BrainBeast
Что такое HTTP клиент?
В клиент-серверной модели Сервер принимает запросы и отправляет ответы, Клиент отправляет запросы и принимает ответы. 
В общем, Клиент — это программа, библиотека или программный метод, который:
Клиент может быть описан, как высокоуровневой многофункциональной библиотекой, так и участком кода с двумя методами (отправить запрос, принять ответ)
Мудро выбранный Клиент играет решающую роль в производительности приложения, которое использует внешний API или имеет дело с большим количеством запросов.
Как правило каждая языковая платформа имеет встроенные инструменты для исполнения работы клиента.
Зачем нужен HTTP клиент?
На сей день существуют стандарты построения HTTP запросов в клиент-серверной модели. Таким образом разные веб системы общаются друг с другом. Как понятно из RFC документации, есть много правил, информации о том, что такое HTTP и как использовать этот протокол. Обычно у рядового разработчика нету времени на изучение этого всего. К тому же, это не всегда стоит делать.
Клиент разработан так, чтобы соответствовать стандартам протокола, с которым он работает, и архитектуре использования этого протокола (к примеру, REST). В нашем случае HTTP или HTTPS.
Клиент позволяет упростить работу с отправкой и получением данных, поскольку:
Методы HTTP запросов
HTTP запросы широко используются в работе с внешними базами данных при помощи API. Чтобы сделать работу с API простой и предсказуемой, запросы разделили по определенным методам:
Примеры HTTP клиента

Javascript HTTP Клиент
В веб-версии JS есть объект XMLHttpRequest, который может отправлять и принимать http запросы, настраивать метод запроса и работать в асинхронном режиме.
При помощи cURL сервера с установленным PHP могут отправлять запросы. cURL — это не единственный вариант.
Как скачать картинку HTTP клиентом на C#?
Как установить время ожидания подключения в C# HTTP Client?
Как добавить header в HTTP запрос на C#?
Как сделать POST запрос и отправить JSON на C#?
Первый вариант — это установить Microsoft.AspNet.WebApi.Client из Nuget.
Оставить комментарий Отменить ответ
Для отправки комментария вам необходимо авторизоваться.
Apache HttpClient — Краткое руководство
Протокол передачи гипертекста (HTTP) — это протокол прикладного уровня для распределенных, совместных, гипермедиа информационных систем. Это основа для обмена данными для Всемирной паутины (т.е. Интернета) с 1990 года. HTTP является универсальным протоколом и протоколом без сохранения состояния, который может использоваться для других целей, а также с использованием расширений его методов запроса, кодов ошибок и заголовков.
По сути, HTTP — это протокол связи на основе TCP / IP, который используется для доставки данных (файлы HTML, файлы изображений, результаты запросов и т. Д.) В World Wide Web. Порт по умолчанию — TCP 80, но можно использовать и другие порты. Он обеспечивает стандартизированный способ связи компьютеров друг с другом. Спецификация HTTP определяет, как данные запросов клиентов будут создаваться и отправляться на сервер, и как серверы отвечают на эти запросы.
Что такое Http-клиент
Http-клиент является библиотекой передачи, он находится на стороне клиента, отправляет и получает сообщения HTTP. Он обеспечивает современную, многофункциональную и эффективную реализацию, соответствующую современным стандартам HTTP.
В дополнение к этому, используя клиентскую библиотеку, можно создавать приложения на основе HTTP, такие как веб-браузеры, клиенты веб-служб и т. Д.
Особенности Http Client
Ниже приведены основные характеристики клиента Http —
Библиотека HttpClient реализует все доступные методы HTTP.
Библиотека HttpClient предоставляет API для защиты запросов с использованием протокола Secure Socket Layer.
Используя HttpClient, вы можете устанавливать соединения, используя прокси.
Вы можете аутентифицировать соединения, используя схемы аутентификации, такие как Basic, Digest, NTLMv1, NTLMv2, NTLM2 Session и т. Д.
Используя библиотеку Apache HttpClient, вы можете установить время ожидания подключения.
Библиотека HttpClient реализует все доступные методы HTTP.
Библиотека HttpClient предоставляет API для защиты запросов с использованием протокола Secure Socket Layer.
Используя HttpClient, вы можете устанавливать соединения, используя прокси.
