CUDA: с места в карьер
NB: Статья — краткое введение, покрыть все ньюансы программирования под CUDA в одной статье вряд ли возможно 🙂
О железе
CUDA работает на видеокартых начиная с 8400GS и выше. Разные видеокарты имеют разые возможности. В целом, если вы видите что в видеокарте например 128 SP(Streaming Processor) — это значит что там 8 SIMD MP (multiprocessor), каждый из которых делает одновременно 16 операций. На один MP есть 16кб shared memory, 8192 штуки 4-хбайтных регистров (В картах серии GTX2xx значения больше). Также есть 64кб констант общие для всех MP, они кешируются, при непопадании в кеш — достаточно большая задержка (400-600 тактов). Есть глобальная память видеокарты, доступ туда не кешируется, и текстуры (кешируется, кеш оптимизирован для 2D выборок). Для использования нескольких видеокарт нужно во первый отключать SLI в дровах, а во вторых — на каждую видеокарту запускать по потоку, и вызывать cudaSetDevice().
С чего начать?
Его вы можете использовать во всех своих проектах, только вместо «../../common/inc » можно указать абсолютный путь (или переменную окружения).
nvcc — это и есть великий и ужасный компилатор CUDA. На выходе он генерирует объектный файл, в котором уже включена откомпилированная программа для видеокарты.
Обратите внимение на описание интерфейса в Mandelbrot_kernel.h — тут руками приходится описывать kernel-ы которые мы собираемся вызывать из основной С++ программы (впрочем их обычно не много, так что это не страшно).
После того как вам удалось запустить пример SDK, можно рассмотреть, чем же CUDA программа отличается от обычной.
Определение функций
Определение данных
__constant__ — задает переменную в константной памяти. Следует обратить внимание, что значения для констант нужно загружать функцией cudaMemcpyToSymbol. Константы доступны из всех тредов, скорость работы сравнима с регистрами(когда в кеш попадает).
__shared__ — задает переменную в общей памяти блока тредов (т.е. и значение будет общее на всех). Тут нужно подходить с осторожностью — компилятор агрессивно оптимизирует доступ сюда(можно придушить модификатором volatile), можно получать race condition, нужно использовать __syncthreads(); чтобы данные гарантированно записались. Shared memory разделена на банки, и когда 2 потока одновременно пытаются обратиться к одному банку, возникает bank conflict и падает скорость.
Все локальные переменные которые вы определеили в ядре (__device__) — в регистрах, самая высокая скорость доступа.
Как поток узнает над чем ему работать
Основая идея CUDA в том, что для решения вашей задачи вы запускаете тысячи и тысячи потоков, поэтому не стоит пугаться того что тут будет дальше написано 🙂
Допустим, надо сделать какую-то операцию над картинкой 200×200. Картинка разбивается на куски 10×10, и на каждый пиксел такого кусочка запускаем по потоку. Выглядить это будет так:
dim3 threads(10, 10);//размер квардатика, 10*10
dim3 grid(20, 20);//сколько квадратиков нужно чтобы покрыть все изображение
your_kernel >>(image, 200,200);//Эта строка запустит 40’000 потоков (не одновременно, одновременно работать будет 200-2000 потоков примерно).
В отличии от Brook+ от AMD, где мы сразу определяем какому потоку над какими данными работать, в CUDA все не так: передаваеиые kernel-у параметры одинаковые для всех потоков, и поток должен сам получить данные для себя, чтобы сделать это, потоку нужно вычислить, в каком месте изображения он находится. В этом помогают магические переменные blockDim, blockIdx.
const int ix = blockDim.x * blockIdx.x + threadIdx.x;
const int iy = blockDim.y * blockIdx.y + threadIdx.y;
В ix и iy — координаты, с помощью которых можно получить исходные данные из массива image, и записать результат работы.
Оптимизация
Не получается?
В первую очередь следует прочитать документацию вместе с SDK (NVIDIA_CUDA_Programming_Guide, CudaReferenceManual, ptx_isa), после этого можно спросить на официальном форуме — там даже девелоперы nVidia часто отписываются, да и вообще много умных людей. По русски можно спросить у меня на форуме например, где отвечу я 🙂 Также много людей обитает на gpgpu.ru.
Надеюсь это введение поможет людям, решившим попробовать программирование для видеокарт. Если есть проблемы/вопросы — буду рад помочь. Ну а в переди нас ждет введение в Brook+ и SIMD x86
Знакомство с программно-аппаратной архитектурой CUDA
Поговорим о том, что такое CUDA, как эта технология связана с NVIDIA и как ускоряет обработку данных вычислительной техникой.
Сложность вычислительных заданий требует резкого увеличения ресурсов и скорости компьютеров. Наиболее перспективным направлением повышения скорости решения задач является внедрение идей параллелизма в работу вычислительных систем.
