Медиана в статистике
Центральную тенденцию данных можно рассматривать не только, как значение с нулевым суммарным отклонением (среднее арифметическое) или максимальную частоту (мода), но и как некоторую отметку (значение в совокупности), делящую ранжированные данные (отсортированные по возрастанию или убыванию) на две равные части. Половина исходных данных меньше этой отметки, а половина – больше. Это и есть медиана.
Итак, медиана в статистике – это уровень показателя, который делит набор данных на две равные половины. Значения в одной половине меньше, а в другой больше медианы. В качестве примера обратимся к набору нормально распределенных случайных чисел.

Очевидно, что при симметричном распределении середина, делящая совокупность пополам, будет находиться в самом центре – там же, где средняя арифметическая (и мода). Это, так сказать, идеальная ситуация, когда мода, медиана и средняя арифметическая совпадают и все их свойства приходятся на одну точку – максимальная частота, деление пополам, нулевая сумма отклонений – все в одном месте. Однако, жизнь не так симметрична, как нормальное распределение.
Допустим, мы имеем дело с техническими замерами отклонений от ожидаемой величины чего-нибудь (содержания элементов, расстояния, уровня, массы и т.д. и т.п.). Если все ОК, то отклонения, скорее всего, будут распределены по закону, близкому к нормальному, примерно, как на рисунке выше. Но если в процессе присутствует важный и неконтролируемый фактор, то могут появиться аномальные значения, которые в значительной мере повлияют на среднюю арифметическую, но при этом почти не затронут медиану.
Медиана выборки – это альтернатива средней арифметической, т.к. она устойчива к аномальным отклонениям (выбросам).
Математическим свойством медианы является то, что сумма абсолютных (по модулю) отклонений от медианного значения дает минимально возможное значение, если сравнивать с отклонениями от любой другой величины. Даже меньше, чем от средней арифметической, о как! Данный факт находит свое применение, например, при решении транспортных задач, когда нужно рассчитать место строительства объектов около дороги таким образом, чтобы суммарная длина рейсов до него из разных мест была минимальной (остановки, заправки, склады и т.д. и т.п.).
Формула медианы
Формула медианы в статистике для дискретных данных чем-то напоминает формулу моды. А именно тем, что формулы как таковой нет. Медианное значение выбирают из имеющихся данных и только, если это невозможно, проводят несложный расчет.
Первым делом данные ранжируют (сортируют по убыванию). Далее есть два варианта. Если количество значений нечетно, то медиана будет соответствовать центральному значению ряда, номер которого можно определить по формуле:

№Me – номер значения, соответствующего медиане,
N – количество значений в совокупности данных.
Тогда медиана обозначается, как

Это первый вариант, когда в данных есть одно центральное значение. Второй вариант наступает тогда, когда количество данных четно, то есть вместо одного есть два центральных значения. Выход прост: берется средняя арифметическая из двух центральных значений:

В интервальных данных выбрать конкретное значение не представляется возможным. Медиану рассчитывают по определенному правилу.
Для начала (после ранжирования данных) находят медианный интервал. Это такой интервал, через который проходит искомое медианное значение. Определяется с помощью накопленной доли ранжированных интервалов. Где накопленная доля впервые перевалила через 50% всех значений, там и медианный интервал.
Не знаю, кто придумал формулу медианы, но исходили явно из того предположения, что распределение данных внутри медианного интервала равномерное (т.е. 30% ширины интервала – это 30% значений, 80% ширины – 80% значений и т.д.). Отсюда, зная количество значений от начала медианного интервала до 50% всех значений совокупности (разница между половиной количества всех значений и накопленной частотой предмедианного интервала), можно найти, какую долю они занимают во всем медианном интервале. Вот эта доля аккурат переносится на ширину медианного интервала, указывая на конкретное значение, именуемое впоследствии медианой.
Обратимся к наглядной схеме.

Немного громоздко получилось, но теперь, надеюсь, все наглядно и понятно. Чтобы при расчете каждый раз не рисовать такой график, можно воспользоваться готовой формулой. Формула медианы имеет следующий вид:

где xMe — нижняя граница медианного интервала;
iMe — ширина медианного интервала;
∑f/2 — количество всех значений, деленное на 2 (два);
S(Me-1)— суммарное количество наблюдений, которое было накоплено до начала медианного интервала, т.е. накопленная частота предмедианного интервала;
fMe — число наблюдений в медианном интервале.
Как нетрудно заметить, формула медианы состоит из двух слагаемых: 1 – значение начала медианного интервала и 2 – та самая часть, которая пропорциональна недостающей накопленной доли до 50%.
Для примера рассчитаем медиану по следующим данным.

