How to use slugs in django url
Have been scared to ask this here, just started with Stack Overflow and, believe me, I have tried searching for this question, but mostly I saw regex patterns.
Please if anyone could be kind enough to guide me through these few issues:
How to fill my blog model slug field automatically with the post name without filling it up myself.
How to make a link to go to the single post page using the slug WITHOUT regex in Django 2.x


1 Answer 1
So you haven’t posted your code, but assuming your model looks like this:
And that you want to pre-fill the slug from the title, you have a few options depending on where you want to do it:
From the admin
The easiest way to get this in the admin is via the prepopulated_fields
Django will auto-update the slug field as you type the title when creating a post. Very nice UX, but limited to the admin.
Outside of the admin
Link Post by slug
Disclaimer: if you need more details on this part, I suggest the part 3 of the official tutorial.
Provided you have a URL path:
Then, in your views module you have a view:
You can link to a Post by calling, in Python:
Or in a Django template:
EDIT: Post index page
You could then add an index page, generating a list linking to all your posts:
Django позволяет создавать приложения очень легко. Если приложение должно быть выпущено быстро и является относительно общим, то эта среда Python идеально подходит для этого. В течение нескольких лет я профессионально работал в этой среде и часто рылся внутри, поэтому знаю почти всё, и сегодня я представлю вам все, что нужно знать, чтобы эффективно использовать универсальный DetailView в Django.
Классовые методы имеют своих сторонников и противников. Люди, которые любят объектно-ориентированные программы, естественно, выбирают общие представления, потому что они более дружелюбны к ним. С другой стороны, люди, которые предпочитают функцию-представление на основе классов, используют ее, только если она приносит разумное упрощение. Я думаю, что стоит придерживаться одного соглашения, поэтому, если вы хотите иметь несколько представлений в своем приложении, лучше, если они все классовые или функциональные. И поскольку классные комнаты предоставляют гораздо больше возможностей, конечно, мой выбор падает на общие взгляды.
Базовая модель
Представление отображает данные, но вам нужно подготовить их. Давайте подготовим модель данных, которую мы хотим отобразить. Пусть это будет модель Post с базовыми данными, такими как заголовок, слаг, некоторый контент и тизер.
Представление
У нас есть модель, поэтому мы собираемся написать простое представление. Представление очень простое, и наиболее важными вопросами являются импорт класса, от которого мы унаследуем, и модели, которую мы регистрируем.
Регистрация представления в urls.py
Поскольку у нас есть представление, мы должны теперь присоединить его, все адреса указаны в файле urls.py. В целях одного представления мы не будем извлекать это в файл для приложения. Если запись окажется ценной и из нее будет создана серия, то в резюме мы проведем рефакторинг.
Регистрация представления по полю pk
Общий вид DetailView построен настолько умно, что по умолчанию обеспечивает вызов как по pk, так и по slug.
Пользовательский slug_field
Шаблон
По сути, эти 3 простых шага позволят вам создать простой сайт. В следующей части поста я представлю дополнительные возможности, предлагаемые общими представлениями, которые стоит знать и могут быть полезны более одного раза.
Загрузка пользовательских объектов
Использование пользовательских запросов
Давайте посмотрим пример того, как отображать только активные записи. Предположим, у этого объекта есть ссылка на фото.
Метод get_queryset
Конечно, здесь есть много упрощений, и я не дал реализацию Api, потому что она здесь неактуальна. Важно, что вы можете свободно переопределить этот метод. Вы также можете сделать своего рода гибрид, который набор запросов будет загружать из базы данных и уже детали после API, или наоборот. Попробуйте сами и дайте мне знать, если вы нашли какое-либо интересное приложение.
Практическое переопределение метода get_queryset
Это все? Ну, не совсем. Таким образом, мы никоим образом не защищаем адрес и не проверяем, появляется ли категория в адресе. Если мы не справимся с этим, существует риск, что один и тот же контент будет отображаться на многих адресах, что не является лучшим решением для Google.
Конечно, мы помним о select_related все время. А так просто добавили интересный патч, который легко забыть.
Наименование объекта в шаблоне
После такого изменения мы можем улучшить шаблон
Альтернативный шаблон
Что, если я хочу иметь два разных представления, например, потому что они поддерживают разную логику, но способ отображения данных идентичен? Я боролся с этим много раз и, поверьте мне, со старыми версиями django, такими как 1.2 (хоть и давно это было), было много путанницы. Однако сегодня просто переопределите атрибут template_name для любого шаблона.
Декораторы на представлениях-классах
Дополнительные данные в контексте
Не раз у вас возникнет ситуация, когда вам придется перенести дополнительные данные в шаблон. Есть много возможностей, и все зависит от того, что вы хотите передать.
Давайте напишем последние записи в шаблоне:
Чаще всего для извлечения объекта вам нужен ключ, то есть какое-то значение, после которого мы должны определить объект. Но это не всегда так, о чем свидетельствует загрузка чего-либо из сессии или из самого запроса. Хорошим примером является загрузка пользователя, например. Посмотрим на пример:
Небольшое обновление в представлении:
Итоги
Вы только что познакомились с одним из трех основных общих представлений в Django, на которых вы можете создавать множество приложений. Конечно, это еще не все, потому что их гораздо больше, но эти три являются своего рода кодом, который вам нужно знать.
Что такое slug в django
Функции-представления могут принимать параметры, через которые могут передаваться различные данные. Подобный параметры передаются в в адресе URL. Например, в запросе http://localhost/index/3/5/ поледние два сегмента 3/5/ могут представлять параметры URL, которые могут быть связанны с параметрами функции-представления через систему маршрутизации.
Определение параметров через функцию re_path
Определим в приложении в файле views.py следующие функции:
Во втором шаблоне адреса определяются два параметра: id и name ( (?P \d+)/(?P \D+) ). При этом параметр id должен представлять число, а параметр name должен состоять только из буквенных символов.
Ну и также отметим, что количество и название параметров в шаблонах адресов URL соответствуют количеству и названиям параметров соответствующих функций, которые обрабатывают запросы по данным адресам.
Теперь мы можем чем адресную строку передать данные в приложение:


Однако, что если мы не передадим значение для параметра или передадим ему значение, которое не соответствует регулярному выражению? В этом случае система не смодет найти ресурс для обработки запроса:

В этом случае мы можем определить в файле views.py для параметра функции products значение параметра по умолчанию:
То есть если в функцию не передается значение для параметра productid, то он получает значение 21.
В этом случае надо дополнительно определить еще один маршрут в файле urls.py :
Определение параметров через функцию path
Возьмем те же функции в файле views.py :
Определение параметров с помощью функции path() будет выглядеть следующим образом:
По умолчанию Django предоставляет следующие спецификаторы:
str : соответствует любой строке за исключенем символа «/». Если спецификатор не указан, то используется по умолчанию
int : соответствует любому положительному числу
slug : соответствует последовательности буквенных символов ASCII, цифр, дефиса и символа подчеркивания, например, building-your-1st-django-site
uuid : сооветствует идентификатору UUID, например, 075194d3-6885-417e-a8a8-6c931e272f00
path : соответствует любой строке, которая также может включать символ «/» в отличие от спецификатора str
Значения для параметров по умолчанию
Определеним для функций в views.py значения для параметров по умолчанию:
В этом случае для каждой функции надо определить по два маршрута:
Что такое «slug» в Django?
Когда я читаю код Django, я часто вижу в моделях то, что называется «slug». Я не совсем уверен, что это такое, но я знаю, что это имеет какое-то отношение к URLs. Как и когда предполагается использовать эту слизняковую штуку?
9 ответов
Я использую prepopulated_fields =
Я обошел вокруг Django и последовал за танго с книгой Django, но этот последний выпуск достает меня после добавления подкатегорий, которые не включены в этот учебник. У меня есть следующее: models.py class Category(models.Model): Category name = models.CharField(max_length=50) slug =.
A «slug»-это способ генерации действительного URL, как правило, с использованием уже полученных данных. Например, пуля использует заголовок статьи для создания URL. Я советую сгенерировать слиток с помощью функции, учитывая название (или другой фрагмент данных), а не устанавливать его вручную.
Теперь давайте представим, что у нас есть модель Django, такая как:
Как бы вы ссылались на этот объект с URL и со значимым именем? Вы могли бы, например, использовать Article.id, чтобы URL выглядел так:
Или, возможно, вы захотите сослаться на название следующим образом:
Обе попытки не приводят к очень значимым результатам, easy-to-read URL. Это лучше:
Также смотрите URL этой самой веб-страницы для другого примера.
Если позволите, я приведу некоторый исторический контекст :
Термин «slug» относится к литейному металлу—свинцу, в данном случае—из которого были изготовлены печатные шрифты. Каждая бумага тогда имела свою фабрику шрифтов, регулярно переплавляемую и переделываемую в новые формы, так как после многих отпечатков они изнашивались. Такие ученики, как я, начинали свою карьеру там и прошли весь путь до вершины (больше нет).
Типографы должны были составлять текст статьи в обратном порядке с помощью свинцовых символов, сложенных в мудром порядке. Таким образом, во время печати буквы будут лежать прямо на бумаге. Все типографы могли читать газету в зеркальном отражении так же быстро, как и печатную. Поэтому слизни (как улитки), а также медленные истории (последние, которые будут исправлены) были многими на скамейке ожидания, идентифицированные исключительно по их буквам в кулаке, в основном весь заголовок, как правило, более читаемый. Некоторые новости «hot» ждали там на скамейке, для возможной коррекции в последнюю минуту (вечерняя газета) перед последней assembly и окончательной печатью.
Django вышел из офиса журнала Лоуренса в Канзасе. Где, вероятно, все еще сохранился какой-то печатный жаргон. A-django-enthusiast-&-friendly-old-slug-boy-from-France.
Django имеет свойство unique_for_date, которое вы можете установить при добавлении SlugField в вашу модель. Это приводит к тому, что слаг будет уникальным только для указанной даты поля: class Example(models.Model): title = models.CharField() slug = models.SlugField(unique_for_date=’publish’).
Термин ‘slug’ происходит из мира газетного производства.
Он может даже датироваться более ранним временем, поскольку в сценариях в начале каждой сцены было «slug lines», что в основном задает фон для этой сцены (где, когда и так далее). Это очень похоже на то, что это точная преамбула того, что следует.
На линотипной машине пуля представляла собой однолинейный кусок металла, который был создан из отдельных буквенных форм. Сделав один слиток для всей линии, это значительно улучшило старую композицию character-by-character.
Хотя следующее является чистой гипотезой, раннее значение slug было для фальшивой монеты (которую нужно было бы как-то отжать). Я мог бы представить, что это использование будет преобразовано в печатный термин (поскольку пуля должна была быть нажата с использованием оригинальных символов), а затем изменится с определения «кусок металла» на определение ‘story summary’. Отсюда-короткий шаг от правильной печати до онлайн-мира.
Слизняк-это газетный термин. Пуля-это короткая метка для чего-либо, содержащая только буквы, цифры, подчеркивания или дефисы. Они обычно используются в URLs. (как и в Django документах)
Поле slug в Django используется для хранения и создания допустимого URLs для динамически создаваемых веб-страниц.
Точно так же, как вы добавили этот вопрос на Stack Overflow, и была создана динамическая страница, и когда вы увидите в адресной строке заголовок вашего вопроса с «-» вместо пробелов. Это в точности работа поля слизней.

