Hibernate для начинающих
Я сталкивался (да и не только я) с проблемой развертывания Hibernate и решил попробовать осветить данную тему. Hibernate — это популярный framework, цель которого связать ООП и реляционную базу данных. Работа с Hibernate сократит время разработки проекта в сравнении с обычным jdbc.
Потом в pom.xml вставляем. Нам понадобятся две зависимости: hibernate-core и mysql-connector, но если вы хотите больше функционала — вы должны подключить больше зависимостей.
Существуют стандартные рекомендации подключать зависимости по отдельности, но я так не делаю.
И щелкаем на Import Changes Enable Auto-Import, автоматически импортируя изменения.

Подключаемся к базе данных, которая развернута на локальном компьютере, выбираем поставщика баз данных MySQL.
Вводим имя базы данных, имя пользователя и пароль. Протестируйте соединение.
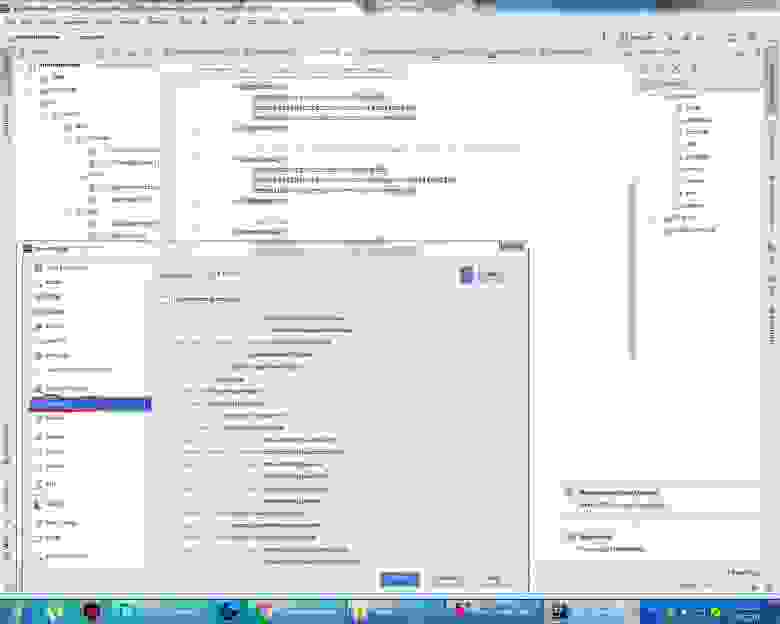
Выбираем проект и через framework support просим у хибернейта создать за нас Entity файлы и классы с Getter и Setter.
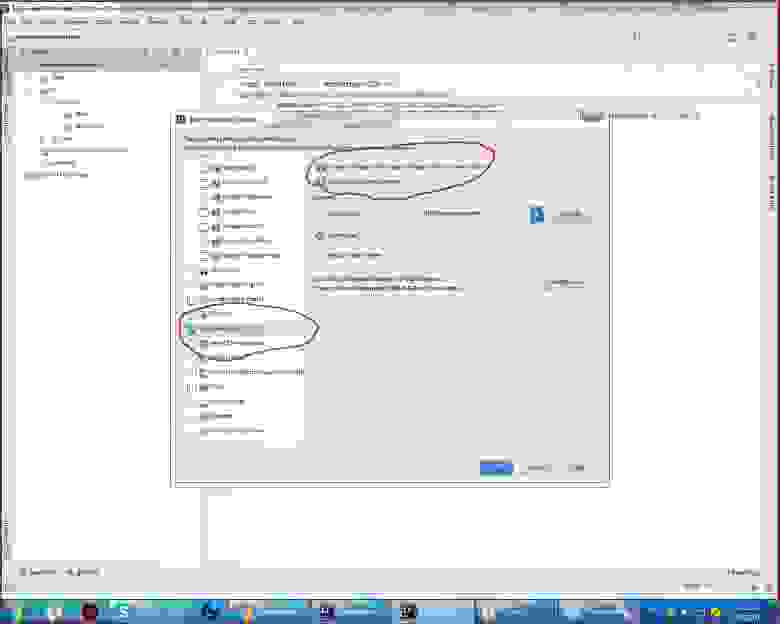
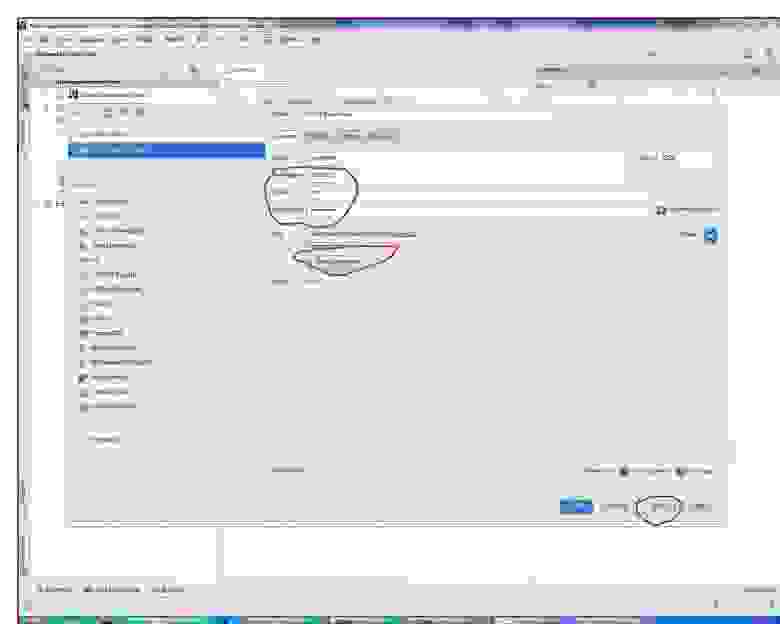
Выбираем Generate Persistence Mapping через кладку Persistence, выбираем jenerate Persistance Mapping, а в появившемся окне прописываем схему базы данных, выбираем prefix и
sufix к автоматически сгенерированным названиям. Будут сгенерированы названия xml файлов и классов с аннотациями:
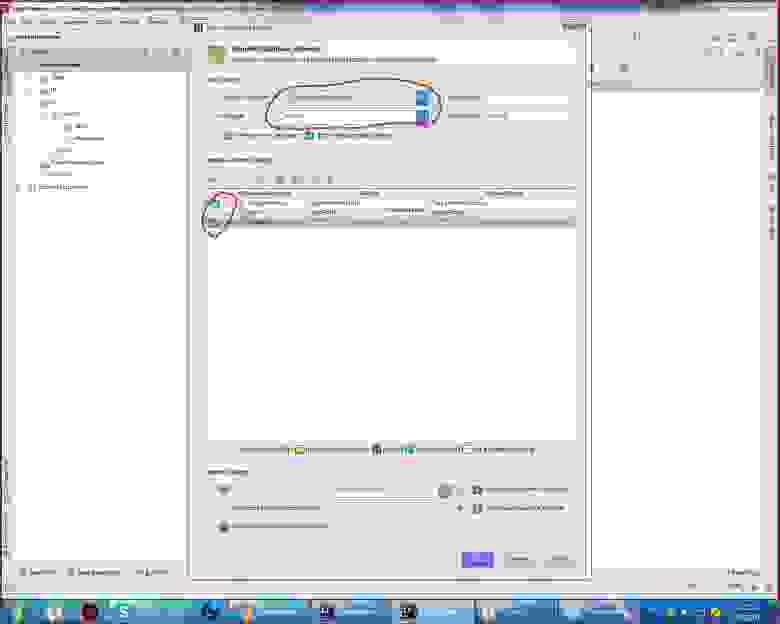
Дописываем в hibernate.cfg username и password (звёзды поставил я, а так пишите обычным шрифтом).

