Что такое URL-адрес?
Данная статья описывает Единый локатор ресурсов или Uniform Resource Locators (URLs), объясняет, что это такое, и описывает его структуру.
Введение
Наряду с понятиями гипертекста и протокола HTTP, понятие URL является одной из основных концепций Всемирной паутины. Это механизм, используемый браузерами для получения любого опубликованного во Всемирной сети ресурса.
URL обозначает Uniform Resource Locator. URL это лишь адрес, который выдан уникальному ресурсу в интернете. В теории, каждый корректный URL ведёт на уникальный ресурс. Такими ресурсами могут быть HTML-страница, CSS-файл, изображение и т.д. На практике, существуют некоторые исключения, когда, например, URL ведёт на ресурс, который больше не существует или который был перемещён. Поскольку ресурс, доступный по URL, а также сам URL обрабатываются веб-сервером, его владелец должен внимательно следить за размещаемыми ресурсами и связанными с ними URL.
Активное обучение
Подробная информация
Основы: анатомия URL
Вот несколько примеров URL:
Каждый из этих URLs могут быть напечатаны в адресной строке браузера, чтобы заставить его загрузить связанную страницу (ресурс).
Как использовать URL
Каждый URL может быть напечатан напрямую в адресной строке браузера, чтобы сразу получить запрошенный ресурс. Но это только вершина айсберга!
Язык HTML — который будет обсуждать позже (en-US) — позволяет активно использовать URL для:

Содержание
Что такое URL и как его настроить
Стандартный URL сайта состоит из нескольких элементов:

Протокол передает браузеру информацию о том, как взаимодействовать с сервером. Именно благодаря ему ссылки могут работать.
Адрес с установленным сетевым протоколом HTTPS выглядит следующим образом: https://ru.wikipedia.org/wiki/Википедия.

Эта часть URL важна при оптимизации, но главную роль играет следующий элемент.

Поисковые системы отлично воспринимают даже сложные URL. Но для выдачи и пользователей важно, чтобы адрес был лаконичным и максимально простым. Гораздо приятнее в адресной строке видеть оптимизированный URL https://ru.wikipedia.org/wiki/Википедия, чем http://www.example.com/index.php?id_145f3.
Влияние URL на SEO
ЧПУ: Что это?

Из примеров становится понятно, что на правильно составленный URL указывает именно путь страницы.
Для настройки ЧПУ получится использовать буквы как латинского алфавита, так и кириллицы.
Преимущества и недостатки ЧПУ
Сайт, где выполнена генерация SEO URL, получает массу преимуществ:
Говоря о том, как прописать URL адрес, стоит сказать и о недостатках ЧПУ:
Как правильно прописывать URL страницы: 15 простых советов

1. Что лучше: подраздел или поддомен?
Лучше при настройке ЧПУ использовать подразделы. Тогда поисковая система автоматически определит их как элементы сайта. Это дает преимущества в SEO. Подразделы в отличие от поддоменов не конкурируют с основным сайтом за ранжирование в выдаче. Кроме того, их лучше использовать, если на источник ссылаются сторонние ресурсы. В системе подразделов ссылки на разделы сайта повышают авторитет вновь созданных страниц.
Динамические ссылки с метками UTM имеют ряд недостатков:
Лучше выбирать статические ссылки. Они сохраняют вид, пока владелец ресурса сам не внесет изменения.

3. Создание логической структуры страниц
Если не позаботиться о логичной структуре сайта заранее, через некоторое время он наполнится множеством конкурирующих адресов. Это мешает пользователям и поисковым системам.
4. Уменьшаем глубину вложенности страниц
Независимо от того, насколько далеко раздел находится от главной страницы сайта, вложенность не должна быть слишком большой. Лучше убирать из адреса упоминания о категориях.

