Что такое SQL. Назначение и основа
Всем привет! Сегодня я максимально просто, специально для начинающих, попытаюсь рассказать Вам о том, что такое SQL, и для чего он нужен. Из данного материала Вы также узнаете, что такое база данных и система управления базами данных, а также что такое диалект языка SQL, ведь вся статья будет построена на том, чтобы плавно подвести Вас к пониманию того, что же такое SQL.

Я думаю, Вы уже представляете себе, что SQL — это некий язык, связанный с какими-то там базами данных, однако для того, чтобы лучше понимать, что же такое SQL, необходимо понять, для чего нужен SQL, для чего нужен этот язык, т.е. его назначение.
Поэтому сначала я дам Вам немного вводной информации, из которой будет ясно назначение языка SQL, и для чего он вообще нужен.
Что такое база данных
И начну я с того, что под базой данных обычно принято понимать любой набор информации, которая хранится определенным образом, и ей можно воспользоваться. Но если говорить о каких-то автоматизированных базах данных, то здесь, конечно же, речь идет о так называемых реляционных базах данных.
Реляционная база данных – это упорядоченная информация, связанная между собой определёнными отношениями. Представлена она в виде таблиц, в которых и лежит вся эта информация. И это очень важно, так как теперь Вы должны представлять себе современную базу данных просто в виде таблиц (если говорить в контексте SQL), т.е. в общем смысле база данных – это набор таблиц. Безусловно, это сильно упрощенное определение, но оно дает некое практическое понимание базы данных.
Что такое SQL
За счет того, что информация в базе данных упорядочена, разделена на определённые сущности и представлена в виде таблиц, к ней легко обратиться и найти нужную нам информацию.
И тут возникает главный вопрос: а как к ней обратиться и получить необходимую нам информацию?
Для этого должен быть специальный инструмент, и здесь к нам на помощь как раз и приходит SQL, который является тем инструментом, с помощью которого происходит манипулирование данными (создание, извлечение, удаление и т.д.) в базе данных.
SQL (Structured Query Language) — язык структурированных запросов, с помощью него пишутся специальные запросы (так называемые SQL инструкции) к базе данных с целью получения данных из базы данных или для манипулирования этими данными.
Также обязательно стоит отметить и то, что база данных, и в частности реляционная модель, основана на теории множеств, которая подразумевает объединение разных объектов в одно целое, под одним целым в базе данных как раз и имеется в виду таблица. Это важно, так как язык SQL работает именно со множеством, с набором данных, т.е. с таблицами.
Полезные материалы по теме:
Что такое СУБД
У Вас может возникнуть вопрос, если база данных это некая информация, которая хранится в таблицах, то как она выглядит физически? Как на нее посмотреть в целом?
Если очень коротко, то это просто файл, созданный в специальном формате, именно так и выглядит база данных (в большинстве случаев БД включает несколько файлов, но сейчас на этом уровне это не так важно).
Идем дальше, если база данных это файл в специальном формате, то как его создать или открыть? И тут возникает сложность, ведь просто так, без каких-либо инструментов создать такой файл, т.е. реляционную базу данных, нельзя, для этого нужен специальный инструмент, который мог бы создавать и управлять базой данных, иными словами, работать с этими файлами.
Таким инструментом как раз и выступает СУБД – это система управления базами данных, сокращенно СУБД.
Какие СУБД бывают
На самом деле, существует достаточно много различных СУБД, некоторые из них платные и стоят немалых денег, если говорить о полнофункциональных версиях, но даже у самых, так скажем, «крутых» есть бесплатные редакции, которые, кстати, отлично подходят для обучения.
Среди всех по своим возможностям и популярности можно выделить следующие системы:
Полезные материалы по теме:
Диалекты языка SQL (расширения SQL)
Язык SQL – это стандарт, он реализован во всех реляционных базах данных, но у каждой СУБД есть расширение этого стандарта, есть собственный язык работы с данными, его обычно называют диалектом SQL, который, конечно же, основан на SQL, но предоставляет больше возможностей для полноценного программирования, кроме того, такой внутренний язык дает возможность получать системную информацию и упрощать SQL запросы.
Вот некоторые диалекты языка SQL:
Таким образом, от СУБД зависит, на каком расширении Вы будете писать SQL инструкции. Если говорить о простых SQL запросах, например,
то, безусловно, во всех СУБД такие запросы работать будут, ведь SQL — это стандарт.
Примечание! Это простой SQL запрос на выборку данных из одной таблицы, выводятся два столбца.
Однако если Вы собираетесь программировать, использовать все внутренние возможности СУБД (разрабатывать процедуры, использовать встроенные функции, получать системную информацию и т.д.), то Вам необходимо изучать конкретный диалект SQL и практиковаться соответственно в той СУБД, в которой используется этот диалект. Это важно, ведь синтаксис многих конструкций различается так же, как различаются возможности и многое другое. И если, допустим, Вы запустите SQL инструкцию, в которой использованы возможности определенного расширения SQL, на другой СУБД, то такая инструкция, конечно же, не выполнится.
Например, лично я специализируюсь на языке T-SQL, и соответственно, работаю с Microsoft SQL Server, вот уже более 8 лет!
Хотя, конечно же, с другими СУБД я также работал, одно время я сопровождал два приложения, одно из которых работало с PostgreSQL, ну а второе, наверное, уже понятно, с Microsoft SQL Server.
С MySQL я работал, как, наверное, и многие, в рамках сопровождения сайтов и сервисов. Ну а с Oracle Database мне приходилось работать в рамках других проектов.
Весь свой накопленный опыт в части языка SQL я сгруппировал в одном месте и оформил в виде книг, поэтому, если у Вас есть желание изучить язык SQL рекомендую почитать мои книги:
Заметка! Начинающим рекомендую пройти мой онлайн-курс по основам SQL, с помощью которого Вы научитесь работать с языком SQL во всех популярных системах управления базами данных. Курс включает много практики: онлайн-тестирование, задания и многое другое.
Надеюсь, теперь Вы понимаете, что такое SQL, и для чего он нужен, в следующих материалах я расскажу, как создавать SQL запросы, расскажу какие инструменты для этого необходимо использовать и для каких СУБД, так как у каждой СУБД есть свои инструменты, поэтому следите за выходом новых статей в моих группах в социальных сетях: ВКонтакте, Facebook, Одноклассники, Twitter и Tumblr. Подписывайтесь, и Вы не пропустите выход нового материала!
Введение в MS SQL Server и T-SQL
Что такое SQL Server и T-SQL
SQL Server является одной из наиболее популярных систем управления базами данных (СУБД) в мире. Данная СУБД подходит для самых различных проектов: от небольших приложений до больших высоконагруженных проектов.
SQL Server был создан компанией Microsoft. Первая версия вышла в 1987 году. А текущей версией является версия 2019, которая вышла в 2019 году и которая будет использоваться в текущем руководстве.
SQL Server долгое время был исключительно системой управления базами данных для Windows, однако начиная с версии 16 эта система доступна и на Linux.
SQL Server характеризуется такими особенностями как:
Производительность. SQL Server работает очень быстро.