Вы можете аутентифицировать соединения, используя схемы аутентификации, такие как Basic, Digest, NTLMv1, NTLMv2, NTLM2 Session и т. Д.
Используя библиотеку Apache HttpClient, вы можете установить время ожидания подключения.
Apache HttpClient — Настройка среды
В этой главе мы объясним, как настроить среду для HttpClient в Eclipse IDE. Прежде чем продолжить установку, убедитесь, что в вашей системе уже установлен Eclipse. Если нет, скачайте и установите Eclipse.
Шаг 1 — Загрузите JAR-файл зависимости
Откройте официальную домашнюю страницу сайта HttpClient (компоненты) и перейдите на страницу загрузки
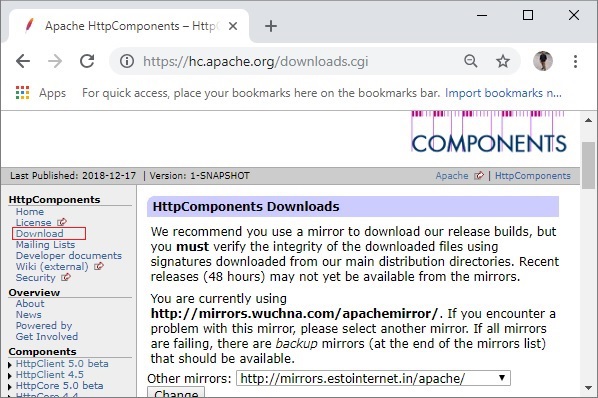
В загруженной папке вы найдете папку с именем lib, которая содержит необходимые файлы Jar, которые необходимо добавить в путь к классам вашего проекта для работы с HttpClient.
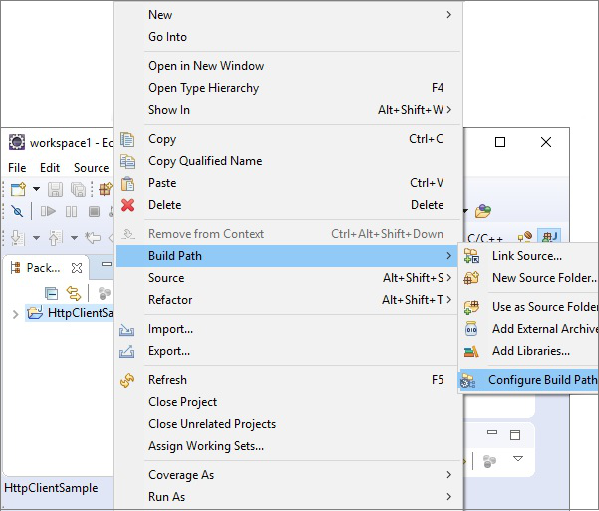
Шаг 2 — Создайте проект и установите путь сборки
Откройте затмение и создайте пример проекта. Щелкните правой кнопкой мыши по проекту и выберите опцию Build Path → Configure Build Path, как показано ниже.
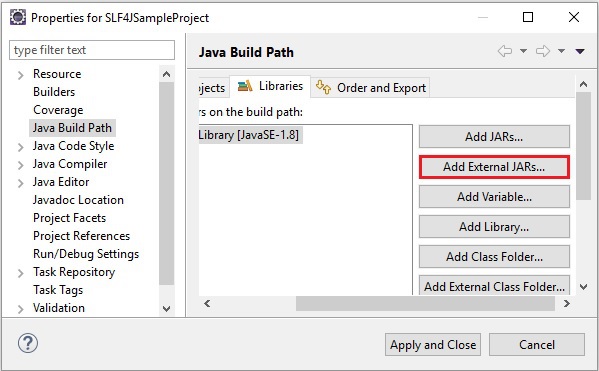
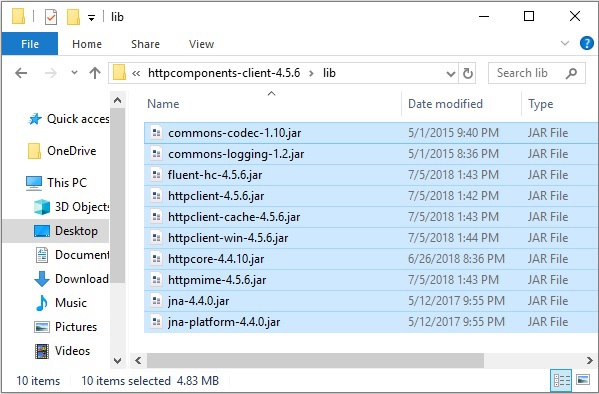
Все готово для работы с библиотекой HttpClient в eclipse.
