Функции XPath для динамических XPath в Selenium
Будущих студентов курса «Java QA Automation Engineer» и всех интересующихся приглашаем посмотреть подарочное демо-занятие в формате открытого вебинара.
А также делимся переводом полезной статьи.
В данной статье рассматриваются примеры использования функций XPath для идентификации элементов.
Автоматизация взаимодействия с любым сайтом начинается с корректной идентификации объекта, над которым будет выполняться какая-либо операция. Как нам известно, легче всего идентифицировать элемент по таким атрибутам, как ID, Name, Link, Class, или любому другому уникальному атрибуту, доступному в теге, в котором находится элемент.
Но правильно идентифицировать объект можно только в том случае, если такие атрибуты присутствуют и (или) являются уникальными.
Чему вы научитесь: [показать]
Обзор функций XPath
Обсудим сценарий, при котором атрибуты недоступны напрямую.
Постановка задачи
Как идентифицировать элемент, если такие локаторы, как ID, Name, Class и Link, недоступны в теге элемента?
Суть проблемы демонстрирует следующий пример:
Плагин Firepath для Firefox сгенерировал следующий путь XPath:
Мы бы не рекомендовали использовать указанный выше путь XPath, поскольку структура страницы или id могут меняться динамически. Если все же использовать этот нестабильный XPath, вероятно, потребуется чаще его обновлять, что подразумевает лишнюю трату времени на поддержку. Это один из случаев, когда мы не можем использовать общее выражение XPath с такими локаторами, как ID, Class, Link или Name.
Решение
Идентификация элемента с помощью функций XPath по тексту
Поскольку у нас есть видимый текст «Log in to Twitter», мы могли бы использовать следующие функции XPath для идентификации уникального элемента.
contains() [по тексту]
starts-with() [по тексту]
1. Метод Contains()
Поиск по тексту:
//h1[contains(text(),’ Log in to’)]
//h1[contains(text(),’ in to Twitter’)]
Примечание. Наличие одного совпадающего узла свидетельствует об успешной идентификации веб-элемента.
Обратите внимание, что при указании всего текста «Log in to Twitter» с методом contains() элемент будет также идентифицирован корректно.
2. Метод starts-with()
Синтаксис. Чтобы найти на веб-странице элемент «Log in to Twitter», используйте следующие выражения XPath на основе метода starts-with().
Поиск по тексту:
//h1[starts-with(text(),’Log in to’)]
Из приведенного выше примера видно, что XPath-функции starts-with() требуется по крайней мере первое слово («Log») видимого текста для однозначной идентификации элемента. Функция работает даже с неполным текстом, но он должен как минимум включать первое слово частично видимого текста.
Обратите внимание, что при использовании всего текста «Log in to Twitter» с методом starts-with() элемент будет также идентифицирован корректно.
Недействительный XPath для starts-with() : //h1[starts-with(text(),’in to Twitter’)]
Примечание. Отсутствие совпадающих узлов свидетельствует о том, что элемент на веб-странице не был идентифицирован.
3. Метод text()
В этом выражении мы указываем весь текст, содержащийся между открывающим тегом
и закрывающим тегом
Недействительное выражение Xpath для text() :
Идентификация элемента с помощью функций XPath по атрибуту
Мы используем функции XPath ( contains или starts-with ) с атрибутом в тех случаях, когда в теге содержатся уникальные значения атрибутов. Доступ к атрибутам производится с помощью символа « @ ».
Для лучшего понимания рассмотрим следующий пример:
1. Метод Contains()
Вариант А — поиск по значению атрибута Value
Вариант Б — поиск по содержимому атрибута Name
Неправильное использование функции XPath с атрибутом:
Если мы воспользуемся атрибутом type при идентификации кнопки «I’m Feeling Lucky», то XPath не сработает.
Наличие двух совпадающих узлов свидетельствует о том, что нам не удалось корректно идентифицировать элемент. В данном случае значение атрибута type не является уникальным.
2. Метод starts-with()
