Маршрутизация в Linux: VRF Lite
Типы маршрутов, таблицы маршрутизации и PBR в Linux
Прежде чем понять суть происходящего, познакомимся с некоторыми отличительными чертами сетевого стека Linux.
Первый отличительный момент — это специальные типы маршрутов. Когда ip-пакет приходит с какого-нибудь интерфейса, надо определить, адресован ли он этому хосту, или другому. Определяется это довольно элегантно — просто для адреса назначения ищется нужный маршрут в таблицах маршрутизации. Если пакет попадает на маршрут типа «local», значит он адресован непосредственно хосту, если нет, то значит его надо маршрутизировать дальше (при этом дальнейший маршрут уже известен) или сделать что-то ещё, в зависимости от типа маршрутов.
Имена таблиц хранятся в файле /etc/iproute2/rt_tables. Под номер таблицы отдано 32 бита, но максимальное количество таблиц в данный момент жёстко ограничено числом 256. Как добавлять/удалять/редактировать маршруты можно почитать в мане к ip-route.
Таблица, в которой надо искать маршруты, определяется политиками маршрутизации. Эта технология называется Policy Based Routing — маршрутизация на основе политик. Суть её в том, что основываясь на каких-либо критериях сетевого пакета мы либо выбираем таблицу, в которой надо искать маршрут, либо определяем действие, которое надо выполнить над пакетом. Каждая политика имеет номер (он может быть даже не уникальным), он же определяем приоритет. Просмотр политик осуществляется в порядке возрастания их приоритетов. Новые политики добавляются перед существующими.
Запираем маршруты в таблицу
Теперь небольшой практический пример после скучного введения. Для начала, мы реализуем схему с vrf-lite вручную, а затем уже усложним пример динамической маршрутизацией.
Допустим, у нас есть вот такая схема: 
Задача состоит в том, чтобы изолировать трафик различного «цвета» друг от друга. При этом адресные пространства цветов могут пересекаться, что делает задачу ещё более интересной. Неформально сформулируем цель: сделать так, чтобы пакеты каждого цвета не уходили за пределы своей таблицы маршрутизации и передавались только по интерфейсам своего цвета.
Для этого для каждого цвета создадим свою таблицу маршрутизации, и для удобства дадим им имя. Затем, добавим в таблицы direct-connected маршруты принадлежащих цвету интерфейсов. И в конце, добавим политики маршрутизации, чтобы пакеты использовали только свою таблицу.
Сначала назначаем интерфейсам адреса. При этом подключенные маршруты будут попадать в таблицу main, а локальные и широковещательные — в таблицу local.
Добавляем для удобства имена таблиц маршрутизации.
Добавляем прямые маршруты в соответствующие таблицы. Нужны это для того, чтобы нам были доступны соседние маршрутизаторы.
Добавляем остальные маршруты.
Есть один нюанс: что будет, если пакет одного цвета не находит маршрута в своей таблице? Значит, будет продолжен поиск маршрута в других таблицах, что для нас не очень хорошо. Чтобы «запереть» пакет в пределах своего цвета, мы можем в каждую изолированную таблицу добавить маршрут по-умолчанию (либо юникастовый, либо запрещающий), либо после каждой политики поиска маршрута в пределах цвета добавить запрещающую политику. Сделаем для одного цвета первый вариант, а для другого — второй.
Так же, желательно перенести все маршруты local и broadcast из таблицы local в таблицы соответствующих цветов, чтобы невозможно было обращаться к локальным интерфейсам маршрутизатора из «чужого» цвета. Для этого лучше всего написать какой-нибудь скрипт, чтобы было не так утомительно.
В итоге, наши таблицы маршрутизации и политики будут выглядеть примерно так:
Собранный в GNS3 стенд показал правильность работы схемы. При обращении к чужому цвету, отправитель получает сообщение о недоступности точки назначения, как и было задумано.
На этом пока всё, но продолжение следует. В нём постараюсь рассказать про динамическую маршрутизацию применительно к vrf с помощью демона маршрутизации bird, и обмен маршрутами между таблицами (vrf leaking).
Два провайдера одновременно или Dual ISP with VRF на Cisco | Part 2
Добрый день! На написание этого материала меня вдохновил HunterXXI в своей статье Два провайдера одновременно или Dual ISP with VRF на Cisco. Я заинтересовался, изучил вопрос и применил на практике. Хотел бы поделится своим опытом в реализации Dual ISP на Cisco с реальным использованием одновременно двух ISP и, даже, балансировкой нагрузки.
Демо схема:
Описание:
Все действия выполняются на Cisco 1921 IOS Version 15.5(3)M3 с установленным модулем EHWIC-4ESG.
Оставшиеся физические порты не задействованы, но Вам ничто не мешает их использовать по собственному усмотрению.
Конфигурация VRF
Технология Cisco Express Forwarding (CEF) — должна быть включена для работы VRF.
Настройка VRF для ISP
Обратите внимание, что в конфигурации нет импорта 65000:101 который будет закреплен за VLAN 101. Таким образом виртуальные маршрутизаторы isp1 и isp2 не будут иметь маршрутов в сеть 192.168.101.0/24
Настройка VRF для VLAN
Снова обратите внимание на VRF 101, который не обменивается маршрутами c ISP но обменивается с VRF 100.
На своём опыте я убедился, что название VRF для ISP удобно использовать как isp1 и isp2, название VRF для VLAN должно соответствовать номеру VLAN, всё что идентифицирует VRF — description. Это связано с тем, что если, например, у Вас поменяется один из провайдеров то вся реконфигурация сведется к изменению IP адреса интерфейса и description-а.
Конфигурация интерфейсов
Применять команду ip vrf forwarding на интерфейсе нужно до назначения IP адреса. В противном случае IP адрес будет удалён и его придётся назначать заново.
Конфигурация BGP
Каждый из BGP address-family настраивается отдельно для VRF и перераспределяет подключенные маршруты (redistribute connected). У нас будет два маршрута по умолчанию, один через VRF isp1 и второй через isp2. Параметр maximum-paths 2 позволит импортировать в VRF 100 и 102 оба маршрута по умолчанию.
Это будет выглядеть так:
Маршрутизаторы Cisco автоматически балансируют трафик по маршрутам в одном направлении с одинаковой стоимостью.
В VRF isp1 и isp2 необходимо, помимо redistribute connected, разрешить redistribute static и default-information originate, что позволит передать шлюз по умолчанию в другие VRF. Вы можете заметить, что redistribute static делается через route-map BGP_Filter. Это происходит исключительно из соображений эстетического вида таблиц маршрутизации VRF определенных в локальную сеть, что бы маршруты к 8.8.8.8 и 80.80.80.80 не попадали в таблицы маршрутизации VRF 100 и 102.
Настройка маршрутизации
Приступим к настройке маршрутизации. Одной из особенностей работы с VRF, которая усложняет конфигурацию, является необходимость всё определять в конкретный VRF.
Используя этот route-map и применяя его в VRF для ISP перераспределяться будут только маршруты с тэгом, а остальные останутся только внутри ISP VRF.
Отдельные маршруты к хостам 8.8.8.8 и 80.80.80.80 необходимы для того, что когда сработает track и отключит шлюз по умолчанию у нас осталась возможность совершать проверку доступности этих адресов. Так как мы не присваиваем им тэг они не будут подпадать под route-map и перераспределяться.
Настройка NAT
Для работы NAT необходимо обозначить inside, outside интерфейсы. В качестве outside мы определяем интерфейсы в которые подключены ISP, командой ip nat outside. Все остальные интерфейсы, которые относятся к LAN обозначаем как inside командой ip nat inside.
Необходимо создать два route-map-а в которых определяются интерфейсы isp1 и isp2
Правила NAT необходимо указывать для каждого VRF через каждый ISP. Так как в нашем условии Vlan 101 не имеет доступа к сети Интернет то правила для него указывать нет необходимости, а даже если их указать — работать не будет, потому что нет маршрутизации.
У Cisco есть много разновидностей NAT. В терминологии Cisco, то что мы используем называется Dynamic NAT with Overload или PAT.
Что нужно для того что бы NAT работал?
Таким образом мы указываем, что/во что и включаем трансляцию, то есть выполняем все необходимые требования.
Это настройка простой конфигурации, она очевидна и понятна без дополнительных подробностей.
Правило которое мы применяем в нашей конфигурации уже не так очевидно. Как мы помним, route-map isp1 определяет интерфейс GigabitEthernet0/0. Перефразируя команду получается нечто подобное
Получается нужно транслировать трафик source которого GigabitEthernet0/0?
Для того что бы это понять необходимо погрузится в механизм прохождения пакета внутри маршрутизатора.
Ошибочно можно подумать, что можно делать route-map LAN match interface Vlan100. Применять этот как ip nat inside source route-map LAN и т.д.
Во избежание этой мысли нужно понять, что это правило трансляции срабатывает тогда, когда трафик уже находится на outside интерфейсе и match интерфейса где этого трафика уже нет ни к чему не приведет.
Настройка SLA
Ничего особенного в конфигурации нет, проверятся доступность по ICMP узлов 8.8.8.8 80.80.80.80 и маршрутизаторов провайдера из каждого ISP VRF.
Настройка track
В таблице маршрутизации есть маршрут ip route vrf isp1 0.0.0.0 0.0.0.0 198.51.100.2 tag 100 track 100 который завязан на track 100.
track 1000
Этот объект умолчанию имеет состояние DOWN.
В данной конфигурации этот объект необходим для того, что бы принудительно отключить одного из ISP и не подключать его. Для этого track 1000 нужно добавить в объект 100 или 200. Исходя из boolean and, если один из объектов DOWN то весь объект считается DOWN.
Настройка EEM
EEM — Embedded Event Manager позволяет автоматизировать действия в соответствии с определенными событиями.
В нашем случае, когда один из ISP перестанет работать, он будет исключен из таблицы маршрутизации. Но правила трансляции NAT будут оставаться. Из-за этого, уже установленные пользовательские соединения зависнут до того момента пока трансляции NAT не очистится по тайм-ауту.
Для того, что бы ускорить этот процесс нам необходимо очистить таблицу NAT командой clear ip nat translation * и лучше всего сделать это автоматически.
Если объекты 100 или 200 перейдут в состояние DOWN то будут выполнены команды action по порядку.
tips and tricks
Хочу отметить ещё несколько особенностей работы с VRF.
Например конфигурация NTP:
Из-за использования VRF любые сетевые операции нужно относить к виртуальному маршрутизатору, это связано с тем, что когда Вы настроите эту конфигурацию и выполните show ip route вы не увидите ни одной записи в таблице маршрутизации.
К преимуществам этой конфигурации я хотел бы отнести её гибкость. Можно с легкостью вывести один VLAN через одного ISP, а другой через второго.
К недостаткам, и это вопрос к уважаемой публике, когда отваливается один из ISP то команда clear ip nat translations * обрывает все соединения, включительно с работающим ISP. Как показала практика, в тех случаях когда отваливается провайдер — пользователи не замечают этот «обрыв» или он не является критичным.
Если кто-то знает как очищать таблицу трансляций частично — буду благодарен.
Не забудьте запретить NAT трансляцию в приватные подсети.
VRF Lite for fun and profit
Технология Virtual Routing and Forwarding (VRF) нашла широкое применение в сетях MPLS. В таких сетях метки MPLS применяются для разграничения трафика различных пользователей, а VRF поддерживает таблицу маршрутизации для каждого из них. Для обмена маршрутной информацией в таких сетях применяется MP-BGP.
Но существует возможность использовать технологию VRF без MPLS — VRF Lite.
VRF Lite

Рассмотрим топологию, изображенную на первом рисунке. Предположим, к маршрутизатору R1 подключены четыре сети. Необходимо разграничить взаимодействие между сетями так, чтобы первая имела связь со второй, третья с четвертой, но между первой и третьей, первой и четвертой, второй и третьей, второй и четвертой связи не было. Одним из возможных решений будет применение списков доступа (ACL). Второй путь — разделить сети с помощью VRF. Ниже приведена конфигурация, позволяющая это сделать.
!включаем маршрутизацию
ip routing
!включаем Cisco Express Forwarding, необходимый для работы VRF
ip cef
!объявляем два VRF с именами ONE и TWO
ip vrf ONE
!указываем route-distinguisher
rd 65000:1
ip vrf TWO
rd 65000:2
interface FastEthernet 0/0
!указываем, что интерфейс относится к тому или иному VRF
!это необходимо сделать до указания IP адреса
!так как команда ip vrf forwarding удаляет адрес с интерфейса
ip vrf forwarding ONE
ip address 10.0.1.1 255.255.255.0
no shutdown
interface FastEthernet 0/1
ip vrf forwarding ONE
ip address 10.0.2.1 255.255.255.0
no shutdown
interface FastEthernet 1/0
ip vrf forwarding TWO
ip address 10.0.3.1 255.255.255.0
no shutdown
interface FastEthernet 1/1
ip vrf forwarding TWO
ip address 10.0.4.1 255.255.255.0
no shutdown
Теперь можно посмотреть, что у нас получилось:
Интерфейсы маршрутизатора и их сопоставление с VRF.
R1#show ip interface brief
Interface IP-Address OK? Method Status Protocol
FastEthernet0/0 10.0.1.1 YES manual up up
FastEthernet0/1 10.0.2.1 YES manual up up
FastEthernet1/0 10.0.3.1 YES manual up up
FastEthernet1/1 10.0.4.1 YES manual up up
Name Default RD Interfaces
Таблицы маршрутизации глобальная и для каждого VRF
Gateway of last resort is not set
R1#show ip route vrf ONE
Gateway of last resort is not set
10.0.0.0/24 is subnetted, 2 subnets
C 10.0.2.0 is directly connected, FastEthernet0/1
C 10.0.1.0 is directly connected, FastEthernet0/0
R1#show ip route vrf TWO
Gateway of last resort is not set
10.0.0.0/24 is subnetted, 2 subnets
C 10.0.3.0 is directly connected, FastEthernet1/0
C 10.0.4.0 is directly connected, FastEthernet1/1
Проверим связь между сетями:
R1#ping vrf ONE 10.0.1.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.1.1, timeout is 2 seconds:
.
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/2/4 ms
R1#ping vrf ONE 10.0.2.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.2.1, timeout is 2 seconds:
.
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
R1#ping vrf ONE 10.0.3.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.3.1, timeout is 2 seconds:
.
Success rate is 0 percent (0/5)
R1#ping vrf ONE 10.0.4.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.4.1, timeout is 2 seconds:
.
Success rate is 0 percent (0/5)
R1#ping vrf TWO 10.0.1.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.1.1, timeout is 2 seconds:
.
Success rate is 0 percent (0/5)
R1#ping vrf TWO 10.0.2.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.2.1, timeout is 2 seconds:
.
Success rate is 0 percent (0/5)
R1#ping vrf TWO 10.0.3.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.3.1, timeout is 2 seconds:
.
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/4 ms
R1#ping vrf TWO 10.0.4.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.4.1, timeout is 2 seconds:
.
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
Для того, чтобы посмотреть arp таблицу отдельного VRF используйте команду
show ip arp vrf NAME
Кроме того, чтобы установить telnet подключение из определенного VRF необходимо выполнить следующую команду:
telnet HOST /vrf NAME
где HOST — узел, к которому устанавливается подключение, NAME — имя VRF.
Как видно, цель достигнута и сети связаны именно так, как надо.
Динамическая маршрутизация в рамках VRF

Рассмотрим топологию на рисунке 2. Задача сводится к организации динамической маршрутизации в каждом из VRF. Пусть в первом это будет протокол OSPF, во втором — EIGRP. Конфигурация маршрутизатора R1 тогда будет выглядеть следующим образом:
router ospf 1 vrf ONE
network 10.0.1.0 0.0.0.255 area 0
network 10.0.2.0 0.0.0.255 area 0
Видно, что достаточно указать, в каком VRF должен работать процесс OSPF, чтобы все заработало.
router eigrp 100
no auto-summary
address-family ipv4 vrf TWO
network 10.0.3.0 0.0.0.255
network 10.0.4.0 0.0.0.255
no auto-summary
autonomous-system 100
exit-address-family
С EIGRP все немного сложнее, но тоже интуитивно понятно.
