Изучаем pandas. Урок 2. Структуры данных Series и DataFrame
Во втором уроке мы познакомимся со структурами данных pandas – это Series и DataFrame. Основное внимание будет уделено вопросам создания и получения доступа к элементам данных структур, а также общим понятиям, которые позволят более интуитивно работать с ними в будущем.
Введение
Структура данных Series
Пора переходить к практике!
Импортируем нужные нам библиотеки.
Создать структуру Series можно на базе различных типов данных:
Конструктор класса Series выглядит следующим образом:
data – массив, словарь или скалярное значение, на базе которого будет построен Series;
copy – создает копию массива данных, если параметр равен True в ином случае ничего не делает.
В большинстве случаев, при создании Series, используют только первые два параметра. Рассмотрим различные варианты как это можно сделать.
Создание Series из списка Python
Самый простой способ создать Series – это передать в качестве единственного параметра в конструктор класса список Python.
Обратите внимание на левый столбец, в нем содержатся метки, которые мы передали в качестве index параметра при создании структуры. Правый столбец – это по-прежнему элементы нашей структуры.
Создание Series из ndarray массива из numpy
Создадим простой массив из пяти чисел, аналогичный списку из предыдущего раздела. Библиотеки pandas и numpy должны быть предварительно импортированы.
Теперь создадим Series с буквенными метками.
Создание Series из словаря (dict)
Еще один способ создать структуру Series – это использовать словарь для одновременного задания меток и значений.
Создание Series с использованием константы
Рассмотрим еще один способ создания структуры. На этот раз значения в ячейках структуры будут одинаковыми.
В созданной структуре Series имеется три элемента с одинаковым содержанием.
Работа с элементами Series
Можно использовать метку, тогда работа с Series будет похожа на работу со словарем (dict) в Python.
Доступно получение slice’ов.
В поле для индекса можно поместить условное выражение.
Со структурами Series можно работать как с векторами: складывать, умножать вектор на число и т.п.
Структура данных DataFrame
Если Series представляет собой одномерную структуру, которую для себя можно представить как таблицу с одной строкой, то DataFrame – это уже двумерная структура – полноценная таблица с множеством строк и столбцов.
Конструктор класса DataFrame выглядит так:
index – список меток для записей (имена строк таблицы);
columns – список меток для полей (имена столбцов таблицы);
copy – создает копию массива данных, если параметр равен True в ином случае ничего не делает.
Структуру DataFrame можно создать на базе:
Создание DataFrame из словаря
В данном случае будет использоваться одномерный словарь, элементами которого будут списки, структуры Series и т.д.
Создание DataFrame из списка словарей
Создание DataFrame из двумерного массива
Работа с элементами DataFrame
Основные подходы представлены в таблице ниже.
| Операция | Синтаксис | Возвращаемый результат |
| Выбор столбца | df[col] | Series |
| Выбор строки по метке | df.loc[label] | Series |
| Выбор строки по индексу | df.iloc[loc] | Series |
| Слайс по строкам | df[0:4] | DataFrame |
| Выбор строк, отвечающих условию | df[bool_vec] | DataFrame |
Теперь посмотрим, как использовать данные операций на практике.
Операция: выбор столбца.
Операция: выбор строки по метке.
Операция: выбор строки по индексу.
Операция: slice по строкам.
Операция: выбор строк, отвечающих условию.
P.S.

Изучаем pandas. Урок 2. Структуры данных Series и DataFrame : 6 комментариев
Опечатка: случае[т]
В большинстве случает, при создании Series
P.S. Спасибо за статью!
> Конструктор класса Series выглядит следующим образом:
> … fastpath=False
Про этот параметр ничего не сказали.
И слово “slice”, которое вы как только не склоняете здесь и далее в книге, переводится как “срез”. Это вполне себе русское и подходящее по смыслу слово.
Как мне кажется, ‘slice’ стало уже сленговым словом, и его вполне можно употреблять. Но слово ‘срез’ звучит тоже не плохо))) В данном случае выбор был сделан в пользу первого.
