Упрощение метрик ROC и AUC.
Дата публикации Mar 3, 2019

Кривые ROC и AUC являются важными метриками оценки для расчета производительности любой модели классификации. Эти определения и жаргоны довольно распространены в сообществе машинного обучения и встречаются каждым из нас, когда мы начинаем изучать модели классификации. Однако в большинстве случаев они не полностью поняты или, скорее, неправильно поняты, и их истинная сущность не может быть использована. Под капотом это очень простые параметры расчета, которые просто нужно немного демистифицировать.
Концепция ROC и AUC основывается на знании матрицы смешения, специфичности и чувствительности. Кроме того, пример, который я буду использовать в этой статье, основан на алгоритме логистической регрессии, однако важно помнить, что концепция ROC и AUC может применяться не только к логистической регрессии.
Рассмотримгипотетический примерсодержащий группу людей. Ось Y имеет две категории, т.е. Has Heart Disease представлены красными людьми и does not have Heart Disease представлены зелеными кружками. длинная ось х, мы имеемхолестеринуровни и классификатор пытается классифицировать людей на две категории в зависимости от их уровня холестерина.

На что обратить внимание:
Это гипотетический пример, поэтому причины также являются гипотетическими😃
Логистическая регрессия
Теперь, если мы подгоним кривую логистической регрессии к данным, ось Y будет преобразована вВероятностьчеловека, имеющего заболевание сердца на основе уровня холестерина.

Белая точка обозначает человека, имеющего более низкую вероятность сердечных заболеваний, чем человек, представленный черной точкой.


Давайте теперь оценим эффективность этой логистической регрессии с порогом классификации, установленным на 0,5, с некоторыми новыми людьми, о которых мы уже знаем, есть ли у них сердечные заболевания или нет.

Наша модель логистической регрессии правильно классифицирует всех людей, кроме лиц 1 и 2.
Матрица путаницы
Давайте создадим Матрицу путаницы, чтобы суммировать классификации.

После того, как запутанная матрица заполнена, мы можем вычислитьчувствительностьиспецифичностьоценить эту логистическую регрессию на 0,5 порога.
Специфичность и чувствительность
В приведенной выше матрице путаницы давайте заменим числа тем, что они на самом деле представляют.

Теперь мы можем рассчитать две полезные метрики на основе матрицы путаницы:
чувствительность
Чувствительность говорит нам, какой процент людейсболезни сердца были на самом деле правильно определены.

Это оказывается: 3/3 + 1 = 0,75
Это говорит нам о том, что75%людей с болезнью сердца были правильно определены нашей моделью.
специфичность
Специфика говорит нам, какой процент людейбезболезни сердца были на самом деле правильно определены.

Это оказывается: 3/3 + 1 = 0,75
Это говорит нам об этом снова75%людейбез болезней сердцабыли правильно определены нашей моделью.
Если для нас важно правильно определить положительные стороны, то мы должны выбрать модель с более высокой чувствительностью. Однако, если правильное определение негативов является более важным, то мы должны выбрать специфичность в качестве метрики измерения.
Определение правильных порогов
Теперь давайте поговорим о том, что происходит, когда мы используем другой порог для принятия решения о том, есть ли у человека болезнь сердца или нет.
Это будет правильно идентифицировать всех людей, которые имеют заболевания сердца. Человек с меткой 1 также правильно классифицирован как пациент с сердечным заболеванием.

Тем не менее, это также увеличит количество ложных срабатываний, поскольку теперь лица 2 и 3 будут ошибочно классифицированы как имеющие сердечные заболевания.
Поэтому нижний порог:
Пересчет матрицы путаницы:

Теперь это правильно идентифицирует всех людей, у которых нет болезней сердца. Однако лицо, помеченное как лицо 1, будет неправильно классифицировано как не имеющее заболевания сердца.

Поэтому нижний порог:
Пересчет матрицы путаницы:

Пороговое значение может быть установлено на любое значение от 0 до 1. Итак, как мы можем определить, какой порог является лучшим? Нужно ли экспериментировать со всеми пороговыми значениями? Каждый порог приводит к разной матрице путаницы, а количество порогов приводит к большому количеству матриц путаницы, что является не лучшим способом работы.
ROC Графики
ROC (Кривая характеристики оператора приемника) может помочь в определении наилучшего порогового значения. Он генерируется путем построения истинной положительной ставки (ось Y) и ложной положительной ставки (ось X).


Истинный положительный показатель показывает, какая доля людей ‘с сердечными заболеваниямиe ‘были правильно классифицированы.
Неверно положительный показатель указывает на долю людей, классифицированных как ‘не имея болезни сердца’, Это ложные срабатывания.
Чтобы лучше узнать РПЦ, давайте начнем с нуля.

Матрица путаницы будет:

Это означает, что истинный положительный показатель, когда порог настолько низок, что каждый отдельный человек классифицируется как имеющий сердечную болезнь, равен 1. Это означает, что каждый отдельный человек с сердечной болезнью был правильно классифицирован.
Кроме того, уровень ложных срабатываний, когда порог настолько низок, что каждый отдельный человек классифицируется как имеющий сердечную болезнь, также равен 1. Это означает, что каждый отдельный человек без сердечной болезни был ошибочно классифицирован.
Построение этой точки на графике РПЦ:

Любая точка на синих диагональных линиях означает, что доля правильно классифицированных образцов равна доле неправильно классифицированных образцов.

