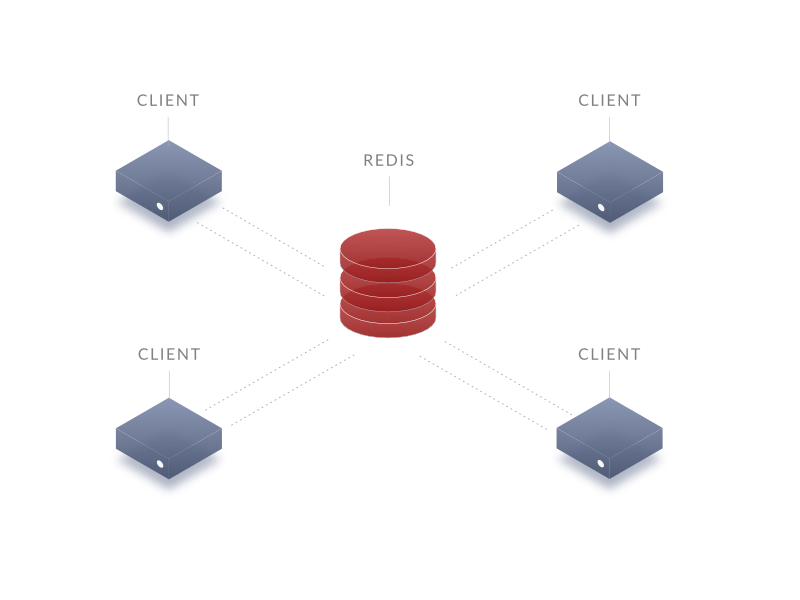
Redis — высокопроизводительное хранилище данных
Бодрый день, хаброчеловеки!
Что такое Redis?
Redis — это высокопроизводительное нереляционное распределённое хранилище данных. В отличие от Memcached, который может в любой момент удалить ваши данные, вытесняя старые записи новыми, Redis хранит информацию постоянно, таким образом он похож на MemcacheDB.
Чем Redis отличается от существующих решений?
API для работы с Memcached (MemcacheDB) позволяет хранить массивы, но эти массивы будут сериализованы и сохранены как строки, таким образом атомарные операции над такими массивами не возможны.
Redis позволяет хранить как строки, так и массивы, к которым можно применять атомарные операции pop / push, делать выборки из таких массивов, выполнять сортировку элементов, получать объединения и пересечения массивов.
Производительность
110000 запросов SET в секунду, 81000 запросов GET в секунду на Linux-сервере начального уровня (тесты).
Высокая скорость работы Redis обеспечивается тем, что данные хранятся в оперативной памяти и сохраняются на диск либо через равные промежутки времени, либо при превышении определённого количества не сохранённых запросов. Из этого вытекает, что используя Redis, вы можете потерять результаты нескольких последних запросов, что вполне приемлимо для большинства веб-приложений, учитывая, что обращение к Redis по скорости сравнимо с обращением к оперативной памяти. Тем не менее, потерь можно избежать через избыточность — Redis поддерживает неблокирующую master-slave репликацию.
Sharding
Redis, как и Memcached, может работать как распределённое хранилище на многих физических серверах. Такой функционал реализуется в клиентских библиотеках, и к сожалению, «из коробки» этот функционал реализован пока только в Ruby API, однако это не мешает вам хешировать ключ самостоятельно и получать ID сервера, к которому с этим ключом обращаться.
API для PHP доступно как в виде модуля, написанного на C, так и в виде PHP5 класса, который общается с Redis-сервером через сокеты, таким образом не требуется устанавливать модуль.
Кроме того существует PHP5 класс от отечественного разрабочика (с именем, заслуживающим доверия. Я серьёзно.) — IMemcacheClient. (Спасибо DYPA за на водку)
Перспективы развития
Разработка ведётся очень активно, комиты происходят почти каждый день, сейчас доступна версия Redis 0.900 (1.0 release candidate 1), которая очень скоро станет версией 1.0
В ближайшем будущем авторы обещают внедрить разные интересные фичи, в том числе и сжатие данных.
