Национальная библиотека им. Н. Э. Баумана
Bauman National Library
Персональные инструменты
Реляционная база данных
Содержание
История
Реляционные системы берут свое начало в математической теории множеств. Эдгар Кодд, сотрудник исследовательской лаборатории корпорации IBM в Сан-Хосе, по существу, создал и описал концепцию реляционных баз данных в своей основополагающей работе «Реляционная модель для крупных, совместно используемых банков данных» (A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, июнь 1970).
Нечеткость многих терминов, используемых в сфере обработки данных, заставила Кодда отказаться от них и придумать новые или дать более точные определения существующим. Так, он не мог использовать широко распространенный термин «запись», который в различных ситуациях может означать экземпляр записи, либо тип записей, запись в стиле Кобола (которая допускает повторяющиеся группы) или плоскую запись (которая их не допускает), логическую запись или физическую запись, хранимую запись или виртуальную запись и т.д. Вместо этого он использовал термин «кортеж длины n» или просто «кортеж», которому дал точное определение.
Кодд предложил модель, которая позволяет разработчикам разделять свои базы данных на отдельные, но взаимосвязанные таблицы, что увеличивает производительность, но при этом внешнее представление остается тем же, что и у исходной базы данных. С тех пор Кодд считается отцом-основателем отрасли реляционных баз данных. Кодд сформулировал 12 правил для реляционных баз данных, большинство которых касаются целостности и обновления данных, а также доступа к ним.
Правила Кодда
Правило 0: Основное правило (Foundation Rule):
Система, которая рекламируется или позиционируется как реляционная система управления базами данных, должна быть способна управлять базами данных, используя исключительно свои реляционные возможности.
Правило 1: Информационное правило (The Information Rule):
Вся информация в реляционной базе данных на логическом уровне должна быть явно представлена единственным способом: значениями в таблицах.
Правило 2: Гарантированный доступ к данным (Guaranteed Access Rule):
В реляционной базе данных каждое отдельное (атомарное) значение данных должно быть логически доступно с помощью комбинации имени таблицы, значения первичного ключа и имени столбца.
Правило 3: Систематическая поддержка отсутствующих значений (Systematic Treatment of Null Values):
Неизвестные, или отсутствующие значения NULL, отличные от любого известного значения, должны поддерживаться для всех типов данных при выполнении любых операций. Например, для числовых данных неизвестные значения не должны рассматриваться как нули, а для символьных данных — как пустые строки.
Правило 4: Доступ к словарю данных в терминах реляционной модели (Active On-Line Catalog Based on the Relational Model):
Словарь данных должен сохраняться в форме реляционных таблиц, и СУБД должна поддерживать доступ к нему при помощи стандартных языковых средств, тех же самых, которые используются для работы с реляционными таблицами, содержащими пользовательские данные.
Правило 5: Полнота подмножества языка (Comprehensive Data Sublanguage Rule):
Система управления реляционными базами данных должна поддерживать хотя бы один реляционный язык, который (а) имеет линейный синтаксис, (б) может использоваться как интерактивно, так и в прикладных программах, (в) поддерживает операции определения данных, определения представлений, манипулирования данными (интерактивные и программные), ограничители целостности, управления доступом и операции управления транзакциями (begin, commit и rollback).
Правило 6: Возможность изменения представлений (View Updating Rule):
Каждое представление должно поддерживать все операции манипулирования данными, которые поддерживают реляционные таблицы: операции выборки, вставки, изменения и удаления данных.
Правило 7: Наличие высокоуровневых операций управления данными (High-Level Insert, Update, and Delete):
Операции вставки, изменения и удаления данных должны поддерживаться не только по отношению к одной строке реляционной таблицы, но и по отношению к любому множеству строк.
Правило 8: Физическая независимость данных (Physical Data Independence):
Приложения не должны зависеть от используемых способов хранения данных на носителях, от аппаратного обеспечения компьютеров, на которых находится реляционная база данных.
Правило 9: Логическая независимость данных (Logical Data Independence):
Представление данных в приложении не должно зависеть от структуры реляционных таблиц. Если в процессе нормализации одна реляционная таблица разделяется на две, представление должно обеспечить объединение этих данных, чтобы изменение структуры реляционных таблиц не сказывалось на работе приложений.
Правило 10: Независимость контроля целостности (Integrity Independence):
Вся информация, необходимая для поддержания целостности, должна находиться в словаре данных. Язык для работы с данными должен выполнять проверку входных данных и автоматически поддерживать целостность данных.
Правило 11: Независимость от расположения (Distribution Independence):
База данных может быть распределённой, может находиться на нескольких компьютерах, и это не должно оказывать влияния на приложения. Перенос базы данных на другой компьютер не должен оказывать влияния на приложения.
Правило 12: Согласование языковых уровней (The Nonsubversion Rule):
Если используется низкоуровневый язык доступа к данным, он не должен игнорировать правила безопасности и правила целостности, которые поддерживаются языком более высокого уровня.
Сущность реляционной базы данных
Реляционная база данных представляет собой набор таблиц (сущностей). Таблицы состоят из колонок и строк (кортежей). Внутри таблиц могут быть определены ограничения, между таблицами существуют отношения. При помощи SQL можно выполнять запросы, которые возвращают наборы данных, получаемых из одной или нескольких таблиц. В рамках одного запроса данные получаются из нескольких таблиц путем их соединения (JOIN), чаще всего для соединения используются те же колонки, которые определяют отношения между таблицами.
Нормализация — это процесс структурирования модели данных, обеспечивающий связность и отсутствие избыточности в данных. Целью нормализации реляционной базы данных является устранение недостатков структуры базы данных, приводящих к избыточности, которая, в свою очередь, потенциально приводит к различным аномалиям и нарушениям целостности данных.Теоретики реляционных баз данных в процессе развития теории выявили и описали типичные примеры избыточности и способы их устранения. Реляционные хранилища обеспечивают наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости. Касаемо масштабируемости, реляционные БД хорошо масштабируются только в том случае, если располагаются на единственном сервере.
Особенностью реляционной базы данных является использование в ней реляционной модели данных и вытекающие из этого последствия:
В реляционной базе данных данные создаются, обновляются, удаляются и запрашиваются с использованием языка структурированных запросов (SQL). SQL-запросы могут извлекать данные как из одиночной таблица, так и из нескольких таблиц.Такие запросы могут включать агрегации и сложные фильтры. Реляционная БД обычно содержит встроенную логику, такую как триггеры, хранимые процедуры и функции.
