Сделай сам: SQL JOIN на Java

Постановка задачи
Людям, которые утверждают, что много и плотно работали с SQL, я задаю на собеседованиях вот такую задачу.
Есть SQL команда
Нужно выполнить то же самое на Java, т.е. реализовать метод
Я не прошу прям закодить реализацию, но жду хотя бы устного объяснения алгоритма.
Дополнительно я спрашиваю, что нужно изменить в сигнатуре и реализации, чтобы сделать вид, что мы работаем с индексами.
Nested Loops Join
Самый базовый алгоритм объединения двух списков сейчас проходят в школах. Суть очень простая — для каждого элемента первого списка пройдемся по всем элементам второго списка; если ключи элементов вдруг оказались равны — запишем совпадение в результирующую таблицу. Для реализации этого алгоритма достаточно двух вложенных циклов, именно поэтому он так и называется.
Основной плюс этого метода — полное безразличие к входным данным. Алгоритм работает для любых двух таблиц, не требует никаких индексов и перекладываний данных в памяти, а также прост в реализации. На практике это означает, что достаточно просто бежать по диску двумя курсорами и периодически выплёвывать в сокет совпадения.
Однако ж, фатальный минус алгоритма — высокая временная сложность O(N*M) (квадратичная асимптотика, если вы понимаете, о чем я). Например, для джойна пары небольших таблиц в 100к и 500к записей потребуется сделать аж 100.000 * 500.000 = 50.000.000.000 (50 млрд) операций сравнения. Запросы с таким джойном будут выполняться невежливо долго, часто именно они — причина беспощадных тормозов кривеньких самописных CMS’ок.
Современные РСУБД используют nested loops join в самых безнадежных случаях, когда не удается применить никакую оптимизацию.
UPD. zhekappp и potapuff поправляют, что nested loops эффективен для малого числа строк, когда разворачивать какую-либо оптимизацию выйдет дороже, чем просто пробежаться вложенным циклом. Есть класс систем, для которых это актуально.
Hash Join
Если размер одной из таблиц позволяет засунуть ее целиком в память, значит, на ее основе можно сделать хеш-таблицу и быстренько искать в ней нужные ключи. Проговорим чуть подробнее.
Проверим размер обоих списков. Возьмем меньший из списков, прочтем его полностью и загрузим в память, построив HashMap. Теперь вернемся к большему списку и пойдем по нему курсором с начала. Для каждого ключа проверим, нет ли такого же в хеш-таблице. Если есть — запишем совпадение в результирующую таблицу.
Временная сложность этого алгоритма падает до линейной O(N+M), но требуется дополнительная память.
Что важно, во времена динозавров считалось, что в память нужно загрузить правую таблицу, а итерироваться по левой. У нормальных РСУБД сейчас есть статистика cardinality, и они сами определяют порядок джойна, но если по какой-то причине статистика недоступна, то в память грузится именно правая таблица. Это важно помнить при работе с молодыми корявыми инструментами типа Cloudera Impala.
Merge Join
А теперь представим, что данные в обоих списках заранее отсортированы, например, по возрастанию. Так бывает, если у нас были индексы по этим таблицам, или же если мы отсортировали данные на предыдущих стадиях запроса. Как вы наверняка помните, два отсортированных списка можно склеить в один отсортированный за линейное время — именно на этом основан алгоритм сортировки слиянием. Здесь нам предстоит похожая задача, но вместо того, чтобы склеивать списки, мы будем искать в них общие элементы.
Итак, ставим по курсору в начало обоих списков. Если ключи под курсорами равны, записываем совпадение в результирующую таблицу. Если же нет, смотрим, под каким из курсоров ключ меньше. Двигаем курсор над меньшим ключом на один вперед, тем самым “догоняя” другой курсор.
Если данные отсортированы, то временная сложность алгоритма линейная O(M+N) и не требуется никакой дополнительной памяти. Если же данные не отсортированы, то нужно сначала их отсортировать. Из-за этого временная сложность возрастает до O(M log M + N log N), плюс появляются дополнительные требования к памяти.
