Что такое CRUD-операции
Если вы когда-либо работали с базами данных, вы, вероятно, использовали операции CRUD. CREATE, READ, UPDATE и DELETE — это четыре основные операции программирования РСУБД. Операции CRUD используются для управления, чтения, вставки, удаления и редактирования данных таблицы.
SQL играет важную роль в большинстве отраслей, поэтому разработчикам во всем мире важно понимать, как работают операции CRUD. В этой статье мы познакомим вас с операциями CRUD с SQL.
Что такое операции CRUD?
Любые организации, отслеживающие данные (например, учетные записи, платежную информацию или другие записи), нуждаются в системах, обеспечивающих постоянное хранение, которое обычно организовано в базу данных. Реляционная база данных состоит из данных, организованных по строкам и столбцам. Их можно подключить к другим таблицам с помощью первичных и внешних ключей.
CRUD (создание, чтение, обновление, удаление) — это аббревиатура, обозначающая четыре функции, которые мы используем для реализации приложений постоянного хранения и приложений реляционных баз данных, включая Oracle Database, Microsoft SQL Server и MySQL.
В таблице ниже показано, что означает каждая операция CRUD.
| Письмо | Операция | Функция |
| C | Создавать | Вставлять |
| р | Читать | Выбирать |
| U | Обновлять | Редактировать |
| D | Удалить | Удалить |
Для SQL карты CRUD для вставки, выбора, обновления и удаления соответственно. Такие операции, как управление безопасностью, управление транзакциями, доступ и разрешение, а также оптимизация производительности, основаны на CRUD.
Почему CRUD так важен?
CRUD постоянно используется для всего, что связано с базами данных и проектированием баз данных. Разработчики программного обеспечения ничего не могут сделать без операций CRUD. Например, при разработке веб-сайтов используется REST (передача репрезентативного состояния), который является надмножеством CRUD, используемого для ресурсов HTTP.
С другой стороны, CRUD не менее важен для конечных пользователей. Без него такие вещи, как регистрация на веб-сайтах, создание блогов или закладок, были бы невозможны. Большинство приложений, которые мы используем, позволяют нам добавлять или создавать новые записи, искать существующие, вносить в них изменения или удалять их.
CRUD предлагает множество преимуществ, в том числе:
CREATE
Create позволяет добавлять новые строки в вашу таблицу. Вы можете сделать это с помощью команды INSERT INTO. Команда начинается с INSERT INTOключевого слова, за которым следует имя таблицы, имена столбцов и значения, которые нужно вставить.
При использовании у INSERT INTOвас есть два варианта:
В приведенном ниже примере мы добавим данные в нашу таблицу пекарни.
Это добавит новые строки в таблицу меню, и каждая запись будет иметь уникальный id.
Функция чтения похожа на функцию поиска, поскольку позволяет извлекать определенные записи и считывать их значения. Читать относится кSELECT
Например, давайте посмотрим на товары, которые мы продаем в нашей пекарне. Для этого мы должны отобразить все данные в нашей таблице меню, используя:
Это не внесет никаких изменений в таблицу меню, а просто отобразит все записи в этой таблице.
Взгляните на этот пример, чтобы увидеть, как SELECTизвлекаются желаемые данные:
UPDATE
Обновление — это то, как мы изменяем существующую запись в таблице. Мы можем использовать это для изменения существующих записей в базе данных. При выполнении UPDATEвам необходимо определить целевую таблицу и столбцы, которые необходимо обновить. Вам также понадобятся связанные значения, а иногда и строки.
Рекомендуется ограничить количество строк, так как это помогает избежать проблем с параллелизмом.
Чтобы обновить существующую запись, используйте следующее:
Допустим, мы хотим обновить название и цену товара. Мы бы использовали:
Это обновит таблицу, так что предыдущая запись с id 1теперь будет заменена шоколадным круассаном с price 2.5.
DELETE
Удалить используется для удаления записи из таблицы. SQL и имеет встроенную функцию удаления для одновременного удаления одной или нескольких записей из базы данных. Некоторые приложения реляционных баз данных могут разрешать жесткое удаление (безвозвратное удаление) или мягкое удаление (обновление статуса строки).
Команда удаления выглядит следующим образом:
Если мы хотим удалить один элемент из таблицы, мы используем:
Это приведет к удалению строки с хлебным предметом из таблицы. Если вы хотите удалить все записи из таблицы, вы можете использовать:
Следующие шаги для вашего обучения
В этой статье мы рассмотрели, что такое CRUD и как он используется в SQL. Эти операции будут иметь важное значение для вашей карьеры в области SQL. Вы будете использовать CRUD во всевозможных приложениях, базах данных и общих задачах программирования.
Если вы хотите узнать больше о SQL, вы можете начать со следующих тем:
Для начала ознакомьтесь с Вводным руководством по SQL для образовательных учреждений. Вы узнаете обо всех основах SQL и познакомитесь с операциями CRUD. Вы будете охватывать все, от создания и обновления баз данных до объединений, вложенных запросов, хранимых процедур, триггеров, и все это в практической среде.
