Kibana
Kibana – это инструмент визуализации и изучения данных, который применяется для таких задач, как анализ журналов и временных рядов, мониторинг приложений и текущих процессов. Он предлагает мощные и простые в использовании возможности: гистограммы, линейные графики, круговые диаграммы, тепловые карты и встроенную геопространственную поддержку. Кроме того, обеспечивает тесное взаимодействие с Elasticsearch, популярной аналитической и поисковой системой, за счет чего Kibana по умолчанию выступает как инструмент визуализации хранящихся в Elasticsearch данных.
21 января 2021 года Elastic NV объявила об изменении стратегии лицензирования программного обеспечения и о том, что новые версии Elasticsearch и Kibana под разрешительной лицензией Apache версии 2.0 (ALv2) выходить не будут. Вместо них предложены новые версии программного обеспечения по лицензии Elastic, а исходный код доступен по лицензии Elastic или SSPL. Эти лицензии не являются открытыми исходными кодами и не дают пользователям ту же свободу. Желая предоставить специалистам, которые работают с открытым исходным кодом, и нашим клиентам безопасный высококачественный комплект инструментов для поиска и аналитики с полностью открытым исходным кодом, мы создали проект OpenSearch – развиваемая сообществом ветвь открытого исходного кода Elasticsearch и Kibana с лицензией ALv2. Комплект OpenSearch состоит из поискового движка, OpenSearch и интерфейса визуализации и пользовательского интерфейса OpenSearch Dashboards.
Версии Kibana с лицензией Apache 2.0 (до версии 7.10.2) можно запускать локально, на Amazon EC2 или в Amazon OpenSearch Service (преемник Amazon Elasticsearch Service). OpenSearch Dashboards – это альтернатива Kibana с открытым исходным кодом, доступная для самостоятельного управления. Сервис создан на базе последней версии Kibana с открытым исходным кодом (7.10.2), включает в себя множество новшеств и успешно поддерживается проектом OpenSearch. При развертывании локально или на Amazon EC2 вы несете ответственность за подготовку и управление инфраструктурой и установку программного обеспечения Kibana или OpenSearch Dashboards. Благодаря Amazon OpenSearch Service Kibana или OpenSearch Dashboards автоматически развертываются вместе с вашим доменом как полностью управляемые сервисы и берут на себя всю тяжелую работу по управлению кластером.
Преимущества Kibana
Интерактивные схемы
Kibana предлагает интуитивно понятные схемы и отчеты, которые можно использовать для интерактивной навигации по большим объемам данных журналов. Вы можете динамически перемещать временные окна, увеличивать и уменьшать масштаб определенных подмножеств данных и детализировать отчеты, чтобы получить полезные выводы из своих данных.
Поддержка привязки
Kibana предлагает мощные геопространственные возможности, позволяя с легкостью накладывать географическую информацию поверх данных и визуализировать результаты на картах.
Встроенные агрегаторы и фильтры
Используя встроенные агрегаторы и фильтры Kibana, можно в несколько кликов запускать различные аналитические функции, такие как гистограммы, запросы top-N и тенденции.
Легкодоступные панели управления
Вы можете легко настраивать панели управления и отчеты и делиться ими с другими. Все, что потребуется – это браузер для просмотра и изучения данных.
Начало работы с Kibana на AWS
Подробнее о ценах на Amazon OpenSearch Service
Руководство пользователя Kibana. Визуализация. Часть 1
Доброго времени суток. Всем пользователям ElasticStack рано или поздно нужно визуализировать данные. Большинство использует Kibana. Под катом перевод официальной документации для версии 6.6.
Creating a Visualization
Чтобы создать визуализацию:
4. Укажите поисковый запрос, с которого будет идти получение данных для вашей визуализации:
5. В конструкторе визуализаций выберите метрику агрегации для оси Y визуализации:
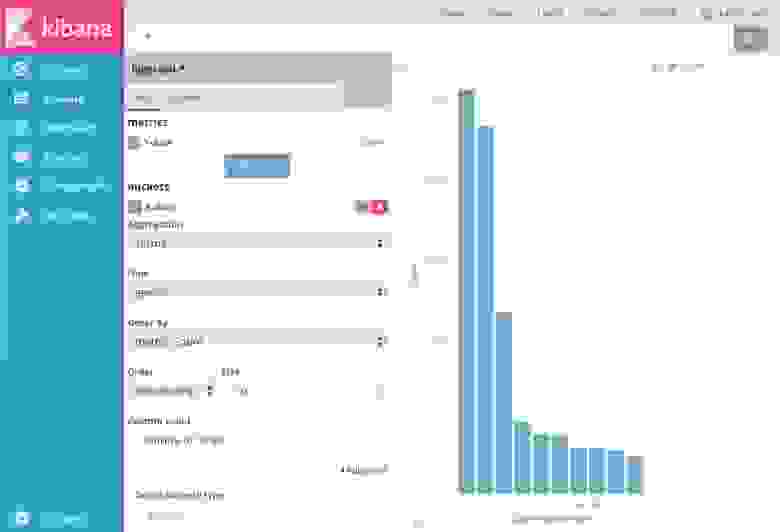
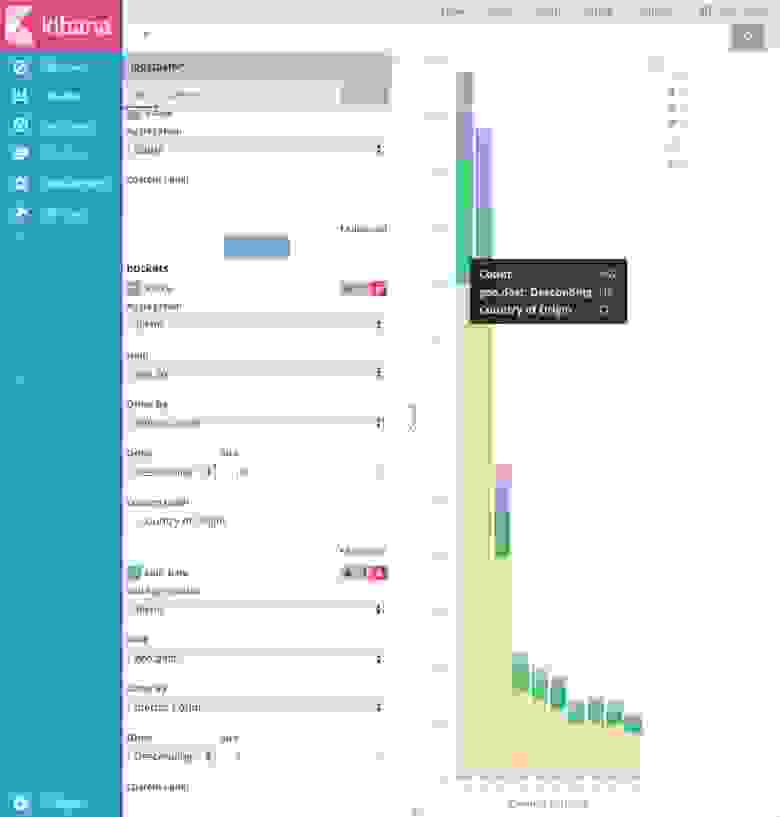
Для дополнительной информации по работе с подгруппами агрегаций смотри Kibana, Aggregation Execution Order, and You.
Line, Area, and Bar charts
Грфик, площадь и гистограмма позволяют строить схемы данных по X/Y осях.
Сначала вам нужно выбрать метрики, что определяют значения осей.
Метрические агрегации:
Count. Агрегация подсчета возвращает чистый подсчет элементов в выбранном шаблоне индекса.
Average. Данная агрегация возвращает среднее значение по числовому полю. Выбирайте поле из выпадающего списка.
Sum. Возвращает общую сумму по числовому полю. Выбирайте поле из выпадающего списка.
Min. Возвращает минимальное значение по числовому полю. Выбирайте поле из выпадающего списка.
Max. Возвращает максимальное значение по числовому полю. Выбирайте поле из выпадающего списка.
Unique Count. Кардинальная агрегация возвращает число уникальных значений в поле. Выбирайте поле из выпадающего списка.
Standard Deviation. Агрегация общей статистики возвращает стандартное отклонение данных в числовом поле. Выбирайте поле из выпадающего списка.
Top Hit. Агрегация топовых значений возвращает один или больше топовых значений из специального поля в вашем документе. Выбирайте поле из выпадающего списка, тип сортировки документов, количество значений, которые нужно вернуть.
Percentiles. Агрегация процентов разделяет значения числового поля на заданные диапазоны. Выбирайте поле из выпадающего списка, затем определите одну или больше областей в полях Percentiles. Кликните X для удаления поля процентов. Кликните Add для добавления процентного поля.
Percentile Rank. Агрегация процентного ранга возвращает процентное ранжирование по выбранному числовому полю. Выбирайте поле из выпадающего списка, затем определите один или больше значений процентного ранга в полях Values. Кликните X для удаления поля значения. Кликните +Add для добавления поля значений.
Агрегации родительских источников данных:
Для каждой агрегации родительского источника информации необходимо определить метрику, для которой агрегация высчитана. Это может быть одна из уже существующих метрик или новая. Вы также можете вкладывать эти агрегации (к примеру, для получения третей производной).
Derivative. Агрегация производной подсчитывает производную определенных метрик.
Cumulative Sum. Агрегация накопительной суммы подсчитывает накопительную сумму определенных метрик в родительской гистограмме.
Moving Average. Агрегация скользящего среднего будет вставлять окно сквозь данные и писать среднее значение этого окна.
Serial Diff. Последовательное дифференцирование — это метод, где значения во временном ряде отнимаются от самых себя в другой временной период или задержки.
Агрегации родственного источника:
Как и в случае с агрегациями родительских источников, вам необходимо указать метрику по которой будет высчитываться агрегация родственного источника. Кроме этого, вам необходимо предусмотреть агрегацию сегментов, которая будет определять на каких сегментах агрегация будет запускаться.
Average Bucket. Среднее сегмента вычисляет среднее значение определенных метрик в агрегации родственных источников.
Sum Bucket. Высчитывает сумму значений определенной метрики в агрегации родственного источника.
Min Bucket. Возвращает минимальное значение определенной метрики в агрегации родственного источника.
Max Bucket. Возвращает максимальное значение определенной метрики в агрегации родственного источника.