Для маршрутизаторов R1 и R2 конфигурации выглядят следующим образом:
router ospf 1
log-adjacency-changes
network 10.0.1.0 0.0.0.255 area 0
network 172.16.1.0 0.0.0.255 area 2
!network 172.16.2.0 0.0.0.255 area 1 для R2
Для маршрутизаторов R3 и R4:
router eigrp 100
network 10.0.3.0 0.0.0.255
network 172.16.3.0 0.0.0.255
!network 172.16.4.0 0.0.0.255 для R4
no auto-summary
Для того, чтобы убедиться, что все работает, достаточно посмотреть на таблицы маршрутизации.
R1#show ip route vrf ONE
Gateway of last resort is not set
172.16.0.0/24 is subnetted, 2 subnets
O IA 172.16.1.0 [110/2] via 10.0.1.2, 00:38:58, FastEthernet0/0
O IA 172.16.2.0 [110/2] via 10.0.2.2, 00:39:00, FastEthernet0/1
10.0.0.0/24 is subnetted, 2 subnets
C 10.0.2.0 is directly connected, FastEthernet0/1
C 10.0.1.0 is directly connected, FastEthernet0/0
R1#show ip route vrf TWO
Gateway of last resort is not set
172.16.0.0/24 is subnetted, 2 subnets
D 172.16.4.0 [90/30720] via 10.0.4.2, 00:17:37, FastEthernet1/1
D 172.16.3.0 [90/30720] via 10.0.3.2, 00:17:50, FastEthernet1/0
10.0.0.0/24 is subnetted, 2 subnets
C 10.0.3.0 is directly connected, FastEthernet1/0
C 10.0.4.0 is directly connected, FastEthernet1/1
Gateway of last resort is not set
172.16.0.0/24 is subnetted, 2 subnets
C 172.16.1.0 is directly connected, FastEthernet0/1
O IA 172.16.2.0 [110/3] via 10.0.1.1, 00:39:37, FastEthernet0/0
10.0.0.0/24 is subnetted, 2 subnets
O 10.0.2.0 [110/2] via 10.0.1.1, 00:39:37, FastEthernet0/0
C 10.0.1.0 is directly connected, FastEthernet0/0
Gateway of last resort is not set
172.16.0.0/24 is subnetted, 2 subnets
D 172.16.4.0 [90/33280] via 10.0.3.1, 00:18:40, FastEthernet0/0
C 172.16.3.0 is directly connected, FastEthernet0/1
10.0.0.0/24 is subnetted, 2 subnets
C 10.0.3.0 is directly connected, FastEthernet0/0
D 10.0.4.0 [90/30720] via 10.0.3.1, 00:18:52, FastEthernet0/0
Заключение
В статье приведены команды, необходимые для функционирования маршрутизатора с несколькими таблицами маршрутизации. Кроме того, описана настройка основных IGP протоколов маршрутизации в рамках одного VRF.
VRF, VPN-Instance, Routing-instance
Когда речь заходит о VPN, возникает вопрос изоляции трафика. Никто другой не должен его получать, а ваши частные адреса не должны появляться там, где им не положено — то есть в Интернете, в сети нашего провайдера и в VPN других клиентов.
Когда вы настраиваете GRE-туннель через Интернет (или OpenVPN, на ваш вкус), то ваши данные автоматически обособлены — никто не видит ваши частные адреса в Интернете, и трафик не попадёт в чужие руки (если не поднимать вопрос нацеленной атаки).
То есть существует некий туннель между двумя публичными адресами, который никак не связан ни с вашим провайдером, ни с другими транзитными туннелями. Два разных VPN — два совершенно разных туннеля — и по вашему туннелю течёт только ваши трафик.
Совсем иначе стоит вопрос в провайдерском VPN — одна и та же магистральная сеть должна переносить данные сотен клиентов. Как тут быть?
Нет, можно, конечно, и тут GRE, OpenVPN, L2TP и иже с ними, но тогда всё, чем будут заниматься инженеры эксплуатации — это настраивать туннели и лопатить миллионы строк конфигурации. Но проблема глубже — вопрос организации такого универсального для всех канала вторичен: главное сейчас — как изолировать двух клиентов, подключенных к одному маршрутизатору? Если, например, оба используют сеть 10.0.0.0/8, как не позволить трафику маршрутизироваться между ними?
Здесь мы приходим к понятию VRF — Virtual Routing and Forwarding instance. Терминология тут не устоявшаяся: в Cisco — это VRF, в Huawei — VPN-instance, в Juniper — Routing Instance. Все названия имеют право на жизнь, но суть одна — виртуальный маршрутизатор. Это что-то вроде виртуальный машины в каком-нибудь VirtualBox — там на одном физическом сервере поднимается много виртуальных серверов, а здесь на одном физическом маршрутизаторе есть много виртуальных маршрутизаторов.
Каждый такой виртуальный маршуртизатор — это по сути отдельный VPN. Их таблицы маршрутизации, FIB, список интерфейсов и прочие параметры не пересекаются — они строго индивидуальны и изолированы. Ровно так же они обособлены и от самого физического маршрутизатора. Но как и в случае виртуальных серверов, между ними возможна коммуникация.
VRF — он строго локален для маршрутизатора — за его пределами VRF не существует. Соответственно VRF на одном маршрутизаторе никак не связан с VRF на другом.
Раз уж мы рассматриваем все примеры на оборудовании Cisco, то будем придерживаться их терминологии.
VRF Lite
Так называется создание провайдерского VPN без MPLS.
Вот, например, так можно настроить VPN в пределах одного маршрутизатора:  Тут у нас есть два клиента — TAR’s Robotics и C3PO Electronic.
Тут у нас есть два клиента — TAR’s Robotics и C3PO Electronic.
Интерфейсы FE0/0 и FE0/1 принадлежат VPN C3PO Electronic, интерфейсы FE1/0 и FE1/1 — VPN TAR’s Robotics. Внутри одного VPN узлы общаются без проблем, между собой — уже никак. 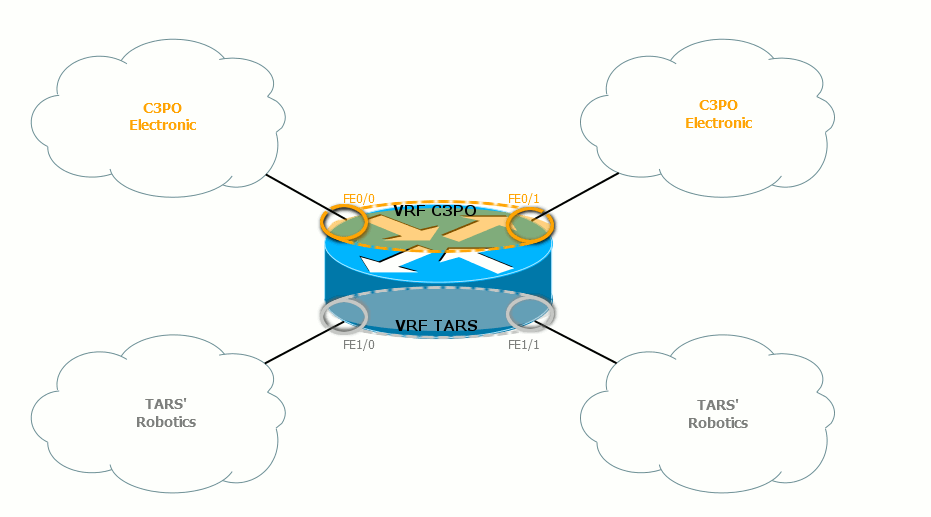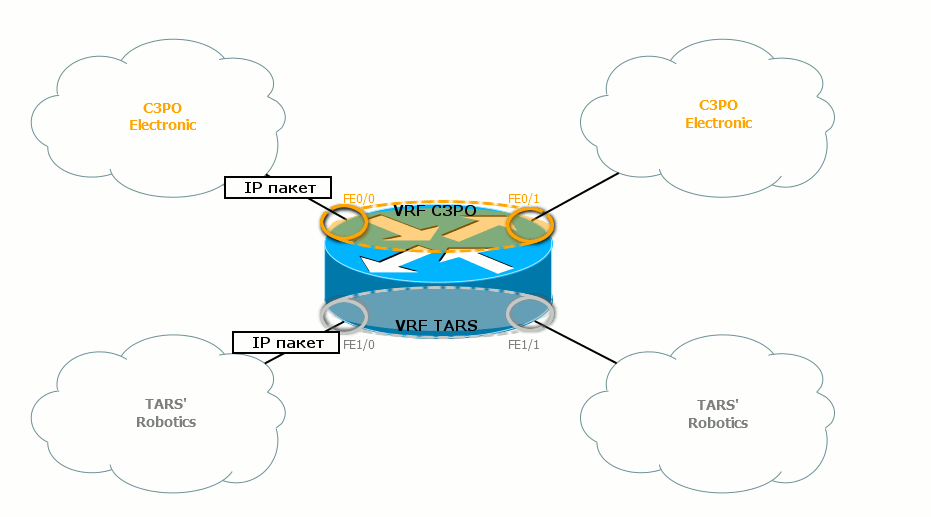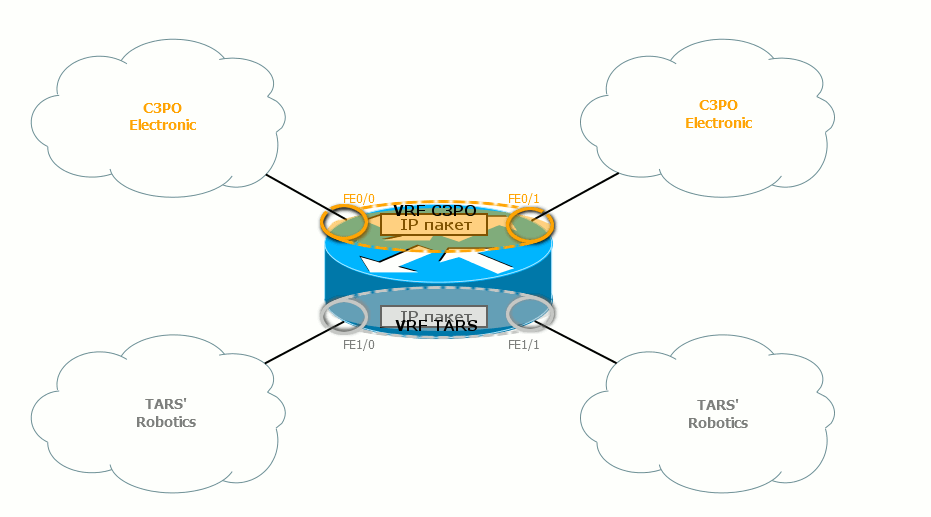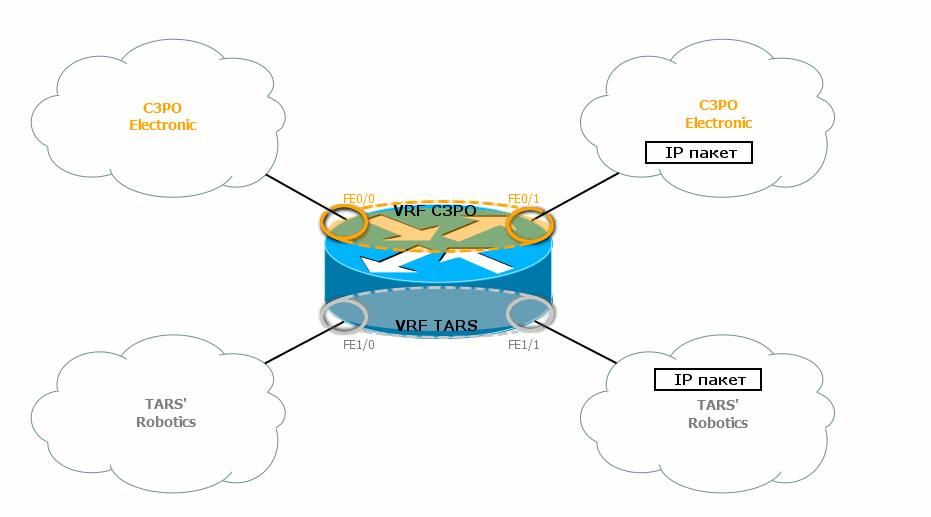 Вот так выглядят их таблицы маршрутизации на провайдерском маршрутизаторе:
Вот так выглядят их таблицы маршрутизации на провайдерском маршрутизаторе: 
 Маршруты C3PO Electronic не попадут в сети TARS’ Robotics и наоборот.
Маршруты C3PO Electronic не попадут в сети TARS’ Robotics и наоборот.
Клиентские интерфейсы здесь привязаны к конкретному VRF.
Один интерфейс не может быть членом двух VRF сразу или членом и VRF и глобальной таблицы маршрутизации.
Используя VRF Lite можно легко пробросить VPN между разными концами сети. Для этого нужно настроить одинаковые VRF на всех промежуточных узлах и правильно привязать их к интерфейсам:  То есть R1 и R2 будут общаться друг с другом через одну пару интерфейсов в глобальной таблице маршрутизации, через другую пару в VRF TARS’ Robotics и через третью в VRF C3PO Electronic. Разумеется, это могут быть сабинтерфейсы.
То есть R1 и R2 будут общаться друг с другом через одну пару интерфейсов в глобальной таблице маршрутизации, через другую пару в VRF TARS’ Robotics и через третью в VRF C3PO Electronic. Разумеется, это могут быть сабинтерфейсы.
Аналогично между R2-R3.
Таким образом, получаются две виртуальные сети, которые друг с другом не пересекаются. Учитывая этот факт, в каждой такой сети нужно поднимать свой процесс IGP, чтобы обеспечить связность. В данном случае будет один процесс для физического маршрутизатора, один для TARS’ Robotics, один для C3PO Electric. Соответственно, каждый из них будет сигнализироваться отдельно от других по своим собственным интерфейсам.
Если говорить о передаче данных, то пакет, придя от узла из сети TARS’s Robotics, сразу попадает в соответствующий VRF, потому что входной интерфейс R1 является его членом. Согласно FIB данного VRF он направляется на R2 через выходной интерфейс. На участке между R1 и R2 ходят самые обычные IP-пакеты, которые и не подозревают, что они принадлежат разным VPN. Вся разница только в том, что они идут по разным физическим интерфейсам, либо несут разный тег в заголовке 802.1q. R2 принимает этот пакет интерфейсом, который также член VRF TARS’s Robotics. R2 варит пакет в нужном FIB и отправляет дальше, согласно IGP. И так до самого выхода пакета ну другой стороне сети.
Как узел определяет, что полученный пакет относится к определённому VPN? Очень просто: данный интерфейс привязан («прибинден») к конкретному VRF. Как вы уже, вероятно, заметили, эти интерфейсы помечены на иллюстрации колечками соответствующего цвета.
Включим немного воображение:
Если пакет проходит через серое колечко, он переходит на серую сторону окрашивается в серый цвет. Далее он будет уже проверяться по серой таблице маршрутизации. Аналогично, когда пакет проходит через золотое кольцо, он покрывается благородной позолотой и проверяется по золотой таблице маршрутизации.
Точно также выходные интерфейсы привязаны к VPN, и соответствующие таблицы маршрутизации знают, какие за ними сети находятся.
Учитывайте, что всё, что мы говорим о таблицах маршрутизации, касается и FIB — в каждом VPN свой собственный FIB. Между маршрутизаторами пакеты не окрашены. Пакеты разных VPN не смешиваются, потому что идут либо по разных физическим интерфейсам, либо по одному, но имеют разные VLAN-теги (каждому VRF соответствует свой выходной саб-интерфейс).
Вот он простой и прозрачный VPN — для клиента сформирована самая что ни на есть частная сеть.  Но этот способ удобен, пока у вас 2-3 клиента и 2-3 маршрутизатора. Он совершенно не поддаётся масштабированию, потому что один новый VPN означает новый VRF на каждом узле, новые интерфейсы, новый пул линковых IP-адресов, новый процесс IGP/BGP.
