмыслении, оценке, переработке) информации. Если анализировать перцептивный контекст, можно увидеть, что тот, кто совершает такую ошибку, воспринимает только часть ситуации или часть информации, имеющей отношение к этой ситуации.
В качестве примера можно привести двойные картинки, на которых можно последовательно видеть вазу и два профиля, утку либо кролика, портрет молодой девушки либо старухи. Причем увидеть оба изображения одновременно невозможно, как ни старайся. Для того чтобы видеть то или иное «закодированное» изображение, нужно переключать внимание на разные детали картинок. Этот процесс можно сравнить с работой прожектора, который, поворачиваясь, освещает разные участки местности.
Примерно то же происходит и на уровне когнитивной оценки ситуации, когда предположения и выводы делаются на основе информации, отражающей лишь определенную сторону события, при этом та часть информации, которая находится за пределами «когнитивного прожектора», не воспринимается».
Где мы с этим сталкиваемся: примеры в жизни и бизнесе
Люди подвергаются этому когнитивному искажению в разных ситуациях: при принятии решений в повседневной жизни, финансовом планировании, в научных исследованиях, бизнесе.
Как все начиналось: сбитые самолеты Второй мировой войны
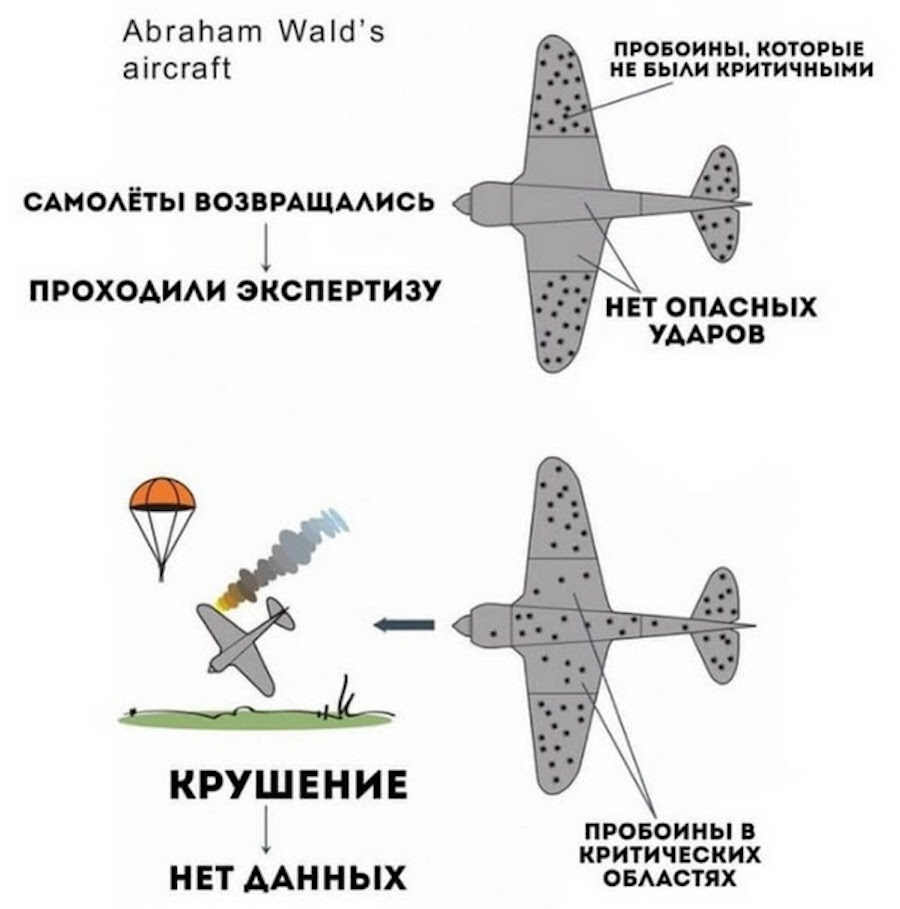
Хрестоматийным примером «ошибки выжившего» является открытие математика Абрахама Вальда во время Второй мировой войны. Американская армия теряла много самолетов в боях. Чтобы решить проблему и уменьшить потери, командование поставило перед Вальдом задачу: придумать, как укрепить конструкцию. Полностью забронировать машины было нельзя, иначе они бы просто не полетели, поэтому нужно было определить самые уязвимые места.
Военные инженеры изучили повреждения машин, вернувшихся с поля боя, и предположили, что нужно укреплять наиболее поврежденные части. Однако Абрахам Вальд отметил, что если самолет смог вернуться на базу, то попадания в эти части не критические. Важнее обратить внимание на те повреждения, с которыми самолеты не возвращались. То есть бронировать нужно те места, где у «выживших» машин не было пробоин. Это помогло снизить потери американской авиации и сохранить жизни многих летчиков.
