Что такое Big Data и почему их называют «новой нефтью»

Что такое Big Data?
Big Data или большие данные — это структурированные или неструктурированные массивы данных большого объема. Их обрабатывают при помощи специальных автоматизированных инструментов, чтобы использовать для статистики, анализа, прогнозов и принятия решений.
Сам термин «большие данные» предложил редактор журнала Nature Клиффорд Линч в спецвыпуске 2008 года [1]. Он говорил о взрывном росте объемов информации в мире. К большим данным Линч отнес любые массивы неоднородных данных более 150 Гб в сутки, однако единого критерия до сих пор не существует.
До 2011 года анализом больших данных занимались только в рамках научных и статистических исследований. Но к началу 2012-го объемы данных выросли до огромных масштабов, и возникла потребность в их систематизации и практическом применении.
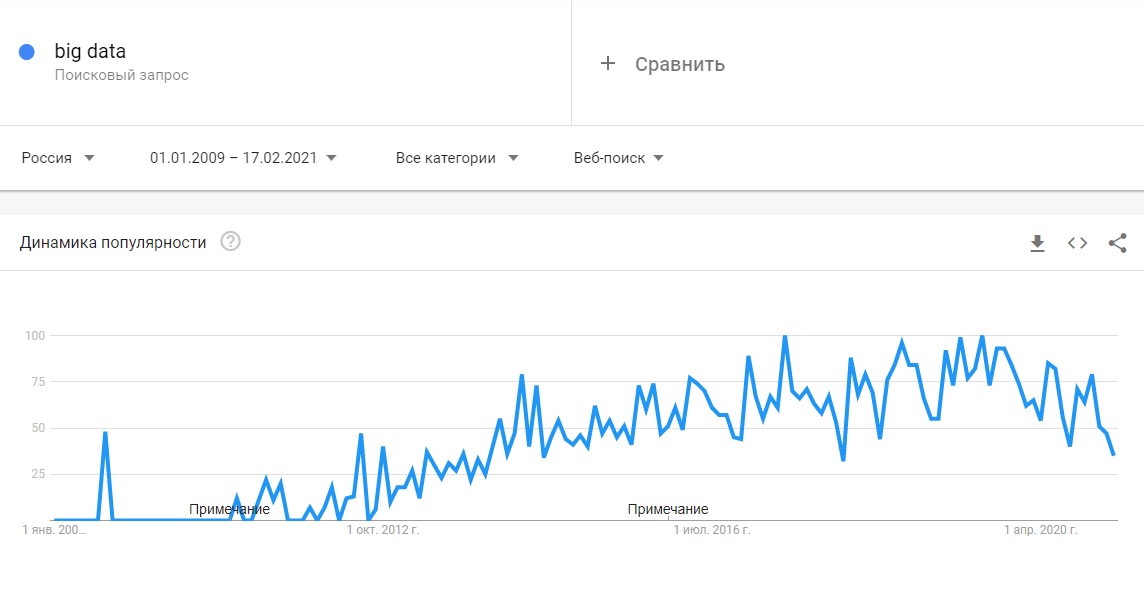
С 2014 на Big Data обратили внимание ведущие мировые вузы, где обучают прикладным инженерным и ИТ-специальностям. Затем к сбору и анализу подключились ИТ-корпорации — такие, как Microsoft, IBM, Oracle, EMC, а затем и Google, Apple, Facebook и Amazon. Сегодня большие данные используют крупные компании во всех отраслях, а также — госорганы. Подробнее об этом — в материале «Кто и зачем собирает большие данные?»
Какие есть характеристики Big Data?
Компания Meta Group предложила основные характеристики больших данных [2]:
Сегодня к этим трем добавляют еще три признака [3]:
Как работает Big Data: как собирают и хранят большие данные?
Большие данные необходимы, чтобы проанализировать все значимые факторы и принять правильное решение. С помощью Big Data строят модели-симуляции, чтобы протестировать то или иное решение, идею, продукт.
