Пример нахождения коэффициента детерминации
Коэффициент детерминации рассчитывается для оценки качества подбора уравнения регрессии. Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 50%. Модели с коэффициентом детерминации выше 80% можно признать достаточно хорошими. Значение коэффициента детерминации R 2 = 1 означает функциональную зависимость между переменными.
В случае нелинейной регрессии коэффициент детерминации рассчитывается через этот калькулятор. При множественной регрессии, коэффициент детемрминации можно найти через сервис Множественная регрессия
Уравнение имеет вид y = ax + b
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая.
Уравнение регрессии
Анализ точности определения оценок коэффициентов регрессии
S a = 3.3432
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 1
(-557.64;913.38)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается (6.95>1.812).
Статистическая значимость коэффициента регрессии b не подтверждается (0.96 Fkp, то коэффициент детерминации статистически значим
R Квадрат Интерпретация | R квадрат линейная регрессия
Дата публикации Apr 30, 2019
Машинное обучение включает в себя много статистики. В следующей статье мы рассмотрим концепцию R-Squared, которая полезна при выборе функций.
Последнее звучит довольно запутанно, поэтому давайте рассмотрим пример. Предположим, мы решили построить график зависимости зарплаты от многолетнего опыта. На следующем графике каждая точка данных представляет человека.

Мы можем рассчитать среднее или среднее значение, взяв сумму всех лиц в выборке и разделив ее на общее количество людей в выборке.

Дисперсия всего набора данных равна сумме расстояния между каждой точкой данных и средним квадратом. Разница возводится в квадрат так, что баллы ниже среднего не отменяются баллами выше среднего.

Теперь скажем, мы взяли тех же людей, но на этот раз мы решили построить график зависимости их зарплаты от роста.

Обратите внимание, что средняя зарплата остается неизменной независимо от того, что мы считаем независимой переменной. Другими словами, мы можем использовать другие аспекты жизни людей какИксно зарплата останется прежней.

Предположим, что мы использовали линейную регрессию, чтобы найтилучший примерлиния.

Значениеr²затем может быть выражено как:
гдепеременная (средний)является дисперсия по отношению к среднему ивар (линия)это дисперсия по отношению к линии.
Как мы упоминали ранее, дисперсию можно рассчитать, взяв сумму разностей между отдельными зарплатами и средним квадратом.

Используя ту же логику, мы можем определить изменение вокруг оранжевой линии.

Предполагая, что мы получили следующие значения для дисперсии линии и среднего значения.

Мы можем рассчитатьr²используя формулу, описанную ранее.

Значение R2 означает, что отклонение по линии на 96% меньше, чем среднее значение. Другими словами, соотношение между заработной платой и многолетним опытом составляет 96%. Иными словами, многолетний опыт является хорошим предиктором заработной платы, потому что, когда годы растут, растет и зарплата, и наоборот.
Давайте посмотрим, как мы можем использовать R² для оценки модели линейной регрессии. Для начала импортируйте следующие библиотеки.
Мы будем использовать следующий набор данных. Если вы хотите следовать, скопируйте его содержимое в CSV-файл.
Мы загружаем данные в нашу программу, используя pandas, и наносим их на график, используя matplotlib.

Далее мы обучаем модель линейной регрессии нашим данным о заработной плате.
Мы можем просмотреть лучшую линию подгонки, произведенную нашей моделью, запустив следующие линии.

Затем мы вычисляем R², используя формулу, рассмотренную в предыдущем разделе.

Вместо того, чтобы реализовывать его с нуля каждый раз, мы можем использовать sklearn r2_score функция.