Реляционная система управления базой данных (РСУБД)
Доступ к реляционным базам данных осуществляется через реляционные системы управления базами данных (РСУБД). Почти все системы баз данных, которые мы используем, являются реляционными, такие как Oracle, SQL Server, MySQL, Sybase, DB2, TeraData и так далее. Причины такого доминирования неочевидны. На протяжении всего существования реляционных БД они постоянно предлагали наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости в сфере управлении данными.
Например, простой SELECT запрос может иметь сотни потенциальных путей выполнения, которые оптимизатор оценит непосредственно во время выполнения запроса. Все это скрыто от пользователей, однако внутри РСУБД создает план выполнения, основывающийся на вещах вроде алгоритмов оценки стоимости и наилучшим образом отвечающий запросу. Однако чтобы обеспечить все эти особенности, реляционные хранилища невероятно сложны внутри.
Реляционная система управления базой данных содержит:
Что значит реляционная база данных
По Вашему запросу ничего не найдено.
Рекомендуем сделать следующее:
Что такое реляционная база данных?
Реляционные базы данных представляют собой базы данных, которые используются для хранения и предоставления доступа к взаимосвязанным элементам информации. Реляционные базы данных основаны на реляционной модели — интуитивно понятном, наглядном табличном способе представления данных. Каждая строка, содержащая в таблице такой базы данных, представляет собой запись с уникальным идентификатором, который называют ключом. Столбцы таблицы имеют атрибуты данных, а каждая запись обычно содержит значение для каждого атрибута, что дает возможность легко устанавливать взаимосвязь между элементами данных.
Пример реляционной базы данных
В качестве примера рассмотрим две таблицы, которые небольшое предприятие использует для обработки заказов продукции. Первая таблица содержит информацию о заказчиках: каждая запись в ней включает в себя имя и адрес заказчика, платежные данные и информацию о доставке, номер телефона и т. д. Каждый элемент информации (атрибут) помещен в отдельный столбец базы данных, которому назначен уникальный идентификатор (ключ) для каждой строки. Во второй таблице—(с информацией о заказе) каждая—запись содержит идентификатор заказчика, совершившего заказ, название заказанного продукта, его количество, размер или цвет и т. д. Записи в этой таблице не содержат таких данных, как имя заказчика или его контактные данные.
У обеих таблиц есть только один общий элемент — идентификатор столбца (ключ). Благодаря наличию этого общего столбца реляционные базы данных могут устанавливать взаимосвязи между двумя таблицами. Когда приложение для обработки заказов передает заказ в базу данных, база данных обращается к таблице со сведениями о заказах, извлекает сведения о продукции и использует идентификатор заказчика из этой таблицы, чтобы найти сведения об оплате и доставке в таблице с информацией о нем. Затем на складе подбирают нужный продукт, заказчик своевременно получает свой заказ и производит оплату.
Структура реляционных баз данных
Реляционная модель подразумевает логическую структуру данных: таблицы, представления и индексы. Логическая структура отличается от физической структуры хранения. Такое разделение дает возможность администраторам управлять физической системой хранения, не меняя данных, содержащихся в логической структуре. Например, изменение имени файла базы данных не повлияет на хранящиеся в нем таблицы.
Разделение между физическим и логическим уровнем распространяется в том числе на операции, которые представляют собой четко определенные действия с данными и структурами базы данных. Логические операции дают возможность приложениям определять требования к необходимому содержанию, в то время как физические операции определяют способ доступа к данным и выполнения задачи.
Чтобы обеспечить точность и доступность данных, в реляционных базах должны соблюдаться определенные правила целостности. Например, в правилах целостности можно запретить использование дубликатов строк в таблицах, чтобы устранить вероятность попадания неправильной информации в базу данных.
Реляционная модель
В первых базах данных данные каждого приложения хранились в отдельной уникальной структуре. Если разработчик хотел создать приложение для использования таких данных, он должен был хорошо знать конкретную структуру, чтобы найти необходимые данные. Такой метод организации был неэффективен, сложен в обслуживании и затруднял оптимизацию эффективности приложений. Реляционная модель была разработана, чтобы устранить потребность в использовании разнообразных структур данных.
Она обеспечила стандартный способ представления данных и отправки запросов, которые могли быть использованы в любых приложениях. Разработчики уяснили, что таблицы являются ключевым преимуществом реляционных баз данных, так как обеспечивают интуитивно понятный, эффективный и гибкий способ хранения структурированной информации и получения к ней доступа.
Со временем, когда разработчики стали использовать язык структурированных запросов (SQL) для записи данных в базу и отправки запросов, стало очевидным и другое преимущество реляционной модели. Вот уже на протяжении многих лет SQL широко используется в качестве языка запросов в базах данных. Он основан на алгоритмах реляционной алгебры и четкой математической структуре, что обеспечивает простоту и эффективность при оптимизации любых запросов к базе данных. Для сравнения: при использовании других подходов приходится создавать отдельные, уникальные запросы.
Преимущества реляционных баз данных
Компании всех типов и размеров используют простую, но функциональную реляционную модель для обслуживания разнообразных информационных потребностей. Реляционные базы данных применяются для отслеживания товарных запасов, обработки торговых транзакций через Интернет, управления большими объемами критически важных данных заказчиков и т. д. Реляционные базы данных можно рекомендовать для обслуживания любых информационных потребностей, где элементы данных связаны между собой и необходимо обеспечивать безопасное и надежное управление ими на основе правил целостности.
Реляционные базы данных появились в 1970-х годах. На сегодняшний день преимущества реляционного подхода сделали его самой распространенной моделью для баз данных в мире.
Целостность данных
Реляционная модель наиболее эффективно поддерживает целостность данных во всех приложениях и копиях (экземплярах) базы данных. Например, когда заказчик кладет деньги на счет с помощью банкомата, а затем проверяет баланс на мобильном телефоне, он ожидает, что поступившие средства сразу же отобразятся на счете. Реляционные базы данных отлично подходят для обеспечения целостности данных в различных экземплярах базы в одно и то же время.
Другие типы баз данных не могут одновременно поддерживать целостность больших объемов данных. Некоторые современные типы баз данных, такие как NoSQL, обеспечивают только так называемую “окончательную целостность.” Это значит, что, когда выполняется масштабирование данных или несколько пользователей одновременно используют одни и те же данные, необходимо некоторое время на “внесение изменений”. В некоторых случаях окончательная целостность вполне приемлема (например, для обновления позиций в товарном каталоге), однако для критически важной операционной деятельности бизнеса (например, транзакций с использованием корзины) реляционные базы представляют собой фундаментальный стандарт.