Главные источники больших данных:
С 2007 года в распоряжении ФБР и ЦРУ появилась PRISM — один из самых продвинутых сервисов, который собирает персональные данные обо всех пользователях соцсетей, а также сервисов Microsoft, Google, Apple, Yahoo и даже записи телефонных разговоров.
Современные вычислительные системы обеспечивают мгновенный доступ к массивам больших данных. Для их хранения используют специальные дата-центры с самыми мощными серверами.
Помимо традиционных, физических серверов используют облачные хранилища, «озера данных» (data lake — хранилища большого объема неструктурированных данных из одного источника) и Hadoop — фреймворк, состоящий из набора утилит для разработки и выполнения программ распределенных вычислений. Для работы с Big Data применяют передовые методы интеграции и управления, а также подготовки данных для аналитики.
Big Data Analytics — как анализируют большие данные?
Благодаря высокопроизводительным технологиям — таким, как грид-вычисления или аналитика в оперативной памяти, компании могут использовать любые объемы больших данных для анализа. Иногда Big Data сначала структурируют, отбирая только те, что нужны для анализа. Все чаще большие данные применяют для задач в рамках расширенной аналитики, включая искусственный интеллект.
Выделяют четыре основных метода анализа Big Data [4]:
1. Описательная аналитика (descriptive analytics) — самая распространенная. Она отвечает на вопрос «Что произошло?», анализирует данные, поступающие в реальном времени, и исторические данные. Главная цель — выяснить причины и закономерности успехов или неудач в той или иной сфере, чтобы использовать эти данные для наиболее эффективных моделей. Для описательной аналитики используют базовые математические функции. Типичный пример — социологические исследования или данные веб-статистики, которые компания получает через Google Analytics.
«Есть два больших класса моделей для принятия решений по ценообразованию. Первый отталкивается от рыночных цен на тот или иной товар. Данные о ценниках в других магазинах собираются, анализируются и на их основе по определенным правилам устанавливаются собственные цены.
Второй класс моделей связан с выстраиванием кривой спроса, которая отражает объемы продаж в зависимости от цены. Это более аналитическая история. В онлайне такой механизм применяется очень широко, и мы переносим эту технологию из онлайна в офлайн».
2. Прогнозная или предикативная аналитика (predictive analytics) — помогает спрогнозировать наиболее вероятное развитие событий на основе имеющихся данных. Для этого используют готовые шаблоны на основе каких-либо объектов или явлений с аналогичным набором характеристик. С помощью предикативной (или предиктивной, прогнозной) аналитики можно, например, просчитать обвал или изменение цен на фондовом рынке. Или оценить возможности потенциального заемщика по выплате кредита.
3. Предписательная аналитика (prescriptive analytics) — следующий уровень по сравнению с прогнозной. С помощью Big Data и современных технологий можно выявить проблемные точки в бизнесе или любой другой деятельности и рассчитать, при каком сценарии их можно избежать их в будущем.
4. Диагностическая аналитика (diagnostic analytics) — использует данные, чтобы проанализировать причины произошедшего. Это помогает выявлять аномалии и случайные связи между событиями и действиями.
Например, Amazon анализирует данные о продажах и валовой прибыли для различных продуктов, чтобы выяснить, почему они принесли меньше дохода, чем ожидалось.
Данные обрабатывают и анализируют с помощью различных инструментов и технологий [6] [7]:
Как отметил в подкасте РБК Трендов менеджер по развитию IoT «Яндекс.Облака» Александр Сурков, разработчики придерживаются двух критериев сбора информации:
Чтобы обрабатывать большие массивы данных в режиме онлайн используют суперкомпьютеры: их мощность и вычислительные возможности многократно превосходят обычные. Подробнее — в материале «Как устроены суперкомпьютеры и что они умеют».
Big Data и Data Science — в чем разница?
