Race condition и D ata Race

Продолжаем серию статей о проблемах многопоточности, параллелизме, concurrency и других интересных штуках.
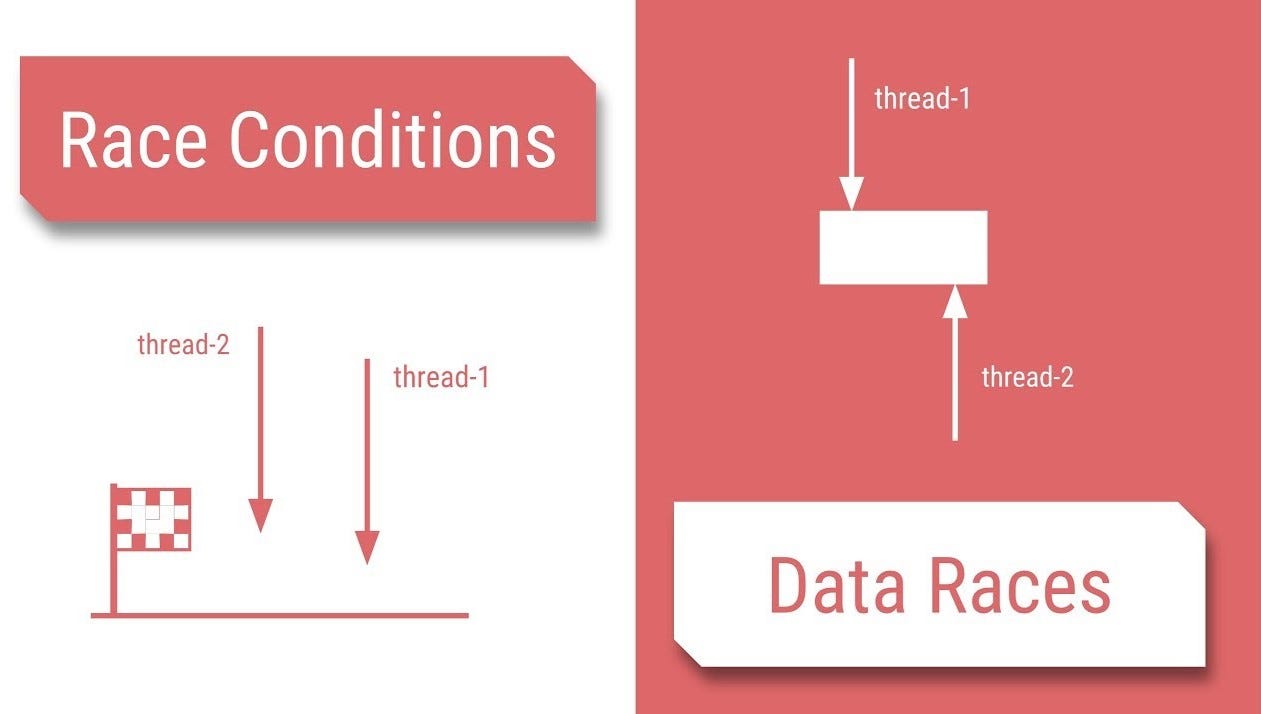
Race condition и data race — две разные проблемы многопоточности, которые часто путают. Попробуем разобраться.
Race condition
Существует много формулировок определения:
Race condition представляет собой класс проблем, в которых корректное поведение системы зависит от двух независимых событий, происходящих в правильном порядке, однако отсутствует механизм, для того чтобы гарантировать фактическое возникновение этих событий.
Race condition — ошибка проектирования многопоточной системы или приложения, при которой работа системы или приложения зависит от того, в каком порядке выполняются части кода.
Race condition — это нежелательная ситуация, которая возникает, когда устройство или система пытается выполнить две или более операций одновременно, но из-за природы устройства или системы, операции должны выполняться в правильной последовательности, чтобы быть выполненными правильно.
Race condition — это недостаток, связанный с синхронизацией или упорядочением событий, что приводит к ошибочному поведению программы.