Фиксация изменений и атомарность
В реляционных базах данных используются очень детальные и строгие бизнес-правила и политики в отношении фиксации изменений в базе данных (то есть сохранения изменений в данных на постоянной основе). Рассмотрим для примера складскую базу данных, в которой отслеживаются три запчасти, всегда использующиеся в комплекте. Когда одну из них извлекают из товарных запасов, две другие также должны извлекаться. Если одна из трех запчастей недоступна, две другие также не могут быть проданы отдельно, то есть, чтобы в базу данных можно было внести изменения, должны быть доступны все три запчасти. Реляционная база данных не разрешит сохранять изменения, если они не касаются всех трех запчастей. Эту особенность реляционных баз данных называют атомарностью или неразрывностью. Неразрывность необходима для сохранения точности данных в базе и обеспечения соответствия с правилами, нормативными положениями и бизнес-политиками.
Реляционные базы данных и ACID
Транзакции в реляционной базе данных имеют четыре важные характеристики: неразрывность (atomicity), целостность (consistency), изолированность (isolation) и неизменность (durability). Это сочетание получило название ACID.
Хранимые процедуры и реляционные базы данных
Доступ к данным включает в себя множество повторяющихся действий. Например, иногда для получения нужного результата простой запрос для получения информации из таблицы необходимо повторить сотню или тысячу раз. Для таких сценариев доступа к базе данных необходимо что-то вроде программного кода. Разработчикам каждый раз писать стандартный код доступа к данным для нового приложения было бы утомительно. К счастью, реляционные базы данных поддерживают хранимые процедуры, представляющие собой блоки кода, к которым можно получить доступ с помощью обычного вызова со стороны кода приложения. Например, одну и ту же хранимую процедуру можно использовать для последовательной маркировки записей в целях удобства пользователей для различных приложений. Хранимые процедуры также помогают разработчикам убедиться в правильной реализации определенных функций данных в приложении.
Блокировки базы данных и параллельный доступ
Когда несколько пользователей или приложений пытаются одновременно изменить одни и те же данные, это может вести к возникновению конфликта в базе. Блокировки и параллельный доступ снижают вероятность конфликтов и способствуют сохранению целостности данных.
Блокировка не разрешает другим пользователям и приложениям получать доступ к данным во время их обновления. В некоторых базах данных блокировка может применяться к целой таблице, что негативно отражается на эффективности приложения. В других типах баз данных, например реляционных базах Oracle, блокировка выполняется на уровне одной записи, оставляя другие записи в таблице доступными. Такой подход помогает сохранить эффективность приложения.
Инструмент параллельного доступа используется, когда несколько пользователей или приложений пытаются одновременно выполнить запросы к одной базе данных. Он обеспечивает доступ пользователей и приложений к базе данных в соответствии с политиками контроля.
Характеристики, на которые следует обратить внимание при выборе реляционной базы данных
Программное обеспечение, которое используется для сохранения, контроля и извлечения данных в базе, а также выполнения к ней запросов, называют системой управления реляционной базой данных (СУРБД). СУРБД обеспечивает интерфейс между пользователями и приложениями и базой данных, а также административные функции для управления хранением данных, их эффективностью и доступом к ним.
При выборе типа базы данных и продуктов на основе реляционных баз данных необходимо учитывать несколько факторов. Выбор СУРБД зависит от потребностей Вашей компании. Задайте себе следующие вопросы.
Реляционная база данных будущего: автономная база данных
На протяжении последних лет реляционные базы данных улучшали свою производительность, надежность и безопасность и становились проще в обслуживании. Однако их структура становилась все более сложной, и, как следствие, администрирование такой базы данных начало требовать немалых усилий. Вместо того, чтобы использовать свои навыки для разработки инновационных приложений, которые будут приносить прибыль компании, разработчики вынуждены посвящать львиную долю времени управлению базой данных для оптимизации ее эффективности.
Мы использовали автономные технологии, чтобы расширить возможности реляционной модели и создать реляционную базу данных нового типа. Самоуправляемая база данных (которую также называют автономной) сохраняет все преимущества и возможности реляционной модели и добавляет к ним средства на основе искусственного интеллекта, машинного обучения и автоматизации для мониторинга и оптимизации скорости выполнения запросов и управления. Например, чтобы улучшить скорость выполнения запросов, самоуправляемая база данных строит прогнозы и проверяет индексы, а затем применяет лучшие результаты на практике — и все это без участия администратора. Самоуправляемые базы данных постоянно вносят такие улучшения в собственную работу без человеческого вмешательства.
Автономные технологии дают возможность разработчикам больше не тратить время на рутинные задачи обслуживания. Например, больше не нужно заблаговременно определять требования к инфраструктуре. При использовании решения IaaS Вы арендуете ресурсы, например вычислительные мощности или хранилище, получаете доступ к нужным ресурсам по мере необходимости и платите только за те из них, которые использует Ваша компания. Разработчики могут создавать автономные реляционные базы данных всего за несколько шагов, ускоряя процесс разработки приложений.
Как работает реляционная БД
 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
На самом деле, мало кто действительно понимает, как работают реляционные БД. А многие разработчики очень не любят, когда они чего-то не понимают. Если реляционные БД используют порядка 40 лет, значит тому есть причина. РБД — штука очень интересная, поскольку в ее основе лежат полезные и широко используемые понятия. Если вы хотели бы разобраться в том, как работают РБД, то эта статья для вас.
Сразу нужно подчеркнуть: из этого материала вы НЕ узнаете, как можно использовать БД. Однако для усвоения материала вы должны уметь написать хотя бы простенький запрос на соединение и CRUD-запрос. Этого вполне достаточно для понимания статьи, остальное будет объяснено.
1. Основы
Давным-давно (в далёкой-далёкой галактике) разработчики должны были держать в голове точное количество операций, которые они кодят. Они всем сердцем чувствовали алгоритмы и структуры данных, поскольку не могли себе позволить тратить впустую ресурсы процессора и памяти на своих медленных компьютерах прошлого. В этой главе мы вспомним некоторые концепции, которые необходимы для понимания работы БД.