Data Science или наука о данных — это сфера деятельности, которая подразумевает сбор, обработку и анализ данных, — структурированных и неструктурированных, не только больших. В ней используют методы математического и статистического анализа, а также программные решения. Data Science работает, в том числе, и с Big Data, но ее главная цель — найти в данных что-то ценное, чтобы использовать это для конкретных задач.
В каких отраслях уже используют Big Data?
Павел Иванченко, руководитель по IoT «МегаФона»:
«IoT-решение из области так называемого точного земледелия — это когда специальные метеостанции, которые стоят в полях, с помощью сенсоров собирают данные (температура, влажность) и с помощью передающих радио-GSM-модулей отправляют их на IoT-платформу. На ней посредством алгоритмов big data происходит обработка собранной с сенсоров информации и строится высокоточный почасовой прогноз погоды. Клиент видит его в интерфейсе на компьютере, планшете или смартфоне и может оперативно принимать решения».
Big Data в России и мире
По данным компании IBS [8], в 2012 году объем хранящихся в мире цифровых данных вырос на 50%: с 1,8 до 2,7 Збайт (2,7 трлн Гбайт). В 2015-м в мире каждые десять минут генерировалось столько же данных, сколько за весь 2003 год.
По данным компании NetApp, к 2003 году в мире накопилось 5 Эбайтов данных (1 Эбайт = 1 млрд Гбайт). В 2015-м — более 6,5 Збайта, причем тогда большие данные использовали лишь 17% компаний по всему миру [9]. Большую часть данных будут генерировать сами компании, а не их клиенты. При этом обычный пользователь будет коммуницировать с различными устройствами, которые генерируют данные, около 4 800 раз в день.
Сейчас в США с большими данными работает более 55% компаний [11], в Европе и Азии — около 53%. Только за последние пять лет распространение Big Data в бизнесе выросло в три раза.
В Китае действует более 200 законов и правил, касающихся защиты личной информации. С 2019 года все популярные приложения для смартфонов начали проверять и блокировать, если они собирают данные о пользователях вопреки законам. В итоге данные через местные сервисы собирает государство, и многие из них недоступны извне.
С 2018 года в Евросоюзе действует GDPR — Всеобщий регламент по защите данных. Он регулирует все, что касается сбора, хранения и использования данных онлайн-пользователей. Когда закон вступил в силу год назад, он считался самой жесткой в мире системой защиты конфиденциальности людей в Интернете.
В России рынок больших данных только зарождается. К примеру, сотовые операторы делятся с банками информацией о потенциальных заемщиках [12]. Среди корпораций, которые собирают и анализируют данные — «Яндекс», «Сбер», Mail.ru. Появились специальные инструменты, которые помогают бизнесу собирать и анализировать Big Data — такие, как российский сервис Ctrl2GO.
Big Data в бизнесе
Большие данные полезны для бизнеса в трех главных направлениях:
Крупные компании — такие, как Netflix, Procter & Gamble или Coca-Cola — с помощью больших данных прогнозируют потребительский спрос. 70% решений в бизнесе и госуправлении принимается на основе геоданных. Подробнее — в материале о том, как бизнес извлекает прибыль из Big Data.
Каковы проблемы и перспективы Big Data?
Главные проблемы:
Плюсы и перспективы:
В ближайшем будущем большие данные станут главным инструментом для принятия решений — начиная с сетевых бизнесов и заканчивая целыми государствами и международными организациями [15].
📊 Data Science и Big Data: сходства и различия

yuliianikolaenko

Если вы заинтересованы в работе с данными, важно иметь четкое представление о связанных с ней направлениях ИТ. В статье, подготовленной при поддержке Факультетов Искусственного интеллекта и Аналитики Big Data онлайн-университета GeekBrains, мы расскажем о сходстве и основных различиях между специализациями Data Science и Big Data.
Термины
Data Science – междисциплинарная область, которая охватывает практически все, что связано с данными: от их подготовки до очистки и анализа. Data Science использует научные методы и алгоритмы для работы как со структурированными, так и с неструктурированными данными. Эта область сочетает в себе статистику, математику, машинное обучение, решение проблем и многое другое.