Вот и все! Дальше через класс main запускаем проект.
Это моя первая статья. Рассчитываю на здравую критику.
Основы Hibernate

Хочу начать со слов благодарности тому человеку, который мне вчера накинул кармы, позволив этим писать мне в персональный блог.
Долго думал, о чем же написать свой «первый» топик… Слово первый не зря взял в кавычки, так как первый топик на самом деле уже был, опыт был к сожалению неудачный — дело закончилось баном. Решил больше не копипастить. Уверенности тому, что надо написать что-то свое, придал вот этот топик. Решил твердо — пусть это будет и редко, но буду писать сам.
Совсем недавно, по роду свой деятельности, мне пришлось столкнуться с таким понятием как ORM — (англ. Object-relational mapping). В двух словах ORM — это отображение объектов какого-либо объектно-ориентированного языка в структуры реляционных баз данных. Именно объектов, таких, какие они есть, со всеми полями, значениями, отношениями м/у друг другом.
ORM-решением для языка Java, является технология Hibernate, которая не только заботится о связи Java классов с таблицами базы данных (и типов данных Java в типы данных SQL), но также предоставляет средства для автоматического построения запросов и извлечения данных и может значительно уменьшить время разработки, которое обычно тратится на ручное написание SQL и JDBC кода. Hibernate генерирует SQL вызовы и освобождает разработчика от ручной обработки результирующего набора данных и конвертации объектов, сохраняя приложение портируемым во все SQL базы данных.
Итак, перед нами стоит задача написать небольшое приложение, которое бы осуществляло простое взаимодействие с базой данных, посредством технологии Hibernate.
Немного подумав, решил написать так называемый «Виртуальный автопарк». Суть парка такова: есть автобусы, есть маршруты и есть водители. Автобусы и маршруты связаны отношением один ко многим, т.е. на одном маршруте может кататься сразу несколько автобусов. Водители и автобусы связаны отношением многие ко многим, т.е. один водитель может водить разные автобусы и один автобус могут водить разные водители. Вроде ничего сложного.
Вот схема базы данных. 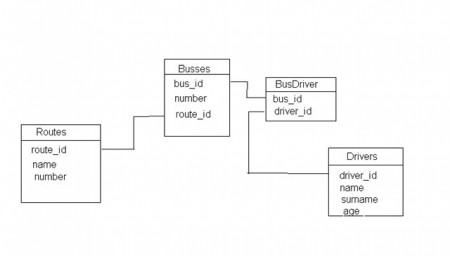
За качество не ругайте — под рукой не оказалось нормального инструмента таблички рисовать…
Вот ссылка на дамп, снятый с базы, вдруг кто-то решит все это дело поднять 🙂
Приступаем к коду. Во первых нам необходимо описать классы наших сущностей, т.е. класс автобуса, водителя и маршрута.
Класс автобус.
import java.util.Set;
import java.util.HashSet;
public class Bus <
private Long id;
private String number;
private Set drivers = new HashSet();
private Long route_id;
import java.util.Set;
import java.util.HashSet;
public class Driver <
private Long id;
private String name;
private String surname;
private int age;
private Set busses = new HashSet();
import java.util.Set;
import java.util.HashSet;
public class Route <
private Long id;
private String name;
private int number;
private Set busses = new HashSet();
Заметьте, что все классы сущностей должны соответствовать Java naming conventions, т.е. у них должны быть обязательно геттеры, сеттеры и конструктор по умолчанию. Ничего сложного 🙂
Теперь для наших классов необходимо описать маппинг в виде xml-файлов, эти файлы как раз и будут отвечать за взаимодействие наших объектов с Hibernate и с базой данных.