Но мне нравиться наиболее короткое и простое:
Race condition — это недостаток, возникающий, когда время или порядок событий влияют на правильность программы.
Важно, что Race condition — это семантическая ошибка.
В проектирование электронных схем есть похожая проблема:
Состязание сигналов — явление в цифровых устройствах несоответствия работы данного устройства с заданным алгоритмом работы по причине возникновения переходных процессов в реальной аппаратуре.
Рассмотрим пример, где результат не определен:
Если запустить такой код много раз, то можно увидеть примерно такое:
Результат выполнения кода зависит от порядка выполнения горутин. Это типичная ошибка race condition. Ситуации могут быть гораздо сложней и не очевидней.
Учитывая, что race condition семантическая ошибка, нет общего способа который может отличить правильное и неправильное поведение программы в общем случае.
Помочь могут хорошие практики и проверенные паттерны.
В результате на консоле получим четные и нечетные числа, а расчитывали увидеть только четные.
Проблемы с доступом к общим ресурсам проще обнаружить автоматически и решаются они обычно с помощью синхронизации:
или локальной копией:
Data Race
Data race это состояние когда разные потоки обращаются к одной ячейке памяти без какой-либо синхронизации и как минимум один из потоков осуществляет запись.
Пример с балансом на счету:
Запускаем в разных горутинах:
Изначально баланс равен 0, депозитим 1000 раз по 1. Ожидаем баланс равный 1000, но результат другой:
Потеряли много денег.
Причина в том, что операция acc.balance += amount не атомарная. Она может разложиться на 3:
Пока мы меняем временную переменную в одном потоке, в других уже изменен основной balance. Таким образом теряется часть изменений.
Например, у нас 2 параллельных потока выполнения, каждый должен прибавить к балансу по 1:
Ожидали получить баланс=102, а получили = 101.
У Data Race есть точное определение, которое не обязательно связано с корректностью, и поэтому их можно обнаружить. Существует множество разновидностей детекторов гонки данных (статическое/динамическое обнаружение, обнаружение на основе блокировок, обнаружение основанное на предшествующих событий, обнаружение гибридного data race).
У Go есть хороший Data Race Detector с помощью которого такие ошибки можно обнаружить.
Решается проблема с помощью синхронизации:
Race Condition и Data Race

Функция для перевода средств с одного счета на другой:
На одном счету у нас будет 1000, а на другом 0. Переводим по 1 в 1000 горутинах и ожидаем, что все деньги из одного счета перетекут в другой:
Но результат может быть таким:
Если запустить цикл на большее кол-во операций, то можно получить еще интересней:
При вызове из нескольких потоков без внешней синхронизации эта функция допускает как dara race (несколько потоков могут одновременно пытаться обновить баланс счета), так и race condition (в параллельном контексте это приведет к потере денег).
Для решения можно применить синхронизацию и локальную копию. Общая логика может быть не такой линейной и в итоге код может выглядит например так:
У нас синхронизированы все участки с записью и чтением, у нас есть локальная копия, Race Detector больше не ругается на код. Запускаем 1000 операций и получаем верный результат:
Но что если горутин будет 10к:
Мы решили проблему data race, но race condition остался. В данном случае можно сделать блокировку на всю логику перевода средств, но это не всегда возможно.
Решив Data Race через синхронизацию доступа к памяти (блокировки) не всегда решается race condition и logical correctness.
Синхронизация в Java. Часть 2

Jul 9, 2020 · 5 min read

Состояние гонки
Вновь приветствую вас в теме “Синхронизация в Java”! Надеюсь, что вы прочли мою предыдущую статью.
Давайте разберёмся, что же такое состояние гонки. Это состояние проявляется, когда нам нужно обратиться к данным параллельно. Хорошо, тогда что же значит параллельное обращение к данным? Проще говоря, это означает, что два разных потока могут считывать одну и ту же переменную, поле, или даже массив, определённые внутри класса Java. Давайте возьмём популярный шаблон проектирования “Singleton” и посмотрим, как в нём проявляется такое состояние гонки.