В статье «Научиться Data Science онлайн» мы подробнее рассказали, чем занимаются специалисты Data Science и как овладеть профессией с нуля.
Big Data
Big Data – область, в которой рассматриваются различные способы анализа и систематического извлечения больших объемов данных. Big Data включает применение механических или алгоритмических процессов получения оперативной информации для решения сложных бизнес-задач. Специалисты по Big Data работают с сырыми неструктурированными данными, результаты анализа которых используются для поддержки принятия решений в бизнесе. Аналитика больших данных включает проверку, преобразование, очистку и моделирование данных.
 Источник
Источник
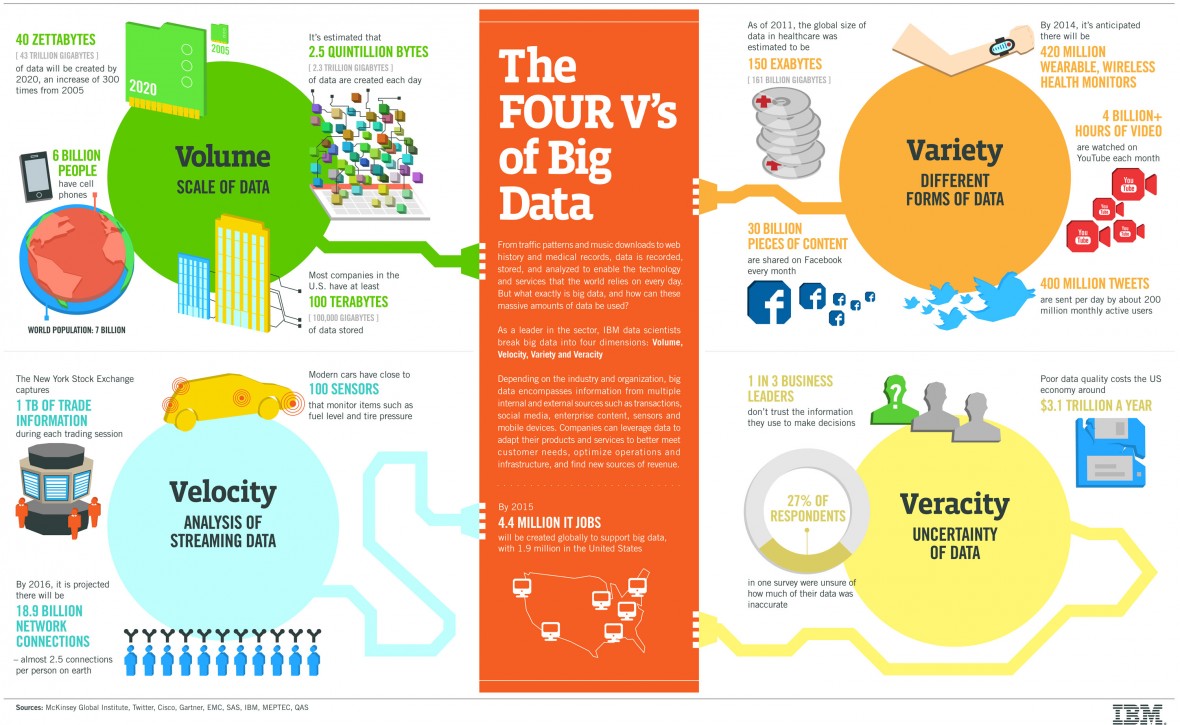
Работа с большими данными строится вокруг четырех правил (c англ. V’s of Big Data: Volume, Velocity, Variety, Veracity):
 Источник
Источник
Применение
Data Science
Big Data
Аналитика больших данных применяется в самых разных областях. Перечислим некоторые из них:
Навыки
Data Science
Big Data
Специалист по анализу больших данных должен хорошо разбираться в таких языках программирования, как R и/или Python и SQL. Наряду с хорошими знаниями статистики и математики, ему потребуются навыки работы с инструментами, вроде Hadoop или Spark, для решения проблем, связанных с огромными объемами данных и их распределенной обработкой. Необходимо владеть навыками визуализации и преобразования данных, а также разбираться в машинном обучении.
