Что такое SQL и как он работает


Википедия гласит, что SQL — это декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе данных, управляемой соответствующей системой управления базами данных. Не самое удобоваримое определение. Чтобы понять, о чём вообще речь, разберём его.
Декларативный язык программирования говорит, что должно быть сделано, а не как это необходимо сделать. Ещё один пример декларативного языка — HTML. Рассмотрим такой код:
С его помощью мы заявляем (declaration — заявление) браузеру, что хотим увидеть блок с классом className и кнопкой с текстом «Ясно. Понятно.» внутри. Для этого мы не создаём каких-либо переменных, циклов, условий. Мы знаем, что браузер нас понял, сам разберёт команду и вернёт результат или ошибку.
Здесь смысл довольно прост: мы даём команду и получаем результат. Мы не описываем, как эту команду выполнять. Чтобы понять, что такое реляционная база данных, разберём, что такое база данных в принципе. Декомпозируем это понятие на «база» и «данные».
Данные
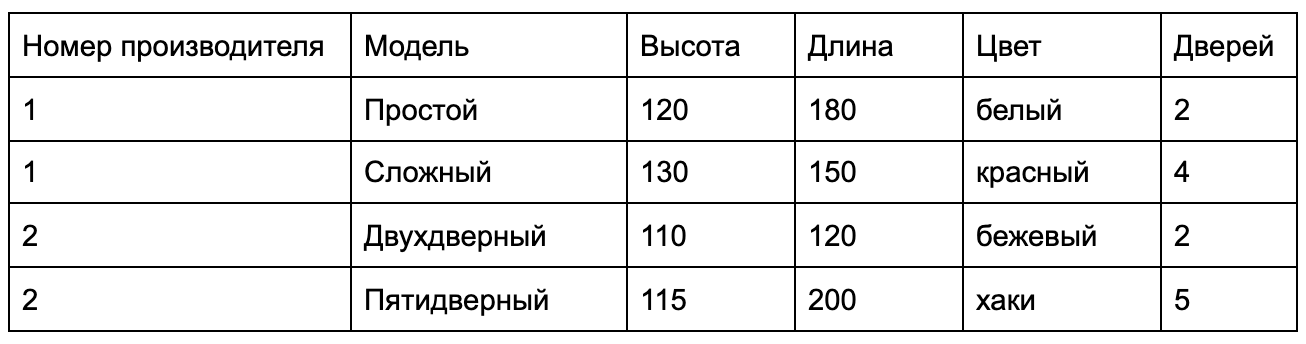
В контексте баз данных под данными понимают набор значений, который собирается в строки и столбцы, тем самым представляя таблицу. Представим, что у нас есть каталог мебельного магазина. Нам нужно сохранить все данные из раздела «Шкафы» этого каталога в таблицу. Мы решили, что все шкафы отличаются друг от друга характеристиками:
Составим таблицу и вобьём в неё выдуманные данные.

У нас есть таблица с данными. Столбцами мы показываем, как они будут храниться. В примере я указал, что мы будем хранить информацию в структуре: производитель, модель, высота, длина, цвет, количество дверей. Иными словами, я создал структуру таблицы.
Добавляя в таблицу строки, я вводил в неё данные, ориентируясь на структуру, заданную в столбцах. Чем больше строк, тем больше данных. Чем больше столбцов, тем подробнее будут эти данные.
Ещё есть такое понятие, как «значение» — это пересечение столбца и строки. Например, у последней строки в столбце «Цвет» написано «хаки». Здесь «хаки» — значение. Если мы начнём группировать таблицы и добавим возможность манипулирования ими, то получим базу данных.
Теперь про базы
Получается, что БД — это совокупность данных, представленных определённым образом (в нашем случае — таблицей), и набор инструментов для манипулирования ими.
Данные могут быть сгруппированы не только в таблицы, но и в коллекции. У каждой базы есть свой инструмент для создания таблиц/коллекций, добавления, удаления или изменения данных, а также для составления выборки. В статье мы рассмотрим базы, которые состоят из таблиц, а инструментом манипулирования данными будет язык SQL.
Таблицы между собой могут объединяться в схемы — в одной базе данных их может быть несколько, а может и не быть деления на схемы вообще. Это зависит от БД.