Два потока пытают с я выполнить этот блок кода. Представьте себе ситуацию, где поток 1 (T1) задерживается в блоке if, в это время в процесс включается T2 и в итоге завершает блок if созданием “статического экземпляра Singleton”, после чего опять запускается T1 и уничтожает только что созданный T2 экземпляр.
Как же этого избежать? В этом случае помогает синхронизация, которая не даёт выполнять блок кода более чем одному потоку одновременно.
Значит синхронизация решит проблему? Да, именно так. Теперь давайте посмотрим её в действии на примере образов. В них мы увидим, как ключевое слово synchronized защищает методы.
Для большей наглядности я подготовил серию рисунков. Образ человека будет представлять собой поток. Взгляните на то, как этот человек просит ключ и попадает с его помощью в метод, а затем, покидая этот метод, возвращает ключ обратно. Поэтому другой человек (поток 2) должен дождаться, чтобы также получить ключ. Достаточно простой принцип, не так ли?

По факту из сказанного следует, что нам нужен объект, который будет содержать ключ, делая подобную синхронизацию возможной. В случае, приведённом выше, мы поместили ключевое слово synchronized в public static method. А что же для преодоления блокировки в таком случае использует JVM? Объект Singleton.class. Т.е. схожим образом в случае синхронизации в нестатических методах JVM использует в качестве объекта синхронизации конкретный экземпляр, в котором Singleton.class находится.
Давайте используем для синхронизации явный объект
Мы можем использовать для выполнения синхронизации явный объект, как это показано в блоке кода ниже. Да, достаточно только самого класса объекта. Я думаю, что вы уже знаете почему. Вместо синхронизирования метода getName() мы можем использовать синхронизированный блок внутри этого метода и передать объект key в качестве параметра ключевого слова synchronized. Помните, что это всегда будет удачным решением.
Синхронизация более чем одного метода
Предположим, что у нас есть класс Student с двумя синхронизированными методами getName() и getMarks(). Объект блокировки, используемый JVM, находится в самом объекте Student. Когда конкретный поток захочет выполнить getName(), он возьмёт этот объект блокировки, тем самым лишая другой поток возможности выполнить этот же метод одновременно с ним. Поскольку мы не объявляли явный объект в синхронизации наших методов, будет использован тот же объект key. Итак, теперь становится понятно, что для независимого выполнения этих двух методов в одно и то же время нам нужно создать в классе Student два объекта блокировки и синхронизировать эти два блока кода из 2 блокировок (2 разных объектов).
Теперь предположим, что у нас есть два экземпляра класса Student: Student1 и Student2. Синхронизирование более одного метода заблокирует объекты двумя ключами.
Что такое состояние гонки?
Мои вопросы для сообщества:
Что такое состояние гонки? Как вы их обнаруживаете? Как вы справляетесь с ними? Наконец, как вы их предотвращаете?
ОТВЕТЫ
Ответ 1
Условие гонки возникает, когда два или более потока могут обращаться к общим данным, и они пытаются изменить его в одно и то же время. Поскольку алгоритм планирования потоков может меняться между потоками в любое время, вы не знаете порядок, в котором потоки будут пытаться получить доступ к общим данным. Следовательно, результат изменения данных зависит от алгоритма планирования потока, то есть оба потока являются «гоночными» для доступа/изменения данных.
Часто возникают проблемы, когда один поток выполняет «check-then-act» (например, «проверка», если значение X, затем «действовать», чтобы делать что-то, что зависит от значения X), а другой поток что-то делает значение между «проверкой» и «действием». Например:
Точка, y может быть 10, или это может быть что угодно, в зависимости от того, изменился ли другой поток x между проверкой и действием. У вас нет реального способа узнать.
Чтобы предотвратить возникновение условий гонки, вы обычно помещаете блокировку общих данных, чтобы гарантировать, что только один поток может получить доступ к данным за раз. Это означало бы что-то вроде этого:
Ответ 2
Условие «гонки» существует, когда многопоточный (или иначе параллельный) код, который будет обращаться к общему ресурсу, может сделать это таким образом, чтобы вызвать неожиданные результаты.