Надежность и безопасность. SQL Server предоставляет шифрование данных.
Простота. С данной СУБД относительно легко работать и вести администрирование.
Центральным аспектом в MS SQL Server, как и в любой СУБД, является база данных. База данных представляет хранилище данных, организованных определенным способом. Нередко физически база данных представляет файл на жестком диске, хотя такое соответствие необязательно. Для хранения и администрирования баз данных применяются системы управления базами данных (database management system) или СУБД (DBMS). И как раз MS SQL Server является одной из такой СУБД.
Для организации баз данных MS SQL Server использует реляционную модель. Эта модель баз данных была разработана еще в 1970 году Эдгаром Коддом. А на сегодняшний день она фактически является стандартом для организации баз данных.
Реляционная модель предполагает хранение данных в виде таблиц, каждая из которых состоит из строк и столбцов. Каждая строка хранит отдельный объект, а в столбцах размещаются атрибуты этого объекта.
Для идентификации каждой строки в рамках таблицы применяется первичный ключ (primary key). В качестве первичного ключа может выступать один или несколько столбцов. Используя первичный ключ, мы можем ссылаться на определенную строку в таблице. Соответственно две строки не могут иметь один и тот же первичный ключ.
Через ключи одна таблица может быть связана с другой, то есть между двумя таблицами могут быть организованы связи. А сама таблица может быть представлена в виде отношения («relation»).
Для взаимодействия с базой данных применяется язык SQL (Structured Query Language). Клиент (например, внешняя программа) отправляет запрос на языке SQL посредством специального API. СУБД должным образом интерпретирует и выполняет запрос, а затем посылает клиенту результат выполнения.
Изначально язык SQL был разработан в компании IBM для системы баз данных, которая называлась System/R. При этом сам язык назывался SEQUEL (Structured English Query Language). Хотя в итоге ни база данных, ни сам язык не были впоследствии официально опубликованы, по традиции сам термин SQL нередко произносят как «сиквел».
В 1979 году компания Relational Software Inc. разработала первую систему управления баз данных, которая называлась Oracle и которая использовала язык SQL. В связи с успехом данного продукта компания была переименована в Oracle.
Впоследствии стали появляться другие системы баз данных, которые использовали SQL. В итоге в 1989 году Американский Национальный Институт Стандартов (ANSI) кодифицировал язык и опубликовал его первый стандарт. После этого стандарт периодически обновлялся и дополнялся. Последнее его обновление состоялось в 2011 году. Но несмотря на наличие стандарта нередко производители СУБД используют свои собственные реализации языка SQL, которые немного отличаются друг от друга.
Выделяются две разновидности языка SQL: PL-SQL и T-SQL. PL-SQL используется в таких СУБД как Oracle и MySQL. T-SQL (Transact-SQL) применяется в SQL Server. Собственно поэтому в рамках текущего руководства будет рассматриваться именно T-SQL.
В зависимости от задачи, которую выполняет команда T-SQL, он может принадлежать к одному из следующих типов:
DDL (Data Definition Language / Язык определения данных). К этому типу относятся различные команды, которые создают базу данных, таблицы, индексы, хранимые процедуры и т.д. В общем определяют данные.
В частности, к этому типу мы можем отнести следующие команды:
CREATE : создает объекты базы данных (саму базу даных, таблицы, индексы и т.д.)
ALTER : изменяет объекты базы данных
DROP : удаляет объекты базы данных
TRUNCATE : удаляет все данные из таблиц
К этому типу относятся следующие команды:
SELECT : извлекает данные из БД
UPDATE : обновляет данные
INSERT : добавляет новые данные
DELETE : удаляет данные
DCL (Data Control Language / Язык управления доступа к данным). К этому типу относят команды, которые управляют правами по доступу к данным. В частности, это следующие команды:
GRANT : предоставляет права для доступа к данным
SQL — что это такое простым языком

SQL — простыми словами, это язык программирования структурированных запросов (SQL, Structured Query Language), который используется в качестве эффективного способа сохранения данных, поиска их частей, обновления, извлечения из базы и удаления.
Произносится как «Эскуэль/ЭсКьюЭль», реже «СиКуЭль/СиКьюЭль», но чаще всего можно услышать жаргонное «Сиквэл/Сиквел».
Главный инструмент оптимизации и обслуживания базы данных — вот, для чего нужен SQL, хотя он и не ограничен этими целями. Возможности обработки охватывают команды определения представлений, указания прав доступа, схем отношений (в том числе, их удаления и изменения), взаимодействие с другими языками программирования, проверку целостности, задание начала и завершения транзакций.

Для чего нужен SQL на конкретном примере
Чтобы непрофессионалу понять, что значит SQL для ИТ-отрасли, приведём простой пример.
Представьте таблицу с информацией о студентах: имена, возраст, предмет обучения и так далее. В ней есть определённое количество строк и столбцов. Один из рядов содержит успеваемость студентов.
Как только все данные будут внесены в таблицу, каждая из записей попадает в разные категории (столбцы или «аттрибуты»). Это и есть организованная база данных. Вся организованная внутри неё информация, которой можно управлять, называется Database Schema (схема данных).
Если вы захотите выдать стипендии учащимся, которые получают оценку 90% или выше, то выполняется запрос данных в SQL, что простыми словами значит «попросить базу данных предоставить информацию о студентах, получающих 90% и более баллов».
Команда будет иметь синтаксический вид:
SELECT * FROM Student WHERE Percentage>=90;
Когда количество данных мало (скажем, 10 студентов), то можно всё легко посчитать и написать на клочке бумаге. Но когда объём данных увеличивается до тысяч записей, становится нужен SQL — он помогает управлять огромными данными эффективно, то есть быстро получать расчёты на их основе.
Как используется SQL и в чём его польза?
С 1974 года, когда язык структурированных запросов только появился, он обеспечивает взаимодейтсвие с системами управления базами данных (СУБД) во всём мире.
SQL, как простой и лёгкий в изучении язык из области свободного программного обеспечения, сегодня активно применяется:
Язык универсален и обладает чётко определённой структурой за счёт устоявшихся стандартов. Взаимодействие с базами данных происходит быстро даже в ситуациях, когда объёмы данных велики (Big Data). Кроме того, эффективное управление возможно даже без особых познаний кода.

Области применения и где используется SQL:
SQL DDL
В качестве языка определения данных (DDL) он даёт возможность независимо создавать базу данных, определять её структуру, использовать, а затем cбрасывать по завершению манипуляций.
SQL DML
В качестве языка управления данными (DML) — для поддержки уже существующих баз данных на эффективном с точки зрения трудозатрат и производительности языке ввода, изменения и извлечения данных в отношении базы данных.
SQL DCL
Как язык контроля данных (DCL), когда нужно защитить свою базу данных от повреждения и неправильного использования.
SQL клиент/сервер
Открывают единую систему входа (SSO) с проверкой подлинности пользователя в нескольких веб-приложениях в рамках единого сеанса.
SQL трёхуровневой архитектуры
Гарантирует защиту информационной составляющей от несанкционированного использования и копирования в цифровом виде.