Вернёмся к определению из Википедии и вспомним про слово «реляционные». Реляционные (от англ. relation — отношения) — это базы данных, таблицы которых могут выстраиваться в различных отношениях. Возьмём предыдущий пример и добавим в него тех самых «отношений». Создадим таблицу «Производитель», а ту, что в примере, обозначим как «Каталог».

Теперь таблицу «Каталог» можно оформить в другом виде:
Получилось так, что у таблиц «Каталог» и «Прозводитель» появились отношения. Значения из столбца «Каталог» ссылаются на строки из таблицы «Производитель». Добавлением отношения мы решили нескольких проблем:
Это не все проблемы, которые мы решили добавлением отношений. Для понимания других проблем необходимо углубиться в тему баз данных. Разделение данных на таблицы с отношениями — это процесс нормализации. Так можно достигать различных нормализованных форм данных. При достижении каждой из нормализованных форм мы избавляем данные от дополнительных проблем.
Вернёмся к SQL
Если читателю показалось, что мы ушли в сторону от SQL, так оно и есть. Но очень трудно понять, что такое SQL, не зная, с чем он работает.
Выходит, что SQL — это язык программирования, необходимый для написания команд к БД, после выполнения которых она вернёт результат. Результат будет зависеть от команды, написанной на SQL. Как в любом другом языке программирования, в SQL есть операторы для работы с данными, из которых складываются команды. Операторы распределены по четырём языкам:
DDL (Data Definition Language, язык описания данных) — язык, включающий операторы для работы со структурой данных. Операторы DDL нужны для реализации этих возможностей:
DDL используется, когда нужно создать структуру для хранения данных. Он не отвечает за сами данные — только за то, как они будут разделены по таблицам и схемам.
DML (Data Manipulation Language, язык манипуляции данными) — язык, который нужен для добавления, удаления, изменения данных и для выборки их из базы. Иными словами, для манипулирования данными. Пройдёмся по операторам:
DCL (Data Control Language, язык управления доступом к данным) — набор операторов, необходимых для предоставления доступа к данным. Кроме данных, в БД есть такие сущности, как пользователи. Нужно обязательно иметь возможность ограничить пользователям доступ к данным. Например, мы не хотим, чтобы менеджер проекта мог редактировать данные или их структуру. Для этого есть три группы операторов.
Есть такое понятие, как транзакции. Это набор команд (там может быть и всего одна), который завершается успешно тогда, когда правильно выполнены все команды из него. В случае неудачного завершения одной команды из транзакции, она вся откатывается (отменяются результаты выполнения предыдущих команд), реализуя принцип атомарности. Обычно в транзакцию включаются DML-команды.
Для управления транзакциями существует TCL (Transaction Control Language — язык управления транзакциями). Операторы здесь следующие:
TCL есть только в тех БД, которые поддерживают транзакции. Самое время поговорить о видах БД.
Виды СУБД
Познакомимся с новым понятием — СУБД, системой управления базой данных.
Сергей Кузнецов в книге «Основы баз данных» описал СУБД как комплекс программ, позволяющих создать базу данных (БД) и манипулировать данными (вставлять, обновлять, удалять и выбирать). Система обеспечивает безопасность, надёжность хранения и целостность данных, а также предоставляет средства для администрирования БД.
Получается что, СУБД — это SQL плюс комплекс программного обеспечения. Очень часто базы данных путают с системой управления базой данных. Это нормально: понятия неразрывны, сама по себе БД без системы управления мало чем отличается от текстового файла со строчками. Важно не только хранить данные, но и управлять ими. СУБД применяются везде, где нужно структурировано хранить данные — от простого блога до проектов Data Science.
Есть много популярных СУБД, рассмотрим несколько из них.
MySQL
MySQL — свободная реляционная СУБД. Разрабатывалась как легковесная замена тяжёлым СУБД, которую можно было установить на маломощный сервер, без сильных потерь в возможностях. MySQL трудится под капотом таких гигантов, как YouTube, Facebook, Twitter, GitHub.
СУБД написана на C и C++. MySQL породил множество ответвлений, которые сейчас стали самостоятельными СУБД, например Percona и MariaDB.