Возьмем этот пример:
Если у вас было 5 потоков, выполняющих этот код сразу, значение x не должно составлять 50 000 000. На самом деле это будет изменяться с каждым прогоном.
Это потому, что для того, чтобы каждый поток увеличивал значение x, они должны сделать следующее: (упрощенно, очевидно)
Любой поток может быть на любом этапе этого процесса в любое время, и они могут наступать друг на друга, когда задействован общий ресурс. Состояние x может быть изменено другим потоком в течение времени между чтением x и после его записи.
Скажем, поток получает значение x, но еще не сохранил его. Другой поток также может получить значение same x (потому что ни один нить еще не изменил его), а затем они оба будут хранить значение same (x + 1) в х!
Условия гонки можно избежать, используя механизм блокировки до кода, который обращается к общему ресурсу:
Здесь ответ приходит как 50 000 000 каждый раз.
Для получения дополнительной информации о блокировке выполните поиск: мьютекс, семафор, критический раздел, общий ресурс.
Ответ 3
Религиозный обзор кода, многопоточные модульные тесты. Нет ярлыка. На этом есть плагин Eclipse, но ничего стабильного пока нет.
Как вы обрабатываете и предотвращаете их?
Лучше всего было бы создавать свободные побочные эффекты и функции без гражданства, максимально использовать неизменяемые. Но это не всегда возможно. Таким образом, используя java.util.concurrent.atomic, помогут параллельные структуры данных, правильная синхронизация и основанный на актерах concurrency.
Лучшим ресурсом для concurrency является JCIP. Вы также можете получить более подробную информацию здесь..
Ответ 4
Существует важное техническое различие между условиями гонки и гонками данных. Большинство ответов, похоже, делают предположение, что эти термины эквивалентны, но они не являются.
Голосование данных происходит, когда 2 команды обращаются к одному и тому же месту памяти, по крайней мере один из этих обращений является записью, и нет необходимости до упорядочивания между этими обращениями. Теперь то, что происходит, происходит до заказа, подвержено большому количеству дебатов, но в целом пары блокировки улоков на одной и той же переменной блокировки и пар сигнала ожидания при одной и той же переменной условия вызывают случайный порядок.
Теперь, когда мы применили терминологию, попробуем ответить на исходный вопрос.
С другой стороны, расы данных имеют точное определение, которое не обязательно связано с правильностью, и поэтому их можно обнаружить. Существует множество разновидностей детекторов гонки данных (статическое/динамическое обнаружение гонки данных, обнаружение гонки данных на основе блокировки, обнаружение на основе данных на основе ранее обнаруженных данных, обнаружение гибридных данных). Современный динамический детектор гонки данных ThreadSanitizer, который на практике работает очень хорошо.
Ответ 5
Ответ 6
Пример: Представьте, что у вас есть два потока: A и B.
Эта ошибка возникает только тогда, когда поток A выгружается сразу после инструкции if, это очень редко, но это может произойти.
Ответ 7
Обнаружение условий гонки может быть затруднительным, но есть пара знаков. Код, который в значительной степени зависит от сна, склонен к условиям гонки, поэтому сначала проверьте, чтобы вызовы спать в затронутом коде. Добавление особенно длинных снов также может быть использовано для отладки, чтобы попытаться заставить определенный порядок событий. Это может быть полезно для воспроизведения поведения, если вы можете заставить его исчезнуть, изменив время и вещи для тестирования. Сны должны быть удалены после отладки.
Знак подписи, что у одного есть условие гонки, есть, если есть проблема, которая возникает только периодически на некоторых машинах. Общими ошибками были бы сбои и взаимоблокировки. С протоколированием вы сможете найти пострадавший район и вернуться оттуда.
Ответ 8
Состояние гонки связано не только с программным обеспечением, но и с аппаратным обеспечением. На самом деле термин первоначально был придуман аппаратной отраслью.
Этот термин связан с идеей двух сигналов, ведущих друг к другу, чтобы влиять на выход в первую очередь.