Вы можете создать агрегацию кликнув на кнопке + Add Metrics.
Введите строку в поле Custom Label, чтобы изменить подпись.
Агрегации сегментов определяют, какая информация будет извлекаться с ваших данных.
До того как вы выберете агрегацию сегмента, укажите, разделяете ли вы срезы в пределах одной схемы или разбиваете на несколько схем. Разделение на несколько схем должно выполнятся перед любыми другими агрегациями. Когда вы разделяете схему, вы можете изменить если разделения выводятся в строке или столбце, кликнув переключатель Rows | Columns.
Ось X этой схемы является осью сегмента. Вы можете определить сегменты для оси X для отдельной области схемы или для отдельных схем.
Эта ось X схемы поддерживает следующие агрегации. Кликните связанное имя этой агрегации для перехода на документацию Elasticsearch по этой агрегации.
Date Histogram. Временная гистограмма построена на основе числового поля и организована по дате. Вы можете определить временные рамки для интервалов в секундах, минутах, часах, днях, неделях, месяцах или годах. Вы также можете определить интервал по умолчанию, выбрав Custom в качестве интервала и указав число и единицу времени в текстовом поле. По умолчанию единицами временного интервала являются: s для секунд, m для минут, h для часов, d для дней, w для недель, y для лет. Различные единицы поддерживают различные уровни точности, вплоть до одной секунды. Интервалы подписываются в начале интервала, используя ключ-дату, который возвращается из Elasticsearch. Для примера, на всплывающей подсказке для месячного интервала будет отображаться первый день месяца.
Histogram. Стандартная гистограмма строится на основе числового поля. Определите целочисленный интервал для этого поля. Установите флажок Show empty buckets, чтобы включить пустые интервалы в гистограмму.
Range. С помощью агрегации рангов вы можете определить ранги для значений числового поля. Кликните Add Range для добавления набора конечных точек ранга. Кликните красный символ (x), чтобы удалить ранг.
Date Range. Агрегация временного ранга сообщает значения, которые находятся в указанном диапазоне дат. Вы можете указать диапазоны дат, используя математические выражения даты. Кликните Add Range, чтобы добавить набор конечных точек ранга. Кликните красный символ (x), чтобы удалить ранг.
IPv4 Range. Агрегация IPv4 ранга позволяет вам определить диапазоны IPv4 адресов. Кликните Add Range, чтобы добавить набор конечных точек ранга. Кликните красный символ (x), чтобы удалить ранг.
Terms. Агрегация значений позволяет вам определить верхние или нижние n элементов данного поля для отображения, упорядоченные по количеству или пользовательской метрике.
Filters. Вы можете определить набор фильтров для данных. Возможно указать фильтр как строку запроса или в формате JSON, так же как и в поисковой вкладке Discover. Кликните Add Filter, чтобы добавить другой фильтр. Кликните кнопку label, чтобы открыть поле подписи, где вы можете напечатать имя для отображения на визуализации.
Significant Terms. Выводит результаты экспериментальной агрегации знаковых значений.
Однажды определив агрегацию оси X, вы можете определить подгруппы агрегаций для улучшения визуализации. Кликните + Add Sub Aggregation для создания вложенной агрегации, затем выберите Split Area или Split Chart, затем выберите вложенную агрегацию из списка типов.
Когда сложные агрегации определенны на осях схемы, вы можете использовать стрелки вверх или вниз справа от типа агрегации что бы изменить приоритет агрегации.
Введите строку в поле Custom Label что бы изменить подпись.
Вы можете настроить цвета вашей визуализации, кликнув цветную точку рядом с каждой подписью что бы отобразить цветовую палитру.