Требуется найти медианную цену, то есть ту цену, дешевле и дороже которой по половине количества товаров. Для начала произведем вспомогательные расчеты накопленной частоты, накопленной доли, общего количества товаров.

По последней колонке «Накопленная доля» определяем медианный интервал – 300-400 руб (накопленная доля впервые более 50%). Ширина интервала – 100 руб. Теперь остается подставить данные в приведенную выше формулу и рассчитать медиану.

То есть у одной половины товаров цена ниже, чем 350 руб., у другой половины – выше. Все просто. Средняя арифметическая, рассчитанная по этим же данным, равна 355 руб. Отличие не значительное, но оно есть.
Расчет медианы в Excel
Медиану для числовых данных легко найти, используя функцию Excel, которая так и называется — МЕДИАНА. Другое дело интервальные данные. Соответствующей функции в Excel нет. Поэтому нужно задействовать приведенную выше формулу. Что поделаешь? Но это не очень трагично, так как расчет медианы по интервальным данным – редкий случай. Можно и на калькуляторе разок посчитать.
Напоследок предлагаю задачку. Имеется набор данных. 15, 5, 20, 5, 10. Каково среднее значение? Четыре варианта:
Мода, медиана и среднее значение выборки – это разный способ определить центральную тенденцию в выборке.
Ниже видеоролик о том, как рассчитать медиану в Excel.
Описательная статистика для числовых переменных
6.2. Вывод статистических характеристик
Чтобы получить описательную статистику числовых переменных, можно щелкнуть в диалоге Frequencies на кнопке Statistics. (Статистика). Откроется диалоговое окно Frequencies: Statistics (Частоты: Статистика).
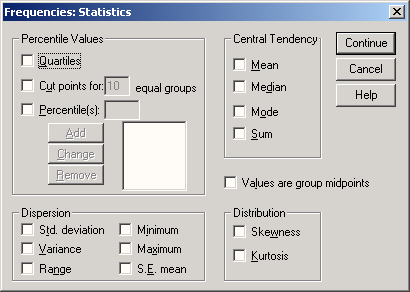
Рис. 6.2: Диалоговое окно frequencies: Statistics
В группе Percentile Values (Значения процентилей) можно выбрать следующие варианты:
Quartiles (Квартили): Будут показаны первый, второй и третий квартили. Первый квартиль (Q1) — это точка на шкале измеренных значений, ниже (левее) которой располагаются 25% измеренных значений. Второй квартиль (Q2) — это точка, ниже которой располагаются 50% измеренных значений. Второй квартиль также называется медианой. Третий квартиль (Q3) — это точка на шкале измеренных значений, ниже которой располагаются 75% значений. Если данные имеются только в форме порядкового отношения, то качестве меры разброса используется межквартильная широта. Она определяется как
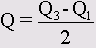
Cut points (Точки раздела): Будут вычислены значения процентилей, разделяющие выборку на группы наблюдений, которые имеют одинаковую ширину, то есть включают одно и то же количество измеренных значений. По умолчанию предлагается количество групп 10. Если задать, к примеру, 4, то будут показаны квартили, то есть квартили соответствуют процентилям 25, 50 и 75. Видно, что число показываемых процентилей на единицу меньше заданного числа групп.
Percentile(s) (Процентили): Здесь имеются в виду значения процентилей, определяемые пользователем. Введите значение процентиля в пределах от 0 до 100 и щелкните на кнопке Add (Добавить). Повторите эти действия для всех желаемых значений процентилей. Значения в порядке возрастания будут показаны в списке. Например, если ввести значения 25, 50 и 75, то мы получим квартили. Можно задавать любые значения процентилей, например, 37 и 83. В первом случае (37) будет показано значение выбранной переменной, ниже которого лежат 37% значений, а во втором случае (83) — значение, ниже которого располагаются 83% значений.
В группе Dispersion (Разброс) можно выбрать следующие меры разброса:
Std. deviation (Стандартное отклонение) — это мера разброса измеренных величин; оно равно квадратному корню из дисперсии. В интервале шириной, равной удвоенному стандартному отклонению, который отложен по обе стороны от среднего значения, располагается примерно 67% всех значений выборки, подчиняющейся нормальному распределению.
Variance (Дисперсия) — это квадрат стандартного отклонения и, следовательно, эта характеристика также является мерой разброса измеренных величин. О на определяется как сумма квадратов отклонений всех измеренных значений от их среднеарифметического значения, деленная на количество измерений минус 1.
Range (Размах) — это разница между наибольшим значением (максимумом) и наименьшим значением (минимумом).
Minimum (Минимум) — Наименьшее значение.
Maximum (Максимум) — Наибольшее значение.
Обычно мерами разброса переменных, относящихся к интервальной шкале и подчиняющихся нормальному распределению, служат стандартное отклонение и стандартная ошибка. Как было сказано выше, стандартное отклонение позволяет задать диапазон разброса отдельных значений. По так называемому правилу кулака, в одном диапазоне стандартного отклонения (охватывающем ширину стандартного отклонения в обе стороны от среднего значения) располагается примерно 67% значений, в диапазоне удвоенного стандартного отклонения — примерно 95%, а в диапазоне утроенного стандартного отклонения — примерно 99% значений.