Почти все реляционные базы данных используют SQL. Некоторые из них даже включают аббревиатуру языка в своём названии: Microsoft SQL Server, MySQL, PostgreSQL, Non Stop SQL, SQLite. Но есть и те, кто именуется независимо, как Oracle, DB/2, Ingres. Есть ещё «NoSQL» — это собирательный термин, который относят ко всем нереляционным базам данных без SQL (либо, когда это не единственный язык запросов).
Видеолекция о том, как и где именно используется SQL, а также каким образом работают базы данных в реальных условиях, простым и доступным русским языком:
Обратитесь в компанию ИТ-аутсорсинга для дальнейшей экспертной поддержки и консультации по этой теме и любым другим техническим вопросам.
MS SQL Server — Краткое руководство
Эта глава знакомит с SQL Server, обсуждает его использование, преимущества, версии и компоненты.
Что такое SQL Server?
Это программное обеспечение, разработанное Microsoft, которое реализовано на основе спецификации RDBMS.
Это зависит от платформы.
Это и графический интерфейс, и программное обеспечение на основе команд.
Он поддерживает язык SQL (SEQUEL), являющийся продуктом IBM, непроцедурный, общий язык баз данных и язык, не чувствительный к регистру.
Это программное обеспечение, разработанное Microsoft, которое реализовано на основе спецификации RDBMS.
Это зависит от платформы.
Это и графический интерфейс, и программное обеспечение на основе команд.
Он поддерживает язык SQL (SEQUEL), являющийся продуктом IBM, непроцедурный, общий язык баз данных и язык, не чувствительный к регистру.
Использование SQL Server
Версии SQL Server
| Версия | Год | Кодовое имя |
|---|---|---|
| 6,0 | 1995 | SQL95 |
| 6,5 | 1996 | гидра |
| 7,0 | 1998 | сфинкс |
| 8,0 (2000) | 2000 | Шило |
| 9,0 (2005) | 2005 | Юкон |
| 10.0 (2008) | 2008 | Катмай |
| 10,5 (2008 R2) | 2010 | Килиманджаро |
| 11.0 (2012) | 2012 | Denali |
| 12 (2014) | 2014 | Гекатон (изначально), SQL 14 (текущий) |
Компоненты SQL Server
SQL Server работает в архитектуре клиент-сервер, поэтому он поддерживает два типа компонентов — (а) рабочая станция и (б) сервер.
Компоненты рабочей станции устанавливаются на каждом устройстве оператора / устройства SQL Server. Это просто интерфейсы для взаимодействия с компонентами Сервера. Пример: SSMS, SSCM, Profiler, BIDS, SQLEM и т. Д.
Серверные компоненты устанавливаются на централизованном сервере. Это услуги. Пример: SQL Server, агент SQL Server, SSIS, SSAS, SSRS, браузер SQL, полнотекстовый поиск SQL Server и т. Д.
Компоненты рабочей станции устанавливаются на каждом устройстве оператора / устройства SQL Server. Это просто интерфейсы для взаимодействия с компонентами Сервера. Пример: SSMS, SSCM, Profiler, BIDS, SQLEM и т. Д.
Серверные компоненты устанавливаются на централизованном сервере. Это услуги. Пример: SQL Server, агент SQL Server, SSIS, SSAS, SSRS, браузер SQL, полнотекстовый поиск SQL Server и т. Д.
Экземпляр SQL Server
Преимущества экземпляров
MS SQL Server — Выпуски
SQL Server доступен в различных редакциях. В этой главе перечислены несколько изданий с его функциями.
Enterprise — это топовая версия с полным набором функций.
Стандартный — в нем меньше возможностей, чем в Enterprise, когда нет необходимости в дополнительных функциях.
Рабочая группа — это подходит для удаленных офисов крупной компании.
Веб — это разработано для веб-приложений.
Разработчик — Это похоже на Enterprise, но лицензировано только одному пользователю для разработки, тестирования и демонстрации. Его можно легко обновить до Enterprise без переустановки.
Экспресс — это бесплатная база данных начального уровня. Он может использовать только 1 процессор и 1 ГБ памяти, максимальный размер базы данных составляет 10 ГБ.
Компактная — это бесплатная встроенная база данных для разработки мобильных приложений. Максимальный размер базы данных составляет 4 ГБ.
Business Intelligence — Business Intelligence Edition — это новое введение в SQL Server 2012. Это издание включает в себя все функции в стандартной редакции и поддержку расширенных функций BI, таких как Power View и PowerPivot, но в нем отсутствует поддержка расширенных функций доступности, таких как группы доступности AlwaysOn. и другие онлайн операции.
Оценка предприятия. Выпуск SQL Server Evaluation Edition — отличный способ получить полностью функциональный и бесплатный экземпляр SQL Server для изучения и разработки решений. Срок действия этой версии составляет 6 месяцев с момента ее установки.
Enterprise — это топовая версия с полным набором функций.
Стандартный — в нем меньше возможностей, чем в Enterprise, когда нет необходимости в дополнительных функциях.
Рабочая группа — это подходит для удаленных офисов крупной компании.
Веб — это разработано для веб-приложений.
Разработчик — Это похоже на Enterprise, но лицензировано только одному пользователю для разработки, тестирования и демонстрации. Его можно легко обновить до Enterprise без переустановки.
Экспресс — это бесплатная база данных начального уровня. Он может использовать только 1 процессор и 1 ГБ памяти, максимальный размер базы данных составляет 10 ГБ.
Компактная — это бесплатная встроенная база данных для разработки мобильных приложений. Максимальный размер базы данных составляет 4 ГБ.
Business Intelligence — Business Intelligence Edition — это новое введение в SQL Server 2012. Это издание включает в себя все функции в стандартной редакции и поддержку расширенных функций BI, таких как Power View и PowerPivot, но в нем отсутствует поддержка расширенных функций доступности, таких как группы доступности AlwaysOn. и другие онлайн операции.
Оценка предприятия. Выпуск SQL Server Evaluation Edition — отличный способ получить полностью функциональный и бесплатный экземпляр SQL Server для изучения и разработки решений. Срок действия этой версии составляет 6 месяцев с момента ее установки.
| 2005 | 2008 | 2008 R2 | 2012 | 2014 |
|---|---|---|---|---|
| предприятие | да | да | да | да |
| стандарт | да | да | да | да |
| разработчик | да | да | да | да |
| Workgroup | да | да | нет | нет |
| Win Compact Edition — мобильная версия | да | да | да | да |
| Оценка предприятия | да | да | да | да |
| экспресс | да | да | да | да |
| Web | да | да | да | |
| Дата центр | нет | нет | ||
| Бизнес-аналитика | да |
MS SQL Server — Установка
SQL Server поддерживает два типа установки:
проверки
Требования
Пререквизиты на 2005 год
Предварительные условия для 2008 и 2008R2
Пререквизиты на 2012 и 2014 годы
Шаги установки
После загрузки программного обеспечения будут доступны следующие файлы в зависимости от варианта загрузки (32 или 64-разрядная версия).