 Источник
Источник
Обязанности
Data Science
Учитывая огромное количество ежедневно обрабатываемых с помощью различных устройств по всему миру данных, организации заинтересованы в получении ценной информации из этого потока. Специалисты Data Science выполняют исследовательский анализ, а также используют различные виды алгоритмов машинного обучения для составления прогнозов определенных событий. Они сосредоточены на выявлении неизвестных корреляций, скрытых моделей и рыночных тенденций.
Big Data
В обязанности аналитиков больших данных входит работа с большим количеством разнородной информации, собранной из различных источников и поступающей с высокой скоростью. Специалисты по Big Data описывают поведение и структуру данных, а также то, как они могут быть представлены с помощью инструментов анализа: Spark, Hadoop и т. д.
Ключевые обязанности специалиста по Big Data включает понимание идей и тенденций, которые выявляются с помощью огромных наборов данных. После преобразования неструктурированной информации, бизнесу становится ясно, чего именно хотят клиенты, какие продукты продвигаются быстрее, каковы ожидания пользователей от обслуживания, как ускорить выход продукта на рынок и какие способы снижения затрат существуют. Большие данные явно приводят к большим временным выгодам для организаций, поэтому существует огромный спрос на специалистов в данной области.
 Источник
Источник
Карьерные перспективы
В российском IT-секторе, есть тенденция к разделению специалистов по Data Science и Big Data при найме на работу. Однако по запросам Big Data в Яндекс.Работа и HeadHunter, можно заметить, что анализ больших данных включен в описание вакансий как Data Scientist, так и Big Data Engineer.
Заключение
Если вы хотите построить карьеру в Data Science или Big Data, лучше начать прямо сейчас. Эти области постоянно расширяются, генерируя новые вакансии. Для освоения необходимых навыков с нуля запишитесь на курсы факультетов Искусственного интеллекта и Аналитики Big Data онлайн-университета GeekBrains. Учебные программы построены на практической работе над проектами с ведущими специалистами отрасли и личным помощником-куратором.
Большой гид по Data Science для начинающих: термины, применение, образование и вход в профессию
Наши друзья из «Цеха» опубликовали пошаговую инструкцию для начинающих в сфере Data Science от Елены Герасимовой, руководителя направления «Аналитика и Data Science» в Нетологии. Делимся с вами.
О чём речь
Data Science — деятельность, связанная с анализом данных и поиском лучших решений на их основе. Раньше подобными задачами занимались специалисты по математике и статистике. Затем на помощь пришел искусственный интеллект, что позволило включить в методы анализа оптимизацию и информатику. Этот новый подход оказался намного эффективнее.
Как строится процесс? Всё начинается со сбора больших массивов структурированных и неструктурированных данных и их преобразования в удобный для восприятия формат. Дальше используется визуализация, работа со статистикой и аналитические методы — машинного и глубокого обучения, вероятностный анализ и прогнозные модели, нейронные сети и их применение для решения актуальных задач.
Пять главных терминов, которые нужно запомнить

Искусственный интеллект, машинное обучение, глубокое обучение и наука о данных — основные и самые популярные термины. Они близки, но не эквивалентны друг другу. На старте важно разобраться, чем они отличаются.
Искусственный интеллект (Artificial Intelligence) — область, посвящённая созданию интеллектуальных систем, работающих и действующих как люди. Её возникновение связано с появлением машин Алана Тьюринга в 1936 году. Несмотря на долгую историю развития, искусственный интеллект пока не способен полностью заменить человека в большинстве областей. А конкуренция ИИ с людьми в шахматах и шифрование данных — две стороны одной медали.