С другой стороны, стандартная ошибка позволяет задать доверительный интервал для среднего значения. В диапазоне удвоенной стандартной ошибки по обе стороны от среднего значения с вероятностью примерно 95% находится среднее значение генеральной совокупности. С вероятностью примерно 99% она лежит в диапазоне утроенной стандартной ошибки. Часто указывают только одну из этих двух мер разброса, обычно — стандартную ошибку, так как ее значение меньше. Во всех случаях следует точно выяснить, какая из мер разброса имеется в виду.
В группе Central Tendency (Средние) можно выбрать следующие характеристики:
Mean (Среднее значение) — это арифметическое среднее измеренных значений; оно определяется как сумма значений, деленная на их количество. Например, если имеется 12 измеренных значений и их сумма составляет 600, то среднее значение будет х = 600 : 12 = 50.
Median (Медиана) — это точка на шкале измеренных значений, выше и ниже которой лежит по половине всех измеренных значений. Например, если измеренные значения таковы:
то сначала они располагаются в порядке возрастания: 23344567889.
В данном случае медианой будет значение 5. Всего у нас 11 измеренных значений, следовательно, медианой является шестое значение. Выше него располагается 5 значений, и ниже — тоже 5. При нечетном количестве значений медиана всегда будет совпадать с одним из измеренных значений. При четном количестве медиана будет средним арифметическим двух соседних значений. Например, если имеются следующие измеренные значения:
то медиана в этом случае будет равна: (6 + 7) : 2 = 6,5.
Mode (Мода) — это значение, которое наиболее часто встречается в выборке. Если одна и та же наибольшая частота встречается у нескольких значений, то выбирается наименьшее из них.
Sum (Сумма) — сумма всех значений.
В группе Distribution (Распределение) можно выбрать следующие меры несимметричности распределения:
Skewness (Коэффициент асимметрии) — это мера отклонения распределения частоты от симметричного распределения, то есть такого, у которого на одинаковом удалении от среднего значения по обе стороны выборки данных располагается одинаковое количество значений. Если наблюдения подчиняются нормальному распределению, то асимметрия равна нулю. Для проверки на нормальное распределение можно применять следующее правило: Если асимметрия значительно отличается от нуля, то гипотезу о том, что данные взяты из нормально распределенной генеральной совокупности, следует отвергнуть. Если вершина асимметричного распределения сдвинута к меньшим значениям, то говорят о положительной асимметрии, в противоположном случае — об отрицательной.
Kurtosis (Коэффициент вариации или эксцесс) — указывает, является ли распределение пологим (при большом значении коэффициента) или крутым. Коэффициент вариации равен нулю, если наблюдения подчиняются нормальному распределению. Поэтому для проверки на нормальное распределение можно применять еще одно правило: Если коэффициент вариации значительно отличается от нуля, то гипотезу о том, что данные взяты из нормально распределенной генеральной совокупности, следует отвергнуть.
Как правило, для переменных, относящихся к интервальной шкале и подчиняющихся нормальному распределению, в качестве основной характеристики используют среднее значение, а в качестве меры разброса — стандартное отклонение или стандартную ошибку. Для порядковых или интервальных переменных, не подчиняющихся нормальному распределению — соответственно медиану или первый и третий квартили. Для переменных относящихся к номинальной шкале, нельзя дать других значимых характеристик кроме моды.
В диалоге есть еще один флажок:
Values are group midpoints (Значения являются средними точками групп): Если установить этот флажок, то при вычислении медианы и остальных значений процентилей оценки этих характеристик будут определяться для концентрированных данных. Этому вопросу посвящен отдельный раздел.
Для переменной alter (возраст) мы определим следующие характеристики: среднее значение, медиану, моду, квартили, стандартное отклонение, дисперсию, размах, минимум, максимум, стандартную ошибку, асимметрию и эксцесс. Поступите следующим образом:
Выберите в меню команды Analyze (Анализ) / Descriptive Statistics (Дескриптивные статистики) / Frequencies. (Частоты)
В диалоге Frequencies щелкните на кнопке Reset (Сброс), чтобы отменить прежние настройки.
Перенесите переменную alter в список выходных переменных.
Щелкните на кнопке Statistics. (Статистика).
В диалоге Frequencies: Statistics установите флажки желаемых характеристик. Затем щелкните на кнопке Continue (Продолжить). Вы вернетесь в диалог Frequencies.
В диалоге Frequencies деактивируйте опцию Display frequency tables (Показывать частотные таблицы). Щелкните на кнопке ОК.
В окне просмотра появятся следующие результаты:
Alter
| N | Valid (Допустимые) | 106 |
| Missing (Утерянные) | 2 | |
| Mean (Среднее значение) | 22,24 | |