Если ЧПУ уменьшить не получается, стоит скрыть его часть.
5. Важна ли длина URL?
Короткие ссылки выглядят привлекательнее. Длинные имена неудобны при копировании, их невозможно набрать вручную.
6. Как добавить ключевые слова
Наличие ключевых слов положительно влияет на продвижение ресурса. Не стоит добавлять слишком много фраз из семантического ядра. Чтобы ссылка выглядела привлекательно как для поисковиков, так и для пользователей, нужно включать по 1-2 ключевика в адрес. Лучше добавлять запросы из meta-тегов (Title, Description).
Ключевая фраза в адресе полезна при Email-рассылке. По ней получатель сразу видит, стоит ли переходить по ссылке.
7. Лучше не использовать заглавные буквы
На учет заглавных букв в URL влияет система хостинга и CMS. Зачастую они воспринимают страницы Example.html и example.html как разные. Поэтому при вводе адреса с неправильным регистром выдается ошибка 404.
8. Дефис, нижнее подчеркивание и пробел: что выбрать для URL?
При указании в адресе более 1 слова стоит для разделения брать дефисы. Google нижние подчеркивания воспринимает нормально, для выдачи в Яндекс их брать не стоит.
Пробелы не воспринимаются поисковыми системами и заменяются на «%20».
9. Какой алфавит подходит: кириллица или латиница?
Поисковые системы научились распознавать кириллицу. Проблемы возникают при копировании доменов, состоящих из русских букв. Тогда слова заменяются на набор символов.
10. Предлоги и специальные символы при настройке ЧПУ
При использовании в meta-тегах предлогов и других стоп-слов не стоит бояться употреблять их в ЧПУ. Но нужно придерживаться правила: эти элементы лучше не использовать, если они не помогают облегчить читабельность адресов.
11. Минусы хэшей и хэштегов в URL
Поисковики пропускают часть адреса, идущую после символа «#». Хэштеги стоит добавлять только для облегчения навигации и в пунктах меню на landing page. В остальных случаях «#» в URL включать не нужно.
12. Канонические ссылки

Так называют приоритетные адреса страниц, предотвращающий их дублирование. При появлении копии раздела на сайте понижается рейтинг у канонической и повторной ссылки. Справиться с проблемой получится при добавлении атрибута. Он укажет поисковикам, какой элемент основной.
13. Настраиваем 301 редирект
Это нужно сделать при:
Переадресация указывает на то, что страница окончательно перемещена на другой адрес.
14. Даты в адресе страницы
15. Карты Sitemap.xml
Как правильно написать URL сайта в Яндекс и Google