Apache HttpClient — Http Получить запрос
Метод GET используется для получения информации с данного сервера с использованием заданного URI. Запросы с использованием GET должны только извлекать данные и не должны оказывать никакого другого влияния на данные.
HttpClient API предоставляет класс с именем HttpGet, который представляет метод запроса get.
Следуйте приведенным ниже инструкциям, чтобы отправить запрос на получение с помощью библиотеки HttpClient.
Шаг 1 — Создайте объект HttpClient
Используя этот метод, создайте объект HttpClient, как показано ниже —
Шаг 2. Создание объекта HttpGet.
Класс HttpGet представляет запрос HTTPGET, который получает информацию о заданном сервере, используя URI.
Создайте запрос HTTP GET, создав экземпляр этого класса. Конструктор этого класса принимает значение String, представляющее URI.
Шаг 3 — Выполнить запрос на получение
Метод execute () класса CloseableHttpClient принимает объект HttpUriRequest (interface) (т. Е. HttpGet, HttpPost, HttpPut, HttpHead и т. Д.) И возвращает объект ответа.
Выполните запрос, используя этот метод, как показано ниже —
пример
Ниже приведен пример, демонстрирующий выполнение HTTP-запроса GET с использованием библиотеки HttpClient.
Выход
Вышеуказанная программа генерирует следующий вывод —
Apache HttpClient — Http Post Request
POST-запрос используется для отправки данных на сервер; например, информация о клиенте, загрузка файла и т. д. с использованием HTML-форм.
HttpClient API предоставляет класс с именем HttpPost, который представляет запрос POST.
Следуйте приведенным ниже инструкциям, чтобы отправить запрос HTTP POST с использованием библиотеки HttpClient.
Шаг 1 — Создание объекта HttpClient
Используя этот метод, создайте объект HttpClient.
Шаг 2 — Создание объекта HttpPost
Создайте этот запрос путем создания экземпляра класса HttpPost и передачи строкового значения, представляющего URI, в качестве параметра его конструктору.
Шаг 3 — Выполнить запрос на получение
Метод execute () объекта CloseableHttpClient принимает объект HttpUriRequest (interface) (т. Е. HttpGet, HttpPost, HttpPut, HttpHead и т. Д.) И возвращает объект ответа.
пример
Ниже приведен пример, демонстрирующий выполнение HTTP-запроса POST с использованием библиотеки HttpClient.
Выход
Вышеуказанная программа генерирует следующий вывод.
Apache HttpClient — обработчики ответов
Рекомендуется обрабатывать ответы HTTP с использованием обработчиков ответов. В этой главе мы собираемся обсудить, как создавать обработчики ответов и как использовать их для обработки ответа.
Если вы используете обработчик ответа, все HTTP-соединения будут освобождены автоматически.
Создание обработчика ответа
Каждый ответ имеет код состояния, и если код состояния находится между 200 и 300, это означает, что действие было успешно получено, понято и принято. Поэтому в нашем примере мы будем обрабатывать сущности ответов с такими кодами состояния.
Выполнение запроса с использованием обработчика ответа
Выполните шаги, приведенные ниже, чтобы выполнить запрос, используя обработчик ответа.
Шаг 1 — Создание объекта HttpClient
Шаг 2 — Создание обработчика ответа
Создайте объект обработчика ответа, созданный выше, используя следующую строку кода:
Шаг 3 — Создание объекта HttpGet
Класс HttpGet представляет HTTP-запрос GET, который извлекает информацию о данном сервере с использованием URI.
Создайте запрос HttpGet, создав экземпляр класса HttpGet и передав строку, представляющую URI, в качестве параметра его конструктору.
Шаг 4 — Выполнить запрос Get с помощью обработчика ответа
Класс CloseableHttpClient имеет вариант метода execute (), который принимает два объекта ResponseHandler и HttpUriRequest и возвращает объект ответа.
пример
Следующий пример демонстрирует использование обработчиков ответов.
Выход
Вышеуказанные программы генерируют следующий вывод —
Apache HttpClient — закрытие соединения
Если вы обрабатываете HTTP-ответы вручную, а не используете обработчик ответов, вам необходимо закрыть все http-соединения самостоятельно. В этой главе объясняется, как закрыть соединения вручную.