Но этот способ удобен, пока у вас 2-3 клиента и 2-3 маршрутизатора. Он совершенно не поддаётся масштабированию, потому что один новый VPN означает новый VRF на каждом узле, новые интерфейсы, новый пул линковых IP-адресов, новый процесс IGP/BGP.
А если точек подключения не 2-3, а 10, а если нужно ещё резервирование, а каково это поднимать IGP с клиентом и обслуживать его маршруты на каждом своём узле?
И тут мы подходим уже к MPLS VPN.
MPLS L3VPN
MPLS VPN позволяет избавиться от вот этих неприятных шагов:
1) Настройка VRF на каждом узле между точками подключения
2) Настройка отдельных интерфейсов для каждого VRF на каждом узле.
3) Настройка отдельных процессов IGP для каждого VRF на каждом узле.
4) Необходимость поддержки таблицы маршрутизации для каждого VRF на каждом узле.
Да как так-то? Рассмотрим, что такое MPLS L3VPN на примере такой сети: Итак, это три филиала нашего клиента TARS’ Robotics: головной офис в Москве и офисы в Новосибирске и Красноярске — весьма удалённые, чтобы дотянуть до них своё оптоволокно. А у нас туда уже есть каналы.
Итак, это три филиала нашего клиента TARS’ Robotics: головной офис в Москве и офисы в Новосибирске и Красноярске — весьма удалённые, чтобы дотянуть до них своё оптоволокно. А у нас туда уже есть каналы.
Центральное облако — это мы — linkmeup — провайдер, который предоставляет услугу L3VPN.
Вообще говоря, TARS Robotics как заказчику, совершенно без разницы, как мы организуем L3VPN — да пусть мы хоть на поезде возим их пакеты, лишь бы в SLA укладывались. Но в рамках данной статьи, конечно, внутри нашей сети работает MPLS.
Data Plane или передача пользовательских данных
Сначала надо бы сказать, что в MPLS VPN VRF создаётся только на тех маршрутизаторах, куда подключены клиентские сети. В нашем примере это R1 и R3. Любым промежуточным узлам не нужно ничего знать о VPN.
А между ними нужно как-то обеспечить изолированную передачу пакетов разных VPN.
Вот какой подход предлагает MPLS VPN: коммутация в пределах магистральной сети осуществляется, как мы описывали в предыдущей статье, по одной метке MPLS, а принадлежность конкретному VPN определяется другой — дополнительной меткой.
Подробнее:
1) Вот клиент отправляет пакет из сети 172.16.0.0/24 в сеть 172.16.1.0/24.
2) Пока он движется в пределах своего филиала (сеть клиента), он представляет из себя самый обычный пакет IP, в котором Source IP — 172.16.0.2, Destination IP — 172.16.1.2.
3) Сеть филиала знает, что добраться до 172.16.1.0/24 можно через Сеть провайдера.
До сих пор это самый обычный пакет, потому что стык идёт по чистому IP с частными адресами.
4) Дальше R1 (маршрутизатор провайдера), получает этот пакет, знает, что он принадлежит определённому VRF (интерфейс привязан к VRF TARS), проверяет таблицу маршрутизации этого VRF — в какой из филиалов отправить пакет — и инкапсулирует его в пакет MPLS.
Метка MPLS на этом пакете означает как раз его принадлежность определённому VPN. Это называется «Сервисная метка».
5) Далее наш маршрутизатор должен отправить пакет на R3 — за ним находится искомый офис клиента. Естественно, по MPLS. Для этого при выходе с R1 на него навешивается транспортная метка MPLS. То есть в этот момент на пакете две метки.
Продвижение пакета MPLS по облаку происходит ровно так, как было описано в выпуске про базовый MPLS. В частности на R2 заменяется транспортная метка — SWAP Label.
6) R3 в итоге получает пакет, отбрасывает транспортную метку, а по сервисной понимает, что тот принадлежит к VPN TARS’ Robotics.
7) Он снимает все заголовки MPLS и отправляет пакет в интерфейс таким, какой он пришёл на R1 изначально.
На диаграмме железо-углерод видно, как преображается пакет по ходу движения от ПК1 до ПК2: 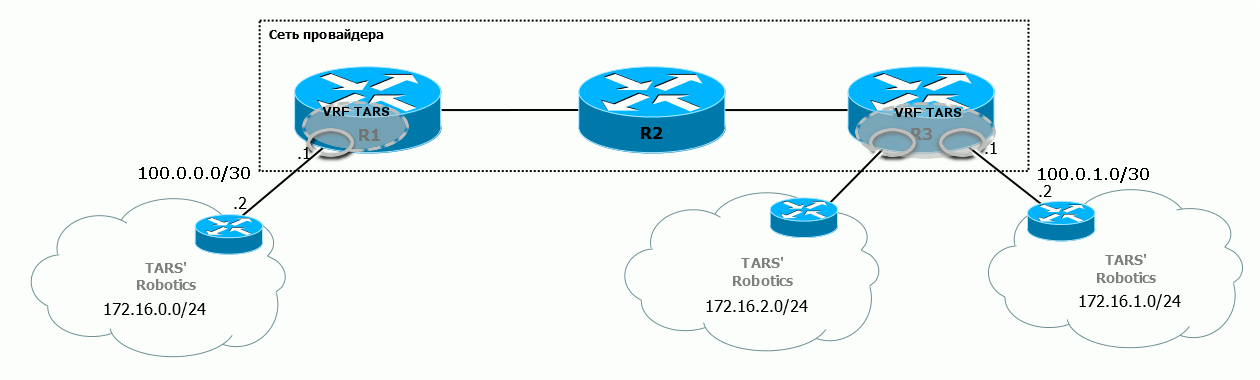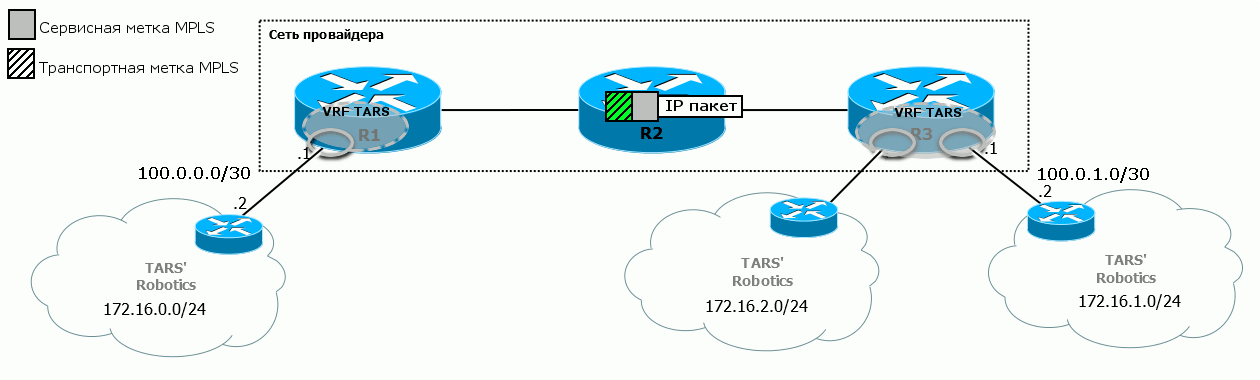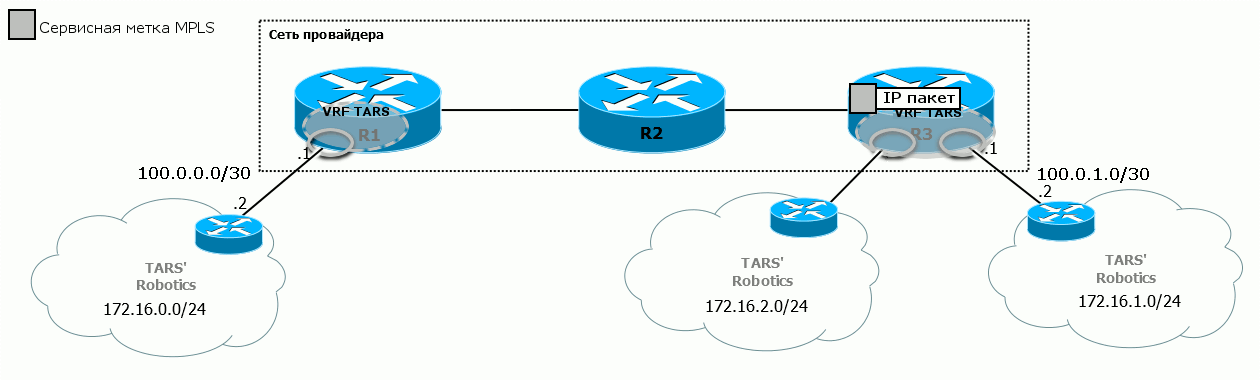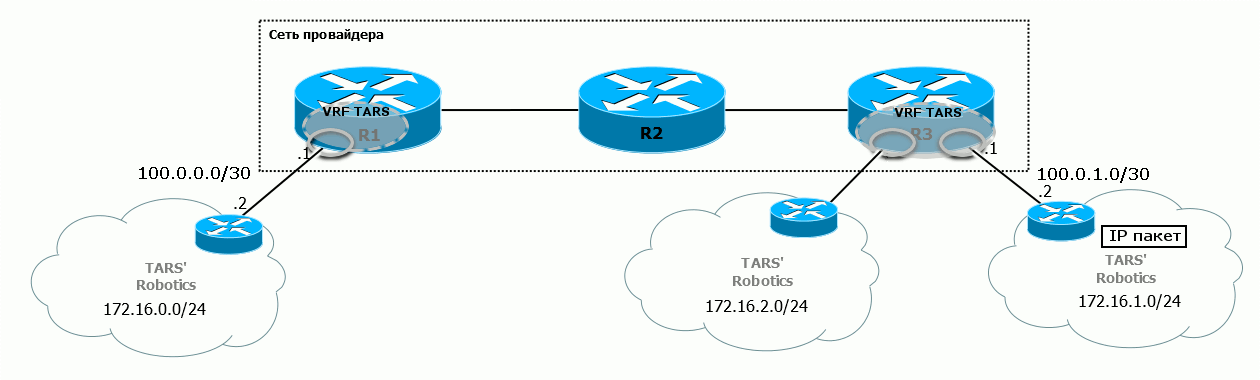 Помните, чем хорош MPLS? Тем, что никому нет дела до того, что находится под меткой. Поэтому в пределах магистральной сети не важно, какие адресные пространства у клиента, то есть, какой IP-пакет кроется под заголовком MPLS.
Помните, чем хорош MPLS? Тем, что никому нет дела до того, что находится под меткой. Поэтому в пределах магистральной сети не важно, какие адресные пространства у клиента, то есть, какой IP-пакет кроется под заголовком MPLS.
Поскольку пакет коммутируется по меткам, а не маршрутизируется по IP-адресам — нет нужды поддерживать и таблицу маршрутизации VPN на промежуточных узлах.
То есть у нас получается такой удобный MPLS-туннель, который сигнализируется, как вы увидите дальше, автоматически.
Итак, в промежутке между R1 и R3 (то есть в облаке MPLS) ни у кого нет понимания, что такое VPN – пакеты VPN движутся по метками до пункта назначения, и только он уже должен волноваться, что с ними делать дальше. Это убирает необходимость поднимать VRF на каждом узле и, соответственно, поддерживать таблицу маршрутизации, FIB, список интерфейсов итд.
Учитывая, что весь дальнейший путь пакета определяется на первом MPLS-маршрутизаторе (R1), отпадает нужда и в индивидуальном протоколе маршрутизации в каждом VPN, хотя остаётся вопрос, как найти выходной маршрутизатор, на который мы ответим дальше.
 Чтобы лучше понять, как передаётся трафик, нужно выяснить значение меток в пакете.
Чтобы лучше понять, как передаётся трафик, нужно выяснить значение меток в пакете.
Роль меток MPLS
Если мы вернёмся к изначальной схеме с VRF-Lite, то проблема в том, что серый цвет IP-пакета (индикатор принадлежности к VPN TARS’ Robotics) существует только в пределах узла, при передаче его на другой эта информация переносится в тегах VLAN. И если мы откажемся от сабинтерфейсов на промежуточных узлах, начнётся каша. А сделать это нужно во благо всего хорошего.
Чтобы этого не произошло в сценарии с MPLS, Ingress LSR на пакет навешивает специальную метку MPLS — Сервисную — она идентификатор VPN. Egress LSR (последний маршрутизатор — R3) по этой метке понимает, что IP-пакет принадлежит VPN TARS’s Robotics и просматривает соответствующий FIB.
То есть очень похоже на VLAN, с той разницей, что только первый маршрутизатор должен об этом заботиться.
Но на основе сервисной метки пакет не может коммутироваться по MPLS-сети — если мы где-то её поменяем, то Egress LSR не сможет распознать, какому VPN она принадлежит.
И тут на выручку приходит стек меток, который мы так тщательно избегали в прошлом выпуске.
Сервисная метка оказывается внутренней — первой в стеке, а сверху на неё ещё навешивается транспортная.
То есть по сети MPLS пакет путешествует с двумя метками — верхней — транспортной и нижней — сервисной).
Для чего нужно две метки, почему нельзя обойтись одной сервисной? Пусть бы, например, одна метка на Ingress LSR задавал один VPN, другая — другой. Соответственно дальше по пути они бы тоже коммутировались как обычно, и Egress LSR точно знал бы какому VRF нужно передать пакет.
Вообще говоря, сделать так можно было бы, и это бы работало, но тогда в магистральной сети для каждого VPN был бы отдельный LSP. И если, например, у вас идёт пучок в 20 VPN с R1 на R3, то пришлось бы создавать 20 LSP. А это сложнее поддерживать, это перерасход меток, это лишняя нагрузка на транзитные LSR. Да и, строго говоря, это то, от чего мы тут пытаемся уйти. Кроме того, для разных префиксов одного VPN могут быть разные метки — это ещё значительно увеличивает количество LSP.
Куда ведь проще создать один LSP, который будет туннелировать сразу все 20 VPN?
Транспортная метка
Таким образом, нам необходима транспортная метка. Она верхняя в стеке.  Она определяет LSP и меняется на каждом узле.
Она определяет LSP и меняется на каждом узле.
Она добавляется (PUSH) Ingress LSR и удаляется (POP) Egress LSR (или Penultimate LSR в случае PHP). На всех промежуточных узлах она меняется с одной на другую (SWAP).
Распространением транспортных меток занимаются протоколы LDP и RSVP-TE. Об этом мы тоже очень хорошо поговорили в прошлой статье и не будем останавливаться сейчас.
В целом транспортная метка нам мало интересна, поскольку всё и так уже понятно, за исключением одной детали — FEC.
FEC здесь уже не сеть назначения пакета (приватный адрес клиента), это адрес последнего LSR в сети MPLS, куда подключен клиент.
Это очень важно, потому что LSP не в курсе про всякие там VPN, соответственно ничего не знает о их приватных маршрутах/префиксах. Зато он хорошо знает адреса интерфейсов Loopback всех LSR. Так вот к какому именно LSR подключен данный префикс клиента, подскажет BGP — это и будет FEC для транспортной метки.
В нашем примере R1, опираясь на адрес назначения клиентского пакета, должен понять, что нужно выбрать тот LSP, который ведёт к R3.
Чуть позже мы ещё вернёмся к этому вопросу.
Сервисная метка
 Нижняя метка в стеке — сервисная. Она является уникальным идентификатором префикса в конкретном VPN.
Нижняя метка в стеке — сервисная. Она является уникальным идентификатором префикса в конкретном VPN.
Она добавляется Ingress LSR и больше не меняется нигде до самого Egress LSR, который в итоге её снимает.
FEC для Сервисной метки — это префикс в VPN, или, грубо говоря, подсеть назначения изначального пакета. В примере ниже FEC – 192.168.1.0/24 для VRF C3PO и 172.16.1.0/24 для VRF TARS.
То есть Ingress LSR должен знать, какая метка выделена для этого VPN. Как это происходит — предмет дальнейших наших с вами исследований.
