Query Parameters
In web development, query parameters are used within a URL as described above but can also be used in API requests that retrieve data. Ember treats these as two different concepts. This section describes how routing query parameters are used in Ember. See finding records to see how query parameters are applied to API requests in Ember Data.
Specifying Query Parameters
To add a category query parameter that will filter out all the articles that haven’t been categorized as popular we’d specify ‘category’ as one of controller:articles ‘s queryParams :
Now we need to define a getter for our category-filtered array, which the articles template will render. For the getter to recompute when values change, category and model should be marked as tracked properties:
With this code, we have established the following behaviors:
In the above examples, direction is presumably a query param property on the posts controller, but it could also refer to a direction property on any of the controllers associated with the posts route hierarchy, matching the leaf-most controller with the supplied property name.
transitionTo
You can also add query params to URL transitions:
Opting into a full transition
Update URL with replaceState instead
By default, Ember will use pushState to update the URL in the address bar in response to a controller query param property change. If you would like to use replaceState instead, which prevents an additional item from being added to your browser’s history, you can specify this as follows:
Map a controller’s property to a different query param key
This will cause changes to the controller:articles ‘s category property to update the articles_category query param, and vice versa.
Query params that require additional customization can be provided along with strings in the queryParams array.
Default values and deserialization
This affects query param behavior in two ways:
Sticky Query Param Values
By default, query param values in Ember are «sticky», in that if you make changes to a query param and then leave and re-enter the route, the new value of that query param will be preserved (rather than reset to its default). This is a particularly handy default for preserving sort/filter parameters as you navigate back and forth between routes.
the generated links would be:
This illustrates that once you change a query param, it is stored and tied to the model loaded into the route.
If you wish to reset a query param, you have two options:
In the following example, the controller’s page query param is reset to 1, while still scoped to the pre-transition ArticlesRoute model. The result of this is that all links pointing back into the exited route will use the newly reset value 1 as the value for the page query param.
In some cases, you might not want the sticky query param value to be scoped to the route’s model but would rather reuse a query param’s value even as a route’s model changes. This can be accomplished by setting the scope option to «controller» within the controller’s queryParams config hash:
The following demonstrates how you can override both the scope and the query param URL key of a single controller query param property:
A Beginner’s Guide to URL Parameters
Mar 19, 2021 7 min read

URL Parameters and How They Impact SEO
URL parameters are an integral part of URL structures. Although they are an invaluable asset in the hands of seasoned SEO professionals, query strings often present serious challenges for your website rankings.
In this guide, you’ll find the most common SEO issues to watch out for when working with URL parameters.
What Are URL Parameters?
URL parameters (known also as “query strings” or “URL query parameters”) are elements inserted in your URLs to help you filter and organize content or track information on your website.
In short, URL parameters are a way to pass information about a click using the URL itself.
To identify a URL parameter, refer to the portion of the URL that comes after a question mark (?). URL parameters are made of a key and a value, separated by an equal sign (=). Multiple parameters are each then separated by an ampersand (&).
A URL string with parameters looks like this:

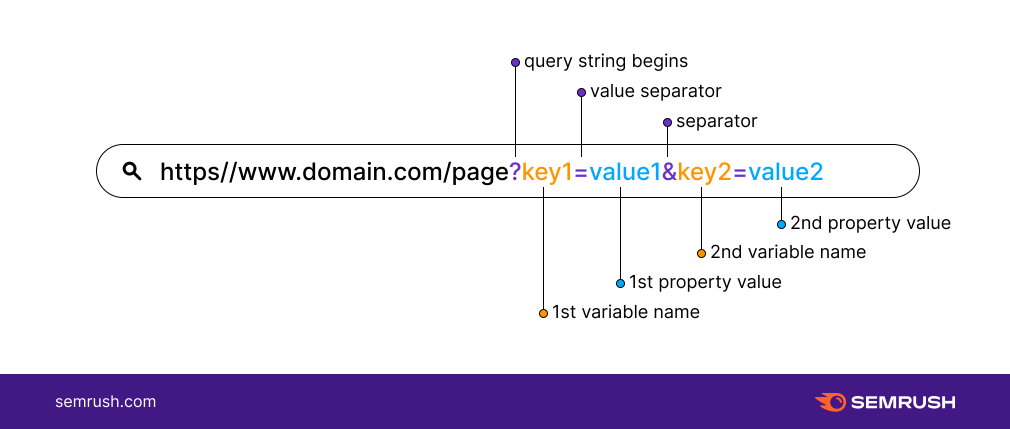
Key1: first variable name
Key2: second variable name
Value1: first property value
Value2: second property value
? : query string begins
= : value separator
& : parameter separator
How to Use URL Parameters (with Examples)
URL parameters are commonly used to sort content on a page, making it easier for users to navigate products in an online store. These query strings allow users to order a page according to specific filters, and to view only a set amount of items per page.

