Что значит метод трансфер
Продолжаем говорить о сверточных нейронных сетях (CNN). Сегодня расскажем вам об одном из методов Transfer Learning — выделение признаков (feature extraction). Читайте в этой статье: использование предварительно обученной модели (VGG16) от TensorFlow для решения задачи классификации в Python, а также передача результатов сверточной основы в собственный классификатор.
Выделение признаков как один из методов Transfer Learning
Transfer Learning — это набирающий популярность метод обучения моделей машинного обучения для задач компьютерного зрения (Computer Vision), NLP и не только. В основе обучения лежит использование предобученных нейронных сетей. Кто-то, обладая большими вычислительными мощностями, сконструировал большую архитектуру нейронной сети, обучил в рамках решения своей задачи и опубликовал её на просторах Интернета. Мы, не имея в наличии множества GPU и больших данных (Big Data), используем предобученную модель для решения своей задачи. Нам не важно, что изначально обученная модель научена распознавать образы самолётов и автомобилей, мы можем использовать её для распознавания кошек и собак.
Сверточные нейронные сети (CNN) являются универсальным инструментом для работы с изображениями. Тем не менее предобученная модель без каких-либо изменений вряд ли покажет высокие результаты при решении текущей задачи (напр., распознавание животных). Поэтому мы дополняем её своими данными и получаем перепрофилированную модель, которая решает нашу задачу.
Transfer Learning предлагает два подхода использования предварительно обученных сетей:
Мы рассмотрим feature extraction на примере простой архитектуры VGG16 с использованием Python-фреймворка TensorFlow [1]. Архитектура VGG16 обучена на данных из ImageNet, которая имеет больше миллиона изображений.
Выделение признаков для решения задачи классификации изображений
Выделение признаков заключается в использовании неизменной сверточной основы архитектуры и создании своего собственного классификатора. Как правило, в моделях CNN последний слой — полносвязный. В feature extraction мы отказываемся от этого слоя и реализуем свой, например через TensorFlow.
При создании своего полносвязного классификатора можно пойти несколькими способами:
В этой статье мы рассмотрим 1-й способ.
Датасет и извлечение сверточной основы
Мы используем набор данных с изображениями собак и кошек, доступный для скачивания. Разделим датасет на тренировочную, валидационную и тестовую выборки, каждая из которых имеет папки с собаками и кошками. Весь процесс разбиения можете посмотреть в прошлой статье.
Прежде всего скачаем архитектуру VGG16, которая доступна в TensorFlow. Вот так выглядит извлечение архитектуры VGG16 в Python:
Аргумент include_top определяет включение полносвязного слоя. ImageNet имеет 1000 классов, но нам не нужно 1000 нейронов на выходе, для бинарной классификации можно обойтись одним. К тому же в основе feature extraction лежит избавление этот этого слоя.
Извлечение и сохранение признаков
Поскольку полученные признаки имеют форму (образцы,4,4,512), то для передачи полносвязному классификатору требуется их преобразовать в форму (образцы,8192). Пример кода на Python для изменения формы массива NumPy:
Создание собственного классификатора в TensorFlow
Ниже пример создания в TensorFlow полносвязного классификатора, который имеет на входе 256 нейронов и 1 на выходе (кошка/не кошка). Ещё мы добавили слой Dropout, чтобы избежать переобучения (overfitting). Также используем TensorBoard для визуализации полученных результатов. Код на Python для создания классификатора:
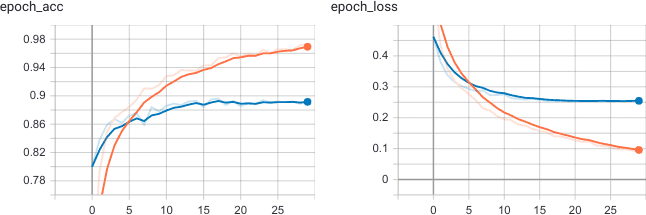 Точность и функция потерь (синие линии — валидационная выборка)
Точность и функция потерь (синие линии — валидационная выборка)
В следующей статье рассмотрим 2-й способ выделения признаков. Ещё больше подробностей о Transfer Learning и использовании предварительно обученных моделей на примерах реальных задач Computer Vision на языке Python, вы узнаете на нашем специализированном курсе «VISI: Computer Vision» в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.
Transfer Learning: как быстро обучить нейросеть на своих данных
Машинное обучение становится доступнее, появляется больше возможностей применять эту технологию, используя «готовые компоненты». Например, Transfer Learning позволяет использовать накопленный при решении одной задачи опыт для решения другой, аналогичной проблемы. Нейросеть сначала обучается на большом объеме данных, затем — на целевом наборе.
В этой статье я расскажу, как использовать метод Transfer Learning на примере распознавания изображений с едой. Про другие инструменты машинного обучения я расскажу на воркшопе «Machine Learning и нейросети для разработчиков».
Если перед нами встает задача распознавания изображений, можно воспользоваться готовым сервисом. Однако, если нужно обучить модель на собственном наборе данных, то придется делать это самостоятельно.
Для таких типовых задач, как классификация изображений, можно воспользоваться готовой архитектурой (AlexNet, VGG, Inception, ResNet и т.д.) и обучить нейросеть на своих данных. Реализации таких сетей с помощью различных фреймворков уже существуют, так что на данном этапе можно использовать одну из них как черный ящик, не вникая глубоко в принцип её работы.
Однако, глубокие нейронные сети требовательны к большим объемам данных для сходимости обучения. И зачастую в нашей частной задаче недостаточно данных для того, чтобы хорошо натренировать все слои нейросети. Transfer Learning решает эту проблему.
Transfer Learning для классификации изображений
Нейронные сети, которые используются для классификации, как правило, содержат N выходных нейронов в последнем слое, где N — это количество классов. Такой выходной вектор трактуется как набор вероятностей принадлежности к классу. В нашей задаче распознавания изображений еды количество классов может отличаться от того, которое было в исходном датасете. В таком случае нам придётся полностью выкинуть этот последний слой и поставить новый, с нужным количеством выходных нейронов
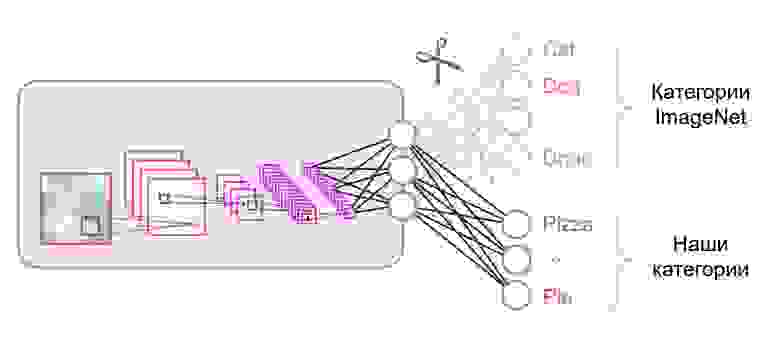
Зачастую в конце классификационных сетей используется полносвязный слой. Так как мы заменили этот слой, использовать предобученные веса для него уже не получится. Придется тренировать его с нуля, инициализировав его веса случайными значениями. Веса для всех остальных слоев мы загружаем из предобученного снэпшота.
Существуют различные стратегии дообучения модели. Мы воспользуемся следующей: будем тренировать всю сеть из конца в конец (end-to-end), а предобученные веса не будем фиксировать, чтобы дать им немного скорректироваться и подстроиться под наши данные. Такой процесс называется тонкой настройкой (fine-tuning).
Структурные компоненты
Для решения задачи нам понадобятся следующие компоненты:
В нашем примере компоненты (1), (2) и (3) я буду брать из собственного репозитория, который содержит максимально легковесный код — при желании с ним можно легко разобраться. Наш пример будет реализован на популярном фреймворке TensorFlow. Предобученные веса (4), подходящие под выбранный фреймворк, можно найти, если они соответствуют одной из классических архитектур. В качестве датасета (5) для демонстрации я возьму Food-101.
Модель
В качестве модели воспользуемся классической нейросетью VGG (точнее, VGG19). Несмотря на некоторые недостатки, эта модель демонстрирует довольно высокое качество. Кроме того, она легко поддается анализу. На TensorFlow Slim описание модели выглядит достаточно компактно:
Веса для VGG19, обученные на ImageNet и совместимые с TensorFlow, скачаем с репозитория на GitHub из раздела Pre-trained Models.
Датасет
В качестве обучающей и валидационной выборки будем использовать публичный датасет Food-101, где собрано более 100 тысяч изображений еды, разбитых на 101 категорию.