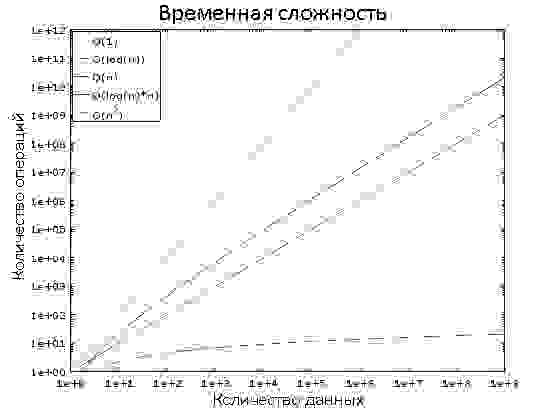
1.1. О(1) против О(n 2 )
Сегодня многие разработчики не особо задумываются о временнόй сложности алгоритмов… и они правы! Но когда приходится работать с большим объёмом данных, или если нужно экономить миллисекунды, то временнáя сложность становится крайне важна.
Временнáя сложность используется для оценки производительности алгоритма, как долго будет выполняться алгоритм для входных данных определённого размера. Обозначается временнáя сложность как «О» (читается как «О большое»). Это обозначение используется вместе с функцией, описывающей количество операций, осуществляемых алгоритмом для обработки входных данных.
Например, если сказать «этот алгоритм есть О большое от некоторой функции», то это означает, что для определённого объёма входных данных алгоритму нужно выполнить количество операций, пропорциональное значению функции от этого определённого объёма данных.
Здесь важен не объём данных, а динамика увеличения количества операций с ростом объёма. Временнáя сложность не позволяет вычислить точное количество, но зато представляет собой хороший способ оценки.
1.1.3. Ещё немного подробностей
1.2. Сортировка слиянием
Что вы делаете, когда вам нужно отсортировать коллекцию? Вызываете функцию sort(), верно? Но понимаете ли вы, как она работает?
Есть несколько хороших алгоритмов сортировки, но здесь мы рассмотрим только один из них: сортировку слиянием. Возможно, сейчас вам это знание не кажется полезным, но вы поменяете мнение после глав про оптимизацию запросов. Более того, понимание работы этого алгоритма поможет понять принцип важной операции — соединение слиянием.
В основе алгоритма сортировки слиянием лежит одна хитрость: для слияния двух отсортированных массивов размером N/2 каждый требуется всего лишь N операций, называющихся слиянием.
Рассмотрим пример операции слияния:

Пример псевдокода сортировки слиянием:
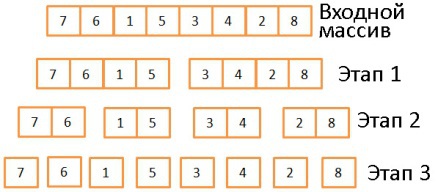
В три этапа исходный массив делится на подмассивы, состоящие из одного элемента. Вообще, количество этапов деления определяется как log(N) (в данном случае N=8, log(N) = 3). Идея в том, чтобы на каждом этапе делить входящие массивы пополам. То есть описывается логарифмом с основанием 2.
1.2.3. Фаза сортировки
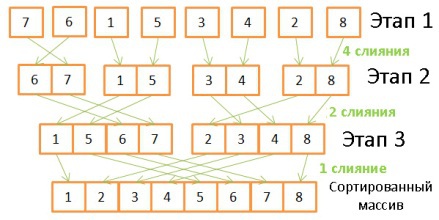
1.2.4. Возможности сортировки слиянием
1.3. Массив, дерево и хэш-таблица
Итак, с временнόй сложностью и сортировкой разобрались. Теперь давайте обсудим три структуры данных, на которых держатся современные БД.
Двумерный массив — простейшая структура данных. Таблица может быть представлена в виде массива:
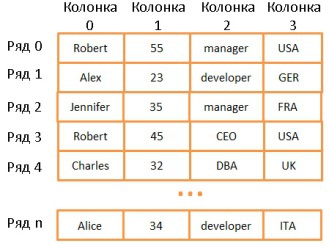
Здесь каждая строка представляет собой какой-то объект, колонка — свойство объекта. Причём разные колонки содержат разные типы данных (целые числа, строки, даты и т.д.).
Это очень удобный способ хранения и визуализации информации, но очень неподходящий для случаев, когда нужно найти какое-то конкретное значение. Допустим, вам нужно найти всех сотрудников, работающих в Великобритании. Для этого придётся просмотреть все строки, чтобы найти те, где имеется значение “UK”. На это потребуется N операций (N — количество строк). Не так уж и плохо, но хорошо бы и побыстрее. И здесь нам помогут деревья.
Примечание: большинство современных СУБД используют продвинутые виды массивов, позволяющие эффективнее хранить таблицы (например, на основе куч или индексов). Но это не решает проблему скорости поиска по колонкам.
1.3.2. Дерево и индекс БД
Каждый узел представляет собой указатель на строку в связанной таблице.
Но вернёмся к нашей проблеме.
Допустим, у нас есть строковые значения, соответствующие названиям разных государств. Соответственно и узлы дерева содержат строковые ключи. Чтобы найти сотрудников, работающих в “UK”, нужно просмотреть все узлы, чтобы найти соответствующий, и извлечь из него ID всех строк, содержащих данное значение. В отличие от поиска по массиву, здесь нам потребуется всего log(N) операций. Описанная конструкция называется индексом БД.
Такой индекс можно создать для любой группы колонок (для строковых, целочисленных, их комбинаций, дат и т.д.), если у вас есть функция для сравнения ключей (т.е. групп колонок). Таким образом вы можете распределить ключи в определённом порядке.
Несмотря на высокую скорость поиска, дерево плохо работает в случаях, когда нужно получить несколько элементов в пределах двух значений. Временнáя сложность будет равна О(N), потому что нам придётся просмотреть каждый узел и сравнить его с заданными условиями. Более того, данная процедура требует большого количества операций ввода/вывода, ведь нужно считывать всё дерево. То есть нам нужен более эффективный способ запроса диапазона. В современных БД для этого используется модифицированная версия дерева — В+дерево. Его особенность в том, что информацию (ID строк связанной таблицы) хранят лишь самые нижние узлы («листья»), а все остальные узлы предназначены для оптимизации поиска по дереву.