Лицензия и поддерживаемые платформы
Redis — написан на ANSI C и работает на большинстве POSIX-систем (Linux, MacOS X). Это бесплатное открытое ПО под BSD лицензией =)
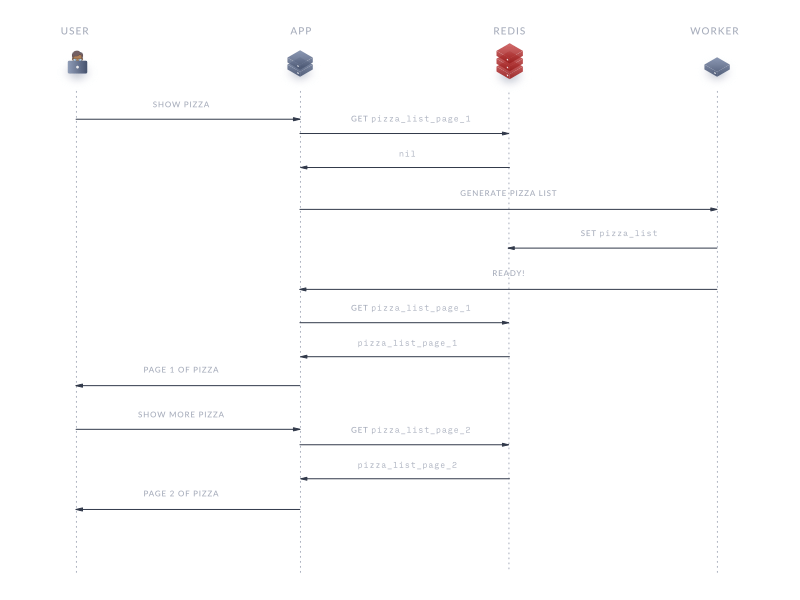
Redis для начинающих
Введение
С одной стороны есть традиционные ACID реляционные базы данных такие как MySQL, PostgreSQL, Oracle и др. Они надежны и стабильны. Сама аббревиатура ACID описывает требования к транзакционной системе (Atomicity — Атомарность, Consistency — Согласованность, Isolation — Изолированность, Durability — Долговечность). Их основная задаче не просто хранить данные, а хранить с максимальной надежностью. Но их основной недостаток, они очень медленные.
С другой стороны есть очень быстрые хранилища в памяти типа ключ-значение, например memcached. Они очень быстрые за счет предельной простоты и отказа от надежности. Несложно привести несколько примеров задач где нужна производительность даже за счет надежности:
— система мониторинга с n-ым количеством датчиков, которые должны постоянно отправлять данные.
— система логирования действий пользователя на каком нибудь сайте
— контроль трафика сети в реалтайм
— хранение сессий пользователей
и т.д.
Redis относится к третьему типу хранилищей. Когда нужно быстрая обработка данных и при этом сохранялось бы определенный уровень надежности и возможности масштабирования.
Redis (REmote DIctionary Server) — это не реляционная структура данных в памяти, используемая в качестве базы данных. Данные хранятся в виде пары ключ-значение. И при этом хранилище умеет масштабироваться путем репликации между серверами. Redis сохраняет все данные в памяти, что позволяет сделать доступ к данным максимально быстрым по сравнению с другими базами данных. Почему Redis известен своей исключительной высокой производительностью даже среди других key-value хранилищ.
Redis позволяет нам хранить данные в высокоуровневых структурах данных, такие как строки, хэши, списки, наборы. Это дает нам больше гибкости в отношении типа и объема информации, которую мы можем хранить в хранилище данных Redis.
Он также довольно дружелюбен для разработчиков, поскольку поддерживает большинство языков высокого уровня, таких как Python, JavaScript, Java, C / C ++ и PHP.
Установка Redis
Для дальнейшего изучения Redis нам необходимо скачать и установить сервер Redis. Можно использовать инструкции с официальной веб-страницы. Так же под MacOS можно использовать Homebrew, а для Linux что типа apt. Для запуска Redis используется команда redis-server
У Redis есть Redis-CLI (Common Line Interface), который можно использовать для взаимодействия с данными напрямую на сервере Redis.
Чтобы проверить правильность установки Redis, запустите redis-cli, а затем введите команду ping в появившейся подсказке:
Если сервер отвечает ответом PONG значит он готов к работе. По умолчанию сервер Redis работает на порту 6379, что видно в нашем приглашении.
Что бы выйти из redis-cli используйте команду quit.
Для вывода помощи по списку команд в консоли можно использовать команду HELP @string. Для вывода помощи по конкретной команде можно использовать команду HELP APPEND Например:
Далее приведен краткий список самых необходимых команд. Для изучения полного списка команд, если в этом есть необходимость, обратитесь к официальной документации.
