Entity Graph в Spring Data JPA
С помощью Entity Graph можно задать для каждого запроса свою стратегию загрузки данных: LAZY либо EAGER. Рассмотрим, как это сделать на примере простой модели — поста с коллекциями картинок и тегов.
Модель
Класс Post с коллекциями:
Теги — просто строки, а картинки — класс:
Нас будет интересовать загрузка коллекций тегов и картинок при выборе (select) поста. Как известно, по умолчанию они загружаются лениво.
@NamedEntityGraphs
Но у нас это не так, поскольку пост аннотирован @NamedEntityGraphs с одним графом @NamedEntityGraph, в котором сказано, что картинки следует загружать EAGER.
attributeNodes
Потому что всё, что указано в attributeNodes будет загружаться EAGER.
Заметьте, что граф у нас один, а можно задать несколько графов @NamedEntityGraph, каждый со своим набором атрибутов. И использовать нужный граф в конкретном запросе.
Ниже рассмотрим, как указать в запросе нужный граф.
Entity Graph в Derived Query Methods
Делается это просто. Причем можно как сослаться на граф, прописанный в аннотации выше, так и создать свой на ходу.
Как сослаться в запросе на существующий граф
Для этого метод репозитория аннотируем с помощью @EntityGraph и укажем внутри имя графа (post-entity-graph — так называется наш граф в аннотации @NamedEntityGraph выше):
Проверим, что при использовании этого метода оператор select выбирает не просто посты, а посты с картинками (так что поле images выбранного Post будет заполнено):
В консоли видим выполняемый select:
В настройках включено:
Но не обязательно аннотировать Post кучей @NamedEntityGraphs, граф можно собрать и на ходу.
Как задать граф с нуля прямо в запросе
Делается это вот таким нехитрым способом:
Теперь мы выбрали теги (tags) в качестве загружаемого EAGER поля, и можно проверить в тесте, что оператор select действительно выбирает теги:
Entity Graph с @Query
Использовать граф с @Query-запросом тоже не проблема:
В консоли опять же получим выбор поста с картинками:
Entity Graph с кастомными методами
Поскольку Entity Graph применим с чистым JPA и Hibernate, с кастомными методами тоже его можно применить не специфичным для Spring способом.
Создадим пользовательский репозиторий с методом:
Как видно в коде выше, граф применяется с помощью метода setHint().
Больше о графах в Hibernate есть тут (а также о типах графа fetch и load). В Spring по умолчанию используется тип графа FETCH.
Как сменить тип графа в Spring с FETCH на LOAD
Если вдруг тип Entity Graph по умолчанию (FETCH) не устраивает, то изменить тип можно так:
Entity Graph
Существуют две стратегии загрузки полей сущности: FetchType.EAGER и FetchType.LAZY. С помощью Entity Graph можно менять стратегию во время выполнения программы.
Модель
Продолжим эксперименты с нашей моделью (пост с тегами и картинками), только теперь над сущностью Post зададим @NamedEntityGraph:
@NamedEntityGraph
Каждая аннотация @NamedEntityGraph (а их может быть несколько) задает свою стратегию загрузки полей. Те поля, которые перечислены в attributeNodes получают fetch = FetchType.EAGER.
Как работает загрузка по умолчанию без Entity Graph
Известно, что по умолчанию коллекции загружаются лениво (FetchType.LAZY), то есть при выборке постов:
В консоли мы увидим select только из таблицы post (а tags и images не загружаются):
Теперь с Entity Graph
Если же использовать Entity Graph, то загрузятся еще и коллекции, которые упомянуты в графе в качестве атрибута.
Статический Entity Graph
Сначала используем граф post-entity-graph, который задали в аннотации.
В нем указано, что нужно загружать images, что и происходит:
Динамический Entity Graph
Но не обязательно задавать граф в аннотации, можно сформировать его на ходу. Создадим граф, загружающий теги, и выполним find():
Выше мы задали граф с атрибутом tags.
В консоли видно, что делается выборка не только из таблицы постов Post, но и тегов Post_tags:
До сих пор мы выполняли запросы методом find(). Теперь сделаем то же самое с помощью createQuery():
Как указать Entity Graph в Query
Как видите, граф мы указали в методе setHint().
Типы Entity Graph: fetch vs load
Стоит упомянуть еще о типах графа. До сих пор мы использовали Entity Graph типа fetch. Его конфигурация полностью переопределяет fetching strategy по умолчанию. Это значит, что если бы, например, в описании класса теги были аннотированы с помощью FetchType.EAGER:
то они все равно бы не загружались, если не упомянуты в графе.