Сегодня спроектированы и испытаны сотни различных компьютеров, которые используют в своей архитектуре тот или иной вид параллельной обработки данных. Основная сложность при проектировании параллельных программ – обеспечение правильной последовательности взаимодействия между разными вычислительными процессами, а также координация ресурсов, которые разделяются между ними.
Поговорим о CUDA
CUDA – это программно-аппаратная архитектура параллельных вычислений, позволяющая существенно увеличить вычислительную продуктивность благодаря использованию графических процессоров NVIDIA.
При использовании данной технологии необходимо знать следующие понятия:
CUDA позволяет программистам реализовывать на специальном упрощенном диалекте языка C алгоритмы, которые используются в графических процессорах NVIDIA, и включать специальные функции в текст программы на C.
«Архитектура CUDA позволяет разработчику на свое усмотрение организовывать доступ к набору инструкций GPU и управлять его памятью.»
Эта технология поддерживает несколько языков программирования. Среди них Java, Python и некоторые другие.
Этапы запуска программы на GPU или как все происходит
Рассмотрим, как происходит запуск программы на графическом процессоре:
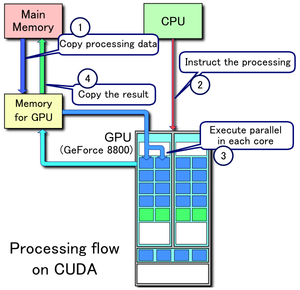
На рисунке изображены все перечисленные шаги запуска программы, кроме первого (источник).
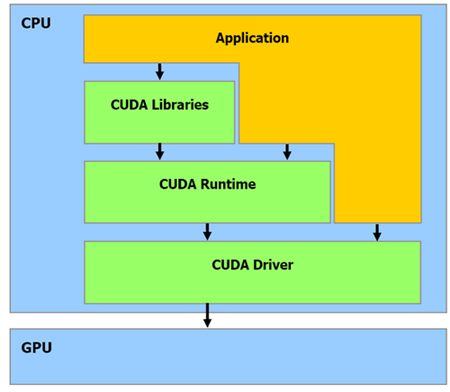 Взаимодействие CPU и GPU
Взаимодействие CPU и GPU
Как видно из рисунка, центральный процессор взаимодействует с графическим через CUDA Runtime API, CUDA Driver API и CUDA Libraries. Runtime и Driver API отличаются уровнем абстракции. Грубо говоря, первый вариант более высокого уровня в плане программирования, более абстрактный, а второй – напротив, более низкого (уровень драйвера).
В целом Runtime API является абстрактной оберткой Driver API. Во время программирования вы можете использовать любой из представленных вариантов. Из личного опыта: при использовании Driver API нужно написать немного «лишнего» кода + данный вариант сложнее.
Также необходимо понять одну важную вещь, которая впоследствии сэкономит вам время и нервы:
«Если отношение времени, потраченного на работу ядер, окажется меньше времени, потраченного на выделение памяти и запуск этих ядер, вы получите нулевую эффективность от использования GPU.»
Давайте разберем написанное подробнее. Чтобы запустить некоторые задачи на GPU, необходимо потратить «немного» времени на выделение памяти, копирование результата, etc., поэтому не нужно выполнять на графическом процессоре легкие задания, которые на деле занимают буквально миллисекунды. Зачем выполнять на GPU то, с чем легко, а главное, быстрее справится центральный процессор?
У вас возникнет вопрос: «Тогда зачем вообще использовать GPU, если при этом приходится тратить драгоценное время на выделение памяти и другие ненужные вещи?». Это заблуждение, и со временем вы поймете, что CUDA – действительно мощная технология. Дальше разберемся, почему это так.
Аппаратная часть
Архитектура GPU построена несколько иначе, нежели CPU. Поскольку графические процессоры сперва использовались только для графических расчетов, которые допускают независимую параллельную обработку данных, то GPU и предназначены именно для параллельных вычислений. Он спроектирован таким образом, чтобы выполнять огромное количество потоков (элементарных параллельных процессов).
![]() Архитектура CPU и GPU
Архитектура CPU и GPU
Как видно из картинки – в GPU есть много простых арифметически-логических устройств (АЛП), которые объединены в несколько групп и обладают общей памятью. Это помогает повысить продуктивность в вычислительных заданиях, но немного усложняет программирование.
«Для достижения лучшего ускорения необходимо продумывать стратегии доступа к памяти и учитывать аппаратные особенности.»
