Строковые методы split() и join() в Python
При работе со строками в Python вам может потребоваться разбить строку на подстроки или, наоборот, объединить несколько мелких кусочков в одну большую строку. В этой статье мы рассмотрим методы split() и join(), которые как раз и используются для разделения и объединения строк. Мы на примерах разберем, как они помогают легко выполнять необходимые нам задачи.
Важно отметить, что поскольку строки в Python неизменяемы, вы можете вызывать для них методы, не изменяя исходные строки. Итак, давайте начнем!
Метод split()
Когда вам нужно разбить строку на подстроки, вы можете использовать метод split().
Метод split() принимает строку и возвращает список подстрок. Синтаксис данного метода выглядит следующим образом:
Здесь – любая допустимая строка в Python, а sep – это разделитель, по которому вы хотите разделить исходную строку. Его следует указывать в виде строки.
sep – необязательный аргумент. По умолчанию метод split() разбивает строки по пробелам.
Таким образом, при одном разрезе строки вы получаете 2 подстроки. При двух разрезах — 3 подстроки. то есть, разрезая строку k раз, вы получите k+1 фрагментов.
Давайте рассмотрим несколько примеров, чтобы увидеть метод split() в действии.
Примеры использования метода split() в Python
Вы можете видеть, что my_string разделена по всем пробелам. Метод возвращает список подстрок.
Рассмотрим следующий пример. Здесь my_string содержит названия фруктов, разделенные запятыми.
Давайте разделим my_string по запятым. Для этого нужно установить sep = «,» или просто передать в метод «,» при вызове.
Как и ожидалось, метод split() вернул список фруктов, где каждый фрукт из my_string стал элементом списка.
Теперь давайте воспользуемся необязательным аргументом maxsplit и установив его равным 2.
Попробуем разобрать получившийся список.
Сделав два разреза строки, мы достигли установленного максимума, и дальнейшее деление невозможно. Поэтому часть строки после второй запятой объединяется в один элемент в возвращаемом списке.
Метод join()
Теперь, когда вы знаете, как разбить строку на подстроки, пора научиться использовать метод join() для формирования строки из подстрок.
Синтаксис метода Python join() следующий:
Здесь – любой итерируемый объект Python, содержащий подстроки. Это может быть, например, список или кортеж. – это разделитель, с помощью которого вы хотите объединить подстроки.
А теперь пора примеров!
Примеры использования метода join() в Python
Теперь давайте сформируем строку, объединив элементы этого списка при помощи метода join(). Все элементы в my_list – это названия фруктов.
Обратите внимание, что разделитель для присоединения должен быть указан именно в виде строки. В противном случае вы столкнетесь с синтаксическими ошибками.
Здесь элементы my_list объединяются в одну строку с помощью запятых, за которыми следуют пробелы.
Разделитель может быть любым.
Теперь вы знаете, как сформировать одну строку из нескольких подстрок с помощью метода join().
Заключение
Итак, мы рассмотрели строковые методы split() и join(). Из этой статьи вы узнали следующее:
Надеюсь, вам была полезна данная статья. Успехов в написании кода!
Функции str.split и rsplit() в Python
Функция split() в Python используется для разделения строки на список строк на основе разделителя.
В качестве разделителя используется аргумент sep. Если строка содержит последовательные разделители, возвращается пустая строка. Аргумент-разделитель также может состоять из нескольких символов.
Если разделитель не указан или None, то в качестве разделителя рассматриваются пробелы. В этом случае пустая строка не будет возвращена, если в начале или в конце есть пробелы. Кроме того, несколько пробелов будут рассматриваться, как один разделитель.
Пример
Давайте посмотрим на простой пример, где строка будет разделена на список на основе указанного разделителя.
split() с maxsplit
Обратите внимание, что в возвращенном списке всего 2 элемента, строка была разделена только один раз.
sep не указан или None
Вывод: [‘Java’, ‘Python’, ‘iOS’, ‘Android’].
Начальные и конечные пробелы игнорируются в возвращаемом списке. Кроме того, последовательные пробелы также считаются одним разделителем.
Пример разделения многострочной строки
Пример многосимвольного разделителя
Пример функции str.split()
Мы также можем использовать функцию split() непосредственно из класса str.
Обратите внимание, что возвращается пустая строка, когда первый символ соответствует разделителю.