Entity Graph же типа load дополняет стратегию по умолчанию. То есть не упомянутые в графе теги загружались бы все равно из-за FetchType.EAGER в описании класса.
Тип графа мы задавали в строках:
Для графа типа load было бы так:
Протестируем loadgraph. Для этого пометим коллекцию тегов (fetch = FetchType.EAGER):
А затем извлечем посты с loadgraph, при этом в граф не добавляем никаких атрибутов:
Несмотря на то, что атрибуты не добавлены в граф, они извлекаются:
Если добавить с тест строку, то загрузятся и теги, и images:
Подграфы
Entity Graph может быть сложным. Если загружаемая сущность Image в свою очередь тоже ссылается на какую-нибудь коллекцию colors или другую сущность, то для нее тоже можно задать вложенный Entity Graph:
Итоги
Код примера есть на GitHub.
Еще об Entity Graph в Spring Data.
Entity Graph: 6 комментариев
Относительно раздела 4 статьи.
Здесь [https://www.baeldung.com/jpa-entity-graph] в разделе 6.1 сказано, что помеченные как EAGER по атрибуты все же загружаются.
да, все верно, у меня также сказано: если пометить в Post коллекцию тегов как (fetch = FetchType.EAGER) и не упоминать теги в loadgraph, то они все равно загрузятся. Потому что loadgraph дополняет, а не перезаписывает FetchType.EAGER-атрибуты. Все EAGER, которые были в посте, остаются в loadgraph.
Пример с loadgraph добавлен.
Вот цитата из статьи где говорится о fetchgraph:
«…если бы, например, в описании класса теги были аннотированы с помощью FetchType.EAGER … то они все равно бы НЕ загружались, если не упомянуты в графе».
Но, насколько я понял из 6.1 [https://www.baeldung.com/jpa-entity-graph] (выделенное жирным шрифтом место), в Hibernate, при установленном режиме fetchgraph, атрибуты помеченные EAGER будут загружаться, даже если они не перечислены в EntityGraph-е.
А, про fetchgraph речь.
Да, действительно, у них сказано, что Hibernate (несмотря на спецификацию JPA) все равно загружает «attributes statically configured as EAGER» (поля с fetch = FetchType.EAGER, если правильно понимаю).
Но, насколько я тестирую с hibernate 5.5.7.Final, аннотация FetchType.EAGER не дает загрузки, если в fetchgraph поле не упомянуто. Только что проверено и для поля OneToMany в Post, и для ManyToOne в Image. И для ElementCollection.
Вот как. Интересное наблюдение. Наверное тогда loadgraph безопаснее использовать (по крайней мере в том кейсе которым я сейчас занимаюсь, с выключенным open session in view).
Spring Data JPA и именованные графы сущностей
Узнайте, как лучше управлять сущностями, которые вы хотите извлечь, используя Spring JPA.
1. Обзор
Проще говоря, Entity Graphs -это еще один способ описания запроса в JPA 2.1. Мы можем использовать их для формулирования более эффективных запросов.
В этом уроке мы узнаем, как реализовать графики сущностей с помощью Spring Data JPA на простом примере.
2. Сущности
Во-первых, давайте создадим модель под названием Элемент который имеет несколько характеристик:
Теперь давайте определим сущность C characteristic :
3. Графы Сущностей
В Spring Data JPA мы можем определить граф сущностей, используя комбинацию @NamedEntityGraph и @EntityGraph аннотаций . Или мы также можем определить специальные графы сущностей только с помощью аргумента attribute Paths аннотации @EntityGraph .
Давайте посмотрим, как это можно сделать.
3.1. С помощью @NamedEntityGraph
Во-первых, мы можем использовать аннотацию JPA @NamedEntityGraph непосредственно на нашем Item entity:
А затем мы можем прикрепить аннотацию @EntityGraph к одному из наших методов репозитория:
Таким образом, в нашем случае свойство characteristics будет загружаться с нетерпением, даже если стратегия выборки по умолчанию аннотации @OneToMany является ленивой.
Одна загвоздка здесь заключается в том, что если определенная стратегия fetch является НЕТЕРПЕЛИВОЙ, то мы не можем изменить ее поведение на ЛЕНИВОЕ . Это сделано специально, поскольку последующие операции могут нуждаться в нетерпеливо извлеченных данных на более позднем этапе выполнения.
3.2. Без @NamedEntityGraph
Или мы можем определить специальный граф сущностей to, width attribute Paths.
Это будет загружать свойство item объекта Characteristic с нетерпением, даже если наша сущность объявляет стратегию ленивой загрузки для этого свойства.