Вот так выглядит целиком процесс передачи пакетов в различных VPN’ах: 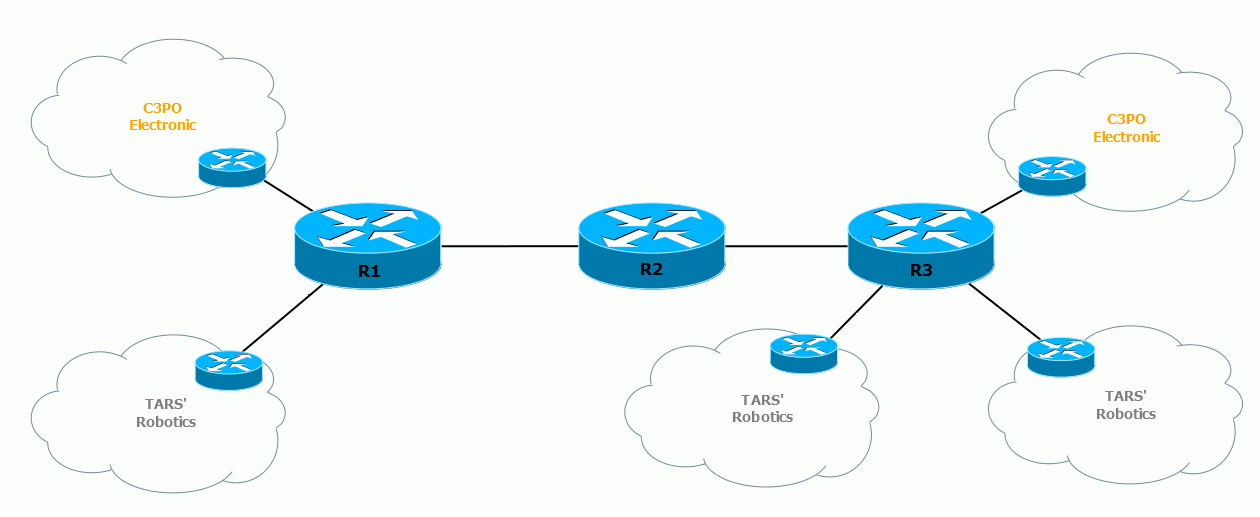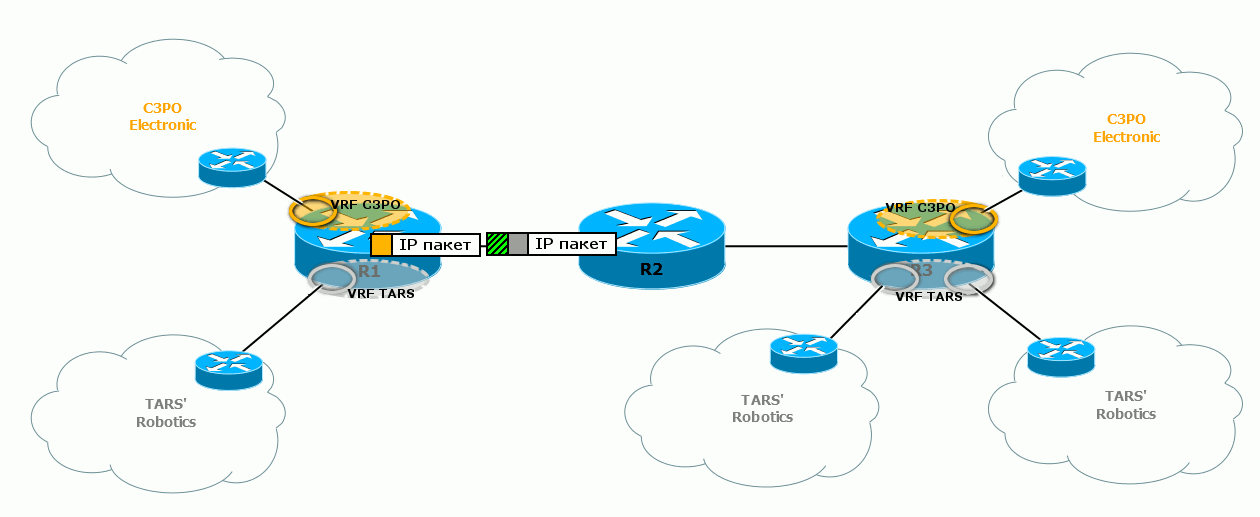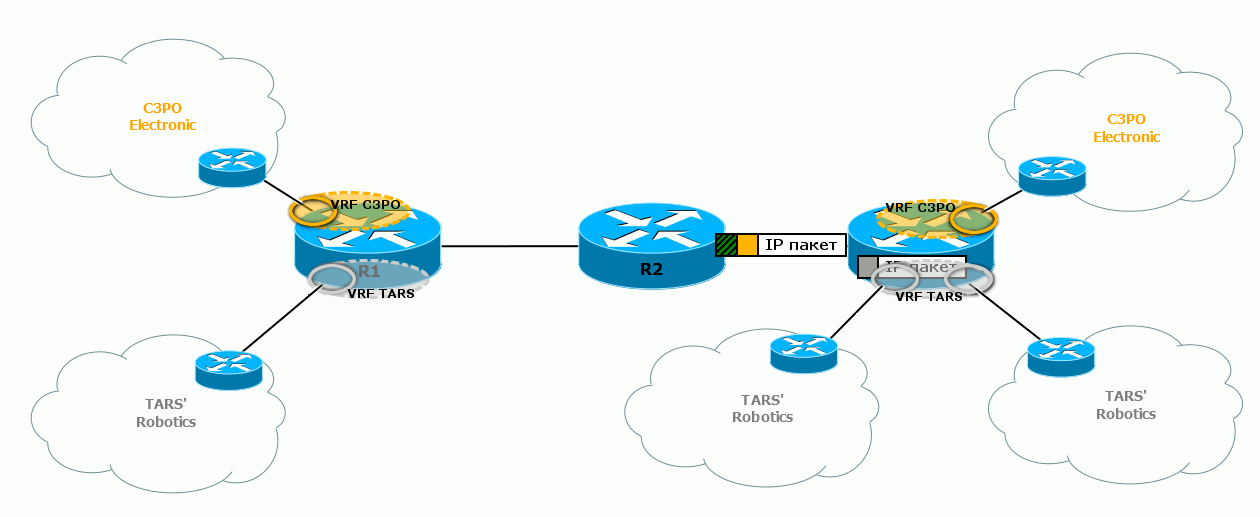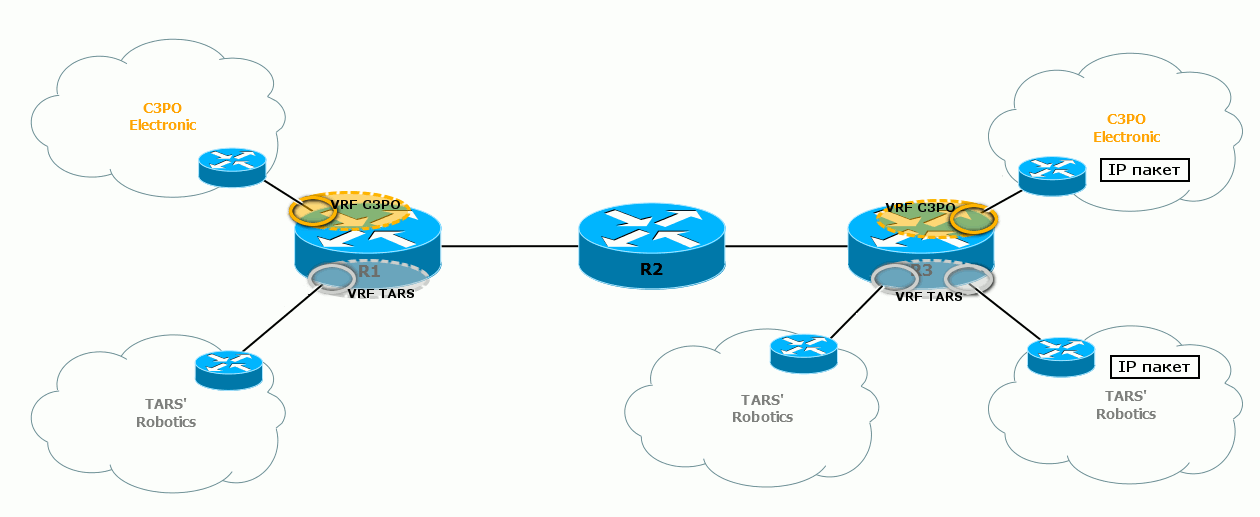 Обратите внимание, что для двух разных VPN отличаются сервисные метки – по ним выходной маршрутизатор узнаёт, в какой VRF передавать пакет.
Обратите внимание, что для двух разных VPN отличаются сервисные метки – по ним выходной маршрутизатор узнаёт, в какой VRF передавать пакет.
А транспортные в данном случае одинаковые для пакетов обоих VRF, потому что они используют один LSP – R1↔R2↔R3.
Терминология
Пока мы не ушли слишком далеко, надо ввести терминологию.
Когда речь заходит о MPLS VPN, появляется несколько новых терминов, которые, впрочем, вполне очевидны:
CE — Customer Edge router — граничный маршрутизатор клиента, который подключен в сеть провайдера.
PE — Provider Edge router — граничный маршрутизатор провайдера. Собственно к нему и подключаются CE. На PE зарождается VPN, на нём они и кончаются. Именно на нём расположены интерфейсы, привязанные к VPN. Именно PE назначает и снимает сервисные метки. Именно PE являются Ingress LSR и Egress LSR.
PE должны знать таблицы маршрутизации каждого VPN, ведь это они принимают решение о том, куда посылать пакет, как в пределах провайдерской сети, так и в плане клиентских интерфейсов. P — Provider router — транзитный маршрутизатор, который не является точкой подключения — пакеты VPN проходят через него без каких-либо дополнительных обработок, иными словами просто коммутируются по транспортной метке. P нет нужды знать таблицы маршрутизации VPN или сервисные метки. На P нет интерфейсов привязанных к VPN.
На самом деле роль P-PE индивидуальна для VPN. Если в одном VPN R1 и R3 — это PE, а R2 — P, то в другом они могут поменять свои роли.
Вот, например, на схеме ниже роли синих маршрутизаторов отличаются для зелёного клиента и для фиолетового:  Стек меток — набор MPLS заголовков, навешанных на один пакет. Каждый из них выполняет какую-то свою роль. В нашей реальности мало кто из вендоров поддерживает больше шести меток в стеке.
Стек меток — набор MPLS заголовков, навешанных на один пакет. Каждый из них выполняет какую-то свою роль. В нашей реальности мало кто из вендоров поддерживает больше шести меток в стеке.
Будет и ещё ряд терминов, но их пока рано вводить.
В целом мы закончили с тем, как передаются данные, то есть как работает Forwading Plane.
Давайте подытожим:
Маршрутизатор PE навешивает на клиентский трафик две метки — внутреннюю сервисную, которая не меняется до самого конца путешествия и по ней последний PE понимает, какому VRF принадлежит пакет, и внешнюю транспортную, по которой пакет передаётся через сеть провайдера — эта метка меняется на каждом P-маршрутизаторе и снимается на последнем PE или предпоследнем P.
Благодаря наличию сервисной метки и VRF трафик различных VPN изолирован друг от друга как в пределах маршрутизаторов, так и в каналах.
И собственно, теперь можно сформулировать ряд беспокоящих вопросов:
1) Как распределяются метки MPLS?
2) Как распространяется маршрутная информация по каждому VPN?
3) Как маршруты разных VPN изолируются друг от друга и не смешиваются?
На эти и другие вопросы отвечаем ниже.
Control Plane или передача служебной (маршрутной) информации
Отвечая на них, как раз поговорим о том, как подготавливается вся эта среда, в которой будут успешно ходить пакеты данных.
Протоколы маршрутизации
Итак, мы имеем два типа сетей и стыки между ними:
Граница этих сетей находится на PE. То есть одной своей половиной он уже клиентский, а другой — провайдерский. Не зря бытует народная мудрость: Как PE ни настраивай, он всё равно на клиентов смотрит.
MPLS настраивается только на магистральных интерфейсах.  Напоминаю, речь о L3VPN. А тут нужно заботиться о IP-связности. Причём теперь у нас куча ограничений. Разберёмся, какие протоколы на каких участках нам пригодятся.
Напоминаю, речь о L3VPN. А тут нужно заботиться о IP-связности. Причём теперь у нас куча ограничений. Разберёмся, какие протоколы на каких участках нам пригодятся.
Во-первых, нужно обеспечить базовую IP-связность внутри магистральной сети провайдера. Чтобы были известны все Loopback-адреса, линковые сети, служебные префиксы, возможно, какие-то выходы вовне.
Для этого запускается IGP (ISIS, OSPF).
Уже поверх связной сети поднимается MPLS.
Так мы обеспечили работоспособность магистральной сети. Во-вторых, у клиента в филиалах может стоять не по одному маршрутизатору, а какие-никакие сети. Эти сети тоже надо маршрутизировать внутри себя как минимум.
Очевидно, что внутри своей собственной сети клиент волен распространять маршрутную информацию, как ему угодно. Мы как провайдер на это повлиять не можем, да нам и без разницы.
Так обеспечивается передача маршрутов в пределах сетей клиентов. В-третьих, клиенту нужно как-то сообщать своим маршруты провайдеру. На стыке CE-PE клиенту и провайдеру уже нужно договариваться о том, какой протокол будет использоваться.
Хотя, едва ли у клиента какой-то свой самописный протокол IGP. Наверняка, это OSPF/ISIS/RIP. Поэтому обычно провайдер идёт навстречу и выбирает тот, который удобен клиенту.
Тут надо понимать, что вот этот протокол взаимодействия с клиентом работает в VPN и никак не пересекается с IGP самого провайдера. Это разные независимые процессы.
Зачастую на этом стыке работает BGP, поскольку позволяет гибко фильтровать префиксы по различным атрибутам.
Так провайдер получает маршруты клиентов.
В-четвёртых, и это самое интересное — осталось передать маршруты одного филиала другому через магистральную сеть. При этом их надо по пути не потерять, не перепутать с чужими, доставить в целости и сохранности. Тут нам поможет расширение протокола BGP — MBGP — Multiprotocol BGP (Часто его называют MP-BGP). О нём мы сейчас и поговорим.
Но сначала посмотрите, что и где работает: 
Может, на примере из реальной жизни будет немного понятнее.
Допустим, вы живёте в посёлке Ола и решили отдохнуть в Шэньчжэне.
1) На своих двоих, на машине или на такси вы добираетесь до автовокзала посёлка Ола (IGP внутри сети).
2) Садитесь на автобус, и он довозит вас до Магадана (IGP/BGP с провайдером).
3) В Магадане вам туроператор выдаёт ваши загранпаспорта, билеты и ваучер (внутренняя сервисная метка). Теперь вы стали членом определённого рейса (VPN).
4) В аэропорту всем без разницы, в какую гостиницу вы в итоге едете — их задача доставить вас в Шэньчжэнь (BGP), а для этого нужно посадить вас на правильный самолёт согласно вашему ваучеру (назначить внешнюю транспортную метку — PUSH Label — и отправить в правильный интерфейс)
Итак, вы сели в самолёт. Этот самолёт является вашей внешней транспортной меткой, а ваучер — сервисной. Самолёт доставит вас до следующего хопа, а ваучер до гостиницы.
5) Самолёт летит из Магадана в Шэньчжэнь не напрямую, а с пересадками. Сначала вы вышли в Москве, пересели в новый самолёт до Пекина. Потом в Пекине вы пересели на самолёт уже до Шэньчжэня. (Так произошла коммутация по меткам — SWAP Label). При этом ваучер — сервисная метка по-прежнему у вас в кармане.
6) В Шэньчжэне вы вышли из самолёта (POP Label) и уже тут проверят ваш ваучер — куда вас собственно нужно везти (в какой VPN).
7) Вас садят в автобус до вашей гостиницы (IGP/BGP с провайдером).
8) Во дворе гостиницы вы самостоятельно находите дорогу до номера, через ресепшн (IGP внутри сети).