Быстрое создание CRUD-основы приложения на Entity Framework/ASP.Net MVC
Предыстория
База данных
Такой общий подход сильно упростит нам жизнь в будущем, скоро увидите почему. Далее садимся и аккуратно и внимательно создаем таблицы в базе данных. Здесь и далее я буду показывать все на примере двух из них:

Остальные таблицы не отличаются чем-либо существенным.
public partial class HomeWorkUnitType : IDataObject
<
public string DisplayName
<
get < return Name; >
>
>
Свойство DisplayName пригодится нам, когда дело дойдет до UI.
Контроллеры
public abstract class DataObjectController : Controller
where T : EntityObject, IDataObject
<
>
private DataModelEntities m_DataContext;
protected DataModelEntities DataContext
<
get
<
if (m_DataContext == null )
<
m_DataContext = new DataModelEntities();
>
return m_DataContext;
>
>
protected abstract IQueryable Table < get ; >
protected abstract Action AddObject
public abstract class DataObjectController : Controller
where T : EntityObject, IDataObject
<
private DataModelEntities m_DataContext;
protected DataModelEntities DataContext
<
get
<
if (m_DataContext == null )
<
m_DataContext = new DataModelEntities();
>
return m_DataContext;
>
>
protected abstract IQueryable Table < get ; >
protected abstract Action AddObject
protected virtual IEnumerable GetAll()
<
foreach ( var t in Table.AsEnumerable())
<
LoadAllDependedObjects(t);
yield return t;
>
>
protected virtual T GetById( int id)
<
var t = Table.First(obj => obj.Id == id);
LoadAllDependedObjects(t);
return t;
>
protected virtual void CreateItem(T data)
<
AddObject(data);
>
protected virtual T EditItem(T data)
<
T existing = GetById(data.Id);
DataContext.ApplyPropertyChanges(existing.EntityKey.EntitySetName, data);
return existing;
>
protected virtual void DeleteItem( int id)
<
DataContext.DeleteObject(GetById(id));
>
public virtual ActionResult Index()
<
return View(GetAll());
>
public virtual ActionResult Details( int id)
<
return View(GetById(id));
>
public virtual ActionResult Create()
<
LoadAllDependedCollections();
return View();
>
[AcceptVerbs(HttpVerbs.Post)]
public virtual ActionResult Create(T data)
<
try
<
ValidateIdOnCreate();
ValidateModel();
CreateItem(data);
DataContext.SaveChanges();
return RedirectToAction( «Index» );
>
catch (Exception ex)
<
LoadAllDependedCollections();
ViewData[ «Error» ] = ex.JoinMessages();
return View(data);
>
>
public virtual ActionResult Edit( int id)
<
LoadAllDependedCollections();
return View(GetById(id));
>
[AcceptVerbs(HttpVerbs.Post)]
public virtual ActionResult Edit(T data)
<
try
<
ValidateModel();
data = EditItem(data);
DataContext.SaveChanges();
return RedirectToAction( «Index» );
>
catch (Exception ex)
<
LoadAllDependedCollections();
ViewData[ «Error» ] = ex.JoinMessages();
return View(data);
>
>
public virtual ActionResult Delete( int id)
<
try
<
ValidateModel();
DeleteItem(id);
DataContext.SaveChanges();
>
catch (Exception ex)
<
ViewData[ «Error» ] = ex.JoinMessages();
>
return RedirectToAction( «Index» );
>
protected void ValidateModel()
<
if (!ModelState.IsValid)
<
throw new Exception( «Model contains errors.» );
>
>
protected virtual void LoadAllDependedCollections()
<
>
protected virtual void LoadAllDependedObjects(T obj)
<
>
protected virtual void ValidateIdOnCreate()
<
ModelState[ «Id» ].Errors.Clear();
>
>
Контроллеры простых объектов
public class HomeWorkUnitTypeController : DataObjectController
<
protected override IQueryable Table
<
get < return DataContext.HomeWorkUnitType; >
>
Контроллеры сложных объектов
protected virtual void LoadAllDependedCollections()
<
>
protected virtual void LoadAllDependedObjects(T obj)
<
>
public class HomeWorkUnitController : DataObjectController
<
protected override IQueryable Table
<
get < return DataContext.HomeWorkUnit; >
>
Микросервисы: от CRUD до Native Image. Часть первая
Слово «микросервисы» на слуху последние несколько лет. Технология активно развивается, на онлайн-конференциях о ней говорят, да и сами мы пишем их каждый день. Когда-то новый подход уже стал рутиной. Но мне как Java-архитектору интересно то, каким код был раньше, как он менялся, какие способы исполнения популярны сейчас и будут использоваться в 2021 году: асинхронность, контейнеры, FaaS.
Так родился этот пост в двух частях, который я подготовил для Хабра на основе своих статей в блоге компании BellSoft и круглого стола Joker 2020, где мы обсуждали будущее джавы. Актуальное сегодня улучшение экосистемы для бэкендов не может существовать без понимания того, как создавать микросервисы: писать с нуля или вырезать скальпелем из монолитов? Предлагаю в первой части поговорить об их сущности, а во второй — разложить микросервисный контейнер на слои и посмотреть на вклад каждого слоя.