Введение в pandas: анализ данных на Python
pandas это высокоуровневая Python библиотека для анализа данных. Почему я её называю высокоуровневой, потому что построена она поверх более низкоуровневой библиотеки NumPy (написана на Си), что является большим плюсом в производительности. В экосистеме Python, pandas является наиболее продвинутой и быстроразвивающейся библиотекой для обработки и анализа данных. В своей работе мне приходится пользоваться ею практически каждый день, поэтому я пишу эту краткую заметку для того, чтобы в будущем ссылаться к ней, если вдруг что-то забуду. Также надеюсь, что читателям блога заметка поможет в решении их собственных задач с помощью pandas, и послужит небольшим введением в возможности этой библиотеки.
DataFrame и Series
Чтобы эффективно работать с pandas, необходимо освоить самые главные структуры данных библиотеки: DataFrame и Series. Без понимания что они из себя представляют, невозможно в дальнейшем проводить качественный анализ.
Series
Структура/объект Series представляет из себя объект, похожий на одномерный массив (питоновский список, например), но отличительной его чертой является наличие ассоциированных меток, т.н. индексов, вдоль каждого элемента из списка. Такая особенность превращает его в ассоциативный массив или словарь в Python.
В строковом представлении объекта Series, индекс находится слева, а сам элемент справа. Если индекс явно не задан, то pandas автоматически создаёт RangeIndex от 0 до N-1, где N общее количество элементов. Также стоит обратить, что у Series есть тип хранимых элементов, в нашем случае это int64, т.к. мы передали целочисленные значения.
У объекта Series есть атрибуты через которые можно получить список элементов и индексы, это values и index соответственно.
Доступ к элементам объекта Series возможны по их индексу (вспоминается аналогия со словарем и доступом по ключу).
Индексы можно задавать явно:
Делать выборку по нескольким индексам и осуществлять групповое присваивание:
Фильтровать Series как душе заблагорассудится, а также применять математические операции и многое другое:
Если Series напоминает нам словарь, где ключом является индекс, а значением сам элемент, то можно сделать так:
У объекта Series и его индекса есть атрибут name, задающий имя объекту и индексу соответственно.
Индекс можно поменять «на лету», присвоив список атрибуту index объекта Series
Имейте в виду, что список с индексами по длине должен совпадать с количеством элементов в Series.
DataFrame
Объект DataFrame лучше всего представлять себе в виде обычной таблицы и это правильно, ведь DataFrame является табличной структурой данных. В любой таблице всегда присутствуют строки и столбцы. Столбцами в объекте DataFrame выступают объекты Series, строки которых являются их непосредственными элементами.
DataFrame проще всего сконструировать на примере питоновского словаря:
Чтобы убедиться, что столбец в DataFrame это Series, извлекаем любой:
Объект DataFrame имеет 2 индекса: по строкам и по столбцам. Если индекс по строкам явно не задан (например, колонка по которой нужно их строить), то pandas задаёт целочисленный индекс RangeIndex от 0 до N-1, где N это количество строк в таблице.
В таблице у нас 4 элемента от 0 до 3.
Доступ по индексу в DataFrame
Индекс по строкам можно задать разными способами, например, при формировании самого объекта DataFrame или «на лету»:
Доступ к строкам по индексу возможен несколькими способами:
Можно делать выборку по индексу и интересующим колонкам:
Фильтровать DataFrame с помощью т.н. булевых массивов:
Кстати, к столбцам можно обращаться, используя атрибут или нотацию словарей Python, т.е. df.population и df[‘population’] это одно и то же.
Сбросить индексы можно вот так:
pandas при операциях над DataFrame, возвращает новый объект DataFrame.
Добавим новый столбец, в котором население (в миллионах) поделим на площадь страны, получив тем самым плотность:
Не нравится новый столбец? Не проблема, удалим его:
Особо ленивые могут просто написать del df[‘density’].
Переименовывать столбцы нужно через метод rename:
В этом примере перед тем как переименовать столбец Country Code, убедитесь, что с него сброшен индекс, иначе не будет никакого эффекта.