GPU ориентирован на выполнение программ с большим объемом данных и расчетов и представляет собой массив потоковых процессоров (Streaming Processor Array), что состоит из кластеров текстурных процессоров (Texture Processor Clusters, TPC). TPC в свою очередь состоит из набора мультипроцессоров (SM – Streaming Multi-processor), в каждом из которых несколько потоковых процессоров (SP – Streaming Processors) или ядер (в современных процессорах количество ядер превышает 1024).
Набор ядер каждого мультипроцессора работает по принципу SIMD (но с некоторым отличием) – реализация, которая позволяет группе процессоров, работающих параллельно, работать с различными данными, но при этом все они в любой момент времени должны выполнять одинаковую команду. Говоря проще, несколько потоков выполняют одно и то же задание.
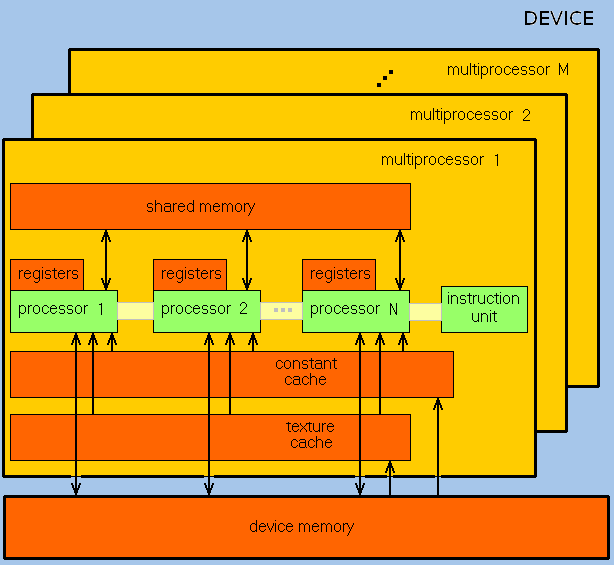 Мультипроцессоры, SM
Мультипроцессоры, SM
В результате GPU фактически стал устройством, которое реализует потоковую вычислительную модель (stream computing model): есть потоки входящих и исходящих данных, что состоят из одинаковых элементов, которые могут быть обработаны независимо друг от друга.

Вычислительные возможности
Продолжаем разбираться с CUDA. Каждая видеокарта обладает так называемыми compute capabilities – количественными характеристиками скорости выполнения определенных операций на графическом процессоре. Данное число показывает, насколько быстро видеокарта будет выполнять свою работу.
В NVIDIA эту характеристику обозначают Compute Capability Version. В таблице приведены некоторые видеокарты и соответствующие им вычислительные возможности:

Полный перечень можно посмотреть здесь. Compute Capability Version описывает множество параметров, среди которых: количество потоков на блок, максимальное количество блоков и потоков, размер warp, а также многое другое.
Потоки, блоки и сетки
CUDA использует большое количество отдельных потоков для расчетов. Все они группируются в иерархию – grid / block / thread.
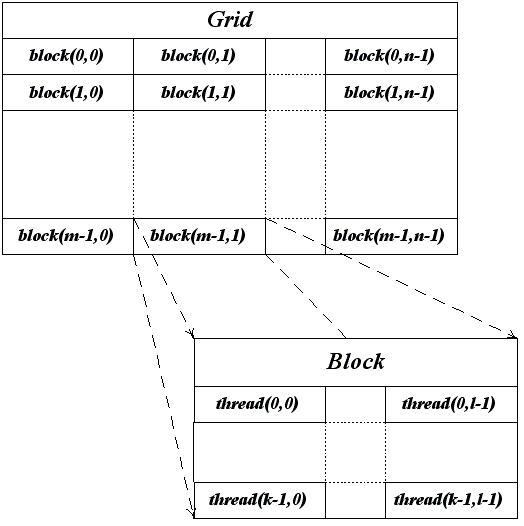 Структура блоков
Структура блоков
Верхний уровень – grid – отвечает ядру и объединяет все потоки, которые выполняет данное ядро. Grid – одномерный или двумерный массив блоков (block). Каждый блок (block) представляет собой полностью независимый набор скоординированных между собой потоков. Потоки из разных блоков не могут взаимодействовать.
Мы упоминали об отличии от SIMD-архитектуры. Есть такое понятие, как warp – группа из 32 потоков (в зависимости от архитектуры GPU, но почти всегда 32). Только потоки в рамках одной группы (warp) могут физически выполняться одновременно. Потоки разных варпов могут находиться на разных стадиях выполнения программы. Такой метод обработки данных обозначается термином SIMT (Single Instruction – Multiple Theads). Управление работой варпов выполняется на аппаратном уровне.
Почему иногда центральный процессор выполняет задания быстрее графического?
Выше уже было написано, что не стоит выполнять на GPU слишком простые задания. Чтобы понять, следует определить два термина:
Таким образом, главный вопрос состоит в следующем: почему графический процессор иногда «тупит»? Объясняем на простом примере.