Бывают случаи, когда вычислительное определение R 2 может давать отрицательные значения, в зависимости от используемого определения. Это может возникнуть, если прогнозы, которые сравниваются с соответствующими результатами, не были получены в результате процедуры подгонки модели с использованием этих данных. Даже если была использована процедура подгонки модели, R 2 все еще может быть отрицательным, например, когда линейная регрессия проводится без включения точки пересечения или когда для подгонки данных используется нелинейная функция. В случаях, когда возникают отрицательные значения, среднее значение данных лучше соответствует результатам, чем значения подобранной функции в соответствии с этим конкретным критерием.
СОДЕРЖАНИЕ
Определения
у ¯ знак равно 1 п ∑ я знак равно 1 п у я <\ displaystyle <\ bar 
тогда изменчивость набора данных может быть измерена двумя формулами сумм квадратов :
Наиболее общее определение коэффициента детерминации:
Отношение к необъяснимой дисперсии
Как объяснили дисперсию
S S res + S S рег знак равно S S малыш <\ displaystyle SS _ <\ text
См. Раздел Разбиение в общей модели OLS для вывода этого результата для одного случая, когда соотношение выполняется. Когда это отношение делает захват, приведенное выше определение R 2 эквивалентно
В этой форме R 2 выражается как отношение объясненной дисперсии (дисперсия прогнозов модели, которая является SS reg / n ) к общей дисперсии (выборочная дисперсия зависимой переменной, которая равна SS tot / n ).
Этот набор условий является важным и имеет ряд последствий для свойств подобранных остатков и смоделированных значений. В частности, в этих условиях:
Квадрат коэффициента корреляции
Его не следует путать с коэффициентом корреляции между двумя оценками, определяемым как
где ковариация между двумя оценками коэффициентов, а также их стандартные отклонения получаются из ковариационной матрицы оценок коэффициентов.
Интерпретация
Значения R 2 вне диапазона от 0 до 1 могут возникать, когда модель соответствует данным хуже, чем горизонтальная гиперплоскость. Это могло произойти, если была выбрана неправильная модель или по ошибке были применены бессмысленные ограничения. Если используется уравнение 1 Кволсета (это уравнение используется наиболее часто), R 2 может быть меньше нуля. Если используется уравнение 2 Квалсета, R 2 может быть больше единицы.
В многолинейной модели
Рассмотрим линейную модель с более чем одной независимой переменной вида
Инфляция R 2
Предостережения
Расширения
Скорректированный R 2
Принцип, лежащий в основе скорректированной статистики R 2, можно увидеть, переписав обычное R 2 как
Коэффициент частичной детерминации
Коэффициент частичной детерминации можно определить как долю вариации, которая не может быть объяснена в сокращенной модели, но может быть объяснена предикторами, указанными в полной (er) модели. Этот коэффициент используется для понимания того, могут ли один или несколько дополнительных предикторов быть полезными в более полной регрессионной модели.
Расчет для частичного R 2 является относительно простым после того, как две модели оценки и генерации ANOVA таблиц для них. Расчет для частичного R 2 IS
который аналогичен обычному коэффициенту детерминации:
Обобщение и разложение R 2
Как объяснялось выше, эвристика выбора модели, такая как скорректированный критерий и F-тест, проверяет, достаточно ли увеличивается общая сумма, чтобы определить, следует ли добавить в модель новый регрессор. Если к модели добавлен регрессор, который сильно коррелирован с другими регрессорами, которые уже были включены, то итоговое значение вряд ли увеличится, даже если новый регрессор является актуальным. В результате вышеупомянутая эвристика будет игнорировать соответствующие регрессоры, когда взаимная корреляция высока. р 2 <\ displaystyle R ^ <2>> р 2 <\ displaystyle R ^ <2>> р 2 <\ displaystyle R ^ <2>>