Outer Joins
Вы могли заметить, что написанный выше код имитирует только INNER JOIN, причем рассчитывает, что все ключи в обоих списках уникальные, т.е. встречаются не более, чем по одному разу. Я сделал так специально по двум причинам. Во-первых, так нагляднее — в коде содержится только логика самих джойнов и ничего лишнего. А во-вторых, мне очень хотелось спать. Но тем не менее, давайте хотя бы обсудим, что нужно изменить в коде, чтобы поддержать различные типы джойнов и неуникальные значения ключей.
Первая проблема — неуникальные, т.е. повторяющиеся ключи. Для повторяющихся ключей нужно порождать декартово произведение всех соответствющих им значений.
В Nested Loops Join почему-то это работает сразу.
В Hash Join придется заменить HashMap на MultiHashMap.
Для Merge Join ситуация гораздо более печальная — придется помнить, сколько элементов с одинаковым ключом мы видели.
Работа с неуникальными ключами увеличивает асимптотику до O(N*m+M*n), где n и m — среднее записей на ключ в таблицах. В вырожденном случае, когда n=N и m=M, операция превращается в CROSS JOIN.
Вторая проблема — надо следить за ключами, для которых не нашлось пары.
Для Merge Join ключ без пары видно сразу для всех направлений JOIN’а.
Для Hash Join сразу можно увидеть нехватку соответствующих ключей при джойне слева. Для того, чтобы фиксировать непарные ключи справа, придется завести отдельный флаг “есть пара!” для каждого элемента хеш-таблицы. После завершения основного джойна надо будет пройти по всей хеш-таблице и добавить в результат ключи без флага пары.
Для Nested Loops Join ситуация аналогичная, причем все настолько просто, что я даже осилил это закодить:
Морализаторское послесловие
Если вы дочитали досюда, значит, статья показалась вам интересной. А значит, вы простите мне небольшую порцию нравоучений.
Я действительно считаю, что знания РСУБД на уровне SQL абсолютно не достаточно, чтобы считать себя профессиональным разработчиком ПО. Профессионал должен знать не только свой код, но и примерное устройство соседей по стеку, т.е. 3rd-party систем, которые он использует — баз данных, фреймворков, сетевых протоколов, файловых систем. Без этого разработчик вырождается до кодера или оператора ЭВМ, и в по настоящему сложных масштабных задачах становится бесполезен.
UPD. Несмотря на это послесловие, статья, на самом деле, про JOIN’ы.
Дополнительные материалы
Disclaimer: вообще-то, я обещал еще одну статью про Scalding, но предыдущая не вызвала большого интереса у публики. Из-за этого тему решено было сменить.
Визуализируем и разбираемся с Hash Match Join
Этот пост является третьей частью серии, посвященной операторам соединения (обязательно прочитайте часть 1 — nested loops joins, и часть 2 — merge joins). Перевод статьи подготовлен специально для студентов курса «MS SQL Server разработчик».
Hash Match Joins — это надежные рабочие лошадки физических операторов соединения.
В то время как Nested Loops Join завершится неудачей, если данных будет слишком много для того, чтобы поместить их в память, а Merge Join потребует, чтобы входные данные были отсортированы, Hash Match соединит любые данные, которые вы подадите на вход (при условии что для соединения выполняется предикат равенства и пока в вашем tempdb достаточно свободного места).
Алгоритм hash match состоит из двух этапов, которые работают следующим образом:
Во время первого этапа «Build» (построение), SQL Server создает в памяти хеш-таблицу из одной из таблиц, поданных на вход (обычно наименьшей из двух). Хеши вычисляются на основе ключей входных данных и затем сохраняются вместе со строкой в хеш-таблице в соответствующий блок. В большинстве случаев в каждом блоке имеется только одна строка данных, кроме случаев, когда:
После создания хеш-таблицы, начинается этап «Probe» (проверка). На втором этапе SQL Server вычисляет хэш ключа для каждой строки во второй входной таблице и проверяет, существует ли он в хеш-таблице, созданной на первом этапе. Если находится совпадение для этого хеша, то проверяется, действительно ли совпадают ключи строки (строк) в хеш-таблице и строки из второй таблицы (эту проверку необходимо выполнять из-за возможных коллизий).
Распространенный вариант алгоритма hash match возникает, когда на этапе построения не удается создать хеш-таблицу, которая может быть полностью сохранена в памяти:
Это происходит, когда данных больше, чем может быть размещено в памяти, или когда SQL Server предоставляет недостаточно памяти для hash match соединения.