Матрица путаницы будет:

Построим эту точку (0.5,1) на графике ROC.

Это означает, что этот порог лучше, чем предыдущий.

Построим эту точку (0,0,75) на графике ROC.

Безусловно, это лучший порог, который мы получили, поскольку он не предсказывал ложных срабатываний.
График, в этом случае, будет в (0,0):

Затем мы можем соединить точки, что дает нам ROC-график. График ROC суммирует матрицы путаницы, созданные для каждого порога, без необходимости их фактического расчета.

Просто взглянув на график, мы можем сделать вывод, что порог C лучше, чем порог B, и в зависимости от того, сколько ложных срабатываний мы готовы принять, мы можем выбрать оптимальный порог.
AUC обозначаетПлощадь под кривой, AUC дает показатель успешной классификации по логистической модели. AUC позволяет легко сравнить кривую ROC одной модели с другой.

ППКдля красногоРПЦкривая больше, чемППКдля голубыхROС кривой. Это означает, что красная кривая лучше. Если бы красная ROC-кривая была сгенерирована, скажем, Случайным лесом и Blue ROC с помощью Логистической регрессии, мы могли бы заключить, что классификатор Random лучше справился с классификацией пациентов.
Вывод
AUC и ROC являются важными показателями оценки для расчета эффективности работы любой модели классификации. Поэтому знакомство с тем, как они рассчитываются, так же важно, как и их использование. Надеемся, что в следующий раз, когда вы столкнетесь с этими терминами, вы сможете легко объяснить их в контексте вашей проблемы.
Логистическая регрессия и ROC-анализ — математический аппарат

Математический аппарат и назначение бинарной логистической регрессии — популярного инструмента для решения задач регрессии и классификации. ROC-анализ тесно связан с бинарной логистической регрессией и применяется для оценки качества моделей: позволяет выбрать аналитику модель с наилучшей прогностической силой, проанализировать чувствительность и специфичность моделей, подобрать порог отсечения.
Введение
Логистическая регрессия — полезный классический инструмент для решения задачи регрессии и классификации. ROC-анализ — аппарат для анализа качества моделей. Оба алгоритма активно используются для построения моделей в медицине и проведения клинических исследований.
Логистическая регрессия получила распространение в скоринге для расчета рейтинга заемщиков и управления кредитными рисками. Поэтому, несмотря на свое «происхождение» из статистики, логистическую регрессию и ROC-анализ почти всегда можно увидеть в наборе Data Mining алгоритмов.
Логистическая регрессия
Логистическая регрессия — это разновидность множественной регрессии, общее назначение которой состоит в анализе связи между несколькими независимыми переменными (называемыми также регрессорами или предикторами) и зависимой переменной. Бинарная логистическая регрессия применяется в случае, когда зависимая переменная является бинарной (т.е. может принимать только два значения). С помощью логистической регрессии можно оценивать вероятность того, что событие наступит для конкретного испытуемого (больной/здоровый, возврат кредита/дефолт и т.д.).
Все регрессионные модели могут быть записаны в виде формулы:
y = F (x_1,\, x_2, \,\dots, \, x_n)
В множественной линейной регрессии предполагается, что зависимая переменная является линейной функцией независимых переменных, т.е.:
Можно ли ее использовать для задачи оценки вероятности исхода события? Да, можно, вычислив стандартные коэффициенты регрессии. Например, если рассматривается исход по займу, задается переменная y со значениями 1 и 0, где 1 означает, что соответствующий заемщик расплатился по кредиту, а 0, что имел место дефолт.
Для решения проблемы задача регрессии может быть сформулирована иначе: вместо предсказания бинарной переменной, мы предсказываем непрерывную переменную со значениями на отрезке [0,1] при любых значениях независимых переменных. Это достигается применением следующего регрессионного уравнения (логит-преобразование):
где P — вероятность того, что произойдет интересующее событие e — основание натуральных логарифмов 2,71…; y — стандартное уравнение регрессии.