Для ранжирования в поисковых системах владельцам сайтов стоит учитывать советы от Яндекс и Google:
Резюме
Грамотный URL не сможет полностью решить проблему. Важно комплексно подходить к поисковой оптимизации.
История URL, часть 2: путь, фрагмент, запрос и авторизация
URL’ы не должны были стать тем, чем стали: мудрёным способом идентифицировать сайт в интернете для пользователя. К сожалению, мы не смогли стандартизировать URN, который мог бы стать более полезной системой наименования. Считать, что современная система URL достаточно хороша — это как боготворить командную строку DOS и говорить, что все люди просто должны научиться пользоваться командной строкой. Оконные интерфейсы были придуманы, чтобы пользоваться компьютерами стало проще, и чтобы сделать их популярнее. Такие же мысли должны привести нас к более хорошему методу определения сайтов в Вебе.
Есть несколько вариантов определения слова «интернет». Один из них — это система компьютеров, соединенных через компьютерную сеть. Такая версия интернета появилась в 1969 году с созданием ARPANET. Почта, файлы и чат работали в этой сети еще до создания HTTP, HTML и веб-браузера.
В 1992 году Тим Бернерс-Ли создал три штуки, благодаря которым родилось то, что мы считаем интернетом: протокол HTTP, HTML и URL. Его целью было воплотить понятие гипертекста в реальности. Гипертекст, в двух словах — это возможность создавать документы, которые ссылаются друг на друга. В те годы идея гипертекста считалась панацеей из научной фантастики, заодно с гипермедиа, и любыми другими словами с приставкой «гипер».
Ключевым требованием гипертекста была возможность ссылаться из одного документа на другой. В то время для хранения документов использовалась куча форматов, а доступ осуществлялся по протоколу вроде Gopher или FTP. Тиму нужен был надежный способ ссылаться на файл, так, чтобы в ссылке был закодирован протокол, хост в интернете и местонахождение на этом хосте. Этим способом стал URL, впервые официально задокументированный в RFC в 1994 году.
В начальной презентации World-Wide Web в марте 1992 Тим Бернерс-Ли описал его как «универсальный идентификатор документов» (Universal Document Identifier или UDI). Множество других форматов также рассматривались в качестве такого идентификатора:
Этот документ также объясняет, почему пробелы должны кодироваться в URL (%20):
В UDI избегают использование пробелов: пробелы — это запрещенные символы. Это сделано потому, что часто появляются лишние пробелы когда строки оборачиваются системами вроде mail, или из-за обычной необходимости выровнять ширину колонки, а так же из-за преобразования различных видов пробелов во время конвертации кодов символов и при передаче текста от приложения к приложению.
Важно понимать, что URL был просто сокращенным способом обратиться к комбинации схемы, домена, порта, учетных данных и пути, которые ранее нужно было определять из контекста для каждой из систем коммуникации.
Эта позволило обращаться к разным системам из гипертекста, но сегодня, возможно, такая форма уже избыточна, так как практически все передается через HTTP. В 1996 браузеры уже добавляли http:// и www. за пользователей автоматически (что делает рекламу с этими кусками URL по-настоящему бессмысленной).
Я не считаю, что вопрос «могут ли люди понять значение URL» имеет смысл. Я просто думаю, что морально неприемлемо заставлять бабушку или дедушку вникать в то, что в конечном итоге является нормами файловой системы UNIX.
Слэш, отделяющий путь в URL, знаком любому, кто использовал компьютер за последние пятьдесят лет. Сама иерархическая файловая система была представлена в системе MULTICS. Ее создатель в свою очередь ссылается на двухчасовую беседу с Альбертом Эйнштейном, которая состоялась в 1952 году.
В MULTICS использовался символ «больше» ( > ) для разделения компонентов файлового пути. Например:
Это совершенно логично, но, к сожалению, ребята из Unix решили использовать > для обозначения перенаправления, а для разделения пути взяли слэш ( / ).
Битые ссылки в решениях Верховного Суда
Неправильно. Теперь я четко вижу, что мы не согласны друг с другом. Вы и я.
Как человек, я хочу сохранить за собой право использовать разные критерии для разных целей. Я хочу иметь возможность давать имена самим работам, и конкретным переводам и конкретным версиям. Я хочу более богатого мира чем тот, что вы предлагаете. Я не хочу ограничивать себя вашей двухуровневой системой «документов» и «вариантов».