Машинное обучение (Machine learning) — создание инструмента для извлечения знаний из данных. Модели ML обучаются на данных самостоятельно или поэтапно: обучение с учителем на подготовленных человеком данных и без учителя — работа со стихийными, зашумленными данными.
Глубокое обучение (Deep learning) — создание многослойных нейронных сетей в областях, где требуется более продвинутый или быстрый анализ и традиционное машинное обучение не справляется. «Глубина» обеспечивается некоторым количеством скрытых слоев нейронов в сети, которые проводят математические вычисления.
Большие данные (Big Data) — работа с большим объёмом часто неструктурированных данных. Специфика сферы — это инструменты и системы, способные выдерживать высокие нагрузки.
Наука об анализе данных (Data Science) — в основе области лежит наделение смыслом массивов данных, визуализация, сбор идей и принятие решений на основе этих данных. Специалисты по анализу данных используют некоторые методы машинного обучения и Big Data: облачные вычисления, инструменты для создания виртуальной среды разработки и многое другое.
Где применяется Data Science
Пять основных этапов в работе с данными
Сбор. Поиск каналов, где можно собирать данные, и выбор методов их получения.
Проверка. Валидация, нивелирование аномалий, которые не влияют на результат и мешают дальнейшему анализу.
Анализ. Изучение данных, подтверждение предположений.
Визуализация. Представление информации в понятном для восприятия виде: графики, диаграммы.
Реакция. Принятие решений на основе данных. Например, изменение маркетинговой стратегии, увеличение бюджета компании.

Руководитель направления «Аналитика и Data Science» в Нетологии
 Профессия
Профессия
Data
Scientist
Образование. Шесть шагов на пути к Data Scientist
Путь к этой профессии труден: невозможно овладеть всеми инструментами за месяц или даже год. Придётся постоянно учиться, делать маленькие шаги каждый день, ошибаться и пытаться вновь.
Шаг 1. Статистика, математика, линейная алгебра
Для серьезного понимания Data Science понадобится фундаментальный курс по теории вероятностей (математический анализ как необходимый инструмент в теории вероятностей), линейной алгебре и математической статистике.
Фундаментальные математические знания важны, чтобы анализировать результаты применения алгоритмов обработки данных. Сильные инженеры в машинном обучении без такого образования есть, но это скорее исключение.
Что почитать
«Элементы статистического обучения», Тревор Хасти, Роберт Тибширани и Джером Фридман — если после учебы в университете осталось много пробелов. Классические разделы машинного обучения представлены в терминах математической статистики со строгими математическими вычислениями.
«Глубокое обучение», Ян Гудфеллоу. Лучшая книга о математических принципах, лежащих в основе нейронных сетей.
«Нейронные сети и глубокое обучение», Майкл Нильсен. Для знакомства с основными принципами.
Полное руководство по математике и статистике для Data Science. Крутое и нескучное пошаговое руководство, которое поможет сориентироваться в математике и статистике.
Введение в статистику для Data Science поможет понять центральную предельную теорему. Оно охватывает генеральные совокупности, выборки и их распределение, содержит полезные видеоматериалы.
Полное руководство для начинающих по линейной алгебре для специалистов по анализу данных. Всё, что необходимо знать о линейной алгебре.
Линейная алгебра для Data Scientists. Интересная статья, знакомящая с основами линейной алгебры.
Шаг 2. Программирование
Большим преимуществом будет знакомство с основами программирования. Вы можете немного упростить себе задачу: начните изучать один язык и сосредоточьтесь на всех нюансах его синтаксиса.
При выборе языка обратите внимание на Python. Во-первых, он идеален для новичков, его синтаксис относительно прост. Во-вторых, Python многофункционален и востребован на рынке труда.
Что почитать
«Автоматизация рутинных задач с помощью Python: практическое руководство для начинающих». Практическое руководство для тех, кто учится с нуля. Достаточно прочесть главу «Манипулирование строками» и выполнить практические задания из нее.
Codecademy — здесь вы научитесь хорошему общему синтаксису.