Чтение и запись данных
pandas поддерживает все самые популярные форматы хранения данных: csv, excel, sql, буфер обмена, html и многое другое:
Чаще всего приходится работать с csv-файлами. Например, чтобы сохранить наш DataFrame со странами, достаточно написать:
Функции to_csv ещё передаются различные аргументы (например, символ разделителя между колонками) о которых подробнее можно узнать в официальной документации.
Считать данные из csv-файла и превратить в DataFrame можно функцией read_csv.
Аргумент sep указывает разделитесь столбцов. Существует ещё масса способов сформировать DataFrame из различных источников, но наиболее часто используют CSV, Excel и SQL. Например, с помощью функции read_sql, pandas может выполнить SQL запрос и на основе ответа от базы данных сформировать необходимый DataFrame. За более подробной информацией стоит обратиться к официальной документации.
Группировка и агрегирование в pandas
Необходимо подсчитать, сколько женщин и мужчин выжило, а сколько нет. В этом нам поможет метод .groupby.
А теперь проанализируем в разрезе класса кабины:
Сводные таблицы в pandas
В качестве индекса теперь у нас будет пол человека, колонками станут значения из PClass, функцией агрегирования будет count (подсчёт количества записей) по колонке Name.
Анализ временных рядов
В pandas очень удобно анализировать временные ряды. В качестве показательного примера я буду использовать цену на акции корпорации Apple за 5 лет по дням. Файл с данными можно скачать тут.
Здесь мы формируем DataFrame с DatetimeIndex по колонке Date и сортируем новый индекс в правильном порядке для работы с выборками. Если колонка имеет формат даты и времени отличный от ISO8601, то для правильного перевода строки в нужный тип, можно использовать метод pandas.to_datetime.
Давайте теперь узнаем среднюю цену акции (mean) на закрытии (Close):
А если взять промежуток с февраля 2012 по февраль 2015 и посчитать среднее:
А что если нам нужно узнать среднюю цену закрытия по неделям?!
Resampling мощный инструмент при работе с временными рядами (time series), помогающий переформировать выборку так, как удобно вам. Метод resample первым аргументом принимает строку rule. Все доступные значения можно найти в документации.
Визуализация данных в pandas
Для визуального анализа данных, pandas использует библиотеку matplotlib. Продемонстрирую простейший способ визуализации в pandas на примере с акциями Apple.
Берём цену закрытия в промежутке между 2012 и 2017.
И видим вот такую картину:
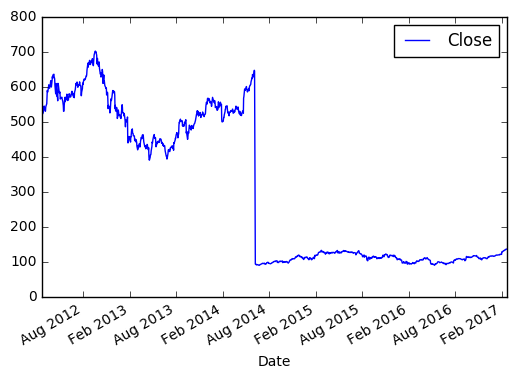
По оси X, если не задано явно, всегда будет индекс. По оси Y в нашем случае цена закрытия. Если внимательно посмотреть, то в 2014 году цена на акцию резко упала, это событие было связано с тем, что Apple проводила сплит 7 к 1. Так мало кода и уже более-менее наглядный анализ 😉
Эта заметка демонстрирует лишь малую часть возможностей pandas. Со своей стороны я постараюсь по мере своих сил обновлять и дополнять её.
Полезные ссылки
💌 Присоединяйтесь к рассылке
Понравился контент? Пожалуйста, подпишись на рассылку.
Структуры данных в pandas / pd 2
Ядром pandas являются две структуры данных, в которых происходят все операции:
Series — это структура, используемая для работы с последовательностью одномерных данных, а Dataframe — более сложная и подходит для нескольких измерений.
Пусть они и не являются универсальными для решения всех проблем, предоставляют отличный инструмент для большинства приложений. При этом их легко использовать, а множество более сложных структур можно упросить до одной из этих двух.