Пример разделения строки CSV с вводом пользователем
Наконец, давайте посмотрим на реальный пример, где пользователь вводит данные CSV, а мы разбиваем их на список строк.

Это все для примеров строковой функции split() в Python. Это очень полезная функция для разделения строки на список на основе некоторого разделителя.
rsplit()
Функция rsplit() очень похожа на функцию split(). Единственная разница в том, что разделение выполняется, начиная с конца строки и двигаясь вперед.
Давайте посмотрим на некоторые примеры функции rsplit().
Обратите внимание, что разница видна, если указан аргумент maxsplit. В противном случае вывод функций split() и rsplit() будет таким же.
python split
Для примера рассмотрим строку с несколькими абстрактными значениями, разделенными запятыми.
> string_with_comas=»thing1, thing2, thing3″
[‘thing1’, ‘ thing2’, ‘ thing3’]
После применения метода split данные представляют собой список (list).
Методу split передается разделитель — запятая,вертикальная черта, тире, двоеточие или что-то иное.
Если аргумент не указывать — разбиение произойдет по пробелам.
[‘thing1,’, ‘thing2,’, ‘thing3’]
> long_string=»Filler text is text that shares some characteristics of a real written text, but is random or otherwise generated. It may be used to display a sample of fonts, generate text for testing, or to spoof an e-mail spam filter.»
[‘Filler’, ‘text’, ‘is’, ‘text’, ‘that’, ‘shares’, ‘some’, ‘characteristics’, ‘of’, ‘a’, ‘real’, ‘written’, ‘text,’, ‘but’, ‘is’, ‘random’, ‘or’, ‘otherwise’, ‘generated.’, ‘It’, ‘may’, ‘be’, ‘used’, ‘to’, ‘display’, ‘a’, ‘sample’, ‘of’, ‘fonts,’, ‘generate’, ‘text’, ‘for’, ‘testing,’, ‘or’, ‘to’, ‘spoof’, ‘an’, ‘e-mail’, ‘spam’, ‘filter.’]
Поскольку на выходе лист, с его элементами можно работать обращаясь к ним по индексу:
‘characteristics’
Метод splitlines
С многострочным текстом нужно работать иначе
>> long_string=»’
… Filler text is text that shares some characteristics of a real
… written text, but is random or otherwise generated. It may be used to display a
… sample of fonts, generate text for testing, or to spoof an e-mail spam filter.»’
split нужного результат не даст и чтобы получить list с отдельными словами требуется выполнить два действия:
Применить метод splitlines
[», ‘Filler text is text that shares some characteristics of a real’, ‘written text, but is random or otherwise generated. It may be used to display a’, ‘sample of fonts, generate text for testing, or to spoof an e-mail spam filter.’]
На выходе будет list из содержимого строк
Далее каждая строка разбирается в цикле for
> for line in long_string.splitlines():
… print (line.split())
[]
[‘Filler’, ‘text’, ‘is’, ‘text’, ‘that’, ‘shares’, ‘some’, ‘characteristics’, ‘of’, ‘a’, ‘real’]
[‘written’, ‘text,’, ‘but’, ‘is’, ‘random’, ‘or’, ‘otherwise’, ‘generated.’, ‘It’, ‘may’, ‘be’, ‘used’, ‘to’, ‘display’, ‘a’]
[‘sample’, ‘of’, ‘fonts,’, ‘generate’, ‘text’, ‘for’, ‘testing,’, ‘or’, ‘to’, ‘spoof’, ‘an’, ‘e-mail’, ‘spam’, ‘filter.’]
Kodomo
Учебная страница курса биоинформатики,
год поступления 2010

Файлы и Строки
Работа с файлами
Для начала, маленькое предисловие. В питоне (как и в подавляющем большинстве языков программирования) с файлами можно делать много разных операций: читать его построчно, читать его целиком, писать в него, двигать по нему курсор позиции, с которой мы будем читать или в которую мы будем писать.
Открытие файла.
В питоне каждый файл, с которым мы работаем, обозначается объектом. (А объект обозначается переменной).