Главное преимущество — в структуре
Абсолютное большинство материалов о микросервисной архитектуре сравнивает её с монолитами с точки зрения строения. Того, каким образом работают компоненты, как единое целое или изолированно. Микросервисы не зависят друг от друга и могут обмениваться данными по сети через произвольные протоколы, например, REST API. Что это нам дает? Как минимум, свободу выбирать любые тулы, не оглядываясь на ESB, ограничения схем и тонкости совместимости. Виртуализация и контейнеризация тоже развиваются, и вот уже крошечные контейнеры с Alpine Linux позволяют запускать на прежде выделенном железе много компонент сразу.
Возьмём простой сервис, такой как бронирование билета или пополнение счёта. Ещё до появления микросервисов для управления жизненным циклом объекта данных в таких системах использовали подход CRUD. Но вся функциональность, которая обеспечивает CRUD операции для какой-то сущности, легко вычленяется. После чего можно отдельно заниматься масштабированием, управлением доступом и взаимодействием в целом, например, через REST.
Вроде, всё отлично, в чём подвох?
Проблемы и решения
Разные части монолитного приложения работают в общей памяти, а все запросы отправляются на один и тот же физический сервер. Микросервисы же связываются между собой через протоколы, а это порождает, например:
сложность в управлении сетевым трафиком и задержки;
сбои запросов и другие ошибки;
необходимость сериализовать данные и шифровать соединения.
Пожалуй, сегодня программист сервиса решит эти проблемы через готовые API Kafka/Redis/RabbitMQ и снимет с себя головную боль, отчасти забыв о сетевом уровне. А задача настройки Kafka уже пойдёт как активность DevOps.
Кроме того, управление микросервисами может стать проблемой, если их много. Поведение приложения становится сложно предсказать. Представьте сеть из сотен виртуальных хранилищ, каждое из которых обращается к другому, а иногда — одновременно. Где-то наверняка произойдёт сбой.
Есть ряд очевидных подходов к решению этой проблемы:
Декомпозиция сервиса с помощью брокеров сообщений и систем управления потоковыми данными (Kafka, Kinesis);
Взаимодействие между сервисами с помощью сервисной сетки, или service mesh (Istio, OSM);
В идеале задача — избежать такой картины:
превратив её, скажем, в такую:
Видим, что современные системы стриминга сообщений предоставляют готовые коннекторы для баз данных и других хранилищ. Здесь streaming platform (допустим, Kafka) позволяет больше не думать, как связать базы со всем остальным приложением.
Если мы взглянем отдельно на первый уровень прямо под пользователем, то он тоже довольно сложный. Редкий сервис работает с одной копией приложения, их могут быть сотни. А значит, нужно понимать, куда полетят запросы.
Service mesh («cервисная сетка») как раз помогает наладить отправку и обработку запросов. При этом возникает задача построения архитектуры, в которой уже есть свои шаблоны проектирования, такие как Sidecar.
Рантаймы, такие как JVM, вместе с языками и фреймворками поддерживают всю эту конструкцию, вывозя на себе исполнение кода.
С самим сервисом разобрались. Вместо того, чтобы запускать его просто так, положим сервис в Docker-контейнер и в следующих разделах разложим контейнер на составляющие.
Выбор инструментов
При исполнении бизнес-логики, конечно же, задействовано само приложение и операционная система. Обратимся к недавней истории и посмотрим, что же ещё нужно для сборки контейнера.
Для начала уместно будет вспомнить о сервис-ориентированной архитектуре. На фоне монолитов это первая успешная попытка решить проблемы в работе всего приложения за счёт слабой связности его частей. Можно сказать, что микросервисы — это усовершенствованная интерпретация SOA.
До поры до времени она справлялась с горизонтальным масштабированием сервисов. Но методы программирования не прекращали развиваться. Железо становилось лучше, сети — быстрее. Появлялись новые, легковесные способы коммуникации между приложениями, например REST.
Как обстояли дела с Java? Здесь всё началось с систем, основанных на наследовании и конфигах. Java EE еще лет 20 назад представила сервлеты. Далее история известна: конфигурация прямо в коде, когда XML и сам код генерировались из javadoc аннотаций; затем появились настоящие аннотации; следом и дженерики в Java 5. А вот сериализация уже была с самого начала. Появляющиеся фичи языка использовались в новых версиях Java EE.
Да, в спецификации Java EE прописаны протоколы (например, JNDI), но разработчикам реально помогло то, она описывает простые декларации того, что фактически контролируется сервером приложений. Когда мир перешел с Web 1.0 на Web 2.0, ответственность за представление перешла от бэкенда к фронтенду. И разница между внешними запросами и запросами от другой части системы исчезла.
Container dependency injection
Или «контейнерное внедрение зависимостей». Время идёт, за долгие годы индустрия освоила фичи языка и сформировала набор производственных практик. «Метапрограммирование при помощи аннотаций» — так теперь джависты могут описать свои будни. И в разработке фреймворков применяются те же подходы. Хотя стоит отметить, что другие языки предлагают достойные альтернативы: trailing lambdas в Kotlin для описания маршрутизации в Ktor; или же data-классы в разных языках, которые наконец догнала Java в 14 версии с её новыми record-ами (хотя и для старых версий давно есть Lombok).