Однако особенности этих структур основаны на одной черте — интеграции в их структуру объектов index и labels (метки). С их помощью структурами становится очень легко манипулировать.
Series (серии)
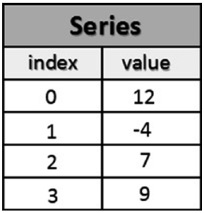
Создание объекта Series
Для создания объекта Series с предыдущего изображения необходимо вызвать конструктор Series() и передать в качестве аргумента массив, содержащий значения, которые необходимо включить.
Как можно увидеть по выводу, слева отображаются значения индексов, а справа — сами значения (данные).
В таком случае необходимо будет при вызове конструктора включить параметр index и присвоить ему массив строк с метками.
Выбор элементов по индексу или метке
Выбирать отдельные элементы можно по принципу обычных массивов numpy, используя для этого индекс.
Или же можно выбрать метку, соответствующую положению индекса.
Таким же образом можно выбрать несколько элементов массива numpy с помощью следующей команды:
В этом случае можно использовать соответствующие метки, но указать их список в массиве.
Присваивание значений элементам
Понимая как выбирать отдельные элементы, важно знать и то, как присваивать им новые значения. Можно делать это по индексу или по метке.
Создание Series из массивов NumPy
Фильтрация значений
Например, если нужно узнать, какие элементы в Series больше 8, то можно написать следующее:
Операции и математические функции
Для операторов можно написать простое арифметическое уравнение.
Количество значений
В Series часто встречаются повторения значений. Поэтому важно иметь информацию, которая бы указывала на то, есть ли дубликаты или конкретное значение в объекте.
Значения NaN
Функции isnull() и notnull() очень полезны для определения индексов без значения.
Series из словарей
Операции с сериями
Одно из главных достоинств этого типа структур данных в том, что он может выравнивать данные, определяя соответствующие метки.
Новый объект получает только те элементы, где метки совпали. Все остальные тоже присутствуют, но со значением NaN.
DataFrame (датафрейм)
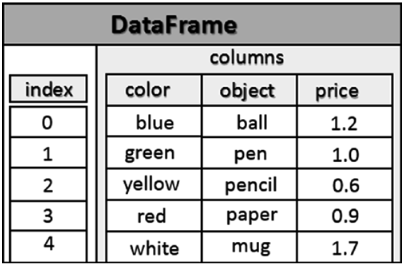
Создание Dataframe
| color | object | price | |
|---|---|---|---|
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 0.6 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
| object | price | |
|---|---|---|
| 0 | ball | 1.2 |
| 1 | pen | 1.0 |
| 2 | pencil | 0.6 |
| 3 | paper | 0.9 |
| 4 | mug | 1.7 |
Выбор элементов
То же можно проделать и для получения списка индексов.
Указав в квадратных скобках название колонки, можно получить значений в ней.
Для строк внутри Dataframe используется атрибут loc со значением индекса нужной строки.
Для выбора нескольких строк можно указать массив с их последовательностью.
| color | object | price | |
|---|---|---|---|
| 2 | yellow | pencil | 0.6 |
| 4 | white | mug | 1.7 |
Если необходимо извлечь часть Dataframe с конкретными строками, для этого можно использовать номера индексов. Она выведет данные из соответствующей строки и названия колонок.
| color | object | price | |
|---|---|---|---|
| 2 | yellow | pencil | 0.6 |
| 4 | white | mug | 1.7 |
Возвращаемое значение — объект Dataframe с одной строкой. Если нужно больше одной строки, необходимо просто указать диапазон.
| color | object | price | |
|---|---|---|---|
| 0 | blue | ball | 1.2 |
Наконец, если необходимо получить одно значение из объекта, сперва нужно указать название колонки, а потом — индекс или метку строки.
Присваивание и замена значений
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 0.6 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
Одна из главных особенностей структур данных pandas — их гибкость. Можно вмешаться на любом уровне для изменения внутренней структуры данных. Например, добавление новой колонки — крайне распространенная операция.