Когда у SQL Server не хватает памяти для хранения хэш-таблицы на этапе построения, он продолжает работать, сохраняя некоторые блоки в памяти, а другие блоки помещая в tempdb.
На этапе проверки SQL Server соединяет строки данных из второй таблицы в блоки из этапа построения, находящиеся в памяти. Если блок, которому эта строка потенциально соответствует, в данный момент отсутствует в памяти, SQL Server записывает эту строку в tempdb для последующего сравнения.
Когда совпадения для одного блока завершены, SQL Server очищает эти данные из памяти и загружает следующие блоки в память. Затем он сравнивает строки второй таблицы (в настоящее время находящиеся в tempdb) с новыми блоками в памяти.
Как и в случае с каждым оператором физического соединения в этой серии, подробности об операторе hash match можно найти в справке Хьюго Корнелиса (Hugo Kornelis) о hash match.
Что показывает Hash Match Join?
Знание внутренних особенностей того, как работает hash match join, позволяет нам определить, что оптимизатор думает о наших данных и вышестоящих операторах соединения, помогая нам сосредоточить усилия на настройке производительности.
Вот несколько сценариев, которые следует рассмотреть в следующий раз, когда вы увидите, что hash match join используется в вашем плане выполнения:
Спасибо за то, что прочитали статью. Вам также может понравиться мой Twitter.
Мы касались этой темы на предыдущем открытом уроке. Ждем ваши комментарии!
Soft — Consulting
Построение запросов (ORACLE)
Оглавление:
Структуры данных для примеров.
Рекомендации по оптимизации запросов
Данные рекомендации взяты мной из руководства Oracle по настройке базы данных, со временем они практически не меняются, посмотреть их можно здесь, это глава 11.5. Ссылка может не работать, все зависит от того, как долго Oracle решит хранить этот фрагмент документации в интернете.
Не используйте SQL-функции в предикатах. Любое выражение в котором используется колонка (expression), например функция, использующая колонку, как аргумент, приведет к тому, что индекс для данной колонки (если он есть) использоваться не будет, даже если это уникальный индекс. Хотя, если для колонки имеется составной индекс (function-based) на основе применяемой в предикате функции, то он может быть использован.
где numexpr выражение числового типа, то Oracle преобразует ваше условие в:
и индекс использован не будет.
Где по числовой колонке numcol построен индекс.
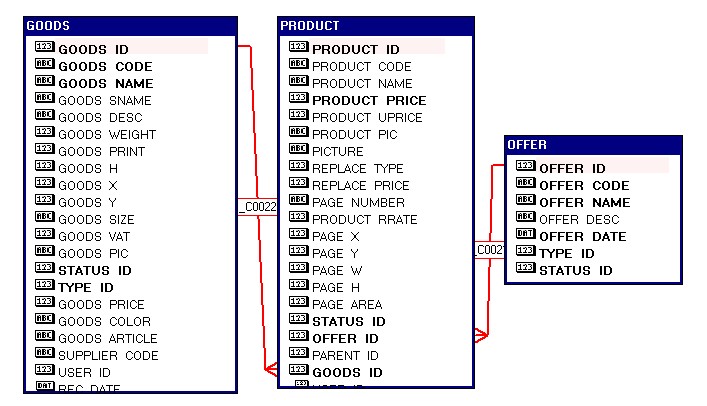
План запроса.
Практически любую задачу по получению каких-либо результатов из базы данных можно решить несколькими способами, т.е. написать несколько разных запросов, которые дадут один и тот же результат. Это, однако не означает, что база данных эти запросы будет выполнять по-разному. Также неверно мнение о том, что структура запроса может повлиять на то, как Oracle будет его выполнять, это касается порядка временных таблиц, JOINS и условий отбора в WHERE. Решение о том, как построить запрос принимает оптимизатор Oracle. Алгоритм получения сервером данных для конкретного запроса называют планом запроса.
Практически все продукты для работы с базой данных Oracle позволяют просмотреть план конкретного запроса. Так как слушатели этих лекций используют PL/SQL Developer, то для получения плана запроса в нем необходимо сделать следующее:
Существует стандартный механизм получения плана запроса. Для этого используется конструкция (команда) EXPLAIN PLAN FOR:
План запроса будет выведен в виде таблицы с одним полем, выглядит он так:
План всегда имеет иерархическую структуру. Операция соединения результирующих наборов оперирует парами дочерних операций. Операция получения данных может использовать вспомогательную операцию, такую, например, как сканирование индекса.