У нас есть 2 автомобиля:
Если одна операция – это передвижение одного человека на определенное расстояние (пусть будет 1 км), то задержка (время, за которое один человек пройдет 1 км) для первого авто составит 3600/120 = 30 сек, а пропускная способность – 9/30 = 0,3. Для автобуса – 3600/90 = 40 сек и 30/40 = 0,75.
CPU – это фургон, а GPU – автобус: у него большая задержка, но также и большая пропускная способность. Если для вашего задания задержка каждой конкретной операции не так важна, как количество этих самых операций в секунду, то стоит рассмотреть использование GPU.
Выводы
Отличительными чертами GPU в сравнении с CPU являются:
Главный минус CUDA в том, что данная технология поддерживается только видеокартами NVIDIA без каких-либо альтернатив.
Графический процессор не всегда может дать ускорение при выполнении определенных алгоритмов. Поэтому перед использованием GPU для вычислений стоит хорошо подумать, а нужен ли он в данном случае. Вы можете использовать видеокарту для сложных вычислений: работа с графикой или изображениями, инженерные расчеты, криптографические задачи (майнинг), и т. д., но не используйте GPU для решения простых задач (разумеется, вы можете, но тогда эффективность будет равняться нулю).
Помните о задаче с фургоном и автобусом, а также не забывайте, что использование графического процессора гораздо вероятнее замедлит программу, нежели ускорит ее.
Вас также могут заинтересовать такие материалы по теме:
Нужны ли графические ядра Nvidia CUDA для игр?

Ядра CUDA являются эквивалентом процессорных ядер Nvidia. Они оптимизированы для одновременного выполнения большого количества вычислений, что очень важно для современной графики. Естественно, на графические настройки больше всего повлияло количество ядер CUDA в видеокарте, и они требуют больше всего от графического процессора, то есть теней и освещения, среди прочего.
CUDA долгое время была одной из самых выдающихся записей в спецификациях любой видеокарты GeForce. Однако не все до конца понимают, что такое ядра CUDA и что конкретно они означают для игр.
В этой статье дан краткий и простой ответ на этот вопрос. Кроме того, мы кратко рассмотрим некоторые другие связанные вопросы, которые могут возникнуть у некоторых пользователей.
Что такое ядра видеокарты CUDA?
CUDA является аббревиатурой от одной из запатентованных технологий Nvidia: Compute Unified Device Architecture. Его цель? Эффективные параллельные вычисления.
Одиночное ядро CUDA аналогично ядру ЦП, основное отличие в том, что оно менее изощренное, но реализовано в большем количестве. Обычный игровой процессор имеет от 2 до 16 ядер, но количество ядер CUDA исчисляется сотнями, даже в самых низких современных видеокартах Nvidia GeForce. Между тем, у высококлассных карт сейчас их тысячи.
Что делают ядра CUDA в играх?
Обработка графики требует одновременного выполнения множества сложных вычислений, поэтому такое огромное количество ядер CUDA реализовано в видеокартах. И учитывая, как графические процессоры разрабатываются и оптимизируются специально для этой цели, их ядра могут быть намного меньше, чем у гораздо более универсального CPU.
И как ядра CUDA влияют на производительность в игре?
По сути, любые графические настройки, которые требуют одновременного выполнения вычислений, значительно выиграют от большего количества ядер CUDA. Наиболее очевидными из них считается освещение и тени, но также включены физика, а также некоторые типы сглаживания и окклюзии окружающей среды.
Ядра CUDA или потоковые процессоры?
Там, где у Nvidia GeForce есть ядра CUDA, у их основного конкурента AMD Radeon есть потоковые процессоры.
Ядра CUDA лучше оптимизированы, поскольку аппаратное обеспечение Nvidia обычно сравнивают с AMD, но нет никаких явных различий в производительности или качестве графики, о которых вам следует беспокоиться, если вы разрываетесь между приобретением Nvidia или AMD GPU.
Сколько ядер CUDA вам нужно?
И вот сложный вопрос. Как часто бывает с бумажными спецификациями, они просто не являются хорошим индикатором того, какую производительность вы можете ожидать от аппаратного обеспечения.
Многие другие спецификации, такие как пропускная способность VRAM, более важны для рассмотрения, чем количество ядер CUDA, а также вопрос оптимизации программного обеспечения.
Для общего представления о том, насколько мощен графический процессор, мы рекомендуем проверить UserBenchmark. Однако, если вы хотите увидеть детальное и всестороннее тестирование, есть несколько надежных сайтов, таких как GamersNexus, TrustedReviews, Tom’s Hardware, AnandTech и ряд других.