Рис. 1 — Логистическая кривая
P’ = \log_e \Bigl(\frac
<1-P>\Bigr)
Это преобразование обычно называют логистическим или логит-преобразованием. Теоретически P’ может принимать любое значение. Поскольку логистическое преобразование решает проблему об ограничении на 0-1 границы для первоначальной зависимой переменной (вероятности), то эти преобразованные значения можно использовать в обычном линейном регрессионном уравнении. А именно, если произвести логистическое преобразование обеих частей описанного выше уравнения, мы получим стандартную модель линейной регрессии.
Существует несколько способов нахождения коэффициентов логистической регрессии. На практике часто используют метод максимального правдоподобия. Он применяется в статистике для получения оценок параметров генеральной совокупности по данным выборки. Основу метода составляет функция правдоподобия (likehood function), выражающая плотность вероятности (вероятность) совместного появления результатов выборки
L\,(Y_1,\,Y_2,\,\dots,\,Y_k;\,\theta) = p\,(Y_1;\, \theta)\cdot\dots\cdotp\,p\,(Y_k;\,\theta)
L\,*\,(Y;\,\theta) = \ln\,(L\,(Y;\,\theta)\,) \rightarrow \max
Логарифмическая функция правдоподобия равна:
Можно показать, что градиент g и гессиан H функции правдоподобия равны:
g = \sum_i (Y_i\,-\,P_i)\,X_i
H=-\sum_i P_i\,(1\,-\,P_i)\,X_i^T\,X_i\,\leq 0
Гессиан всюду отрицательно определенный, поэтому логарифмическая функция правдоподобия всюду вогнута. Для поиска максимума можно использовать метод Ньютона, который здесь будет всегда сходиться (выполнено условие сходимости метода):
Логистическую регрессию можно представить в виде однослойной нейронной сети с сигмоидальной функцией активации, веса которой есть коэффициенты логистической регрессии, а вес поляризации — константа регрессионного уравнения (рис. 2).

Рис. 2 — Представление логистической регрессии в виде нейронной сети
Однослойная нейронная сеть может успешно решить лишь задачу линейной сепарации. Поэтому возможности по моделированию нелинейных зависимостей у логистической регрессии отсутствуют. Однако для оценки качества модели логистической регрессии существует эффективный инструмент ROC-анализа, что является несомненным ее преимуществом.
Для расчета коэффициентов логистической регрессии можно применять любые градиентные методы: метод сопряженных градиентов, методы переменной метрики и другие.
ROC-анализ
ROC-кривая (Receiver Operator Characteristic) — кривая, которая наиболее часто используется для представления результатов бинарной классификации в машинном обучении. Название пришло из систем обработки сигналов. Поскольку классов два, один из них называется классом с положительными исходами, второй — с отрицательными исходами. ROC-кривая показывает зависимость количества верно классифицированных положительных примеров от количества неверно классифицированных отрицательных примеров.
В терминологии ROC-анализа первые называются истинно положительным, вторые — ложно отрицательным множеством. При этом предполагается, что у классификатора имеется некоторый параметр, варьируя который, мы будем получать то или иное разбиение на два класса. Этот параметр часто называют порогом, или точкой отсечения (cut-off value). В зависимости от него будут получаться различные величины ошибок I и II рода.
В логистической регрессии порог отсечения изменяется от 0 до 1 — это и есть расчетное значение уравнения регрессии. Будем называть его рейтингом.
Для понимания сути ошибок I и II рода рассмотрим четырехпольную таблицу сопряженности (confusion matrix), которая строится на основе результатов классификации моделью и фактической (объективной) принадлежностью примеров к классам.
| Модель | Фактически положительно | Фактически отрицательно |
|---|---|---|
| Положительно | TP | FP |
| Отрицательно | FN | TN |
Что является положительным событием, а что — отрицательным, зависит от конкретной задачи. Например, если мы прогнозируем вероятность наличия заболевания, то положительным исходом будет класс «Больной пациент», отрицательным — «Здоровый пациент». И наоборот, если мы хотим определить вероятность того, что человек здоров, то положительным исходом будет класс «Здоровый пациент», и так далее.
При анализе чаще оперируют не абсолютными показателями, а относительными — долями (rates), выраженными в процентах:
Введем еще два определения: чувствительность и специфичность модели. Ими определяется объективная ценность любого бинарного классификатора.
Чувствительность (Sensitivity) — это и есть доля истинно положительных случаев:
Специфичность (Specificity) — доля истинно отрицательных случаев, которые были правильно идентифицированы моделью:
Заметим, что FPR=100-Sp
Попытаемся разобраться в этих определениях.
Модель с высокой чувствительностью часто дает истинный результат при наличии положительного исхода (обнаруживает положительные примеры). Наоборот, модель с высокой специфичностью чаще дает истинный результат при наличии отрицательного исхода (обнаруживает отрицательные примеры). Если рассуждать в терминах медицины — задачи диагностики заболевания, где модель классификации пациентов на больных и здоровых называется диагностическим тестом, то получится следующее:
ROC-кривая получается следующим образом:
Канонический алгоритм построения ROC-кривой
В результате вырисовывается некоторая кривая (рис. 3).

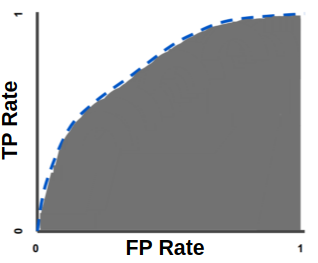
Для идеального классификатора график ROC-кривой проходит через верхний левый угол, где доля истинно положительных случаев составляет 100% или 1,0 (идеальная чувствительность), а доля ложно положительных примеров равна нулю. Поэтому чем ближе кривая к верхнему левому углу, тем выше предсказательная способность модели. Наоборот, чем меньше изгиб кривой и чем ближе она расположена к диагональной прямой, тем менее эффективна модель. Диагональная линия соответствует «бесполезному» классификатору, т.е. полной неразличимости двух классов.
При визуальной оценке ROC-кривых расположение их относительно друг друга указывает на их сравнительную эффективность. Кривая, расположенная выше и левее, свидетельствует о большей предсказательной способности модели. Так, на рис. 4 две ROC-кривые совмещены на одном графике. Видно, что модель «A» лучше.

