15 топовых веб скрапинг решений 2021 года
Веб скрапинг позволяет компаниям автоматизировать процессы сбора веб данных с помощью ботов или автоматизированных скриптов, называемых веб-сканерами и загружать эти данные в формате Excel, CSV или XML для последующей аналитики.
Представляем вашему вниманию список топ 15 инструментов для парсинга 2021 года.
Scraper API
Scraper API позволяет получить содержимое HTML с любой страницы с помощью вызова API. С Scraper API можно с легкостью работать с браузерами и прокси-серверами и обходить проверочные код CAPTCHA. Единственное на что необходимо сосредоточиться это превращение веб-сайтов в ценную информацию. С этим иснтрументом практически невозможно быть заблокированным, так как он меняет IP-адреса при каждом запросе, автоматически повторяет неудачные попытки и решает капчу за вас.
Octoparse
Octoparse это бесплатный инструмент предназначенный для веб скрапинга. Он позволяет извлекать данные с интернета без строчки кода и превращать веб-страницы в структурированные данные всего за один клик. Благодаря автоматической ротации IP-адресов для предотвращения блокировки и возможности планирования последующего скрапинга этот инструмент является одним из самых эффективных.
DataOx
DataOx— настоящий эксперт в области скрапинга веб-страниц. Инструменты предлогаемые компанией DataOx обеспечивают крупномасштабные сборы данных и предоставляют комплексные решения адаптированные к потребностям клиентов. Этой компании могут доверять как стартапы, создающие продукты на основе данных, так и большие предприятия, которые предпочитают поручать сбор собственных данных профессионалам.
ScrapingBot
Scraping-Bot.io предлагает мощный API для извлечения HTML-содержимого. Компания предлагает API-интерфейсы для сбора данных в области розничной торговли (описание продукта, цена, валюта, отзыв) и недвижимости (цена покупки или аренды, площадь, местоположение). Доступные тарифные планы, JS-рендеринг, парсинг с веб-сайтов на Angular JS, Ajax, JS, React JS, а также возможность геотаргетинга делают этот продукт незаменимым помощником для сбора данных.
Wintr
Wintr это API для парсинга веб-страниц, использующий вращающиеся резидентные прокси, позволяющий извлекать и анализировать любые данные доступные в сети. Простой в использовании и полностью настраиваемый Wintr включает множество инструментов для сбора данных даже с самых сложных веб-сайтов. Например, можно легко извлечь содержимое с общедоступной веб-страницы с помощью ротационного IP-адреса или автоматизировать аутентификацию с помощью Javascript рендеринга, а затем извлечь личные данные с помощью файлов cookie и постоянного IP-адреса.
Import.io
Webhose.io
Webhose.io это расширенный API сервис для извлечения веб данных в реальном времени. Это инструмент очень часто изпользуют для извлечения исторических данных, мониторинга СМИ, бизнес-аналитики, финансового анализа, а также для академических исследований.
ParseHub
Mozenda
Mozenda это корпоративное программное обеспечение разработанное для всех видов задач по извлечению данных. Этой компании доверяют тысячи предприятий и более 30% компаний из списка Global Fortune 500. Это один из лучших инструментов для парсинга веб-страниц, который поможет за считанные минуты создать скрапер агента. Mozenda также предлагает функции Job Sequencer and Request Blocking для сбора веб-данных в реальном времени и лучший сервис для работы с клиентами.
Diffbot
Diffbot автоматизирует извлечение веб-данных с помощью искусственного интеллекта и позволяет легко получать различные данные с любого сайта. Вам не нужно платить за дорогостоящий парсинг веб-страниц или делать это в ручную.
Этот инструмент поможет увеличить объем скрапинга до 10 000 доменов, а функция Knowledge Graph предоставит точные, полные и подробные данные с любого интернет источника.
Luminati
Luminati предлагает инструмент для сбора данных нового поколения, который позволяет получать автоматизированный и настраиваемый поток данных с помощью одной простой панели управления. Необходимо только отправить запрос, а всем остальным: IP-адресами, заголовками, файлами cookie, капча будет управлять система. С Luminati вы получите структурированные данные с любого веб-сайта, от тенденций в электронной коммерции и данных с социальных сетей до исследований рынка и конкурентной разведки.