Прежде чем начать использовать Redis в любом языке программирования нужно узнать о базовых командах и структурах используемых в Redis.
Команды
Прежде всего Redis это хранилище типа ключ: значение. И самые первые команды которую все изучают, это команды SET и GET:
Команда используется для установки ключа и его значения, с дополнительными необязательными параметрами для указания срока действия записи значения ключа. Давайте установим ключ foo со значением «hello world». Параметр EX указывает время жизни объекта в секундах, PX в милисекундах:
Команда используется для получения значения, связанного с ключом. Если запись значения ключа превысила срок действия, будет возвращено nil:
По умолчанию все значение в Redis сохраняются как строки.
EXISTS
Эта команда проверяет, существует ли что то с данным ключом. Она возвращает 1 если объект существует или 0 если нет. Boolean типа в Redis нет.
FLUSHALL
Эта команда полностью удаляет все данные в текущем сеансе.
GETSET
Команда возвращает текущее значение и устанавливает новое. Используется для атомарного управления данными.
Команда удаляет ключ и соответствующее значение:
APPEND
Команда добавляем в соотвествующий ключ дополнительное значение. Возвращает количество символов итогового значения.
Возвращает все ключи из базы по указанному шаблону. Есть предостережение что в реальных приложения эту команду лучше не использовать из-за того что она очень медленная.
INCR / DECR
Инкремент / декримент. Если значение ключа integer (хотя в базе храниться все равно строка) можно увеличить или уменьшить значение на 1. Если использовать команду INCR с несуществующем значением то создаться новый ключ со значением 1.
Когда ключ установлен с истечением срока действия (например SET foo EX 10), эту команду можно использовать для просмотра оставшегося времени:
PERSIST
Если мы передумаем об истечении срока действия ключа, мы можем использовать эту команду, чтобы удалить период истечения срока действия:
RENAME
Эта команда используется для переименования ключей на нашем сервере Redis:
Комплексные типы данных
Хеш таблицы
Redis позволяет в качестве значения так же использовать ключ: значение. Что по сути будет почти аналогией объектов из JavaScript или словари в Python. Для записи объекта используется команда HSET в следующем формате HSET имя_ключа имя_атрибута значение. Для чтения объекта используется команда HGET в формате HGET имя_ключа имя_атрибута. Команда HGETALL используется для получения
Множества
Не упорядоченная коллекция уникальных элементов. Аналог set в Python. Для добавление нового элемента во множество используется команда SADD. Для получения все элементов используется команда SMEMBERS. SUNION используется для объединение множеств. SDIFF используется для вычитания из первого множества второго. SINTER возвращает общие элементы указаных множеств. SPOP удаляет и возвращает случайный элемент множества.
Упорядоченные множества
Упорядоченная коллекция уникальных элементов. Для добавление нового элемента в упорядоченное множество используется команда ZADD. Формат ZADD имя_ключа порядковое_число_упорядочивания_множества значение
Команда ZRANGE возвращает срез данных множества
Списки
Транзакции в Redis
Обычное определение транзакций для реляционных баз данных означает следующее: транзакции это группа команд с базой данных, которые должны либо полностью выполнится или в случае возникновение ошибки вернуть состояние базы данных в исходное состояние. В Redis то же есть такое понятие как транзакции. Но означает немного другое. Транзакции в Redis это просто последовательное выполнение ранее записаных команд без возможности полноценного возвращения исходного состояния в случае ошибки исполнения.
С помощью команды MULTI можно начать запись команд. Далее введенные команды не исполняются а записываются в буфер. Это будет происходит до ввода команды на исполнения транзакции EXEC. Далее все ранее введенные команды будут исполнены один за другим. Команда DISCARD отмена записи команд транзакций. Если возникнет ошибка в процессе ввода команд вся транзакция не будет выполнена.
Механиз подписок PUS-SUB
Одно из основных преимуществ Redis от других key-value хранилищ заключается в том, что в Redis есть механизм подписок. То есть Redis можно использовать как сервер сообщений.
Одни клиенты подписываются на определенные каналы используя команду SUBSCRIBE имя_канала
Другие клиенты могут отправлять сообщения в этот канал используя команду PUBLISH имя_канала значение
Допустим один клиент подписывается на канал
Другой клиент что то отправляет в этот канал
И в этот момент первый клиент получит это сообщение
Основы применение Redis в Python
Redis очень широко применяется в современной разработке ПО. Библиотеки поддержки есть для любого языка программирования.
Кратко рассмотрим использование Redis в Python. Для этого первым делом загрузим библиотеку поддержки:
Далее подключимся к серверу
И далее можно уже начать попробовать использовать все ранее рассмотренные команды. Надеюсь они будут понятны без дополнительных пояснений:
Заключение
Redis — это мощный и быстрый вариант хранения данных, который при правильном использовании может принести много преимуществ. Он не имеет крутой кривой обучения, поэтому с ним легко начать работать. Также поставляется с удобным инструментом CLI, который помогает нам взаимодействовать с ним с помощью простых и интуитивно понятных команд.
ИТ База знаний
Полезно
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Redis – что это и для чего?
Еще немного про open source
Друг, начнем с цитаты:
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps

Redis – это высокопроизводительная БД с открытым исходным кодом (лицензия BSD), которая хранит данные в памяти, доступ к которым осуществляется по ключу доступа. Так же Редис это кэш и брокер сообщений.
Надо признаться, определение не дает точного понимания, что же такое Redis. Если это так круто, то зачем вообще нужны другие БД? На самом деле, Redis правильнее всего использовать в определенных кейсах, само собой, зная про подводные камни – именно об этом и поговорим.
Про установку Redis в CentOS 8 мы рассказываем в этой статье.
Redis как база данных
Говорим про случай, когда Redis выступает в роли базы данных:
Пару слов про ограничения такой модели:
Теперь про преимущества модели:
Примеры использования
Представь, у нас есть приложение, где пользователям необходимо авторизоваться, чтобы выполнять какие – либо действия внутри приложения. Каждый раз, когда мы обновляем авторизационные данные клиента, мы хотим их получать для последующего контроля.
Мы могли бы отправлять лист авторизационных параметров (с некими номерами авторизаций, сроком действия с соответствующими подписями), чтобы каждое действие внутри приложения, сопровождалось авторизацонной транзакцией из листа, который мы прислали клиенту. С точки зрения безопасности, в этом подходе нет ничего плохого, если мы храним на своей стороне данные в безопасности и используем Javascript Object Signing and Encryption (JOSE), например. Но проблема появится в том случае, когда наш пользователь имеет более одной авторизации внутри приложения – такие схемы плохо поддаются масштабированию.
А что если вместо отправки листа авторизационных параметров, мы сохраним его у себя, а пользователю отправим некий токен, который они должны отправлять для авторизации? Далее, по этому токену, мы легко сможем найти авторизации юзера. Это делает систему гораздо масштабируемой. Redis, такой Redis.
Итого, для указанной выше схемы, мы хотим:
А вот, что на эти вызовы может ответить Redis:
В качестве бонуса от Redis, вы получите механизм экспайринга токенов (устаревания). Все будет работать.
Redis как кэш!
Redis почти заменил memcached в современных приложениях. Его фичи делают супер – удобным кэширование данных.
Еще один кейс
Предположим, перед нами такая задача: приложение, отображает пользователям данные с определенными значениями, которые можно сортировать по множеству признаков. Все наши данные хранятся в БД (например, MySQL) и показывать отсортированные данные нужно часто. Дергать БД каждый раз весьма тяжело и ресурсозатратно, а значит, нам нужно кэшировать данные в отсортированном порядке.
Окей, кейс понятен. Рэдис, что скажешь на такие требования?
Redis как брокер сообщений
Как и раньше, давайте обсудим плюсы и минусы, хотя их тут и не так много. Минусы:
Ну а плюсы, как обычно для Редиса – скорость и стабильность.
Кейс напоследок
Простой пример – коллаборация сотрудников одной компании. Предположим, у них есть приложение, где они работают над общими задачами. Каждый пользователь делает свой набор действий, о котором другие пользователи должны знать. А так же, юзеры могут иметь разные экземпляры приложений – десктоп, мобильный или что то еще.
Требования по этой задаче:
Выводы
Если данные нуждаются в усиленной защите, Редис подойдет в меньшей степени, лучше посмотрите в сторону MongoDB или Elasticsearch.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps
Национальная библиотека им. Н. Э. Баумана
Bauman National Library
Персональные инструменты
Redis
Redis (англ. REmote DIctionary Server ) — сетевое журналируемое хранилище данных типа «ключ — значение» с открытым исходным кодом. Нереляционная высокопроизводительная СУБД.