Вывод
Надеемся, что это помогло пролить некоторый свет на то, чем на самом деле являются ядра CUDA, что они делают и насколько они важны. Прежде всего, мы надеемся, что помогли развеять любые ваши заблуждения по этому поводу.
Куда применить CUDA?
На протяжении десятилетий действовал закон Мура, который гласит, что каждые два года количество транзисторов на кристалле будет удваиваться. Однако это было в далеком 1965 году, а последние 5 лет стала бурно развиваться идея физической многоядерности в процессорах потребительского класса: в 2005 году Intel представила Pentium D, а AMD – Athlon X2. Тогда приложений, использующих 2 ядра, можно было пересчитать по пальцам одной руки. Однако следующее поколение процессоров Intel, совершившее революцию, имело именно 2 физических ядра. Более того, в январе 2007 года появилась серия Quad, тогда же и сам Мур признался, что вскоре его закон перестанет действовать.
Что же сейчас? Двухядерные процессоры даже в бюджетных офисных системах, а 4 физических ядра стало нормой и это всего за 2-3 го.
На протяжении десятилетий действовал закон Мура, который гласит, что каждые два года количество транзисторов на кристалле будет удваиваться. Однако это было в далеком 1965 году, а последние 5 лет стала бурно развиваться идея физической многоядерности в процессорах потребительского класса: в 2005 году Intel представила Pentium D, а AMD – Athlon X2. Тогда приложений, использующих 2 ядра, можно было пересчитать по пальцам одной руки. Однако следующее поколение процессоров Intel, совершившее революцию, имело именно 2 физических ядра. Более того, в январе 2007 года появилась серия Quad, тогда же и сам Мур признался, что вскоре его закон перестанет действовать.
Что же сейчас? Двухядерные процессоры даже в бюджетных офисных системах, а 4 физических ядра стало нормой и это всего за 2-3 года. Частота процессоров не наращивается, а улучшается архитектура, увеличивается количество физических и виртуальных ядер. Однако идея использования видеоадаптеров, наделенных десятками, а то и сотнями вычислительных «блоков» витала давно.
И хотя перспективы вычислений силами GPU огромны, наиболее популярное решение – Nvidia CUDA бесплатно, имеет множество документаций и в целом весьма несложное в реализации, приложений, использующих эту технологию не так много. В основном это всевозможные специализированные расчеты, до которых рядовому пользователю в большинстве случаев нет дела. Но есть и программы, рассчитанные на массового пользователя, о них мы и поговорим в данной статье.
Для начала немного о самой технологии и с чем ее едят. Т.к. при написании статьи я ориентируюсь на широкий круг читателей, то и объяснить постараюсь доступным языком без сложных терминов и несколько вкратце.
CUDA (англ. Compute Unified Device Architecture) — программно-аппаратная архитектура, позволяющая производить вычисления с использованием графических процессоров NVIDIA, поддерживающих технологию GPGPU (произвольных вычислений на видеокартах). Архитектура CUDA впервые появились на рынке с выходом чипа NVIDIA восьмого поколения — G80 и присутствует во всех последующих сериях графических чипов, которые используются в семействах ускорителей GeForce, Quadro и Tesla. (с) Wikipedia.org
Входящие потоки обрабатываются независимо друг от друга, т.е. параллельно.
При этом существует разделение на 3 уровня:
Grid – ядро. Содержит одно/двух/трехмерный массив блоков.
Block – содержит в себе множество потоков (thread). Потоки разных блоков между собой взаимодействовать не могут. Для чего нужно было вводить блоки? Каждый блок по сути отвечает за свою подзадачу. Например, большое изображение (которое является матрицей) можно разбить на несколько более мелких частей (матриц) и параллельно работать с каждой частью изображения.
Thread – поток. Потоки внутри одного блока могут взаимодействовать либо через общую (shared) память, которая, кстати, куда быстрее глобальной (global) памяти, либо через средства синхронизации потоков.
Warp – это объединение взаимодействующих между собой потоков, для всех современных GPU размер Warp’а равен 32. Далее идет half-warp, являющийся половинкой warp’a, т.к. обращение к памяти обычно идет раздельно для первой и второй половины warp’a.
Как можно заметить, данная архитектура отлично подходит для распараллеливания задач. И хотя программирование ведется на языке Си с некоторыми ограничениями, на деле не все так просто, т.к. не все можно распараллелить. Нет же и стандартных функций для генерации случайных чисел (или инициализации), все это приходится реализовывать отдельно. И хотя готовых вариантов имеется в достаточном количестве, радости все это не приносит. Возможность использования рекурсии появилась сравнительно недавно.