С помощью аннотаций или внешних конфигов можно помечать обычные поля классов. А после построения необходимых объектов их внедрением занимаются контейнеры или фреймворки, контролирующие жизненный цикл класса/бина. Это может быть сложно устроено, однако исходный код не заметит этой сложности, либо подмены, которую внедрили для тестирования, или смены способа коммуникации. Этот метод широко поддерживается современными IDE, а значит можно писать код, состоящий из более мелких компонентов. Все эти действия — шаги на пути к надёжному ПО.
Собственно такой шаблон построения компонентных моделей называется Contexts and Dependency Injection (CDI). CDI как спецификация Java EE была принята в JSR 299/365 и получила эталонную реализацию в Weld, которая до сих пор используется в контейнерах вроде WildFly. Основной принцип подобной архитектуры — инверсия управления (Inversion of Control, IoC).
Не все задачи предполагают строгие стандарты: например, модули, которые подключаются к базам данных (как Spring Data) или участвуют в создании интерактивного HTML. Но для них существуют фреймворки. В каждом — ограниченный набор таких модулей, что позволяет вести разработку продуктивно. Внедрение зависимостей и инверсия управления, наряду с еще одной полезной парадигмой Convention over Configuration (также известной как «кодирование по соглашению»), реализованы в IoC-контейнерах во фреймворках, например BeanFactory в Spring. Но о них поговорим в следующий раз.
Заключение
Как я и обещал во вступлении, этот пост стал небольшим экскурсом в историю микросервисной архитектуры — ведь без этого никуда. Мы работаем с отличными технологиями, которым уже 20 с лишним лет, но они по-прежнему ощущаются современными. Всё потому, что методы востребованные и живые, а не превращаются в legacy.
Во второй части я подробно разберу слои микросервисного контейнера, объясню, на что влияет правильный выбор рантайма, и расскажу, как снизить потребление ресурсов до минимума.
Пример CRUD на Laravel 8 | Руководство по Laravel 8 для начинающих
В этом руководстве мы поэтапно рассмотрим пример CRUD-приложения на Laravel 8. CRUD – это аббревиатура для «создать, прочесть, обновить, удалить» (от английских слов create, read, update, delete). Операции CRUD – это базовые функции, используемые при работе с данными и базой данных. Эта статья описывает CRUD-приложение на Laravel, которое будет выполнять все эти операции в одном месте — в таблице базы данных MySQL.
Мы объясним, как работает CRUD-операция на Laravel 8, и усовершенствуем простой и лучший способ научиться создавать, обновлять, удалять и редактировать с помощью базы данных. Прежде чем начать работать с Laravel 8 с нуля, новичок должен разбираться в таких вещах как: контроллер, маршруты, модальные окна, миграции и создание макетов тем в Laravel. Если вы все это уже знаете, давайте перейдем к примеру пошагового процесса CRUD на Laravel 8, начиная с азов.
Шаг 1: Установите приложение Laravel 8
Для начала создайте новый проект в Laravel 8, добавив следующую команду в терминал.
Шаг 2: Настройте базу данных MySQL
Теперь вы сможете добавлять таблицы с помощью базы данных MySQL.
Шаг 3: Создайте модальное окно и миграцию
Теперь создайте модальное окно и миграцию, просто добавив в свой терминал указанную ниже команду, генерирующую модальное окно и миграцию, которая откроет вашу таблицу базы данных после запуска команды миграции.
Теперь вы можете увидеть, что в папке migration в вашей базе данных создан новый файл, такой же, как показано ниже. Теперь вам нужно добавить в базу данных столбцы.
Теперь, когда вы добавили столбцы, запустите следующую команду, которая сгенерирует таблицу в вашей базе данных.
Добавьте свойство fillable : Внутри вашего приложения/модального окна сгенерирован файл Post.php, в который вам нужно добавить свойства fillable.
Шаг 4: Добавляем маршруты к источникам
В Laravel 8 в разделе маршрутов появились некоторые изменения: вам нужно использовать свой контроллер, а затем инициализировать класс контроллера. Откройте файл «routes / web.php» и укажите маршруты, как показано ниже.
Шаг 5: Создайте контроллер
Теперь вам нужно создать контроллер, просто добавив указанную ниже команду, и сгенерировать новый контроллер ресурсов – PostController.
После выполнения данной команды вы найдете новый файл по следующему пути: «app / Http / Controllers / PostController.php». Там вы увидите уже сформированные методы, такие как показано ниже. Теперь вам нужно добавить следующие коды в ваши функции:
1) index() => этот метод предоставляет вам все данные из базы данных.
2) create() => это метод для создания новой записи.
3) store() => этот метод хранит данные в вашей базе данных.
3) show() => этот метод показывает запись.
3) edit() => используя этот метод, мы можем отредактировать нашу запись.
3) update() => это метод для обновления записи.
7) destroy() => используя этот метод, мы можем удалить нашу запись.
Теперь откройте файл PostController.php и добавьте в него приведенный ниже код.