Oracle Database
История Oracle Database начинается с 1977 года. Это объектно-реляционная система управления данными. Это довольно тяжёлая СУБД, поддерживает системы любой сложности, например, в банковской или финансовой сферах. У неё нет бесплатной лицензии. Процедурный SQL — PL/SQL. Языки написания СУБД — Java/C/С++
Microsoft SQL Server
Microsoft SQL Server — система управления реляционными базами данных, разработанная Microsoft. Первая версия SQL Server появилась 29 апреля 1989 года. Это конкурент Oracle Database. Есть бесплатная лицензия для разработчиков, но не для коммерческого использования. Процедурный SQL — Transact-SQL. СУБД написана на C/C++/C#.
PostgreSQL
PostgreSQL — свободная объектно-реляционная система управления базами данных. Эта СУБД увидела свет 8 июля 1996 года. Конкурент MySQL в веб-разработке проектов любой сложности, также соперничает с базами от Oracle и Microsoft в промышленной разработке. У неё прекрасная русскоязычная документация. Как и MySQL, имеет бесплатную лицензию для коммерческой разработки, за что так же, как и MySQL, горячо любима. Процедурный SQL — PL/pgSQL. Разработана на языке С.
Каждая из приведённых СУБД работает на своём расширении SQL. У каждой — своя ниша применения, плюсы и минусы.
Что после знакомства?
Если вы не знаете, какая конкретно СУБД вам нужна, выбирайте MySQL. Она лишена изысканных возможностей, которые будут только сбивать начинающего разработчика. Большое комьюнити не оставит в беде и уже решило 95% проблем. Разнообразие графических клиентов для всех операционных систем хорошо помогает на ранних этапах. MySQL позволит набраться опыта и понять, чем она хуже или лучше других СУБД. Когда вы поймёте принципы работы MySQL, для вас не составит труда переключиться на работу с PostgreSQL или другой СУБД. Цель работы у всех СУБД одна — рациональное и надёжное хранение данных и быстрое их извлечение или изменение.
После того как вы определитесь с выбором, хорошо будет посмотреть практики других разработчиков на YouTube-каналах «Технострим Mail.ru Group» или HighLoad Channel, почитать замечательный портал ruhighload.com, где, кроме статей про базы данных, рассматриваются проблемы больших нагрузок. А для тех, кто любит почитать больше, подойдёт книга «MySQL по максимуму. 3-е издание» Бэрона Шварца, Петра Зайцева и Вадима Ткаченко. Узнать больше вы, конечно, можете и в GeekBrains — приходите ко мне или моим коллегам на курс «Основы баз данных».
Освоить востребованную профессию в Data Science можно всего за полтора года на курсах GeekBrains. После учёбы вы сможете работать по специальностям Data Scientist, Data Analyst, Machine Learning, Engineer Computer Vision-специалист или NLP-специалист.
Википедия гласит, что SQL — это декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе данных, управляемой соответствующей системой управления базами данных. Не самое удобоваримое определение. Чтобы понять, о чём вообще речь, разберём его.
Декларативный язык программирования говорит, что должно быть сделано, а не как это необходимо сделать. Ещё один пример декларативного языка — HTML. Рассмотрим такой код:
С его помощью мы заявляем (declaration — заявление) браузеру, что хотим увидеть блок с классом className и кнопкой с текстом «Ясно. Понятно.» внутри. Для этого мы не создаём каких-либо переменных, циклов, условий. Мы знаем, что браузер нас понял, сам разберёт команду и вернёт результат или ошибку.
Здесь смысл довольно прост: мы даём команду и получаем результат. Мы не описываем, как эту команду выполнять. Чтобы понять, что такое реляционная база данных, разберём, что такое база данных в принципе. Декомпозируем это понятие на «база» и «данные».
Данные
В контексте баз данных под данными понимают набор значений, который собирается в строки и столбцы, тем самым представляя таблицу. Представим, что у нас есть каталог мебельного магазина. Нам нужно сохранить все данные из раздела «Шкафы» этого каталога в таблицу. Мы решили, что все шкафы отличаются друг от друга характеристиками:
Составим таблицу и вобьём в неё выдуманные данные.