Bus.hbm.xml
hibernate-mapping >
class name =«logic.Bus» table =«busses» >
id column =«bus_id» name =«id» type =«java.lang.Long» >
generator class =«increment»/>
id >
property column =«number» name =«number» type =«java.lang.String»/>
set name =«drivers» table =«busDriver» lazy =«false» >
key column =«bus_id»/>
many-to-many column =«driver_id» class =«logic.Driver»/>
set >
Driver.hbm.xml
hibernate-mapping >
class name =«logic.Driver» table =«drivers» >
id column =«driver_id» name =«id» type =«java.lang.Long» >
generator class =«increment»/>
id >
property column =«name» name =«name» type =«java.lang.String»/>
property column =«surname» name =«surname» type =«java.lang.String»/>
property column =«age» name =«age» type =«java.lang.Integer»/>
set name =«busses» table =«busDriver» lazy =«false» >
key column =«driver_id»/>
many-to-many column =«bus_id» class =«logic.Bus»/>
set >
hibernate-mapping >
class name =«logic.Route» table =«routes» >
id column =«route_id» name =«id» type =«java.lang.Long» >
generator class =«increment»/>
id >
property column =«name» name =«name» type =«java.lang.String»/>
property column =«number» name =«number» type =«java.lang.Integer»/>
set name =«busses» lazy =«false» >
key column =«route_id»/>
one-to-many class =«logic.Bus»/>
set >
Теперь создадим главный конфигурационный файл hibernate.cfg.xml, файл, откуда он будет дергать всю необходимую ему информацию.
session-factory >
property name =«connection.url» > jdbc:mysql://localhost/autopark property >
property name =«connection.driver_class» > com.mysql.jdbc.Driver property >
property name =«connection.username» > root property >
property name =«connection.password»/>
property name =«connection.pool_size» > 1 property >
property name =«current_session_context_class» > thread property >
property name =«show_sql» > true property >
property name =«dialect» > org.hibernate.dialect.MySQL5Dialect property >
mapping resource =«logic/Bus.hbm.xml»/>
mapping resource =«logic/Driver.hbm.xml»/>
mapping resource =«logic/Route.hbm.xml»/>
Тут я не буду особо вдаваться в объяснение, думаю многим и так все понятно 🙂 Скажу, что надо только в конце не забыть добавить тег mapping и указать в качестве параметра resources файлы конфигурации ваших бинов.
Теперь создадим класс, который будет хавать наш конфиг-файл и возвращать нам объект типа SessionFactory, который отвечает за создание hibernate-сессии.
import org.hibernate.cfg.Configuration;
import org.hibernate.SessionFactory;
public class HibernateUtil <
private static final SessionFactory sessionFactory;
static <
try <
sessionFactory = new Configuration().configure().buildSessionFactory();
> catch (Throwable ex) <
System.err.println( «Initial SessionFactory creation failed.» + ex);
throw new ExceptionInInitializerError(ex);
>
>
Теперь нам осталось разобраться со взаимодействием нашего приложения с базой данных. Для этого для каждого класса-сущности, определим интерфейс, содержащий набор необходимых методов (Я приведу только один интерфейс и одну его реализацию, интерфейсы и реализации для др. классов подобны этим.)
import logic.Bus;
import logic.Driver;
import logic.Route;
import java.util.Collection;
import java.sql.SQLException;
public interface BusDAO <
public void addBus(Bus bus) throws SQLException;
public void updateBus(Long bus_id, Bus bus) throws SQLException;
public Bus getBusById(Long bus_id) throws SQLException;
public Collection getAllBusses() throws SQLException;
public void deleteBus(Bus bus) throws SQLException;
public Collection getBussesByDriver(Driver driver) throws SQLException;
public Collection getBussesByRoute(Route route) throws SQLException;
Теперь определим реализацию этого интерфейса в классе BusDAOImpl
import DAO.BusDAO;
import logic.Bus;
import logic.Driver;
import logic.Route;
import java.sql.SQLException;
import java.util.Collection;
import java.util. ArrayList ;
import java.util. List ;
import util.HibernateUtil;
import javax.swing.*;
import org.hibernate.Session;
import org.hibernate.Query;
public class BusDAOImpl implements BusDAO <
Еще рас скажу, что реализации DriverDAOImpl и RouteDAOImpl будут аналогичны этой.
Наибольший интерес для нас представляют два последних метода, взгляните на них повнимательнее. Как происходит общение с базой? От объекта SessionFactory создается новая или получается текущая сессия, зачем начинается транзакция, выполняются необходимые действия, коммит транзакции и закрытие сессии. Вроде ничего сложного 🙂 Обратите внимание, на то, каким синтаксисом описан запрос к базе. Это так называемый HQL (Hibernate Query Language) HQL представляет собой объектно-ориентированный язык запросов, возможности его широки, но мной настолько широко еще не осилены 🙂 Помимо save, load, update, delete и HQL, можно пользоваться и обычным SQL. Например:
String query = «SELECT driver_id, name, surname, age FROM drivers»;
List drivers = new ArrayList();
drivers = (List) session.createSQLQuery(query).list();
Теперь создадим класс фабрики, к которой будем обращаться за нашими реализациями DAO, от которых и будем вызывать необходимые нам методы.
private static BusDAO busDAO = null ;
private static DriverDAO driverDAO = null ;
private static RouteDAO routeDAO = null ;
private static Factory instance = null ;
public static synchronized Factory getInstance() <
if (instance == null ) <
instance = new Factory();
>
return instance;
>
public BusDAO getBusDAO() <
if (busDAO == null ) <
busDAO = new BusDAOImpl();
>
return busDAO;
>
public DriverDAO getDriverDAO() <
if (driverDAO == null ) <
driverDAO = new DriverDAOImpl();
>
return driverDAO;
>
Теперь нам осталось создать какой-либо демонстрационный класс, для того, чтобы посмотреть и опробовать все то, что мы написали. Ну, не будем тянуть, вот этот класс, возможно не самый удачный, но все же 🙂
public class Main <
public static void main( String [] args) throws SQLException <
Еще раз скажу, что может не самый удачный вариант использования всего нами написанного, но для этого уже лучше GUI писать или Web-интерфейс, а это уже другая песня 🙂
Что такое hibernate

В этой статье я постараюсь максимально просто объяснить Вам что такое hibernate фреймворк:
Все вышеперечисленное закрепим примером. А для начала постараемся вникнуть в теорию.
Hibernate — это библиотека, которая предназначена для задач объектно-реляционного отображения. Примерно такое описание будет в википедии. Если простыми словами — hibernate позволяет разработчику работать с базой данных не напрямую, как мы это делали с помощью библиотеки JDBC в статье Работа с базой данных, а с помощью представления таблиц баз данных в виде классов java.
Чтобы до конца понять дебри терминов давайте разберем что такое JPA — Java Persistance API.
JPA — спецификация, которая дает возможность сохранять в удобном виде Java-объекты в базе данных. Hibernate — это одна из самых популярных реализаций этой спецификации. Вот такая вот драма. Данные термины даны только в ознакомительных целях так как очень часто запутывают и пугают начинающих разработчиков.