Соответственно, прежде, чем с файлом начинать работать, нам нужно создать питонское представление об этом файле – создать объект, который представляет именно конкретный файл. В питоне эта операция называется «открыть файл». Делается это так:
Такой файл можно только читать. Питон будет запрещать для него операции записи. Если нам нужно в файл писать, то мы пишем так:
Тут сразу предупреждаю: в тот момент, когда питон открывает файл на запись, если такой файл уже существовал, то он будет стёрт! Это свойство даже не столько питона, сколько большинства операционных систем. Его нужно всегда учитывать: нельзя указывать одинаковым входной и выходной файл для программы.
Что делать, если мы хотим дописать в файл? Для этого существуют еще один параметр ‘a’ (от ‘append’):
Путь к файлу указывается либо относительно текущей директории, либо относительно корневой директории (абсолютный путь):
Так эти строки будут выглядять изнутри питона. Если имена файлов приходят из аргументов командной строки, то дублировать бэкслеши не надо. (В командной строке будет H:\Task3\Python – то, как FAR пишет пути, если ему щёлкнуть Ctrl-Enter по файлу).
Чтение по строкам
Если мы подставляем файл туда, где питон ожидал бы список, то питон будет интерпретировать файл как список строк файла – включая переносы в концах строк.
Если мы распечатаем каждую строку таким образом, то в итоге на экране мы увидим все строки через пробел (пустую строку). Это произойдет из-за того, что в файле в конце каждой строки стоит символ ‘\n’, а print автоматически прибавляет этот символ к концу печатаемого объекта. О решении этой проблемы поговорим чуть позже (см. Работа со строками и всякие полезные вещи при работе с файлами).
Чтение целиком
Запись в файл.
дописывает одну строку в конец файла.
Обратите внимания: в отличие от print, эта функция переноса строки в конец не дописывает, нам приходится вставлять его туда самостоятельно!
StdIO
Существует три специальных потока, которые называются: стандартный поток ввода, стандартный поток вывода и стандартный поток ошибок.
Можно рассматривать каждую программу как некий универсальный переработчик, который имеет два разъёма: вход и выход. Эти вход и выход называются «стандартный вход» (stdin) и «стандартный выход» (stdout). Если мы у програмы никуда не привязываем выход, то, что из неё высыпается, сыпется на экран. А если не привязан вход, то она присасывается к клавиатуре и ловит всё, что вы набираете в консоли.
С точки зрения питона:
Стандартный вывод – это то, куда пишет print. Это такой файл. К нему можно дотянуться через sys.stdout.
Стандартный ввод – это то, чем мы пока что не пользовались. Это тоже такой файл. К нему можно дотянуться, как вы догадались, черзе sys.stdin.
Работа со строками.
Итак, вернемся к чтению по строкам.
Как уже было сказано, у нас возникает проблема с удвоением ‘\n’. Избавиться от этого лишнего пробельного символа можно с помощью метода strip().
.strip(): обрезание символов с концов строки
strip отрезает с начала и конца строки те символы, которые указаны в его аргументах (т.е. в скобках). Пустые скобки означают пробельные символы
Важно! Строки, как и кортежи, нельзя изменить, поэтому при их любой обработке каким-то методом будет возвращаться новая строка!
то a изменит адрес, однако исходная строка останется прежней.
Еще примеры со strip:
Как уже было сказано, strip обрезает с начала и конца строки все символы, которые указаны в его аргументах. Он работает только посимвольно! Поэтому с его помощью нельзя вырезать из строки ‘123abc231’число 12.
.split(): разбиение строки по заданным разделителям
В данном случае split() возвращает список, элементами которого являются слова, разделенные в исходной строке пробельными символами.
Ниже в примере _ означает пробел!
split(«строка») разбивает по строке, а не по символам, из которых она состоит!
split() при разбиении выкидывает пробелы в начале и в конце строки (смотри пример выше), а split(» «) нет!
Есть два разделителя подряд – будет в списке пустая строка.
Строки в python 3: методы, функции, форматирование
В уроке по присвоению типа переменной в Python вы могли узнать, как определять строки: объекты, состоящие из последовательности символьных данных. Обработка строк неотъемлемая частью программирования на python. Крайне редко приложение, не использует строковые типы данных.
Из этого урока вы узнаете: Python предоставляет большую коллекцию операторов, функций и методов для работы со строками. Когда вы закончите изучение этой документации, узнаете, как получить доступ и извлечь часть строки, а также познакомитесь с методами, которые доступны для манипулирования и изменения строковых данных.