р ⊗ знак равно ( Икс ′ у
R 2 в логистической регрессии
Нагелькерке отметил, что он обладает следующими свойствами:
Сравнение с нормой остатков
Иногда для указания степени соответствия используется норма остатков. Этот член рассчитывается как квадратный корень из суммы квадратов остатков :
Оба R 2 и норма невязки имеют свои относительные преимущества. Для анализа методом наименьших квадратов R 2 изменяется от 0 до 1, при этом более крупные числа указывают на лучшее соответствие, а 1 представляет собой идеальное соответствие. Норма остатков варьируется от 0 до бесконечности, при этом меньшие числа указывают на лучшее соответствие, а ноль указывает на идеальное соответствие. Одно из преимуществ и недостатков R 2 заключается в том, что этот член нормализует значение. Если все значения y i умножить на константу, норма остатков также изменится на эту константу, но R 2 останется прежним. В качестве базового примера для линейного метода наименьших квадратов, подходящего к набору данных: S S малыш <\ displaystyle SS _ <\ text
R 2 = 0,998, а норма остатков = 0,302. Если все значения y умножаются на 1000 (например, при изменении префикса SI ), то R 2 остается прежним, но норма остатков = 302.
История
Создание коэффициента детерминации было приписано генетику Сьюоллу Райту и впервые было опубликовано в 1921 году.
R-квадрат
Опубликовано 20.05.2020 · Обновлено 20.05.2021
Что такое R-квадрат?
R-квадрат (R 2 ) – это статистическая мера, которая представляет долю дисперсии для зависимой переменной, которая объясняется независимой переменной или переменными в регрессионной модели. В то время как корреляция объясняет силу взаимосвязи между независимой и зависимой переменной, R-квадрат объясняет, в какой степени дисперсия одной переменной объясняет дисперсию второй переменной. Таким образом, если R 2 модели равен 0,50, то примерно половина наблюдаемой вариации может быть объяснена входными данными модели.
При инвестировании R-квадрат обычно интерпретируется как процент движений фонда или ценных бумаг, которые можно объяснить движениями эталонного индекса. Например, R-квадрат для ценной бумаги с фиксированным доходом по сравнению с индексом облигаций определяет долю движения цены ценной бумаги, которая предсказуема на основе движения цены индекса. То же самое можно применить к акции по сравнению с индексом S&P 500 или любым другим соответствующим индексом.
Формула для R-квадрата

Ключевые моменты
Расчет R-квадрат
Чтобы рассчитать общую дисперсию, вы должны вычесть среднее фактическое значение из каждого фактического значения, возвести результаты в квадрат и просуммировать их. Оттуда разделите первую сумму ошибок (объясненную дисперсию) на вторую сумму (общую дисперсию), вычтите результат из единицы, и вы получите R-квадрат.
Что вам говорит R-Squared?
Значения R-квадрат находятся в диапазоне от 0 до 1 и обычно выражаются в процентах от 0% до 100%. R-квадрат 100% означает, что все движения ценной бумаги (или другой зависимой переменной) полностью объясняются движениями индекса (или интересующих вас независимых переменных).
Разница между R-квадрат и скорректированный R-квадрат
Разница между R-Squared и Beta
Ограничения R-Squared
R-квадрат даст вам оценку взаимосвязи между движениями зависимой переменной на основе движений независимой переменной. Он не говорит вам, хороша ли ваша выбранная модель или плоха, и не говорит вам, являются ли данные и прогнозы необъективными. Высокий или низкий R-квадрат не обязательно хорош или плох, поскольку он не передает надежность модели или правильность выбора регрессии. Вы можете получить низкий R-квадрат для хорошей модели или высокий R-квадрат для плохо подогнанной модели, и наоборот.
Часто задаваемые вопросы
Что такое хорошее значение R-квадрат
То, что считается «хорошим» значением R-Squared, будет зависеть от контекста. В некоторых областях, таких как социальные науки, даже относительно низкий R-Squared, такой как 0,5, можно считать относительно сильным. В других областях стандарты хорошего показания R-Squared могут быть намного выше, например 0,9 или выше. В сфере финансов R-Squared выше 0,7 обычно рассматривается как показывающий высокий уровень корреляции, тогда как показатель ниже 0,4 показывает низкую корреляцию. Однако это не жесткое правило, и оно будет зависеть от конкретного анализа.
Что означает значение R-Squared 0,9?
По сути, значение R-Squared, равное 0,9, означает, что 90% дисперсии изучаемой зависимой переменной объясняется дисперсией независимой переменной. Например, если у паевого инвестиционного фонда значение R-Squared составляет 0,9 относительно его эталонного показателя, это будет означать, что 90% дисперсии фонда объясняется дисперсией его эталонного индекса.
Лучше ли более высокий R-квадрат?
Что такое r квадрат в регрессии