Как это работать с базой данных через классы java? Если Вы открыли эту статью, то наверняка уже подключали базу данных к своему приложению и работали с ней. Если нет — то настоятельно советую прочитать цикл статей Java WEB, в которых подробно описано как создать веб приложение на чистой Java. Также, советую ознакомитья с SQL. А если я прав, и Вы уже знакомы с подключением базы данных, то наверняка работали с ней таким образом: создавали объект, который отображает таблицу базы данных. Например таблицу users с полями:
Потом писали метод подключения к базе, возможно даже пул соединений. Далее был DAO класс в котором делался запрос в базу, доставались или создавались данные, распарсивали их и подавали в виде списка или объекта примерно вот таким образом:
Hibernate дает Вашей разработке приложений новые инструменты: теперь вместо кучи ненужного кода нужно просто создать класс-сущность базы данных, пометить его специальным аннотациями и фреймворк все сделает за Вас.
Это называется ORM — Object Relational Mapping. Вам всего лишь нужно создать классы, которые соответствуют таблицам в базе данных, и написать методы, которые Вы хотите сделать с данными (получить, удалить, создать, обновить). Hibernate сам генерирует SQL запрос и выполняет его. Причем, ему не важно какую базу данных Вы используете. Это дает возможность переключать базы данных и не заботиться о том, что код не будет работать.
С теорией закончили. Теперь давайте узнаем как подключить Hibernate, мапить классы и делать простые запросы.
Начнем с нуля. Создадим простое Maven приложение. Если Вы используете Eclipse: File->New->Maven project.

Не забудьте проставить галочку возле Create a simple project. Даем нашему проекту название:

Далее нужно подключить библиотеку hibernate, JPA и драйвера к базе данных к нашему проекту. В данном примере я использую Postgresql, но разницы не будет никакой если Вы будете использовать другую базу данных. Я укажу место, где нужно будет сделать поправки.
После подключения зависимостей мой файл pom.xml выглядит так:
Теперь нужно придумать с чем будет работать наше приложение. Предлагаю использовать пример, который я описал выше. В этой ознакомительной статье с Hibernate я покажу работу этого фреймворка только с одной таблицей. Создадим в нашей постгрес базу данных hibernate_tutorial и в этой базе создадим таблицу users.

С этим, думаю, проблем не будет.
Теперь создадим класс Users в котором будут поля, геттеры, сеттеры, методы equals, hashCode, toString.
public class Users <
public Integer getId ( ) <
return id ;
>
public String getName ( ) <
return name ;
>
public String getEmail ( ) <
return email ;
>
public String getPassword ( ) <
return password ;
>
@Override
public String toString ( ) <
return «Users [id=» + id + «, name=» + name + «, email=» + email + «, password=» + password + «]» ;
>
Ничего особенного в этом классе нет: это простой объект, который Вы видели много раз. Если Вы когда-нибудь слышали или видели аббревиатуру POJO — Plain Old Java Object то это имелся ввиду именно такой класс. Старый простой объект java. Для того, чтобы этот класс стал сущностью базы данных нужно добавить к нему немного аннотаций.
Перед объявлением класса нужно добавить аннотацию @Entity — которая укажет, что данный класс является сущностью. Это часть спецификации JPA. Далее над классом нужно добавить еще одну аннотацию — @Table. Если Ваш класс совпадает с именем таблицы, то ничего добавлять не нужно. Но, в данной аннотации есть атрибут name в значении которого можно указать имя таблицы в базе данных, которую отображает класс. Поля класса нужно пометить аннотацией @Column в атрибут которой можно также поместить имя поля в таблице базы данных. Отдельного внимания заслуживает поле Id. Для него есть отдельная аннотация @Id. Для генерируемого значение важно указать аннотацию @GeneratedValue в атрибут которой нужно указать стратегию генерируемого значение. JPA поддерживает 3 стратегии генерации ключа. Вам же нужно выбрать стратегию в зависимости от того, как Вы генерируете айди в своей базе данных. Чтобы не усложнять и так запутанную тему мы выберем стратегию GenerationType.IDENTITY которая укажет, что мы генерируем это значение автоматически.
@ Entity
@Table ( name = «users» )
public class Users <
@Id
@GeneratedValue ( strategy = GenerationType. IDENTITY )
private Integer id ;
@Column ( name = «name» )
private String name ;
@Column ( name = «email» )
private String email ;
@Column ( name = «password» )
private String password ;
public Integer getId ( ) <
return id ;
>
public String getName ( ) <
return name ;
>
public String getEmail ( ) <
return email ;
>
public String getPassword ( ) <
return password ;
>
@Override
public String toString ( ) <
return «Users [id=» + id + «, name=» + name + «, email=» + email + «, password=» + password + «]» ;
>
Теперь на подобии коннектора подключений нужно указать настройки hibernate, чтобы библиотека знала с какой базой мы работаем, логин, пароль и тип базы. Создадим класс HibernateUtill и добавим в него немного магии.
import java.util.HashMap ;
import java.util.Map ;
import org.hibernate.SessionFactory ;
import org.hibernate.boot.Metadata ;
import org.hibernate.boot.MetadataSources ;
import org.hibernate.boot.registry.StandardServiceRegistry ;
import org.hibernate.boot.registry.StandardServiceRegistryBuilder ;
import org.hibernate.cfg.Environment ;
public class HibernateUtil <
private static StandardServiceRegistry registry ;
private static SessionFactory sessionFactory ;
registryBuilder. applySettings ( settings ) ;
registry = registryBuilder. build ( ) ;
Это конфигурационный файл, который позволяет настроить hibernate без xml. Я стараюсь не программировать с xml там, где это позволяют новые возможности.
Далее создадим простой класс-сервис по CRUD операциям с сущностью Users.
import javax.persistence.criteria.CriteriaQuery ;
import javax.transaction.Transactional ;
public class UsersCRUD <
В данном примере я не буду использовать язык HQL дабы не усложнять материал. Только уточню, что с помощью данного фреймворка можно работать с базой данных очень большим количеством способов, выбор которых падает на программиста и предметную область.