Скачиваем и распаковываем датасет:
Пайплайн данных в нашем обучении устроен так, что из датасета нам понадобится распарсить следующее:
Все вспомогательные функции, ответственные за обработку данных, вынесены в отдельный файл data.py :
Обучение модели
Код обучения модели состоит из следующих шагов:
После запуска обучения можно посмотреть на его ход с помощью утилиты TensorBoard, которая поставляется в комплекте с TensorFlow и служит для визуализации различных метрик и других параметров.
В конце обучения в TensorBoard мы наблюдаем практически идеальную картину: снижение Train loss и рост Validation Accuracy
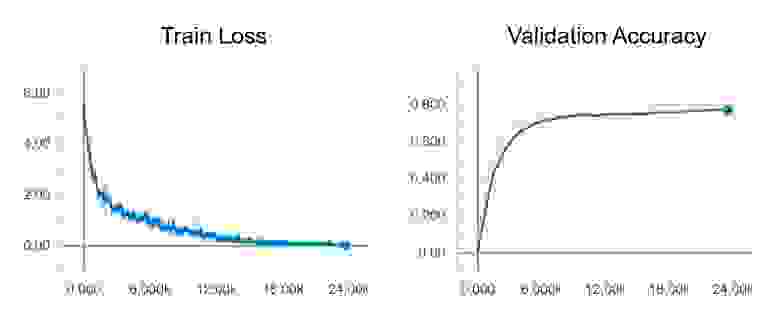
Тестирование модели
Теперь протестируем нашу модель. Для этого:

Весь код, включая ресурсы для построения и запуска Docker контейнера со всеми нужными версиями библиотек, находятся в этом репозитории — на момент прочтения статьи код в репозитории может иметь обновления.
На воркшопе «Machine Learning и нейросети для разработчиков» я разберу и другие задачи машинного обучения, а студенты к концу интенсива сами представят свои проекты.
Что значит метод трансфер
Трансферрин – белок крови, функцией которого является транспорт железа.
Переносчик железа, сидерофилин.
Синонимы английские
Siderophilin, transferrin, Tf.
Какой биоматериал можно использовать для исследования?
Как правильно подготовиться к исследованию?
Общая информация об исследовании
Трансферрин – главный белок-переносчик железа в плазме крови. Он образуется в печени из аминокислот, которые всасываются из пищи в процессе переваривания. Трансферрин связывается с железом, которое поступает с едой или при разрушении эритроцитов, и переносит его к органам и тканям (к печени, селезенке). Трансферрин способен присоединить больше железа, чем весит сам.
Железо – важный микроэлемент в организме. Оно является частью гемоглобина – белка, который заполняет эритроциты и позволяет им переносить кислород от легких к органам и тканям. Железо также входит в состав мышечного белка миоглобина.
В норме в организме содержится 4-5 г железа, около 3-4 мг (0,1 % от общего количества) циркулирует в крови в соединении с трансферрином. Как правило, железом заполнена 1/3 связывающих центров трансферрина, остальные 2/3 остаются в резерве. Степень «заполненности» трансферрина железом отражают такие показатели, как общая железосвязывающая способность сыворотки, латентная железосвязывающая способность сыворотки и процент насыщения трансферрина.
При дефиците железа уровень трансферрина повышается, чтобы он смог связаться даже с небольшим количеством железа в сыворотке.
Количество трансферрина в крови зависит к тому же от состояния печени, питания человека и работы кишечника. Если функция печени нарушается из-за значительного разрастания в ней рубцовой ткани (цирроза), то уровень трансферрина падает. При недостатке белковой пищи в рационе или нарушении всасывания аминокислот из-за воспаления в кишечнике трансферрин также не образуется в достаточных количествах.
Для чего используется исследование?
Когда назначается исследование?
Что означают результаты?
Интерпретация результатов обычно производится с учетом остальных показателей, отражающих метаболизм железа.
Причины повышения уровня трансферрина
Причины понижения уровня трансферрина
Что может влиять на результат?
Кто назначает исследование?
Врач общей практики, терапевт, гематолог, гастроэнтеролог, ревматолог, нефролог, хирург.
Структуры данных в картинках. HashMap
Приветствую вас, хабрачитатели!
Продолжаю попытки визуализировать структуры данных в Java. В предыдущих сериях мы уже ознакомились с ArrayList и LinkedList, сегодня же рассмотрим HashMap.