Шаг 6: Создайте файлы blade
На этом этапе, мы создаем наши файлы просмотра. Для начала создайте две папки: первая – «макет», а вторая – «записи». В папке макета создайте файл app.blade.php, а внутри папки записей создайте ещё один файл blade. Если вы не знаете, как интегрировать наши blade-файлы в Laravel, то сначала прочитайте Как интегрировать шаблон Bootstrap в админ-панели Laravel. Теперь создайте следующие blade-файлы для вашего CRUD-приложения.
Теперь давайте создадим следующие файлы и вставим в них соответствующий код.
Ну, вот мы и подошли к концу нашего пошагового руководства по работе с CRUD в Laravel 8. В рассмотренном нами CRUD-приложении мы использовали одну функцию для создания и редактирования. Давайте запустим этот пример CRUD-приложения. Примените приведенную ниже команду и посмотрите в свой браузер.
Теперь вы можете открыть в своем браузере следующий URL-адрес: http: //localhost:8000/posts. Итак, друзья, это очень простой пошаговый способ работы с CRUD на фреймворке Laravel.
Надеюсь, это руководство поможет вам разобраться с CRUD на Laravel 8. Если у вас есть какие-либо вопросы относительно генератора операций CRUD на Laravel, пожалуйста, оставьте комментарий к этой статье, мы очень ценим ваше мнение.
Пожалуйста, оставьте ваши мнения по текущей теме материала. За комментарии, подписки, дизлайки, лайки, отклики огромное вам спасибо!
Создание простой микрослужбы CRUD на основе данных
В этом разделе показывается создание простой микрослужбы, которая выполняет операции create, read, update и delete (CRUD) в источнике данных.
Разработка простой микрослужбы CRUD
С точки зрения проектирования этот тип контейнерной микрослужбы очень прост. Возможно, решаемая проблема не представляет особой сложности, или реализация является лишь проверкой концепции.

Рис. 6-4. Внутренняя структура простой микрослужбы CRUD
Примером простой службы на основе данных такого рода является микрослужба каталога из эталонного приложения eShopOnContainers. Служба такого типа реализует все свои функции в одном проекте веб-API ASP.NET Core, который включает классы для своей модели данных, бизнес-логику и код доступа к данным. Она хранит свои связанные данные в базе данных, работающей в SQL Server (в качестве другого контейнера для целей разработки и тестирования), но это может также быть любой обычный узел SQL Server, как показано на рисунке 6-5.

Рис. 6-5. Структура простой микрослужбы CRUD на основе данных
На предыдущей схеме показана логическая микрослужба каталога, включающая свою базу данных каталога, которая может находиться на том же или другом узле Docker. Наличие базы данных на том же узле Docker может быть удобно для разработки, но не подходит для рабочей среды. При разработке такого рода службы требуется только ASP.NET Core и ORM или API для доступа к данным, например Entity Framework Core. Можно также автоматически создать метаданные Swagger посредством Swashbuckle, чтобы предоставить описание возможностей службы, как показано в следующем разделе.
Обратите внимание, что запуск сервера базы данных, такого как SQL Server, в контейнере Docker отлично подходит для сред разработки, так как вы можете получить все нужные зависимости в полной готовности без необходимости подготовки базы данных в облаке или локально. Это удобно при выполнении интеграционных тестов. Однако для рабочих сред запуск сервера базы данных в контейнере не рекомендуется, так как при таком подходе обычно не удается добиться высокой доступности. Для рабочей среды в Azure рекомендуется использовать базу данных SQL Azure или любую другую технологию базы данных, которая может обеспечить высокий уровень доступности и масштабируемости. Например, для варианта NoSQL можно выбрать CosmosDB.
Наконец, путем редактирования файлов метаданных Dockerfile и docker-compose.yml можно настроить порядок создания образа этого контейнера — какой базовый образ будет использоваться, а также конструктивные параметры, такие как внутренние и внешние имена и порты TCP.
Реализация простой микрослужбы CRUD в ASP.NET Core

Рис. 6-6. Создание проекта веб-API ASP.NET Core в Visual Studio 2019

Рис. 6-7. Зависимости в простой микрослужбе CRUD веб-API
Проект API содержит ссылки на пакет NuGet Microsoft.AspNetCore.App, включающий в себя ссылки на все основные пакеты. Кроме того, он может включать и некоторые другие пакеты.
Реализация служб CRUD веб-API с помощью Entity Framework Core
Модель данных
В EF Core доступ к данным осуществляется с помощью модели. Модель состоит из классов сущностей (модель предметной области) и производного контекста (DbContext), который представляет сеанс взаимодействия с базой данных, позволяя запрашивать и сохранять данные. Вы можете создать модель из существующей базы данных, вручную написать код модели, соответствующей вашей базе данных, или воспользоваться миграциями EF для создания базы данных из своей модели на базе подхода Code First (что упрощает развитие базы данных по мере изменения модели). Для микрослужбы каталога использовался последний подход. Пример класса CatalogItem можно увидеть в следующем примере кода, который представляет простой класс сущностей Plain Old CLR (POCO).
Также потребуется DbContext, который представляет сеанс работы с базой данных. Для микрослужбы каталога класс CatalogContext является производным от базового класса DbContext, как показано в следующем примере.