Теперь осталось протестировать наши методы.
public static void main ( String [ ] args ) <
UsersCRUD usersCRUD = new UsersCRUD ( ) ;
Users users1 = new Users ( ) ;
users1. setName ( «John» ) ;
users1. setEmail ( «connor_john@gmail.com» ) ;
users1. setPassword ( «somepswd123» ) ;
usersCRUD. save ( users1 ) ;
Users users2 = new Users ( ) ;
users2. setName ( «Sara» ) ;
users2. setEmail ( «sarra_mother@gmail.com» ) ;
users2. setPassword ( «qwerty123» ) ;
usersCRUD. save ( users2 ) ;
usersCRUD. delete ( userWithId1 ) ;
Ну и результат запуска приложения:

Надеюсь, Вы поняли что такое hibernate и JPA и какие возможности открывает данный фреймворк для программиста. Это лишь малая часть того, что умеет этот инструмент. Но для ознакомления и первого впечатления должно хватить.
Шпаргалка Java программиста 1: JPA и Hibernate в вопросах и ответах
Знаете ли вы JPA? А Hibernate? А если проверить?
За время работы Java программистом я заметил, что как правило программисты постоянно и планомерно используют от силы 10-20% от возможностей той или иной технологии, при этом остальные возможности быстро забываются и при появлении новых требований, переходе на новую работу или подготовке к техническому интервью приходится перечитывать все документации и спецификации с нуля. Зато наличие краткого конспекта особенностей тех или иных технологий (шпаргалок) позволяет быстро освежить в памяти особенности той или иной технологии.
Данная статья будет полезна и для тех кто только собирается изучать JPA и Hibernate (В этом случае рекомендую сразу открывать ответы), и для тех кто уже хорошо знает JPA и Hibernate (В этом случае статья позволит проверить свои знания и освежить особенности технологий). Особенно статья будет полезна тем кто собирается пройти техническое интервью, где возможно будут задавать вопросы по JPA и Hibernate (или сам собирается провести техническое интервью).
Рекомендую так считать правильные ответы: если вы ответили на вопрос по вашему мнению правильно и полностью — поставьте себе 1 балл, если ответили только частично — 0.5 балл. Везде где только возможно я старался добавлять цитаты из оригинальной документации (но из-за ограничений лицензии Oracle не могу давать слишком большие цитаты из документации).
Общие вопросы
JPA (Java Persistence API) это спецификация Java EE и Java SE, описывающая систему управления сохранением java объектов в таблицы реляционных баз данных в удобном виде. Сама Java не содержит реализации JPA, однако есть существует много реализаций данной спецификации от разных компаний (открытых и нет). Это не единственный способ сохранения java объектов в базы данных (ORM систем), но один из самых популярных в Java мире.
Entity это легковесный хранимый объект бизнес логики (persistent domain object). Основная программная сущность это entity класс, который так же может использовать дополнительные классы, который могут использоваться как вспомогательные классы или для сохранения состояния еntity.
И это тоже допустимо
Может, при этом он сохраняет все свойства Entity, за исключением того что его нельзя непосредственно инициализировать.
1) Entity класс должен быть отмечен аннотацией Entity или описан в XML файле конфигурации JPA,
2) Entity класс должен содержать public или protected конструктор без аргументов (он также может иметь конструкторы с аргументами),
3) Entity класс должен быть классом верхнего уровня (top-level class),
4) Entity класс не может быть enum или интерфейсом,
5) Entity класс не может быть финальным классом (final class),
6) Entity класс не может содержать финальные поля или методы, если они участвуют в маппинге (persistent final methods or persistent final instance variables),
7) Если объект Entity класса будет передаваться по значению как отдельный объект (detached object), например через удаленный интерфейс (through a remote interface), он так же должен реализовывать Serializable интерфейс,
8) Поля Entity класс должны быть напрямую доступны только методам самого Entity класса и не должны быть напрямую доступны другим классам, использующим этот Entity. Такие классы должны обращаться только к методам (getter/setter методам или другим методам бизнес-логики в Entity классе),
9) Enity класс должен содержать первичный ключ, то есть атрибут или группу атрибутов которые уникально определяют запись этого Enity класса в базе данных,
JPA указывает что она может работать как с свойствами классов (property), оформленные в стиле JavaBeans, либо с полями (field), то есть переменными класса (instance variables). Соответственно, при этом тип доступа будет либо property access или field access.
JPA указывает что она может работать как с свойствами классов (property), оформленные в стиле JavaBeans, либо с полями (field), то есть переменными класса (instance variables). Оба типа элементов Entity класса называются атрибутами Entity класса.
Допустимые типы атрибутов у Entity классов:
1. примитивные типы и их обертки Java,
2. строки,
3. любые сериализуемые типы Java (реализующие Serializable интерфейс),
4. enums;
5. entity types;
6. embeddable классы
7. и коллекции типов 1-6
Допустимые типы атрибутов, входящих в первичный ключ:
1. примитивные типы и их обертки Java,
2. строки,
3. BigDecimal и BigInteger,
4. java.util.Date и java.sql.Date,
В случае автогенерируемого первичного ключа (generated primary keys) допустимы
1. только числовые типы,
В случае использования других типов данных в первичном ключе, он может работать только для некоторых баз данных, т.е. становится не переносимым (not portable),
Сложные структуры JPA
Встраиваемый (Embeddable) класс это класс который не используется сам по себе, только как часть одного или нескольких Entity классов. Entity класс могут содержать как одиночные встраиваемые классы, так и коллекции таких классов. Также такие классы могут быть использованы как ключи или значения map. Во время выполнения каждый встраиваемый класс принадлежит только одному объекту Entity класса и не может быть использован для передачи данных между объектами Entity классов (то есть такой класс не является общей структурой данных для разных объектов). В целом, такой класс служит для того чтобы выносить определение общих атрибутов для нескольких Entity, можно считать что JPA просто встраивает в Entity вместо объекта такого класса те атрибуты, которые он содержит.
Может, но только в случае если такой класс не используется как первичный ключ или ключ map’ы.