Query strings of tracking parameters are equally common. They’re often used by digital marketers to monitor where traffic comes from, so they can determine whether their latest investment in social, ad campaign, or newsletter was successful.
Handle URL Parameters
with the Site Audit Tool
How Do URL Parameters Work?
According to Google Developers, there are two types of URL parameters:
1. Content-modifying parameters (active): parameters that will modify the content displayed on the page
2. Tracking parameters (passive) for advanced tracking: parameters that will pass information about the click — i.e. which network it came from, which campaign or ad group etc. — but won’t change the content on the page.
This information will be clearly recorded in a tracking template and will include valuable data for you to evaluate your recent marketing investments.
It might seem fairly simple to manage, but there is a correct and an incorrect way to use URL parameters, which we’ll discuss shortly after some examples.
URL Query String Examples
Common uses for URL parameters include:

When Do URL Parameters Become an SEO Issue?
Most SEO-friendly advice for URL structuring suggests keeping away from URL parameters as much as possible. This is because however useful URLs parameters might be, they tend to slow down web crawlers as they eat up a good chunk of crawl budget.
Poorly structured, passive URL parameters that do not change the content on the page (such as session IDs, UTM codes and affiliate IDs) hold the potential to create endless URLs with non-unique content.
The most common SEO issues caused by URL parameters are:
1. Duplicate content: Since every URL is treated by search engines as an independent page, multiple versions of the same page created by a URL parameter might be considered duplicate content. This is because a page reordered according to a URL parameter is often very similar to the original page, while some parameters might return the exact same content as the original.
2. Loss in crawl budget: Keeping a simple URL structure is part of the basics for URL optimization. Complex URLs with multiple parameters create many different URLs that point to identical (or similar) content. According to Google Developers, crawlers might decide to avoid “wasting” bandwidth indexing all content on the website, mark it as low-quality and move on to the next one.
3. Keyword cannibalization: Filtered versions of the original URL target the same keyword group. This leads to various pages competing for the same rankings, which may lead crawlers to decide that the filtered pages do not add any real value for the users.
4. Diluted ranking signals: With multiple URLs pointing to the same content, links and social shares might point to any parameterized version of the page. This can further confuse crawlers, who won’t understand which of the competing pages should be ranking for the search query.
5. Poor URL readability: When optimizing URL structure, we want the URL to be straightforward and understandable. A long string of code and numbers hardly fits the bill. A parameterized URL is virtually unreadable for users. When displayed in the SERPs or in a newsletter or on social media, the parameterized URL looks spammy and untrustworthy, making it less likely for users to click on and share the page.
How to Manage URL Parameters for Good SEO
The majority of the aforementioned SEO issues point to one main cause: crawling and indexing all parameterized URLs. But thankfully, webmasters are not powerless against the endless creation of new URLs via parameters.
At the core of good URL parameter handling, we find proper tagging.
Please note: SEO issues arise when URLs containing parameters display duplicate, non-unique content, i.e. those generated by passive URL parameters. These links — and only these links — should not be indexed.
Check Your Crawl Budget
Your crawl budget is the number of pages bots will crawl on your site before moving on to the next one. Every website has a different crawl budget, and you should always make sure yours is not being wasted.
Unfortunately, having many crawlable, low-value URLs — such as parameterized URLs created from faceted navigations — is a waste of the crawl budget.
Consistent Internal Linking
If your website has many parameter-based URLs, it is important to signal to crawlers which page not to index and to consistently link to the static, non-parameterized page.
For example, here are a few parameterized URLs from an online shoe store:

In this case, be careful and consistently link only to the static page and never to the versions with parameters. In this way you will avoid sending inconsistent signals to search engines as to which version of the page to index.
Canonicalize One Version of the URL
Once you decided on which static page should be indexed, remember to canonicalize it. Set up canonical tags on the parameterized URLs, referencing the preferred URL.
If you create parameters to help users navigate your online shop landing page for shoes, all URL variations should include the canonical tag identifying the main landing page as the canonical page. So for example:
In this case, the three URLs above are “related” to the non-parameterized women shoes landing page. This will send a signal to crawlers that only the main landing page is to be indexed and not the parameterized URLs.
Block Crawlers via Disallow
URL parameters intended to sort and filter can potentially create endless URLs with non-unique content. You can choose to block crawlers from accessing these sections of your website by using the disallow tag.
Blocking crawlers, like Googlebot, from crawling parameterized duplicate content means controlling what they can access on your website via robots.txt. The robots.txt file is checked by bots before crawling a website, thus making it a great point to start when optimizing your parameterized URLs.
The following robots.txt file will disallow any URLs featuring a question mark:
This disallow tag will block all URL parameters from being crawled by search engines. Before choosing this option, make sure no other portion of your URL structure uses parameters, or those will be blocked as well.
You might need to carry out a crawl yourself to locate all URLs containing a question mark (?).
Move URL Parameters to Static URLs
This falls into the wider discussion about dynamic vs static URLs. Rewriting dynamic pages as static ones improves the URL structure of the website.
However, especially if the parameterized URLs are currently indexed, you should take the time not only to rewrite the URLs but also to redirect those pages to their corresponding new static locations.
Google Developers also suggest to:
Using Semrush’s URL Parameter Tool
As it must be clear by now, handling URL parameters is a complex task and you might need some help with it. When setting up a site audit with Semrush, you can save yourself a headache by identifying early on all URL parameters to avoid crawling.
In the Site Audit tool settings, you’ll find a dedicated step ( Remove URL parameters) where you can list the parameters URLs to ignore during a crawl (UTMs, page, language etc.)
This is useful because, as we mentioned before, not all parameterized URLs need to be crawled and indexed. Content-modifying parameters do not usually cause duplicate content and other SEO issues so having them indexed will add value to your website.
If you already have a project set up in Semrush, you can still change your URL parameter settings by clicking on the gear icon.
Incorporating URL Parameters into your SEO Strategy
Parameterized URLs make it easier to modify or track content, so it’s worth incorporating them when you need to. You’ll need to let web crawlers know when to and when not to index specific URLs with parameters, and to highlight the version of the page that is the most valuable.
Take your time and decide which parameterized URLs shouldn’t be indexed. With time, web crawlers will better understand how to navigate and value your site’s pages.
Use query parameters to customize responses
Microsoft Graph supports optional query parameters that you can use to specify and control the amount of data returned in a response. The support for the exact query parameters varies from one API operation to another, and depending on the API, can differ between the v1.0 and beta endpoints.
Query parameters can be OData system query options or other query parameters.
OData system query options
A Microsoft Graph API operation might support one or more of the following OData system query options. These query options are compatible with the OData V4 query language.
Note: OData 4.0 supports system query options in only GET operations.
Click the examples to try them in Graph Explorer.
Other query parameters
Other OData URL capabilities
The following OData 4.0 capabilities are URL segments, not query parameters.
| Name | Description | Example |
|---|---|---|
| $count | Retrieves the integer total of the collection. | GET /users/$count GET /groups/ |
| $ref | Updates entities membership to a collection. | POST /groups/ |
| $value | Retrieves or updates the binary value of an item. | GET /me/photo/$value |
Encoding query parameters
The values of query parameters should be percent-encoded. Many HTTP clients, browsers, and tools (such as the Graph Explorer) will help you with this. If a query is failing, one possible cause is failure to encode the query parameter values appropriately.
An unencoded URL looks like this:
A properly encoded URL looks like this:
Escaping single quotes
For requests that use single quotes, if any parameter values also contain single quotes, those must be double escaped; otherwise, the request will fail due to invalid syntax. In the example, the string value let»s meet for lunch? has the single quote escaped.
count parameter
$count can also be used as a URL segment to retrieve the integer total of the collection. On resources that derive from directoryObject, is it only supported in an advanced query. See Advanced query capabilities in Azure AD directory objects.
For example, the following request returns both the contact collection of the current user, and the number of items in the contact collection in the @odata.count property.
expand parameter
Many Microsoft Graph resources expose both declared properties of the resource as well as its relationships with other resources. These relationships are also called reference properties or navigation properties, and they can reference either a single resource or a collection of resources. For example, the mail folders, manager, and direct reports of a user are all exposed as relationships.
The following example gets root drive information along with the top-level child items in a drive:
filter parameter
The following example finds users whose display name starts with the letter ‘J’:
Filter using lambda operators
OData defines the any and all operators to evaluate matches on multi-valued properties, that is, either collection of primitive values such as String types or collection of entities.
Note: For directory objects like users, the not and ne operators are supported only in advanced queries.
Examples using the filter query operator
Note: Click the examples to try them in Graph Explorer.
format parameter
For example, the following request returns the users in the organization in the json format:
orderby parameter
For example, the following request returns the users in the organization ordered by their display name:
You can also sort by complex type entities. The following request gets messages and sorts them by the address field of the from property, which is of the complex type emailAddress:
With some APIs, you can order results on multiple properties. For example, the following request orders the messages in the user’s Inbox, first by the name of the person who sent it in descending order (Z to A), and then by subject in ascending order (default).
The following example shows a query filtered by the subject and importance properties, and then sorted by the subject, importance, and receivedDateTime properties in descending order.
search parameter
select parameter
For example, when retrieving the messages of the signed-in user, you can specify that only the from and subject properties be returned:
skip parameter
The ConsistencyLevel header required for advanced queries against directory objects is not included by default in subsequent page requests. It must be set explicitly in subsequent pages.
skipToken parameter
The ConsistencyLevel header required for advanced queries against directory objects is not included by default in subsequent page requests. It must be set explicitly in subsequent pages.
top parameter
If more items remain in the result set, the response body will contain an @odata.nextLink parameter. This parameter contains a URL that you can use to get the next page of results. To learn more, see Paging.
For example, the following list messages request returns the first five messages in the user’s mailbox:
The ConsistencyLevel header required for advanced queries against directory objects is not included by default in subsequent page requests. It must be set explicitly in subsequent pages.
Error handling for query parameters
However, it is important to note that query parameters specified in a request might fail silently. This can be true for unsupported query parameters as well as for unsupported combinations of query parameters. In these cases, you should examine the data returned by the request to determine whether the query parameters you specified had the desired effect.