У нас есть таблица с данными. Столбцами мы показываем, как они будут храниться. В примере я указал, что мы будем хранить информацию в структуре: производитель, модель, высота, длина, цвет, количество дверей. Иными словами, я создал структуру таблицы.
Добавляя в таблицу строки, я вводил в неё данные, ориентируясь на структуру, заданную в столбцах. Чем больше строк, тем больше данных. Чем больше столбцов, тем подробнее будут эти данные.
Ещё есть такое понятие, как «значение» — это пересечение столбца и строки. Например, у последней строки в столбце «Цвет» написано «хаки». Здесь «хаки» — значение. Если мы начнём группировать таблицы и добавим возможность манипулирования ими, то получим базу данных.
Теперь про базы
Получается, что БД — это совокупность данных, представленных определённым образом (в нашем случае — таблицей), и набор инструментов для манипулирования ими.
Данные могут быть сгруппированы не только в таблицы, но и в коллекции. У каждой базы есть свой инструмент для создания таблиц/коллекций, добавления, удаления или изменения данных, а также для составления выборки. В статье мы рассмотрим базы, которые состоят из таблиц, а инструментом манипулирования данными будет язык SQL.
Таблицы между собой могут объединяться в схемы — в одной базе данных их может быть несколько, а может и не быть деления на схемы вообще. Это зависит от БД.
Вернёмся к определению из Википедии и вспомним про слово «реляционные». Реляционные (от англ. relation — отношения) — это базы данных, таблицы которых могут выстраиваться в различных отношениях. Возьмём предыдущий пример и добавим в него тех самых «отношений». Создадим таблицу «Производитель», а ту, что в примере, обозначим как «Каталог».
Теперь таблицу «Каталог» можно оформить в другом виде:
Получилось так, что у таблиц «Каталог» и «Прозводитель» появились отношения. Значения из столбца «Каталог» ссылаются на строки из таблицы «Производитель». Добавлением отношения мы решили нескольких проблем:
Это не все проблемы, которые мы решили добавлением отношений. Для понимания других проблем необходимо углубиться в тему баз данных. Разделение данных на таблицы с отношениями — это процесс нормализации. Так можно достигать различных нормализованных форм данных. При достижении каждой из нормализованных форм мы избавляем данные от дополнительных проблем.
Вернёмся к SQL
Если читателю показалось, что мы ушли в сторону от SQL, так оно и есть. Но очень трудно понять, что такое SQL, не зная, с чем он работает.
Выходит, что SQL — это язык программирования, необходимый для написания команд к БД, после выполнения которых она вернёт результат. Результат будет зависеть от команды, написанной на SQL. Как в любом другом языке программирования, в SQL есть операторы для работы с данными, из которых складываются команды. Операторы распределены по четырём языкам:
DDL (Data Definition Language, язык описания данных) — язык, включающий операторы для работы со структурой данных. Операторы DDL нужны для реализации этих возможностей:
DDL используется, когда нужно создать структуру для хранения данных. Он не отвечает за сами данные — только за то, как они будут разделены по таблицам и схемам.
DML (Data Manipulation Language, язык манипуляции данными) — язык, который нужен для добавления, удаления, изменения данных и для выборки их из базы. Иными словами, для манипулирования данными. Пройдёмся по операторам:
DCL (Data Control Language, язык управления доступом к данным) — набор операторов, необходимых для предоставления доступа к данным. Кроме данных, в БД есть такие сущности, как пользователи. Нужно обязательно иметь возможность ограничить пользователям доступ к данным. Например, мы не хотим, чтобы менеджер проекта мог редактировать данные или их структуру. Для этого есть три группы операторов.
Есть такое понятие, как транзакции. Это набор команд (там может быть и всего одна), который завершается успешно тогда, когда правильно выполнены все команды из него. В случае неудачного завершения одной команды из транзакции, она вся откатывается (отменяются результаты выполнения предыдущих команд), реализуя принцип атомарности. Обычно в транзакцию включаются DML-команды.
Для управления транзакциями существует TCL (Transaction Control Language — язык управления транзакциями). Операторы здесь следующие:
TCL есть только в тех БД, которые поддерживают транзакции. Самое время поговорить о видах БД.