Рис. 4 — Сравнение ROC-кривых
Визуальное сравнение кривых ROC не всегда позволяет выявить наиболее эффективную модель. Своеобразным методом сравнения ROC-кривых является оценка площади под кривыми. Теоретически она изменяется от 0 до 1,0, но, поскольку модель всегда характеризуются кривой, расположенной выше положительной диагонали, то обычно говорят об изменениях от 0,5 («бесполезный» классификатор) до 1,0 («идеальная» модель).
Эта оценка может быть получена непосредственно вычислением площади под многогранником, ограниченным справа и снизу осями координат и слева вверху — экспериментально полученными точками (рис. 5). Численный показатель площади под кривой называется AUC (Area Under Curve). Вычислить его можно, например, с помощью численного метода трапеций:
AUC = \int f(x)\,dx = \sum_i \Bigl[ \frac

Рис. 5 — Площадь под ROC-кривой
| Интервал AUC | Качество модели |
|---|---|
| 0,9-1,0 | Отличное |
| 0,8-0,9 | Очень хорошее |
| 0,7-0,8 | Хорошее |
| 0,6-0,7 | Среднее |
| 0,5-0,6 | Неудовлетворительное |
Порог отсечения нужен для того, чтобы применять модель на практике: относить новые примеры к одному из двух классов. Для определения оптимального порога нужно задать критерий его определения, т.к. в разных задачах присутствует своя оптимальная стратегия. Критериями выбора порога отсечения могут выступать:
Второе значение порога обычно предлагается пользователю по умолчанию. В третьем случае порог есть точка пересечения двух кривых, когда по оси X откладывается порог отсечения, а по оси Y — чувствительность или специфичность модели (рис. 6).

Рис. 6 — «Точка баланса» между чувствительностью и специфичностью
Существуют и другие подходы, когда ошибкам I и II рода назначается вес, который интерпретируется как цена ошибок. Но здесь встает проблема определения этих весов, что само по себе является сложной, а часто не разрешимой задачей.
Техблог Александра Куракина
Машинное обучение, нейронные сети
Страницы
среда, 29 августа 2018 г.
Классификация: ROC и AUC
ROC кривая
Ложно положительная скорость (FPR) определяется следующим образом:
Кривая ROC является графиком TPR и FPR при разных значениях порогов классификации. Снижение порога классификации классифицирует больше примеров как позитивные, при этом увеличиваются и Ложно положительные и Истинно положительные. Следующий график показывает типичную ROC кривую.

TP и FP скорость при разных классификационных порогах.
Чтобы вычислить точки на ROC кривой мы можем оценить модель логистической регрессии много раз с разными классификационными порогами, но это будет неэффективно. К счастью, существует эффективный, основанный на сортировке, алгоритм, который может предоставить нам эту информацию, называемый AUC.
AUC: область под ROC кривой
AUC обозначает «область под ROC кривой» («Area under the ROC Curve»). AUC измеряет всю двухмерную область под всей ROC привой (то есть вычисляет интеграл) от (0,0) до (1,1).
AUC (область под ROC кривой)

Прогнозы ранжированные в восходящем порядке счета логистической регрессии.
AUC предоставляет вероятность того, что случайный позитивный (зеленый) пример будет расположен правее случайного отрицательного (красного) примера.
AUC выдает результаты в периоде от 0 до 1. Модель, чьи прогнозы 100% ошибочны, имеет AUC равную 0.0, а модель со 100% верными прогнозами имеет AUC равную 1.0.
AUC привлекательна по следующим двум причинам:
Однако, обе эти причины имеют ограничения, которые могут ограничить полезность AUC в определенных случаях:
Введение: Соревнование от финансовой группы HOME CREDIT по определению риска дефолта заемщика