В DbContext используется метод OnModelCreating для настройки сопоставлений сущностей объектов или базы данных, а также других точек расширяемости EF.
Запрос данных из контроллеров веб-API
Экземпляры классов сущностей обычно извлекаются из базы данных с помощью LINQ, как показано в следующем примере:
Сохранение данных
Для создания, удаления и изменения данных в базе данных используются экземпляры классов сущностей. К своим контроллерам веб-API можно добавить код, как в следующем примере с жестким заданием (макета данных в этом случае).
Внедрение зависимостей в ASP.NET Core и контроллеры веб-API
В ASP.NET Core можно использовать внедрение зависимостей (DI) без дополнительной настройки. Не требуется настраивать сторонний контейнер инверсии управления (IoC), хотя при желании можно включить в инфраструктуру ASP.NET Core свой предпочитаемый контейнер IoC. В данном случае это означает, что вы можете напрямую внедрить требуемый DBContext EF или дополнительные репозитории с помощью конструктора контроллера.
Дополнительные ресурсы
Строка подключения к базе данных и переменные среды, используемые контейнерами Docker
Вы можете использовать параметры ASP.NET Core и добавить свойство ConnectionString в файл settings.json, как показано в следующем примере.
Файл settings.json может иметь значения по умолчанию для свойства ConnectionString или любого другого свойства. Однако при использовании Docker эти свойства будут переопределяться значениями переменных среды, заданными в файле docker-compose.override.yml.
Из файлов docker-compose.yml или docker-compose.override.yml можно инициализировать эти переменные среды, чтобы Docker устанавливал их в качестве переменных среды операционной системы, как показано в следующем файле docker-compose.override.yml (в этом примере строка подключения и другие строки переносятся, но в вашем собственном файле они не будут переноситься).
Файлы docker-compose.yml на уровне решения не только более гибкие, чем файлы конфигурации на уровне проекта или микрослужбы, но также и более безопасные, если вы переопределяете переменные среды, объявленные в файлах docker-compose, значениями, установленными из инструментов развертывания, например из задач развертывания Docker в Azure DevOps Services.
Наконец, можно получить это значение из кода с помощью Configuration[«ConnectionString»], как показано в методе ConfigureServices в предыдущем примере кода.
Однако для рабочей среды вы можете исследовать дополнительные возможности по хранению секретов, таких как строки подключения. Прекрасным способом управления секретами приложений является использование Azure Key Vault.
Azure Key Vault обеспечивает хранение и защиту ключей шифрования и секретов, используемых облачными приложениями и службами. Секрет — это все то, что вы хотите жестко контролировать, например ключи API, строки подключения, пароли и т. п., при этом в число средств такого контроля, среди прочего, входит ведение журналов использования, срок действия параметров и управление доступом.
Azure Key Vault позволяет детально управлять уровнем использования секретов приложений, не раскрывая их никому постороннему. Секреты можно даже менять, чтобы повысить уровень безопасности, не нарушая процедуры разработки или эксплуатации.
Чтобы приложения могли использовать Key Vault, они должны быть зарегистрированы в Active Directory организации.
Дополнительные сведения см. в документации об основных понятиях Key Vault.
Реализация управления версиями в веб-API ASP.NET
По мере изменения бизнес-требований может происходить добавление новых коллекций ресурсов, изменение связей между ресурсами и совершенствование структуры данных в ресурсах. Обновление веб-API для обработки новых требований выполняется относительно просто, однако необходимо учитывать воздействие, которое такие изменения будут оказывать на клиентские приложения, использующие веб-API. Несмотря на то, что разработчик, проектирующий и реализующий веб-API, имеет полный контроль над этим API, у него нет той же степени контроля над клиентскими приложениями, которые могут быть созданы сторонними организациями, работающими удаленно.
Управление версиями позволяет веб-API указать компоненты и ресурсы, которые он предоставляет. Затем клиентское приложение может отправлять запросы к определенной версии функции или ресурса. Существует несколько методов реализации управления версиями:
управление версиями с помощью URI;
управление версиями с помощью строки запроса;
управление версиями с помощью заголовка.
Проще всего реализовать управление версиями с помощью строки заголовка и URI. Управление версиями с помощью заголовка — хороший метод. Но он не настолько явный и простой, как управление версиями с помощью URI. Так как управление версиями с помощью URI является самым простым и очевидным методом, в эталонном приложении eShopOnContainers используется именно управление версиями с помощью URI.
При использовании управления версиями с помощью URI, как в эталонном приложении eShopOnContainers, при каждом изменении веб-API или схемы ресурсов в URI для каждого ресурса добавляется номер версии. Существующие URI должны продолжать работать как и прежде, возвращая ресурсы, которые подходят для схемы, соответствующей запрошенной версии.
Как показано в следующем примере кода, версию можно устанавливать с помощью атрибута Route в контроллере веб-API, что делает версию в URI явной (в данном случае это v1).
Этот механизм управления версиями прост и зависит от сервера, направляющего запрос в соответствующую конечную точку. Однако для более сложного управления версиями и наиболее подходящего метода при использовании REST следует использовать гиперсредства и реализовать подход HATEOAS (гипертекст как обработчик состояния приложения).