Виды СУБД
Познакомимся с новым понятием — СУБД, системой управления базой данных.
Сергей Кузнецов в книге «Основы баз данных» описал СУБД как комплекс программ, позволяющих создать базу данных (БД) и манипулировать данными (вставлять, обновлять, удалять и выбирать). Система обеспечивает безопасность, надёжность хранения и целостность данных, а также предоставляет средства для администрирования БД.
Получается что, СУБД — это SQL плюс комплекс программного обеспечения. Очень часто базы данных путают с системой управления базой данных. Это нормально: понятия неразрывны, сама по себе БД без системы управления мало чем отличается от текстового файла со строчками. Важно не только хранить данные, но и управлять ими. СУБД применяются везде, где нужно структурировано хранить данные — от простого блога до проектов Data Science.
Есть много популярных СУБД, рассмотрим несколько из них.
MySQL
MySQL — свободная реляционная СУБД. Разрабатывалась как легковесная замена тяжёлым СУБД, которую можно было установить на маломощный сервер, без сильных потерь в возможностях. MySQL трудится под капотом таких гигантов, как YouTube, Facebook, Twitter, GitHub.
СУБД написана на C и C++. MySQL породил множество ответвлений, которые сейчас стали самостоятельными СУБД, например Percona и MariaDB.
Oracle Database
История Oracle Database начинается с 1977 года. Это объектно-реляционная система управления данными. Это довольно тяжёлая СУБД, поддерживает системы любой сложности, например, в банковской или финансовой сферах. У неё нет бесплатной лицензии. Процедурный SQL — PL/SQL. Языки написания СУБД — Java/C/С++
Microsoft SQL Server
Microsoft SQL Server — система управления реляционными базами данных, разработанная Microsoft. Первая версия SQL Server появилась 29 апреля 1989 года. Это конкурент Oracle Database. Есть бесплатная лицензия для разработчиков, но не для коммерческого использования. Процедурный SQL — Transact-SQL. СУБД написана на C/C++/C#.
PostgreSQL
PostgreSQL — свободная объектно-реляционная система управления базами данных. Эта СУБД увидела свет 8 июля 1996 года. Конкурент MySQL в веб-разработке проектов любой сложности, также соперничает с базами от Oracle и Microsoft в промышленной разработке. У неё прекрасная русскоязычная документация. Как и MySQL, имеет бесплатную лицензию для коммерческой разработки, за что так же, как и MySQL, горячо любима. Процедурный SQL — PL/pgSQL. Разработана на языке С.
Каждая из приведённых СУБД работает на своём расширении SQL. У каждой — своя ниша применения, плюсы и минусы.
Что после знакомства?
Если вы не знаете, какая конкретно СУБД вам нужна, выбирайте MySQL. Она лишена изысканных возможностей, которые будут только сбивать начинающего разработчика. Большое комьюнити не оставит в беде и уже решило 95% проблем. Разнообразие графических клиентов для всех операционных систем хорошо помогает на ранних этапах. MySQL позволит набраться опыта и понять, чем она хуже или лучше других СУБД. Когда вы поймёте принципы работы MySQL, для вас не составит труда переключиться на работу с PostgreSQL или другой СУБД. Цель работы у всех СУБД одна — рациональное и надёжное хранение данных и быстрое их извлечение или изменение.
После того как вы определитесь с выбором, хорошо будет посмотреть практики других разработчиков на YouTube-каналах «Технострим Mail.ru Group» или HighLoad Channel, почитать замечательный портал ruhighload.com, где, кроме статей про базы данных, рассматриваются проблемы больших нагрузок. А для тех, кто любит почитать больше, подойдёт книга «MySQL по максимуму. 3-е издание» Бэрона Шварца, Петра Зайцева и Вадима Ткаченко. Узнать больше вы, конечно, можете и в GeekBrains — приходите ко мне или моим коллегам на курс «Основы баз данных».
Освоить востребованную профессию в Data Science можно всего за полтора года на курсах GeekBrains. После учёбы вы сможете работать по специальностям Data Scientist, Data Analyst, Machine Learning, Engineer Computer Vision-специалист или NLP-специалист.