При закрытии HTTP-соединений вручную следуйте инструкциям ниже:
Шаг 1 — Создайте объект HttpClient
Используя этот метод, создайте объект HttpClient, как показано ниже —
Шаг 2 — Запустите блок try-finally
Запустите блок try-finally, запишите оставшийся код в программах в блоке try и закройте объект CloseableHttpClient в блоке finally.
Шаг 3 — Создание HttpGetobject
Класс HttpGet представляет HTTP-запрос GET, который извлекает информацию о данном сервере с использованием URI.
Создайте HTTP-запрос GET, создав экземпляр класса HttpGet, передав строку, представляющую URI.
Шаг 4 — Выполнить запрос Get
Метод execute () объекта CloseableHttpClient принимает объект HttpUriRequest (interface) (т. Е. HttpGet, HttpPost, HttpPut, HttpHead и т. Д.) И возвращает объект ответа.
Выполнить запрос, используя данный метод —
Шаг 5 — Запустите еще одну (вложенную) попытку
Запустите другой блок try-finally (вложенный в предыдущий блок try-finally), запишите оставшийся код в программах этого блока try и закройте объект HttpResponse в блоке finally.
пример
Всякий раз, когда вы создаете / получаете объекты, такие как запрос, поток ответов и т. Д., Начинайте блок try finally на следующей строке, пишите оставшийся код в блоке try и закрывайте соответствующий объект в блоке finally, как показано в следующей программе:
Выход
При выполнении вышеупомянутой программы генерируется следующий вывод:
Apache HttpClient — прерывание запроса
Если этот метод вызывается после одного выполнения, ответы этого выполнения не будут затронуты, и последующие выполнения будут прерваны.
пример
Затем мы выполнили еще одно выполнение с тем же запросом. Напечатал строку состояния снова, используя 1- е исполнение. Наконец, печатается строка состояния второго исполнения.
Как обсуждалось, ответы 1- го исполнения (выполнение перед методом прерывания) печатаются (включая вторую строку состояния, которая записывается после метода прерывания), и все последующие исполнения текущего запроса после метода прерывания завершаются неудачно, вызывая исключение.
Выход
При выполнении вышеупомянутая программа генерирует следующий вывод —
Apache HttpClient — перехватчики
Перехватчики — это те, которые помогают блокировать или изменять запросы или ответы. Протокол-перехватчики обычно действуют на определенный заголовок или группу связанных заголовков. Библиотека HttpClient обеспечивает поддержку перехватчиков.
Запрос перехватчика
Интерфейс HttpRequestInterceptor представляет перехватчики запросов. Этот интерфейс содержит метод, известный как процесс, в котором вам нужно написать кусок кода для перехвата запросов.
На стороне клиента этот метод проверяет / обрабатывает запросы перед их отправкой на сервер, а на стороне сервера этот метод выполняется перед оценкой тела запроса.
Создание запроса-перехватчика
Вы можете создать перехватчик запроса, выполнив шаги, указанные ниже.
Шаг 1 — Создание объекта HttpRequestInterceptor
Создайте объект интерфейса HttpRequestInterceptor, реализовав его абстрактный метод process.
Шаг 2. Создание объекта CloseableHttpClient
Используя этот объект, вы можете выполнять запросы как обычно.
пример
Следующий пример демонстрирует использование перехватчиков запросов. В этом примере мы создали объект запроса HTTP GET и добавили к нему три заголовка: sample-header, demoheader и test-header.
Выход
При выполнении вышеупомянутой программы генерируется следующий вывод:
Ответ перехватчик
На стороне сервера этот метод проверяет / обрабатывает ответ перед отправкой его клиенту, а на стороне клиента этот метод выполняется перед оценкой тела ответа.
Создание ответного перехватчика
Вы можете создать перехватчик ответа, выполнив следующие шаги:
Шаг 1 — Создание объекта HttpResponseInterceptor
Шаг 2: создание объекта CloseableHttpClient
Протокол HTTP: обзор для чайников



Каждый раз, когда вы посещаете страницу в интернете, ваш компьютер использует протокол передачи гипертекста (HTTP) для загрузки этой страницы. HTTP — это набор правил для передачи файлов: текста, изображений, звука, видео и других мультимедиа. HTTP работает поверх набора протоколов TCP/IP, которые составляют основу интернета.