Для наглядности была написана небольшая консольная (для минимизации кода) программа, производящая операции с двумя массивами типа float, т.е. с нецелочисленными значениями. По указанным выше причинам инициализация (заполнение массива различными произвольными значениями) производилось силами CPU. Далее с соответствующими элементами из каждого массива производилось 25 всевозможных операций, промежуточные результаты записывались в третий массив. Менялся размер массива, результаты следующие:
Всего было проведено 4 теста:
1024 элемента в каждом массиве:
Наглядно видно, что при таком малом количестве элементов толку от параллельных вычислений немного, т.к. сами вычисления проходят куда быстрее, чем их подготовка.
4096 элементов в каждом массиве:
И вот уже видно, что видеокарта в 3 раза быстрее производит операции над массивами, чем процессор. Более того, время выполнения данного теста на видеокарте не увеличилось (незначительное уменьшение времени можно сослать на погрешность).
Теперь 12288 элементов в каждом массиве:
Отрыв видеокарты увеличился еще в 2 раза. Опять же стоит обратить внимание, что время выполнения на видеокарте увеличилось
незначительно, а вот на процессоре более чем в 3 раза, т.е. пропорционально усложнению задачи.
И последний тест – 36864 элемента в каждом массиве:
В данном случае ускорение достигает внушительных значений – почти в 22 раза быстрее на видеокарте. И опять же время выполнения на видеокарте возросло незначительно, а на процессоре – положенные 3 раза, что опять же пропорционально усложнению задачи.
Если же и дальше усложнять вычисления, то видеокарта выигрывает все больше и больше. Хоть и пример несколько утрированный, но в целом ситуацию показывает наглядно. Но как упоминалось выше, не все можно распараллелить. Например, вычисление числа Пи. Существуют лишь примеры, написанные посредством метода Monte Carlo, но точность вычислений составляет 7 знаков после запятой, т.е. обычный float. Для того, чтобы увеличить точность вычислений необходима длинная арифметика, а вот тут то и наступают проблемы, т.к. эффективно это реализовать очень и очень сложно. В интернете найти примеров, использующих CUDA и рассчитывающих число Пи до 1 миллиона знаков после запятой мне не удалось. Были предприняты попытки написать такое приложение, но самый простой и эффективный метод расчета числа Пи – это алгоритм Брента — Саламина или формула Гаусса. В известном SuperPI скорее всего (судя по скорости работы и количеству итераций) используется формула Гаусса. И, судя по
тому, что SuperPI однопоточный, отсутствию примеров под CUDA и провалу моих попыток, эффективно распараллелить подсчет Pi невозможно.
Кстати, можно заметить, как в процессе выполнения вычислений повышается нагрузка на GPU, а так же происходит выделение памяти.
Теперь же перейдем к более практической пользе от CUDA, а именно существующие на данный момент программы, использующие данную технологию. В большинстве своем это всевозможные аудио/видео конвертеры и редакторы.
Начнем с весьма нашумевшего и популярного продукта – Badaboom. Использовалась версия – 1.2.1.74. Стоимость программы составляет $29.90.
Интерфейс программы простой и наглядный – слева выбираем исходный файл или диск, а справа – необходимое устройство, для которого будем кодировать. Есть и пользовательский режим, в котором вручную задаются параметры, он и использовался.
Скорость кодирования напрямую зависит от качества, это очевидно. Стоит отметить, что легкое разрешение (назовем его традиционно – SD) не проблема для Badaboom – скорость кодирования в 5,5 раз превысила исходный (24 fps) фреймрейт видео. Да и даже тяжелый 1080p видеоролик программа преобразует в реальном времени. Стоит отметить, что качество итогового видео очень близко к исходному видеоматериалу, т.е. кодирует Badaboom весьма и весьма качественно.
Но обычно перегоняют видео в более низкое разрешение, посмотрим как обстоят дела в этом режиме. При снижении разрешения снижался и битрейт видео. Он составлял 9500 кбит/с для 1080p выходного файла, 4100 кбит/с для 720 p и 2400 кбит/с для 720х404. Выбор сделан исходя из разумного соотношения размер/качество.
Комментарии излишни. Если делать из 720p рип до обычного SD качества, то на перекодирование фильма длительностью 2 часа уйдет около 30 минут. И при этом загрузка процессора будет незначительной, можно заниматься своими делами не ощущая дискомфорта.
А что если перегнать видео в формат для мобильного устройства? Для этого выберем профиль iPhone (битрейт 1 мбит/с, 480х320) и посмотрим на скорость кодирования:
Нужно ли что-то говорить? Двухчасовой фильм в обычном качестве для iPhone перекодируется менее чем за 15 минут. С HD качеством сложнее, но все равно весьма быстро. Главное, что качество выходного видеоматериала остается на довольно высоком уровне при просмотре на дисплее телефона.