Введите строку в поле Custom Label что бы изменить надпись.
Вы можете кликнуть по ссылке Advanced что бы отобразить больше опций для ваших метрик или агрегации сегмента:
Exclude Pattern. Укажите шаблон в этом поле что бы исключить с результатов.
Include Pattern. Укажите шаблон в этом поле что бы включить в результаты.
JSON Input. Текстовое поле, где вы можете добавить специфичные свойства в формате JSON для слияния с определенной агрегацией, как нижеследующем примере:
Примечание. В Elasticsearch 1.4.3 и позже этот функционал нуждается во включенном динамическом скриптинге Groovy.
Доступность этих параметров зависит от выбранной вами агрегации.
Метрики и оси
Выберите вкладку Metrics & Axes для изменения способа, которым индивидуальная метрика отображается на схеме. Наборы данных стилизованы в секции Метрики, в то время как оси стилизованы в секции осей X и Y.
Метрики
Изменение способа отображения каждой метрики на панели Данные на схеме.
Chart type. Выберите между Графиком, Площадью и Гистограммой.
Mode. Стек различных метрик или отображать их рядом друг с другом.
Value Axis. Выберите ось, для которой вы хотите построить данные (свойства каждой из них настраиваются под осью Y).
Line mode. Должен ли контур графиков или гистограмм быть ровным, прямым или ступенчатым.
Ось Y
Стиль всех осей Y схемы.
Position. Позиция оси Y (слева или справа для вертикальной схемы и сверху или внизу для горизонтальной схемы).
Scale type. Масштабирование значений (линейное, логарифмическое или квадратичное).
Labels — Show Labels. Позволяет вам скрывать подписи осей.
Labels — Filter Labels. Если фильтр подписей включен некоторые подписи будут скрыты в случае недостатка пространства для отображения их.
Labels — Rotate. Вы можете ввести число градусов, на которое вы хотите обернуть подписи.
Labels — Truncate. Вы можете ввести количество пикселей, до которого подписи подгоняются.
Scale to Data Bounds. По умолчанию границы оси Y равны нулю и максимальному значению, которое возвращается из данных. Установите этот флажок что бы изменить обе, верхнюю и нижнюю, границы соответственно значениям, что возвращаются из данных.
Custom Extents. Вы можете определить свои значения максимума и минимума для каждой оси.
Ось X
Position. Позиция оси X (слева или справа для горизонтальной схемы и сверху или внизу для вертикальной схемы).
Advanced Options:
Labels — Show Labels. Позволяет вам скрывать подписи осей.
Labels — Filter Labels. Если фильтр подписей включен некоторые подписи будут скрыты в случае недостатка пространства для отображения их.
Labels — Rotate. Вы можете ввести число градусов, на которое вы хотите обернуть подписи.
Labels — Truncate. Вы можете ввести количество пикселей, до которого подписи подгоняются.
Панель настроек
Здесь находятся параметры, которые применяются ко всей схеме, а не только к отдельными рядам данных.
Общие параметры
Legend Position. Переместить легенду влево, вправо, вверх или вниз.
Show Tooltip. Включить или выключить отображение всплывающей подсказки при наведении на объект схемы.
Current Time Marker. Показать строку текущего времени.
Варианты сетки
Вы можете включить сетку на схеме. По умолчанию, сетка выводится только на оси категорий.
Ось X. Вы можете отключить сетку оси категорий.
Ось Y. Вы можете выбрать на каких осях значений вы будете отображать линии сетки.
5 причин, которые заставят тебя использовать Kibana
Во многих компаниях для сбора и анализа логов используют такой инструмент как Kibana. Но существует проблема которая выражается в том, что этим инструментом редко или почти не пользуются. Почему же так происходит? Дело в том, что человек привык анализировать логи непосредственно на инстансе. Читать логи так сказать из первоисточника. Безусловно это самый лучший способ. И мало кто не любит менять свои привычки. Потому что это своего рода выход из зоны комфорта и к этому не все и не всегда готовы.
Кейсы чтения логов