FMiner
FMiner это программное обеспечение для парсинга веб-страниц, извлечения веб-данных, веб-сканирования и поддержки веб-макросов для Windows и Mac OS X. Этот простой в использовании инструмент извлечения данных сочетает в себе лучшие в своем классе функции от простых задач до комплексных проектов по извлечению данных, требующими ввода форм, списков прокси-серверов, обработки Ajax и многоуровневого сканирования веб страниц.
Outwit
Data streamer
Data Streamer помогает получать контент из социальных сетей. Это один из лучших веб-парсеров, который позволяет извлекать важные метаданные с помощью NLP. Встроенный полнотекстовый поиск на базе Kibana и Elasticsearch и простая в использовании и всеобъемлющая консоль администратора обеспечивает эффективный сбор необходимой информации.
Веб-скрапинг для веб-разработчиков: краткие сведения

Для извлечения данных с веб-страницы существует множество решений и инструментов. Каждый метод обладает своими сильными и слабыми сторонами, знание которых сохранит время и повысит эффективность решения задач.
С помощью каких способов можно извлечь данные с веб-страницы?
Каковы плюсы и минусы каждого подхода?
Как использовать облачные сервисы для повышения уровня автоматизации?
Ответы на эти вопросы можно найти в этом руководстве.
Если вы не знакомы с базовыми понятиями работы браузеров, такими как HTTP-запросы, DOM (Document Object Model), HTML, CSS-селекторы и Async JavaScript, то изучите их, прежде чем продолжить чтение этой статьи. Примеры реализованы в Node.js, однако эту теорию можно использовать и для других языков.
Статическое содержимое
HTML source
Начнем с самого простого подхода. Он не требует большого количества вычислительной мощности и много времени на реализацию.
Однако он работает только в том случае, если исходный HTML-код содержит необходимые данные. Для проверки в Chrome нажмите правой кнопкой мыши и выберите View page source. Отобразится исходный код HTML.
Стоит отметить, что при использовании inspect tool в Chrome отобразится структура HTML, связанная с текущим состоянием страницы. Она не всегда совпадает с исходным HTML-документом, который можно получить с сервера.
После того, как вы найдете данные, напишите CSS-селектор, принадлежащий элементу wrapping. В дальнейшем вы будете ссылаться на него.
Для реализации отправьте запрос HTTP GET к URL-адресу страницы. Вы получите исходный HTML-код.
В Node можно использовать инструмент под названием CheerioJS для парсинга raw HTML и извлечения данных с помощью селектора. Код выглядит следующим образом:
Динамическое содержимое
В большинстве случаев невозможно получить доступ к информации из кода raw HTML, поскольку DOM находится под управлением JavaScript, который выполняется в фоновом режиме. К примеру, в SPA (Single Page Application) HTML-документ содержит минимальное количество информации, а JavaScript заполняет ее во время выполнения.
Чтобы решить эту проблему, нужно создать DOM и запустить сценарии, находящиеся в исходном HTML-коде, так же, как это происходит в браузере. В результате, данные из этого объекта можно извлечь с помощью селекторов.
Headless-браузеры
Headless-браузер очень схож с обычным браузером, однако в нем отсутствует пользовательский интерфейс. Он работает в фоновом режиме и может контролироваться с помощью программы.
Среди headless-браузеров самым популярным является Puppeteer. Это простая в использовании библиотека Node, предоставляющая высокоуровневый API для контроля Chrome в headless-режиме. Его можно настроить для работы в non-headless-режиме, что очень пригодится при разработке. Следующий код выполняет те же действия, что и предыдущий, но работает с динамическими страницами:
Чтобы узнать больше о Puppeteer, посмотрите документацию. Фрагмент кода, с помощью которого можно перейти в URL, сделать скриншот и сохранить его:
Запуск браузера требует намного больше вычислительной мощности, чем отправка простого запроса GET и парсинг ответа. Следовательно, выполнение относительно более медлительно и энергозатратно. Помимо этого, включение браузера в качестве зависимости увеличивает размер пакета развертывания.
С другой стороны, этот метод очень гибкий. Его можно использовать для навигации по страницам, моделирования кликов, движений мышки и событий от клавиатуры, заполнения форм, скриншотов и генерирования PDF-страниц, выполнения команд в консоли, а также выбора элементов для извлечения их текстового содержимого. По сути, все действия, выполняемые в браузере вручную.