Состояние гонки в логической схеме:

Программная индустрия приняла этот термин без изменений, что делает его немного трудным для понимания.
Вам нужно сделать некоторую замену, чтобы отобразить ее в мире программного обеспечения:
Таким образом, состояние гонки в индустрии программного обеспечения означает «два потока»/»два процесса», которые участвуют друг в друге, «влияют на какое-то общее состояние», а конечный результат общего состояния будет зависеть от некоторой тонкой разницы во времени, что может быть вызвано некоторыми конкретными порядок запуска потоков/процессов, планирование потоков/процессов и т.д.
Ответ 9
Ответ 10
Microsoft действительно опубликовала действительно подробную статью по этому вопросу условий гонки и тупиков. Наиболее суммарным из них будет абзац заголовка:
Условие гонки возникает, когда два потока обращаются к общей переменной при в то же время. Первый поток читает переменную, а второй thread считывает одно и то же значение из переменной. Затем первая нить и вторая нить выполняет свои операции над значением, и они участвуют в гонке чтобы увидеть, какой поток может записать значение, последнее для общей переменной. Значение потока, которое записывает свое значение last, сохраняется, потому что поток пишет над значением, которое предыдущий поток написал.
Ответ 11
Вот классический пример баланса банковского счета, который поможет новичкам понять потоки в Java легко w.r.t. условия гонки:
Ответ 12
Условие гонки является нежелательной ситуацией, когда устройство или система пытаются выполнить две или более операции одновременно, но из-за характера устройства или системы операции должны выполняться в правильной последовательности в чтобы сделать это правильно.
В памяти компьютера или в хранилище может возникнуть условие гонки, если команды для чтения и записи большого количества данных принимаются почти в одно и то же мгновение, и машина пытается перезаписать некоторые или все старые данные, а старые данные все еще читается. Результатом может быть одно или несколько из следующего: компьютерный сбой, «незаконная операция», уведомление и завершение работы программы, ошибки чтения старых данных или ошибки записи новых данных.
Ответ 13
Ситуация, когда процесс критически зависит от последовательности или времени других событий.
Например, процессору A и процессору B необходимы идентичные ресурсы для их выполнения.
Есть инструменты для автоматического определения состояния гонки:
Состояние гонки может быть обработано с помощью Mutex или Semaphores. Они действуют как блокировка, позволяющая процессу получать ресурсы на основе определенных требований для предотвращения состояния гонки.
Как вы предотвращаете их появление?
Существуют различные способы предотвращения состояния расы, такие как предотвращение критических участков.
Ответ 14
Попробуйте этот базовый пример для лучшего понимания состояния гонки:
Ответ 15
Вы не всегда хотите отказаться от состояния гонки. Если у вас есть флаг, который может быть прочитан и написан несколькими потоками, и этот флаг установлен на «done» одним потоком, так что другая обработка прекращения потока, когда флаг установлен на «done», вы не хотите, чтобы «гонка» условие «будет устранено. Фактически, это можно назвать доброкачественным состоянием гонок.
Однако, используя инструмент для обнаружения состояния гонки, он будет замечен как опасное состояние гонки.
Ответ 16
Рассмотрим операцию, которая должна отображать счет, как только счет будет увеличен. т.е., как только CounterThread увеличивает значение DisplayThread, необходимо отобразить последнее обновленное значение.
Здесь CounterThread часто блокирует блокировку и обновляет значение до того, как его отобразит DisplayThread. Здесь существует условие Расы. Состояние гонки можно решить, используя Synchronzation
Ответ 17
Вы можете предотвратить состояние гонки, если используете классы «Atomic». Причина в том, что поток не разделяет операции get и set, пример ниже:
В результате у вас будет 7 в ссылке «ai». Хотя вы сделали два действия, но обе операции подтверждают тот же поток, и ни один другой поток не будет вмешиваться в это, это означает отсутствие условий гонки!
Ответ 18
Условие гонки является нежелательной ситуацией, которая возникает, когда два или более процесса могут одновременно получать доступ и изменять совместно используемые данные. Это произошло из-за конфликта доступа к ресурсу. Проблема критического сечения может привести к состоянию гонки. Для решения критического состояния процесса мы вынимаем только один процесс за раз, который выполняет критический раздел.