Это удобно, так как мы можем определить граф сущностей встроенным, а не ссылаться на существующий именованный граф сущностей.
4. Тестовый случай
Теперь когда мы определили наши графы сущностей давайте создадим тестовый случай для его проверки:
Давайте посмотрим на SQL, сгенерированный Hibernate:
Для сравнения давайте удалим аннотацию @EntityGraph из репозитория и проверим запрос:
Наконец, давайте сравним запросы Hibernate второго теста с аннотацией @EntityGraph :
И запрос без аннотации @EntityGraph :
5. Заключение
Hibernate — о чем молчат туториалы
Эта статья не будет затрагивать основы hibernate (как определить entity или написать criteria query). Тут я постараюсь рассказать о более интересных моментах, действительно полезных в работе. Информацию о которых я не встречал в одной месте. 
Сразу оговорюсь. Все ниже изложенное справедливо для Hibernate 5.2. Также возможны ошибки в силу того, что я что-то неправильно понял. Если обнаружите — пишите.
Проблемы отображения объектной модели в реляционную
Но начнем все же с основ ORM. ORM — объектно-реляционное отображение — соответственно у нас есть реляционная и объектная модели. И при отображении одной в другую существуют проблемы, которые нам нужно решить самостоятельно. Давайте их разберем.
Для иллюстрации возьмем следующий пример: у нас есть сущность “Пользователь”, который может быть либо джедаем либо штурмовиком. У джедая обязательно должна быть сила, а у штурмовика специализация. Ниже приведена диаграмма классов.
Проблема 1. Наследование и полиморфные запросы.
В объектной модели есть наследование, а в реляционной нет. Соответственно это и первая проблема — как правильно отобразить наследование в реляционную модель.
Hibernate предлагает 3 варианта ее отображения такой объектной модели:
В этом случае, общие поля и поля наследников лежат в одной таблице. Используя такую стратегию мы избегаем join-ов при выборе сущностей. Из минусов стоит отметить, что во-первых, мы не можем в реляционной модели задать “NOT NULL” ограничение для колонки “force” и во-вторых, мы теряем третью нормальную форму. (появляется транзитивная зависимость неключевых атрибутов: force и disc).
Кстати, в том числе и по этой причине есть 2 способа указать not null ограничение у поля — NotNull отвечает за валидацию; @Column(nullable = true) — отвечает за not null ограничение в базе данных.
В этом случае у нас нет общей таблицы. Используя эту стратегию, при полиморфных запросах мы используется UNION. У нас появляеются проблемы с генераторами первичных ключей и другими ограничениями целостности. Данный тип отображения наследования строго не рекомендуется использовать.
На всякий случай упомяну про аннотацию — @MappedSuperclass. Она используется когда вы хотите “спрятать” общие поля для нескольких сущностей объектной модели. При этом сам аннотированный класс не рассматривается как отдельная сущность.
Проблема 2. Отношение композиции в ООП
Возвращаясь к нашему примеру заметим, что в объектной модели мы вынесли профиль пользователя в отдельную сущность — Profile. Но в реляционной модели мы не стали выделять под нее отдельную таблицу.
Отношение OneToOne чаще является плохой практикой, т.к. в селекте у нас появляется неоправданный JOIN (даже указав fetchType=LAZY в большинстве случаев у нас JOIN останется — эту проблему обсудим позже).
Для отображения композиции в общую таблицу существуют аннотации @Embedable и @Embeded. Первая ставится над полем, а вторая над классом. Они взаимозаменяемые.
Entity Manager
Каждый экземпляр EntityManager-а (EM) определяет сеанс взаимодействия с базой данных. В рамках экземпляра EM-а, существует кэш первого уровня. Тут я выделю следующие значимые моменты:
Под операцией flush скрывается интересная фича hibernate — он пытается снизить время блокировки строк в БД.
Dirty Checking — это механизм, выполняемый во время операции flush. Его цель найти сущности, которые изменились и обновить их. Чтобы реализовать такой механизм, hibernate должен хранить оригинальную копию объекта (то с чем будет сравниваться актуальный объект). Если быть точнее, то hibernate хранит копию полей объекта, а не сам объект.
Тут стоит отметить, что если граф сущностей большой, то операция dirty checking-а может стоить дорого. Не стоит забывать о том, что hibernate хранит 2 копии сущностей (грубо говоря).