«Ошибка выжившего» сегодня: как проявляется в повседневной жизни
Дмитрий Ковпак, врач-психотерапевт, к. м. н., доцент кафедры психотерапии, медицинской психологии и сексологии Северо-Западного государственного медицинского университета им. И. И. Мечникова, президент Ассоциации когнитивно-поведенческой психотерапии:
«Пандемия ярко показывает, как «ошибка выжившего» искажает восприятие и к чему она приводит. Люди верили в заговоры правительств и транснациональных корпораций, выдвигали конспирологические теории происходящего, а в некоторых странах все доходило до абсурда: граждане, отрицавшие существование нового коронавируса, приводящего к заболеванию COVID-19, демонстративно лизали дверные ручки, лишь бы показать, что этого вируса не существует. И если они не заразились после этого, то преподносили это как доказательство своей теории. Другие люди смотрели на все это и верили в то, что вируса действительно не существует. А потом оказывались в больницах.
В этом случае «ошибка выжившего» — это опасно и больно. Потому что когда человек верит в отсутствие проблемы, а потом сталкивается с ней лицом к лицу, это становится двойным ударом. Помимо того, что он оказывается в тяжелой жизненной ситуации, он еще поражен тем, что случилось то, чего в его картине мира быть просто не могло. Такие серьезные кризисы могут формировать посттравматические расстройства, кризис доверия себе и миру, выученную беспомощность и депрессию».
«Ошибка выжившего» в бизнесе: как она влияет на принятие решений
«Ошибка выжившего» часто встречается в сфере бизнеса. Никто не говорит о компаниях, которые потерпели неудачу на ранней стадии и больше не существуют, зато успехи нескольких десятков компаний, которые «выстрелили», превозносятся десятилетиями. Это искажает статистику и убеждает многих, что положительный исход более вероятен, чем есть на самом деле. Например, несмотря на то, что по статистике 90% стартапов терпят неудачу, начинающие предприниматели уверены, что они смогут попасть в число победителей.

Истории чужого успеха и карьерная стратегия
Яркий пример «ошибки выжившего» — культ историй успеха. Многие черпают вдохновение из рассказов о предпринимателях-миллиардерах и при этом неверно понимают причины и следствие. Например: «Стив Джобс бросил колледж и стал миллионером. Значит, секрет успеха — это уйти из университета и посвятить все время своей идее». На деле это не работает, и миллиардеры без высшего образования встречаются реже, чем кажется: из 362 самых богатых людей Америки только 12,2% бросили университет.
Те, кто стремится повторить историю успеха компании или конкретного человека, часто игнорируют роль времени, удачи, связей и социально-экономического фона. Многие из известных предпринимателей добились успеха, несмотря на свой необычный выбор, а не благодаря ему.
Как не стать жертвой ошибки выжившего
Дмитрий Ковпак:
«Когнитивным искажениям подвержены в той или иной степени все люди. Это систематические отклонения в восприятии, мышлении и поведении, тесно связанные с предубеждениями или так называемыми ограничивающими убеждениями, ошибочными стереотипами. Чаще всего они не осознаются самим носителем и требуют специальных навыков для их обнаружения и коррекции. Если человек думает, что никакого из когнитивных искажений у него нет, то это тоже своего рода когнитивное искажение.
Что касается «ошибки выжившего», то больше всего им подвержены люди, которые живут и действуют на автомате, не задумываются, что из их мыслей, предположений и ожиданий верно, а что нет, не анализируют и не проверяют факты, то есть редко пользуются критическим мышлением, логикой и анализом опыта».
Когда человек знает об «ошибке выжившего», ему гораздо проще не попасться в эту когнитивную ловушку. Кроме этого, избежать последствий влияния этой ошибки можно, если подходить к принятию решения критически.

Копайте глубже
Не доверяйте поверхностным суждениям и скоропалительным выводам, убедитесь, что у вас достаточно информации для принятия решения. Задавайте вопросы, которые помогут увидеть картину целиком. Например:
Изучайте разные точки зрения
Воспринимайте любую историю успеха как одну из версий развития событий, а не как истину в последней инстанции. Найдите неудачную статистику или истории провала и посмотрите, что в них пошло не так.
Дмитрий Ковпак:
«Многие любят публичные выступления людей, которые преодолели превратности судьбы и выжили всему вопреки. Книги наподобие «Секретов успеха от Джона Смита» также страдают «ошибкой выжившего»: это значит лишь то, что дело Джона Смита не разорилось. Куда полезнее было бы узнать, какие ошибки допустили его разорившиеся конкуренты.
Если вам пришла идея открыть ресторан в своем городе исходя из факта, что здесь много прибыльных ресторанов, вы проигнорировали то, что видите только уцелевшие и ставшие успешными точки общепита, победившие в конкурентной борьбе. Может быть, 90% всех открытых заведений в вашем городе разорились за первые два года. Но вы этого не знаете, потому что для вас они не существуют. Как писал Нассим Талеб в своей книге «Черный лебедь», на кладбище закрытых ресторанов очень тихо».