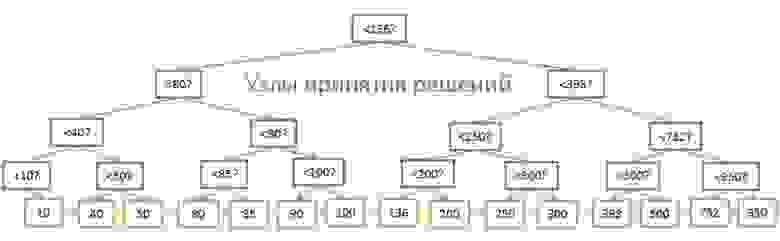
Как видите, здесь вдвое больше узлов. «Узлы принятия решений» помогают найти нужные узлы, содержащие ID строк в таблице. Но сложность поиска всё ещё равна О(log(N)) (добавился один уровень узлов). Однако главной особенностью B-дерева является то, что «листья» образуют наследственные связи.
Подробнее о В+деревьях можно почитать на Википедии, а также в статьях (один, два) от ведущих разработчиков MySQL. В них рассказывается о том, как InnoDB (движок MySQL) работает с индексами.
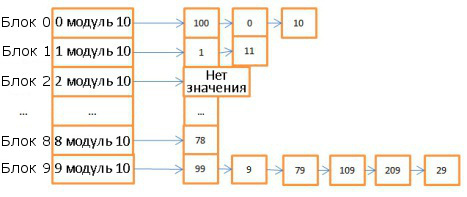
Здесь 10 блоков, в качестве хэш-функции брался модуль 10 от значения ключа. То есть для поиска нужного блока достаточно знать последнюю цифру значения ключа: если это 0, то элемент хранится в корзине 0, если 1, то в корзине 1, и т.д. В качестве функции сравнения используется операция сравнения двух целочисленных.
Как видите, скорость поиска зависит от искомого значения. Изменим хэш-функцию, будет вычислять хэши по модулю 1 000 000 (то есть берём последние 6 цифр). В этом случае на поиск элемента 59 уйдёт лишь одна операция, поскольку в блоке 000059 нет никаких элементов. Поэтому крайне важно подобрать удачную хэш-функцию, которая будет генерировать блоки с очень небольшим количеством элементов.
Массив против хэш-таблицы
2. Общий обзор
Мы рассмотрели базовые компоненты БД. Теперь давайте отойдём назад и окинем взглядом всю картину.
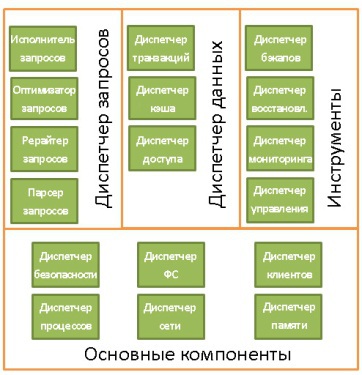
На самом деле, существует куча разных представлений о том, как может выглядеть структура БД. Так что не надо зацикливаться на данной иллюстрации. Нужно лишь усвоить, что БД состоит из различных компонентов, взаимодействующих между собой.
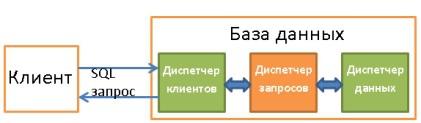
3. Диспетчер клиентов
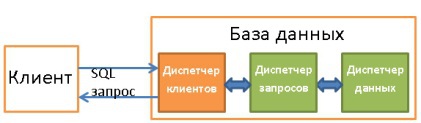
Используется для управления соединениями с клиентами — веб-серверами или конечными пользователями/приложениями. Диспетчер клиентов обеспечивает разные способы доступа к БД с помощью как всем известных API (JDBC, ODBC, OLE-DB и т.д.), так и с помощью проприетарных.
4. Диспетчер запросов
4.1. Парсер запросов
Каждый SQL-оператор отправляется в парсер и проверяется на правильность синтаксиса. Если вы сделаете ошибку в запросе, то парсер его отклонит. Например, напишете SLECT вместо SELECT.
Но этим функции парсера не ограничиваются. Он также проверяет, чтобы ключевые слова использовались в правильном порядке. Например, если WHERE будет идти до SELECT, то запрос будет отклонён.
В ходе всех этих проверок SQL-запрос трансформируется во внутреннее представление (чаще всего в дерево). Если всё в порядке, то оно отправляется в рерайтер запросов.
4.2. Рерайтер запросов
4.3. Статистика
Прежде чем перейти к рассмотрению оптимизирования запросов, давайте поговорим о статистике, поскольку без неё БД становится совершенно безмозглой. Если вы не скажете ей проанализировать собственные данные, она этого и не сделает, сделав очень плохие допущения.
Какого рода информация нужна БД?
Сначала давайте вспомним, как БД и ОС хранят данные. Для этого они используют такие минимально возможные сущности, как страницы или блоки (размером по 4 или 8 Кбайт по умолчанию). Если вам нужно сохранить 1 Кбайт, то на это всё-равно уйдёт целая страница. То есть вы попусту тратите много места в памяти и на диске.
Очень большое значение имеет статистика по каждой колонке. Например, нам нужно в таблице объединить две колонки: «фамилия» и «имя». Благодаря статистике БД знает, что в ней содержится 1 000 уникальных значений «имя» и 1 000 000 — «фамилия». Поэтому база объединит данные именно в таком порядке — «фамилия, имя», а не «имя, фамилия»: это требует гораздо меньше операций сравнения, поскольку вероятность совпадения фамилий гораздо ниже, и в большинстве случаев для сравнения достаточно брать 2-3 первые буквы фамилии.
Если вы уже знакомы с динамическим программированием или алгоритмизацией, можете поиграться с этим алгоритмом:
Но если запрос очень велик, или если нам нужно крайне быстро получить ответ, используется другой класс алгоритмов — жадные алгоритмы.
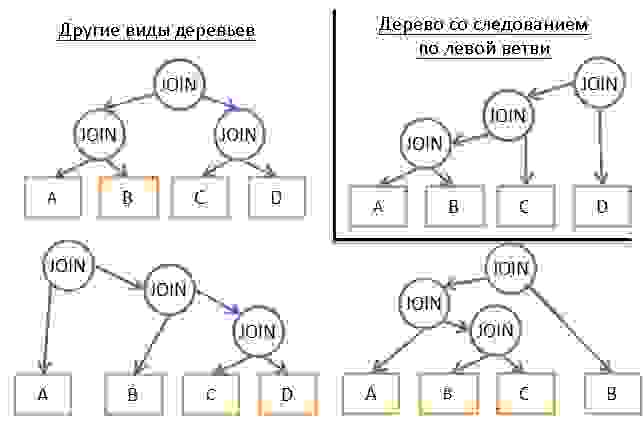
В данном случае план исполнения запроса строится пошагово с помощью некоего правила (эвристики). Благодаря ему жадный алгоритм ищет наилучшее решение для каждого этапа по отдельности. План начинается с оператор JOIN, а затем на каждом этапе добавляется новый JOIN в соответствии с правилом.