Составляющие HTTP
В HTTP-протоколе есть две разные роли: сервер и клиент. Запрос всегда инициирует клиент, а сервер на него отвечает. Клиентом может быть как браузер, так и, к примеру, поисковый робот, который просматривает страницы в интернете и индексирует их согласно релевантности ключевого запроса. HTTP основан на тексте — сообщения между клиентом и сервером по сути представляют собой фрагменты текста, хотя в теле сообщения могут быть другие элементы: видео, фото, аудио и т.д.
Каждый отдельный запрос отправляется на сервер, который обрабатывает его и предоставляет ответ. Между клиентом и сервером существует множество объектов, которые называются прокси-серверами. Они обеспечивают различные уровни функциональности, безопасности и конфиденциальности в зависимости от ваших потребностей или политики компании.

Схематичное изображение работы HTTP-протокола
Итак, мы выяснили, что HTTP содержит три основных элемента:
Рассмотрим подробнее, что это такое и как они работают.
Клиент
Клиент — это любой инструмент, который действует от имени пользователя. В основном эту роль выполняет веб-браузер, но помимо браузера это быть программы, используемые инженерами или веб-разработчиками для отладки своих приложений. Клиент всегда инициирует запрос, это никогда не делает сервер.
Веб-сервер
На другой стороне канала связи находится сервер, который обслуживает документ по запросу клиента. Хотя для пользователя сервер выглядит как одна виртуальная машина, на самом деле это может быть набор серверов, разделяющих нагрузку. С другой стороны, несколько серверов могут быть расположены на одной и той же машине. При HTTP/1.1 и заголовке Host они могут даже использовать один и тот же IP-адрес.
Прокси
Прокси-серверы — это серверы, компьютеры или другие машины уровня приложений, которые находятся между клиентским устройством и непосредственно сервером. Они ретранслируют HTTP-запросы и ответы. Обычно для каждого взаимодействия клиент-сервер используется один или несколько прокси.
Веб-разработчики могут использовать прокси для следующих целей:
Как работает HTTP-протокол
Шаг первый: направляем URL в браузер.
Когда мы хотим посмотреть веб-страницу, мы можем использовать разные типы девайсов: ноутбук, стационарный компьютер или телефон. Главное, чтобы на устройстве было приложение браузера. Пользователь либо вводит унифицированный указатель ресурса (URL) в поисковую строку браузера, либо переходит по ссылке с уже открытой страницы:
URL-адрес начинается с HTTP. Это сигнал браузеру, что ему необходимо использовать HTTP-протокол для получения документа по этому адресу.
Шаг второй: браузер ищет нужный IP-адрес.
Обычно IP-адреса содержат удобные и читабельные для человека названия доменов, например «highload.today» или «wikipedia.org». Браузер использует преобразователь DNS для сопоставления домена с IP-адресом.
Шаг третий: браузер посылает HTTP-запрос.
Как только браузер определяет IP-адрес компьютера, на котором размещен запрошенный URL, он отправляет HTTP-запрос.
HTTP-запрос может состоять всего из двух строк текста:
Кроме GET в HTTP-протоколе существует еще два вида запросов. Разберем их отличия:
Шаг четвертый: сервер отправляет HTTP-ответ.
Как только хост-компьютер получает HTTP-запрос, он отправляет клиенту ответ с содержанием и метаданными.
HTTP-ответ начинается аналогично запросу:
Ответ начинается с указания версии HTTP-протокола — 1.1. Следующее число — это код статуса HTTP, в примере это число 200. Этот код значит, что запрашиваемый документ был успешно извлечен.
Следующая часть ответа HTTP — это заголовки. Они предоставляют браузеру дополнительные сведения и помогают ему отображать контент. Эти два заголовка являются общими для большинства запросов:
Content-length показывает длину документа в байтах, что помогает браузеру узнать, сколько времени потребуется для загрузки файла.
Кроме кода 200, в случае если загрузка страницы прошла успешно, есть еще несколько статусов:
Шаг пятый: отображается нужная веб-страница. После выполнения всех шагов, браузер получает всю необходимую информацию, для отображения запрошенного документа.
Основные характеристики HTTP-протокола
Есть три основные особенности, которые делают HTTP простым, но мощным протоколом.