| Std. Error of Mean (Стандартная ошибка среднего) | 21 | |
| Median (Медиана) | 22,00 | |
| Mode (Мода) | 21 | |
| Std. Deviation (Стандартное отклонение) | 2,189 | |
| Variance (Дисперсия) | 4,791 | |
| Skewness (Асимметрия) | 0,859 | |
| Std. Error of Skewness (Стандартная ошибка асимметрии) | 0,235 | |
| Kurtosis (Коэффициент вариации / Эксцесс) | 1,042 | |
| Std. Error of Kurtosis (Стандартная ошибка эксцесса) | 0,465 | |
| Range (Размах) | 11 | |
| Minimum (Минимум) | 18 | |
| Maximum (Максимум) | 29 | |
| Percentiles (Процентили) | 25 | 21,00 |
| 50 | 22,00 | |
| 75 | 23,00 |
Респонденты опроса о психическом состоянии и социальном положении имеют средний возраст 22,24 года. Медиана составляет 22. Большинству респондентов 21 год (это мода). Самому молодому респонденту 18 лет (минимум), самому старшему — 29 лет (максимум). Самый старший респондент на 11 лет старше самого молодого (размах). Стандартное отклонение составляет 2,19. Следовательно, дисперсия — квадрат стандартного отклонения — равна (2,19) 2 = 4,79. Асимметрия и коэффициент вариации даны со соответсвующими стандартными ошибками.
Среднее значение, медиана и мода
Эти три термина являются основными показателями в статистическом анализе. Если 20 лет назад в нашей стране они интересовали только экономистов и работников статистики, то теперь почти каждый, кто имеет хоть какое-либо отношение к коммерции, следит за этими данными. Это работники банковского сектора, торговли, сервиса о больше всех брокеры.
Но в этой статье мы не будем подробно объяснять каждый из этих терминов. Их достаточно распиарили и без нас. Вместо этого остановимся на объяснении этих трех терминов: среднее значение, медиана и мода. Все три термина объясним с примерами.
Среднее значение
Часто так называют среднеарифметическое значение выборки (или множества чисел). Это, пожалуй, самый распространенный термин, из вышеперечисленных трех. Хотя бы потому, что почти каждый день мы слышим это слово в СМИ. Значение его тоже объясняет само название. Тем не менее, для тех, кому непонятен смысл этого слова, объясним “на пальцах”.
Это сумма данных чисел, деленное на количество. Если написать в виде формулы, это выглядит так.
Пример из практики
Медиана
Медиана – число, характеризующее выборку, т.е. если взять все элементы множества, то это число ровно делит множество пополам. Одна половина множества равна или больше этого число, а другая меньше или равна этому числу.
Пример из практики
Значит, среднее значение в год составляет
$(1,000,000 + 200,000 + 8,900) : 100 = 1,208,900 : 100 = 12,089$ у.е.
Зная соотношение неработающих людей, на каждого работающего, и поделив полученное на это число, получим доход на душу населения (с учетом детей, стариков и больных без пенсии).
Итак, такая статистика показывает, что народ живет припеваючи, зарабатывая примерно 1,000 у.е. в месяц, а действительность другая. Как раз, так и вычисляется доход на душу населения. Берется национальный доход и делится на численность населения. Теперь вы понимаете, почему в сводках всегда называют эту цифру, потому что она никоим образом не отображает благосостояние большинства, а только является показателем экономического благосостояния страны.
Пример из практики
Если постоять на проспекте и в течение 10 минут и посчитать все проезжающие автомобили и классифицировать их по цветам, то можно определить моду для цвета автомобилей этого города. Допустим, насчитали 95 белых, 45 черных, 12 красных, 38 серых и 70 других цветов. Значит, модой в этом городе являются автомобили белого цвета. Это хорошая информация для дистрибьюторов автомобилей.
Подробнее о среднем значении
Иногда вычисляют среднее значение для группы данных. Тогда значения разбивают на группы и вычисляют серединную точку каждой группы. Затем эти значения умножают на количество членов каждой группы (на частотность) и складывают. А результат делят на общее количество. Такое значение называют средним значением группы. Посмотрите на этот пример:
| Группа | Частота | Середина |
|---|---|---|
| 1-20 | 5 | 10.5 |
| 21-40 | 25 | 30.5 |
| 41-60 | 37 | 50.5 |
| 61-80 | 23 | 70.5 |
Умножаем эти значения на частоты и складываем, затем делим на общее количество:
Как уже показали на примере с доходом населения, экстремумы сильно влияют на среднеарифметическое значение, поэтому иногда полезно их отбрасывать. Тогда среднее значение называется урезанным средним.
В симметричном распределении (типа нормального распределения) среднее значение, медиана и мода равны или близки друг другу. В асимметричном же, они отличаются, и число, на которое отличаются эти показатели, дают информацию о “скошенности” распределения относительно нормального.
Надеемся, что нам удалось “на пальцах” объяснить значение терминов среднеарифметическое значение, медиана и мода. Если кто-то из Ваших знакомых до сих пор в недоумении, просвещайте их, поделившись данной статьей в соц. сетях.
Читайте также