Не будем углубляться в подробности, но при хорошем моделировании сложности сортировки N*log(N) данная проблема может быть легко решена. Временнáя сложность алгоритма равна О(N*log(N)) вместо О(3 N ) для полной версии с динамическим программированием. Если у вас большой запрос с 20 объединениями, то это будет 26 против 3 486 784 401. Большая разница, верно?
Но есть нюанс. Мы предполагаем, что если найдём наилучший способ объединения двух таблиц, то получим самую низкую стоимость при объединении результатом предыдущих объединений со следующими таблицами. Однако даже если A JOIN B будет самым дешёвым вариантом, то (A JOIN C) JOIN B может иметь стоимость ниже, чем (A JOIN B) JOIN C.
Так что если вам позарез нужно найти самый дешёвый план всех времён и народов, то можно посоветовать многократно прогонять жадные алгоритмы с использованием разных правил.
Если вы уже сыты по горло всеми этими алгоритмами, то можете пропустить эту главу. Она не обязательна для усвоения всего остального материала.
Многие исследователи занимаются проблемой поиска наилучшего плана исполнения запроса. Зачастую пытаются найти решения для каких-то конкретных задач и шаблонов. Например, для звездообразных объединений, исполнения параллельных запросов и т.д.
Ищутся варианты замены динамического программирования для исполнения больших запросов. Те же жадные алгоритмы являются подмножеством эвристических алгоритмов. Они действуют сообразно правилу, запоминают результат одного этапа и используют его для поиска лучшего варианта для следующего этапа. И алгоритмы, которые не всегда используют решение, найденное для предыдущего этапа, называются эвристическими.
В БД используются и такие эвристические алгоритмы, как симулированная нормализация (Simulated Annealing), итеративное улучшение (Iterative Improvement), двухфазная оптимизация (Two-Phase Optimization). Но не факт, что они применяются в корпоративных системах, возможно, их удел — исследовательские продукты.
4.4.6. Настоящие оптимизаторы
Тоже необязательная глава, можно и пропустить.
Прочие условия (GROUP BY, DISTINCT и т.д.) обрабатываются простыми правилами.
4.4.7. Кэш плана запросов
Поскольку составление плана требует времени, большинство БД хранят план в кэше плана запросов. Это помогает избежать ненужных вычислений одних и тех же этапов. БД должна знать, когда именно ей нужно обновить устаревшие планы. Для этого устанавливается некий порог, и если изменения в статистике его превышают, то план, относящийся к данной таблице, удаляется из кэша.
Исполнитель запросов
На данном этапе наш план уже оптимизирован. Он перекомпилируется в исполняемый код и, если ресурсов достаточно, исполняется. Операторы, содержащиеся в плане (JOIN, SORT BY и т.д.) могут обрабатываться как последовательно, так и параллельно, решение принимает исполнитель. Для получения и записи данных он взаимодействует с диспетчером данных.
5. Диспетчер данных
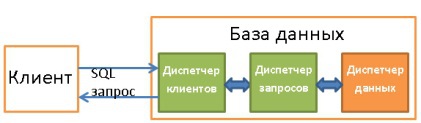
5.1. Диспетчер кэша
Как уже не раз говорилось, самым узким местом в БД является дисковая подсистема. Поэтому для увеличения производительности используется диспетчер кэша.
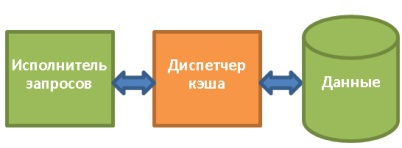
Однако тут мы сталкиваемся с другой проблемой. Диспетчеру кэша нужно положить данные в память ДО того, как они понадобятся исполнителю запросов. Иначе тому придётся ждать их получения с медленного диска.
Исполнитель запросов знает, какие данные ему понадобятся, поскольку ему известен весь план, то, какие данные содержатся на диске и статистика.
Когда исполнитель обрабатывает первую порцию данных, он просит диспетчер кэша заранее подгрузить следующую порцию. А когда переходит к её обработке, то просит ДК подгрузить третью и подтверждает, что первую порцию можно удалить из кэша.
Диспетчер кэша хранит эти данные в буферном пуле. Он также добавляет к ним сервисную информацию (триггер, latch), чтобы знать нужны ли они ещё в буфере.
Иногда исполнитель не знает, какие данные ему будут нужны, или некоторые БД не имеют подобного функционала. Тогда используется спекулятивное упреждение (speculative prefetching) (например, если исполнитель запрашивает данные 1, 3, 5, то наверняка запросит в будущем 7, 9, 11) или последовательное упреждение (sequential prefetching) (в данном случае ДК просто подгружает с диска следующую по порядку порцию данных.
Для контроля качества упреждения в современных БД используется метрика «коэффициент использования буфера/кэша» (buffer/cache hit ratio). Она показывает, как часто запрашиваемые данные оказываются в кэше, без необходимости обращения к диску. Однако низкое значение коэффициента не всегда говорит о плохом использовании кэша. Подробнее об этом можно почитать в документации Oracle.
Нельзя забывать, что буфер ограничен объёмом доступной памяти. То есть для загрузки одних данных нам приходится периодически удалять другие. Заполнение и очистка кэша потребляет часть ресурсов дисковой подсистемы и сети. Если у вас есть часто исполняемый запрос, то было бы контрпродуктивно каждый раз загружать и очищать используемые им данные. Для решения данной проблемы в современных БД используется стратегия замены буфера.
5.1.2. Стратегии замены буфера
Большинство БД (по крайне мере, SQL Server, MySQL, Oracle и DB2) используют для этого алгоритм LRU (Least Recently Used). Он предназначен для поддержания в кэше тех данных, которые недавно использовались, а значит велика вероятность, что они могут понадобиться снова.