В целом впечатления от Badaboom положительные, скорость работы радует, интерфейс простой и понятный. Всевозможные баги ранних версий (пользовался еще бетой в 2008-ом году) вылечены. Кроме одного – путь к исходному файлу, а так же к папке, в которую сохраняется готовое видео, не должен содержать русских букв. Но на фоне достоинств программы этот недостаток незначителен.
Следующим на очереди у нас будет Super LoiLoScope. За обычную его версию просят 3 280 рублей, а за touch версию, поддерживающую сенсорное управление в Windows 7, просят аж 4 440 рублей. Попробуем разобраться за что разработчик хочет таких денег и зачем видеоредактору поддержка multitouch. Использовалась последняя версия – 1.8.3.3.
Описать интерфейс программы словами довольно сложно, поэтому я решил снять небольшой видеоролик. Сразу скажу, что, как и все видеоконвертеры под CUDA, ускорение средствами GPU поддерживается только для вывода видео в MPEG4 с кодеком h.264.
Теперь запросто можно понять, зачем же нужна поддержка сенсорных дисплеев и технологии мультитач. Более того, программа наделена многозадачностью, как бы странно это ни звучало. Как? Смотрим ролик:
Во время кодирования загрузка процессора составляет 100%, однако дискомфорта это не вызывает. Браузер и другие не тяжелые приложения не тормозят.
Теперь перейдем к производительности. Для начала все тоже самое, что и с Badaboom – перекодирование видео в аналогичное по качеству.
Результаты куда лучше, чем у Badaboom. Качество так же на высоте, разницу с оригиналом можно заметить только сравнивая попарно кадры под лупой.
Далее перейдет к перекодированию с понижением разрешения и битрейта:
Ого, а вот тут LoiloScope обходит Badaboom в 2,5 раза. При этом можно запросто параллельно резать и кодировать другое видео, читать новости и даже смотреть кино, причем даже FullHD проигрываются без проблем, хоть загрузка процессора и максимальна.
Теперь же попробуем сделать видео для мобильного устройства, профиль назовем так же, как он назывался в Badaboom – iPhone (480×320, 1 мбит/с):
Никакой ошибки нет. Все перепроверялось несколько раз, каждый раз результат был аналогичным. Скорее всего, это происходит по той простой причине, что SD файл записан с другим кодеком и в другом контейнере. При перекодировании видео сначала декодируется, разбивается на матрицы определенного размера, сжимается. ASP декодер, использующийся в случае с xvid, медленнее, чем AVC (для h.264) при параллельном декодировании. Однако и 192 fps – это в 8 раз быстрее, чем скорость исходного видео, серия длительностью 23 минуты сжимается менее чем за 4 минуты. Ситуация повторялась и с другими файлами, пережатыми в xvid/DivX.
Подобный интерфейс встречается во многих видеоконвертерах, ничего необычного в нем нет. Неудобно, что битрейт задается не конкретным числом, а перемещая ползунок в графе Quality/Size, при этом какой именно выставляется битрейт можно понять только посчитав исходя из продолжительности видео и предполагаемого размера. В настройках кодека можно выбрать либо переменный битрейт, либо задать конкретное число, но на итоговый результат это все не влияет – программа кодирует видео исходя из положения того самого ползунка.
В первую очередь проверим насколько быстро видео кодируется «само в себя»:
Результаты схожи с теми, что показал LoiloScope.
Теперь с понижением разрешения и битрейта:
Результаты в 2-2,5 раза хуже, чем у LoiloScope. Да и качество несколько хуже при сравнимом размере. Однако стоит отметить, что Movavi несколько быстрее справляется с задачей, чем Badaboom.
А теперь так же попробуем создать профиль для мобильного устройства (480х320,
На этот раз Movavi проигрывает и Badaboom. Качество видео при этом несколько хуже, чем у LoiloScope и Badaboom.
Загрузка процессора в процессе преобразования видео была около 50%.
Учитывая сравнительно высокую стоимость Movavi, среднюю скорость кодирования, а так же нестабильность даже последних версий, покупка данного продукта весьма сомнительна.
Но по-настоящему меня потряс MediaShow Espresso от CyberLink. При цене в $30, данный видеоконвертер имеет очень приятный интерфейс, множество стандартных профилей под любое устройство, а так же весьма богатые возможности по созданию собственных предустановок. Признаюсь, что это единственный конвертер, где я сразу же за несколько секунд создал необходимые мне профили для тестов. В остальных же часть все равно приходилось постоянно задавать вручную, либо создание профиля было более запутанным и удобнее было задавать параметры каждый раз самостоятельно.
Удобство удобством, но нам же важнее скорость, верно?
Кодируем исходные файлы с сохранением качества:
А со скоростью все отлично, тут и добавить нечего. В данном тесте это лучшие результаты, даже FullHD кодируется в 3 раза быстрее оригинального фреймрейта.