Итак, аэропорт Магадана — это PE/Ingress LSR, аэропорт Шэньчжэня — это другой PE/Egress LSR, аэропорт Москвы — P/Intermediate LSR.
Особенно интересно будет выглядеть PHP в этой фантазии.
Сейчас ответим на два вопроса: как маршруты передаются в провайдерской сети от одного PE к другому и как обеспечивается изоляция.
В общем-то до сих пор не придумано ничего лучше для передачи маршрутов на удалённые узлы, чем BGP: и гибкость передачи самих маршрутов, и масса инструментов по влиянию на выбор маршрута, и политики получения и передачи маршрутов, и Community, сильно упрощающие групповые действия над маршрутами.
Если вдруг вы забыли, тот вот обычное сообщение BGP Update:  В секции NLRI оно переносит сам префикс. А в других секциях масса его параметров.
В секции NLRI оно переносит сам префикс. А в других секциях масса его параметров.
К его помощи и прибегают при реализации MPLS L3VPN. Поэтому его второе имя MPLS BGP VPN.
Вы ведь помните, как это происходит? BGP устанавливает сессию со своими соседями через TCP на порт 179. Это позволяет в качестве соседей выбирать не напрямую подключенный маршрутизатор, а те, что находятся в нескольких хопах. Так и работает IBGP, где в пределах магистральной сети предполагается связь «каждый с каждым».
Когда несколько маршрутов, ведущих в одну сеть, приходят на узел, BGP просто выбирает из них лучший и инсталлирует его в таблицу маршрутизации.
То есть в целом нам ничего не стоит передать маршрут VPN через сеть на другой её конец.
BGP должен взять маршруты из VRF на одном узле, доставить их на другой и там экспортировать в правильный VRF.
Вот только загвоздка в том, что BGP изначально ориентирован на работу с публичными адресами, которые предполагаются уникальными во всём мире. А клиенты-негодяи обычно хотят передавать маршруты в частные сети (RFC1918) и, как назло, они запросто могут пересекаться как с сетями других VPN, так и со внутренним адресным пространством самого провайдера.
То есть, если, например, R3 получит два маршрута в сеть 10.10.10.10/32 (один от TARS’s Robotics, другой от C3PO Electronic), он выберет только один — с лучшими показателями, как предписывает стандарт — он думает, что это два маршрута в одну и ту же сеть.  Естественно, нам это не подходит. Нужно, чтобы выполнялось два условия:
Естественно, нам это не подходит. Нужно, чтобы выполнялось два условия:
1) Маршруты разных VPN были уникальными и не смешивались при передаче между PE.
2) Маршруты в конечной точке должны быть переданы правильному VRF.
Этим проблемам было найдено элегантное решение. Начнём с п.1 — уникальность маршрутов.
В нашем примере 10.10.10.10/32 от TARS’s Robotics должен чем-то отличаться от 10.10.10.10/32 от C3PO Electronic.
BGP невероятно гибкий протокол (не зря ведь он стал единственным протоколом внешнего шлюза). Он легко масштабируется и с помощью так называемых Address Family он может передавать маршруты не только IPv4, но и IPv6 и IPX (да только кому он нужен). Хочешь передать что-то новое — заведи свою Address Family, И создал IETF новый Address Family. И дал он имя ему VPNv4 (или VPN-IPv4).
Route Distinguisher
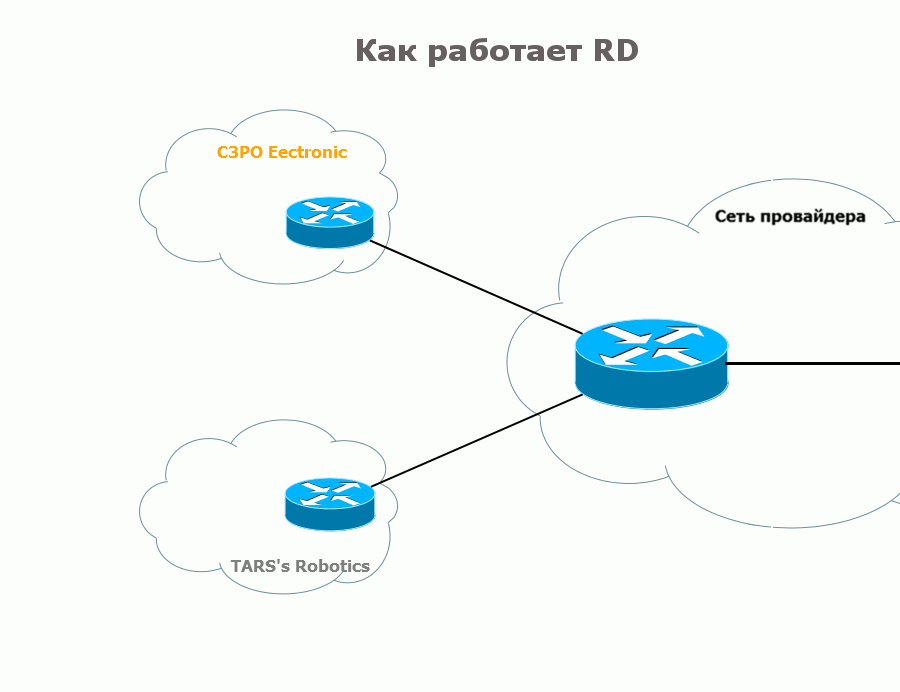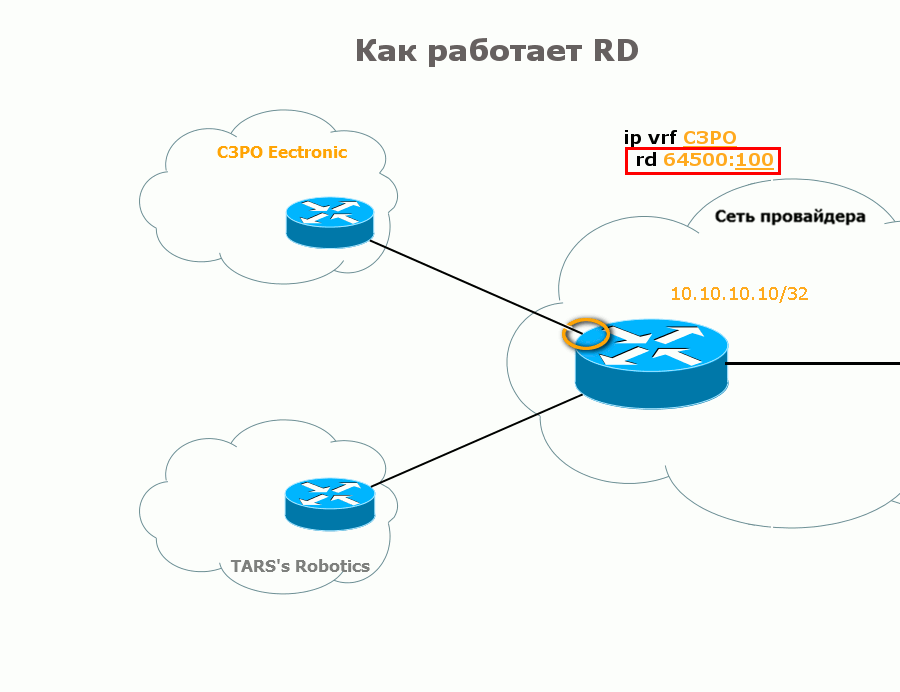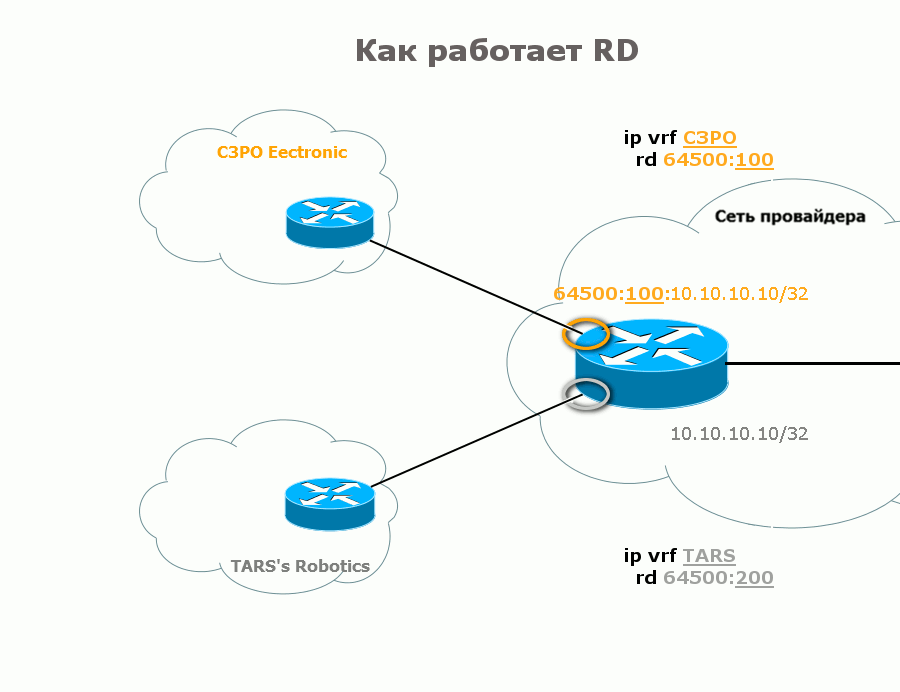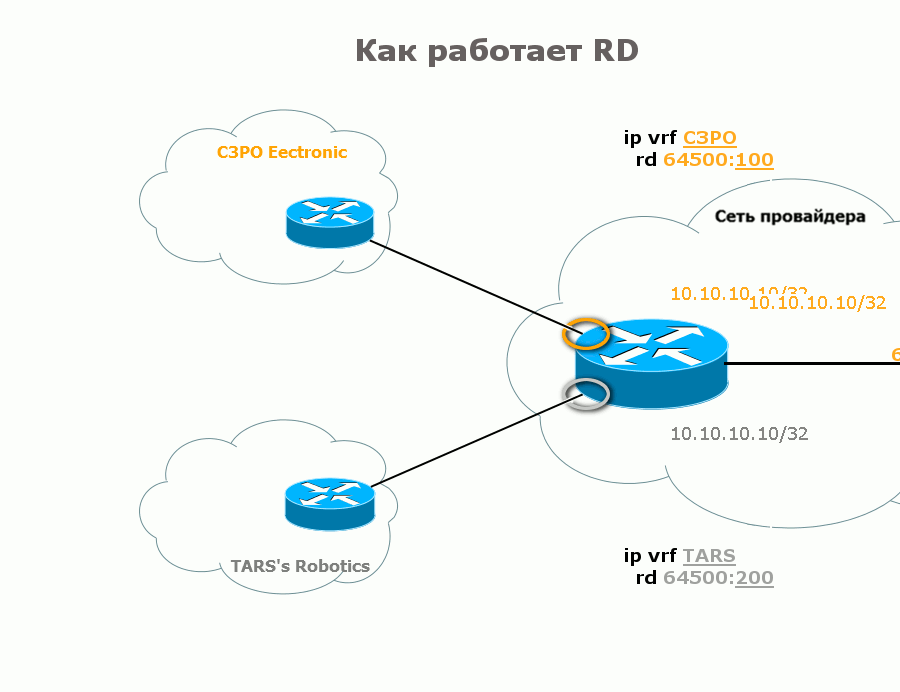
Для того, чтобы различать маршруты различных VPN, обычный IPv4 префикс дополняется специальной приставкой длиной 8 байтов — RD — Route Distinguisher.
Тогда маршрут от C3PO будет выглядеть так: 64500:100:10.10.10.10/32, а от TARS так: 64500:200:10.10.10.10/32. И теперь это совершенно разные вещи, которые процесс BGP сможет друг от друга отличить.
Разберёмся что из себя представляет RD и как его определить.
Существует 3 типа RD:  Навеяно. Первая часть — сам тип (0, 1 или 2);
Навеяно. Первая часть — сам тип (0, 1 или 2);
Вторая часть — Административное поле (Administrator field) — это всегда публичный параметр — публичный IP-адрес или публичный номер AS. Она необходима для того, чтобы ваши RD были уникальны не только в пределах сети, но и в пределах планеты.
То есть в Административной части не должны появиться случайно IP адрес 172.16.127.2 или AS 65001. Это может пригодиться в том случае, когда VPN нужно передать в сеть другого провайдера (а такое тоже не исключено в наше безумное время, и оно даже носит название Inter-AS VPN).
Третья часть — Выделенный номер (Assigned Number) — это уже то, что назначаете вы. Эта часть позволяет RD быть уникальным в пределах вашей сети и, собственно, определять VPN.
Как видите, RD уникальны в пределах планеты.
Вот два примера преобразования обычного IPv4-префикса 10.10.10.10/32 в VPNv4:
Какой выберете вы, не имеет значения, даже если в пределах сети вы будете использовать оба подхода одновременно. Даже для одного VRF на разных маршрутизаторах. Главная задача RD — разделить префиксы.
То есть если совсем простым языком: совершенно не важно, что вы настроите, главное, чтобы вы были уверены, что BGP никогда не спутает маршруты разных VPN.
Хотя систематизация ещё никому не мешала.
Обычно используют тип 0, Административное поле — это номер AS провайдера, а Выделенный номер вы выбираете самостоятельно. При настройке RD первые «0:» или «1:» (тип RD) сокращаются и получается так: 64500:100 и 100.0.0.1:100.
Cisco позволяет использовать типы 0 и 1.
Да, RD придётся настроить вручную и самому следить за его уникальностью. Но по-другому тут и не получится — сами маршрутизаторы не умеют отслеживать, есть ли на других узлах уже такой RD или нет. А если и есть, то не тот же ли самый это VPN?
И что же у нас получается?
1) Приходит от CE анонс новой сети. Пусть это будет 10.10.10.10/32, как мы и договаривались. PE добавляет этот маршрут в таблицу маршрутизации конкретного VRF. Заметьте, что в таблице маршрутизации хранится обычный IPv4 маршрут — никаких VPNv4. А это и не нужно: VRF изолированы друг от друга, как мы уже говорили раньше — это отдельный, пусть и виртуальный маршрутизатор.
2) BGP заметил, что появился новый префикс в VPN. Из конфигурации VRF он видит какой RD нужно использовать. Компилирует из RD и нового IPv4-префикса, VPNv4-префикс. Получается так: C3PO: 64500:100:10.10.10.10/32
или так:
TARS: 64500:200:10.10.10.10/32
3) Создавая BGP Update, маршрутизатор вставляет туда полученный VPNv4-префикс, адрес Next Hop и прочие атрибуты BGP. Но кроме всего прочего, он добавляет в поле NLRI информацию о метке. Эта метка привязана к маршруту, или точнее говоря, VPNv4-префикс — это FEC, а в NLRI передаётся связка данного FEC и метки.
По-английски это называется Labeled Route — по-русски, пожалуй, маршрут, снабжённый меткой. Так данный PE уведомляет своих соседей, что если те получили от CE IP-пакет в эту сеть, ему нужно назначить такую сервисную метку.
 Обратите также внимание на адрес Next Hop — это Loopback PE. И это очень правильно — Ingress PE должен знать, до какого Egress PE нужно отправить пришедший пакет с данными, то есть знать его Loopback, а дальше хоть потоп.
Обратите также внимание на адрес Next Hop — это Loopback PE. И это очень правильно — Ingress PE должен знать, до какого Egress PE нужно отправить пришедший пакет с данными, то есть знать его Loopback, а дальше хоть потоп.
4) Дальше BGP Update передаётся всем соседям, настроенным в секции VPNv4 family.
5) Удалённый PE получает этот Update, видит в NLRI, что это не обычный IPv4 маршрут, а VPNv4. Помните, да: если придёт два маршрута в одну сеть от разных клиентов — они не перепутаются, потому что имеют разные RD. Далее Egress PE определяет, в какой VRF этот маршрут нужно экспортировать и, собственно, делает это. Так маршрут появляется в таблице маршрутизации и FIB нужного VRF, а оттуда уходит в сеть клиента.