Гумилева \ x86 \ SQLFULL_x86_ENU_Core.box
Гумилева \ x86 \ SQLFULL_x86_ENU_Install.exe
Гумилева \ x86 \ SQLFULL_x86_ENU_Lang.box
Гумилева \ x86 \ SQLFULL_x64_ENU_Core.box
Гумилева \ x86 \ SQLFULL_x64_ENU_Install.exe
Гумилева \ x86 \ SQLFULL_x64_ENU_Lang.box
Примечание — X86 (32 бит) и X64 (64 бит)
Шаг 2 — Дважды щелкните «SQLFULL_x86_ENU_Install.exe» или «SQLFULL_x64_ENU_Install.exe», он извлечет необходимые файлы для установки в папку «SQLFULL_x86_ENU» или «SQLFULL_x86_ENU» соответственно.
Шаг 3 — Щелкните папку «SQLFULL_x86_ENU» или «SQLFULL_x64_ENU_Install.exe» и дважды щелкните приложение «SETUP».
Для понимания здесь мы использовали программное обеспечение SQLFULL_x64_ENU_Install.exe.
Шаг 4 — Как только мы нажмем «Настройка» приложения, откроется следующий экран.
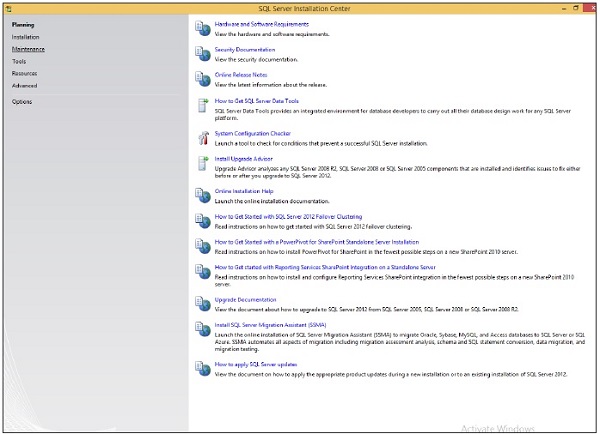
Шаг 5 — Нажмите Установка, которая находится в левой части экрана выше.
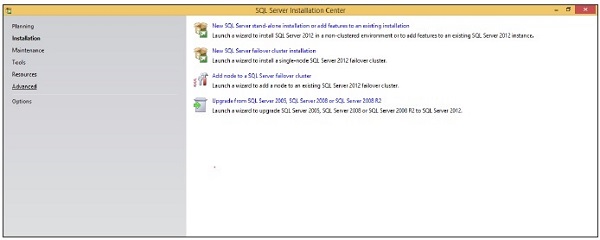
Шаг 6 — Нажмите на первый вариант правой стороны, показанной на экране выше. Откроется следующий экран.
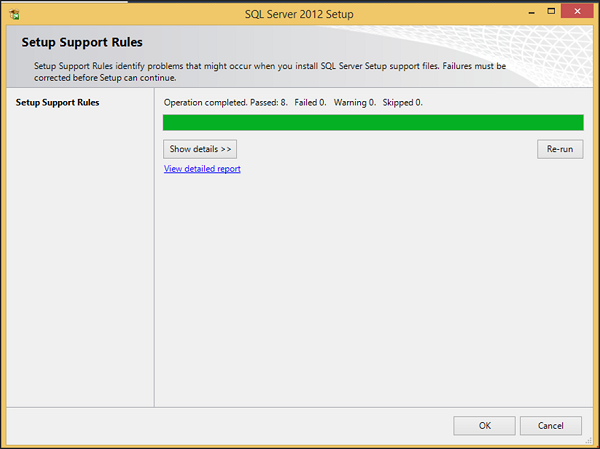
Шаг 7 — Нажмите OK, и появится следующий экран.
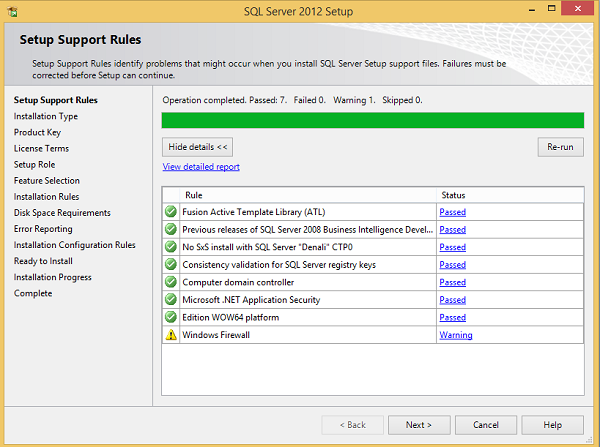
Шаг 8 — Нажмите Далее, чтобы получить следующий экран.
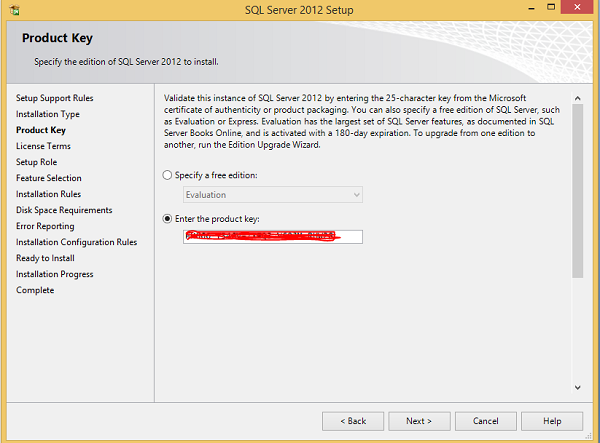
Шаг 9 — Обязательно проверьте выбор ключа продукта и нажмите Далее.
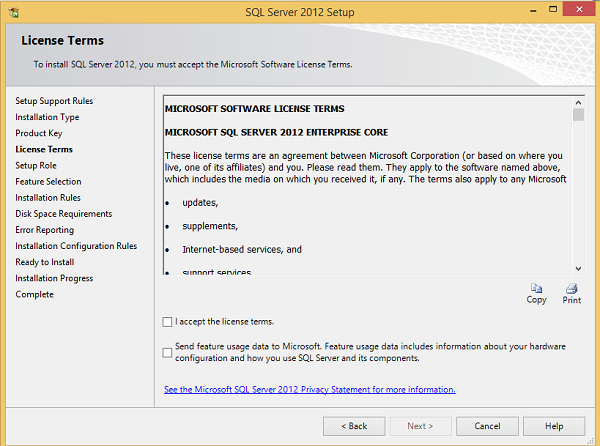
Шаг 10 — Установите флажок, чтобы принять опцию лицензии, и нажмите Далее.
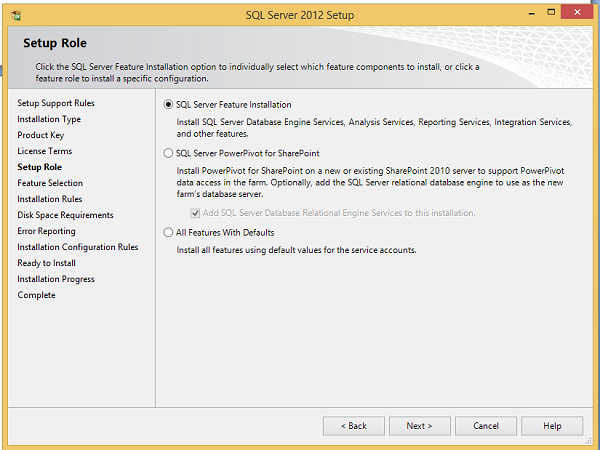
Шаг 11 — Выберите вариант установки компонента SQL Server и нажмите Далее.