Далее кодирование с понижением разрешения и битрейта:
До LoiloScope не дотягивает, конечно, но результаты все равно очень впечатляющие. Загрузка процессора во время выполнения всех тестов была около 50-60%. Качество итогового видео во всех случаях была на высоком уровне, сравнимо с LoiloScope и лучше Movavi.
А теперь для мобильного устройства. В MediaShow множество встроенных профилей, в том числе и для iPhone, но в готовых профилях не видно битрейт и разрешение, по этой причине использовался собственный профиль (480х320, 1 мбит/с):
LoiloScope опять же быстрее, разве что в MediaShow более продвинутый ASP декодер, за счет чего видео из xvid кодируется куда быстрее.
В качестве итога скажу, что MediaShow Espresso – отличный продукт. Меня он подкупил своим простым и красивым интерфейсом, да и скорость работы на высоком уровне, местами даже лучшая среди других конвертеров.
Понимая, что анализировать кучу графиков с целью понять, какой же конвертер лучше, довольно сложно, я решился сравнить их в лоб. Т.к. кодек используется один и тот же (h.264), битрейт был схожим, а итоговый размер получался практически одинаковым для каждого конвертера, то данный подход позволителен. Посчитаем среднюю производительность для каждого разрешения, сложив результаты в данном разрешении по каждому конвертеру и поделив на количество тестов с данным разрешением. Например, с SD разрешением было всего 2 теста – кодирование без потери качества и для мобильного устройства. А вот для 1080p уже 4 – без потери качества, в 720p, в SD и для мобильного устройства.
Если смотреть на HD разрешение, то LoiloScope явный лидер, MediaShow отстал на 10-20%. Badaboom и Movavi явные аутсайдеры. В SD разрешении вырвался вперед MediaShow, остальные участники показали примерно равные результаты.
Что имеет в итоге? LoiloScope и MediaShow заслуживают особого внимания. И хотя возможности по редактированию у LoiloScope относительно скудные, но их хватит для многих рядовых задач, а скорость кодирования видео лучшая среди всех.
Если же вам нужен простой конвертер, то идеальным выбором станет MediaShow. Он прост и удобен, с HD файлами работает незначительно медленнее, чем с LoiloScope, а с SD контентом, которого сейчас очень много, быстрее в 1,5 раза.
Что же касается Badaboom, то при всей своей раскрученности он оказался в 2 раза медленнее вышеописанных участников, при этом по удобству у MediaShow он явно не выигрывает. Еще хуже Movavi – он незначительно быстрее Badaboom, но неудобнее, менее стабилен, дороже.
Вне конкурса мне хотелось бы рассмотреть vReveal, который в первую очередь предназначен для тех случаев, когда видео снималось с рук и без стабилизатора, т.е. цифровой стабилизатор изображения. Стоимость программы составляет почти 1 300 рублей или $40.
Почти все функции доступны и в бесплатной версии, за исключением фильтра Clean, который убирает шумы и артефакты с видео. Основное ограничение – на качество вывода видео, в бесплатной версии можно сохранять только в 480p + будет периодически появляться логотип vReveal.
Ожидать чудес не приходиться, чудес и не будет. Наглядно показать разницу довольно сложно, но она есть. В целом, если просто прогонять все любительские видеозаписи, попутно повышая резкость и немного контрастность, то качество итогового материала улучшится. Но если нужно что-то более серьезное, то vReveal не подойдет. Смею предположить, что нужно что-нибудь вроде ручного покадрового монтажа, чтобы дейсвительно стабилизировать изображение. С другой стороны, небольшие колебания видео, так называемый «тремор», он гасит неплохо.
Пару слов скажу и о CyberLink PowerDirector, стоимостью $70 за обычную версию и $100 за версию с поддержкой x64 архитектуры.
Этот видеоредактор тоже поддерживает CUDA, ролик для демонстрации vReveal длительностью 24 секунды был готов через 6 секунд. Power Director можно назвать продвинутой заменой стандартного Movie Maker, с неплохим внешним видом, он удобнее и быстрее. Более того, к нему можно найти сотни всевозможных плагинов, так что вещь стоящая.
На этом хочется подвести итог: у технологии CUDA действительно огромный потенциал и настанет время, когда GPU будут более широко использоваться в повседневных задачах, а не только в математических расчетах. Сейчас же программ не так много, но стоящие есть, их я уже отметил выше. В следующей части статьи будет детально разобрана польза от PhysX, дает ли эта технология существенные визуальные улучшения, сколько стоящих игр с поддержкой данной технологии и что еще только готовиться разработчиками.
Критику, дополнения и пожелания по добавлению игр в тестирование сюда или сюда.