При хранении его в поле slug он становится «what-is-a-slug-in-django» (см. URL этой страницы)
Slug-это удобная короткая метка URL для конкретного контента. Он содержит только буквы, цифры, подчеркивания или дефисы. Слизни обычно сохраняются с соответствующим содержимым и передаются в виде строки URL.
Слизень может создавать с помощью SlugField
Если вы хотите использовать title как slug, django имеет простую функцию под названием slugify
Если ему нужна уникальность, добавьте unique=True в поле slug.
например, из предыдущего примера:
Также автоматический слиток в django-admin. Добавлено в ModelAdmin:
слизень
Короткая метка для чего-либо, содержащая только буквы, цифры, подчеркивания или дефисы. Они обычно используются в URLs. Например, в типичной записи в блоге URL:
Похожие вопросы:
Я пытаюсь загрузить некоторые смайлики на определенный сайт. Обязательными полями являются: Кратчайший путь: Изображение: Категория: Предлагаемая Категория: Для изображения я просто выбираю его из.
Я только что начал использовать Django в течение некоторого времени, и я застрял, пытаясь работать со слизняком. Я знаю, что это такое, но мне трудно определить простой слизень и отобразить его в.
Я использую prepopulated_fields =
Я обошел вокруг Django и последовал за танго с книгой Django, но этот последний выпуск достает меня после добавления подкатегорий, которые не включены в этот учебник. У меня есть следующее.
Django имеет свойство unique_for_date, которое вы можете установить при добавлении SlugField в вашу модель. Это приводит к тому, что слаг будет уникальным только для указанной даты поля: class.
Основы ORM Django за час
На этом занятии мы рассмотрим основные команды ORM Django (иногда еще говорят API модели). Это будет лишь обзорное занятие огромной темы. Если вы уже знакомы с ORM, то можно пропустить его и переходить к следующим темам. Для всех остальных – это введение, чтобы у вас сформировалось начальное представление об использовании этого API.
Некоторое введение у нас уже было, когда мы рассматривали операции для одной конкретной модели (таблицы). Здесь же углубимся в эту тему и посмотрим, как можно выполнять манипуляции со связанными таблицами. В качестве примера у нас будет две наших ранее созданных модели: Women и Category, которые связаны по внешнему ключу:
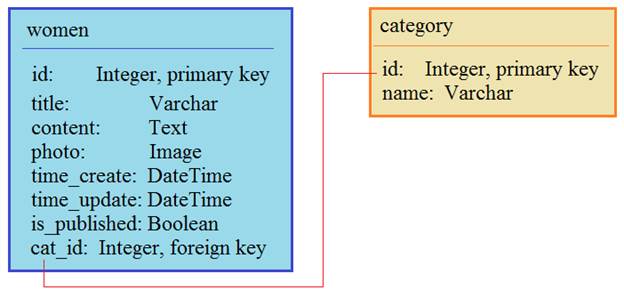
Вообще, ORM Django имеет очень богатый функционал и вам вряд ли понадобится переходить на уровень SQL-запросов, все можно сделать на уровне этого API. Кроме того, начинающим разработчикам уровень ORM позволит писать грамотные и оптимизированные запросы к БД любого типа: SQLite, MySQL, PostgreSQL, Oracle, то есть, приложение будет совершенно независимым от типа СУБД. Все это и привело к тому, что сейчас, в основном, используются различные ORM при работе с таблицами БД. Подробную информацию обо всем этом можно посмотреть на сайте русскоязычной документации:
в разделе «ORM и работа с базой данных» и подразделе «QuerySet». В частности ссылка «методы QuerySet»:
приводит нас на страницу с описанием различных методов, которые доступны в ORM Django. Как всегда, советую с ними подробно ознакомиться, чтобы грамотно их использовать в своих проектах. Чаще всего используются методы: filter, all, get, о которых мы уже немного говорили. Также здесь вы найдете, так называемые, lookup’ы, которые позволяют формировать различные условия для выборки записей, и ниже представлены функции агрегации.
Чтобы демонстрировать работу команд, я перейду в терминал и запущу оболочку Django:
python manage.py shell
Первой строчкой импортирую модели, с которыми будем работать:
Давайте проверим, все ли работает корректно. Выполним уже знакомую нам команду для выборки всех записей из таблицы women:
Мы видим список, порядок сортировки которого определен в классе Meta класса модели Women. Если нужно отобрать не все записи, а лишь некоторые из них, то можно использовать синтаксис срезов, чтобы Django указать сделать это, например, так:
Получим первые пять записей. Вы можете подумать, что здесь просто берется срез из полученного списка записей на уровне языка Python. Но это не так. В действительности, отбор происходит на уровне SQL-запроса. И если выполнить команду:
то в конце последнего запроса увидим фрагмент «LIMIT 5». А при выполнении такой команды:
получим в запросе «LIMIT 5 OFFSET 3». То есть, здесь везде делается отбор на уровне SQL-запросов, что очень эффективно.
Далее, если нужно поменять порядок и отсортировать записи по определенному полю, то используется метод order_by():
В данном случае мы сортируем записи по их идентификатору. Почему здесь используется имя поля pk, а не id? Как я уже отмечал, по соглашению в Django имя pk по умолчанию используется для обращения к первичному ключу, так как это поле в таблице мы могли бы назвать не id, а как то иначе. Чтобы сделать его название универсальным на уровне ORM, Django и использует это имя pk.