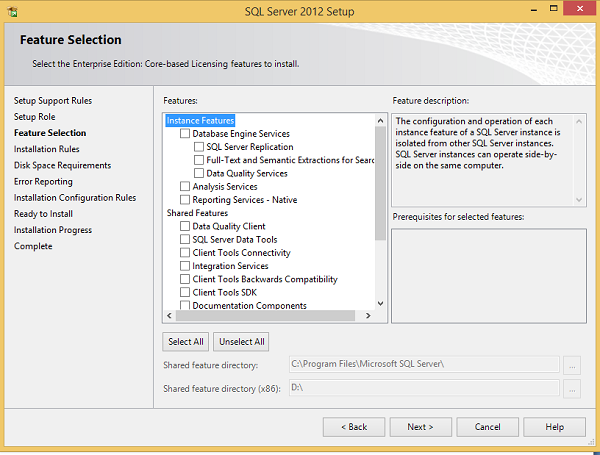
Шаг 12 — Установите флажок Службы ядра СУБД и нажмите Далее.
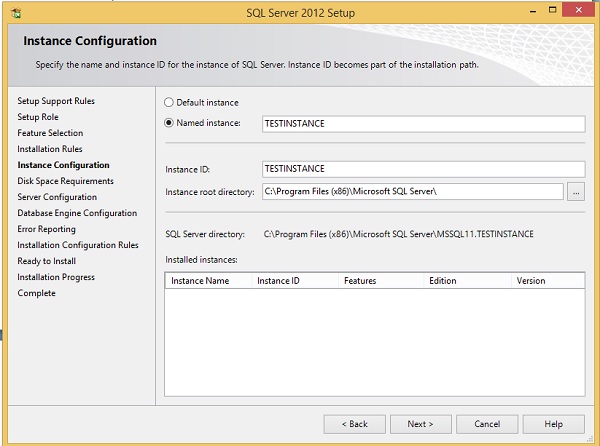
Шаг 13 — Введите именованный экземпляр (здесь я использовал TestInstance) и нажмите Next.
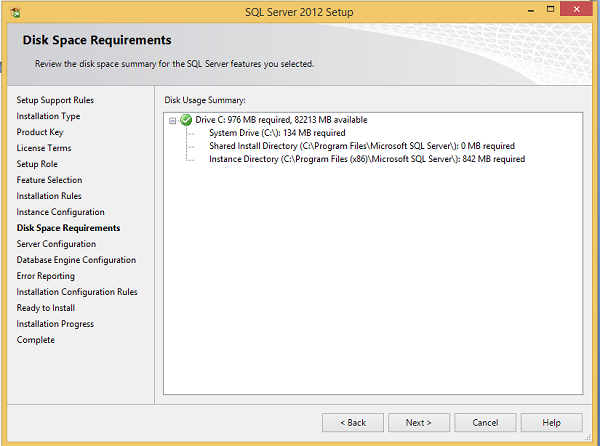
Шаг 14 — Нажмите Next на приведенном выше экране, и появится следующий экран.
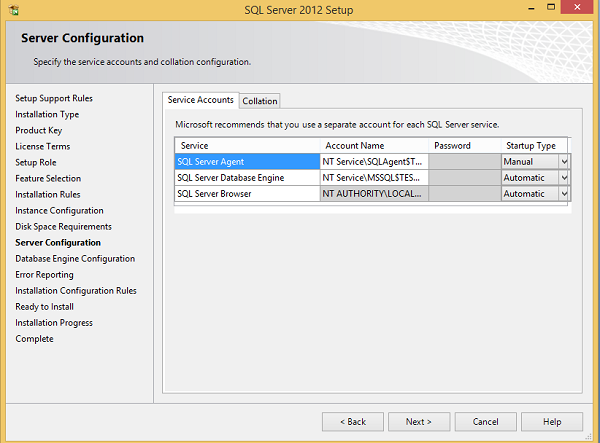
Шаг 15 — Выберите имена учетных записей служб и типы запуска для вышеперечисленных служб и нажмите Сортировка.
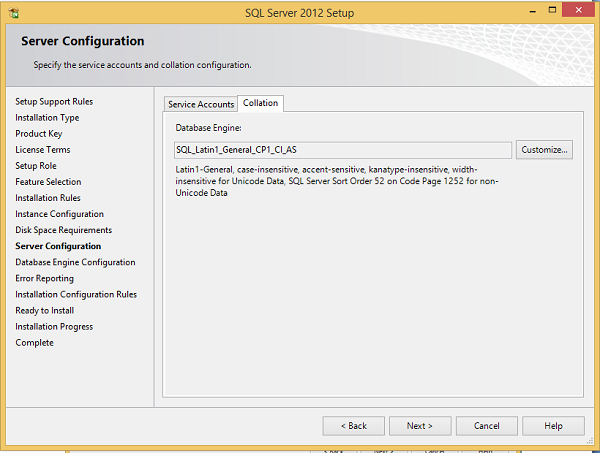
Шаг 16 — Убедитесь, что выбран правильный параметр сортировки и нажмите Далее.
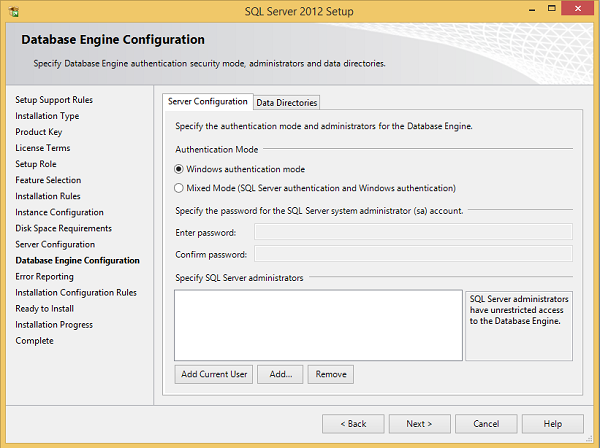
Шаг 17 — Убедитесь, что выбран режим аутентификации и администраторы проверены, и нажмите «Каталоги данных».
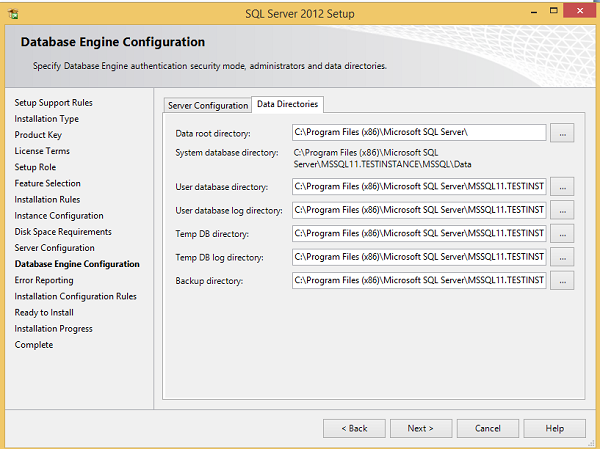
Шаг 18 — Обязательно выберите вышеуказанные каталоги и нажмите «Далее». Появится следующий экран.