История СУБД Oracle — первой коммерчески успешной реляционной СУБД

До середины 70-х годов информация в базах данных распределялась по старинному иерархическому, или «древовидному», принципу, который до сих пор используется в настольных операционных системах.
Первые прототипы реляционных СУБД существовали уже в 70-е годы ХХ века. Однако мало кто верил в возможность добиться эффективной реализации таких систем. Тем не менее, к концу 1980-х годов реляционные системы заняли на мировом рынке СУБД доминирующее положение.
В связи с этим многие компании стали позиционировать свои СУБД как «реляционные» в рекламных целях. Но далеко не всегда они имели для этого достаточно оснований. Поэтому автор реляционной модели данных Эдгар Кодд в 1985 году опубликовал свои знаменитые «12 правил Кодда», которым должна удовлетворять каждая РСУБД.

16 июня 1977 года Эдом Оутсом, Бобом Майнером и Ларри Эллисоном в Калифорнии (США) была основана компания Software Development Laboratories, вскоре переименованная в Relational Software Inc. Молодые программисты начали разработку системы управления базами данных (СУБД), построенной на принципах реляционной алгебры.
Oracle 2
Первая коммерческая версия СУБД Oracle получила название Oracle 2. Такой ход должен был дать заказчикам понять, что система надежна и даже прошла проверку временем.
В конце 70-х главным конкурентным преимуществом СУБД Oracle была высокая скорость обработки огромных массивов информации, которую отметили все эксперты. В отличие от System R, для работы которой был необходим мощный суперкомпьютер — мейнфрейм, Oracle 2 справлялась с обработкой информации на более «миниатюрных» машинах. Эти и другие преимущества привели к тому, что в начале 80-х годов СУБД начала стремительно распространяться.
У Эллисона с коллегами возникли сложности при реализации совместимости с СУБД IBM System R. Нежелание IBM раскрывать исходные коды стало ключевой проблемой. В результате совместимости между двумя системами так и не удалось достичь.

Ларри Эллисон — основатель Oracle
Oracle стала исторически первой и одной из наиболее развитых реализаций архитектуры клиент/сервер. Переносимость и масштабируемость всегда имели высокий приоритет у разработчиков Oracle. Это сыграло ключевую роль в достижении успеха компании на рынке СУБД.
Oracle 2 работала на мини-компьютере PDP-11 фирмы Digital Equipment в операционной среде RSX-11. Большая часть Oracle была написана на ассемблере PDP-11, а отдельные компоненты — на новом для того времени языке C. Уже в те дни система была портируемой и работала в других операционных средах PDP-11: IAS, RSTS и UNIX. Тогда же было принято решение о переносе Oracle в новую ОС VMS. Благодаря этому СУБД Oracle заняла обширную нишу корпоративных информационных систем на быстро растущем рынке VAX.
Еще одной важной особенностью системы стала полная реализация возможностей нового языка запросов SQL — подзапросы, операция соединения и так далее. Благодаря этому многократно выросла производительность труда SQL-программистов.
Стандартный SQL (IBM) был расширен операцией CONNECT BY, позволяющим обрабатывать древовидные структуры, что становится уникальным для SQL-систем.
Конечно, над СУБД нужно было еще долго работать. В Oracle 2, например, не поддерживались транзакции: если в процессе обновления базы данных происходил сбой, предыдущее состояние БД восстановить было практически невозможно. Поэтому пользователи были вынуждены часто делать резервные копии базы данных во избежание потерь информации.
29 октября 1982 года компания переименована в Oracle Systems.
Oracle 3 и 4
В 1983 году на рынок вышла Oracle 3. Она была полностью переписана на С. Это во многом помогло решить проблему переносимости Oracle на широкий спектр платформ – их тогда было не менее 20. Кроме того, было реализовано атомарное выполнение транзакций: операция либо выполнялась полностью, либо не выполнялась вообще, соответственно, транзакция либо завершалась успешно по всем изменениям базы данных, либо откатывала все сделанные ею изменения.
С выходом Oracle 4 система была портирована на большие компьютеры c ОС VM и MVS, а также на персональный компьютер с 640 килобайтами оперативной памяти.