Половины URL-адресов, на которые ссылается Верховный Суд США, уже не существует. Если вы читаете академическую работу в 2011 году, и написана она была в 2001 году, то с большой вероятностью любой URL там будет нерабочим.
В 1993 году многие страстно верили, что URL отомрет, и на замену ему придет URN. Uniform Resource Name — это постоянная ссылка на любой фрагмент, который, в отличие от URL, никогда не изменится и не сломается. Тим Бернерс-Ли описал его как «срочную необходимость» еще в 1991.
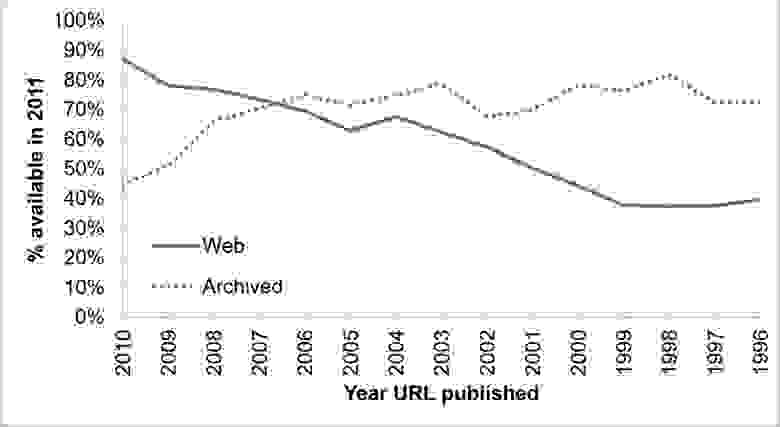
В 1996 Киф Шэйфер и несколько других специалистов предложили решение проблемы поломанных URL. Ссылка на это решение сейчас не работает. Рой Филдинг опубликовал предложение реализации в июле 1995 года. Ссылка тоже поломана.
Учитывая мощность поисковых движков, возможно, что лучшим на сегодня форматом URN могла бы стать простая возможность файлов ссылаться на свой прошлый URL. Мы можем позволить поисковым движкам индексировать эту информацию, и ссылаться на наши страницы корректно:
Параметры запроса
Формат application/x-www-form-urlencoded — это аномальный монстр во многих отношениях, результат многих лет случайностей реализаций и компромиссов, которые привели к необходимому для интероперабельности набору требований. Но это точно не образец хорошей архитектуры.
Изначально эта часть URL использовалась исключительно для поиска индексов. Веб изначально был создан (и его финансирование было основано на этом) как метод совместной работы физиков, занимающихся элементарными частицами. Это не означает, что Тим Бернерс-Ли не знал, что он создает систему коммуникации с по-настоящему широким применением. Он не добавлял поддержку таблиц несколько лет, не смотря на то, что таблицы, наверное, пригодились бы физикам.
Запрос представлял собой набор ключевых слов, отделенных друг от друга плюсами ( + ):
В том предложении использовался символ плюса для отделения компонентов запроса, но в остальном все напоминает современный GET-запрос:
Далеко не все одобрили это. Некоторые считали, что нужен способ указать поддержку поиска по ту сторону ссылки:
Тим Бернерс-Ли думал, что нужен способ определения строго типизированных запросов:
Изучая прошлое, готов с определенной долей уверенности сказать: я рад, что победило более общее решение.
Работа над тегом началась в январе 1993 года, она основывалась на более старом типе SGML. Было решено (пожалуй, к сожалению), что тегу
Дополнительные предложения использовали @ вместо = для разделения компонентов запроса:
Марк Андриссен предложил метод, основанный на том, что он уже реализовал в Mosaic:
Всего два месяца спустя Mosaic добавил поддержку method=POST в формы, и так родились современные HTML-формы.
Фрагменты
Часть URL после символа ‘#’ известна как «фрагмент» (fragment). Фрагменты были частью URL со времен первой спецификации, они использовались для создания ссылки на конкретное место на загруженной странице. Например, если у меня есть якорь на сайте:
Я могу сделать на него ссылку:
Эта концепция постепенно была расширена до всех элементов (а не только якорей), и перешла на атрибут id вместо name :
Тим Бернерс-Ли решил использовать этот символ, основываясь на связи с форматом почтовых адресов в США (не смотря на то, что сам Тим — британец). По его словам:
Оказывается, первичная система гипертекста, созданная Дугласом Энгельбартом, также использовала «#» для таких целей. Это может быть совпадением или случайным «заимствованием идеи».
Фрагменты специально не включаются в HTTP-запросы, то есть они живут исключительно в браузере. Такая концепция оказалась ценной, когда пришло время реализовывать клиентскую навигацию (до изобретения pushState). Фрагменты также были очень полезными, когда пришло время задуматься о сохранении состояния в URL без отправки на сервер. Что это значит? Давайте разберемся:
Кротовые холмики и горы
Есть целый стандарт, такой же мерзкий как SGML, созданный для передачи электронных данных, другими словами — для форм и отправки форм. Единственное, что мне известно: он выглядит как фортран задом наперед без пробелов.