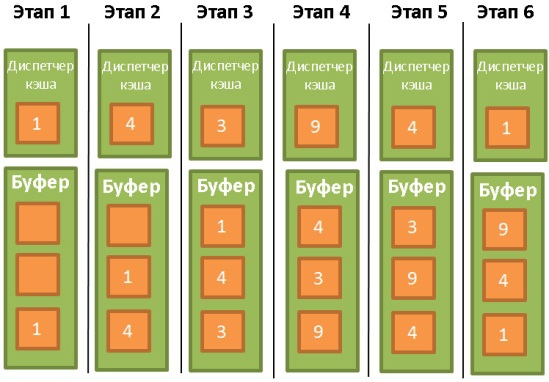
Чтобы этого не произошло, в некоторых БД используются специальные правила. Согласно документации Oracle:
«Для очень больших таблиц обычно используется прямой доступ, то есть блоки данных считываются напрямую, чтобы избежать переполнения буфера кэша. Для таблиц среднего размера может использоваться как прямой доступ, так и чтение из кэша. Если система решит использовать кэш, то БД помещает блоки данных в конец списка LRU, чтобы предотвратить очистку буфера».
Также используется улучшенная версия LRU — LRU-K. В SQL Server применяется LRU-K при К = 2. Суть этого алгоритма в том, что при оценке ситуации он учитывает больше информации о прошлых операциях, а не только запоминает последние использованные данные. Буква К в названии означает, что алгоритм принимает во внимание, какие данные использовались последние К раз. Им присваивается определённый вес. Когда в кэш загружаются новые данные, то старые, но часто используемые не удаляются, потому что их вес выше. Конечно, если данные больше не используются, то они всё-таки будут удалены. И чем дольше данные остаются невостребованными, тем сильнее уменьшается со временем их вес.
Вычисление веса довольно накладно, поэтому в SQL Server используется LRU-K при К равном всего лишь 2. При некотором увеличении значения К эффективность алгоритма улучшается. Вы можете ближе познакомиться с ним благодаря одной работе 1993-го года.
Конечно, LRU-K не единственное решение. Существуют также 2Q и CLOCK (оба похожи на LRU-K), MRU (Most Recently Used, в котором используется логика LRU, но применяется другое правило, LRFU (Least Recently and Frequently Used) и т.д. В некоторых БД можно выбирать, какой алгоритм будет использоваться.
Мы говорили только о буфере чтения, но БД используют и буферы записи, которые накапливают данные и сбрасывают на диск порциями, вместо последовательной записи. Это позволяет экономить операции ввода/вывода.
Помните, что буферы хранят страницы (неделимые единицы данных), а не ряды из таблиц. Страница в буферном пуле называется «грязной», если она модифицирована, но не записана на диск. Есть много разных алгоритмов, с помощью которых выбирается время записи грязных страниц. Но это во многом связано с понятием транзакций.
5.2. Диспетчер транзакций
В его обязанности входит отслеживание, чтобы каждый запрос исполнялся с помощью собственной транзакции. Но прежде чем поговорить о диспетчере, давайте проясним концепцию ACID-транзакций.
5.2.1. «Под кислотой» (игра слов, если кто не понял)

Например, транзакция А выполняет
Потом транзакция Б добавляет в таблицу Х и коммитит новые данные. И если после этого транзакция А снова выполняет count(1), то результат будет уже другим.
Это называется грязным чтением.
Большинство БД добавляют собственные уровни изолированности (например, на основе снэпшотов, как в PostgreSQL, Oracle и SQL Server). Также во многих БД не реализованы все четыре вышеописанных уровня, особенно чтение незафиксированных данных.
Пользователь или разработчик может сразу же после установления соединения переопределить уровень изолированности по умолчанию. Для этого достаточно добавить очень простую строчку кода.
5.2.2. Управление параллелизмом
Главное, для чего нам нужны изолированность, согласованность и атомарность, это возможность осуществлять операции записи над одними и теми же данными (добавлять, обновлять и удалять).
Если все транзакции будут только читать данные, то смогут работать одновременно, не влияя на другие транзакции.
Если хотя бы одна транзакция изменяет данные, читаемые другими транзакциями, то БД нужно найти способ скрыть от них эти изменения. Также нужно удостовериться, что сделанные изменения не будут удалены другими транзакциями, которые не видят изменённых данных.
Это называется управлением параллелизмом.
Проще всего просто выполнять транзакции поочерёдно. Но такой подход обычно неэффективен (задействуется лишь одно ядро одного процессора), и к тому же теряется возможность масштабирования.
5.2.3. Диспетчер блокировок
Для решения вышеописанной проблемы во многих БД используются блокировки (locks) и/или версионность данных.
Если транзакции нужны какие-то данные, то она блокирует их. Если другой транзакции они тоже потребовались, то её придётся ждать, пока первая транзакция не снимет блокировку.
Это называется эксклюзивной блокировкой.
Но слишком расточительно использовать эксклюзивные блокировки в случаях, когда транзакциям нужно всего лишь считать данные. Зачем мешать чтению данных? В таких случаях используются совместные блокировки. Если транзакции нужно считать данные, они применяет к ним совместную блокировку и читает. Это не мешает другим транзакциям тоже применять совместные блокировки и читать данные. Если же какой-то из них нужно изменить данные, то ей придётся подождать, пока все совместные блокировки не будут сняты. Только после этого она сможет применить эксклюзивную блокировку. И тогда уже всем остальным транзакциям придётся ждать её снятия, чтобы считывать эти данные.
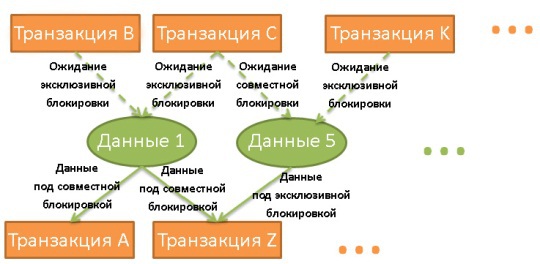
Диспетчер блокировок — это процесс, который применяет и снимает блокировки. Они хранятся в хэш-таблице (ключами являются блокируемые данные). Диспетчер знает для всех данных, какие транзакции применили блокировки или ждут их снятия.
Взаимная блокировка (deadlock)
Использование блокировок может привести к ситуации, когда две транзакции бесконечно ожидают снятия блокировок:
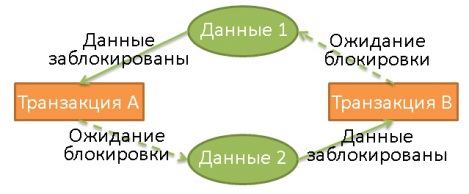
Здесь транзакция А эксклюзивно заблокировала данные 1 и ожидает освобождения данных 2. В то же время транзакция Б эксклюзивно заблокировала данные 2 и ожидает освобождения данных 1.