1. Такие классы должны удовлетворять тем же правилам что Entity классы, за исключением того что они не обязаны содержать первичный ключ и быть отмечены аннотацией Entity (см. вопрос 10),
2. Embeddable класс должен быть отмечен аннотацией Embeddable или описан в XML файле конфигурации JPA,
Существуют следующие четыре типа связей
1. OneToOne (связь один к одному, то есть один объект Entity может связан не больше чем с один объектом другого Entity ),
2. OneToMany (связь один ко многим, один объект Entity может быть связан с целой коллекцией других Entity),
3. ManyToOne (связь многие к одному, обратная связь для OneToMany),
4. ManyToMany (связь многие ко многим)
Каждую из которых можно разделить ещё на два вида:
1. Bidirectional
2. Unidirectional
Bidirectional — ссылка на связь устанавливается у всех Entity, то есть в случае OneToOne A-B в Entity A есть ссылка на Entity B, в Entity B есть ссылка на Entity A, Entity A считается владельцем этой связи (это важно для случаев каскадного удаления данных, тогда при удалении A также будет удалено B, но не наоборот).
Undirectional- ссылка на связь устанавливается только с одной стороны, то есть в случае OneToOne A-B только у Entity A будет ссылка на Entity B, у Entity B ссылки на A не будет.
Mapped Superclass это класс от которого наследуются Entity, он может содержать анотации JPA, однако сам такой класс не является Entity, ему не обязательно выполнять все требования установленные для Entity (например, он может не содержать первичного ключа). Такой класс не может использоваться в операциях EntityManager или Query. Такой класс должен быть отмечен аннотацией MappedSuperclass или соответственно описан в xml файле.
Example: Concrete class as a mapped superclass
В JPA описаны три стратегии наследования мапинга (Inheritance Mapping Strategies), то есть как JPA будет работать с классами-наследниками Entity:
1) одна таблица на всю иерархию наследования (a single table per class hierarchy) — все enity, со всеми наследниками записываются в одну таблицу, для идентификации типа entity определяется специальная колонка “discriminator column”. Например, если есть entity Animals c классами-потомками Cats и Dogs, при такой стратегии все entity записываются в таблицу Animals, но при это имеют дополнительную колонку animalType в которую соответственно пишется значение «cat» или «dog». Минусом является то что в общей таблице, будут созданы все поля уникальные для каждого из классов-потомков, которые будет пусты для всех других классов-потомков. Например, в таблице animals окажется и скорость лазанья по дереву от cats и может ли пес приносить тапки от dogs, которые будут всегда иметь null для dog и cat соотвественно.
2) объединяющая стратегия (joined subclass strategy) — в этой стратегии каждый класс enity сохраняет данные в свою таблицу, но только уникальные колонки (не унаследованные от классов-предков) и первичный ключ, а все унаследованные колонки записываются в таблицы класса-предка, дополнительно устанавливается связь (relationships) между этими таблицами, например в случае классов Animals (см.выше), будут три таблицы animals, cats, dogs, причем в cats будет записана только ключ и скорость лазанья, в dogs — ключ и умеет ли пес приносить палку, а в animals все остальные данные cats и dogs c ссылкой на соответствующие таблицы. Минусом тут являются потери производительности от объединения таблиц (join) для любых операций.
3) одна таблица для каждого класса (table per concrete class strategy) — тут все просто каждый отдельный класс-наследник имеет свою таблицу, т.е. для cats и dogs (см.выше) все данные будут записываться просто в таблицы cats и dogs как если бы они вообще не имели общего суперкласса. Минусом является плохая поддержка полиморфизма (polymorphic relationships) и то что для выборки всех классов иерархии потребуются большое количество отдельных sql запросов или использование UNION запроса.
Для задания стратегии наследования используется аннотация Inheritance (или соответствующие блоки
Java Persistence 2.1. Chapter 2.12, J7EE javadoc
В JPA описаны два типа fetch стратегии:
1) LAZY — данные поля будут загруженны только во время первого доступа к этому полю,
2) EAGER — данные поля будут загруженны немедленно,
Основные операции с Entity
EntityManager это интерфейс, который описывает API для всех основных операций над Enitity, получение данных и других сущностей JPA. По сути главный API для работы с JPA. Основные операции:
1) Для операций над Entity: persist (добавление Entity под управление JPA), merge (обновление), remove (удаления), refresh (обновление данных), detach (удаление из управление JPA), lock (блокирование Enity от изменений в других thread),
2) Получение данных: find (поиск и получение Entity), createQuery, createNamedQuery, createNativeQuery, contains, createNamedStoredProcedureQuery, createStoredProcedureQuery
3) Получение других сущностей JPA: getTransaction, getEntityManagerFactory, getCriteriaBuilder, getMetamodel, getDelegate
4) Работа с EntityGraph: createEntityGraph, getEntityGraph
4) Общие операции над EntityManager или всеми Entities: close, isOpen, getProperties, setProperty, clear
Interface used to interact with the persistence context.
An EntityManager instance is associated with a persistence context. A persistence context is a set of entity instances in which for any persistent entity identity there is a unique entity instance. Within the persistence context, the entity instances and their lifecycle are managed. The EntityManager API is used to create and remove persistent entity instances, to find entities by their primary key, and to query over entities.
The set of entities that can be managed by a given EntityManager instance is defined by a persistence unit. A persistence unit defines the set of all classes that are related or grouped by the application, and which must be colocated in their mapping to a single database.
У Entity объекта существует четыре статуса жизненного цикла: new, managed, detached, или removed. Их описание
1) new — объект создан, но при этом ещё не имеет сгенерированных первичных ключей и пока ещё не сохранен в базе данных,
2) managed — объект создан, управляется JPA, имеет сгенерированные первичные ключи,
3) detached — объект был создан, но не управляется (или больше не управляется) JPA,
4) removed — объект создан, управляется JPA, но будет удален после commit’a транзакции.
An entity instance can be characterized as being new, managed, detached, or removed.
• A new entity instance has no persistent identity, and is not yet associated with a persistence context.
• A managed entity instance is an instance with a persistent identity that is currently associated with a persistence context.
• A detached entity instance is an instance with a persistent identity that is not (or no longer) associated with a persistence context.