Есть ощущение, разделяемое многими, что организации, отвечающие за стандарты интернета ничего особо не делали с момента окончательного принятия HTTP 1.1. и HTML 4.01 в 2002 до тех пор, пока HTML 5 не стал по-настоящему популярным. Этот период также известен (только для меня) как Темный Век XHTML. В реальности люди, занимающиеся стандартами, были безумно заняты. Просто они занимались тем, что в итоге оказалось не слишком ценным.
Одним из направлений было создание Семантического Веба. Была мечта: создать Фреймворк Описания Ресурсов (Resource Description Framework). (прим. ред.: бегите от любой команды, которая хочет сделать фреймворк). Такой фреймворк позволял бы универсально описывать мета-информацию о содержании. Например, вместо того, чтобы делать красивую веб-страницу про мой Корвет Стингрэй, я бы сделал RDF-документ с описанием размеров, цвета и количества штрафов за превышение скорости, которые мне выписали за все время езды.
Это, конечно, совсем не плохая идея. Но формат был основан на XML, и это большая проблема курицы и яйца: нужно задокументировать весь мир, и нужны браузеры, которые умеют делать полезные штуки с этой документацией.
Но эта идея хотя бы родила условия для философских споров. Один из лучших подобных споров длился как минимум десять лет, он известен под искусным кодовым именем ‘httpRange-14’.
Целью httpRange-14 было ответить на фундаментальный вопрос «чем является URL?». Всегда ли URL ссылается на документ или он может ссылаться на все, что угодно? Может ли URL ссылаться на мою машину?
Они не пытались ответить на этот вопрос хоть сколько-нибудь удовлетворительно. Вместо этого они фокусировались на том, как и когда можно использовать редирект 303 чтобы сообщить пользователю, что по ссылке нет документа, и перенаправить его туда, где документ есть. И на том, когда можно использовать фрагменты (часть после ‘#’), чтобы направлять пользователей на связанные данные.
Прагматичному современному человеку эти вопросы могут показаться смешными. Многие из нас привыкли, что если URL получается использовать для чего-то, то значит его можно использовать для этого. И люди или будут использовать ваш продукт, или нет.
Но Семантический Веб заботился только о семантике.
Эта конкретная тема обсуждалась 1 июля 2002 года, 15 июля 2002 года, 22 июля 2002 года, 29 июля 2002 года, 16 сентября 2002 года, и как минимум еще 20 раз в течение 2005 года. Обсуждение закончилось благодаря тому самому ‘решению httpRange-14’ в 2005 году, и к нему вернулись снова из-за жалоб в 2007 и 2011, а запрос новых решений был открыт в 2012. Вопрос долго обсуждался группой pedantic web, у которой очень подходящее название. Единственное, чего так и не произошло — никакие из этих семантических данных так и не были добавлены в веб в какой-либо URL.
Авторизация
Как вы знаете, в URL можно включить логин и пароль:
Браузер кодирует эти данные в формат Base64 и посылает в виде заголовка:
Base64 используется только для того, чтобы можно было передавать запрещенные в заголовках символы. Он никак не скрывает логин и пароль.
Это было проблемой, особенно до распространения SSL. Любой человек, который следит за вашим соединением, мог с легкостью увидеть пароль. Предлагали много альтернатив, в том числе Kerberos, который был и остается популярным протоколом безопасности.
Как и с другими примерами нашей истории, простую базовую авторизацию было проще всего реализовать разработчикам браузеров (Mosaic). Так базовая авторизация стала первым и единственным решением до тех пор, пока разработчики не получили инструменты для создания собственных систем аутентификации.
Веб-приложение
В мире веб-приложений странно представить, что основой веба является гиперссылка. Это метод соединения одного документа с другим, который со временем оброс стилями, возможностью запуска кода, сессиями, аутентификацией и в конечном итоге стал общей социальной компьютерной системой, которую пытались (безуспешно) создать так много исследователей 70-х годов.
Вывод такой же, как и у любого современного проекта или стартапа: только распространение имеет смысл. Если вы сделали что-то, что люди используют, даже если это некачественный продукт, то они помогут вам превратить его в то, чего хотят сами. И с другой стороны, конечно, если никто не пользуется продуктом, то его техническое совершенство не имеет значения. Существует бесчисленное количество инструментов, на которые ушли миллионы часов работы, но ими пользуется ровно ноль человек.
Url (урл) адрес что это такое простыми словами, как он выглядит и где находится