Создание DOM
Возможно, вы подумаете, что не стоит моделировать браузер целиком только для создания DOM. И вы правы. По крайней мере, при определенных обстоятельствах.
Библиотека Node под названием Jsdom выполняет парсинг HTML так же, как и браузер. Однако это не браузер, а инструмент для создания DOM из исходного кода HTML, одновременно выполняющий код JavaScript в этом HTML.
Благодаря абстракции, Jsdom работает быстрее, чем headless-браузер. Раз он быстрее, то почему бы не использовать его вместо headless-браузеров всегда?
Отрывок из документации:
При использовании jsdom часто возникают проблемы с асинхронной загрузкой сценариев. Многие страницы загружают сценарии асинхронно, однако невозможно определить, в какой момент это происходит, и следовательно, когда нужно запустить код и проверить полученную структуру DOM. Это основное ограничение.
… Его можно обойти с помощью проверки наличия определенного элемента.
Решение отображено в примере. Каждые 100 мс проверяется, появился ли элемент или произошел тайм-аут (через 2 секунды).
Также, если какая-либо функция браузера на странице не реализуется Jsdom, то появляются сообщения об ошибке. Например: “Error: Not implemented: window.alert…” или “Error: Not implemented: window.scrollTo…”. Эту проблему можно решить с помощью workarounds (virtual consoles).
В целом, это низкоуровневый API, по сравнению с Puppeteer, поэтому некоторые действия нужно реализовывать вручную.
Как видно из примера, все это усложняет его использование. Puppeteer решает эти проблемы за кадром и максимально упрощает использование. А Jsdom предложит быстрое решение для дополнительной работы.
Рассмотрим предыдущий пример, но с использованием Jsdom:
Обратная разработка
Jsdom — это быстрое и простое решение, однако можно найти более легкий подход.
Нужно ли вообще моделировать DOM?
Как правило, веб-страница, из которой нужно извлечь данные, состоит из HTML, JavaScript и других общеизвестных технологий. Таким образом, если найти кусочек кода, из которого получены необходимые данные, можно повторить ту же операцию для получения того же результата.
Проще говоря, этими данными могут быть:
Доступ к этим источникам данных можно получить с помощью сетевых запросов. С нашей точки зрения, не имеет значения, использует ли веб-страница HTTP, WebSockets или любой другой протокол связи, поскольку все они воспроизводимы в теории.
После нахождения ресурса, содержащего данные, можно отправить аналогичный сетевой запрос к тому же серверу, как и в исходной странице. В результате вы получаете ответ, содержащий необходимые данные, которые можно с легкостью извлечь с помощью регулярных выражений, методов string, JSON.parse и т. д.
Проще говоря, можно просто взять ресурс, в котором расположены данные, вместо того, чтобы обрабатывать и загружать все сразу. Таким образом, проблема, показанная в предыдущих примерах, решается с помощью одного HTTP-запроса.
В теории это решение выглядит простым, однако в большинстве случаев его выполнение занимает много времени и требует опыта работы с веб-страницами и серверами.
Поиски можно начать с наблюдения за сетевым трафиком. Для этого есть отличный инструмент Network tab в Chrome DevTools. Он отобразит все исходящие запросы с ответами (включая статические файлы, запросы AJAX и т. д.), которые можно просмотреть в поисках данных.
Процесс может замедлиться, если ответ был изменен фрагментом кода перед отображением на экране. В этом случае, нужно найти этот кусочек кода и разобраться, в чем дело.
Как можно заметить, это решение может потребовать еще больше работы, чем предыдущие методы. С другой стороны, после реализации оно предоставляет наилучшую производительность.