• A removed entity instance is an instance with a persistent identity, associated with a persistence context, that will be removed from the database upon transaction commit.
1) Если статус Entity new, то он меняется на managed и объект будет сохранен в базу при commit’е транзакции или в результате flush операций,
2) Если статус уже managed, операция игнорируется, однако зависимые Entity могут поменять статус на managed, если у них есть аннотации каскадных изменений,
3) Если статус removed, то он меняется на managed,
4) Если статус detached, будет выкинут exception сразу или на этапе commit’а транзакции,
1) Если статус Entity new, операция игнорируется, однако зависимые Entity могут поменять статус на removed, если у них есть аннотации каскадных изменений и они имели статус managed,
2) Если статус managed, то статус меняется на removed и запись объект в базе данных будет удалена при commit’е транзакции (так же произойдут операции remove для всех каскадно зависимых объектов),
3) Если статус removed, то операция игнорируется,
4) Если статус detached, будет выкинут exception сразу или на этапе commit’а транзакции,
1) Если статус detached, то либо данные будет скопированы в существующей managed entity с тем же первичным ключом, либо создан новый managed в который скопируются данные,
1) Если статус Entity new, то будет создана новый managed entity, в который будут скопированы данные прошлого объекта,
2) Если статус managed, операция игнорируется, однако операция merge сработает на каскадно зависимые Entity, если их статус не managed,
3) Если статус removed, будет выкинут exception сразу или на этапе commit’а транзакции,
1) Если статус Entity managed, то в результате операции будут востановлены все изменения из базы данных данного Entity, так же произойдет refresh всех каскадно зависимых объектов,
2) Если статус new, removed или detached, будет выкинут exception,
1) Если статус Entity managed или removed, то в результате операции статус Entity (и всех каскадно-зависимых объектов) станет detached.
2) Если статус new или detached, то операция игнорируется,
Аннотации JPA
Она определяет тип доступа (access type) для класса entity, суперкласса, embeddable или отдельных атрибутов, то есть как JPA будет обращаться к атрибутам entity, как к полям класса (FIELD) или как к свойствам класса (PROPERTY), имеющие гетеры (getter) и сетеры (setter).
Для такого перекрывания существует четыре аннотации:
1. AttributeOverride чтобы перекрыть поля, свойства и первичные ключи,
2. AttributeOverrides аналогично можно перекрыть поля, свойства и первичные ключи со множественными значениями,
3. AssociationOverride чтобы перекрывать связи (override entity relationship),
4. AssociationOverrides чтобы перекрывать множественные связи (multiple relationship),
Example 2: Overriding of the mapping for the phoneNumbers relationship defined in the ContactInfo
embeddable class.
The Cacheable annotation specifies whether an entity should be cached if caching is enabled when
the value of the persistence.xml shared-cache-mode element is ENABLE_SELECTIVE or
DISABLE_SELECTIVE. The value of the Cacheable annotation is inherited by subclasses; it can be
overridden by specifying Cacheable on a subclass.
Cacheable(false) means that the entity and its state must not be cached by the provider.
If the shared-cache-mode element is not specified in the persistence.xml file and the
javax.persistence.sharedCache.mode property is not specified when the entity manager
factory for the persistence unit is created, the semantics of the Cacheable annotation are undefined.
Convert и Converts — позволяют указать класс для конвертации Basic аттрибута Entity в другой тип (Converts — позволяют указать несколько классов конвертации). Классы для конвертации должны реализовать интерфейс AttributeConverter и могут быть отмечены (но это не обязательно) аннотацией Converter.
Аннотация EntityListeners позволяет задать класс Listener, который будет содержать методы обработки событий (сallback methods) определенных Entity или Mapped Superclass.
Callback методы служат для вызова при определенных событиях Entity (то есть добавить обработку например удаления Entity методами JPA), могут быть добавлены к entity классу, к mapped superclass, или к callback listener классу, заданному аннотацией EntityListeners (см предыдущий вопрос). Существует семь callback методов (и аннотаций с теми же именами):
1) PrePersist
2) PostPersist
3) PreRemove
4) PostRemove
5) PreUpdate
6) PostUpdate
7) PostLoad
Подробнее, см Javadoc 7ee или спецификация JPA2.1 глава 3.5.2
Для этого служит аннотация OrderBy и OrderColumn
Подробнее, см Javadoc 7ee или спецификация JPA2.1 глава 11.1.42
Для этого служит аннотация Transient
Подробнее, см Javadoc 7ee или спецификация JPA2.1 глава 11.1.52
Сложные вопросы JPA
У JPA есть шесть видов блокировок, перечислим их в порядке увеличения надежности (от самого ненадежного и быстрого, до самого надежного и медленного):
1) NONE — без блокировки
2) OPTIMISTIC (или синоним READ, оставшийся от JPA 1) — оптимистическая блокировка,
3) OPTIMISTIC_FORCE_INCREMENT (или синоним WRITE, оставшийся от JPA 1) — оптимистическая блокировка с принудительным увеличением поля версионности,
4) PESSIMISTIC_READ — пессимистичная блокировка на чтение,
5) PESSIMISTIC_WRITE — пессимистичная блокировка на запись (и чтение),
6) PESSIMISTIC_FORCE_INCREMENT — пессимистичная блокировка на запись (и чтение) с принудительным увеличением поля версионности,
Подробнее, см Javadoc 7ee и описание оптимистичных и пессимистичных блокировок баз данных.
JPA говорит о двух видов кэшей (cache):
1) first-level cache (кэш первого уровня) — кэширует данные одной транзакции,
2) second-level cache (кэш второго уровня) — кэширует данные дольше чем одна транзакция. Провайдер JPA может, но не обязан реализовывать работу с кэшем второго уровня. Такой вид кэша позволяет сэкономить время доступа и улучшить производительность, однако оборотной стороной является возможность получить устаревшие данные.