Теперь, когда PE получает от CE пакет с данными, который следует в сеть 10.10.10.10/32, в FIB этого VPN он находит сервисную метку (22) и Next-Hop (1.1.1.1). Инкапсулирует IP в MPLS, дальше ищет в уже глобальном FIB транспортную метку для Next Hop.
Сама транспортная метка как и прежде доставляется протоколами LDP или RSVP-TE, а сервисная — MBGP.
Сравните поле NLRI в обычном BGP и в MP-BGP. 
Route Target
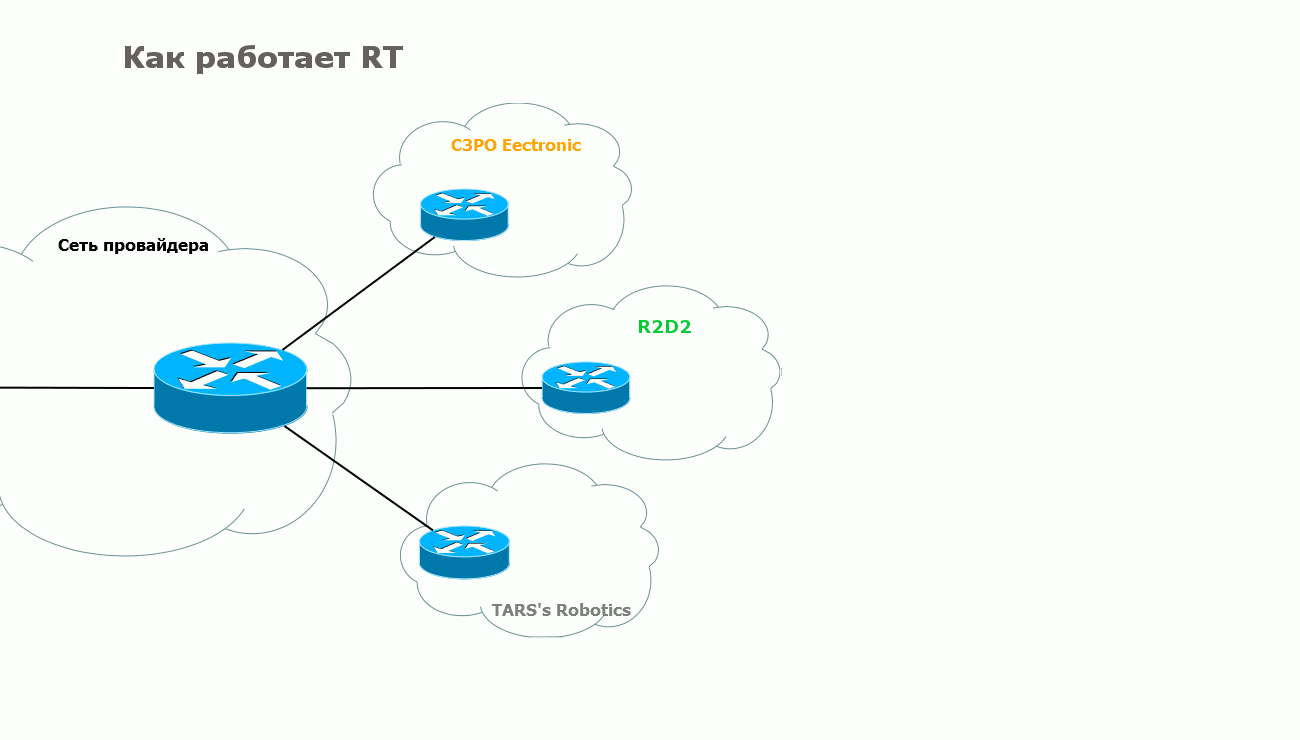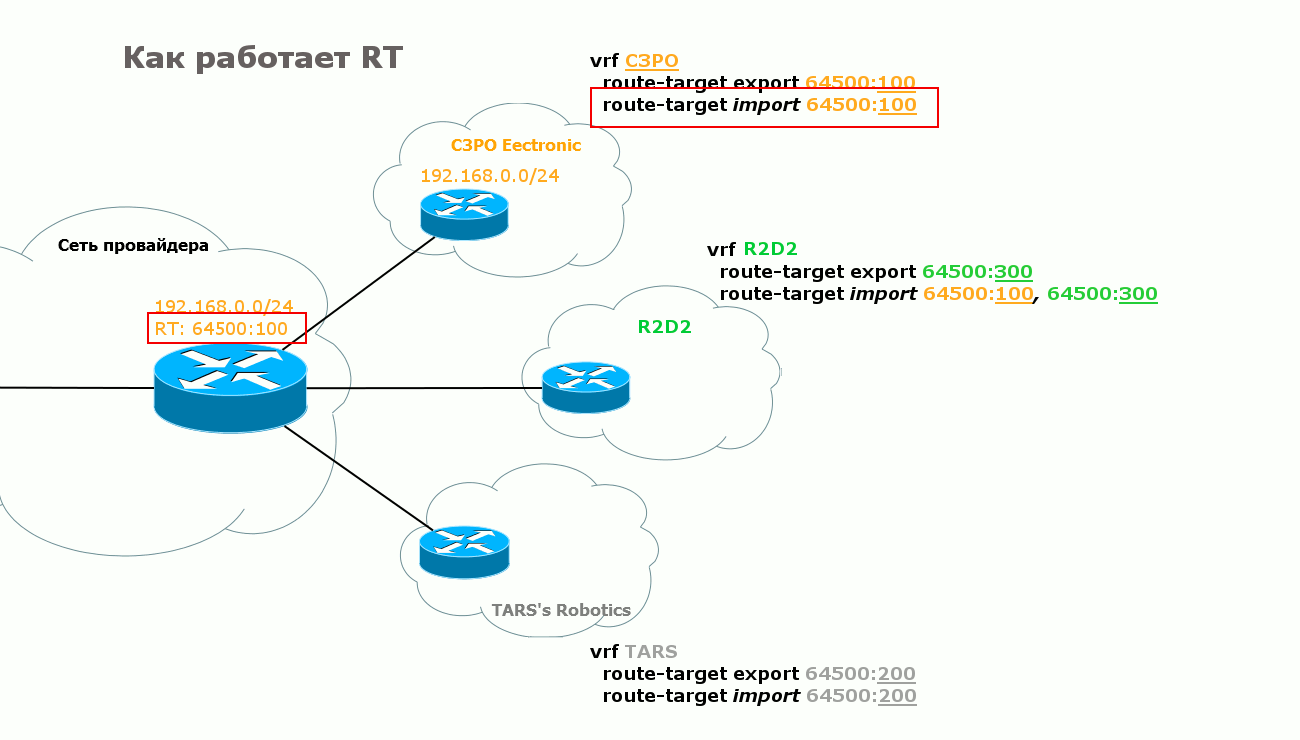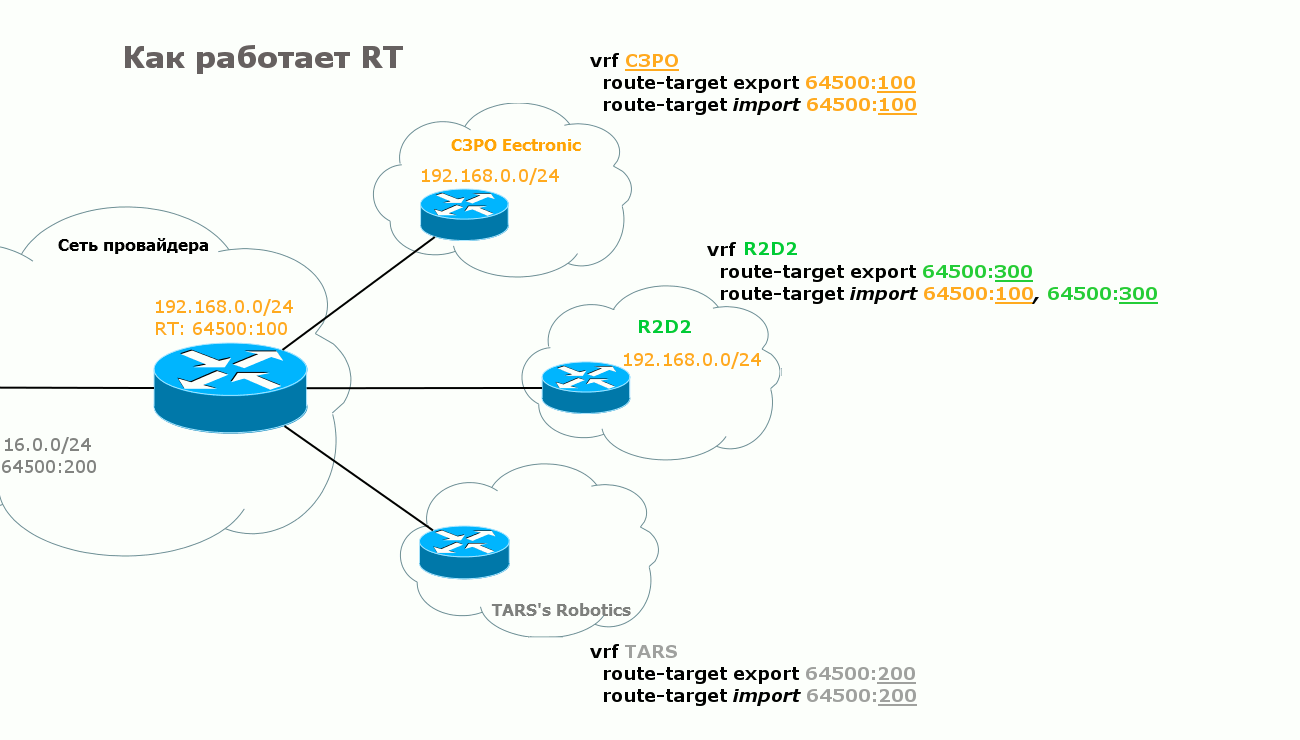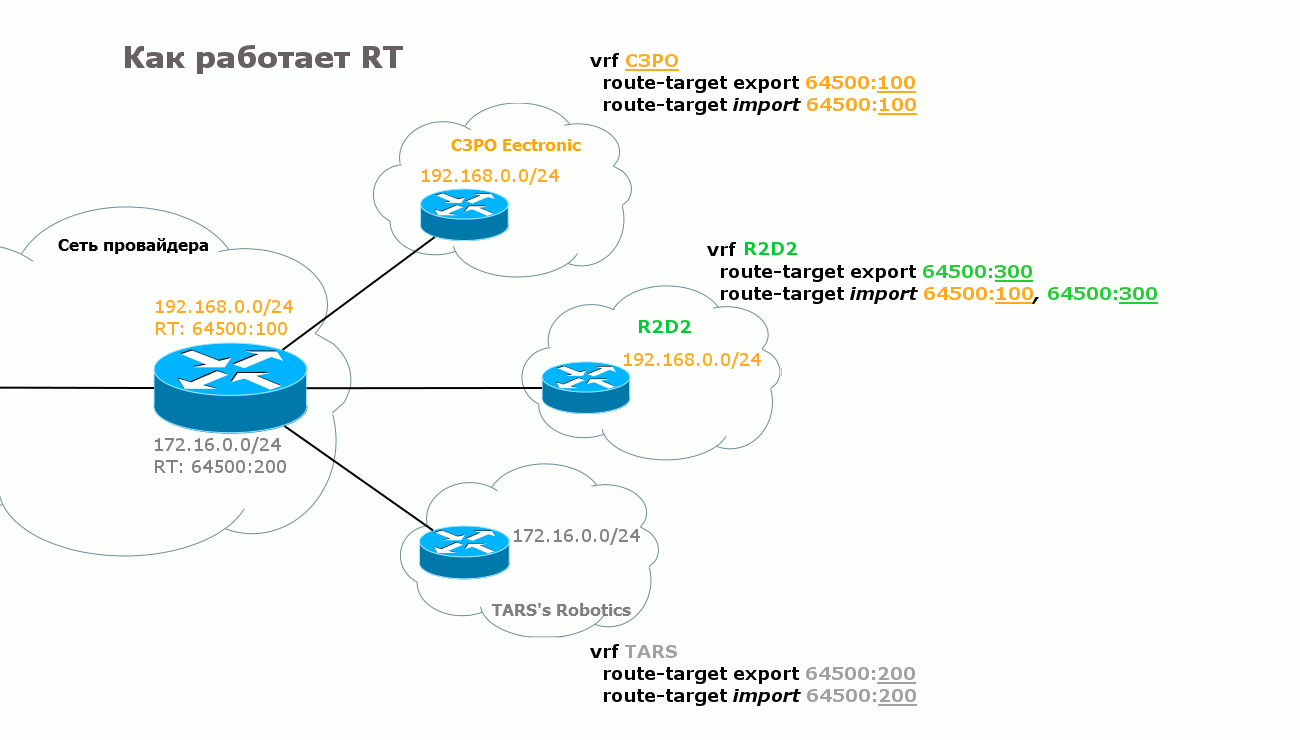
Я ведь не зря выше в пятом пункте выделил фразу «определяет, в какой VRF этот маршрут нужно экспортировать» курсивом. За этой простотой скрывается ещё одна вещь — RT — Route Target.
Дело в том, что единственная роль RD — разнообразить жизнь BGP, то есть сделать маршруты уникальными. Несмотря на то, что он настраивается для VRF, он не является каким-то его уникальными идентификатором и на всех точках подключения это значение может быть даже разным. Поэтому PE не может определить в какой VRF засунуть маршрут на основе RD. Да и это было бы не совсем в традициях BGP — разбирать переданный адрес, анализировать его перед тем, как куда-то анонсировать. Для этих целей у нас есть политики. То есть в классическом BGP, пришлось бы вешать политики на экспорт маршрутов в VRF для каждого отдельно. И мы бы вручную отфильтровывали куда нужно пристроить каждый маршрут. Один шаг в сторону упрощения — использование community. При отправке маршрута с одного PE на другой можно устанавливать определённый community — свой для каждого VRF, а на удалённой по этому community уже настраивать экспорт в соответствующий VRF. Это уже выглядит удобно и убедительно.
В MBGP зашли ещё немного дальше — идею community развили до понятия Route Target. По сути, это то же community — RT даже передаётся в атрибуте Extended Community, только все политики работают автоматически.
Формат RT, точно такой же, как у обычного Extended Community. Например:
64500:100
То есть он похож на первый тип RD. Отчасти поэтому RD и RT так часто путают.
На одной стороне в VRF настраивается RT на экспорт маршрута — тот RT, с которым он будет путешествовать к удалённому PE. На другой именно это же значение RT устанавливается на импорт. И наоборот.
Обычно, если задача — просто организовать услугу VPN для одного клиента, то RT на экспорт и на импорт совпадают на всех точках подключения.
Возвращаясь к нашему примеру:
R1 посылает R3 маршрут к сети 10.10.10.10/32 (TARS’ Robotics), указывает метку и всяческие другие параметры, и в числе прочего в атрибут Extended Community он записывает RT на экспорт маршрута, который настроен для данного VRF: 64500:200.
R3 получает этот анонс, проверят community, видит 64500:200, а из конфигурации он знает, что маршруты с этим RT нужно импортировать в VRF TARS.
 Красиво? Элегантно? Но это ещё не всё. Гибкость BGP и здесь проявляется в очередной раз. С помощью механизма RT вы можете импортировать маршруты как вам заблагорассудится как в пределах одного VPN, так и между различными VPN.
Красиво? Элегантно? Но это ещё не всё. Гибкость BGP и здесь проявляется в очередной раз. С помощью механизма RT вы можете импортировать маршруты как вам заблагорассудится как в пределах одного VPN, так и между различными VPN.
Вот вам два сценария:
1) Клиент хочет организовать топологию звезда, а не каждый с каждым. То есть центральная точка должна знать маршруты во все точки подключения, а вот те должны знать только маршруты до центра. Таким образом, любые взаимодействия между разделёнными клиентскими сетями будут осуществляться через центральный узел. Без всяких действий со стороны клиента — удобно же! Решение: У каждого филиала — свой RT на экспорт. В филиалах RT на импорт равен RT на экспорт, настроенный на центральном узле — то есть они могут получать маршруты от центра. При этом на импорт нет RT других филиалов — соответственно напрямую их маршруты они не видят. Зато в центре на импорт настроены RT всех филиалов, то есть он будет получать всё-всё-всё.