Этот график отображает необходимое время выполнения и размер пакета в сравнении с Jsdom и Puppeteer:
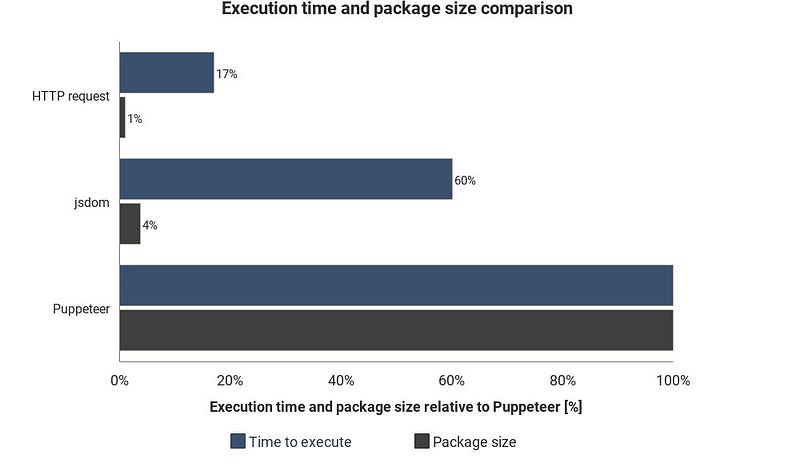
Результаты могут варьироваться в зависимости от ситуации, они лишь показывают примерную разницу между этими техниками.
Интеграция облачного сервиса
Допустим, вы реализовали одно из перечисленных решений. Один из способов выполнения сценария — включить компьютер, открыть терминал и запустить его вручную.
Однако все можно упростить, загрузив сценарий на сервер. Он будет выполнять код систематически в зависимости от настроек.
Это можно сделать, запустив сервер и настроив параметры выполнения сценария. Сервера светятся при наблюдении за элементом на странице. В других случаях облачная функция, вероятно, является более простым способом.
Облачные функции — это контейнеры, предназначенные для выполнения загруженного кода при появлении определенного события. Это означает, что не нужно управлять серверами, все выполняется автоматически с помощью выбранного облачного провайдера.
Возможным инициатором может быть программа, сетевой запрос и любые другие события. Полученные данные можно сохранить в базе данных, записать в Google sheet или отправить на email. Все зависит от вашей фантазии.
Популярные облачные провайдеры: Amazon Web Services (AWS), Google Cloud Platform (GCP) и Microsoft Azure. Все они обладают сервисной функцией:
Google’s Cloud Functions — лучшее решение при использовании Puppeteer. Размер сжатого пакета Headless Chrome (
130MB) превышает лимит максимального сжатого размера AWS Lambda (50MB). Есть несколько техник выполнения для Lambda, однако функции GCP поддерживают headless Chrome по умолчанию. Нужно просто включить Puppeteer в качестве зависимости в package.json.
Вывод
Для реализации каждого решения вам понадобится заглянуть в документацию и прочитать несколько статей. Однако я надеюсь, что вы получили базовое представление о техниках, используемых для сбора данных с веб-страниц и продолжите дальнейшее изучение.
Руководство по вэб-скрепингу на Python: приёмы и хитрости

Jul 22, 2018 · 7 min read

Как-то я хотела купить авиабилеты и заметила, что цены изменяются несколько в течение дня. Я попыталась выяснить, когда наступает самый лучший момент для покупки билетов, но не нашла в Интернете ничего, что бы могло мне помочь решить эту задачу. Тогда я написала небольшую программу для автоматического сбора данных в Интернете — так называемую программу скрепинга. Программа извлекла информацию по моему запросу для определенного пункта назначения на выбранные мной даты и показала мне, когда стоимость становится минимальной.
Веб-скрепинг — это метод автоматизированного извлечения данных с веб-сайтов.
Я и м ею большой опыт веб-скрепинга и хочу с вами поделиться.
Этот пост предназначен для тех, кому интересно узнать об общих шаблонах проектирования, подвохах и правилах, связанных с веб-скрепингом. В статье представлено несколько реальных примеров и перечень типовых задач, таких как, например, что делать, чтобы вас не обнаружили, что можно делать, а что не следует и, наконец, как ускорить работу вашего скрепера с помощью распараллеливания.
Все примеры будут сопровождаться фрагментами кода на Python, так что вы можете сразу же ими воспользоваться. В этом материале также будет показано, как привлекать к работе полезные пакеты Python.
Реальные примеры
Существует различные причины и варианты необходимости использования сбора (скрэпинга) данных в Интернете. Позвольте мне перечислить некоторые из них:
Руководство
Прежде чем мы приступим: БУДЬТЕ аккуратны с серверами; вы же НЕ ХОТИТЕ сломать вэб-сайт.