Шаг 19 — Нажмите Далее на приведенном выше экране.
Шаг 20 — Нажмите Далее на приведенном выше экране, чтобы получить следующий экран.
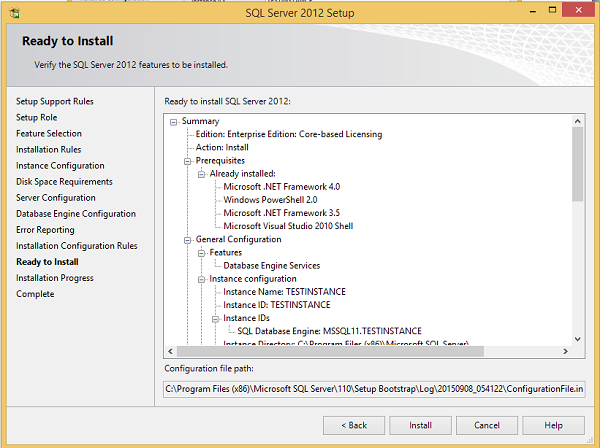
Шаг 21 — Убедитесь, что правильно проверили вышеуказанный выбор и нажмите «Установить».
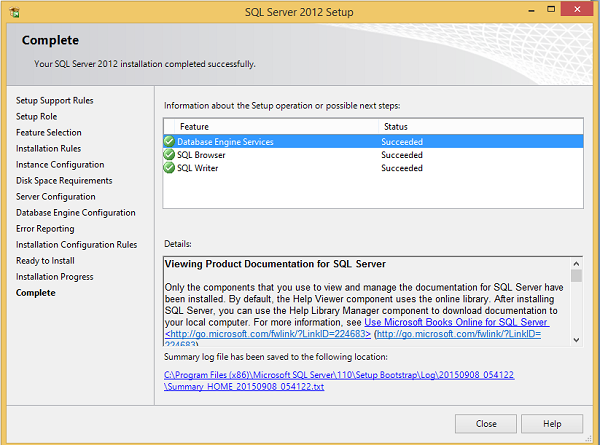
Установка прошла успешно, как показано на приведенном выше экране. Нажмите Закрыть, чтобы закончить.
MS SQL Server — Архитектура
Для удобства понимания мы классифицировали архитектуру SQL Server на следующие части:
Общая архитектура
Клиент — где запрос инициирован.
Запрос — SQL-запрос на языке высокого уровня.
Логические единицы — ключевые слова, выражения и операторы и т. Д.
N / W Packets — Код, связанный с сетью.
Протоколы — в SQL Server у нас есть 4 протокола.
Общая память (для локальных подключений и устранения неполадок).
Именованные каналы (для соединений, которые находятся в локальной сети).
TCP / IP (для соединений, подключенных к глобальной сети).
Адаптер виртуального интерфейса VIA (требуется специальное оборудование для настройки поставщиком, а также устаревший из версии SQL 2012).
Общая память (для локальных подключений и устранения неполадок).
Именованные каналы (для соединений, которые находятся в локальной сети).
TCP / IP (для соединений, подключенных к глобальной сети).
Адаптер виртуального интерфейса VIA (требуется специальное оборудование для настройки поставщиком, а также устаревший из версии SQL 2012).
Сервер — где установлены службы SQL и базы данных.
Relational Engine — это то место, где будет выполнено реальное выполнение. Он содержит анализатор запросов, оптимизатор запросов и исполнитель запросов.
Query Parser (Command Parser) и Compiler (Translator) — это проверит синтаксис запроса и преобразует запрос в машинный язык.
Оптимизатор запросов — он подготавливает план выполнения в качестве вывода, принимая запрос, статистику и дерево алгебры в качестве входных данных.
План выполнения — это похоже на план, который содержит порядок всех шагов, которые должны быть выполнены как часть выполнения запроса.
Query Executor — здесь запрос будет выполняться шаг за шагом с помощью плана выполнения, а также будет связываться с механизмом хранения.
Storage Engine — отвечает за хранение и извлечение данных в системе хранения (диск, SAN и т. Д.), Манипулирование данными, блокировку и управление транзакциями.
ОС SQL — это находится между хост-машиной (ОС Windows) и SQL Server. Все действия, выполняемые с ядром базы данных, выполняются операционной системой SQL. Операционная система SQL предоставляет различные сервисы операционной системы, такие как управление памятью, пул буферов, буфер журналов и обнаружение взаимоблокировок с использованием структуры блокировки и блокировки.
Процесс контрольной точки — контрольная точка — это внутренний процесс, который записывает все грязные страницы (измененные страницы) из буферного кэша на физический диск. Помимо этого, он также записывает записи журнала из буфера журнала в физический файл. Запись грязных страниц из буферного кэша в файл данных также называется усилением грязных страниц.
Это выделенный процесс, который автоматически запускается SQL Server через определенные промежутки времени. SQL Server запускает процесс проверки для каждой базы данных в отдельности. Контрольная точка помогает сократить время восстановления SQL Server в случае неожиданного завершения работы или сбоя системы \ сбоя.
Контрольные точки в SQL Server
В SQL Server 2012 есть четыре типа контрольных точек —
Автоматически — это самая распространенная контрольная точка, которая выполняется как фоновый процесс, чтобы обеспечить возможность восстановления базы данных SQL Server в течение срока, определенного параметром «Интервал восстановления — Настройка сервера».
Косвенный — это новый компонент в SQL Server 2012. Он также работает в фоновом режиме, но соответствует заданному пользователем целевому времени восстановления для конкретной базы данных, в которой был настроен параметр. Как только Target_Recovery_Time для данной базы данных будет выбран, это переопределит Интервал Восстановления, указанный для сервера, и исключит автоматическую контрольную точку в такой БД.
Вручную — эта команда запускается так же, как и любая другая инструкция T-SQL, после того, как вы введете команду контрольной точки, она будет выполнена до конца. Ручная контрольная точка работает только для вашей текущей базы данных. Вы также можете указать Checkpoint_Duration, который является необязательным — эта продолжительность указывает время, в которое вы хотите, чтобы ваша контрольная точка завершилась.
Внутренний — как пользователь, вы не можете контролировать внутреннюю контрольную точку. Выдается на конкретных операциях, таких как
Завершение работы инициирует операцию контрольной точки во всех базах данных, кроме случаев, когда выключение не является чистым (завершение работы с nowait).
Если модель восстановления изменяется с Full \ Bulk-logged на Simple.
Принимая резервную копию базы данных.
Если ваша БД находится в простой модели восстановления, процесс контрольной точки выполняется автоматически либо при заполнении журнала на 70%, либо на основе параметра сервера — Интервал восстановления.