Но бывают ситуации, когда нет возможности зайти непосредственно на инстанс. Например необходимо проанализировать инцидент случившийся на продакшене и у нас нет доступа к этому окружению по известным всем причинам. Другая ситуация, если сервис работает на операционной системе Windows, а доступ нужен для трех и более сотрудников одновременно. Как мы все хорошо знаем у компании Windows есть политика одновременной работы не более двух человек при входе по RDP (Remote Desktop Protocol). Для того чтобы получить одновременный доступ по RDP большему количеству сотрудников, необходимо купить лицензию, а на это готова пойти далеко не каждая компания.
Стек ELK
Таким образом мы возвращаемся к нашему замечательному инструменту Kibana. Kibana это часть стека ELK, в который помимо неё входят Elasticsearch и Logstash. Kibana используется не только для визуализации данных в различных форматах, но также и для быстрого поиска и анализа логов. И сегодня речь пойдет о том, как комфортно перейти на этот инструмент и какие у него есть скрытые возможности для этого.
Способы и лайфхаки
Для начала можно ввести в поле Search номер какой-нибудь операции и выбрать промежуток времени за который необходимо произвести поиск. В результате этого запроса отобразиться временной график с количеством совпадений этого номера.
Так же можно составлять сложные поисковые запросы. Существует специальный язык запросов, называемый KQL (Kibana Query Language). С помощью этого языка можно составлять многоуровневые запросы, которые помогают отфильтровывать нужную информацию. Например можно выбрать тестовое окружение и задать конкретное его имя. Если необходимо найти какое-нибудь словосочетание, то нам на помощь приходят двойные кавычки. При заключении двух и более слов в двойные кавычки происходит поиск всей фразы целиком.
Более подробную информацию по составлению сложных запросов можно найти на официальном сайте elastic. Для тех кто привык изучать логи в хронологическом порядке, в Kibana тоже есть такая возможность. При нахождении конкретной ошибки в нашем логе, хотелось бы увидеть что происходило до этого и после. Для этого необходимо кликнуть на найденный фрагмент лога и далее нажать на Просмотр. Перед вами откроется список логов, в котором ваш запрос будет подсвечен серым цветом. И будет загружено несколько строчек лога которые предшествовали нашей ошибке.
Эти логи будут внизу. И несколько строчек которые были после нашей ошибки. Эти строчки будут выше нашей ошибки. В Kibana логи читаются снизу вверх в отличии от логов на инстансе, где логи идут сверху вниз. По умолчанию загружаются 5 строчек до и 5 после, но это значение можно изменить и затем нажать кнопку Загрузка. После чего произойдет загрузка указанного количества строк лога выше нашей ошибки. Тоже самое можно сделать и с предыдущими логами.
Дефолтное значение 5 можно изменить в настройках системы перейдя Stack Management > Advanced Settings
Заключение
В данной статье я не преследовал цель научить пользоваться инструментом Kibana. В интернете очень много подробных статей и видео об этом. Да и на официальном сайте elastic есть предостаточно информации. Мне хотелось показать, как комфортно и без особых усилий можно начать пользоваться другим способом чтения логов. И при этом можно решить одновременно несколько задач, начиная от выхода из зоны комфорта и заканчивая сложнейшими запросами в совокупности с быстродействием получения результата.
В преддверии старта курса «Java QA Engineer. Basic» приглашаем всех желающих на двухдневный онлайн-интенсив «Теория тестирования и практика в системах TestIT и Jira».
На интенсиве вы узнаете, что такое тестирование и откуда оно появилось, кто такой тестировщик и что он делает. Изучим модели разработки ПО, жизненный цикл тестирования, чек листы и тест-кейсы, а также дефекты. На втором занятии познакомимся с одним из главных трекеров задач и дефектов — Jira, а также попрактикуемся в TestIT — отечественной разработке для решения задач по тестированию и обеспечению качества ПО.
Русские Блоги
Кибана: как использовать панель поиска
Как искать
В панели поиска Kibana есть три способа поиска:


Когда мы выключаем переключатель KQL, он становится следующим:

Ниже мы опишем, как использовать их для нашего поиска отдельно.
Что такое шаблон индекса?
Шаблон индекса: он указывает на один или несколько индексов Elasticsearch и сообщает Kibana, с какими индексами работать.

тип данных
Для Elasticsearch существует два типа данных, которые можно анализировать:
Когда мы создаем наш собственный шаблон индекса, нам нужно выбрать наш тип данных:



Выше мы должны ввести соответствующий шаблон индекса в соответствии с именем нашего собственного индекса. Он может указывать на один индекс или на несколько индексов через символы подстановки. Если ваш индекс содержит поля, относящиеся ко времени, Kibana автоматически отобразит опцию, позволяющую нам выбрать, нужен ли Time Filter:

Если мы выберем поле Time Filter, оно будет обработано в соответствии с методом временных рядов. В противном случае мы можем отказаться от использования фильтра времени, тогда мы можем только искать в индексе и не выполнять операции, связанные с временным рядом. Ввиду этой ситуации средство выбора времени, которое мы представляем ниже, больше не будет применяться.
Если мы хотим удалить шаблон индекса, мы также можем выбрать удаление на странице выше:

Подготовить данные
Мы можем использовать данные, поставляемые с Kibana, для демонстрации. Мы загружаем данные следующим образом:

Выбрать»Add sample data”:

Мы выбираем»Add datamsgstr «, чтобы мы могли загрузить нужные нам образцы данных в Elasticsearch.
Прежде чем искать, мы должны понять две важные вещи:

Кибана поиск
Давайте сначала посмотрим на документ, проиндексированный нашими kibana_sample_data_flights.
Как я упоминал выше, мы сначала выбираем наш индекс, а затем устанавливаем время, соответствующее нашему методу времени.

KQL способ поиска:

Выше мы видим, что когда мы используем KQL, большое преимущество заключается в том, что он может помочь нам автоматически запрашивать поля, которые мы хотим найти. Например, когда мы наступим на следующий день, Kibana автоматически откроет варианты, чтобы мы могли выбрать.
Мы даже можем напечатать нужную строку, например Baidu, без использования специального поля:

Мы также можем использовать шаблоны для выполнения нечетких поисков:

Кавычки вокруг поискового запроса инициируют поиск по фразе. Например, сообщение «Быстрый коричневый лис» будет искать фразу «быстрый коричневый лис» в поле сообщения. Без кавычек ваш запрос будет разбит на токены анализатором, настроенным в поле сообщения, и будет сопоставлять документы, содержащие эти токены, независимо от порядка их появления. Это означает, что документы с «быстрой коричневой лисой» будут совпадать, но «быстрая коричневая лиса» также будет совпадать. Если вы хотите найти фразу, не забудьте использовать кавычки. При поиске фразы порядок каждого токена очень важен.
Анализатор запросов больше не будет разбиваться на пустое пространство. Несколько поисковых терминов должны быть разделены явными логическими операторами. Lucene объединяет условия поиска с или по умолчанию. Эти логические операторы являются или, и не и.

Вышеуказанный поиск вернет все документы, для которых dayofWeek равен 1 или OriginCountry имеет значение «DE». Если мы хотим искать документы, которые удовлетворяют обоим этим условиям, мы можем использовать и

Очевидно, в это время мы видели только 23 документа, намного меньше, чем раньше. Мы также можем использовать, чтобы не возвращать неоперации. Например, если мы хотим получить все документы, где OriginCountry не является DE, мы можем напрямую искать не OriginCountry: «DE»

Мы также можем искать поле по диапазону, например:

Поиск Lucene:
Чтобы иметь возможность искать в режиме Lucene, мы должны переключиться в режим Lucence. Таким образом, когда мы вводим поле в поле ввода без запроса, мы не можем помочь нам завершить ввод автоматически.

Мы можем искать ряд документов:

Выше, если мы не хотим включать 3, мы должны написать: dayOfWeek: [0 TO 3>. Вы также можете написать любое значение от 3 и выше:

Мы также можем выполнить поиск всех документов, для которых OriginCountry является США или DE, в соответствии со следующим методом.

Или нечеткий запрос:

Или только одна правкаНечеткий запрос:

Вы также можете использовать подстановочные знаки? Чтобы соответствовать любому письму (обратите внимание, что это не доступно в KQL):


Точно так же мы можем использовать обычный запрос, чтобы иметь 0 или 1 букву:

Вы также можете использовать. * Обычный, чтобы соответствовать 0 или более букв:



