Атрибут rel=canonical. Что это за атрибут и какая от него польза в SEO
Привет, друзья! Я уже писал про дубли страниц и то какой вред они могут нанести сайту. Сегодняшняя тема напрямую связана с этим явлением. Я расскажу про атрибут rel=canonical.

Атрибут rel=canonical был введен Google 12 февраля 2009 года. Он учитывается до сих пор, поисковой системой Яндекс в том числе. Атрибут rel=canonical указывает поисковым роботам какая страница является предпочтительной при индексации, если на сайте имеется несколько страниц с одинаковым содержимым, но с разными URL-адресами.
Допустим существует 2 страницы:
В данном случае первая страница является основной, именно для нее и должен быть прописан атрибут rel=canonical. А вторая страница является лишь ее копией, но с другим URL-адресом. Следовательно, если не будет прописан rel=canonical, то поисковая система будет индексировать как основной адрес, так и дубль страницы.
Конечно, поисковые системы не глупы и со временем выкинут дубль из индекса, но на это требуется время. А если сайт ежедневно пополняется несколькими сотнями новых страниц, то отсутствие указания канонического URL-адреса может негативно сказаться на продвижении.
Возьмем интернет магазин с 10 000 товарами. У каждого товара на сайте своя страница и несколько дублей. Представляете как подпортит продвижение сайта могут 20 000 дублированных страниц?
Откуда берутся неканонические страницы на сайте
Неканонические страницы или дубли генерируют движки управления, такие как WordPress, phpBB и прочие. Если у вас сайт написан на чистом HTML, то дублированных страниц в принципе быть не должно, если только вы их специально не добавляли конечно.
Если мы обратимся к справочнику вебмастера в Google и Яндекс, то увидим следующее:
Сообщение Google
Рекомендации Яндекс
Как прописать атрибут rel=canonical
С тех пор, как Google ввел данный атрибут, прошло много времени и практически на всех CMS и конструкторах сайтов есть возможность его прописать. В конструкторах сайтов он обычно прописывается автоматически, а для движков существуют дополнения в виде модулей и плагинов.
Если взять CMS WordPress, то практически все SEO плагины предоставляют возможность прописать канонический URL автоматически. Я пользуюсь плагином All In One Seo Pack, поэтому покажу на его примере.
В настройках плагина нужно отметить галочкой, чтобы автоматически прописывались канонические URL-адреса.
Если взглянем на исходный код страницы, то увидим что rel=canonical прописан. И если поисковый робот зайдет на этот дубль страницы, то увидит, что страница не является основной.
Вот такой вот интересный атрибут. Конечно, ничего нового я вам не открыл. Но почему-то многие не обращают внимания на вот такие мелочи, особенно владельцы небольших интернет-магазинов.
Руководство по работе с канониклами
В этой статье собраны свежие данные на лето 2021 года о канонических страницах. Разобраны все возможные случаи использования атрибута rel=“canonical”. Рассмотрены основные ошибки при работе, а также даны ответы на популярные вопросы.
Определения каноничности
Каноническая страница — это страница, которую поисковая система считает главной в группе схожих по содержимому.
Неканоническая страница — это страница на которой размещен атрибут rel=»canonical» с адресом другой страницы.
Как выглядит атрибут каноникал
Атрибут rel=“canonical” может быть прописан двумя способами:
Какой из этих методов выбрать лучше всего, разберем в главе «Как указать канонический адрес страницы».
Процесс канонизации

Канонизация — это процесс выбора главной страницы среди дублей (одинаковых страниц доступных по разным адресам) и/или среди страниц с похожим контентом.
В подкасте Search Off the Record от 4 ноября 2020 сотрудник Google Мартин Сплитт рассказал, как поисковик обрабатывает канонизацию:
Сначала нужно обнаружить дубликаты, сгруппировать их вместе и отметить, что эти страницы дублируют друг друга. Затем для всех них нужно найти страницу лидера.
На вопрос: «Обнаруживает ли такой метод только точные дубли или частичные тоже?» специалист ответил:
У нас есть несколько алгоритмов, которые пытаются обнаружить и не учитывать шаблонную часть страниц. Так, например, мы исключаем навигацию из расчета контрольной суммы, убираем нижний колонтитул. Тогда у нас остается то, что мы называем центральным элементом, то есть центральное содержимое страницы, что-то вроде самой сути страницы.
После вычисления и сравнения контрольных сумм, те, которые похожи между собой (сильно или частично) мы объединяем в дублирующий кластер.
Далее по словам Мартина, необходимо выбрать один документ из кластера, который и будет показываться в результатах поиска:
Но вычислить какая из них будет ведущей в кластере не так просто. Есть случаи, когда даже людям будет сложно определить, какая именно страница должна отображаться в результатах поиска. Мы используем более 20 сигналов, чтобы решить, какую страницу выбрать как каноническую из дублирующего кластера.
После сравнения всех сигналов для всех пар страниц, мы приближаемся к фактическому определению канонической.
Почему канониклы важны для SEO
1) Поисковики не любят дублирующийся контент, потому что он засоряют выдачу. Так же алгоритмам бывает непросто выбрать правильно главную страницу. Атрибут rel=»canonical» подсказывает какой URL стоит индексировать.
Google и Яндекс заявляют, что они не всегда признают указанный канонический адрес. Из-за того, что теги каноничности считаются подсказками, а не директивами (указаниями). Учитываются различные сигналы (были рассмотрены выше). Грамотное использование тегов каноничности помогает снизить риск того, что робот сочтет канонической не ту страницу.
Неканоническая страница что это
Доброго всем времени суток! С вами Анатолий Кузнецов и сегодня поговорим о таком понятии, как неканоническая страница, что это такое и как она влияет на позиции сайта в органической выдаче Яндекс. Итак, поехали!
Что такое неканоническая страница сайта
Объясним от обратного!
Каноническая ссылка — это бэклинк на сайте оформленный со специальным атрибутом rel=»canonical», который информирует поискового робота о важности данной страницы и исключает за счет неё дублирование других похожих страниц. Прописывается каноническая ссылка в головном разделе сайта и она должна быть единственной для каждого URL страницы.
Не сложно догадаться, что неканоническая ссылка на сайте это обратная сторона канонической.
Как прописывается каноническая ссылка на сайте
В HTML коде каноническая ссылка прописывается так:
Как ненканоническая и каноническая ссылка влияет на продвижение сайта
На крупных WEB сайтах (и не только) существует большое количество дублирующих страниц. Похожие URL дублируют друг друга, создавая внутри сайта огромное количество одинаковых страниц, тем самым путая пользователей и усложняя работу поисковых роботов. Чаще всего, такие дубли массово встречаются в интернет магазинах, и если владелец сайта с помощью атрибута rel=»canonical» не указал Яндекс боту какие страницы и товары на сайте являются основными, то Yandex и Google сделают это сами, исключив из индексации дубляж. Вот пример такого исключения в Яндексе:
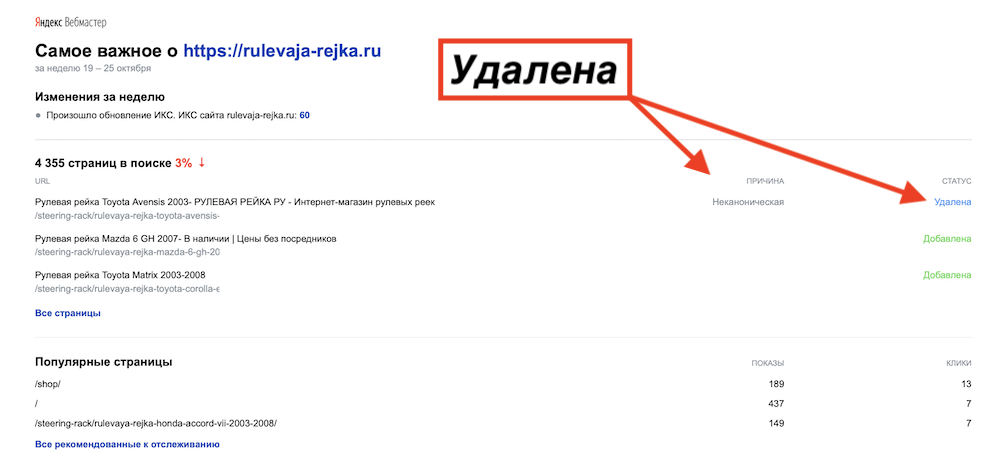
Очень частая ситуация, когда из-за дублирования карточек товаров и страниц интернет-магазина, Яндекс исключает их из выдачи, а владелец сайта не может понять, почему интернет-магазин не продаёт. А по факту, просто не указана основная страница атрибутом rel=»canonical».
Пример дублирования URL страницы
Атрибут rel=canonical был впервые был анонсирован компанией Google в феврале 2009 года. Яндекс его также начал использовать, но позже. Данный атрибут указывает Google и Yandex ботам предпочтение в индексации, той или иной страницы, в том случае, если на сайте таких одинаковых страниц несколько.
Допустим есть две страницы с такими URL:
В этом случае первая страница является основной на сайте, а вторая дублирующей. Если для роботов не прописать основную страницу атрибутом rel=»canonical», то роботы могут её исключить из индексации, а вы этого даже не будете знать. Соответственно такая страница не будет показываться в поисковой выдаче и приводить на сайт целевых клиентов. Отсюда и возникает важность обозначения канонических страниц на сайтах и интернет-магазинах.
У каждого сайта и интернет магазина дублирующих страниц очень много и с ними нужно бороться. Представьте интернет-магазин с 20 000 товаров у которого страница дублируется несколько раз. В глазах поисковых роботов этот магазин будет иметь 60 000 страниц (условно). Представляете, как этот дубляж подпортит репутацию сайту и ухудшит SEO продвижение? Надеюсь понятно объяснил!
Откуда берутся неканонические страницы на сайте
Неканонические страницы генерируются автоматически, системами управления сайта (CMS), такими как Вордпресс, Модэкс, Тильда, Джумла, Опенкад итд. Полное исключение дублирования достигается на рукописных сайтах с чистым HTML.
Вот, что говорят по этому поводу Google и Яндекс:

Если Вы не хотите, чтобы поисковые системы самовольно определяли важность страниц, товаров и услуг на ваших сайтах, обязательно указывайте rel=canonical.
Каноническая страница rel=canonical как прописывать
После появления атрибута rel=canonical прошло уже очень много времени и практически все системы управления сайтами позволяют прописывать внутри себя канонические ссылки и исключать неканонические.
К примеру в CMS WordPress, у меня это делается автоматически за счет плагина Yoast SEO. Но если к примеру нужно поменять пагинацию, то делается это в дополнительных настройках плагина в этой графе:
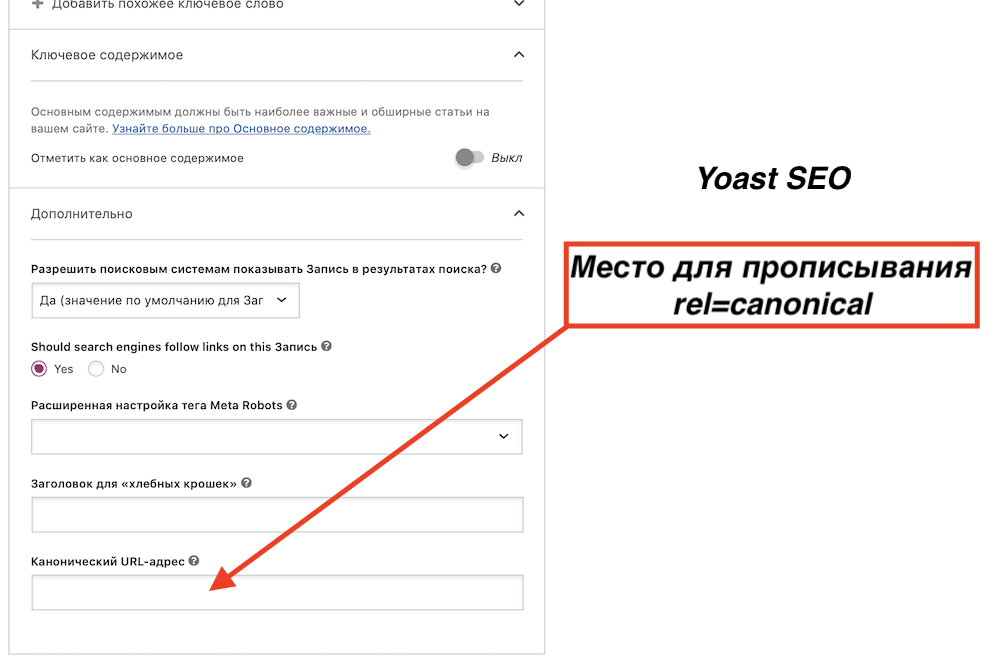
В коде элемента по умолчанию данная страница выглядет так:
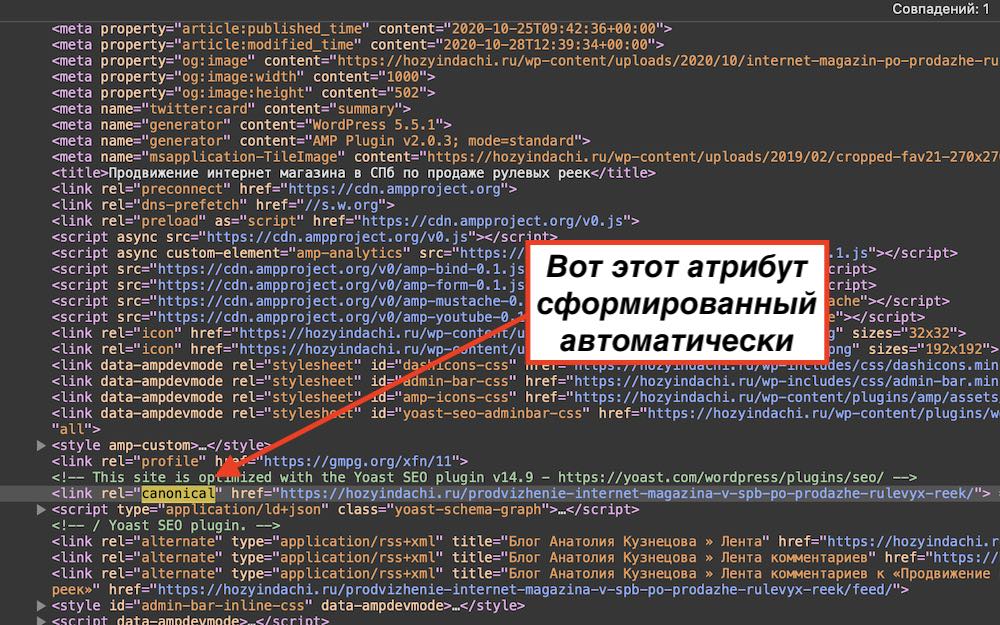
Ну надеюсь теперь Вы поняли, что такое канонические и неканонические ссылки, как их прописывать и как они влияют на продвижение сайта в Яндекс и Google.
Заключение
Хотите быстро продвинуть свой сайт в ТОП10 Яндекс и долго там оставаться? Продвигайтесь исключительно белыми, безопасными и современными LSI методами! Не умеете? Могу научить! Тем, кто хочет разобраться во всех премудростях LSI продвижения, предлагаю посетить мои уроки по SEO обучению, которые я провожу индивидуально, в режиме онлайн по скайпу.
Для тех, у кого нет времени проходить обучение и самостоятельно заниматься продвижением своих сайтов и интернет-магазинов, предлагаю и в этом вопросе помощь. Я могу взять ваш веб сайт на продвижение и за месяц вывести его в ТОП10 Яндекс. Для того, чтобы убедиться в моей экспертности, предлагаю ознакомиться с моими последними кейсами и только после этого заказать у меня SEO продвижение.
«Яндекс» начнёт чаще показывать неканонические страницы
Часто на сайтах присутствуют страницы с разными URL, но с одинаковым или очень похожим содержанием. С помощью атрибута rel=«canonical» вебмастера могут указать, какая страница является «канонической» — предпочтительной для индексации и появления в результатах поиска. Остальные, неканонические версии, как правило, на поиск не попадают.
Исследования «Яндекса» показывают, что страницы, размеченные как неканонические могут быть полезны, а их наличие в поиске может влиять на качество и полноту ответа на запрос пользователя. Например, если для темы форума владелец сайта указал канонической страницу с началом ветки, то многие важные и нужные ответы, которые были даны пользователями позже, на поиск не попадают.
Другой пример: бывает, что какое-то литературное произведение разбито на страницы и в качестве канонической прописана первая страница. В результате сайт не находится по запросу-цитате, соответствующей тексту за пределами первой страницы. Поэтому теперь в поиске неканонические страницы будут появляться чаще.
Они будут показаны в том случае, если они более релевантны запросу и их контент существенно отличался от канонической версии во время сканирования роботом. В Вебмастере такие страницы можно увидеть на странице «Страницы в поиске» с пометкой «Неканоническая». Помимо этого статуса поисковик начал показывать статусы «Каноническая» и «Каноническая страница не указана» для всех страниц, попавших в поиск.
Если канонические страницы настроены на сайте без ошибок, то никаких дополнительных действий от вебмастера не требуется. Для сайтов, имеющих много неканонических страниц, которые сильно отличались от канонических, возможен прирост количества страниц в Поиске.
Впрочем, канонические страницы по-прежнему попадают на поиск гораздо чаще и имеют более высокий приоритет при показе в результатах поиска. Объем трафика для каждого конкретного сайта существенно не изменится.
Неканонические страницы теперь попадают в индекс
4 июля Яндекс анонсировал, что теперь страницы, отмеченные как «неканонические» с помощью атрибута rel=«canonical», но которые он посчитает полезными, будут попадать в индекс, показываться в поиске.
Обычно страницы, помеченные этим атрибутом, в котором указана другая страница, по идее в индекс Яндекса никак не должны попадать. Однако теперь их будут сравнивать с указанной в rel=«canonical», и если отличия значительные, то может быть принято решение эту страницу из индекса не выбрасывать.
Если такое случилось с вашей страницей, то в Яндекс.Вебмастере придет сообщение о том, что «страница попала в поиск, поскольку во время сканирования роботом ее содержимое существенно отличалось от содержимого страницы по адресу, который указывался в rel=«canonical». И похоже, что эта страница будет ранжироваться точно так же, как если бы этого атрибута не было.
Какие могут быть негативные эффекты?
Чем это может быть чревато? В индекс могут попасть страницы, которые вы бы точно не хотели, чтобы туда попадали.
Но не стоит слишком паниковать. По тому, что демонстрирует Яндекс на данный момент, в тех случаях, когда приходили такие сообщения в Вебмастер, по факту оказывалось — там действительно страница имела некоторую самостоятельную ценностью.
То есть, когда применяется rel=«canonical»?
Например, на сайте есть страницы, которые создают дубль основной: с лишним слешем, с какими-то параметрами, с другим размером букв и т.д. И обычно в тех случаях, когда их не закрывают от поисковика другим способом — можно поставить редирект, например — то используют атрибут rel=«canonical». Для программистов это самый простой вариант, так действительно часто делают — и это нормальная ситуация. Этот атрибут закрывает от поиска нежелательные страницы и дубль не создается.
И здесь Яндекс пока ни разу не ошибся. То есть в тех страницах, которые действительно полностью дублируют «родительскую», атрибут rel=«canonical» применялся правлиьно — закрывал от поиска.
Когда же приходит в Вебмастер это сообщение, в каких случаях страница добавляется обратно в индекс? В основном это страницы типа форумов либо постраничная пагинация в комментариях — то есть там, где отличия существенны. И важно посмотреть, действительно ли имеются какие-то посты на форуме, которые несут самостоятельную ценность и могут ранжироваться. Стоит отдельно посмотреть на пагинацию на сайтах (то есть там, где в рубриках есть постраничность). Здесь есть такой нюанс: если у вас страницы вроде как друг от друга никак не отличаются и по идее указанные в rel=«canonical» не должны выводится, следует учесть, что товары на них указаны разные. И Яндекс может посчитать, что такие страницы имеют самостоятельную ценность и индексировать их. Что даст некоторый негативный эффект.
Чем это грозит?
Например, вы оптимизировали первую страницу рубрики, и у вас в остальные также подтянется и тайтл тот же самый, и h1 будет одинаковый, а в ряде случаев еще и тексты туда размножатся. Что в общем может создать негативный эффект: разные страницы рубрики будут мешаться друг другу, периодически может слетать релевантность с первой, перекидываясь на другую страницу пагинации, позиции в этот момент у первой страницы в большинстве случаев будут просаживаться. Поэтому стоит учесть этот момент и заранее проверить свои сайты.
Что делать?
Если у вас страницы пагинации стали залетать в индекс с таким статусом, то можно:
закрыть их от индексации более жестко;
попытался уникализировать настолько, чтобы они несли некоторую самостоятельную ценность. Сделать заголовки уникальными, тексты отдельные закидывать — то есть действительно оптимизировать под какую-то группу ключей, раз уж Яндекс посчитал их нормальными.
Но здесь опять же непонятно, под какую группу ключей тогда оптимизировать, потому что это же не подрубрика, а одна из страниц рубрики. То есть подобный вариант действий не оптимален. И скорее всего, если сайты с постраничностью начнут «влетать» под такое, то эти страницы лучше закрывать в robots, а может и в X-Robots-Tag, чтобы робот их не сканировал и не индексировал.
Стоит внимательно следить за этой ситуацией, за сайтами, потому как в любой момент может что-то пойти не так, «сбоинуть» и на позиции повлиять не лучшим образом.