Представим хэш-таблицу в виде диаграммы, как на иллюстрации выше. Если на диаграмме присутствует циклическая связь, то взаимная блокировка подтверждена. Но поскольку проверять на наличие циклов достаточно дорого (ведь диаграмма, на которой отражены все блокировки, будет весьма большой), зачастую используется более простой подход: использование таймаутов. Если блокировка не снимается в течение определённого времени, значит транзакция вошла в состояние взаимной блокировки.
Перед наложением блокировки диспетчер также может проверить, не приведёт ли это к возникновению взаимной блокировки. Но чтобы однозначно на это ответить, тоже придётся потратиться на вычисления. Поэтому подобные предпроверки зачастую представлены в виде набора базовых правил.
Проще всего полная изолированность обеспечивается, когда блокировка применяется в начале и снимается в конце транзакции. Это означает, что транзакции перед началом приходится дожидаться снятия всех блокировок, а применённые ею блокировки снимаются лишь по завершении. Такой подход можно применять, но тогда теряется куча времени на все эти ожидания снятия блокировок.
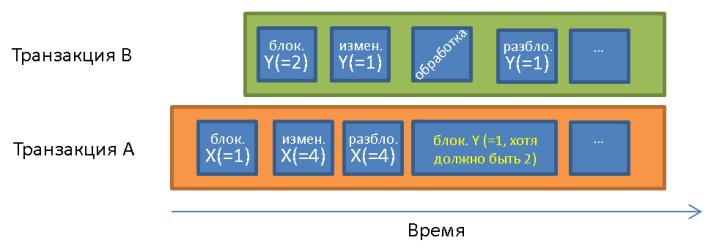
До транзакции А X = 1 и Y = 1. Она обрабатывает данные Y = 1, которые были изменены транзакцией В уже после начала транзакции А. В связи с принципом изолированности транзакция А должна обрабатывать Y = 2.
Конечно, реальные БД используют более сложные системы, больше видов блокировок и с большей гранулярностью (блокировки строк, страниц, партиций, таблиц, табличных пространств), но суть та же.
Оба подхода — блокировки и версионность — имеют плюсы и минусы, многое зависит от того, в какой ситуации они применяются (больше чтений или больше записей). Можете изучить очень хорошую презентацию, посвящённую реализации мультиверсионного управления параллелизмом в PostgreSQL.
В некоторых БД (DB2 до версии 9.7, SQL Server) используются только блокировки. Другие, вроде PostgreSQL, MySQL и Oracle, используются комбинированные подходы.
Примечание: версионность оказывает интересное влияние на индексы. Иногда в уникальном индексе появляются дубликаты, индекс может содержаться больше записей, чем строк в таблице и т.д.
Если часть данных считывается при одном уровне изолированности, а потом он увеличивается, то вырастает количество блокировок, а значит теряется больше времени на ожидания транзакций. Поэтому большинство БД не используют по умолчанию максимальный уровень изолированности.
Как обычно, за более подробной информацией обращайтесь к документации: MySQL, PostgreSQL, Oracle.
5.2.4. Диспетчер логов
Как мы уже знаем, ради увеличения производительности БД хранит часть данных в буферной памяти. Но если сервер падает во время коммита транзакции, то находящиеся в памяти данные будут потеряны. А это нарушает принцип надёжности транзакций.
Конечно, можно всё писать на диск, но при падении вы останетесь с недописанными данными, а это уже нарушение принципа атомарности.
Любые изменения, записанные транзакцией, должны быть отменены или завершены.
В больших БД с многочисленными транзакциями теневые копии/страницы занимают невероятно много места в дисковой подсистеме. Поэтому в современных БД используется лог транзакции. Он должен размещаться в защищённом от сбоев хранилище.
За выполнением этих правил следит диспетчер логов. Логически он расположен между диспетчером кэша и диспетчером доступа к данным. Диспетчер логов регистрирует каждую операцию, выполняемую транзакциями, до момента записи на диск. Вроде верно?
НЕВЕРНО! После всего, через что мы с вами прошли в этой статье, пора бы уже запомнить, что всё связанное с БД подвергается проклятью «эффекта базы данных». Если серьёзно, то проблема в том, что нужно найти способ писать в лог, при этом сохраняя хорошую производительность. Ведь если лог транзакций работает медленно, то он тормозит все остальные процессы.
В 1992 год исследователи из IBM создали расширенную версию WAL, которую назвали ARIES. В том или ином виде ARIES используется большинством современных БД. Если вы захотите поглубже изучить этот протокол, можете проштудировать соответствующую работу.
Как это возможно? Чтобы ответить на это, нужно сначала разобраться с тем, какая информация сохраняется в логе.
Насколько известно, UNDO не используется только в PostgreSQL. Вместо этого используется сборщик мусора, убирающий старые версии данных. Это связано с реализацией версионности данных в этой СУБД.
Чтобы вам было легче представить состав записи в логе, вот визуальный упрощённый пример, в котором выполняется запрос UPDATE FROM PERSON SET AGE = 18;. Пусть он исполняется в транзакции номер 18:
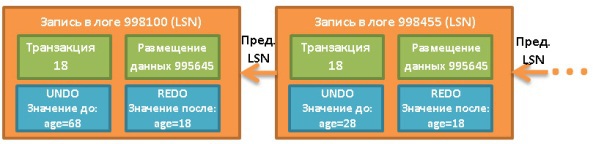
Каждый лог имеет уникальный LSN. Связанные логи относятся к одной и той же транзакции, причём линкуются они в хронологическом порядке (последний лог списка относится к последней операции).
Буфер логов
Чтобы запись в лог не превратилась в узкое место системы, используется буфер логов.
Политики STEAL и FORCE
Для увеличения производительности шаг номер 5 нужно делать после коммита, поскольку в случае сбоя всё ещё возможно восстановить транзакцию с помощью REDO. Это называется «политика NO-FORCE».
Но БД может выбрать и политику FORCE ради уменьшения нагрузки во время восстановления. Тогда шаг номер 5 выполняется до коммита.
Также БД выбирает, записывать ли данные на диск пошагово (политика STEAL) или, если диспетчер буфера должен дождаться коммита, записать всё разом (NO-STEAL). Выбор зависит от того, что вам нужно: быструю запись с долгим восстановлением или быстрое восстановление?
Если LSN(страницы_на_диске)>=LSN(записи_в_логе), то значит данные уже были записаны на диск перед сбоем. Но значение было перезаписано операцией, которая была выполнена после записи в лог и до сбоя. Так что ничего не сделано, на самом деле.