Данные результирующих наборов получаются в порядке следования этих наборов в плане запроса. Операция получения данных результирующего набора может состоять из нескольких шагов, которые характеризуются глубиной операции (колонка Depth).
При анализе плана в первую очередь необходимо обращать внимание на способы, с помощью которых получены данные результирующих наборов.
Некоторые термины в плане запроса.
План запроса имеет форму таблицы, один из столбцов которой описывает тип производимых сервером операций. Вот некоторые из них, которые встречаются наиболее часто:
Анализ плана запроса.
При анализе плана запроса вам необходимо примерно представлять объемы записей в таблицах и наличие у них индексов, которые могут пригодиться при фильтрации записей. Для доступа к данным Oracle использует несколько стратегий, какие из них выбраны для каждой из таблиц можно понять из плана запроса. При просмотре плана, вам необходимо решить, правильная ли выбрана стратегия в том или ином случае. Ниже приведены краткие описания способов доступа и механизмов отбора записей при соединениях результирующих наборов.
Full Table Scan (Table Access Full).
Может показаться, что доступ к данным таблицы быстрее осуществлять через индекс, но это не так. Иногда дешевле прочитать всю таблицу целиком, чем прочитать, например, 80% записей таблицы через индекс, так как чтение индекса тоже требует ресурсов. Очень не желательна ситуация, когда эта операция стоит первой в объединении наборов записей и таблица, которая читается полностью, большая. Еще хуже ситуация с большой таблицей на второй позиции в объединении, это означает, что она также будет прочитана полностью, как минимум, один раз, а если объединение производится через NESTED LOOPS, то таблица будет читаться несколько раз, поэтому запрос будет работать очень долго.
Nested Loops.
Такое соединение может использоваться оптимизатором, когда небольшой основной набор записей (стоит первым в плане запроса) объединяется с помощью условия, позволяющего эффективно выбрать записи из второго набора. Важным условием успешного использования такого соединения является наличие связи между основным и второстепенным набором записей. Если такой связи нет, то для каждой записи в первом наборе, из второго набора будут извлекаться одни и те же записи, что может привести к значительному увеличению времени запроса. Если вы видите, что в плане запроса применен NESTED LOOPS, а соединяемые наборы не удовлетворяют этому условию, то налицо ошибка.
Hash Joins.
Используется при соединении больших наборов данных. Оптимизатор использует наименьший из наборов данных для построения в памяти хэш-таблицы по ключу соединения. Затем он сканирует большую таблицу, используя хэш-таблицу для нахождения записей, которые удовлетворяют условию объединения.
Оптимизатор использует HASH JOIN, если наборы данных соединяются с помощью операторов и ключевых слов эквивалентности (=, AND) и если присутствует одно из условий:
■ Необходимо соединить наборы данных большого объема.
■ Большая часть небольшого набора данных должна быть использована в соединении.
Sort Merge Join.
Данное соединение может быть применено для независимых наборов данных. Обычно Oracle выбирает такую стратегию, если наборы данных уже отсортированы ранее, и если дальнейшая сортировка результата соединения не требуется. Обычно это имеет место для наборов, которые соединяются с помощью операторов , >=. Для этого типа соединения нет понятия главного и вспомогательного набора данных, сначала оба набора сортируются по общему ключу, а затем сливаются в одно целое. Если какой-то из наборов уже отсортирован, то повторная сортировка для него не производится.
Cartesian Joins.
Это соединение используется, когда одна и более таблиц не имеют никаких условий соединения с какой-либо другой таблицей в запросе. В этом случае произойдет объединение каждой записи из одного набора данных с каждой записью в другом. Такое соединение может быть выбрано между двумя небольшими таблицами, а в дальнейшем этот набор данных будет соединен с другой большой таблицей. Наличие такого соединения может обозначать присутствие серьезных проблем в запросе, особенно, если соединяемые таблицы по MERGE JOIN CARTESIAN. В этом случае, возможно, упущены дополнительные условия соединения наборов данных.
Хинты.