HTTP-протокол — простой, но многофункциональный
HTTP — это основа всего интернета. Он быстрый, легкий и многофункциональный. Подводя итоги, рассмотрим преимущества и особенности HTTP-протокола.
Для закрепления материала можно посмотреть эти два образовательные видео:
Простым языком об HTTP
Вашему вниманию предлагается описание основных аспектов протокола HTTP — сетевого протокола, с начала 90-х и по сей день позволяющего вашему браузеру загружать веб-страницы. Данная статья написана для тех, кто только начинает работать с компьютерными сетями и заниматься разработкой сетевых приложений, и кому пока что сложно самостоятельно читать официальные спецификации.
HTTP — широко распространённый протокол передачи данных, изначально предназначенный для передачи гипертекстовых документов (то есть документов, которые могут содержать ссылки, позволяющие организовать переход к другим документам).
Аббревиатура HTTP расшифровывается как HyperText Transfer Protocol, «протокол передачи гипертекста». В соответствии со спецификацией OSI, HTTP является протоколом прикладного (верхнего, 7-го) уровня. Актуальная на данный момент версия протокола, HTTP 1.1, описана в спецификации RFC 2616.
Протокол HTTP предполагает использование клиент-серверной структуры передачи данных. Клиентское приложение формирует запрос и отправляет его на сервер, после чего серверное программное обеспечение обрабатывает данный запрос, формирует ответ и передаёт его обратно клиенту. После этого клиентское приложение может продолжить отправлять другие запросы, которые будут обработаны аналогичным образом.
Задача, которая традиционно решается с помощью протокола HTTP — обмен данными между пользовательским приложением, осуществляющим доступ к веб-ресурсам (обычно это веб-браузер) и веб-сервером. На данный момент именно благодаря протоколу HTTP обеспечивается работа Всемирной паутины.
Также HTTP часто используется как протокол передачи информации для других протоколов прикладного уровня, таких как SOAP, XML-RPC и WebDAV. В таком случае говорят, что протокол HTTP используется как «транспорт».
API многих программных продуктов также подразумевает использование HTTP для передачи данных — сами данные при этом могут иметь любой формат, например, XML или JSON.
Как правило, передача данных по протоколу HTTP осуществляется через TCP/IP-соединения. Серверное программное обеспечение при этом обычно использует TCP-порт 80 (и, если порт не указан явно, то обычно клиентское программное обеспечение по умолчанию использует именно 80-й порт для открываемых HTTP-соединений), хотя может использовать и любой другой.
Как отправить HTTP-запрос?
Самый простой способ разобраться с протоколом HTTP — это попробовать обратиться к какому-нибудь веб-ресурсу вручную. Представьте, что вы браузер, и у вас есть пользователь, который очень хочет прочитать статьи Анатолия Ализара.
Предположим, что он ввёл в адресной строке следующее:
Соответственно вам, как веб-браузеру, теперь необходимо подключиться к веб-серверу по адресу alizar.habrahabr.ru.
Для этого вы можете воспользоваться любой подходящей утилитой командной строки. Например, telnet:
telnet alizar.habrahabr.ru 80
Сразу уточню, что если вы вдруг передумаете, то нажмите Ctrl + «]», и затем ввод — это позволит вам закрыть HTTP-соединение. Помимо telnet можете попробовать nc (или ncat) — по вкусу.
После того, как вы подключитесь к серверу, нужно отправить HTTP-запрос. Это, кстати, очень легко — HTTP-запросы могут состоять всего из двух строчек.
Для того, чтобы сформировать HTTP-запрос, необходимо составить стартовую строку, а также задать по крайней мере один заголовок — это заголовок Host, который является обязательным, и должен присутствовать в каждом запросе. Дело в том, что преобразование доменного имени в IP-адрес осуществляется на стороне клиента, и, соответственно, когда вы открываете TCP-соединение, то удалённый сервер не обладает никакой информацией о том, какой именно адрес использовался для соединения: это мог быть, например, адрес alizar.habrahabr.ru, habrahabr.ru или m.habrahabr.ru — и во всех этих случаях ответ может отличаться. Однако фактически сетевое соединение во всех случаях открывается с узлом 212.24.43.44, и даже если первоначально при открытии соединения был задан не этот IP-адрес, а какое-либо доменное имя, то сервер об этом никак не информируется — и именно поэтому этот адрес необходимо передать в заголовке Host.