1. Известные пакеты и инструменты
Для веб-скрэпинга нет универсального решения, поскольку способ, с помощью которого хранится на каждом из веб-сайтов обычно специфичны. На самом деле, если вы хотите собрать данные с сайта, вам необходимо понять структуру сайта и, либо создать собственное решение, либо воспользоваться гибким и перенастраиваемым вариантом уже готового решения.
Изобретать колесо здесь не нужно: существует множество пакетов, которые скорее всего, вам вполне подойдут. В зависимости от ваших навыков программирования и предполагаемого варианта использования вы можете найти разные более или менее полезные для себя пакеты.
1.1 Проверяем параметры
Чтобы вам было проще проверять HTML-сайт, воспользуйтесь опцией инспектора в вашем вэб-браузере.

Раздел веб-сайта, который содержит мое имя, мой аватар и мое описание, называется hero hero—profile u-flexTOP (любопытно, что Medium называет своих писателей героями:)). Класс
Вы можете более подробно познакомиться с HTML-тэгами и различиями между классами и id здесь.
В моем случае я воспользовалась готовым методом «из коробки»: я просто хотела извлечь ссылки со всех страниц, получить доступ по каждой ссылке и извлечь из нее информацию.
1.3 BeautifulSoup с библиотекой Request
Я выбрала BeautifulSoup, поскольку эта библиотека помогла мне понять сколько всего Scrapy может делать самостоятельно и, я надеюсь, помогла мне быстрее научиться на своих собственных ошибках.
2. Основной программный код
Примечание: элемент discounted_price является необязательным.
3. Распространенные ошибки
3.1 Check robots.txt
3.2 HTML может быть злом
HTML-теги могут содержать идентификатор (id), класс или сразу оба этих элемента. Идентификатор (т.е. id) HTML описывает уникальный идентификатор, а класс HTML не является уникальным. Изменения в имени или элементе класса могут либо сломать ваш код, либо выдать вам неправильные результаты.
Есть два способа избежать, или, по крайней мере, предупредить это:
Однако, поскольку некоторые поля могут быть необязательными (например, discounted_price в нашем HTML-примере), соответствующие элементы не будут отображаться в каждом списке. В этом случае вы можете подсчитать процентное соотношение частоты возврата None конкретным элементом в списке. Если это 100%, вы, возможно, захотите проверить, было ли изменено имя элемента.
3.3 Обмануть программу-агент
Каждый раз, когда вы посещаете веб-сайт, он получает информацию о вашем браузере через пользовательский агент. Некоторые веб-сайты не будут показывать вам какой-либо контент, если вы не предоставите им пользовательский агент. Кроме того, некоторые сайты предлагают разные материалы для разных браузеров. Веб-сайты не хотят блокировать разрешенных пользователей, но вы будете выглядеть подозрительно, если вы отправите 200 одинаковых запросов в секунду с помощью одного и того же пользовательского агента. Выход из этой ситуации может заключаться в том, чтобы сгенерировать (почти) случайного пользовательского агента или задать его самостоятельно.
3.4 Время ожидания запроса
По умолчанию Request будет продолжать ожидать ответ в течение неопределенного срока. Поэтому рекомендуется установить параметр таймаута.
Частое появление кодов состояния, таких как 404 (не найдено), 403 (Запрещено), 408 (Тайм-аут запроса), может указывать на то, что вы заблокированы. Вы можете проверить эти коды ошибок и действовать соответственно.
Кроме того, будьте готовы обработать исключения из запроса.
Даже если вы рандомизировали своего пользовательского агента, все ваши запросы будут отправлены с одного и того же IP-адреса. Это вполне нормально, поскольку библиотеки, университеты, а также компании имеют всего несколько IP-адресов. Однако, если очень много запросов поступает с одного IP-адреса, сервер может это обнаружить.
Использование общих прокси, VPN или TOR может помочь вам стать незаметным;)
Если вы используете общий прокси-сервер, веб-сайт увидит IP-адрес прокси-сервера, а не ваш. VPN соединяет вас с другой сетью, а IP-адрес поставщика VPN будет отправлен на веб-сайт.
3.7 Ловушки для хакеров
Ловушки для хакеров — это средства для обнаружения сканеров или скреперов.