Хинт — это ключевое слово, иногда с набором параметров, которое может повлиять на оптимизатор при составлении плана запроса. Другими словами, с помощью хинтов вы можете попытаться изменить способ с помощью которого будут получены или обработаны данные (хинты есть не только у операторов SELECT).
Если у вас есть желание более детально ознакомиться с хинтами, то я рекомендовал бы вам просмотреть эту статью.
Использование хинтов.
Хинт ставится после ключевого слова, которое определяет некую цельную конструкцию запроса, в данном разделе речь пойдет о хинтах в запросах к данным, т.е. тех, которые оформляются оператором SELECT и ключевых словах, используемых в сочетании с ним. Хинт указывается в закрытом комментарии после оператора:
В данном примере используется хинт RULE.
Этот хинт официально не поддерживается с версии Oracle 10G. При его успешном применении включается оптимизация по определенным правилам (RBO — Rule Based Optimization). Данный хинт может быть полезен, если у вас сложный запрос с неэффективным планом выполнения и использование других хинтов может занять время, которого мало. Если в запросе не пропущены какие-то JOINS или условия и вы считаете, что он написан верно, то есть достаточно большая вероятность, что RBO построит верный план.
В 11G этот хинт пока работает с некоторыми ограничениями, важны для практической работы следующие:
■ В запросе не должны использоваться другие хинты.
■ Не должен использоваться синтаксис ANSI (left join | full outer join …)
FIRST_ROWS.
Данный хинт дает указание оптимизатору выбрать такой план запроса при котором первые записи результатов будут получены максиально быстрым способом. Хорош при отладке запроса, чтобы убедиться, что выдается то, что необходимо. Если предполагается, что запрос вернет много записей, то при использовании такого хинта он может работать дольше.
ORDERED / LEADING.
При использовании этого хинта оптимизатор соединяет наборы данных в том порядке, в каком они следуют после оператора FROM. Вот пример разных последовательностей:
Порядок наборов данных необходимо выбирать аккуратно, чтобы соединяемые объекты имели какое-то условие связи в WHERE или после ключевого слова ON. Например в приведенном выше примере 4 версия списка во FROM приведет к перемножению таблиц GOODS и OFFER, так как они не связаны друг с другом условиями.
Данный хинт часто бывает полезен, если статистика по таблицам не собрана, план запроса не верный, и вам точно известно, как должны соединяться таблицы. При использовании данного хинта старайтесь выстроить порядок соединения так, чтобы тяжесть обработки данных следовала в сторону увеличения, т.е. сначала соедините наборы поменьше или с хорошими условиями отбора, чтобы результат их соединения был наименьшим по количеству записей, затем подключайте наборы данных большего размера.
Более удобен в использовании хинт LEADING. Он позволяет соединить наборы данных в порядке перечисления их (или их алиасов) в списке аргументов хинта:
MATERIALIZE.
Дает указание оптимизатору построить временную таблицу (материализовать результаты) для запроса, к которому этот хинт применяется, работает только в конструкции WITH. Очень полезен при обработке больших объемов данных, так как позволяет разбить запрос на части, в этом случае улучшается читабельность запроса, а также может быть получен правильный план. Пример использования:
План запроса выглядит так:
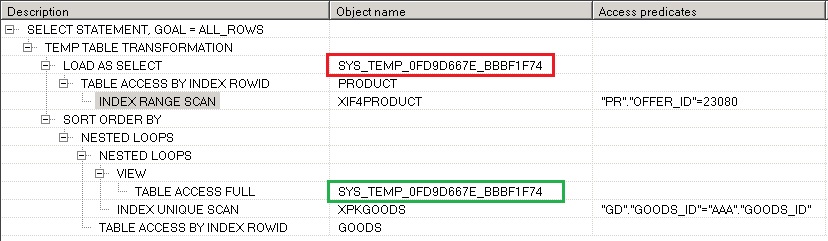
Красным цветом помечена таблица при ее создании, зеленым ее использование в соединении.
INDEX.
Дает указание оптимизатору использовать индекс при чтении данных из таблицы. Полезен тем, что может предотвратить чтение всего содержимого таблицы, если вы считаете, что этого делать не нужно. Пример использования:
Этот хинт сработает в том случае, если у таблицы есть указываемый индекс, и его можно использовать на основе одного или нескольких условий при получении данных таблицы. В приведенном примере в составе индекса есть поле OFFER_ID на второй позиции и он может быть использован, план запроса выглядит в этом случае так:

Комбинации хинтов.