Переменные потока и запасы
Все экономические переменные, которые имеют временное измерение, т.е. величины которых можно измерить по истечении времени называем переменными потока. А запас не имеет временное измерение.
Показатели вариации
Чтобы знать, насколько далеко значение совокупности простирается от центральной тенденции, вычисляют вариацию (на английском dispersion или variability, но не путайте с variation). Есть несколько показателей вариации. Это размах, межквартильный размах, среднее линейное отклонение, дисперсия и стандартное отклонение.
Типы выборки
Для расследования генеральной совокупности применяют два вида выборки. Случайную и неслучайную выборку. Простая, систематическая, стратифицированная и кластерная выборка являются случайными выборками. Стихийная, удобная и квотная выборка являются примером неслучайной выборки.

Скользящее среднее значение
Среди наиболее популярных технических индикаторов чаще всего, скользящее среднее значение используются для измерения направления текущего тренда. Самая простая формула скользящей средней, известна как Простое Скользящее Среднее значение.
Генеральная совокупность и выборка
Генеральной совокупностью называют всё исследуемое множество. На английском языке этот термин называется популяцией (population). Выборкой (на английском sample) называют некоторое случайно отобранное подмножество из генеральной совокупности.
Нулевая гипотеза
Нулевая гипотеза утверждает, что между исследуемыми данными никакой закономерности нет. Пока нулевая гипотеза не опровергнута, она в силе. Альтернативная гипотеза является обратной нулевой гипотезе.

Типы данных в статистике
Такие выражения, как минимум, максимум, медиана и процентиль имеют значение лишь для порядковых данных. Порядковые данные делятся на метрические и неметрические.

Что такое тренд?
Термины тренд и тенденция используются в различных целях. Люди часто говорят о тенденции относительно роста цен и падения курса какой-то валюты. Здесь мы раскроем статистическое значение этих терминов.
Ошибка репрезентативности
Стандартная ошибка (standard error) и ошибка репрезентативности часто употребляются, как взаимозаменяемые термины. Ошибка репрезентативности показывает, насколько результаты, полученные при выборочном наблюдении отличаются от результатов, полученных при исследовании генеральной совокупности.
Медиана в статистике
Медиана – середина упорядоченного ряда. Медиана делит этот ряд пополам таким образом, что в одной половине стоят все значения меньшие, а в другой все значения большие медианы.
© Все права защищены
Все статьи этого сайта написаны Джафаром Н.Алиевым. Перепечатывание любой статьи на стороннем ресурсе должно сопровождаться именем автора и ссылкой на данный ресурс. Сам автор следует этим правилам.