Ее можно выполнить, присвоив значение экземпляру Dataframe и определив новое имя колонки.
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 12 |
| 1 | green | pen | 1.0 | 12 |
| 2 | yellow | pencil | 0.6 | 12 |
| 3 | red | paper | 0.9 | 12 |
| 4 | white | mug | 1.7 | 12 |
Здесь видно, что появилась новая колонка new со значениями 12 для каждого элемента.
Для обновления значений можно использовать массив.
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 3.0 |
| 1 | green | pen | 1.0 | 1.3 |
| 2 | yellow | pencil | 0.6 | 2.2 |
| 3 | red | paper | 0.9 | 0.8 |
| 4 | white | mug | 1.7 | 1.1 |
Тот же подход используется для обновления целой колонки. Например, можно применить функцию np.arrange() для обновления значений колонки с помощью заранее заданной последовательности.
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 0 |
| 1 | green | pen | 1.0 | 1 |
| 2 | yellow | pencil | 0.6 | 2 |
| 3 | red | paper | 0.9 | 3 |
| 4 | white | mug | 1.7 | 4 |
Наконец, для изменения одного значения нужно лишь выбрать элемент и присвоить ему новое значение.
Вхождение значений
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | False | False | False | False |
| 1 | False | True | True | True |
| 2 | False | False | False | False |
| 3 | False | False | False | False |
| 4 | False | False | False | False |
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | NaN | NaN | NaN | NaN |
| 1 | NaN | pen | 1.0 | 1.0 |
| 2 | NaN | NaN | NaN | NaN |
| 3 | NaN | NaN | NaN | NaN |
| 4 | NaN | NaN | NaN | NaN |
Удаление колонки
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 3.3 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
Фильтрация
Даже для Dataframe можно применять фильтры, используя определенные условия. Например, вам нужно получить все значения меньше определенного числа (допустим, 1,2).
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | NaN |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | NaN |
| 3 | red | paper | 0.9 |
| 4 | white | mug | NaN |
Dataframe из вложенного словаря
В Python часто используется вложенный dict :
При интерпретации вложенный структуры возможно такое, что не все поля будут совпадать. pandas компенсирует это несоответствие, добавляя NaN на место недостающих значений.
| blue | red | white | |
|---|---|---|---|
| 2011 | 17 | NaN | 13 |
| 2012 | 27 | 22.0 | 22 |
| 2013 | 18 | 33.0 | 16 |
Транспонирование Dataframe
| 2011 | 2012 | 2013 | |
|---|---|---|---|
| blue | 17.0 | 27.0 | 18.0 |
| red | NaN | 22.0 | 33.0 |
| white | 13.0 | 22.0 | 16.0 |
Объекты Index
В отличие от других элементов в структурах данных pandas ( Series и Dataframe ) объекты index — неизменяемые. Это обеспечивает безопасность, когда нужно передавать данные между разными структурами.
У каждого объекта Index есть методы и свойства, которые нужны, чтобы узнавать значения.
Методы Index
Есть методы для получения информации об индексах из структуры данных. Например, idmin() и idmax() — структуры, возвращающие индексы с самым маленьким и большим значениями.
Индекс с повторяющимися метками
Пока что были только те случаи, когда у индексов одной структуры лишь одна, уникальная метка. Для большинства функций это обязательное условие, но не для структур данных pandas.
Определим, например, Series с повторяющимися метками.
Операции между структурами данных
Гибкие арифметические методы
Уже рассмотренные операции можно выполнять с помощью гибких арифметических методов:
| ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|
| blue | 6.0 | NaN | NaN | 6.0 | NaN |
| green | NaN | NaN | NaN | NaN | NaN |
| red | NaN | NaN | NaN | NaN | NaN |
| white | 20.0 | NaN | NaN | 20.0 | NaN |
| yellow | 19.0 | NaN | NaN | 19.0 | NaN |
Операции между Dataframe и Series
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 0 | 0 | 0 |
| blue | 4 | 4 | 4 | 4 |
| yellow | 8 | 8 | 8 | 8 |
| white | 12 | 12 | 12 | 12 |