2) Допустим, помимо наших двух VPN появился третий — R2D2. У него есть какие-то свои задачи, но ещё они поддерживают сервера с прошивками для микропроцессоров, шаблонами, дополнительными модулями итд, которые необходимы C3PO Electronic. При этом он не хочет светить в мир своими серверами, а для клиентов обеспечить доступ через сеть провайдера. И тогда с помощью RT можно обеспечить взаимодействие между различными VPN. Для этого в C3PO Electronic мы настраиваем такой RT на импорт, который в VPN R2D2 был указан на экспорт. И, соответственно, наоборот.
Правда в этом случае нужно следить за тем, не пересекаются ли используемые подсети. Ведь несмотря на все RD и RT, BGP выберет только один маршрут в каждую подсеть в VRF.
 Осталось увидеть процесс передачи маршрута от и до:
Осталось увидеть процесс передачи маршрута от и до: 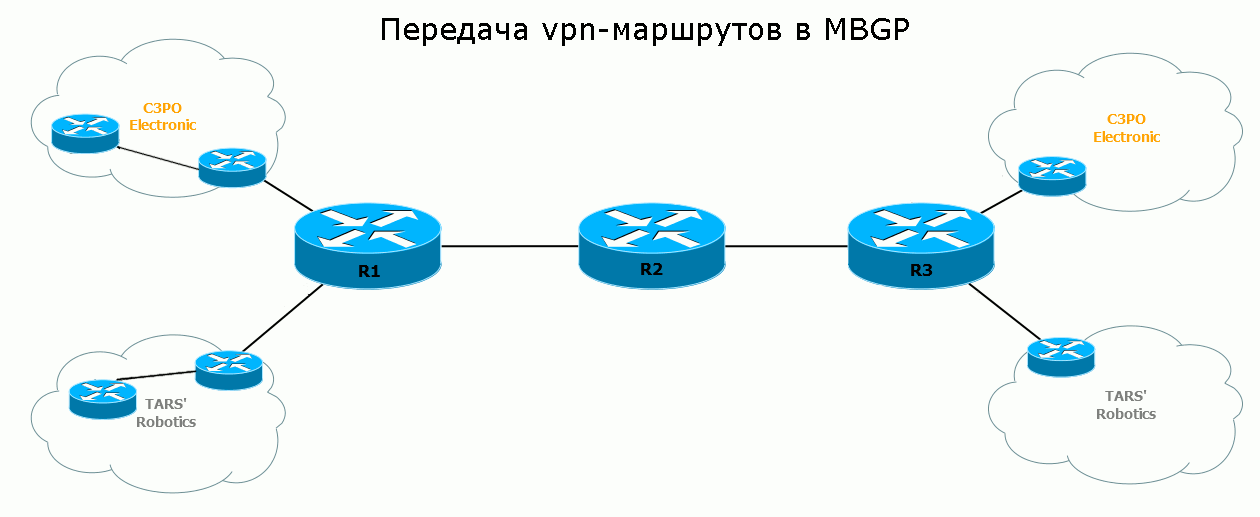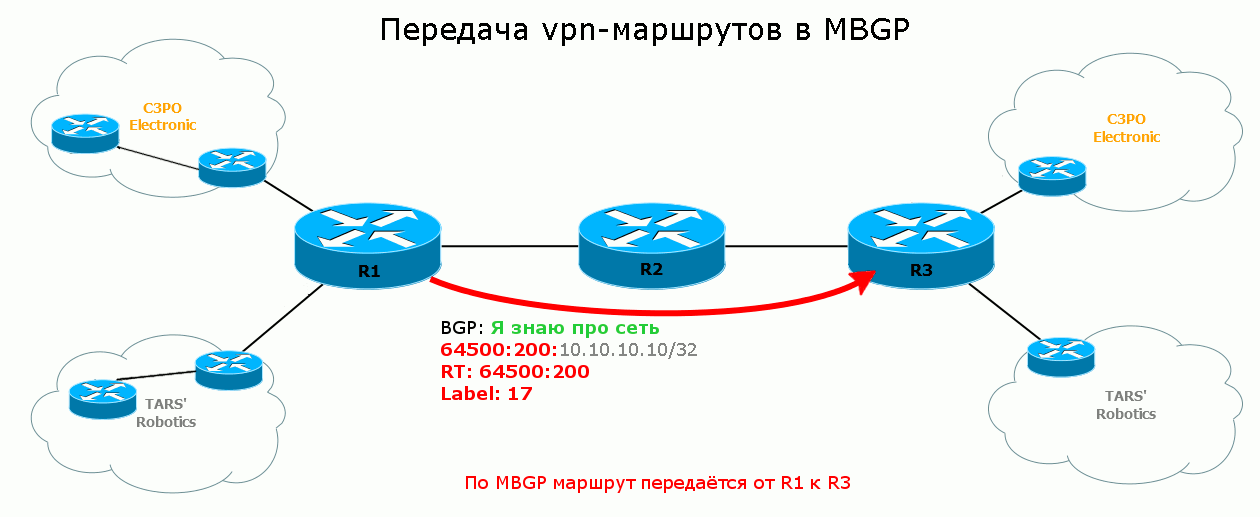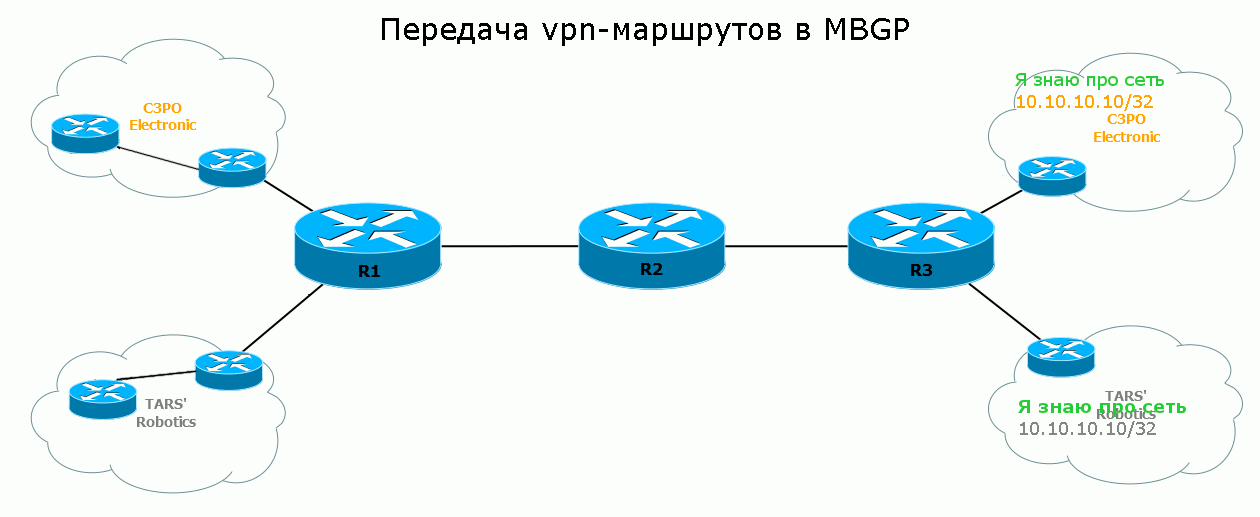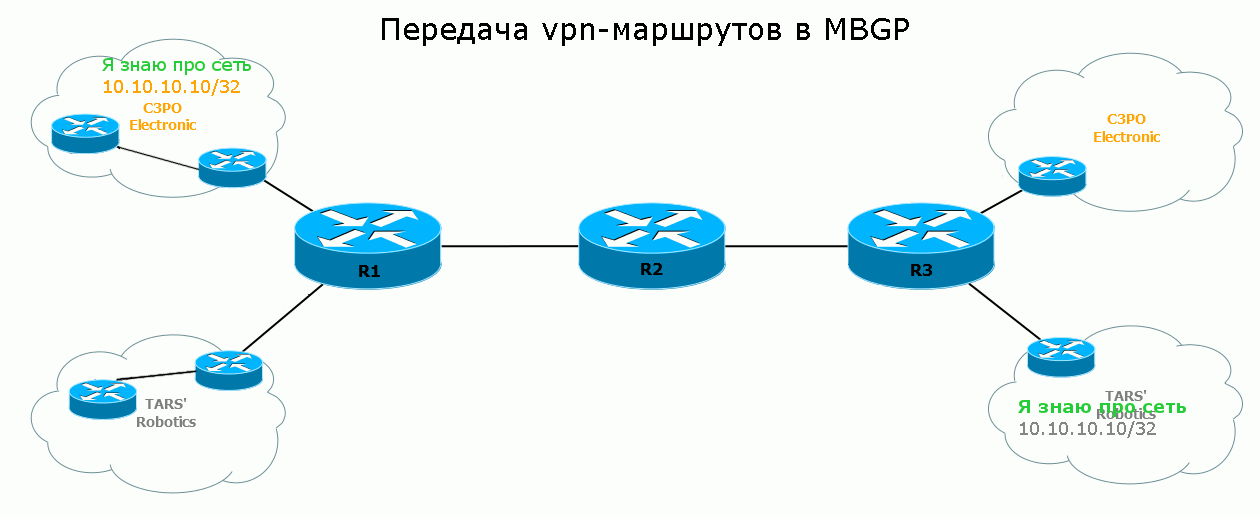

Практика
Традиционно на практике повторим всё то, что было до сих пор в теории.
VRF-Lite
Так и пойдём от простого к сложному. Начнём с ситуации, когда один клиент имеет два подключения в один маршрутизатор:
 Сначала попробуем настроить всё так, как мы делали это раньше:
Сначала попробуем настроить всё так, как мы делали это раньше:
Linkmeup:
Пинг между филиалами появляется — они друг друга видят.  Но при этом они видят и, например, адрес Loopback R1:
Но при этом они видят и, например, адрес Loopback R1:  Соответственно, они видят всю сеть провайдера и будут видеть сети других клиентов.
Соответственно, они видят всю сеть провайдера и будут видеть сети других клиентов.
Поэтому настраиваем VRF:
Чтобы в этот VRF поместить клиентов, нужно их интерфейсы привязать к VRF:
Обратите внимание, что после выполнения команды ip vrf forwarding C3PO, IOS удалил IP-адреса с интерфейсов, теперь их нужно настроить повторно. Это произошло для того, чтобы удалить указанные подсети из глобальной таблицы маршрутизации.
После повторной настройки адреса эти подсети появятся уже в таблице маршрутизации VRF.  Проверяем снова пинг:
Проверяем снова пинг:  А вот до внутреннего адреса провайдера уже не будет:
А вот до внутреннего адреса провайдера уже не будет:  Аналогичные настройки нужно сделать и для клиента TARS:
Аналогичные настройки нужно сделать и для клиента TARS:
Вот и славно. VRF TARS и C3PO полностью изолированы от сети провайдера и друг от друга: 


Теперь растягиваем удовольствие на сеть linkmeup:  Первый шаг настройки — создать VRF на каждом узле от R1 до R3:
Первый шаг настройки — создать VRF на каждом узле от R1 до R3:
* Следует понимать, что VRF — это строго локальное для узла понятие. Вполне можно устанавливать разные имена VRF на разных маршрутизаторах. Второй шаг — создать цепочку линковых сетей между всеми узлами и привязать каждую пару интерфейсов к нужному VRF.
Мы не стали указывать на схеме линковые адреса, чтобы не загромождать её. Для порядка выберем префиксы 10.0/16 для собственно сети провайдера (VLAN1), 192.168/16 для C3PO Electronic (Vlan 2) и 100.0/16 для TARS’ Robotics (Vlan 3).
ISIS для связности внутренней сети провайдера, OSPF для VPN.
OSPF поднимается и с клиентами, чтобы они изучали маршруты динамически. Соответственно, в них должна быть конструкция вроде этой:
Собственно всё. Теперь каждая сеть знает свои маршруты: 
 В принципе, на базе одной физической сети мы создали три абсолютно самостоятельных виртуальных сети, внутри которых можно делать практически всё, что угодно — хоть свой MPLS поднимать.
В принципе, на базе одной физической сети мы создали три абсолютно самостоятельных виртуальных сети, внутри которых можно делать практически всё, что угодно — хоть свой MPLS поднимать.
Но, как и было сказано раньше — это очень инертное решение, поэтому переходим к MPLS BGP VPN.
MPLS L3VPN
Я предлагаю в этот раз не брать уже готовую сеть, где уже всё преднастроено. Сейчас интереснее будет пройти этот путь с нуля, пусть и только вехами, не вдаваясь в детали.
Итак, мучаем всё ту же сеть, но упростим её удалением одного филиала:
Начнём с одного клиента и двух точек подключения.
Клиентские маршрутизаторы имеют очень простую конфигурацию:
C3PO_1:
На клиентских узлах настроены линковые адреса с провайдером и интерфейс Loopback (как и прежде, мы используем этот интерфейс, чтобы имитировать сеть, дабы не плодить маршрутизаторы). То есть если на C3PO_2 мы увидим сеть 192.168.255.1/32, это значит, что мы увидели бы и всю сеть полностью.
В качестве локального протокола динамической маршрутизации используется OSPF. Собственно, именно он позволит сообщить адрес Loopback-интерфейса всем заинтересованным.
Что же касается сети провайдера.
Вначале мы приведём краткий порядок настройки, а потом покажем на примере.
1) Настраиваем IP-адреса: линковые и loopback. Клиентские пока не трогаем.
Linkmeup_R1:
Файл начальной конфигурации.
2) Теперь поднимаем ISIS в качестве IGP — он свяжет всю сеть linkmeup, распространив маршрутную информацию о линковых и Loopback-адресах.
Linkmeup_R1:
На этом шаге получили глобальную таблицу маршрутизации — необходимая платформа для следующего шага.  3) Включаем MPLS и LDP:
3) Включаем MPLS и LDP:
Linkmeup_R1:
На этом шаге у нас построены LSP между всеми парами LSR:  *Пример выделения меток на Linkmeup_R1.
*Пример выделения меток на Linkmeup_R1.
Это базис для VPN. Эти LSP — это набор транспортных меток.
Мы выбрали здесь LDP, чтобы не усложнять конфигурацию. С RSVP-TE ещё поразбираемся в статье про Traffic Engineering.
4) Создаём VRF на двух узлах: Linkmeup_R1 и Linkmeup_R3.
Linkmeup_R1:
Это позволяет нам обособить все данные одного клиента от других и от сети самого провайдера.
Здесь же указываем RD и RT. Поскольку задача у нас простая — связать все филиалы C3PO Electronic, то сделаем RD и RT совпадающими. Причём RT на Import и RT на Export тоже будут одинаковыми. Поскольку это обычная практика, существует даже специальная директива — both — тогда создаются оба RT сразу одинаковыми.
В 8-м выпуске мы выбрали номер AS для сети linkmeup — 64500. Он и используется в качестве административного поля.
Выделенный номер выбирается произвольно, но отслеживается, чтобы не было совпадения с другим, уже использованным.
5) Привязываем интерфейсы к VRF и указываем на них IP-адреса.
Linkmeup_R1:
В таблицах маршрутизации VRF C3PO должны появиться настроенные сети, как Directly connected. 
 6) Нужно поднять протокол маршрутизации с клиентом. В нашем случае это будет OSPF, хотя с равным успехом это мог бы быть и ISIS или EBGP. Данный процесс никак не должен пересекаться с глобальной таблицей маршрутизации, поэтому помещаем его в VRF:
6) Нужно поднять протокол маршрутизации с клиентом. В нашем случае это будет OSPF, хотя с равным успехом это мог бы быть и ISIS или EBGP. Данный процесс никак не должен пересекаться с глобальной таблицей маршрутизации, поэтому помещаем его в VRF:
Linkmeup_R1:
Учитывая, что у клиента OSPF уже настроен, мы должны увидеть адреса Loopback-интерфейсов в таблице маршрутизации. 