HashMap — основан на хэш-таблицах, реализует интерфейс Map (что подразумевает хранение данных в виде пар ключ/значение). Ключи и значения могут быть любых типов, в том числе и null. Данная реализация не дает гарантий относительно порядка элементов с течением времени. Разрешение коллизий осуществляется с помощью метода цепочек.
Создание объекта
Вы можете указать свои емкость и коэффициент загрузки, используя конструкторы HashMap(capacity) и HashMap(capacity, loadFactor). Максимальная емкость, которую вы сможете установить, равна половине максимального значения int (1073741824).
Добавление элементов
Комментарий из исходников объясняет, каких результатов стоит ожидать — метод hash(key) гарантирует что полученные хэш-коды, будут иметь только ограниченное количество коллизий (примерно 8, при дефолтном значении коэффициента загрузки).
В моем случае, для ключа со значением »0» метод hashCode() вернул значение 48, в итоге:
При значении хэша 51 и размере таблице 16, мы получаем индекс в массиве:
Для того чтобы продемонстрировать, как заполняется HashMap, добавим еще несколько элементов.
Footprint
Object size: 376 bytes
Footprint
Object size: 496 bytes
Resize и Transfer
Когда массив table[] заполняется до предельного значения, его размер увеличивается вдвое и происходит перераспределение элементов. Как вы сами можете убедиться, ничего сложного в методах resize(capacity) и transfer(newTable) нет.
Метод transfer() перебирает все элементы текущего хранилища, пересчитывает их индексы (с учетом нового размера) и перераспределяет элементы по новому массиву.
Если в исходный hashmap добавить, скажем, еще 15 элементов, то в результате размер будет увеличен и распределение элементов изменится.
Удаление элементов
У HashMap есть такая же «проблема» как и у ArrayList — при удалении элементов размер массива table[] не уменьшается. И если в ArrayList предусмотрен метод trimToSize(), то в HashMap таких методов нет (хотя, как сказал один мой коллега — «А может оно и не надо?«).
Небольшой тест, для демонстрации того что написано выше. Исходный объект занимает 496 байт. Добавим, например, 150 элементов.
Теперь удалим те же 150 элементов, и снова замерим.
Как видно, размер даже близко не вернулся к исходному. Если есть желание/потребность исправить ситуацию, можно, например, воспользоваться конструктором HashMap(Map).
Итераторы
HashMap имеет встроенные итераторы, такие, что вы можете получить список всех ключей keySet(), всех значений values() или же все пары ключ/значение entrySet(). Ниже представлены некоторые варианты для перебора элементов:
Стоит помнить, что если в ходе работы итератора HashMap был изменен (без использования собственным методов итератора), то результат перебора элементов будет непредсказуемым.
Итоги
— Добавление элемента выполняется за время O(1), потому как новые элементы вставляются в начало цепочки;
— Операции получения и удаления элемента могут выполняться за время O(1), если хэш-функция равномерно распределяет элементы и отсутствуют коллизии. Среднее же время работы будет Θ(1 + α), где α — коэффициент загрузки. В самом худшем случае, время выполнения может составить Θ(n) (все элементы в одной цепочке);
— Ключи и значения могут быть любых типов, в том числе и null. Для хранения примитивных типов используются соответствующие классы-оберки;
— Не синхронизирован.
Ссылки
Инструменты для замеров — memory-measurer и Guava (Google Core Libraries).
Слепочный трансфер – это не обязательный компонент конструкций, используемый при реставрациях зубных рядов, но его рекомендуют для повышения точности. Суть в том, что на этапе формирования модели эти металлические компоненты устанавливаются и имитируют положение, угол наклона природных единиц.
Аналогичный результат позволяет получить хирургический шаблон.
Оценим возможности и основные методики использования данных ортопедических компонентов.