В статье рассматривается соревнование по машинному обучению «Home Credit Default Risk», цель которого – использовать исторические данные о заявках на получение кредита, чтобы предсказать, сможет ли заявитель погасить ссуду (определить риск дефолта заемщика). Прогнозирование того, вернет ли клиент ссуду или столкнется с трудностями, является критически важной бизнес-задачей, и Home Credit проводит конкурс на платформе Kaggle, чтобы увидеть, какие модели машинного обучения, способные помочь им в решении этой задачи, может разработать сообщество.
Это стандартная задача классификации с учителем:
Обучение с учителем: верные ответы включаются в состав обучающих данных, и цель состоит в том, чтобы обучить модель предсказывать эти ответы на основе имеющихся признаков.
Задача классификации: для каждого набора признаков необходимо предсказать ответ, который представляет собой двоичную переменную со значениями – 0 (заемщик выплатит кредит вовремя) или 1 (возникнут трудности с погашением кредита).
Данные
Данные предоставлены финансовой группой Home Credit, предлагающей кредитные линии (ссуды) населению, не охваченному банковскими услугами. Всего имеется 7 различных источников данных:
applicationtrain / applicationtest: основные данные для обучения и тестирования с информацией о каждой кредитной заявке в Home Credit. Каждая ссуда представлена отдельной строкой, в которой признак SKIDCURR является уникальным идентификатором. Данные обучающей выборки имеют метку TARGET со значениями:
0, если ссуда была возвращена;
1, если ссуда не была погашена.
bureau: данные о предыдущих кредитах клиента в других финансовых учреждениях. Каждый предыдущий кредит в этом файле представлен отдельной строкой, при этом для каждой записи в обучающей выборке может иметься несколько записей о предыдущих кредитах.
bureaubalance: ежемесячные данные о предыдущих кредитах. Каждая строка представляет собой данные за один месяц срока действия предыдущего кредита. При этом каждый предыдущий кредит может иметь несколько строк, по одной на каждый месяц продолжительности кредита.
previousapplication: предыдущие заявки на получение ссуд в Home Credit для клиентов, данные которых имеются в обучающей выборке. Каждая текущая ссуда в обучающей выборке может иметь несколько предыдущих ссуд, каждая из которых представлена в файле одной строкой и идентифицируется признаком SKIDPREV.
POSCASHBALANCE: исторические ежемесячные данные о покупках и выдаче наличных денег для клиентов, обслуживающихся в Home Credit. Каждая строка представляет собой данные за один месяц, при этом каждая предыдущая ссуда может иметь несколько строк в данном файле.
creditcardbalance: ежемесячные данные о предыдущих кредитных картах, которые клиенты получили в Home Credit. Каждая строка представляет собой информацию о балансе кредитной карты за один месяц. При этом одна кредитная карта может быть представлена несколькими строками.
installments_payment: история платежей по предыдущим кредитам в Home Credit, содержит по одной строке для каждого совершенного и пропущенного платежа.
Эта диаграмма показывает, как данные связаны между собой:

Кроме того, в рамках соревнования предоставлены описания всех признаков (в файле HomeCredit_columns_description.csv) и пример результирующего файла с предсказанными ответами.
В рамках данной статьи я буду использовать только основные данные для обучения и тестирования (application_train / application_test), который должны быть более понятными. Это позволит установить базовый уровень, который можно постепенно улучшать. В подобных соревнованиях лучше постепенно осмысливать проблему, чем сразу полностью погрузиться в нее и запутаться! Однако если вы хотите иметь хоть какую-то надежду на серьезный результат, в дальнейшем нужно будет использовать все данные.
Метрика: ROC AUC
Как только вы разберетесь с данными (в этом очень помогает прочтение описания признаков), следующим шагом должно стать понимание метрике, по которой оценивается работа. В данном случае это общепринятая метрика классификации, известная как площадь под кривой ошибок (ROC AUC, также иногда называемая AUROC).
Метрика ROC AUC может показаться пугающей, но она относительно проста, если разобраться с двумя отдельными концепциями.
Кривая ошибок (ROC) отображает соотношение между долей объектов от общего количества носителей признака, верно классифицированных как несущие признак, и долей объектов от общего количества объектов, не несущих признака, ошибочно классифицированных как несущие признак:
Отдельные линии на графике обозначают кривую для одной модели, а движение вдоль линии указывает на изменение порога, используемого для классификации положительных экземпляров. Порог начинается с 0 в правом верхнем углу и переходит в 1 в левом нижнем углу. Кривая, которая находится левее и выше других, указывает на лучшую модель. Например, модель, представленная синей линией, лучше красной, которая, в свою очередь, лучше черной (эта диагональная линия указывает на наивную модель случайного угадывания).
Площадь под кривой (AUC) уже содержит объяснение в своем названии. Это просто область под кривой ROC (интеграл кривой). Этот показатель находится в диапазоне от 0 до 1, при этом лучшая модель получает более высокий балл. Модель, которая просто угадывает результат случайным образом, будет иметь ROC AUC = 0,5.
Когда мы оцениваем классификатор в соответствии с метрикой ROC AUC, мы генерируем не точные прогнозы 0 или 1, а скорее вероятность от 0 до 1. Это может сбивать с толку, потому что обычно мы предпочитаем думать с точки зрения точности, однако, когда мы сталкиваемся с проблемой несбалансированных классов (далее мы увидим, что это так) точность — не лучшая метрика. Например, если бы я хотел построить модель, которая могла бы обнаруживать террористов с точностью 99,9999%, я бы просто сделал модель, предсказывающую, что каждый человек не является террористом. Ясно, что это будет неэффективно (полнота будет равна нулю), поэтому мы будем использовать более сложные показатели, такие как ROC AUC или оценка F1, чтобы более точно отразить эффективность классификатора. Модель с высоким значением ROC AUC также будет иметь высокую точность, но кроме этого ROC AUC лучше отражает и другие характеристики модели.
Сейчас мы ознакомились с используемыми данными и метрикой, которую нужно максимизировать, поэтому давайте перейдем непосредственно к более глубокому изучению данных. Как упоминалось ранее, я буду придерживаться основных источников данных и простых моделей, которые можно использовать в дальнейшей работе. Приступим к написанию кода.
Импорт
Я буду использовать типичный стек библиотек для работы с данными: numpy и pandas для манипулирования данными, sklearn preprocessing для работы с категориальными переменными, matplotlib и¨C11C¨C12C¨C13Cдля построения графиков и диаграмм. Также импортирую дополнительные модули для упрощения работы.
Для начала, посмотрим, какие файлы данных доступны в рамках задачи. Всего имеется 9 файлов: файл с обучающими данными (с целевой меткой), файл для тестирования (без целевой метки), файл с примером результата и 6 других файлов, содержащих дополнительную информацию о каждой ссуде.
‘POSCASHbalance.csv’, ‘bureaubalance.csv’, ‘applicationtrain.csv’, ‘previousapplication.csv’, ‘installmentspayments.csv’, ‘creditcardbalance.csv’, ‘samplesubmission.csv’, ‘applicationtest.csv’, ‘bureau.csv’]
Training data shape: (307511, 122)
Файл с тренировочными данными содержит 307511 строк, для каждой из которых имеется 120 признаков, а также столбец с идентификатором ссуды и столбец с целевой меткой, которую мы хотим предсказать.
Testing data shape: (48744, 121)
Тестовых данных значительно меньше, и в них отсутствует столбец TARGET.
Исследовательский анализ данных (EXPLORATORY DATA ANALYSIS – EDA)
Исследовательский анализ данных (EDA) — это открытый процесс, в ходе которого необходимо рассчитывать статистики и строить графики, чтобы найти тенденции, аномалии, закономерности или взаимосвязи в данных. Цель EDA — узнать, что могут нам сказать наши данные. Обычно он начинается с общего обзора, а затем сужается к конкретным областям, когда мы находим интересные области данных. Результаты могут быть интересны сами по себе, или их можно использовать для принятия решения о выборе модели, например, помогая нам решить, какие признаки использовать.
Изучим распределение целевой метки
Цель — это то, что нас просят предсказать: либо 0, если ссуда была выплачена вовремя, либо 1, если у клиента возникли трудности с оплатой. Сначала мы можем изучить количество кредитов, попадающих в каждую категорию.
Из этой информации можно понять, что в данной задаче присутствует проблема несбалансированного класса. Ссуд, выплаченных вовремя, намного больше, чем невыплаченных ссуд. Когда вы будете переходить к более сложным моделям машинного обучения, сможете взвесить классы по их доле в данных, чтобы смягчить этот дисбаланс.
Проверим пропущенные значения
Теперь мы можем посмотреть количество и процент пропущенных значений в каждом столбце.
Your selected dataframe has 122 columns.
There are 67 columns that have missing values.
Когда придет время строить модели машинного обучения, нужно будет чем-то заполнить эти недостающие значения. В дальнейшем я покажу использование таких моделей, как XGBoost, которые могут обрабатывать отсутствующие значения без необходимости их заполнения. Другой вариант – отбросить столбцы с высоким процентом пропущенных значений, хотя заранее невозможно узнать, будут ли они полезны для модели. Поэтому пока оставим все столбцы датафрейма.