Метод starts-with() в сочетании с атрибутом может пригодиться для поиска элементов, у которых начало атрибута постоянное, а окончание изменяется. Такой метод позволяет работать с объектами, динамически изменяющими значения своих атрибутов. Его также можно использовать для поиска однотипных элементов.
Изучите первое текстовое поле First Name (Имя) и второе текстовое поле Surname (Фамилия) формы авторизации.
Первое текстовое поле First Name идентифицировано.
Второе текстовое поле Surname идентифицировано.
В случае обоих текстовых полей, из которых состоит форма авторизации Facebook, первая часть атрибута id всегда остается неизменной.
First Name
Surname
Starts-with() [по атрибуту id]
11 найденных узлов указывают на то, что данное выражение XPath позволило идентифицировать все элементы, id которых начинается с «u0». Вторая часть id («2» для имени, «4» для фамилии и т. д.) позволяет однозначно идентифицировать элемент.
Мы можем использовать атрибут с функцией starts-with там, где нам нужно собрать элементы похожего типа в список и динамически выбрать один из них, передавая аргумент в обобщенный метод, чтобы однозначно идентифицировать элемент.
/ Generic Method /
public void xpathLoc(String identifier)<
//The below step identifies the element “First Name” uniquely when the argument is “2”
E1.sendKeys(“Test1”); / This step enters the value of First Name as “Test 1” /
/ Main Method*/
public static void main(String[] args) <
Примечание. Eclipse может не допускать использование двойных кавычек. Возможно, вам придется прибегнуть к другому коду, чтобы сформировать динамический XPath.
Приведенный код является лишь примером. Вы можете усовершенствовать его, чтобы он работал со всеми элементами, выполняемыми операциями и вводимыми значениями (в случае текстовых полей), сделав код более универсальным.
Заключение
Ниже приведены некоторые замечания касательно функций XPath:
Используйте метод contains() в XPath, если известна часть постоянно видимого текста или атрибута.
Используйте метод starts-with() в XPath, если известна первая часть постоянно видимого текста или атрибута.
Вы также можете использовать методы contains() и starts-with() со всем текстом или полным атрибутом.
Используйте метод text() в XPath, если вам известен весь видимый текст.
Нельзя использовать метод text() с частичным текстом.
В следующем уроке мы узнаем, как использовать оси XPath с функциями XPath для более точного определения расположения элементов на веб-странице.
Все знают как написать хороший тест, а может быть даже несколько. Но вот что делать, когда этих тестов у вас больше 100 или возможно даже несколько тысяч?
Об этом расскажем на открытом вебинаре. Регистрируйтесь
Узнать подробнее о курсе «Java QA Automation Engineer» можно здесь.
Selenium для Python. Глава 4. Поиск элементов
Продолжение перевода неофициальной документации Selenium для Python.
Перевод сделан с разрешения автора Baiju Muthukadan.
Оригинал можно найти здесь.
Содержание:
4. Поиск элементов
Существует ряд способов поиска элементов на странице. Вы вправе использовать наиболее уместные для конкретных задач. Selenium предоставляет следующие методы поиска элементов на странице:
Помимо общедоступных (public) методов, перечисленных выше, существует два приватных (private) метода, которые при знании указателей объектов страницы могут быть очень полезны: find_element and find_elements.
Для класса By доступны следующие атрибуты:
4.1. Поиск по Id
Используйте этот способ, когда известен id элемента. Если ни один элемент не удовлетворяет заданному значению id, будет вызвано исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
Элемент form может быть определен следующим образом:
4.2. Поиск по Name
Используйте этот способ, когда известен атрибут name элемента. Результатом будет первый элемент с искомым значением атрибута name. Если ни один элемент не удовлетворяет заданному значению name, будет вызвано исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