Другой способ обнаружить хакеров — это добавить ссылки с бесконечно глубокими деревьями директорий. В этом случае вам нужно ограничить количество загруженных страниц или ограничить глубину обхода.
4. Общие правила
Опять таки, не перегружайте веб-сайт, отправляя сотни запросов в секунду.
5. Ускорение ‑ распараллеливание
Если вы решитесь на распараллеливание своей программы, будьте осторожны с реализацией, чтобы не “свалить” сервер. Обязательно прочитайте раздел « Распространенные ошибки», приведенный выше. Ознакомьтесь с определениями параллельного и последовательного выполнения, процессоров и потоков здесь и здесь.
Если вы извлекаете большое количество информации со страницы и выполняете некоторую предварительную обработку данных, количество повторных запросов в секунду, которое вы отправляете на страницу, может быть относительно низким.
В своем другом проекте я собирала цены на аренду квартиры и сделала для этого довольно сложную предварительную обработку данных, в результате чего мне удалось отправлять только один запрос в секунду. Чтобы собрать объявления размером в 4K, моя программа должна проработать около часа.
Чтобы отправлять запросы параллельно, вы можете воспользоваться пакетом multiprocessing.
Я назначила 1K страниц для каждого из 4-х процессоров, имевшихся у меня в распоряжении, в результате было создано 4 повторных запроса в секунду, что сократило время сбора данных моей программой до 17 минут.
Как заработать на веб-скрапинге
А вы знали о том, что то, что вы сейчас читаете, это — данные? Вы видите слова, но на серверах всё это хранится в виде данных. Эти данные можно куда-то скопировать, можно разобраться в их структуре, с ними можно сделать что-то ещё. Собственно говоря, только что мы привели упрощённое описание веб-скрапинга. Скраперы просматривают код, из которого созданы веб-сайты (HTML-код), или работают с базами данных, и вытаскивают отовсюду те данные, которые им нужны. Практически каждый веб-сайт можно подвергнуть скрапингу. На некоторых сайтах применяются особые меры, которые мешают работе веб-скраперов. Но тот, кто достаточно хорошо знает своё дело, способен успешно собрать данные с 99% существующих сайтов.

Если вы не знали о том, что такое веб-скрапер, то теперь вы, в общих чертах, об этом знаете. А это значит, что мы можем заняться тем, ради чего вы, вероятно, начали читать эту статью. Мы сможем приступить к разговору о заработке на скрапинге. Такой заработок, кстати, не так сложен, как может показаться на первый взгляд. На самом деле, все методы и примеры, которые я собираюсь вам показать, укладываются в менее чем 50 строк кода. А изучить всё это можно буквально за несколько часов. Собственно говоря, полагаю, что сейчас вы вполне готовы к тому, чтобы узнать о трёх способах заработка с помощью веб-скрапинга.
Способ №1: создание ботов
«Бот» — это всего лишь технический термин, обозначающий программу, которая способна что-то делать. Такую программу можно создать и продать тому, кому нужно автоматизировать то, что умеет программа.
Для того чтобы продемонстрировать вам технологию разработки и продажи ботов, я создал бота для Airbnb. Этот бот позволяет пользователям вводить данные о некоем городе и возвращает сведения обо всех жилищах, которые в этом городе предлагает Airbnb. Сюда входят данные о цене, рейтинге, о количестве постояльцев, которое может принять дом, о количестве спален, кроватей, ванных комнат. И всё это делается благодаря применению технологий веб-скрапинга при сборе данных из постов, размещаемых на сайте Airbnb.
Для того чтобы показать этого бота в действии, я собираюсь узнать с его помощью о том, что можно снять в Риме, в Италии. Я передаю боту соответствующие данные, а он, за секунды, находит 272 уникальных предложения и оформляет их в виде удобного Excel-листа.

Теперь с такими данными работать гораздо легче, чем на сайте. Можно, например, сравнить разные жилища и их особенности. Кроме того, эти данные удобно фильтровать. В моей семье 4 человека. Если мы соберёмся в Рим, то нам понадобится Airbnb-жильё с как минимум 2 кроватями, отличающееся адекватной ценой. Благодаря тому, что все данные собраны в удобном формате, в Excel, с ними можно весьма продуктивно работать. Как оказалось, моим нуждам удовлетворяют 7 результатов из 272.