Команда изменения базы данных для добавления или удаления файла данных \ журнала также запускает контрольную точку.
Контрольная точка также имеет место, когда модель восстановления базы данных записана в массовом режиме и выполняется минимально зарегистрированная операция.
Создание снимка БД.
Lazy Writer Process — Lazy Writer будет выгружать грязные страницы на диск по совершенно другой причине, потому что ему нужно освободить память в пуле буферов. Это происходит, когда SQL-сервер находится под давлением памяти. Насколько я знаю, это контролируется внутренним процессом, и нет никаких настроек для этого.
Автоматически — это самая распространенная контрольная точка, которая выполняется как фоновый процесс, чтобы обеспечить возможность восстановления базы данных SQL Server в течение срока, определенного параметром «Интервал восстановления — Настройка сервера».
Косвенный — это новый компонент в SQL Server 2012. Он также работает в фоновом режиме, но соответствует заданному пользователем целевому времени восстановления для конкретной базы данных, в которой был настроен параметр. Как только Target_Recovery_Time для данной базы данных будет выбран, это переопределит Интервал Восстановления, указанный для сервера, и исключит автоматическую контрольную точку в такой БД.
Вручную — эта команда запускается так же, как и любая другая инструкция T-SQL, после того, как вы введете команду контрольной точки, она будет выполнена до конца. Ручная контрольная точка работает только для вашей текущей базы данных. Вы также можете указать Checkpoint_Duration, который является необязательным — эта продолжительность указывает время, в которое вы хотите, чтобы ваша контрольная точка завершилась.
Внутренний — как пользователь, вы не можете контролировать внутреннюю контрольную точку. Выдается на конкретных операциях, таких как
Завершение работы инициирует операцию контрольной точки во всех базах данных, кроме случаев, когда выключение не является чистым (завершение работы с nowait).
Если модель восстановления изменяется с Full \ Bulk-logged на Simple.
Принимая резервную копию базы данных.
Если ваша БД находится в простой модели восстановления, процесс контрольной точки выполняется автоматически либо при заполнении журнала на 70%, либо на основе параметра сервера — Интервал восстановления.
Команда изменения базы данных для добавления или удаления файла данных \ журнала также запускает контрольную точку.
Контрольная точка также имеет место, когда модель восстановления базы данных записана в массовом режиме и выполняется минимально зарегистрированная операция.
Создание снимка БД.
Lazy Writer Process — Lazy Writer будет выгружать грязные страницы на диск по совершенно другой причине, потому что ему нужно освободить память в пуле буферов. Это происходит, когда SQL-сервер находится под давлением памяти. Насколько я знаю, это контролируется внутренним процессом, и нет никаких настроек для этого.
SQL-сервер постоянно следит за использованием памяти, чтобы оценить конфликт ресурсов (или доступность); его задача заключается в том, чтобы всегда было определенное количество свободного места. Как часть этого процесса, когда он замечает любой такой конфликт ресурсов, он запускает Lazy Writer для освобождения некоторых страниц в памяти путем записи грязных страниц на диск. Он использует алгоритм Least недавно Used (LRU), чтобы решить, какие страницы должны быть сброшены на диск.
Если Lazy Writer всегда активен, это может указывать на узкое место в памяти.
Архитектура памяти
Ниже приведены некоторые характерные особенности архитектуры памяти.
Одной из основных целей проектирования всего программного обеспечения для баз данных является минимизация дискового ввода-вывода, поскольку чтение и запись на диск являются одними из наиболее ресурсоемких операций.
Память в окнах может быть вызвана с помощью виртуального адресного пространства, совместно используемого режимом ядра (режим ОС) и режимом пользователя (приложение, такое как SQL Server).
SQL Server «Адресное пространство пользователя» разбит на две области: MemToLeave и Buffer Pool.
Размер MemToLeave (MTL) и пула буферов (BPool) определяется SQL Server во время запуска.
Управление буфером является ключевым компонентом в достижении высокой эффективности ввода / вывода. Компонент управления буфером состоит из двух механизмов: диспетчера буфера для доступа и обновления страниц базы данных и пула буферов для уменьшения количества операций ввода-вывода файла базы данных.
Буферный пул разделен на несколько разделов. Наиболее важными из них являются буферный кеш (также называемый кешем данных) и кеш процедур. Буферный кеш хранит страницы данных в памяти, так что часто используемые данные могут быть извлечены из кеша. Альтернативой будет чтение страниц данных с диска. Чтение страниц данных из кэша оптимизирует производительность, сводя к минимуму количество необходимых операций ввода-вывода, которые по своей природе медленнее, чем извлечение данных из памяти.
Кэш процедур хранит хранимые процедуры и планы выполнения запросов, чтобы минимизировать количество раз, когда планы запросов должны быть сгенерированы. Вы можете узнать информацию о размере и активности в кэше процедур, используя инструкцию DBCC PROCCACHE.
Одной из основных целей проектирования всего программного обеспечения для баз данных является минимизация дискового ввода-вывода, поскольку чтение и запись на диск являются одними из наиболее ресурсоемких операций.
Память в окнах может быть вызвана с помощью виртуального адресного пространства, совместно используемого режимом ядра (режим ОС) и режимом пользователя (приложение, такое как SQL Server).
SQL Server «Адресное пространство пользователя» разбит на две области: MemToLeave и Buffer Pool.
Размер MemToLeave (MTL) и пула буферов (BPool) определяется SQL Server во время запуска.
Управление буфером является ключевым компонентом в достижении высокой эффективности ввода / вывода. Компонент управления буфером состоит из двух механизмов: диспетчера буфера для доступа и обновления страниц базы данных и пула буферов для уменьшения количества операций ввода-вывода файла базы данных.
Буферный пул разделен на несколько разделов. Наиболее важными из них являются буферный кеш (также называемый кешем данных) и кеш процедур. Буферный кеш хранит страницы данных в памяти, так что часто используемые данные могут быть извлечены из кеша. Альтернативой будет чтение страниц данных с диска. Чтение страниц данных из кэша оптимизирует производительность, сводя к минимуму количество необходимых операций ввода-вывода, которые по своей природе медленнее, чем извлечение данных из памяти.
Кэш процедур хранит хранимые процедуры и планы выполнения запросов, чтобы минимизировать количество раз, когда планы запросов должны быть сгенерированы. Вы можете узнать информацию о размере и активности в кэше процедур, используя инструкцию DBCC PROCCACHE.
Другие части буферного пула включают в себя —
Структуры данных системного уровня. Содержит данные уровня экземпляра SQL Server о базах данных и блокировках.
Кэш журнала — зарезервирован для чтения и записи страниц журнала транзакций.
Контекст соединения. Каждое соединение с экземпляром имеет небольшую область памяти для записи текущего состояния соединения. Эта информация включает в себя хранимые процедуры и параметры пользовательских функций, позиции курсора и многое другое.
Пространство стека — Windows выделяет пространство стека для каждого потока, запускаемого SQL Server.
Структуры данных системного уровня. Содержит данные уровня экземпляра SQL Server о базах данных и блокировках.