Элементы с именами username и password могут быть определены следующим образом:
Следующий код получит кнопку “Login”, находящуюся перед кнопкой “Clear”:
4.3. Поиск по XPath
XPath – это язык, использующийся для поиска узлов дерева XML-документа. Поскольку в основе HTML может лежать структура XML (XHTML), пользователям Selenium предоставляется возможность посредоством этого мощного языка отыскивать элементы в их веб-приложениях. XPath выходит за рамки простых методов поиска по атрибутам id или name (и в то же время поддерживает их), и открывает спектр новых возможностей, таких как поиск третьего чекбокса (checkbox) на странице, к примеру.
Одно из веских оснований использовать XPath заключено в наличии ситуаций, когда вы не можете похвастать пригодными в качестве указателей атрибутами, такими как id или name, для элемента, который вы хотите получить. Вы можете использовать XPath для поиска элемента как по абсолютному пути (не рекомендуется), так и по относительному (для элементов с заданными id или name). XPath указатели в том числе могут быть использованы для определения элементов с помощью атрибутов отличных от id и name.
Абсолютный путь XPath содержит в себе все узлы дерева от корня (html) до необходимого элемента, и, как следствие, подвержен ошибкам в результате малейших корректировок исходного кода страницы. Если найти ближайщий элемент с атрибутами id или name (в идеале один из элементов-родителей), можно определить искомый элемент, используя связь «родитель-подчиненный». Эти связи будут куда стабильнее и сделают ваши тесты устойчивыми к изменениям в исходном коде страницы.
Для примера, рассмотрим следующий исходный код страницы:
Элемент form может быть определен следующими способами:
4.4. Поиск гиперссылок по тексту гиперссылки
Используйте этот способ, когда известен текст внутри анкер-тэга [anchor tag, анкер-тэг, тег «якорь» — тэг — Прим. пер.]. С помощью такого способа вы получите первый элемент с искомым значением текста тэга. Если никакой элемент не удовлетворяет искомому значению, будет вызвано исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
Элемент-гиперссылка с адресом «continue.html» может быть получен следующим образом:
4.5. Поиск элементов по тэгу
Используйте этот способ, когда вы хотите найти элемент по его тэгу. Таким способом вы получите первый элемент с указанным именем тега. Если поиск не даст результатов, будет возбуждено исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
Элемент заголовка h1 может быть найден следующим образом:
4.6. Поиск элементов по классу
Используйте этот способ в случаях, когда хотите найти элемент по значению атрибута class. Таким способом вы получите первый элемент с искомым именем класса. Если поиск не даст результата, будет возбуждено исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
Элемент “p” может быть найден следующим образом:
4.7. Поиск элементов по CSS-селектору
Используйте этот способ, когда хотите получить элемент с использованием синтаксиса CSS-селекторов [CSS-селектор — это формальное описание относительного пути до элемента/элементов HTML. Классически, селекторы используются для задания правил стиля. В случае с WebDriver, существование самих правил не обязательно, веб-драйвер использует синтаксис CSS только для поиска — Прим. пер.]. Этим способом вы получите первый элемент удовлетворяющий CSS-селектору. Если ни один элемент не удовлетворяют селектору CSS, будет возбуждено исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
Элемент “p” может быть определен следующим образом:
Парсим любой сайт за считанные секунды. Как достать нужную информацию с сайта используя Selenium, XPath и Proxy Sever
Дарова, Хабр! Около года назад я решил заработать на ставках на спорт используя свои знания математики и программирования и тогда я наткнулся на небольшую проблему — как же достать нужную мне информацию с сайта? Как парсить веб-страницы? В этой статье я расскажу простыми словами каким тонкостям я научился.