С целью “удешевить” этот процесс пользуйтесь следующими фичами:
Как известно hibernate позволяет обновлять сущности только внутри транзакции. Больше свободы предлагают операции чтения — их мы можем выполнять не открывая явно транзакцию. Но в этом как раз и вопрос, стоит ли для операций чтения открывать транзакцию явно?
Приведу несколько фактов:
Генераторы
Генераторы нужны для описания, каким способом первичные ключи наших сущностей будут получать значения. Давайте быстро пробежимся по вариантам:
Deadlock
Давайте разберем на примере псевдокода ситуацию, которая может привести к deadlock-у:
Для предотвращения таких проблем у hibernate есть механизм, который позволяет избежать deadlock-ов такого типа — параметр hibernate.order_updates. В этом случае все update-ы будут упорядочены по id и выполнены. Также еще раз упомяну, что hibernate старается “отсрочить” захват коннекшена и выполнение insert-ов и update-ов.
Set, Bag, List
В hibernate есть 3 основных способа представить коллекцию связи OneToMany.
Возникает вопрос, а что все-таки лучше использовать bag или set? Начнем с того, что при использовании bag-а возможны следующие проблемы:
Сила References
Reference — это ссылка на объект, загрузку которого мы решили отложить. В случае отношения ManyToOne с fetchType=LAZY, мы получаем такой reference. Инициализация объекта происходит в момент обращения к полям сущности, за исключением id (т.к. значение этого поля нам известно).
Стоит отметить, что в случае Lazy Loading-а reference всегда ссылается на существующую строку в БД. Именно по этой причине большинство случаев Lazy Loading-а в отношениях OneToOne не работает — hibernate необходимо сделать JOIN для проверки существования связи и JOIN уже был, то hibernate загружает его в объектную модель. Если же мы укажем в OneToOne связи nullable=true, то LazyLoad должен заработать.
Мы можем и самостоятельно создать reference, используя метод em.getReference. Правда в таком случае нет гарантии, что reference ссылается на существующую строку в БД.
Давайте приведем пример использования такой ссылки:
На всякий случай напомню, что мы получим LazyInitializationException в случае закрытого EM-а или отсоединенной(detached) ссылки.
Дата и время
Не смотря на то что в java 8 появилось прекрасное API для работы с датой и временем, JDBC API по прежнему позволяет работать только со старым API дат. Поэтому разберем некоторые интересные моменты.
Во-первых, нужно четко понимать отличия LocalDateTime от Instant и от ZonedDateTime. (Не буду растягивать, а приведу отличные статьи на эту тему: первая и вторая)
Более интересный и важный момент — как даты сохраняется в базу данных. Если у нас проставлен тип TIMESTAMP WITH TIMEZONE то проблем быть не должно, если же стоит TIMESTAMP (WITHOUT TIMEZONE) то есть вероятность, что дата запишется/прочитается неверная. (за исключением LocalDate и LocalDateTime)
Давайте разберемся почему:
Когда мы сохраняем дату, используется метод со следующей сигнатурой:
Как видим тут используется старое API. Дополнительный аргумент Calendar нужен для того, чтобы преобразовать timestamp в строковое представление. т.е он хранит в себе timezone-у. Если Calendar не передается, то используется Calendar по-умолчанию с таймзоной JVM.
Решить эту проблему можно 3 способами:
Для ответа на этот вопрос нужно понимать структуру класса java.util.Date (java.sql.Date и java.sql.Timestamp его наследники и их отличия в данном случае нас не волнуют). Date хранит дату в миллисекундах c 1970 года грубо говоря в UTC, но метод toString преобразует дату согласно системной timeZone.
Соответственно, когда мы получаем из базы данных дату без таймзоны, она отображатеся в объект Timestamp, так чтобы метод toString отобразил ее желаемое значение. При этом количество миллисекунд с 1970-го года может отличаться (в зависимости от временной зоны). Именно поэтому только локальное время отображается всегда корректно.
Также привожу в пример код, ответственный за преобразование Timesamp в LocalDateTime и Instant:
Batching
По-умолчанию запросы отправляются в БД по одному. При включении batching-а hibernate сможет в одном запросе к БД отправлять несколько statement-ов. (т.е. batching сокращает количество round-trip-ов к БД)
Для этого необходимо:
N+1 проблема
Это достаточно изъезженная тема, поэтому пробежимся по ней быстро.
N+1 проблема — это ситуация, когда вместо одного запроса на выбор N книг происходит по меньшей мере N+1 запрос.