Содержание
Дизайн
Хранит базу данных в оперативной памяти, снабжена механизмами снимков и журналирования для обеспечения постоянного хранения (на диске). Также предоставляет операции для реализации механизма обмена сообщениями в паттерне publish — subscribe[en]. С его помощью приложения могут создавать каналы, подписываться на них и помещать в каналы сообщения, которые будут получены всеми подписчиками (как IRC-чат). Поддерживает репликацию данных с основных узлов на несколько подчинённых (англ. master — slave replication). Также Redis поддерживает транзакции (последовательное выполнение всех операций, либо ни одной) и пакетную обработку команд (выполнение пакета команд, получение пакета результатов).
В версии 2.6.0 добавлена поддержка Lua, позволяющего выполнять запросы на сервере. Lua позволяет атомарно совершить произвольную обработку данных на сервере и предназначена для использования в случае, когда нельзя достичь того же результата с использованием стандартных команд.
Поддерживаемые языки программирования
Множество языков программирования имеют библиотеки для работы с Redis: C, C++, C#, Clojure, Lisp, Erlang, Java, JavaScript, Haskell, Lua, Perl, PHP, Python, Ruby, Scala, Go, Tcl, Rust.
Модели данных
Все данные Redis хранит в виде словаря, в котором ключи связаны со своими значениями. Одно из ключевых отличий Redis от других хранилищ данных заключается в том, что значения этих ключей не ограничиваются строками. Поддерживаются следующие абстрактные типы данных:
Тип данных значения определяет, какие операции (команды) доступны для него. Redis поддерживает такие высокоуровневые операции, как объединение и разность наборов, а также их сортировку.
Настройка
Перед установкой Redis следует учесть пару нюансов. Для начала обновим пакеты apt-get:
По завершению процесса, установим компилятор с зависимыми пакетами, при помощи которого мы и установим Redis из исходного кода:
Наконец, скачает tcl:
Установка Redis
После необходимой подготовки, мы готовы приступить к установке Redis из исходников:
Далее выполните команду make:
Рекомендуется провести тест сборки:
Закончим, выполнив `make install`, в результате чего программа будет установлена глобально:
По завершению установки, мы получим Redis со встроенным скриптом для запуска сервера в качестве службы. Для доступа к скрипту перейдите в каталог utils:
Запустите скрипт из этого каталога:
Во время работы скрипта вы можете выбрать настройки по-умолчанию нажав enter. По окончанию работы скрипта Redis сервер будет запущен в фоновом режиме. Запустить и прервать работу сервера можно следующими командами (номер порта зависит от выбранного вами во время установки):
Получить доступ к БД Redis можно при помощи команды:
Ваш Redis сервер готов и запущен, подтверждением тому служит строка:
Для автоматического запуска сервера при загрузке системы выполните:
Чтобы вы не запутались и было более понятно, прикрепляю видео с установкой Redis на Ubuntu Server 14.04.4 LTS, а также показан пример записи и получения множества с сортировкой.
Операции Redis
Простейшая команда для добавления строковых данных (основной тип данных) может выглядеть так:
В этом случае за командой SET следует ключ (users:GeorgeWashington), а за ним значение (сама строка). Двоеточие в Redis не оказывает влияния на команду. Тем не менее его использование полезно для описания ключа.
Извлечь данные можно командой GET:
Диапазоны
Срок действия
Redis полезен в качестве хранилища в котором можно хранить данные с определённым сроком действия. Время действия может быть указано в секундах или в формате Unix timestamp (количество секунд с 1.1.1970).
Две команды для настройки:
При попытке выборки просроченных данных, мы получим nil
Инкремент
Redis поддерживает атомарный инкремент строковых данных. При работе инкремента доступ к данным блокируется, таким образом осуществляется целостность данных.
Транзакции
Redis также поддерживает выполнение транзакций, которые должны следовать двум принципам:
Команды должны выполняться по порядку. Они не будет прерваны другими запросами в течение всего процесса. Должна быть обеспечена целостность транзакции. Транзакции начинаются с команды MULTI, а запускаются командой EXEC. Если по каким-либо причинам транзакция прерывается, Redis заблокирует её выполнение до тех пор, пока не будет выполнена команда redis-check-aof и отменены все изменения. После этого сервер можно будет перезапустить:
Типы данных Redis
Redis работает с пятью типами данных: Strings (строки), Sets (множества), Sorted Sets (сортированные множества), Lists (списки), Hashes (хеш)
Строки
Множества
Примером использования множеств может быть проверка IP адреса посетителя сайт на уникальность или извлечение случайного значения командой SRANDMEMBER.