Сразу же здесь напомню, что символ минус перед именем поля означает обратный порядок сортировки:
Также порядок (на противоположный) можно менять с помощью метода reverse():
Он удобен, если формируется некая выборка и нам нужно просто поменять порядок следования записей на противоположный. Здесь уже нет необходимости указывать конкретное поле, а просто записать reverse().
На одном из прошлых занятий я вам приводил пример метода filter() для выбора нескольких записей по некоторому условию:
и метод get() для получения строго одной записи:
Но не сказал, что filter() всегда возвращает записи в виде списка, а get() – в виде одного объекта (экземпляра модели). Обычно, метод get() необходим для выбора строго одной записи и для этого использую или поле pk, или поле slug (они оба создаются как уникальные).
Давайте теперь посмотрим, как происходит обработка связанных данных. Сохраним объект какой-либо записи в переменной w:
Давайте, для примера, выполним строчку, чтобы убедиться, что cat – это действительно ссылка на экземпляр класса Category:
Соответственно, для получения связанных данных о категории, можно использовать этот объект, например, так:
получим название категории. Причем, получение конкретных связанных данных происходит только в момент обращения к ним. В данном случае в строчке w.cat Django автоматически сгенерировал запрос к таблице category и взял запись с Таким образом, мы увидели как вторичная модель Women связывается с первичной моделью Category и получает соответствующие данные.
Но можно сделать и наоборот, используя первичную модель Category получить все связанные с ней посты из вторичной модели Women. Для этого у любой первичной модели по умолчанию автоматически создается специальное свойство (объект) с именем:
И уже с его помощью можно выбирать связанные записи. Давайте сделаем это. Сначала прочитаем запись из таблицы category, например, с >
чтобы получить ссылку на объект записи первичной модели. А, затем, используя механизм обратного связывания, прочитаем все связанные с данной категорией посты:
Если мы хотим переименовать атрибут women_set, то для этого в классе ForeignKey вторичной модели Women следует дополнительно прописать параметр:
Здесь get_posts – это новое имя атрибута для обратного связывания. Чтобы изменения вступили в силу, нужно выйти из оболочки Django, снова зайти, импортировать модели, прочитать категорию и отобразить связанные посты с уже новым именем атрибута:
Разумеется, вместо метода all() мы можем использовать и другие уже известные нам методы, например, filter():
(Убираем параметр related_name и перезапускаем оболочку).
Фильтры полей
Рассмотрим еще несколько интересных примеров lookups. Фильтр contains позволяет находить строки по их фрагменту, учитывая регистр букв. Например, вот такая команда:
выдаст список всех женщин, в заголовке у которых присутствует фрагмент «ли». Опять же, на уровне SQL-запроса это делается с помощью фрагмента:
«WHERE title LIKE ‘%ли%’»
Похожий фильтр icontains осуществляет поиск без учета регистра символов. Однако, если мы запишем вот такую команду:
то получим пустой список. Почему? Дело в том, что СУБД SQLite не поддерживает регистронезависимый поиск для русских символов (вообще, для всех не ASCII-символов), поэтому получаем пустой список. Другие СУБД, как правило, отрабатывают все это корректно. В случае с латинскими символами в SQLite поиск всегда проходит как регистронезависимый.
Следующий полезный фильтр in позволяет указывать через список выбираемые записи по значениям. Например, выберем записи с id равными 2, 5, 11, 12:
Если по условию нужно отработать сразу несколько фильтров, то они указываются через запятую:
Теперь мы видим всего две записи, так как посты с id 11 и 12 отмечены как неопубликованные. Причем, обратите внимание, указывая два критерия через запятую, на уровне SQL-запросов формируется связка через AND (логическое И):
WHERE («women_women».»is_published» AND «women_women».»id» IN (2, 5, 11, 12))
то есть, запись выбирается, если оба критерия срабатывают одновременно. Чтобы определять условия через OR (логическое ИЛИ) используется специальный класс Q. Речь о нем пойдет дальше.
Также мы можем использовать фильтр in и для внешнего ключа, причем, записать его в двух видах:
Результат будет один и тот же. Или, вместо указания конкретных id записей категорий, можно вначале прочитать нужные рубрики, например, все:
а, затем, подставить их вместо списка:
По аналогии используются и все остальные фильтры фреймворка Django.
Использование класса Q
— логическое НЕ (приоритет 1).
Давайте посмотрим, как это все работает. Вначале его нужно импортировать:
Теперь, смотрите, если выполнить вот такой запрос:
то на выходе получим пустой список, т.к. все записи с id =5 или cat_id=2.