Использование комбинации хинтов допустимо. Нужный эффект можно получить, если хинты в одном запросе не протеворечат друг другу. При записи хинты разделяются пробелами:
В данном примере используется хинт для установки порядка соединения наборов данных и способа доступа к таблице, противоречия в их использовании нет.
Скахин Алексей / pihel
Личный блог. Заметки о программировании и не только
Страницы
суббота, 3 декабря 2016 г.
Oracle: реализация hash соединения
1. Открытая адресация
 Коллизии размещаются в томже хэш массиве, но смещаются вправо, пока не найдется свободное место.
Коллизии размещаются в томже хэш массиве, но смещаются вправо, пока не найдется свободное место.
Пример:
Массив из элементов: 1, 11, 2, 3
Хэширующая функция: остаток от деления на 10
Результирующий хэш массив:
Реализацию на java можно посмотреть здесь.
2. Метод цепочек
 Хэш таблица содержит список коллизий. Число элементов хэш таблицы фиксировано = числу различных вариантов хэширующей функции.
Хэш таблица содержит список коллизий. Число элементов хэш таблицы фиксировано = числу различных вариантов хэширующей функции.
Пример на том же массиве и той же хэширующей функции:
3. Метод красно-черного дерева
В случае большого числа коллизий, когда все элементы попадают в одну хэш секцию, для хранения данных секции целесообразно использовать красно-черное дерево, замен списка во 2 методе. В этом случае поиск элемента будет осуществляться за логарифмическое время, вместо линейного в списке.
 Слева графически представлен механизм поиска в хэш таблице Oracle.
Слева графически представлен механизм поиска в хэш таблице Oracle.
Изменения в реализации хэш таблиц Oracle:
* Хэш таблица над таблицей бд может быть сколь угодно большой и она может не поместиться в памяти
* битовая карта над данными в хэш таблице, если соответствующий бит таблицы установлен, то элемент есть в хэш таблице, иначе строку можно даже не искать.
Когда Oracle выбирает соединение хэшированием:
В основе выбора способ лежит стоимостная оценка:
Стоимость соединения вложенными циклами (NL) = стоимость получения T1 + кардинальность Т1 * Стоимость одного обращения к Т2
Стоимость соединения хэшированием (hash) = стоимость получения Т1 + стоимость получения Т2 + стоимость хэширования и сравнения.
Когда hash join не может быть использован:
* Поиск по диапазону (или любой операции отличной от = ) не применим для хэш таблицы, результат функции дает непоследовательные данные, которые не просканировать последовательно.
* При добавлении элемента происходит дополнительная проверка на доступность памяти в hash_area для нового элемента: HashEntryHolder.addCnt()
Если места нет, то элемент пишется на диск:
3. Поиск элемента в хэш таблице:
* В первую очередь тестируем элемент на наличии в битовом массиве, без обращения к хэш таблице bitmap[getBitmapHash(key)
* Если элемент найден в битовом массиве и хэш секция находится в памяти, то ищем элемент в хэш массиве.
Если элементов с таким значеним несколько, то возвращается список этих элементов ValueList:
Дальнейший алгоритм не реализовался и описывается на словах:
* Если хэш секция не находится в памяти, то искомый элемент правой таблицы пропускается и добавляется в новую хэш таблицу для правой таблицы.
* И так до конца правой таблицы. В итоге после первого прохода мы имеем 2 хэш таблицы левой и правой таблицы. Oracle знает полное распределение данных в обоих частях.
* На основе этих данных хэш таблица для поиска, которая может целиком поместиться в памяти выбирается как из левой, так и из правой таблицы.
Также при следующих проходах не нужно считывать правую таблицу целиком, можно взять только соответствующую секцию из правой.
Более сложный механизм, когда ни одна секция не помещается в памяти, алгоритм еще сильней усложняется, т.к. чтобы проверить наличие элемента в левой секции ее так или иначе надо считать целиком в память, хоть и последовательно. Описание алгоритма: Основы стоимостной оптимизации join
Полную реализацию Oracle Hash можно посмотреть на github