Множества с сортировкой
Такой тип данных часто применяется с диапазонами, так как добавление и удаление данных выполняется значительно быстрее. Часто встречаемые команды:
Списки
Добавление человека в начало очереди выглядит следующим образом:
Команда LRANGE выведет весь список:
Списка часто применяются для хранения временных событий или коллекции из ограниченного числа элементов.
Для получения определенной информации используйте команду HMGET
Восстановление данных
Репликация
Redis поддерживает репликацию типа master-slave. Данные с любого сервера Redis могут реплицироваться произвольное количество раз. Репликация полезна для масштабирования чтения (но не записи) или при очень больших объёмах данных. Все данные, которые попадают на один узел Redis (который называется master) будут попадать также на другие узлы (называются slave). Для конфигурирования slave-узлов можно изменить опцию slaveof или аналогичную по написанию команду (узлы, запущенные без подобных опций являются master-узлами).
Репликация помогает защитить данные, копируя их на другие сервера. Репликация также может быть использована для увеличения производительности, так как запросы на чтение могут обслуживаться slave-узлами. Эти узлы могут ответить слегка устаревшими данными, но для большинства приложений это приемлемо.
К сожалению, система репликации Redis еще не поддерживает автоматическую отказоустойчивость. Если master-узел выходит из строя, необходимо вручную выбрать новый master- из списка slave-узлов. Необходимо использовать Redis Sentinel для мониторинга и автоматического переключения master-узлов, если необходима устойчивая к сбоям система.
Пример создания реплики
Для создания реплики нам нужно две машины, с уже установленными Redis. Как установить его, уже было описано выше. На второй машине делаем то же самое, с одним лишь отличием: когда при установке запросит порт, пропишем не стандартный 6379, а любой другой, например 6380. Далее просто настраиваем связь master-slave, при помощи следующих программ. На машине master прописываем:
На машине slave прописываем:
Чтобы убедиться, можно просмотреть информацию о репликациях. На master:
Т.к. я использую виртуальные машины для реализации данной связи, то мне придётся предварительно настроить внутреннюю сеть и связать мои виртуальные машины, чтобы они могли связаться друг с другом.
Redis Sentinel
Redis Sentinel [7] — это система, разработанная для помощи в управлении узлами Redis. Она выполняет следующие задачи:
Sentinel не рекомендуется использовать в единственном экземпляре. Кластер Sentinel-узлов поддерживает кворум, благодаря чему, сохраняет работоспособность даже при переменном составе и временном отсутствии некоторых из них.
Redis и Memcached
На первый взгляд может показаться, что Redis мало чем отличается от Memcached. И Redis, и Memcached хранят данные в памяти и осуществляют доступ к ним по ключу. Оба написаны на Си и распространяются под лицензией BSD. Но в действительности, между ними больше различий, чем сходства.
В первую очередь, Redis умеет сохранять данные на диск. Можно настроить Redis так, чтобы данные вообще не сохранялись, сохранялись периодически по принципу copy-on-write или сохранялись периодически и писались в журнал (binlog). Таким образом, всегда можно добиться требуемого баланса между производительностью и надежностью.
Redis, в отличие от Memcached, позволяет хранить не только строки, но и массивы (которые могут использоваться в качестве очередей или стеков), словари, множества без повторов, большие массивы бит (bitmaps), а также множества, отсортированные по некой величине. Разумеется, можно работать с отдельными элементами списков, словарей и множеств. Как и Memcached, Redis позволяет указать время жизни данных (двумя способами — «удалить в заданный момент времени» и «удалить через заданный промежуток времени»). По умолчанию все данные хранятся вечно.
Интересная особенность Redis заключается в том, что это — однопоточный сервер. Такое решение сильно упрощает поддержку кода, обеспечивает атомарность операций и позволяет запустить по одному процессу Redis на каждое ядро процессора. Разумеется, каждый процесс будет прослушивать свой порт. Решение нетипичное, но вполне оправданное, так как на выполнение одной операции Redis тратит очень небольшое количество времени.
Производительность
Высокая производительность Redis обуславливается тем, что все данные хранятся в оперативной памяти. На Linux-сервере начального уровня был установлен результат в 110 000 запросов SET и 81 000 запросов GET в секунду(бенчмарк).