Подробнее, см JPA 2.1 specification, 3.9 Caching
JPA говорит о пяти значениях shared-cache-mode из persistence.xml, который определяет как будет использоваться second-level cache:
1) ALL — все Entity могут кэшироваться в кеше второго уровня,
2) NONE — кеширование отключено для всех Entity,
3) ENABLE_SELECTIVE — кэширование работает только для тех Entity, у которых установлена аннотация Cacheable(true) или её xml эквивалент, для всех остальных кэширование отключено,
4) DISABLE_SELECTIVE — кэширование работает для всех Entity, за исключением тех у которых установлена аннотация Cacheable(false) или её xml эквивалент
5) UNSPECIFIED — кеширование не определенно, каждый провайдер JPA использует свою значение по умолчанию для кэширования,
Подробнее, см JPA 2.1 specification, 3.9 Caching
Для этого существует EntityGraph API, используется он так: с помощью аннотации NamedEntityGraph для Entity, создаются именованные EntityGraph объекты, которые содержат список атрибутов у которых нужно поменять fetchType на EAGER, а потом данное имя указывается в hits запросов или метода find. В результате fetchType атрибутов Entity меняется, но только для этого запроса. Существует две стандартных property для указания EntityGraph в hit:
1) javax.persistence.fetchgraph — все атрибуты перечисленные в EntityGraph меняют fetchType на EAGER, все остальные на LAZY
2) javax.persistence.loadgraph — все атрибуты перечисленные в EntityGraph меняют fetchType на EAGER, все остальные сохраняют свой fetchType (то есть если у атрибута, не указанного в EntityGraph, fetchType был EAGER, то он и останется EAGER)
С помощью NamedSubgraph можно также изменить fetchType вложенных объектов Entity.
Подробнее, см JPA 2.1 specification, 3.7 EntityGraph
Для работы с кэшем второго уровня (second level cache) в JPA описан Cache интерфейс, содержащий большое количество методов по управлению кэшем второго уровня (second level cache), если он поддерживается провайдером JPA, конечно. Объект данного интерфейса можно получить с помощью метода getCache у EntityManagerFactory.
Подробнее, см JPA 2.1 specification, 7.10 Cache Interface
Для получения такой информации в JPA используется интерфейс Metamodel. Объект этого интерфейса можно получить методом getMetamodel у EntityManagerFactory или EntityManager.
Подробнее, см JPA 2.1 specification, 5 Metamodel API
JPQL (Java Persistence query language) это язык запросов, практически такой же как SQL, однако вместо имен и колонок таблиц базы данных, он использует имена классов Entity и их атрибуты. В качестве параметров запросов так же используются типы данных атрибутов Entity, а не полей баз данных. В отличии от SQL в JPQL есть автоматический полиморфизм (см. следующий вопрос). Также в JPQL используется функции которых нет в SQL: такие как KEY (ключ Map’ы), VALUE (значение Map’ы), TREAT (для приведение суперкласса к его объекту-наследнику, downcasting), ENTRY и т.п.
Подробнее, см JPA 2.1 specification, Chapter 4 Query Language
В отличии от SQL в запросах JPQL есть автоматический полиморфизм, то есть каждый запрос к Entity возвращает не только объекты этого Entity, но так же объекты всех его классов-потомков, независимо от стратегии наследования (например, запрос select * from Animal, вернет не только объекты Animal, но и объекты классов Cat и Dog, которые унаследованы от Animal). Чтобы исключить такое поведение используется функция TYPE в where условии (например select * from Animal a where TYPE(a) IN (Animal, Cat) уже не вернет объекты класса Dog).
Подробнее, см JPA 2.1 specification, Chapter 4 Query Language
Criteria API это тоже язык запросов, аналогичным JPQL (Java Persistence query language), однако запросы основаны на методах и объектах, то есть запросы выглядят так:
Подробнее, см JPA 2.1 specification, Chapter 6 Criteria API
Отличия Hibernate 5.0 от JPA 2.1 или JPA 2.0 от JPA 2.1
1) Конструктор без аргументов не обязан быть public или protected, рекомендуется чтобы он был хотя бы package видимости, однако это только рекомендация, если настройки безопасности Java позволяют доступ к приватным полям, то он может быть приватным,
2) JPA категорически требует не использовать final классы, Hibernate лишь рекомендует не использовать такие классы чтобы он мог создавать прокси для ленивой загрузки, однако позволяет либо выключить прокси Proxy(lazy=false), либо использовать в качестве прокси интерфейс, содержащий все методы маппинга для данного класса (аннотацией Proxy(proxyClass=интерфейс.class) )
В отличии JPA в Hibernate есть уникальная стратегия наследования, которая называется implicit polymorphism.
Hibernate supports the three basic inheritance mapping strategies:
table per class hierarchy
table per subclass
table per concrete class
In addition, Hibernate supports a fourth, slightly different kind of polymorphism:
В спецификации JPA 2.1 появились:
1) Entity Graphs — механизм динамического изменения fetchType для каждого запроса,
2) Converters — механизм определения конвертеров для задания функций конвертации атрибутов Entity в поля базы данных,
3) DDL генерация — автоматическая генерация таблиц, индексов и схем,
4) Stored Procedures — механизм вызова хранимых процедур из JPA,
5) Criteria Update/Delete — механизм вызова bulk updates или deletes, используя Criteria API,
6) Unsynchronized persistence contexts — появление возможности указать SynchronizationType,
7) Новые возможности в JPQL/Criteria API: арифметические подзапросы, generic database functions, join ON clause, функция TREAT,
8) Динамическое создание именованных запросов (named queries)
Подробнее о изменении интерфейсов и API в JPA 2.1:
1) Интерфейс EntityManager получил новые методы createStoredProcedureQuery, isJoinedToTransaction и createQuery(CriteriaUpdate или CriteriaDelete)
2) Абстрактный класс AbstractQuery стал наследоваться от класса CommonAbstractCriteria, появились новые интерфейсы CriteriaUpdate, CriteriaDelete унаследованные CommonAbstractCriteria,
3) PersistenceProvider получил новые функции generateSchema позволяющие генерить схемы,
4) EntityManagerFactory получил методы addNamedQuery, unwrap, addNamedEntityGraph, createEntityManager (с указанием SynchronizationType)
5) Появился новый enum SynchronizationType, Entity Graphs, StoredProcedureQuery и AttributeConverter интерфейсы,