 Как видите, Linkmeup_R1 видит 192.168.255.1, но не видит удалённый Loopback – 192.168.255.2. Аналогично и Linkmeup_R3 видит только маршруты со своей стороны. Это потому, что через сеть провайдера пока не передаются маршруты клиента.
Как видите, Linkmeup_R1 видит 192.168.255.1, но не видит удалённый Loopback – 192.168.255.2. Аналогично и Linkmeup_R3 видит только маршруты со своей стороны. Это потому, что через сеть провайдера пока не передаются маршруты клиента.
7) Вот и пришло время MBGP.
Помните, мы говорили о BGP Free Core в прошлом выпуске? Этот приём мы вполне можем использовать и здесь. Нам без надобности BGP на Linkmeup_R2 — там и не будем его поднимать.
Первая часть — это базовая настройка соседей iBGP.
Linkmeup_R1:
Вторая часть — настройка Address Family VPNv4 — это то, что позволит с Linkmeup_R1 на Linkmeup_R3 передать клиентские маршруты. Заметьте, что мы активируем передачу community, потому что этот атрибут используется RT.
Linkmeup_R1:
Третья часть — это Address Family для данного конкретного VRF. Он работает с обычными IPv4 префиксами, но из VRF C3PO Electronic. Он нужен для того, чтобы передавать маршруты между MBGP и OSPF.
Linkmeup_R1:
Как видите, здесь настроен импорт маршрутов из процесса OSPF с номером 2.
Соответственно, нужно настроить и импорт маршрутов в OSPF из BGP:
Linkmeup_R1:
И вот теперь всё завертится, закрутится.
Маршруты на PE: 
 Маршруты на CE:
Маршруты на CE:  Пинг между клиентскими сетями:
Пинг между клиентскими сетями:  Попытка пинга провайдерской сети:
Попытка пинга провайдерской сети:  Вот и славно.
Вот и славно.
Подключение клиента по BGP
Теперь подключим клиента TAR’S Robotics. Маршруты между CE и PE будут передаваться по BGP или, иными словами, поднимаем EBGP с клиентским маршрутизатором.
Шаги 4 и 5 не будут отличаться. Приведём конфигурацию только одной стороны:
6) На CE EBGP настраивается самым обычным образом.
TARS_1:
Здесь указано, что TARS’ Robotics будет анонсировать свою сеть 172.16.255.1/32.
OSPF по-прежнему может быть нужен, но он уже будет использоваться для маршрутизации внутри этого филиала и только.
На PE всё то же самое, только не будет нового процесс OSPF (потому что с клиентом теперь EBGP, вместо OSPF) и меняется address family ipv4 vrf TARS:
Linkmeup_R1:
Теперь Linkmeup_R1 является BGP-соседом TARS_1:  Клиентские сети он получит сообщениями Update от CE.
Клиентские сети он получит сообщениями Update от CE.
7) Всё, что касается MBGP — то же самое. От того, что мы поменяли протокол взаимодействия с клиентом, в нём ничего не перевернётся.
То есть уже сейчас всё должно заработать (если, конечно, вторая сторона настроена):


 Полная конфигурация всех узлов с комментариями и без.
Полная конфигурация всех узлов с комментариями и без.
Что же мы натворили?
Давайте теперь проследим распространение меток.
Вот что передал Linkmeup_R1 узлу Linkmeup_R3.  Вы видите здесь метку 22 для FEC 192.168.255.1 и адрес Next Hop 1.1.1.1.
Вы видите здесь метку 22 для FEC 192.168.255.1 и адрес Next Hop 1.1.1.1.
Как её понимает маршрутизатор?
В ТМ VRF C3PO он заносит информацию о том, какой Next Hop:  Рекурсивно вычислить, как доступен 1.1.1.1:
Рекурсивно вычислить, как доступен 1.1.1.1:  Сервисную метку можно увидеть в таблице BGP для VRF C3PO:
Сервисную метку можно увидеть в таблице BGP для VRF C3PO:  Кстати, здесь же видно и Next Hop.
Кстати, здесь же видно и Next Hop.
Транспортная метка для FEC 1.1.1.1:  Но, как обычно FIB содержит всю актуальную информацию без многократных обращений к ТМ:
Но, как обычно FIB содержит всю актуальную информацию без многократных обращений к ТМ:  FIB говорит нам: упаковать пакет с DIP 192.168.255.1 в стек меток <17, 22>и отправить его в сторону 10.0.23.2 в интерфейс FE0/0.
FIB говорит нам: упаковать пакет с DIP 192.168.255.1 в стек меток <17, 22>и отправить его в сторону 10.0.23.2 в интерфейс FE0/0.
Всё тут предельно ясно и детерминировано.
Давайте подытожим шаги настройки L3VPN с нуля в правильном порядке от общего к частному.
Это были необходимые и достаточные действия для настройки базового L3VPN.
Ну и последний сценарий в рамках практики — это
Взаимодействие между VPN
Где-то там — далеко вверху — мы предположили существование некого третьего клиента — R2D2, у которого есть некоторые виды на C3PO — а конкретно они должны обмениваться маршрутами, находясь при этом в разных VPN.
Вот такая схема:
Здесь мы поработаем с RT — сделаем так, чтобы маршруты из VPN C3PO передавались в R2D2 протоколом BGP. Ну, и обратно — куда без этого?
Конфигурация маршрутизатора R2D2:
Настройка VRF на Linkmeup_R3:
Собственно ничего здесь нового нет, за исключением настройки route-target в VRF.
Как видите, кроме обычной команды «route-target both 64500:300» мы дали ещё и «route-target import 64500:100». Она означает, что в VRF необходимо импортировать маршруты с RT 645500:100, то есть из VPN C3PO, как мы этого и хотели.
Сразу после этого маршруты появляются на R2D2:  После этого пинг успешно проходит до 192.168.255.2:
После этого пинг успешно проходит до 192.168.255.2:  Но, если запустить пинг до адреса 192.168.255.1, то он не пройдёт. Почему?
Но, если запустить пинг до адреса 192.168.255.1, то он не пройдёт. Почему?  Для интереса вы можете добавить на TARS_2 Loopback 1 с адресом 10.20.22.22/32 — такой же, как у Loopback 0 R2D2 и посмотреть что из этого получится.
Для интереса вы можете добавить на TARS_2 Loopback 1 с адресом 10.20.22.22/32 — такой же, как у Loopback 0 R2D2 и посмотреть что из этого получится.
Полная конфигурация всех узлов для сценария взаимодействия между VPN.
Доступ из VPN в Интернет
Может статься, что провайдер в тот же самый VPN подаёт и доступ в Интернет. Именно в VPN, не отдельный кабель, не отдельный VLAN, а именно доступ в Интернет через то же самое подключение, через те же адреса. Это может быть также капризом заказчика.
Тема интересная, но большая, поэтому я раскрою её чуть позже в отдельном микровыпуске.
Трассировка в MPLS L3VPN
Около года назад у меня была небольшая статейка с каверзными вопросами.
Среди них был один очень для нас актуальный.
Пришло время разобрать его получше.
Если вдруг, вы не знали, как работает обычная трассировка, то стыд вам я вкратце расскажу.
Вы отправляете получателю пакеты с постепенно увеличивающимся значением TTL. Обычно это UDP, но может быть и ICMP и даже TCP.
Сначала это 1. Пакет доходит до непосредственно подключенного маршрутизатора, тот уменьшает TTL, видит, что теперь он равен нулю, формирует сообщение «time exceeded in transit» и посылает его вам обратно. Так по адресу отправителя вы знаете первый хоп.
Потом это 2. Пакет доходит до второго маршрутизатора. Происходит то же самое, так вы узнали следующий хоп.
… Наконец TTL достигает N, узел назначения получает пакет, видит, что это к нему, формирует ответ (в соответствии с протоколом), по которому вы понимаете, что всё, кончено, и концы в консоль.
Кроме того, можно добавить, что на каждой итерации вы посылаете не один, а несколько пакетов (как правило, три).
В чём же особенность трассировки через L3VPN?
Пока пакет коммутируется по меткам значения каких-бы то ни было полей любых заголовков глубже MPLS не имеют никакого значения. В том числе и TTL. Маршрутизаторы ориентируются на TTL в заголовке MPLS.
И вот когда PE получает пакет от CE, есть два варианта:
В первом сценарии вы сможете увидеть каждый маршрутизатор на пути к получателю. Результат трассировки будет таким:  Механика же следующая:
Механика же следующая:
А что, если у меня есть закономерное желание, чтобы клиенты не видели топологию моей сети своими трассировками? Надо запретить, скажете вы. Как отец двухгодовалой дочки, я вам говорю: не нужно запрещать. Можно и нужно поступить хитрее – я просто не буду внутри своей сети уменьшать TTL MPLS до нуля. Для этого используется второй сценарий — установить TTL MPLS в 255. В этом случае при трассировке с TARS_1 вы увидите следующий путь: R1↔R3↔TARS_2. 
И сколько бы ни было транзитных P-маршрутизаторов, TTL=3 будет достаточно всегда при трассировке с TARS_1 на TARS_2.
Поведение по умолчанию различается у вендоров.
Циска считает, что инженер знает, что делает и чем ему грозит каждое действие, поэтому выбирает первый путь, а, например, Хуавэй предпочитает перестраховаться — лучше сначала запретить, дабы чего не вышло, а потом инженер разрешит при необходимости.
Как бы то ни было, режим всегда можно поменять — в нашем случае в режиме глобальной конфигурации нужно для этого дать команду «no mpls ip propagate-ttl».
Замечательный пятидесятитрёхстраничный документ по трассировке на nano.org.
Кстати, для MPLS есть особенные утилиы пинга и трассировки.
Замечательная глава Вопросы и Ответы. Мне очень нравится, потому что сюда можно засунуть всё, чему не хватило места в основной статье.
В1: Можно ли говорить, что P — это Intermediate LSR, а PE — это LER?
Строго говоря, нет. Как минимум, потому что понятия LER, LSR — это базовый MPLS и касаются LSP, а P, PE, CE — только в VPN.
Хотя, конечно, обычно тот узел, к которому подключен клиент, выполняет и роль Ingress/Egress LSR в MPLS и роль PE в VPN.
В2: Почему MBGP — это MultiProtocol BGP, а не, например, MPLS BGP? Что в нём многопротокольного?
Задача BGP — передавать маршруты. Исторически и классически — это IPv4. Но помимо обычных префиксов BGP может передавать и массу других: IPv6, IPX, Multicast, VPN. Каждый тип префиксов настраивается как отдельный Address Family — то есть группа адресов одного типа. Собственно вот за эту возможность передавать маршрутные данные разных протоколов такой BGP и получил имя MBGP.
В3: Где передаются сами маршруты, RD и их атрибуты в MBGP?
RD является частью VPNv4-маршрута и вместе с ним передаётся в секции NLRI — Network Layer Reachability Information. RT передаётся в секции Extended Community, поскольку им и является по своей сути.
Вообще многие атрибуты VPN-маршрута в сообщении BGP Update вынесены в специальную секцию — MP_REACH_NLRI, частью которого являются привычные NLRI и Next-Hop.
В4: Так в чём всё-таки разница между RD и RT? Почему недостаточно только одного из них? И я правильно понял: RD не является идентификатором VPN, как и RT?
Да, ни RD, ни RT однозначно не идентифицируют VPN. Как для одного VPN на разных маршрутизаторах могут быть настроены разные RD/RT, так и для двух разных теоретически могут быть одинаковые RD/RT.
Ещё раз:
RD — Route Distinguisher — его основная и единственная задача — сделать так, чтобы маршруты не смешались в MBGP — два одинаковых маршрута из разных VPN должны быть таки двумя разными маршрутами. RD не говорит PE, куда нужно экспортировать маршрут и существует/работает только при передаче маршрута.
RT — Route Target. Он не помогает разделить маршруты разных VPN, но он позволяет экспортировать их в те VRF, в которые надо. То есть он имеет значение в момент импорта маршрута из VRF в самом начале и в момент экспорта в VRF на другом конце в самом конце. Передаётся в Extended Community.
Одного RD не хватит, потому что PE не будут знать, как правильно распорядиться маршрутами.
А одного RT не хватит, потому что маршруты смешаются при передаче и потеряются все, кроме одного.
Можно было бы оставить только RD, например, и на его основе решать, куда маршрут передать, но это и не гибко и идёт в разрез с принципами BGP.
В5: Молодой, человек, мы крупный оператор, мы занимаемся серьёзными вещами — строим Adnvanced LTE, пока поддерживаем 2G, у нас нет клиентов, которые хотят VPN, ваша гигантская статья бесполезна для нас.
Вовсе не зря. Как минимум ещё одно применение — это разделение своих собственных услуг в пределах своей же сети.
Например, если вы оператор сотовой связи и предоставляете услуги в сетях 2G, 3G, 4G и строите уже вовсю 5G, то свою сеть Mobile Backhaul (MBH) вы можете разбить на 5 VPN: по одной для каждого поколения радиосвязи и одну для сети управления элементами. Это позволит к каждой сети применять свои правила маршрутизации, качества обслуживания, политики обработки трафика. А если совместить это ещё и с Traffic Engineering…
Причём тут даже не надо будет настраивать взаимосвязь между VPN в пределах MBH — каждая сеть изолирована от абонента до Core Network: у 2G в ядре стоит BSC, у 3G — RNC, у 4G — MME. И только в ядре сети на специальном маршрутизаторе или файрволе можно их скрестить.
А вот ещё пример: столь популярная ныне технология MVNO — Mobile Virtual Network Operator — когда одна сеть MBH используется для двух и более операторов. Здесь уже однозначно нужно будет разделятьи властвовать.
Но как ни крути, да, MPLS VPN — это всё-таки преимущественно игрушка больших воротил телекома или интерпрайза.
В6: Не возьму в толк: как Egress PE, получив пакет с одной меткой, то есть если произошёл PHP, определяет что эта метка VPN, а не транспортная, и, соответственно, что по метке нужно передать его в VRF, а не скоммутировать куда-то дальше?
Всё очень просто — пространство меток для VPN, для LSP, для всевозможных FRR и CSC — общее. Не может быть такого, что для VPN и для LSP была выделена одна и та же метка. Ну а каждой метке при её создании ставится в соответствие её роль и действия при её получении.
Полезные ссылки
Не устаю говорить, что все термины и сокращения, использованные в статье, вы можете найти в глоссарии lookmeup. Ладно, я лукавлю: не все, а лишь большинство
Горячо мной любимый Джеф Дойл: VPN в двух частях: Part I, Part II.
О различиях RD и RT пишет Jeremy Stretch: Route Distinguishers and Route Targets.
Как вы могли заметить, создание L3VPN — это большое количество ручной работы. И в случае необходимости организовать взаимодействие между VPN, придётся настроить не только один Интернет-шлюз даже в самом правильном и красивом способе, но и клиентские PE.
Но вся эта работа необходима, здесь нет избыточности. Для контраста вспомните, во что бы вам встала настройка, VPN с помощью GRE или VRF-Lite.
И обратите внимание, маршрутизатор P — Linkmeup_R2 — оставался абсолютно неизменным в течение всех стадий настройки с момента первоначального включения на нём MPLS. Это ли не прелестно?!
Нельзя сказать, что этой небольшой статьёй мы объяли весь L3VPN, в частности остались за пределами общей картины такие интереснейшие вещи, как Inter-AS VPN, коих 3 вида, и CSC (Carrier Support Carrier). Но я надеюсь конкретно по этим двум механизмам написать отдельную статью.
L3VPN — вещь зрелая, продуманная и стандартизированная. У всех производителей она работает плюс/минус одинаково.
А вот впереди ещё статья про L2VPN, которая включит в себя AToM, VLL, PWE3 и VPLS. В ней узнаем, какую роль сыграли Cisco и Juniper в развитии этого направления, какие радости в нашу жизнь привносят такие услуги, как CES или EoMPLS. Наберитесь терпения — в этом году я постараюсь увеличить темпы, набрать обороты, раскрутиться и увеличить КПД.
Иллюстратор проекта — Анастасия Мецлер.
За помощь в подготовке статьи, спасибо JDima.