Парсинг
Что ж такое парсинг? Это собирание и систематизирование информации, которая размещена на веб-сайтах с помощью специальных программ, автоматизирующих процесс.
Парсинг обычно используется для анализа ценовой политики и получения контента.
Начало
Чтобы забрать деньги у букмекеров мне надо было оперативно получать информацию про коэффициенты на определённые события с нескольких сайтов. В математическую часть вдаваться не будем.
Поскольку я изучал С# у себя в шараге, я решил всё писать на нём. Ребята со Stack Overflow посоветовали использовать Selenium WebDriver. Это драйвер браузера(программная библиотека), который позволяет разрабатывать программы, управляющие поведением браузера. То что надо, подумал я.
Установил библиотеку и побежал смотреть гайды в интернете. Спустя некоторое время я написал программу, которая могла открыть браузер и переходить по некоторым ссылкам.
Ура! Хотя стоп, а как на кнопки нажимать, как доставать нужную информацию? Тут нам поможет XPath.
XPath
Если простыми словами, то это язык запросов к элементам XML и XHTML документа.
В этой статье я буду использовать Google Chrome. Однако в других современных браузерах должен быть если не такой же, то очень похожий интерфейс.
Чтобы посмотреть код страницы, на которой вы находитесь надо нажать F12.
Чтобы посмотреть, в каком месте кода находиться элемент на странице(текст, картинка, кнопка) надо нажать на стрелочку в левом верхнем углу и выбрать данный элемент на странице. Теперь перейдем к синтаксису.
Стандартный синтаксис для написания XPath:
//: Выбирает все узлы в html документе начиная от текущего узла
Tagname: Тег текущего узла.
@: Выбирает атрибуты
Attribute: Имя атрибута узла.
Value: Значение атрибута.
Может быть поначалу непонятно, но после примеров всё должно встать на свои места.
Рассмотри несколько простых примеров:
Рассмотрим более сложные примеры для заданного html’я:
XPath = //div[@class= ‘contentBlock’]//div
Для этого XPath’а будут выбраны следующие элементы:
XPath = //div[@class= ‘contentBlock’]/div
Обратите внимание на разницу между /(выбирает от корневого узла) и //(выбирает узлы от текущего узла независимо от их местонахождения). Если непонятно, то посмотрите на примеры выше ещё раз.
//div[@class= ‘contentBlock’]/div[@class= ‘listItem’]/a[@class= ‘link’]/span[@class= ‘name’]
Этот запрос равносилен этим при таком html’е:
//a[@class= ‘link’]/span[@class= ‘name’]
//a[@class=’link’ and href= ‘habr.com’]/span
//span[text() = ‘habr’ or text() = ‘habrhabr’]
//div[@class= ‘listItem’]//span[@class= ‘name’]
parent:: — возвращает предка на один уровень выше.
Есть ещё супер крутая фича, такая как following-sibling:: — возвращает множество элементов на том же уровне, следующих за текущим, аналогично preceding-sibling:: — возвращает множество элементов на том же уровне, предшествующих текущему.
Думаю, теперь стало понятнее. Для закрепления материала советую зайти на этот сайт и написать несколько запросов, чтобы найти некоторые элементы этого html’я.
Теперь зная, что такое XPath, вернемся к написанию кода. Поскольку модераторам хабра не нравятся букмекерские конторы, то будет парсить цены на кофе в Walmart’е
Thread.Sleep’ы были написаны, чтобы веб-страничка успевала загрузиться.
Программа откроет сайт магазина Walmart, нажмёт пару кнопок, откроет отдел с кофе и получит название и цены на товары.
Если веб-страничка довольно таки большая и поэтому XPath’ы долго работают или их сложно написать, то надо воспользоваться каким-то другим методом.
HTTP запросы
Для начала рассмотрим как на сайте появляется контент.
Если простыми словами, то браузер делает запрос серверу с просьбой дать нужную информацию, а сервер в свою очередь, эту информацию предоставляет. Всё это осуществляется с помощью HTTP запросов.
Чтобы посмотреть на запросы, которые отправляет ваш браузер на конкретном сайте, то просто откройте этот сайт, нажмите F12 и перейдите во вкладку Network, после этого перезагрузите страницу.
Теперь осталось найти нужный нам запрос.
Как это делать? – рассмотрите все запросы с типом fetch(третья колонка на картинке выше) и смотрите на вкладку Preview.
Если она не пустая, то она должна быть в формате XML или JSON, если нет – продолжайте поиски. Если да, то посмотрите, есть ли здесь нужная вам информация. Чтобы это проверить советую использовать какой – то JSON Viewer или XML Viewer(загуглите и откройте первую ссылку, скопируйте текст с вкладки Response и вставьте в Viewer). Когда вы найдёте нужный вам запрос, то сохраните у себя где то его название(левая колонка) или хост URL’а(вкладка Headers), чтоб потом не искать. Например если на сайте walmart’а открыть отдел кофе, то будет отправляться запрос, юрл которого начинается с walmart.com/cp/api/wpa. Там будет вся информация про кофе в продаже.