Среди этих 7 результатов я выбрал бы жильё Vatican St.Peter Daniel. У него очень хороший рейтинг и, из 7 найденных результатов, оно самое дешёвое ($67 за ночь). После того, как я нашёл то, что меня заинтересовало, я могу взять соответствующую ссылку из таблицы, открыть её в браузере и забронировать жильё.
Поиск жилища, в котором можно остановиться в путешествии, может оказаться непростой задачей. Я уверен, что все с этим сталкивались. Именно поэтому есть люди, которые, ради упрощения этого процесса, готовы платить. Мне удалось упростить поиск жилья с помощью созданного мной бота. Только что я продемонстрировал вам то, как я всего за 5 минут нашёл именно то, что мне нужно.
Люди готовы платить за то, что хотя бы немного облегчает им жизнь.
Способ №2: перепродажа товаров, купленных с хорошими скидками
Один из наиболее распространённых способов использования веб-скрапинга заключается в сборе с различных сайтов информации о ценах товаров. Есть люди, которые создают скраперов, запускающихся ежедневно и собирающих цены на конкретный товар. Когда цена на товар упадёт до определённого уровня, программа автоматически покупает товар, стремясь сделать это до того, как этот товар окажется распроданным. Затем, так как спрос на товар будет выше предложения, тот, кто до этого купил товар по низкой цене, перепродаёт его по более высокой цене и получает прибыль. Это — пример лишь одной из тактик перепродажи товаров, купленных по низким ценам, которой пользуются создатели веб-скраперов.
Ещё одна схема, пример которой я сейчас продемонстрирую, может помочь вам хорошо сэкономить или достойно заработать.
Применим эти рассуждения к анализу цен на товары в универсальном интернет-магазине Hudson’s Bay. У них постоянно бывают распродажи товаров самых разных марок. Мы, пользуясь технологиями веб-скрапинга, собираемся найти товары с самыми высокими скидками.
После обработки сайта скрапер выдал более 900 товаров, и, как можно заметить, среди них есть всего один, скидка на который превышает 50%. Это — товар Perry Ellis Solid Non-Iron Dress Shirt.
Этот метод, если найти подходящую нишу, способен помочь в заработке серьёзных денег.
Способ №3: сбор и продажа данных
В интернете море бесплатных, доступных каждому данных. Часто эти данные довольно легко собирать, а значит, они легко доступны тем, кто хочет их как-то использовать. Но, с другой стороны, есть данные, собрать которые не так уж и легко. Для их сбора и представления в виде аккуратного набора данных может понадобиться либо много времени, либо много работы. Это стало основой развития рынка продажи данных. Существуют компании, которые занимаются только тем, что собирают данные, которые может быть непросто собрать. Они приводят эти данные в приличный вид, возможно, делают интерфейсы для работы с такими данными, и, за определённую плату, дают работать с этими данными тем, кому они нужны.
А я сейчас хочу рассказать о том, как получить те же данные, которые продаются на BigDataBall, совершенно бесплатно, и о том, как сформировать из них аккуратно оформленный набор данных, напоминающий те наборы, которые я уже вам показывал.
Как я уже говорил, доступ к данным, которые продаёт сайт BigDataBall, есть не только у этого сайта. Например, на сайте basketball-reference.com размещены те же данные, но они не структурированы и не сгруппированы. То есть — работать с ними неудобно, их нельзя просто загрузить, сформировав из них необходимый кому-то набор данных. Именно тут нам на помощь и приходит веб-скрапинг. А именно, я хочу собрать с сайта журналы игроков и оформить всё это в виде структурированного набора данных, напоминающего наборы данных BigDataBall. Ниже показан результат сбора данных
Не стоит и говорить, что вы вполне можете заниматься тем же самым, чем занимаются сотрудники BigDataBall. А именно: находить данные, которые сложно собирать вручную, собирать их с помощью компьютера и продавать их тем, кто хочет получить их в удобном для работы виде.
Итоги
Веб-скрапинг — это весьма интересный современный способ заработка. Если правильно воспользоваться технологиями веб-скрапинга, это может принести немалые деньги. И это гораздо проще, чем многие думают.