Для реализации процедуры Регрессия необходимо: выбрать в меню Сервис команду Анализ данных. В появившемся диалоговом окне Анализ данных в списке Инструменты анализа выбрать строку Регрессия.
Рис.1. Окно «Регрессия»
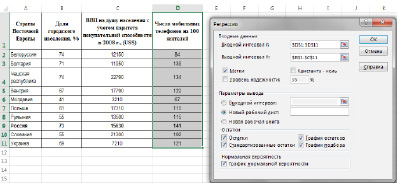
В появившемся диалоговом окне (рис.1) задать:
Входной интервал Y– диапазон (столбец), содержащий данные со значениями объясняемой переменной;
Входной интервал Х– диапазон (столбцы), содержащий данные с заголовками.
Метки – флажок, который указывает, содержат ли первые элементы отмеченных диапазонов названия переменных (столбцов) или нет;
Константа-ноль– флажок, указывающий на наличие или отсутствие свободного члена в уравнении (а);
Уровень надежности– уровень значимости, (например, 0,05);
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона, в котором будет сохранен отчет по построению модели;
Новый рабочий лист– поставить значок и задать имя нового листа (Отчет – регрессия), в котором будет сохранен отчет.
Если необходимо получить значения и график остатков, а также график подбора (чтобы визуально проверить отличие экспериментальных точек от предсказанных по регрессионной модели), установите соответствующие флажки в диалоговом окне.
Рассмотрим результаты регрессионного анализа (рис. 2, 3).
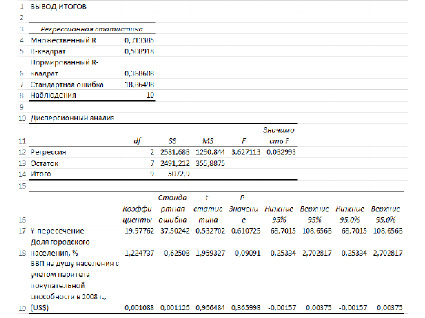
Рис. 2. Вывод итогов регрессионного анализа
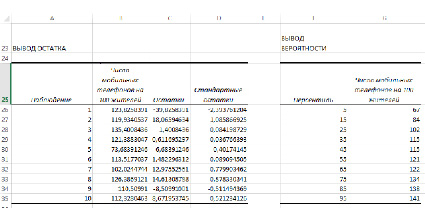
Рис. 3. Вывод остатков и вероятности по результатам регрессионного анализа
Множественный R – коэффициент корреляции
R-квадрат – это коэффициент линейной детерминации. Коэффициент является одной из наиболее эффективных оценок адекватности регрессионной R2модели, мерой качества уравнения регрессии в целом (или, как говорят, мерой качества подгонки регрессионной модели к наблюденным значениям.
Если R-квадрат > 0,95, говорят о высокой точности аппроксимации (модель хорошо описывает явление). Если R-квадрат лежит в диапазоне от 0,8 до 0,95, говорят об удовлетворительной аппроксимации (модель в целом адекватна описываемому явлению). Если R-квадрат 0,05, коэффициент может считаться нулевым, что означает, что соответствующая независимая переменная практически не влияет на зависимую переменную.
В нашем случае оба коэффициента оказались «нулевыми», а значит обе независимые переменные не влияют на модель.
Остатки – остатки по модели регрессии.
На основе данных об остатках модели регрессии был построен график остатков (рис. 4) и график подбора – поле корреляции фактических и теоретических (расчетных) значений результативной переменной (рис.5).
Рис. 4. График остатков по значениям признака «Доля городского населения, %»
Рис. 5. График подбора для признаков «Доля городского населения, %» и «Число мобильных телефонов на 100 жителей»
Рассмотрение графиков подбора позволяет предположить, что, возможно, качество модели можно усовершенствовать, исключив данные по Белоруссии как аномальные значения.