Полпути пройдено, теперь этот запрос можно «подделывать» и отправлять сразу через программу, получая нужную информацию за считанные секунды. Осталось распарсить JSON или XML, а это делается намного проще, чем писание XPath’ов. Но зачастую формирование таких запросов вещь довольно таки неприятная(смотри на URL на картинке выше) и если у вас даже всё получиться, то в некоторых случаях вы будете получать такой ответ.
Сейчас вы узнаете, как можно избежать проблем с подражанием запроса используя альтернативу — прокси сервера.
Прокси сервер
Прокси сервер — устройство, являющееся посредником между компьютером и интернетом.
Было б замечательно, если б наша программа была прокси сервером, тогда можно быстро и удобно обрабатывать нужные респонсы с сервера. Тогда была б такая цепочка Браузер – Программа – Интернет(сервер сайта, который парсим).
Благо для си шарпа есть замечательная библиотека для таких нужд – Titanium Web Proxy.
Создадим класс PServer
Теперь пройдемся по каждому методу отдельно.
proxyServer.BeforeRepsone += OnRespone – добавляем метод обработки ответа с сервера. Он будет вызываться автоматически, когда будет приходить респонс.
explicitEndPoint — Конфигурация прокси сервера,
ExplicitProxyEndPoint(IPAddress ipAddress, int port, bool decryptSsl = true)
IPAddress и port, на котором работает прокси сервер.
decryptSsl – стоит ли расшифровывать SSL. Иначе говоря, если decrtyptSsl = true, то прокси сервер будет обрабатывать все запросы и ответы.
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest — добавляем метод обработки запроса перед его отправкой на сервер. Он также будет вызываться автоматически перед отправкой запроса.
proxyServer.Start() — «запуск» прокси-сервера, с этого момента он начинает обрабатывать запросы и ответы.
e.DecryptSsl = false — текущий запрос и ответ на него не будут обрабатываться.
Если нас не интересует запрос или ответ на него(например картинка или какой – то скрипт), то зачем его расшифровывать? На это тратиться довольно много ресурсов, и если будут расшифровываться все запросы и ответы, то программа будет долго работать. Поэтому если текущий запрос не содержит хост интересующего нас запроса, то расшифровывать его нет смысла.
await e.GetResponseBodyAsString() – возвращает респонс в виде строки.
Чтобы WebDriver подключился к прокси серверу, то надо написать следующие:
Теперь можно обрабатывать нужные вам запросы.
XPath in Selenium WebDriver Tutorial: How to Find XPath?
Updated November 19, 2021
In this tutorial, we will learn about the xpath and different XPath expression to find the complex or dynamic elements, whose attributes changes dynamically on refresh or any operations.
In this XPath tutorial, you will learn-
What is XPath in Selenium?
XPath in Selenium is an XML path used for navigation through the HTML structure of the page. It is a syntax or language for finding any element on a web page using XML path expression. XPath can be used for both HTML and XML documents to find the location of any element on a webpage using HTML DOM structure.
The basic format of XPath in selenium is explained below with screen shot.
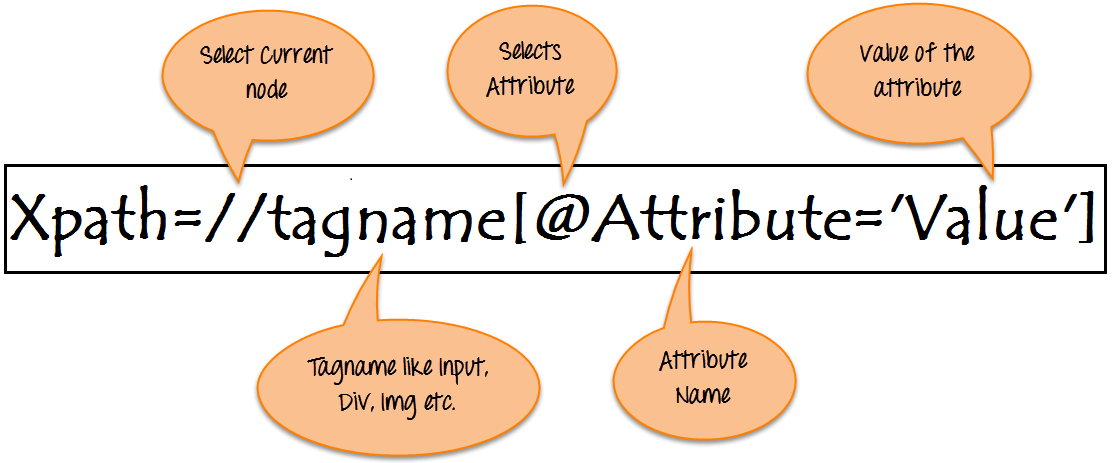
Basic Format of XPath
Syntax for XPath selenium:
XPath contains the path of the element situated at the web page. Standard XPath syntax for creating XPath is.
To find the element on web pages accurately there are different types of locators:
| XPath Locators | Find different elements on web page |
|---|---|
| ID | To find the element by ID of the element |
| Classname | To find the element by Classname of the element |
| Name | To find the element by name of the element |
| Link text | To find the element by text of the link |
| XPath | XPath required for finding the dynamic element and traverse between various elements of the web page |
| CSS path | CSS path also locates elements having no name, class or ID. |
Types of X-path
There are two types of XPath:
1) Absolute XPath
2) Relative XPath
Absolute XPath:
It is the direct way to find the element, but the disadvantage of the absolute XPath is that if there are any changes made in the path of the element then that XPath gets failed.
Below is the example of an absolute xpath expression of the element shown in the below screen.
NOTE: You can practise the following XPath exercise on this http://demo.guru99.com/test/selenium-xpath.html
Click here if the video is not accessible
Absolute XPath:

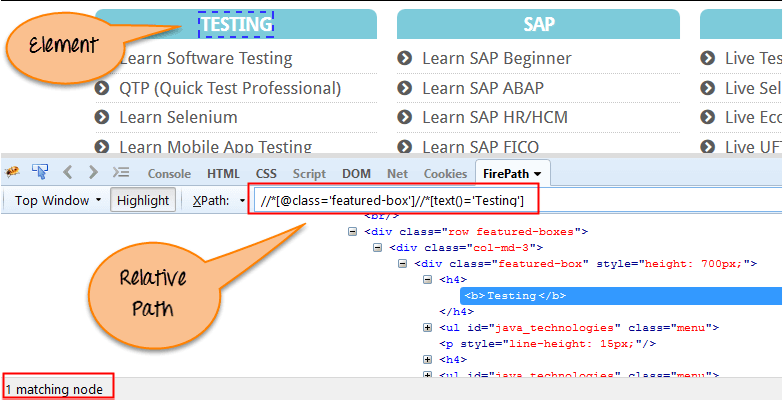
Relative Xpath:
Relative Xpath starts from the middle of HTML DOM structure. It starts with double forward slash (//). It can search elements anywhere on the webpage, means no need to write a long xpath and you can start from the middle of HTML DOM structure. Relative Xpath is always preferred as it is not a complete path from the root element.
Below is the example of a relative XPath expression of the same element shown in the below screen. This is the common format used to find element by XPath.
Click here if the video is not accessible
What are XPath axes.
Axes methods are used to find those elements, which dynamically change on refresh or any other operations. There are few axes methods commonly used in Selenium Webdriver like child, parent, ancestor, sibling, preceding, self, etc.
Using XPath Handling complex & Dynamic elements in Selenium
1) Basic XPath:
Here is a link to access the page http://demo.guru99.com/test/selenium-xpath.html