Ниже рассмотрим операторы, методы и функции, доступные для работы с текстом.
Строковые операторы
Оператор сложения строк +
+ — оператор конкатенации строк. Он возвращает строку, состоящую из других строк, как показано здесь:
Оператор умножения строк *
* — оператор создает несколько копий строки. Если s это строка, а n целое число, любое из следующих выражений возвращает строку, состоящую из n объединенных копий s :
Вот примеры умножения строк:
Значение множителя n должно быть целым положительным числом. Оно может быть нулем или отрицательным, но этом случае результатом будет пустая строка:
Оператор принадлежности подстроки in
Встроенные функции строк в python
Python предоставляет множество функций, которые встроены в интерпретатор. Вот несколько, которые работают со строками:
| Функция | Описание |
|---|---|
| chr() | Преобразует целое число в символ |
| ord() | Преобразует символ в целое число |
| len() | Возвращает длину строки |
| str() | Изменяет тип объекта на string |
Более подробно о них ниже.
Функция ord(c) возвращает числовое значение для заданного символа.
На базовом уровне компьютеры хранят всю информацию в виде цифр. Для представления символьных данных используется схема перевода, которая содержит каждый символ с его репрезентативным номером.
ASCII прекрасен, но есть много других языков в мире, которые часто встречаются. Полный набор символов, которые потенциально могут быть представлены в коде, намного больше обычных латинских букв, цифр и символом.
Unicode — это современный стандарт, который пытается предоставить числовой код для всех возможных символов, на всех возможных языках, на каждой возможной платформе. Python 3 поддерживает Unicode, в том числе позволяет использовать символы Unicode в строках.
Функция ord() также возвращает числовые значения для символов Юникода:
Функция chr(n) возвращает символьное значение для данного целого числа.
chr() также обрабатывает символы Юникода:
Функция len(s) возвращает длину строки.
len(s) возвращает количество символов в строке s :
Функция str(obj) возвращает строковое представление объекта.
Практически любой объект в Python может быть представлен как строка. str(obj) возвращает строковое представление объекта obj :
Индексация строк
Часто в языках программирования, отдельные элементы в упорядоченном наборе данных могут быть доступны с помощью числового индекса или ключа. Этот процесс называется индексация.
Например, схематическое представление индексов строки ‘foobar’ выглядит следующим образом:
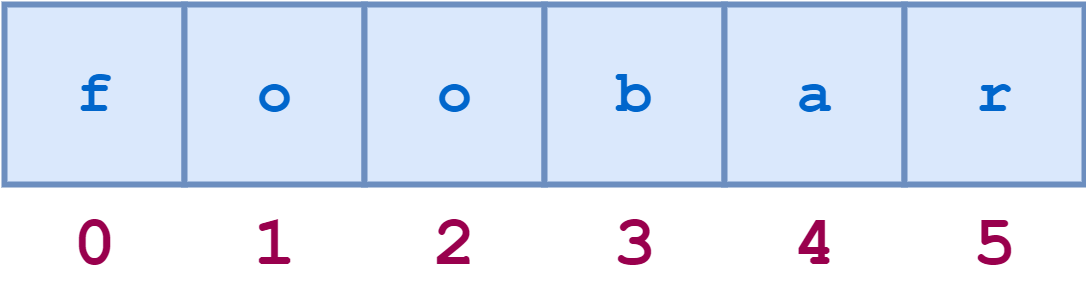