Приветствую Вас на страницах блога: My-busines.ru. В этой статье мы рассмотрим, что такое адрес сайта, какие они бывают, для чего нужны и как их создать.
Итак, простыми словами, URL адрес (Uniform Resource Locator) – это такой указатель, который говорит о том, где в интернете находится тот или иной сайт. Как правило, он включает в себя имя домена и путь к странице, который, в свою очередь, содержит в себе ее название.
Изобретателем данной технологии является Sir Timothy John «Tim» Berners-Lee. Реализовал идею он в 1990 году, которая, на тот момент, выполняла лишь функцию адреса размещения.
Конечно же данная технология имеет достаточно большой список своих достоинств, но у нее имеется и свой, достаточно существенный недостаток. Он заключается в использовании лишь латинских символов, а также цифр и некоторых других знаков. Допустим, если нужно использовать кириллицу, нужно будет провести процесс перекодировки, который, в свою очередь, выполняется достаточно сложно.
Что это такое и для чего нужен
Исходя из названия и всего вышесказанного можно сказать, что URL адрес служит непосредственно для адресации того или иного сайта. С его помощью можно узнать, где в интернете находится какой-либо ресурс. URL адрес содержит в себе название самого сайта, на который и указывает. Таким образом можно подытожить, что эта технология – очень важный элемент интернета, без которого он был бы запутанной и непонятной паутиной.
Пример того, как выглядит url (урл) адрес
Наглядным примером может послужить вот такая строчка:
Она выводится в окне, которое, в свою очередь, расположено на верхней части страницы. Он состоит из нескольких компонентов, которые образуют специальную структуру, но об этом мы поговорим позднее.
Примерно так выглядят URL адреса всех страницы в интернете. Но нужно знать, что это правильная вариация оформления. Она может быть и неправильной, отличаясь большим количеством непонятных неподготовленному человеку символов.
Структура
Для того, чтобы понять, как устроены URL адреса, нужно рассмотреть подробно их структуру. Для этого давайте еще раз обратимся к нашему сайту, который уже использовали в роли примера Выше. http://www.company.com/blog/page-name. Итак, если смотреть на эту строку, то можно разделить ее на несколько частей, которые выполняют свою функцию, итак:
Где находится
Существует достаточно много разных способов посмотреть URL адрес страницы. Если Вы обычный пользователь, который не особо разбирается в компьютерах, то просто не заморачивайте голову. Нажмите на поле адресной строки, у Вас выделится ссылка. Нажмите сочетание клавиш CTRL + C и скопируйте текст, либо проведите стандартную процедуру по копированию текста. Нажмите по выделенному тексту правой кнопкой мыши и нажмите на параметр «Копировать».
Если Вы более опытный юзер и Вам нужно скопировать URL адрес картинки, то кликните по ней правой кнопкой мыши и выберите пункт «Копировать URL картинки». Но, нужно помнить, что URL адрес имеют не только картинки или сайты, но и файлы. Для того, чтобы узнать и при надобности скопировать URL файла, нужно перейти в загрузки, кликнуть правой кнопкой мыши по интересующему Вас файлу и выбрать параметр «Копировать ссылку на загрузку». Таким образом становится понятно, что процесс стандартного копирования адреса – достаточно легкая процедура, с которой справится даже самые неопытный пользователь интернета.
Как создать URL адрес
Существует небольшая пошаговая инструкция, которая объясняет, как связать ссылку с URL. Итак:
Какие виды бывают
Все указатели, как правило, можно разделить не две больших группы: простые и сложные. В случае использования простой вариации, вся интересующая информация находится непосредственно в самой строке URL адреса, 1 страничка – 1 файл.
Со сложным все обстоит по другому. Они имеют наиболее сложную систему хранения и получения информации, но при этом такие адреса имеют достаточно большой список возможностей, которые невозможно реализовать на простых вариациях сайта. Сложный сайт может состоять из одной страницы, которая имеет совершенно разное содержание. Ярким примером может послужить Yandex-Search. Абсолютно любой вводимый Вами запрос приводит Вас на одну и ту же страницу. Все начинается лишь с момента добавления вопросительного запроса в поисковую строку браузера. Абсолютно все, что располагается после него называется запросом GET формы.
Вывод
Таким образом, подытожив все вышесказанное, можно сказать, что URL адрес – достаточно сложная технология, смотря как ее использовать. А она, как известно, встречается в двух вариациях – в простой и сложной. Соответственно первая достаточно проста в изучении и использовании, а вот со сложной системой надо будет немного попотеть. Ну, отсюда в принципе и соответствующее название.
Если Вы всерьез решили заняться изучением этого вопроса, то нужно еще раз познакомиться со всей важной информацией, а также постараться запомнить ее. Также стоит ознакомиться со всеми преимущества и недостатками той или иной вариации данной технологии, потому что это может достаточно сильно повлиять на Ваш выбор.
В некоторых случаях изучение сложной вариации стоит того, хоть и занимает достаточно большое количество времени (смотря от интенсивности работы). В другом случае, если нужно лишь узнать, где располагается тот самый адрес, то достаточно лишь один раз прочитать и запомнить, чтобы в будущем сэкономить время. То есть становится понятно, что изучение этого вопроса может быть и сложным, и простым, смотря для каких целей он потребуется. Желаем Вам удачи!