Дополнительные ресурсы
Скотт Ханселман (Scott Hanselman). Упрощение управления версиями веб-API ASP.NET Core с поддержкой REST
https://www.hanselman.com/blog/ASPNETCoreRESTfulWebAPIVersioningMadeEasy.aspx
Рой Филдинг (Roy Fielding). Управление версиями, гипермедиа и REST
https://www.infoq.com/articles/roy-fielding-on-versioning
Создание метаданных описания Swagger из веб-API ASP.NET Core
Swagger — это распространенная платформа с открытым исходным кодом, поддерживаемая большой экосистемой инструментов, помогающих разрабатывать, собирать, документировать и использовать ваши API RESTful. Она становится стандартом для домена метаданных описания API. Следует включать метаданные описания Swagger в микрослужбы любого вида — и в микрослужбы на основе данных, и в более сложные предметно-ориентированные микрослужбы (как описывается в следующем разделе).
Основу Swagger составляет спецификация Swagger, представляющая собой метаданные описания API в файле JSON или YAML. Эта спецификация создает контракт RESTful для вашего API, детализируя все его ресурсы и операции как в форме, удобной для восприятия человеком, так и в машинно-распознаваемой форме для упрощения разработки, обнаружения и интеграции.
Спецификация является основой спецификации OpenAPI (OAS) и разрабатывается в открытом, прозрачном, совместно работающем сообществе для стандартизации способа определения интерфейсов RESTful.
Спецификация определяет структуру способа обнаружения службы и понимания ее возможностей. Дополнительные сведения, включая веб-редактор и примеры спецификаций Swagger от таких компаний, как Spotify, Uber, Slack и Майкрософт, см. на сайте Swagger (https://swagger.io).
Почему следует использовать Swagger?
Ниже перечислены основные причины создания метаданных Swagger для ваших API.
Возможность для других продуктов автоматически использовать и интегрировать ваши API. Десятки продуктов и коммерческих инструментов, а также множество библиотек и платформ поддерживают Swagger. Корпорация Майкрософт предоставляет высокоуровневые продукты и инструменты, которые могут автоматически использовать API на основе Swagger, например следующие.
Microsoft Flow. Вы можете автоматически использовать и интегрировать свои API в высокоуровневый процесс Microsoft Flow без каких-либо навыков программирования.
Microsoft PowerApps. Вы можете автоматически использовать свои API из мобильных приложений PowerApps, созданных с помощью PowerApps Studio, без каких-либо навыков программирования.
Возможность автоматического создания документации по API. При создании крупномасштабных API RESTful, например сложных приложений на основе микрослужб, необходимо обрабатывать много конечных точек с разными моделями данных, используемых в полезной нагрузке запросов и ответов. Наличие соответствующей документации и надежного обозревателя API, что можно получить с помощью Swagger, является ключом для успеха API и внедрения разработчиками.
Метаданные Swagger используются Microsoft Flow, PowerApps и Azure Logic Apps для понимания, как следует использовать API и подключаться к ним.
Существует несколько способов автоматизировать создание метаданных Swagger для приложений REST API ASP.NET Core в виде функциональных страниц справки API на основе swagger-ui.
Вероятно, наиболее известен Swashbuckle, который сейчас используется в eShopOnContainers, и мы рассмотрим его подробнее в этом руководстве. Однако можно также использовать NSwag, который может создавать клиенты API Typescript и C#, а также контроллеры C# на базе спецификации Swagger или OpenAPI и даже посредством сканирования библиотеки DLL, содержащей контроллеры, с помощью NSwagStudio.
Автоматизация создания метаданных Swagger API с помощью пакета NuGet Swashbuckle
Создание метаданных Swagger вручную (в файле JSON или YAML) может быть утомительным. Однако вы можете автоматизировать обнаружение API службами веб-API ASP.NET с помощью пакета NuGet Swashbuckle для динамического создания метаданных Swagger API.
Swashbuckle автоматически создает метаданные Swagger для проектов веб-API ASP.NET. Он поддерживает проекты веб-API ASP.NET Core, классические веб-API ASP.NET и любые разновидности, такие как приложение API Azure, мобильное приложение Azure, микрослужбы Azure Service Fabric на основе ASP.NET. Он также поддерживает простой веб-API, развертываемый в контейнерах, как в эталонном приложении.
Swashbuckle объединяет обозреватель API и Swagger или пользовательский интерфейс Swagger для обеспечения вашим клиентам API широких возможностей использования обнаружения и документации. Помимо своей подсистемы создания метаданных Swagger, Swashbuckle также содержит встроенную версию пользовательского интерфейса swagger, которую он будет автоматически обслуживать после установки Swashbuckle.
Это означает, что вы можете дополнять свой API отличным пользовательским интерфейсом обнаружения, чтобы помочь разработчикам использовать этот API. Для него требуется немного кода и поддержки, так как он создается автоматически, что позволяет сосредоточиться на построении API. Результат в обозревателе API выглядит подобно показанному на рисунке 6-8.