Some more basic xpath expressions:
2) Contains():
Contains() is a method used in XPath expression. It is used when the value of any attribute changes dynamically, for example, login information.
The contain feature has an ability to find the element with partial text as shown in below XPath example.
In this example, we tried to identify the element by just using partial text value of the attribute. In the below XPath expression partial value ‘sub’ is used in place of submit button. It can be observed that the element is found successfully.
Complete value of ‘Type’ is ‘submit’ but using only partial value ‘sub’.
Complete value of ‘name’ is ‘btnLogin’ but using only partial value ‘btn’.
In the above expression, we have taken the ‘name’ as an attribute and ‘btn’ as an partial value as shown in the below screenshot. This will find 2 elements (LOGIN & RESET) as their ‘name’ attribute begins with ‘btn’.

Similarly, in the below expression, we have taken the ‘id’ as an attribute and ‘message’ as a partial value. This will find 2 elements (‘User-ID must not be blank’ & ‘Password must not be blank’) as its ‘name’ attribute begins with ‘message’.

In the below expression, we have taken the “text” of the link as an attribute and ‘here’ as a partial value as shown in the below screenshot. This will find the link (‘here’) as it displays the text ‘here’.

3) Using OR & AND:
In OR expression, two conditions are used, whether 1st condition OR 2nd condition should be true. It is also applicable if any one condition is true or maybe both. Means any one condition should be true to find the element.
In the below XPath expression, it identifies the elements whose single or both conditions are true.
Highlighting both elements as “LOGIN ” element having attribute ‘type’ and “RESET” element having attribute ‘name’.

In AND expression, two conditions are used, both conditions should be true to find the element. It fails to find element if any one condition is false.
In below expression, highlighting ‘LOGIN’ element as it having both attribute ‘type’ and ‘name’.

4) Xpath Starts-with
XPath starts-with() is a function used for finding the web element whose attribute value gets changed on refresh or by other dynamic operations on the webpage. In this method, the starting text of the attribute is matched to find the element whose attribute value changes dynamically. You can also find elements whose attribute value is static (not changes).
and so on.. but the initial text is same. In this case, we use Start-with expression.
In the below expression, there are two elements with an id starting “message”(i.e., ‘User-ID must not be blank’ & ‘Password must not be blank’). In below example, XPath finds those element whose ‘ID’ starting with ‘message’.

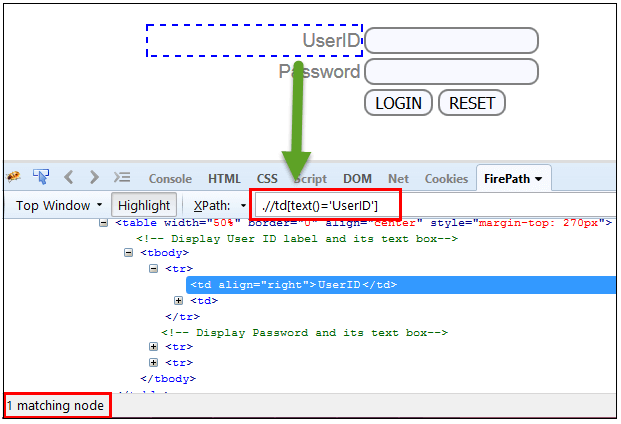
5) XPath Text() Function
The XPath text() function is a built-in function of selenium webdriver which is used to locate elements based on text of a web element. It helps to find the exact text elements and it locates the elements within the set of text nodes. The elements to be located should be in string form.
In this expression, with text function, we find the element with exact text match as shown below. In our case, we find the element with text “UserID”.
6) XPath axes methods:
These XPath axes methods are used to find the complex or dynamic elements. Below we will see some of these methods.
For illustrating these XPath axes method, we will use the Guru99 bank demo site.
a) Following:
Selects all elements in the document of the current node( ) [ UserID input box is the current node] as shown in the below screen.

There are 3 “input” nodes matching by using “following” axis- password, login and reset button. If you want to focus on any particular element then you can use the below XPath method:
You can change the XPath according to the requirement by putting [1],[2]…………and so on.
With the input as ‘1’, the below screen shot finds the particular node that is ‘Password’ input box element.

b) Ancestor:
The ancestor axis selects all ancestors element (grandparent, parent, etc.) of the current node as shown in the below screen.
In the below expression, we are finding ancestors element of the current node(“ENTERPRISE TESTING” node).

There are 13 “div” nodes matching by using “ancestor” axis. If you want to focus on any particular element then you can use the below XPath, where you change the number 1, 2 as per your requirement:
You can change the XPath according to the requirement by putting [1], [2]…………and so on.
c) Child:
Selects all children elements of the current node (Java) as shown in the below screen.