Стартовая (начальная) строка запроса для HTTP 1.1 составляется по следующей схеме:
Например (такая стартовая строка может указывать на то, что запрашивается главная страница сайта):
Метод (в англоязычной тематической литературе используется слово method, а также иногда слово verb — «глагол») представляет собой последовательность из любых символов, кроме управляющих и разделителей, и определяет операцию, которую нужно осуществить с указанным ресурсом. Спецификация HTTP 1.1 не ограничивает количество разных методов, которые могут быть использованы, однако в целях соответствия общим стандартам и сохранения совместимости с максимально широким спектром программного обеспечения как правило используются лишь некоторые, наиболее стандартные методы, смысл которых однозначно раскрыт в спецификации протокола.
URI (Uniform Resource Identifier, унифицированный идентификатор ресурса) — путь до конкретного ресурса (например, документа), над которым необходимо осуществить операцию (например, в случае использования метода GET подразумевается получение ресурса). Некоторые запросы могут не относиться к какому-либо ресурсу, в этом случае вместо URI в стартовую строку может быть добавлена звёздочка (астериск, символ «*»). Например, это может быть запрос, который относится к самому веб-серверу, а не какому-либо конкретному ресурсу. В этом случае стартовая строка может выглядеть так:
Версия определяет, в соответствии с какой версией стандарта HTTP составлен запрос. Указывается как два числа, разделённых точкой (например 1.1).
Для того, чтобы обратиться к веб-странице по определённому адресу (в данном случае путь к ресурсу — это «/»), нам следует отправить следующий запрос:
GET / HTTP/1.1
Host: alizar.habrahabr.ru
При этом учитывайте, что для переноса строки следует использовать символ возврата каретки (Carriage Return), за которым следует символ перевода строки (Line Feed). После объявления последнего заголовка последовательность символов для переноса строки добавляется дважды.
Впрочем, в спецификации HTTP рекомендуется программировать HTTP-сервер таким образом, чтобы при обработке запросов в качестве межстрочного разделителя воспринимался символ LF, а предшествующий символ CR, при наличии такового, игнорировался. Соответственно, на практике бо́льшая часть серверов корректно обработает и такой запрос, где заголовки отделены символом LF, и он же дважды добавлен после объявления последнего заголовка.
Если вы хотите отправить запрос в точном соответствии со спецификацией, можете воспользоваться управляющими последовательностями \r и \n:
Как прочитать ответ?
Стартовая строка ответа имеет следующую структуру:
Версия протокола здесь задаётся так же, как в запросе.
Код состояния (Status Code) — три цифры (первая из которых указывает на класс состояния), которые определяют результат совершения запроса. Например, в случае, если был использован метод GET, и сервер предоставляет ресурс с указанным идентификатором, то такое состояние задаётся с помощью кода 200. Если сервер сообщает о том, что такого ресурса не существует — 404. Если сервер сообщает о том, что не может предоставить доступ к данному ресурсу по причине отсутствия необходимых привилегий у клиента, то используется код 403. Спецификация HTTP 1.1 определяет 40 различных кодов HTTP, а также допускается расширение протокола и использование дополнительных кодов состояний.
Пояснение к коду состояния (Reason Phrase) — текстовое (но не включающее символы CR и LF) пояснение к коду ответа, предназначено для упрощения чтения ответа человеком. Пояснение может не учитываться клиентским программным обеспечением, а также может отличаться от стандартного в некоторых реализациях серверного ПО.
После стартовой строки следуют заголовки, а также тело ответа. Например:
Тело ответа следует через два переноса строки после последнего заголовка. Для определения окончания тела ответа используется значение заголовка Content-Length (в данном случае ответ содержит 7 восьмеричных байтов: слово «Wisdom» и символ переноса строки).
Но вот по тому запросу, который мы составили ранее, веб-сервер вернёт ответ не с кодом 200, а с кодом 302. Таким образом он сообщает клиенту о том, что обращаться к данному ресурсу на данный момент нужно по другому адресу.
В заголовке Location передан новый адрес. Теперь URI (идентификатор ресурса) изменился на /users/alizar/, а обращаться нужно на этот раз к серверу по адресу habrahabr.ru (впрочем, в данном случае это тот же самый сервер), и его же указывать в заголовке Host.