Характеристики
Конструктивно трансфер представляет собой деталь из металла, которая включает:
— втулка конической формы с усеченной вершиной, шейка имеет круглое сечение;
— винт, который обеспечивает фиксацию на имплантате или его аналоге.
Выпускают трансферы из титана различных марок и нержавеющих сталей. Это необходимо для безопасности пациента и соблюдения санитарно-эпидемиологических норм, так как при работе элементы устанавливаются и в ротовой полости. При этом компоненты являются многоразовыми, а между их применениями проводится дезинфекция.
При установке трансфера в ротовой полости или на модели удается получить точное положение абатментов и имплантатов, углы наклона.
Благодаря этому минимизируется погрешность определения позиции вживляемых компонентов, сокращается риск ошибки. Однако, для достоверного результата необходимо строго соблюдать все пункты работы при установке трансферов и оснований для них.

Оттиски
Работа с трансферами начинается с создания оттиска челюстей. Это позволяет получить трехмерную картину расположения сохранившихся зубов, а так же уже вживленных искусственных элементов, слизистых оболочек, мягких и твердых тканей.
Слепок снимается с помощью металлической/пластмассовой ложки, в которую закладывается масса.
Ложка вводится в рот и прижимается к челюстям поочередно, время экспозиции зависит от того, какое вещество использовано. На этом этапе и устанавливаются трансферы, которые затем фиксируются в слепочном материале и передают положение имплантатов.
Далее полученный отпечаток отливается из гипса, по нему создается набросок, выбирается принцип расположения протезов и имплантированных деталей. Полученный макет носит название “рабочего”.
Оттиск можно снять двумя способами:
— с головки имплантата. Этот метод подойдет, если предполагается создавать протезы, которые ставятся непосредственно на имплантаты, либо если конечная форма абатмента еще не подобрана;
— с высоты абатмента. Данный метод подойдет для любых супраструктур, фиксируемых на абатментах, но уже после того, как компонент выбран.

Отмечается, что оттиски можно снимать открытыми или закрытыми ложками. Конечный выбор не сказывается на точности, но может зависеть от положения реставрации в ротовой полости.
Подготовка к работе
Трансферы контактируют с тканями, в том числе потревоженными установленными имплантатами, потому должны быть полностью безопасны для человека.
Есть ряд важных критериев:
— высокая сопротивляемость коррозии, в том числе при контакте с активными веществами;
— биосовместимость на высоком уровне;
— отсутствие выделяемых соединений, которые могут представлять опасность при длительном контакте.
При малейшей несовместимости, контакт со слизистыми или травмированной частью приведет к негативным реакциям или даже отторжению.
Чтобы избежать подобных ситуаций, необходима стерилизация, которая проводится паром и специальными жидкими средствами.