Кэш журнала — зарезервирован для чтения и записи страниц журнала транзакций.
Контекст соединения. Каждое соединение с экземпляром имеет небольшую область памяти для записи текущего состояния соединения. Эта информация включает в себя хранимые процедуры и параметры пользовательских функций, позиции курсора и многое другое.
Пространство стека — Windows выделяет пространство стека для каждого потока, запускаемого SQL Server.
Архитектура Файла Данных
Архитектура Файла Данных имеет следующие компоненты —
Файловые группы
Файлы базы данных могут быть сгруппированы в группы файлов для целей размещения и администрирования. Ни один файл не может быть членом более чем одной файловой группы. Файлы журнала никогда не входят в файловую группу. Пространство журнала управляется отдельно от пространства данных.
Существует два типа групп файлов в SQL Server: основной и пользовательский. Первичная файловая группа содержит первичный файл данных и любые другие файлы, специально не назначенные другой файловой группе. Все страницы для системных таблиц размещаются в основной группе файлов. Пользовательские файловые группы — это любые файловые группы, указанные с помощью ключевого слова file file group в операторе create database или alter database.
Одна файловая группа в каждой базе данных работает как файловая группа по умолчанию. Когда SQL Server выделяет страницу для таблицы или индекса, для которых при создании не было указано ни одной группы файлов, страницы выделяются из группы файлов по умолчанию. Чтобы переключить файловую группу по умолчанию из одной файловой группы в другую файловую группу, она должна иметь фиксированную роль db_owner.
По умолчанию основная файловая группа является файловой группой по умолчанию. Пользователь должен иметь предопределенную роль базы данных db_owner, чтобы выполнять резервное копирование файлов и групп файлов по отдельности.
файлы
Базы данных имеют три типа файлов: первичный файл данных, вторичный файл данных и файл журнала. Первичный файл данных является отправной точкой базы данных и указывает на другие файлы в базе данных.
Расположение всех файлов в базе данных записывается как в основной базе данных, так и в основном файле базы данных. В большинстве случаев ядро базы данных использует местоположение файла из базы данных master.
Файлы имеют два имени — логическое и физическое. Логическое имя используется для ссылки на файл во всех операторах T-SQL. Физическое имя OS_file_name, оно должно соответствовать правилам ОС. Файлы данных и журналов могут быть размещены в файловых системах FAT или NTFS, но не могут быть размещены в сжатых файловых системах. В одной базе данных может быть до 32 767 файлов.
Extents
Экстенты являются базовой единицей, в которой пространство выделяется для таблиц и индексов. Экстент составляет 8 смежных страниц или 64 КБ. SQL Server имеет два типа экстентов — Унифицированный и Смешанный. Унифицированные экстенты состоят только из одного объекта. Смешанные экстенты совместно используются до восьми объектов.
страницы
Это фундаментальная единица хранения данных в MS SQL Server. Размер страницы составляет 8 КБ. Начало каждой страницы — 96-байтовый заголовок, используемый для хранения системной информации, такой как тип страницы, объем свободного места на странице и идентификатор объекта объекта, владеющего страницей. В SQL Server существует 9 типов страниц данных.
Данные — строки данных со всеми данными, кроме текста, текста и данных изображения.
Индекс — индекс записей.
Текст \ Изображение — текст, изображение и текстовые данные.
GAM — информация о выделенных экстентах.
SGAM — информация о выделенных экстентах на системном уровне.
Page Free Space (PFS) — Информация о свободном пространстве, доступном на страницах.
Карта распределения индекса (IAM) — информация об экстентах, используемых таблицей или индексом.
Массовая измененная карта (BCM) — информация об экстентах, измененных массовыми операциями со времени последнего оператора журнала резервного копирования.
Дифференциально измененная карта (DCM) — информация об экстентах, которые изменились со времени последнего оператора резервного копирования базы данных.
Данные — строки данных со всеми данными, кроме текста, текста и данных изображения.
Индекс — индекс записей.
Текст \ Изображение — текст, изображение и текстовые данные.
GAM — информация о выделенных экстентах.
SGAM — информация о выделенных экстентах на системном уровне.
Page Free Space (PFS) — Информация о свободном пространстве, доступном на страницах.
Карта распределения индекса (IAM) — информация об экстентах, используемых таблицей или индексом.
Массовая измененная карта (BCM) — информация об экстентах, измененных массовыми операциями со времени последнего оператора журнала резервного копирования.
Дифференциально измененная карта (DCM) — информация об экстентах, которые изменились со времени последнего оператора резервного копирования базы данных.
Архитектура файла журнала
Журнал транзакций SQL Server работает логически, как если бы журнал транзакций представлял собой строку записей журнала. Каждая запись журнала идентифицируется по порядковому номеру журнала (LSN). Каждая запись журнала содержит идентификатор транзакции, которой она принадлежит.
Записи журнала для изменений данных записывают либо выполненную логическую операцию, либо они записывают образы измененных данных до и после. Предыдущее изображение является копией данных перед выполнением операции; последующее изображение является копией данных после выполнения операции.
Действия по восстановлению операции зависят от типа записи журнала.
Различные типы операций записываются в журнал транзакций. Эти операции включают в себя —
Начало и конец каждой транзакции.
Каждое изменение данных (вставить, обновить или удалить). Это включает в себя изменения с помощью системных хранимых процедур или операторов языка определения данных (DDL) для любой таблицы, включая системные таблицы.
Каждый экстент и распределение страниц или де-распределение.
Создание или удаление таблицы или индекса.
Начало и конец каждой транзакции.
Каждое изменение данных (вставить, обновить или удалить). Это включает в себя изменения с помощью системных хранимых процедур или операторов языка определения данных (DDL) для любой таблицы, включая системные таблицы.
Каждый экстент и распределение страниц или де-распределение.
Создание или удаление таблицы или индекса.
Операции отката также регистрируются. Каждая транзакция резервирует пространство в журнале транзакций, чтобы убедиться, что в журнале достаточно места для поддержки отката, вызванного либо явным оператором отката, либо в случае возникновения ошибки. Это зарезервированное пространство освобождается после завершения транзакции.
Раздел файла журнала из первой записи журнала, который должен присутствовать для успешного отката всей базы данных к последней записанной записи журнала, называется активной частью журнала или активным журналом. Это раздел журнала, необходимый для полного восстановления базы данных. Ни одна часть активного журнала не может быть усечена. LSN этой первой записи журнала известен как минимальный LSN восстановления (Min LSN).
Механизм базы данных SQL Server разделяет каждый физический файл журнала внутри на несколько виртуальных файлов журнала. Виртуальные файлы журнала не имеют фиксированного размера, и для физического файла журнала не существует фиксированного количества файлов виртуального журнала.
Компонент Database Engine выбирает размер файлов виртуального журнала динамически при создании или расширении файлов журнала. Компонент Database Engine пытается поддерживать небольшое количество виртуальных файлов. Размер или количество виртуальных файлов журнала не могут быть настроены или установлены администраторами. Единственный раз, когда виртуальные файлы журнала влияют на производительность системы, это если физические файлы журнала определяются значениями small size и growth_increment.