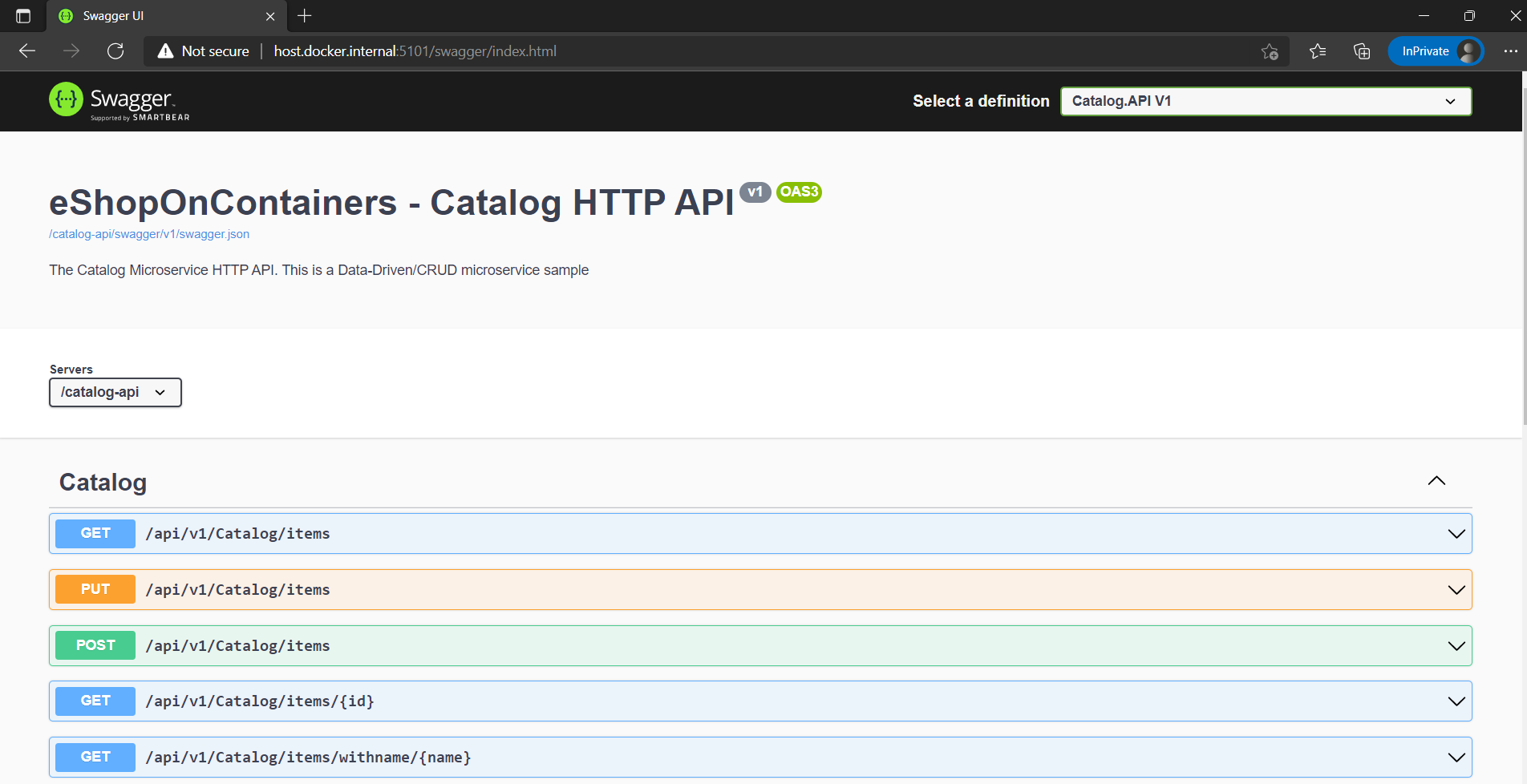
Рис. 6-8. Обозреватель API Swashbuckle на основе метаданных Swagger — микрослужба каталога eShopOnContainers
В настоящее время Swashbuckle состоит из пяти независимых внутренних пакетов NuGet в высокоуровневом метапакете Swashbuckle.AspNetCore для приложений ASP.NET Core.
После установки этих пакетов NuGet в проекте веб-API нужно настроить Swagger в классе Startup, как показано в следующем упрощенном коде:
После этого можно запустить приложение и перейти к следующим конечным точкам пользовательского интерфейса и JSON Swagger, используя URL-адреса, подобные приведенным ниже.

Рис. 6-9. Тестирование метода API Catalog/Items в пользовательском интерфейсе Swashbuckle
В сведениях об API пользовательского интерфейса Swagger приведен пример отклика, который можно использовать для выполнения реального API, что отлично подходит для обнаружения разработчика. На рисунке 6-10 показаны метаданные JSON Swagger, созданные из микрослужбы eShopOnContainers (именно ее инструменты используют на внутреннем уровне) при запросе http:// /swagger/v1/swagger.json с помощью Postman.

Рис. 6-10. Метаданные JSON Swagger
Это так просто. И так как они создаются автоматически, метаданные Swagger будет увеличиваться при добавлении дополнительных функций к вашему API.