Соответствующим образом должна подготавливаться и ложка. В нее закладывается материал вязкий и мягкий, который с высокой точностью отображает рельеф после прижатия.
В качестве заполнителя для ложки используют:
Не меньше внимания требуется при подборе трансферов, они должны соответствовать ряду параметров:
— диаметр, он должен соответствовать диаметру формирователя десны, который уже установлен на имплантированную опору;
— длина. Это значение подбирается с таким запасом, чтобы над плоскостью рядов не было возвышения.
Слепок с имплантата
Слепок с трансферами с уровня имплантата создается после ряда предварительных операций.
Этапы работ следующие:
— снимается формирователь десны;
— в основу вкручивается трансфер;
— проводится рентгенографическое исследование. Снимок позволяет удостовериться, что металлический элемент установлен верно;
— ложка примеряется, подбирается индивидуальная или один из стандартных форматов.

Эти этапы общие вне зависимости от выбранного метода, но далее начинаются различия. Для открытой и закрытой ложки этапы имеют свои особенности.
— подбирается подходящая по размеру ложка. Обычно это прозрачные инструменты из пластика, потому металлические конусы трансферов хорошо просвещаются и можно легко разметить их положение на ложке;
— далее высверливаются отверстия, соответствующие установленным маркерам;
— масса на основе поливинилсилоксана наносится и на участки ротовой полости, и на ложку, после чего прижимается. Монофазная масса укладывается шприцем уже на участок, где размещена конструкция. Жидкие составы укладываются непосредственно в ложку, вытекание можно предотвратить заклеиванием отверстия воском;
— винты трансферов выворачиваются, удаляются;
— ложка извлекается изо рта вместе с зафиксированными в оттискном материале трансферами.
Методика открытой ложки хороша возможностью снять качественный слепок, точно передать положение и углы наклона металлических компонентов.
Методика закрытой ложки имеет главное отличие – это сохранение трансфера на имплантате даже после снятия оттиска.
Для этого проводятся операции, идентичные открытому методу. Перед установкой ложки в ротовую полость винты трансферов запаиваются воском, чтобы исключить погрешности и забивание шлица крепления оттискным составом.

После твердения срезаются переборки из материала, оставшиеся между единицами. Конструкция снова размещается во рту со свежей оттискной смесью, так получают уточненный окончательный оттиск. Трансферы отсоединяются отдельно и устанавливаются на свои позиции после дезинфекции.
Слепок с уровня абатмента
Эта методика задействуется при уже установленном абатменте, методов так же два:
— с сохранением трансфера в полости рта;
— со снятием компонентов.
Если трансфер вместе с оттиском извлекается, то метод идентичен способу снятия с уровня имплантата. Трансферы применяются стандартные, крепление на абатменте винтовое.
Отличия есть при снятии оттиска с сохранением трансфера в ротовой полости. Этот способ достаточно редко используют специалисты, так как подходит он только при слишком ограниченном пространстве, которое не позволяет работать с оттисками прочими способами.
В этом случае применяют конические устройства, которые не обладают выраженными ретенционными характеристиками. В этой связи необходимо особое внимание и осторожность при реализации процессов.

— на абатменте фиксируется стандартный чек, конструкция простая – однофрагментная деталь;
— подготавливается ложка, в нее загружается необходимое количество оттискного материала;
— ложка вводится в полость рта, сжимается и фиксируется на некоторое время, необходимое для застывания вещества;
— далее все извлекается изо рта, инструмент фиксируется на полученном отпечатке.
Необходимо тщательно выставлять трансферы на начальном этапе, так как от него зависит точность всей конструкции в итоге. При выполнении остальных задач так же нужно исключать смещения чека.

После окончания работ нужно удостовериться в отсутствии погрешностей, для чего проводится ряд проверок. В первую очередь стоит при помощи пинцета пошатать трансфер. При качественной установке не должно быть смещений даже при ощутимых воздействиях. Часто проблемы связаны с ошибками на этапе создания модели. Могут повлиять плохо очерченные естественные изгибы слизистых.
Если выявлены ошибки, потребуется создание нового оттиска. Все этапы начинаются с начала, использовать созданные модели и слепки запрещено.
В целом трансферы позволяют добиться максимальной точности установки протезов. Особенно в сочетании с технологиями CAD/CAM, к примеру, используя индивидуальный абатмент удается добиться максимальной точности прилегания, а значит минимального процента отторжений и комфорта.