There are 71 “li” nodes matching by using “child” axis. If you want to focus on any particular element then you can use the below xpath:
You can change the xpath according to the requirement by putting [1],[2]…………and so on.
d) Preceding:
Select all nodes that come before the current node as shown in the below screen.
In the below expression, it identifies all the input elements before “LOGIN” button that is Userid and password input element.
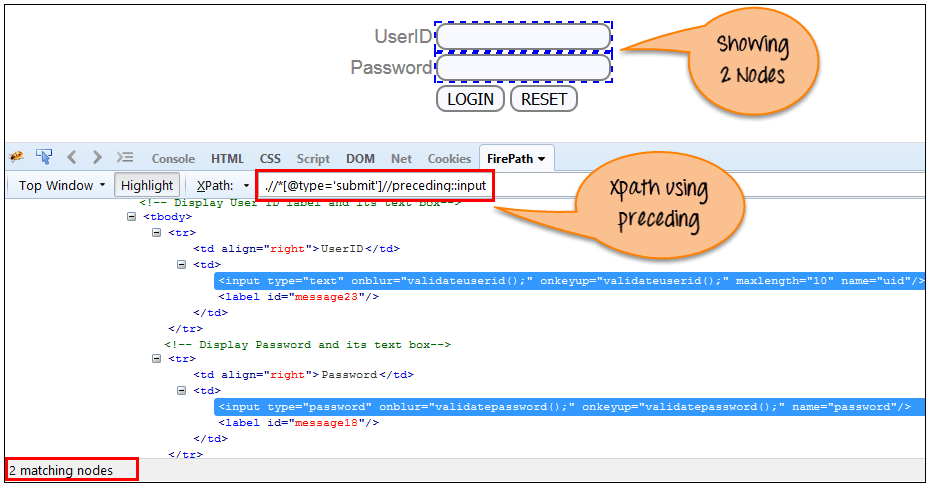
There are 2 “input” nodes matching by using “preceding” axis. If you want to focus on any particular element then you can use the below XPath:
You can change the xpath according to the requirement by putting [1],[2]…………and so on.
e) Following-sibling:
Select the following siblings of the context node. Siblings are at the same level of the current node as shown in the below screen. It will find the element after the current node.

One input nodes matching by using “following-sibling” axis.
f) Parent:
Selects the parent of the current node as shown in the below screen.

There are 65 “div” nodes matching by using “parent” axis. If you want to focus on any particular element then you can use the below XPath:
You can change the XPath according to the requirement by putting [1],[2]…………and so on.
g) Self:
Selects the current node or ‘self’ means it indicates the node itself as shown in the below screen.

One node matching by using “self ” axis. It always finds only one node as it represents self-element.
h) Descendant:
Selects the descendants of the current node as shown in the below screen.
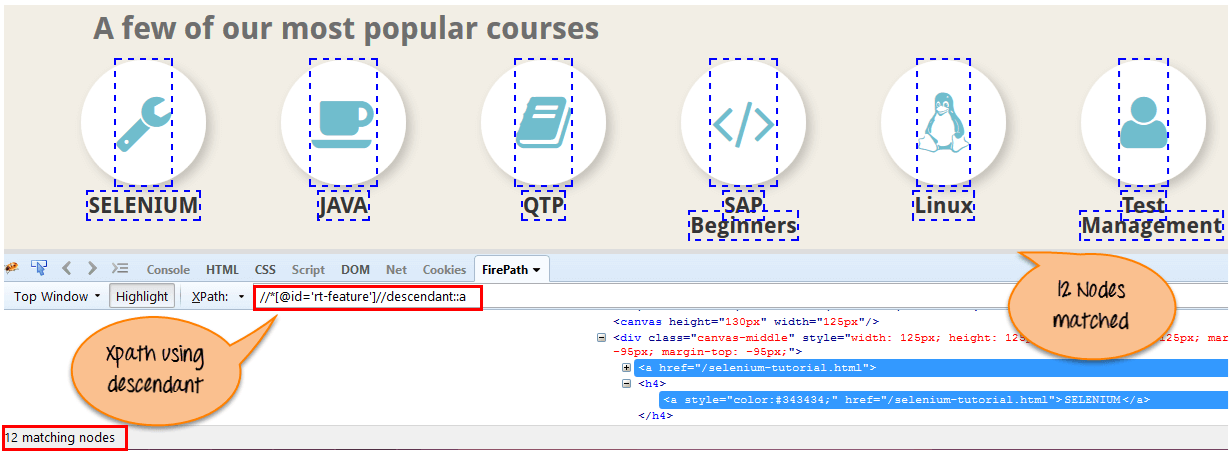
There are 12 “link” nodes matching by using “descendant” axis. If you want to focus on any particular element then you can use the below XPath:
You can change the XPath according to the requirement by putting [1],[2]…………and so on.
Summary:
XPath is required to find an element on the web page as to do an operation on that particular element.