Легкий способ выучить Python 3 — блестящий мануал, в котором объясняются основы.
Dataquest поможет освоить синтаксис.
После того, как изучите основы Python, познакомьтесь с основными библиотеками:
Машинное обучение и глубокое обучение:
Обработка естественного языка:
Web scraping (Работа с web):

курс
Python
для анализа данных
Шаг 3. Машинное обучение
Компьютеры обучаются действовать самостоятельно, нам больше не нужно писать подробные инструкции для выполнения определённых задач. Поэтому машинное обучение имеет большое значение для практически любой области, но прежде всего будет хорошо работать там, где есть Data Science.
Первый шаг в изучении машинного обучения — знакомство с тремя его основными формами.
1) Обучение с учителем — наиболее развитая форма машинного обучения. Идея в том, чтобы на основе исторических данных, для которых нам известны «правильные» значения (целевые метки), построить функцию, предсказывающую целевые метки для новых данных. Исторические данные промаркированы. Маркировка (отнесение к какому-либо классу) означает, что у вас есть особое выходное значение для каждой строки данных. В этом и заключается суть алгоритма.
2) Обучение без учителя. У нас нет промаркированных переменных, а есть много необработанных данных. Это позволяет идентифицировать то, что называется закономерностями в исторических входных данных, а также сделать интересные выводы из общей перспективы. Итак, выходные данные здесь отсутствуют, есть только шаблон, видимый в неконтролируемом наборе входных данных. Прелесть обучения без учителя в том, что оно поддается многочисленным комбинациям шаблонов, поэтому такие алгоритмы сложнее.
3) Обучение с подкреплением применяется, когда у вас есть алгоритм с примерами, в которых отсутствует маркировка, как при неконтролируемом обучении. Однако вы можете дополнить пример положительными или отрицательными откликами в соответствии с решениями, предлагаемыми алгоритмом. Обучение с подкреплением связано с приложениями, для которых алгоритм должен принимать решения, имеющие последствия. Это похоже на обучение методом проб и ошибок. Интересный пример обучения с подкреплением — когда компьютеры учатся самостоятельно играть в видеоигры.
Что почитать
Визуализация в машинном обучении. Отличная визуализация, которая поможет понять, как используется машинное обучение.
Шаг 4. Data Mining (анализ данных) и визуализация данных
Data Mining — важный исследовательский процесс. Он включает анализ скрытых моделей данных в соответствии с различными вариантами перевода в полезную информацию, которая собирается и формируется в хранилищах данных для облегчения принятия деловых решений, призванных сократить расходы и увеличить доход.
Что почитать и посмотреть
Как работает анализ данных. Отличное видео с доходчивым объяснением анализа данных.
«Работа уборщика данных — главное препятствие для анализа» — интересная статья, в которой подробно рассматривается важность анализа данных в области Data Science.
Шаг 5. Практический опыт
Заниматься исключительно теорией не очень интересно, важно попробовать свои силы на практике. Вот несколько хороших вариантов для этого.
Используйте Kaggle. Здесь проходят соревнования по анализу данных. Существует большое количество открытых массивов данных, которые можно анализировать и публиковать свои результаты. Кроме того, вы можете смотреть скрипты, опубликованные другими участниками и учиться на успешном опыте.
Шаг 6. Подтверждение квалификации
После того, как вы изучите всё, что необходимо для анализа данных, и попробуете свои силы в открытых соревнованиях, начинайте искать работу. Преимуществом станет независимое подтверждение вашей квалификации.
Последний совет: не будьте копией копий, найдите свой путь. Любой может стать Data Scientist. В том числе самостоятельно. В свободном доступе есть всё необходимое: онлайн-курсы, книги, соревнования для практики.
Но не стоит приходить в сферу только из-за моды. Что мы слышим о Data Science: это круто, это самая привлекательная работа XXI века. Если это основной стимул для вас, его вряд ли хватит надолго. Чтобы добиться успеха, важно получать удовольствие от процесса.
курс