Также была реализована модель контроля доступа к базе данных, которая гарантировала, что результат запроса не противоречит состоянию базы данных на начало запроса. Благодаря этому было устранено известное противоречие между процессами чтения и записи.
Oracle 5
В 1985 году Oracle выпустила на рынок версию 5.0, в которой была впервые введена архитектура клиент/сервер. Кроме того, компания выпустила SQL*Net – сетевой продукт, обеспечивающий прозрачное соединение между клиентом и базой данных или между двумя базами данных.
В версии 5.1 были впервые реализованы распределенные запросы — это давало возможность обращаться к данным, физически размещенным в разных узлах. Несколько взаимодействующих серверов могли создать у пользователя многих физически разнесенных баз данных иллюзию единой логической базы данных.
Oracle 6
Разработчики версии 6 стремились создать инструмент построения крупномасштабных информационных систем, ориентированных на обработку транзакций в режиме реального времени.
Были введены генераторы последовательностей и блокировка на уровне записи. В это же время Oracle стал первым многопользовательским сетевым сервером баз данных для OS/2, Xenix, Banyan Vines и Macintosh.
В версии 6 были заложены принципиально новые возможности, в полном объеме реализованные позже:
Кризис
В 1990 году компания столкнулась с серьезными проблемами, сообщив о значительных убытках. Эллисону пришлось уволить более 400 сотрудников для сокращения издержек. Он также распустил практически весь топ-менеджмент, в числе которого были близкие Ларри люди, в течение 10 лет вместе с ним приумножавшие славу и благосостояние Oracle. Ларри оставил в компании Боба Майнера, которого всегда считал одаренным программистом и просто хорошим добрым человеком.
Столь жесткие методы Ларри объяснил так:
Кроме того, из-за совершенных ошибок в регистрации продаж и учёта ещё не прошедших сделок в бухгалтерских документах у Oracle возникли сложности с регуляторами на местном рынке.
В результате Oracle оказалась близка к банкротству, а такие конкуренты, как Informix и Sybase, начали медленно увеличивать свою долю на рынке.
На тот момент конкуренция между крупными игроками рынка достигла своего апогея — 90-ые могли запомниться многим, как период рекламной войны Oracle и Informix. Так, последняя выкупила билборд рядом с офисом Oracle и разместила на нем надпись «Осторожно, динозавры переходят дорогу», намекая на устаревшие технологии Oracle.

Однако Ларри все-таки нашел решение: он сформировал новый управленческий штат, который был «натаскан» на громадные объемы производства и жесткую конкуренцию. В результате через определенное время Oracle снова вернулась на прежние высоты.
А в 1992 году релиз Oracle 7 окончательно изменил ситуацию в лучшую сторону.
Oracle 7
Помимо общего повышения эффективности ввода/вывода, использования центрального процессора и работы с памятью, версия СУБД Oracle 7 обладала рядом инновационных архитектурных решений:
В версии 7 были полностью реализованы декларативные ограничения ссылочной целостности в соответствии со стандартами ANSI/ISO. В рамках этих ограничений (первичные и внешние ключи) пользователь мог специфицировать каскадное удаление связанных с некоторым первичным ключом записей. Процедуры PL/SQL могли описываться на уровне схемы базы данных (хранимые процедуры) и вызываться любым приложением, другими процедурами и триггерами.
Другим важным нововведением стали триггеры базы данных.
Триггер представляет собой пару (событие+действие), где событие — это удаление/занесение/обновление записей таблицы, а действие (тело триггера) — процедура PL/SQL, выполняемая при совершении события.
Триггеры могут определяться на уровне операций (DELETE, INSERT, UPDATE) или на уровне отдельных строк (FOR-EACH-ROW-триггеры, которые, к тому же, могут работать со старыми и новыми значениями строк). С помощью триггеров можно реализовать сложные правила контроля целостности, прав доступа, вывода значений и прочее.
Роль — это совокупность прав доступа к объектам базы данных (INSERT, UPDATE, SELECT и другие) и системных прав (CREATE TABLE, ALTER SYSTEM и так далее). Определив роль, администратор базы данных может с помощью одной команды дать пользователю привилегии для работы с некоторым приложением.