Самый простой способ решения N+1 проблемы это сделать fetch связанных таблиц. В этом случае у нас может возникнуть несколько других проблем:
Тестирование
В идеале development окружение должно предоставлять как можно больше полезной информации о работе hibernate и о взаимодействии с БД. А именно:
JPA Entity Graphs
Одной из последних функций в JPA 2.1 является возможность задавать планы выборки с использованием графов объектов. Это полезно, поскольку позволяет настраивать данные, полученные с помощью запроса или операции поиска. При работе с приложениями среднего и большого размера распространено отображение данных из одной и той же сущности разными и разными способами. В других случаях вам просто нужно выбрать наименьший набор информации для оптимизации производительности вашего приложения.
пример
Рассмотрим следующий граф сущностей:
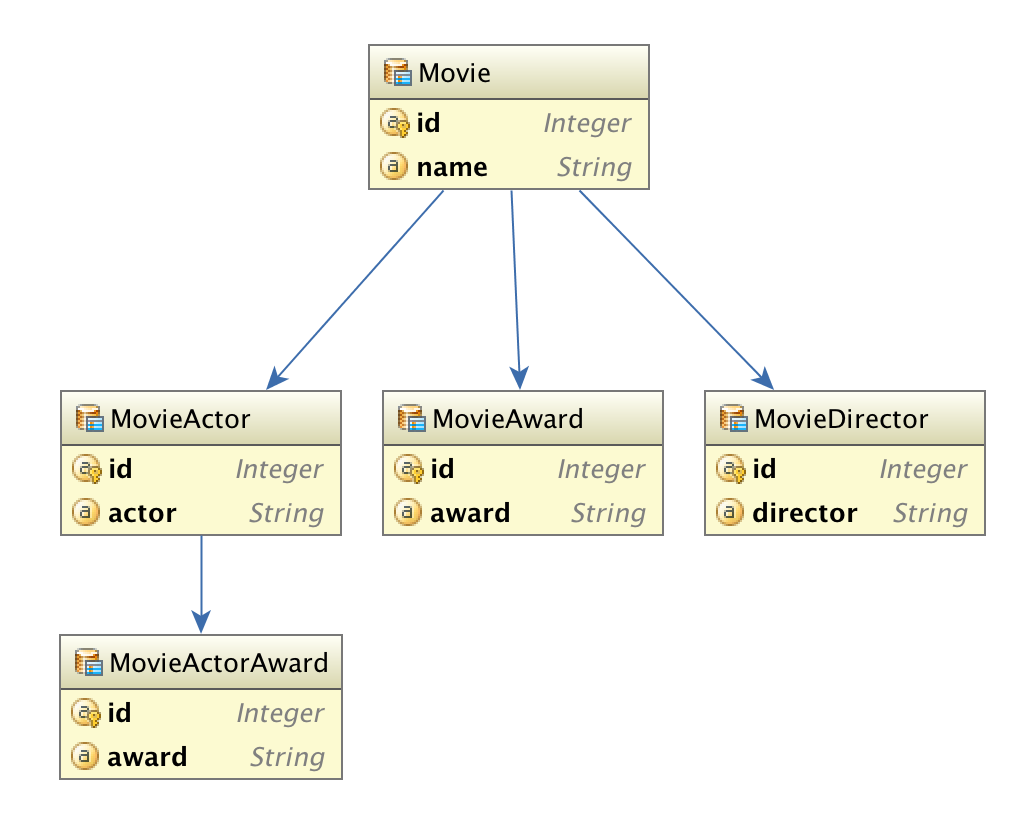
(Вероятно, отношения должны быть от N до N, но давайте сделаем это проще).
А у сущности Кино есть следующее определение:
Аннотации
Entity Graph фильмWithActors
Это определяет Entity Graph с именем movieWithActors и указывает, что отношение movieActors должно быть загружено.
Entity Graph фильмWithActorsAndAwards
Обратите внимание, что мы не указываем атрибут id в графе сущностей. Это потому, что первичные ключи всегда выбираются независимо от того, что указано. Это также верно для атрибутов версии.
Советы
Чтобы использовать графы сущностей, определенные в запросе, вы должны установить их как подсказку. Вы можете использовать два свойства подсказки, и они также влияют на способ загрузки данных.
Для упрощения и на основе нашего примера при применении Entity Graph movieWithActors :
| По умолчанию / указано | javax.persistence.fetchgraph | javax.persistence.loadgraph | |
|---|---|---|---|
| movieActors | LAZY | EAGER | EAGER |
| movieDirectors | EAGER | LAZY | EAGER |
| movieAwards | LAZY | LAZY | LAZY |
запрос
Выполнить запрос легко. Вы делаете это, как обычно, но просто вызываете setHint для объекта Query :