What is a race condition?
When writing multithreaded applications, one of the most common problems experienced is race conditions.
My questions to the community are:
18 Answers 18
A race condition occurs when two or more threads can access shared data and they try to change it at the same time. Because the thread scheduling algorithm can swap between threads at any time, you don’t know the order in which the threads will attempt to access the shared data. Therefore, the result of the change in data is dependent on the thread scheduling algorithm, i.e. both threads are «racing» to access/change the data.
Problems often occur when one thread does a «check-then-act» (e.g. «check» if the value is X, then «act» to do something that depends on the value being X) and another thread does something to the value in between the «check» and the «act». E.g:
The point being, y could be 10, or it could be anything, depending on whether another thread changed x in between the check and act. You have no real way of knowing.
In order to prevent race conditions from occurring, you would typically put a lock around the shared data to ensure only one thread can access the data at a time. This would mean something like this:

A «race condition» exists when multithreaded (or otherwise parallel) code that would access a shared resource could do so in such a way as to cause unexpected results.
If you had 5 threads executing this code at once, the value of x WOULD NOT end up being 50,000,000. It would in fact vary with each run.
This is because, in order for each thread to increment the value of x, they have to do the following: (simplified, obviously)
Any thread can be at any step in this process at any time, and they can step on each other when a shared resource is involved. The state of x can be changed by another thread during the time between x is being read and when it is written back.
Let’s say a thread retrieves the value of x, but hasn’t stored it yet. Another thread can also retrieve the same value of x (because no thread has changed it yet) and then they would both be storing the same value (x+1) back in x!
Race conditions can be avoided by employing some sort of locking mechanism before the code that accesses the shared resource:
Here, the answer comes out as 50,000,000 every time.
For more on locking, search for: mutex, semaphore, critical section, shared resource.

Religious code review, multi-threaded unit tests. There is no shortcut. There are few Eclipse plugin emerging on this, but nothing stable yet.
How do you handle and prevent them?
The best thing would be to create side-effect free and stateless functions, use immutables as much as possible. But that is not always possible. So using java.util.concurrent.atomic, concurrent data structures, proper synchronization, and actor based concurrency will help.
The best resource for concurrency is JCIP. You can also get some more details on above explanation here.


There is an important technical difference between race conditions and data races. Most answers seem to make the assumption that these terms are equivalent, but they are not.
A data race occurs when 2 instructions access the same memory location, at least one of these accesses is a write and there is no happens before ordering among these accesses. Now what constitutes a happens before ordering is subject to a lot of debate, but in general ulock-lock pairs on the same lock variable and wait-signal pairs on the same condition variable induce a happens-before order.
A race condition is a semantic error. It is a flaw that occurs in the timing or the ordering of events that leads to erroneous program behavior.
Many race conditions can be (and in fact are) caused by data races, but this is not necessary. As a matter of fact, data races and race conditions are neither the necessary, nor the sufficient condition for one another. This blog post also explains the difference very well, with a simple bank transaction example. Here is another simple example that explains the difference.
Now that we nailed down the terminology, let us try to answer the original question.
Given that race conditions are semantic bugs, there is no general way of detecting them. This is because there is no way of having an automated oracle that can distinguish correct vs. incorrect program behavior in the general case. Race detection is an undecidable problem.
On the other hand, data races have a precise definition that does not necessarily relate to correctness, and therefore one can detect them. There are many flavors of data race detectors (static/dynamic data race detection, lockset-based data race detection, happens-before based data race detection, hybrid data race detection). A state of the art dynamic data race detector is ThreadSanitizer which works very well in practice.
Handling data races in general requires some programming discipline to induce happens-before edges between accesses to shared data (either during development, or once they are detected using the above mentioned tools). this can be done through locks, condition variables, semaphores, etc. However, one can also employ different programming paradigms like message passing (instead of shared memory) that avoid data races by construction.