В 1994 году компания выпустила версию Oracle 7.1, в том числе и для IBM PC. Ранее Oracle не рассматривала эту платформу как серверную, а ограничивалась лишь созданием для нее клиентских частей своей СУБД.
В Oracle 7.1 появилась опция параллельных запросов (parallel query option), а также возможность определения количества серверных процессов, необходимых для выполнения SQL-запроса, на основе результатов работы оптимизатора запросов. В данной версии была достигнута полная интеграция PL/SQL и SQL, введен встроенный пакет DBMS_SQL и асинхронная симметричная репликация данных вместе с асинхронным вызовом удаленных процедур.
Oracle 8 и 9
В 1997 году вышла версия 8, в которой появились объектная модель, новые свойства и средства администрирования. Oracle 8.0 была более надежной по сравнению с предыдущей версией, обладала большей устойчивостью к высоким нагрузкам. Кроме того, в ней была реализована возможность партиционирования таблиц.
В 1998 году компания анонсировала Oracle 8i Release 1 (8.1.5). Буква «i» означает, что версия обладает поддержкой Интернета.
Начиная с Oracle 8.1.5 в последующих версиях появляется встроенная в СУБД виртуальная машина Java (JVM). Далее вышла версия Oracle 8i Release 2 (8.1.6), которая поддерживала XML, а также содержала определенные новшества, связанные с созданием хранилищ данных.
В 2001 году появилась версия Oracle 9i Release 1 (9.0.1), в которой было сделано более 400 изменений по сравнению с предыдущей. Среди них – «интеллектуализация» автоматизированных систем и расширение возможностей для аналитики.
В новой версии появились средства обработки XML-документов, технология Oracle RAC (Real Application Clusters) – как замена Oracle Parallel Server (OPS), механизм создания репликаций Oracle Streams, скроллируемый курсор для программ на Си и C++, встроенная в СУБД поддержка OLAP и Data Mining, переименование столбцов и ограничений целостности, поддержка Java 1.3.1 и Unicode 3.1.
Лучшие финансовые годы
Примерное разделение рынка СУБД для платформы Unix.
Примерное разделение рынка СУБД для платформы Windows NT.
В 2004 году появилась версия Oracle 10g Release 1 (10.1.0). Буква «g» в названии обозначает «Grid» («сеть») и символизирует поддержку Grid-вычислений.
Этот год стал одним из самых успешных в истории компании – норма прибыли составила 38% (самый высокий показатель за все время существования корпорации), годовой оборот возрос до 7% ($10,2 миллиарда), доходы от продаж ПО поднялись на 12% ($8,1 миллиарда), чистая прибыль выросла на 16% ($2,7 миллиарда).
Офис Oracle в России и СНГ вошел в тройку лучших представительств Oracle по темпам роста в регионе ЕМЕА (Европа, Ближний Восток и Африка), а также пятый год подряд — в пятерку лучших среди 145 представительств Oracle в мире.
До наших дней
В 2005-м была анонсирована Oracle 10g Release 2 (10.2.0.1). А в 2007-м – Oracle 11g Release 1 (11.1.0.6).
Состояние рынка СУБД на 2007 год
В 2009 году компания выпустила Oracle 11g Release 2 (11.2.0.1). В версию была введена новая для Oracle возможность «горячего» (без остановки сервера) внесения изменений в метаданные и бизнес-логику на PL/SQL – это стало возможным благодаря механизму одновременной поддержки нескольких версий схемы и логики под названием editions.
2013 год — вышла версия 12c (12.1.0.1), основное новшество — поддержка подключаемых баз данных (pluggable database), обеспечивающая свойства мультиарендности и живой миграции баз данных, суффикс «c» в названии обозначает cloud (облако).
24 апреля 2015 года стало известно о планах Oracle перевести почти все свои продукты в облако. Таким образом, американская компания решила изменить свою бизнес-модель, чтобы соответствовать изменениям на рынке.

В сентябре 2016 года Ларри Эллисон объявил о создании в Oracle дата-центров для работы с IaaS второго поколения и заявил, что лидерство компании Amazon на облачном рынке подходит к концу. Цель компании – предложить клиентам Oracle пакет услуг, где будут совмещены IaaS, PaaS и SaaS («ПО как услуга»).