Вот так можно использовать класс Q для описания запросов с использованием операторов &, | и
. И всегда помните о приоритетах операций: сначала выполняется НЕ, затем, И и в последнюю очередь ИЛИ.
Методы выбора записей
В ORM Django есть несколько полезных методов для быстрого получения определенных записей из таблицы. Например, чтобы взять первую запись из выборки, используется метод first():
Мы в этом можем убедиться, если выведем все посты:
То есть, берется первая запись в соответствии с порядком сортировки модели. Мы можем поменять этот порядок и с помощью этого же метода first() выбирать разные записи, например, так:
Или же воспользоваться методом last() для выбора последней записи из набора:
Методы latest и earliest
Для чего могут понадобиться такие методы? Например, сделана выборка с сортировкой по какому-либо другому полю (не time_update) и из этой выборки нужно получить самую раннюю или самую позднюю запись:
Методы get_previous_by_, get_next_by_
Если нужно выбрать предыдущую или следующую запись относительно текущей, то в ORM для этого существует два специальных метода, которые выбирают записи опять же по указанному полю с датой и временем. Например, мы выбираем некую запись с pk=7:
Тогда, для получения предыдущей записи относительно текущей, можно записать:
Здесь суффикс time_update – это название поля, по которому определяется предыдущая запись. То есть, здесь используется не порядок следования записей в выборке, а временное поле. И уже по нему смотрится предыдущая или следующая запись:
Дополнительно в этих методах можно указывать условия выборки следующей или предыдущей записи. Например:
выбирается следующая запись с id больше 10.
Методы exists и count
Они часто используются для реализации простых проверок до выполнения других, более сложных запросов.
Давайте я добавлю в таблицу Category еще одну рубрику «Спортсменки» и эта рубрика пока у нас пуста, то есть, нет ни одной записи с ней связанной. Как вы уже догадались, мы сейчас протестируем метод exists(), который возвращает True, если записи есть и False – в противном случае.
Увидим False, а для второй категории:
получим значение True. Соответственно, вызывая второй метод, можем получить число записей:
То есть, методы exists() и count() применяются к любой выборке.
Выборка записей по полям связанных моделей
В одном из прошлых занятий мы с вами выбирали все записи из модели Women для определенной категории, используя слаг:
Как это работает? В действительности, вот этот параметр cat__slug сформирован по следующему правилу:
То есть, здесь мы обращаемся к первичной модели через атрибут cat, который прописан во вторичной модели Women, а затем, через два подчеркивания указываем имя поля тоже первичной модели, по которому отбираются записи уже вторичной модели. И на выходе получаем список постов для актрис.
Этот синтаксис немного похож на использование фильтра in:
Только здесь вместо указания списка идентификаторов рубрик, используется слаг с определенным названием. Во всем остальном принцип работы идентичен.
Или, можно взять другое поле (name) и по нему произвести выборку записей из вторичной модели:
Мало того, после имени поля можно дополнительно указывать различные фильтры. Например, выберем записи, у которых имя категории содержит букву ‘ы’:
Конечно, это несколько странный, искусственный пример, но он хорошо показывает принцип использования фильтров для полей первичной модели. Если уточнить этот фильтр:
то получим уже записи только по певицам. Или сделать наоборот, выбрать все категории, которые связаны с записями вторичной модели Women, содержащие в заголовке фрагмент строки «ли»:
Обратите внимание, на выходе получим набор из нескольких повторяющихся категорий, каждая из которых соответствует определенной записи из модели Women. Если нужно отобрать только уникальные записи (категории), то дополнительно следует указать метод distinct():
Агрегирующие функции
Далее, мы с вами рассмотрим несколько агрегирующих методов. С одним из них, мы в принципе, уже знакомы – это метод count(), который подсчитывает число записей. В самом простом случае, с его помощью можно определить число записей в таблице women:
Подробно о том, что такое агрегация на уровне SQL-запросов, я уже рассказывал на занятии по SQLite и, если вы мало знакомы с этой информацией, то дополнительно советую посмотреть и это видео:
Остальные агрегирующие команды обычно прописываются в специальном методе aggregate(), например:
Но, чтобы ими воспользоваться, нужно их импортировать:
и после этого предыдущая команда выдаст наименьшее значение для поля cat_id. Также можно прописывать сразу несколько команд:
На выходе получим следующий словарь:
Если по каким-либо причинам стандартные ключи нам не подходят, и мы бы хотели их поменять, то делается это так:
С агрегирующими значениями можно выполнять различные математические операции, например:
По аналогии используются все остальные агрегирующие операции:
Здесь агрегация выполняется не для всех записей, а только для тех, у которых id больше 4.
Метод values
Во всех наших примерах выше, при выборке записей автоматически возвращались все поля. Если это была таблица women, то получали девять полей от id до cat_id. Но часто этого не требуется и достаточно ограничится несколькими нужными полями. Кроме того, такое ограничение положительно сказывается на скорости обращения к БД.
Итак, для указания нужных полей в выборке, используется метод values() с указанием названий полей, например, так:
На выходе имеем запись только с двумя полями. Причем, смотрите, если мы укажем взять данные из связанной таблицы для имени категории:
то Django сформирует запрос с использованием оператора JOIN SQL-запроса. Если посмотреть коллекцию:
то увидим следующее:
SELECT «women_women».»title», «women_category».»name» FROM «women_women» INNER JOIN «women_category» ON («women_women».»cat_id» = «women_category».»id») WHERE «women_women».»id» = 1 LIMIT 21
Благодаря такой конструкции одним запросом выбираются все нужные данные. Или, даже так:
При выполнении этой строчки пока ни один SQL-запрос выполнен не был, т.к. запросы в Django «ленивые», обращение к БД происходит только в момент получения данных. Но, если вывести список постов:
то увидим, что для этой операции также был сделан всего один запрос. То есть, Django достаточно хорошо оптимизирует процесс обращения к БД.
Группировка записей и агрегирование через метод annotate
Часто вызов агрегирующих функций применяется не ко всем записям, а к группам, сформированным по определенному полю. Например, в таблице Women можно сгруппировать записи по cat_id и получим две независимые группы записей. Затем, к каждой группе применить агрегацию и получить искомые значения.
В качестве примера, давайте подсчитаем число постов для каждой группы категорий. Для этого запишем такую команду:
Ее действие графически можно представить так:
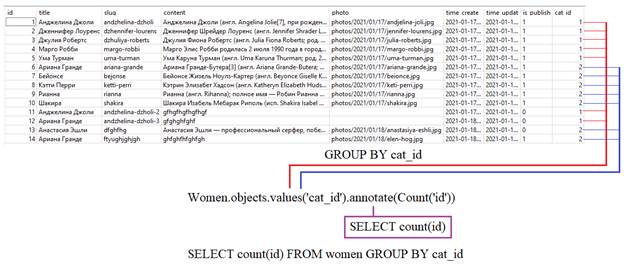
То есть, здесь группировка автоматически выполняется по единственному полю, которое мы выбираем из таблицы. Однако, выполняя ее, мы не видим ожидаемого результата. Почему? Если посмотреть последний SQL-запрос:
то увидим, что группировка также выполняется по полям title и time_create. Это связано с тем, что в модели Women во вложенном классе Meta прописана сортировка по этим полям:
Поставим эту строчку в комментарий, выйдем из оболочки Django, снова зайдем, импортируем необходимые модули:
и повторим команду:
Теперь видим две группы и для каждой подсчитано число статей. Мы можем изменить имя параметра id__count, скажем, на total, указав этот именной параметр:
Вот так можно группировать записи и вызывать для них с помощью метода annotate() нужную агрегатную функцию.
Вообще, метод annotate() используется для вызова агрегирующих функций в пределах групп. Если не указывать никаких полей для группировки:
То получим просто все записи (так как группировка будет выполняться для всех полей). А вот если записать наоборот:
то также получим все рубрики, но в каждом объекте списка будет атрибут:
содержащий число записей для текущей рубрики. Мало того, далее, мы можем прописывать другие методы, для отбора этих рубрик по значению агрегатной функции:
Здесь отбираются все категории, в которых более нуля записей, то есть, есть хотя бы одна запись.
Класс F
Во всех предыдущих примерах мы делали выборки, указывая конкретные значения полей, например, так:
Но что если вместо 2 нужно прописать значение другого поля таблицы? Просто указать его не получится, например, такая запись:
приведет к ошибке. Для этого нужно использовать специальный класс F, позволяющий нам выполнять подобные операции. Сначала мы его импортируем:
И, далее, вместо двойки запишем класс F, допустим, с полем cat_id:
Получим все записи, кроме первой (с А SQL-запрос будет иметь вид:
SELECT … FROM «women_women» WHERE «women_women».»id» > «women_women».»cat_id»
Здесь условие «id > cat_id» как раз и было сформировано благодаря использованию F класса.
Конечно, это такой искусственный пример, демонстрирующий работу F-класса. Часто подобные операции приходится делать, когда нужно увеличить, например, счетчик просмотра страниц. Если предположить, что в нашей таблице women есть поле views для числа просмотров, то при каждом посещении страницы, мы могли бы увеличивать его значение на 1, следующим образом:
При посещении страницы со слагом ‘bejonse’ произойдет увеличение ее считчика на 1.
Или, бывает удобно делать так. Сначала статья читается из таблицы (мы ее так и так должны отображать на HTML-странице):
А, затем, происходит изменение счетчика:
После сохранения, новое значение будет записано в таблицу БД.
У вас здесь может возникнуть вопрос: а почему бы нам в данном случае не использовать операцию инкремента:
Скорее всего, так тоже сработает, но в документации по Django такой подход не рекомендуется. Здесь могут возникать неопределенности при одновременном получении одной и той же страницы разными пользователями. Тогда значение views будет увеличено только один раз, хотя просмотров было два. Класс F решает подобные коллизии.
Организация вычислений на уровне СУБД
Фреймворк Django содержит набор функций, позволяющие выполнять вычисления, связанные с полями таблицы, на стороне СУБД. Полный их список можно посмотреть по ссылке:
Фактически, здесь приведены обертки над функциями, которые выполняются СУБД. Этих функций достаточно много. Это и функции работы со строками, датой, математические функции и так далее. Использование этих функций является рекомендуемой практикой, т.к. СУБД оптимизировано для их выполнения. Конечно, все имеет свои разумные пределы и нужно лишь по необходимости прибегать к этому функционалу.
Давайте для примера рассмотрим использование функции Length для вычисления длины строки. Первым делом нам нужно ее импортировать:
И, затем, аннотируем новое вычисляемое поле, например, для заголовков статей:
В результате, на ряду со всеми стандартными полями, получим дополнительное поле len:
По аналогии используются все остальные подобные функции.
Raw SQL
В случаях, когда уровня ORM Django недостаточно, всегда можно перейти на уровень SQL-запросов и записать свой для конкретной используемой СУБД. Необходимость в этом возникает крайне редко, но, тем не менее, нужно знать о такой возможности.
В простейшем варианте выполнить непосредственно SQL-запрос можно через метод:
На выходе получаем объект RawQuerySet, содержащий данные выборки. Давайте выведем ее в консоль через цикл for:
Как видите, все достаточно просто. Причем, абсолютно тот же самый результат увидим и при использовании класса модели Category:
Здесь модель не имеет особого значения, мы с ее помощью просто обращаемся к менеджеру записей (objects), чтобы выполнить метод raw() для запуска SQL-запроса. Хотя сами объекты в списке w будут являться уже экземплярами класса Category. Поэтому, для обращения к таблице women лучше использовать модель Women.
Вместо представленного простейшего запроса, можно записывать и другие, самые разные, гораздо более сложные. Если вы не знакомы с SQL-запросами, то в качестве базового материала можно посмотреть курс по SQLite, где я затрагиваю эту тему:
Однако, метод raw() имеет несколько нюансов в своей работе. Первый из них – это «ленивое» исполнение запроса, то есть, отложенная загрузка информации до момента первого обращения к ней. Например, при выполнении команды:
никакого SQL-запроса выполнено не будет. До тех пор, пока мы не попытаемся что-либо прочитать из переменной w:
увидим один выполненный запрос:
Второй нюанс связан с тем, что при выборке конкретных полей в команде SELECT мы обязаны всегда указывать поле id, например, так:
Без id метод raw() выдаст исключение. Также, смотрите, несмотря на то, что мы указали в SELECT всего два поля, мы, тем не менее, через ссылку w можем обратиться к любому другому, например, так:
Здесь сработал механизм отложенной загрузки полей и при обращении к конкретному, не указанному ранее полю, происходит дополнительное обращение к БД для его получения. И, действительно, в списке запросов мы видим это:
SELECT «women_women».»id», «women_women».»is_published» FROM «women_women» WHERE «women_women».»id» = 1
Как вы понимаете, это не лучшая практика и такого нужно избегать. Если у вас много постов и вы для каждого поля is_published будете так выбирать данные, то Django сгенерирует множество одиночных SQL-запросов для их чтения. Это может заметно и необоснованно нагрузить используемую СУБД.
Следующий момент – это возможность передавать параметры в SQL-запрос. Например, если мы хотим выбрать запись по ее слагу, то нужно написать что-то вроде:
Но здесь вместо ‘shakira’, обычно, используется некий параметр, в котором и хранится значение слага. Конечно, первое что приходит на ум, это объявить некую переменную:
и напрямую передать ее в SQL-запрос:
Однако, это прямой путь к SQL-инъекциям, когда злоумышленник вместо слага запишет фрагмент SQL-запроса и прочитает данные из БД. Поэтому правильно будет использовать механизм параметров в таких raw-запросах:
Соответственно, в списке параметров можно указывать множество переменных и прописывать их в SQL-запросе.
На этом мы завершим обзор этой объемной темы – ORM Django. Конечно, здесь я вам показывал лишь принцип использовать различных методов и рассказывал о нюансах их работы. Объять этот материал целиком – слишком амбициозная задача, да и напоминать такие занятия будут справочное руководство. В конце концов, для этого есть документация – наше все. Без нее при изучении и дальнейшем использовании Django – никуда. Ссылки на нее будут под этим видео.
Видео по теме