Типы данных признаков
Настало время посмотреть на количество признаков каждого типа данных. int64 и float64 — числовые переменные (которые могут быть дискретными или непрерывными). Признаки с типом данных object содержат строки и являются категориальными признаками.
Теперь узнаем количество уникальных записей в каждом из столбцов типа object(категориальных).
Как видим, большинство категориальных переменных имеют относительно небольшое количество уникальных записей. Теперь нужно найти способ обработки этих признаков.
Кодирование категориальных переменных
Прежде чем продолжить, необходимо разобраться с категориальными переменными. К сожалению, модели машинного обучения не могут работать с категориальными переменными (за исключением некоторых моделей, таких как LightGBM). Следовательно, мы должны найти способ закодировать (представить) эти переменные в виде чисел, прежде чем передавать их модели. Есть два основных способа осуществить этот процесс:
Кодирование метки (Label encoding): назначаем каждой уникальной категории в категориальной переменной целое число. Новые столбцы не создаются. Пример показан ниже:
Однопроходное кодирование (One-hot encoding): создаем новый столбец для каждой уникальной категории в категориальной переменной. Каждое наблюдение получает 1 в столбце для соответствующей категории и 0 во всех других новых столбцах.
Проблема с кодированием меток состоит в том, что оно дает категориям произвольный порядок. Значение, присвоенное каждой из категорий, является случайным и не отражает каких-либо неотъемлемых аспектов категории. В приведенном выше примере программист получает метку 4, а специалист по данным — 1, но если бы мы повторили тот же процесс снова, метки могли бы быть перевернутыми или совершенно другими. Фактическое присвоение целых чисел произвольно. Следовательно, когда мы выполняем кодирование меток, модель может использовать относительное значение функции (например, программист = 4 и специалист по данным = 1) для присвоения весов, а это совсем не то, чего мы хотим. Если у нас есть только два уникальных значения для категориальной переменной (например, мужчина / женщина), тогда кодирование метки подойдет, но для более чем двух уникальных категорий безопасным вариантом является однопроходное кодирование.
Об относительных достоинствах этих подходов ведутся споры, и некоторые модели могут без проблем работать с категориальными переменными, закодированными метками. Один из участников рассматриваемого мной соревнования – Kaggle-master Will Koehrsen, считает, что для категориальных переменных с множеством классов наиболее безопасным подходом является однопроходное кодирование, поскольку оно не навязывает произвольные значения категориям. И в этом с ним согласны многие специалисты в области машинного обучения и анализа данных. Единственным недостатком этого метода является то, что количество признаков (измерений данных) может увеличиваться из-за категориальных переменных со многими категориями. Чтобы справиться с этим, можно выполнить однопроходное кодирование с последующим применением метода PCA или другими методами уменьшения размерности, чтобы уменьшить количество измерений (при этом, все еще пытаясь сохранить полезную информацию).
В своем примере я буду использовать Label Encoding для любых категориальных переменных только с 2 категориями и One-Hot Encoding для любых категориальных переменных с более чем 2 категориями. Возможно, потребуется изменить этот подход по мере того, как мы углубимся в проект, но пока можно посмотреть, к чему это приведет. Я также не буду использовать какие-либо методы уменьшение размерности.
Label Encoding И One-Hot Encoding
Реализуем описанные выше методы: для любой категориальной переменной (dtype == object) с двумя уникальными категориями я буду использовать кодирование меток, а для любой категориальной переменной с более чем двумя уникальными категориями – однопроходное кодирование.
Для кодирования меток воспользуюсь методом LabelEncoder из библиотеки Scikit-Learn, а для однопроходного кодирования – функцией pandas get_dummies(df).
3 columns were label encoded.
raining Features shape: (307511, 243)
Testing Features shape: (48744, 239).
Выравнивание данных обучения и тестирования
В данных для обучения и тестирования должны быть одни и те же признаки (столбцы). Однопроходное кодирование создало больше столбцов в обучающих данных, потому что в них имелись категориальные переменные с категориями, не представленными в данных тестирования. В связи с этим необходимо выровнять фреймы данных. Сначала извлекаем целевой столбец из данных обучения (потому что его нет в данных тестирования, но нужно сохранить эту информацию). При выполнении выравнивание необходимо убедиться, что установлен параметр axis = 1, чтобы выровнять фреймы данных на основе столбцов, а не строк!
Training Features shape: (307511, 240)
Testing Features shape: (48744, 239)
Теперь наборы данных для обучения и тестирования имеют одинаковые признаки, которые требуются для машинного обучения. Количество признаков значительно выросло за счет «однопроходного» кодирования. В какой-то момент вы, вероятно, захотите попробовать уменьшить размерность (удалить признаки, которые не имеют отношения к делу), чтобы уменьшить размер наборов данных.
Возвращаемся к исследовательскому анализу данных аномалии
Данные о возрасте выглядят разумно — нет никаких выбросов значений. Теперь рассмотрим рабочие дни.
Это выглядит неправильно – максимальное значение (кроме того, что оно положительное) — около 1000 лет!
Давайте рассмотрим аномальных клиентов и посмотрим, имеют ли они отличия в показателях дефолта от остальных клиентов.
The non-anomalies default on 8.66% of loans
The anomalies default on 5.40% of loans
There are 55374 anomalous days of employment
Это выглядит очень интересно – оказывается, аномалии имеют меньшую частоту дефолта.
Обработка аномалий зависит от конкретной ситуации и не имеет установленных правил. Один из самых безопасных подходов — просто установить для аномальных значений пропуски, а затем заполнить их перед машинным обучением. В этом случае, поскольку все аномалии имеют одинаковое значение, можно заполнить их одинаковым значением на случай, если все эти ссуды имеют что-то общее. Возможно, аномальные значения имеют некоторую важность, поэтому желательно сообщить модели машинного обучения, действительно ли мы сами заполнили эти значения. В качестве решения заполним аномальные значения не числом (np.nan), а затем создадим новый логический столбец, указывающий, было ли значение аномальным.