GET /users/alizar/ HTTP/1.1
Host: habrahabr.ru
В ответ на этот запрос веб-сервер Хабрахабра уже выдаст ответ с кодом 200 и достаточно большой документ в формате HTML.
Если вы уже успели вжиться в роль, то можете теперь прочитать полученный от сервера HTML-код, взять карандаш и блокнот, и нарисовать профайл Ализара — в принципе, именно этим бы на вашем месте браузер сейчас и занялся.
А что с безопасностью?
Сам по себе протокол HTTP не предполагает использование шифрования для передачи информации. Тем не менее, для HTTP есть распространённое расширение, которое реализует упаковку передаваемых данных в криптографический протокол SSL или TLS.
Название этого расширения — HTTPS (HyperText Transfer Protocol Secure). Для HTTPS-соединений обычно используется TCP-порт 443. HTTPS широко используется для защиты информации от перехвата, а также, как правило, обеспечивает защиту от атак вида man-in-the-middle — в том случае, если сертификат проверяется на клиенте, и при этом приватный ключ сертификата не был скомпрометирован, пользователь не подтверждал использование неподписанного сертификата, и на компьютере пользователя не были внедрены сертификаты центра сертификации злоумышленника.
На данный момент HTTPS поддерживается всеми популярными веб-браузерами.
А есть дополнительные возможности?
Протокол HTTP предполагает достаточно большое количество возможностей для расширения. В частности, спецификация HTTP 1.1 предполагает возможность использования заголовка Upgrade для переключения на обмен данными по другому протоколу. Запрос с таким заголовком отправляется клиентом. Если серверу требуется произвести переход на обмен данными по другому протоколу, то он может вернуть клиенту ответ со статусом «426 Upgrade Required», и в этом случае клиент может отправить новый запрос, уже с заголовком Upgrade.
Такая возможность используется, в частности, для организации обмена данными по протоколу WebSocket (протокол, описанный в спецификации RFC 6455, позволяющий обеим сторонам передавать данные в нужный момент, без отправки дополнительных HTTP-запросов): стандартное «рукопожатие» (handshake) сводится к отправке HTTP-запроса с заголовком Upgrade, имеющим значение «websocket», на который сервер возвращает ответ с состоянием «101 Switching Protocols», и далее любая сторона может начать передавать данные уже по протоколу WebSocket.
Что-то ещё, кстати, используют?
На данный момент существуют и другие протоколы, предназначенные для передачи веб-содержимого. В частности, протокол SPDY (произносится как английское слово speedy, не является аббревиатурой) является модификацией протокола HTTP, цель которой — уменьшить задержки при загрузке веб-страниц, а также обеспечить дополнительную безопасность.
Увеличение скорости обеспечивается посредством сжатия, приоритизации и мультиплексирования дополнительных ресурсов, необходимых для веб-страницы, чтобы все данные можно было передать в рамках одного соединения.
Опубликованный в ноябре 2012 года черновик спецификации протокола HTTP 2.0 (следующая версия протокола HTTP после версии 1.1, окончательная спецификация для которой была опубликована в 1999) базируется на спецификации протокола SPDY.
Многие архитектурные решения, используемые в протоколе SPDY, а также в других предложенных реализациях, которые рабочая группа httpbis рассматривала в ходе подготовки черновика спецификации HTTP 2.0, уже ранее были получены в ходе разработки протокола HTTP-NG, однако работы над протоколом HTTP-NG были прекращены в 1998.
На данный момент поддержка протокола SPDY есть в браузерах Firefox, Chromium/Chrome, Opera, Internet Exporer и Amazon Silk.
И что, всё?
В общем-то, да. Можно было бы описать конкретные методы и заголовки, но фактически эти знания нужны скорее в том случае, если вы пишете что-то конкретное (например, веб-сервер или какое-то клиентское программное обеспечение, которое связывается с серверами через HTTP), и для базового понимания принципа работы протокола не требуются. К тому же, всё это вы можете очень легко найти через Google — эта информация есть и в спецификациях, и в Википедии, и много где ещё.
Впрочем, если вы знаете английский и хотите углубиться в изучение не только самого HTTP, но и используемых для передачи пакетов TCP/IP, то рекомендую прочитать вот эту статью.
Ну и, конечно, не забывайте, что любая технология становится намного проще и понятнее тогда, когда вы фактически начинаете ей пользоваться.