#2. Модель MTV. Маршрутизация. Функции представления

#3. Маршрутизация, обработка исключений запросов, перенаправления

#4. Определение моделей. Миграции: создание и выполнение


#6. Шаблоны (templates). Начало

#7. Подключение статических файлов. Фильтры шаблонов

#8. Формирование URL-адресов в шаблонах

#9. Создание связей между моделями через класс ForeignKey

#10. Начинаем работу с админ-панелью

#11. Пользовательские теги шаблонов

#12. Добавляем слаги (slug) к URL-адресам

#13. Использование форм, не связанных с моделями

#14. Формы, связанные с моделями. Пользовательские валидаторы

#15. Классы представлений: ListView, DetailView, CreateView

#16. Основы ORM Django за час


#18. Постраничная навигация (пагинация)

#19. Регистрация пользователей на сайте

#20. Делаем авторизацию пользователей на сайте

#21. Оптимизация сайта с Django Debug Toolbar

#22. Включаем кэширование данных

#23. Использование капчи captcha

#24. Тонкая настройка админ панели

#25. Начинаем развертывание Django-сайта на хостинге

#26. Завершаем развертывание Django-сайта на хостинге
© 2021 Частичное или полное копирование информации с данного сайта для распространения на других ресурсах, в том числе и бумажных, строго запрещено. Все тексты и изображения являются собственностью сайта