Теперь распределение выглядит гораздо более соответствующим тому, что можно было ожидать. Также создан новый столбец, чтобы сообщить модели, что эти значения изначально были аномальными (поскольку нужно будет заполнить nans некоторым значением, возможно, медианным значением столбца). Другие столбцы с DAYS во фрейме данных выглядят примерно так, как и ожидается, без явных выбросов.
Чрезвычайно важное замечание: все, что мы делаем с данными обучения, необходимо делать и с данными тестирования. Обязательно создайте новый столбец и заполните аномальные значения np.nan в данных тестирования.
There are 9274 anomalies in the test data out of 48744 entries
КОРРЕЛЯЦИИ
Теперь, когда мы разобрались с категориальными переменными и выбросами, продолжим работу с EDA. Один из способов попытаться понять данные — это поиск корреляций между признаками и целью. Мы можем рассчитать коэффициент корреляции Пирсона между каждой переменной и целью, используя метод фрейма данных .corr.
Коэффициент корреляции — не лучший метод представления «релевантности» признака, но он дает нам представление о возможных взаимосвязях в данных. Некоторые общие интерпретации абсолютного значения коэффициента корреляции:
.00–0.19 «очень слабый»
0,80–1,0 «очень сильный»
Посмотрим на некоторые из наиболее значимых корреляций: у признака DAYSBIRTH — самая положительная корреляция (кроме TARGET, потому что корреляция переменной с самой собой всегда равна 1). Если посмотреть в описании, DAYSBIRTH — это возраст клиента в отрицательных днях на момент выдачи кредита. Корреляция положительная, но значение этого признака на самом деле отрицательное, что означает, что по мере того, как клиент становится старше, он с меньшей вероятностью не выплатит свой кредит (т.е. цель == 0). Это немного сбивает с толку, поэтому стоит взять абсолютное значение признака, чтобы корреляция стала отрицательной.
По мере того, как клиент становится старше, возникает отрицательная линейная связь с целью, что означает, что по мере взросления клиенты склонны чаще возвращать свои ссуды вовремя.
Стоит подробнее проанализировать эту переменную. Во-первых, можно построить гистограмму возраста. Чтобы сделать график более понятным, проведем ось x через годы.
Само по себе возрастное распределение не говорит нам ничего, кроме того, что в нем отсутствуют явные выбросы, поскольку все возрасты выглядят разумно. Чтобы визуализировать влияние возраста на цель, мы построим график оценки плотности ядра(KDE), раскрашенный значением цели. График оценки плотности ядра показывает распределение одной переменной и может рассматриваться как сглаженная гистограмма (она создается путем вычисления ядра, обычно гауссовского, в каждой точке данных, а затем усреднения всех отдельных ядер для получения единой сглаженной кривой). Для этого графика мы будем использовать seaborn kdeplot.
Чтобы построить этот график, сначала поделим возрастную категорию на ячейки по 5 лет каждая. Затем для каждой ячейки вычислим среднее значение целевого показателя, которое показывает соотношение невыплаченных кредитов в каждой возрастной категории.
Прослеживается четкая тенденция: молодые заемщики чаще не возвращают кредит. Уровень невозврата составляет более 10% для трех младших возрастных групп и ниже 5% для самой старшей возрастной группы.
Эта информация может быть использована банком напрямую: поскольку молодые клиенты с меньшей вероятностью вернут ссуду, возможно, им следует предоставить дополнительные рекомендации или советы по финансовому планированию. Это не означает, что банк должен дискриминировать молодых клиентов, но было бы разумно принять меры предосторожности, чтобы помочь более молодым клиентам платить вовремя.
Внешние источники
Три переменных с наиболее сильной отрицательной корреляцией с целью: EXTSOURCE1, EXTSOURCE2 и EXTSOURCE3. Согласно документации, эти признаки представляют собой «нормализованную оценку из внешнего источника данных». У меня нет полной уверенности, что именно это означает, но, возможно, это совокупный кредитный рейтинг, рассчитанный с использованием многочисленных источников данных.
Давайте посмотрим на эти переменные.
Во-первых, мы можем показать корреляции функций EXT_SOURCE с целью и друг с другом.
Все три признака EXT_SOURCE имеют отрицательную корреляцию с целью, что указывает на то, что по мере увеличения значения EXT_SOURCE клиент с большей вероятностью погасит ссуду. Мы также можем видеть, что DAYS_BIRTH положительно коррелирует с EXT_SOURCE_1, указывая на то, что, возможно, одним из факторов в этой оценке является возраст клиента.
Далее мы можем посмотреть на распределение каждого из этих признаков, окрашенных в соответствии со значением цели. Это позволит визуализировать влияние этих переменных на цель.
EXT_SOURCE_3 отображает наибольшую разницу между значениями цели. Можно ясно видеть, что этот признак имеет некоторое отношение к вероятности возврата кредита заемщиком. Связь не очень сильная (на самом деле все они считаются очень слабыми), но эти признаки все равно будут полезны для модели машинного обучения, чтобы предсказать, вернет ли кандидат ссуду вовремя.
Парный график
В качестве дополнительного исследовательского сюжета мы можем построить парный график признаков EXTSOURCE и признака DAYSBIRTH. График пар – отличный инструмент для исследования, потому что он позволяет видеть отношения между несколькими парами признаков, а также распределения отдельных признаков. Здесь мы используем библиотеку визуализации seaborn и функцию PairGrid, чтобы создать график пар с диаграммами рассеяния в верхнем треугольнике, гистограммами на диагонали и графиками плотности ядра 2D и коэффициентами корреляции в нижнем треугольнике.
На этом графике красный цвет указывает ссуды, которые не были погашены, а синий — ссуды, которые выплачены. Мы можем видеть различные отношения в данных. Между EXT_SOURCE_1 и YEARS_BIRTH действительно существует умеренная положительная линейная зависимость, указывающая на то, что этот признак может учитывать возраст клиента.
На этом первая статья завершена. В следующей части я расскажу о разработке дополнительных признаков на основе имеющихся данных, а также продемонстрирую создание простейшей модели машинного обучения.
При подготовке статьи были использованы материалы из открытых источников: источник_1, источник_2.