Отдельные символы доступны по индексу следующим образом:
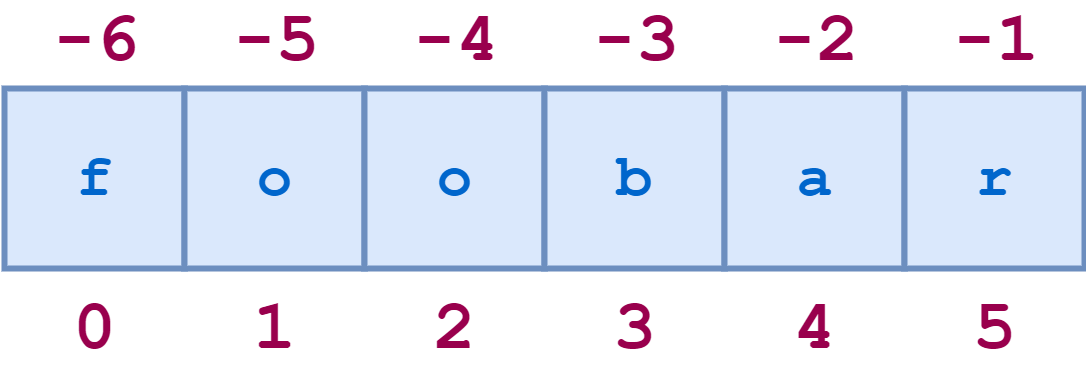
Вот несколько примеров отрицательного индексирования:
Срезы строк
Если пропустить первый индекс, срез начинается с начала строки. Таким образом, s[:m] = s[0:m] :
Для любой строки s и любого целого n числа ( 0 ≤ n ≤ len(s) ), s[:n] + s[n:] будет s :
Пропуск обоих индексов возвращает исходную строку. Это не копия, это ссылка на исходную строку:
Если первый индекс в срезе больше или равен второму индексу, Python возвращает пустую строку. Это еще один не очевидный способ сгенерировать пустую строку, если вы его искали:
Отрицательные индексы можно использовать и со срезами. Вот пример кода Python:
Шаг для среза строки
Существует еще один вариант синтаксиса среза, о котором стоит упомянуть. Добавление дополнительного : и третьего индекса означает шаг, который указывает, сколько символов следует пропустить после извлечения каждого символа в срезе.
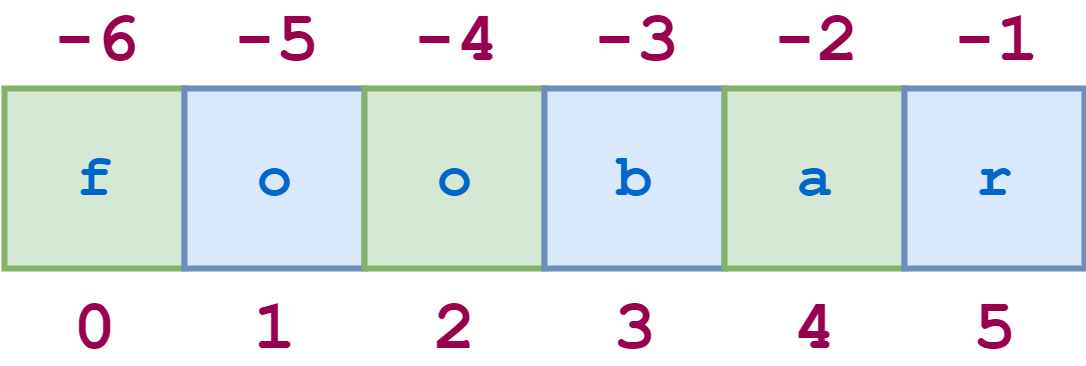
Иллюстративный код показан здесь:
Как и в случае с простым срезом, первый и второй индексы могут быть пропущены:
Вы также можете указать отрицательное значение шага, в этом случае Python идет с конца строки. Начальный/первый индекс должен быть больше конечного/второго индекса:
В приведенном выше примере, 5:0:-2 означает «начать с последнего символа и делать два шага назад, но не включая первый символ.”
Когда вы идете назад, если первый и второй индексы пропущены, значения по умолчанию применяются так: первый индекс — конец строки, а второй индекс — начало. Вот пример:
Это общая парадигма для разворота (reverse) строки:
Форматирование строки
В Python версии 3.6 был представлен новый способ форматирования строк. Эта функция официально названа литералом отформатированной строки, но обычно упоминается как f-string.
Возможности форматирования строк огромны и не будут подробно описана здесь.
Одной простой особенностью f-строк, которые вы можете начать использовать сразу, является интерполяция переменной. Вы можете указать имя переменной непосредственно в f-строковом литерале ( f’string’ ), и python заменит имя соответствующим значением.
Но это громоздко. Чтобы выполнить то же самое с помощью f-строки:
Код с использованием f-string, приведенный ниже выглядит намного чище:
Любой из трех типов кавычек в python можно использовать для f-строки:
Изменение строк
Строки — один из типов данных, которые Python считает неизменяемыми, что означает невозможность их изменять. Как вы ниже увидите, python дает возможность изменять (заменять и перезаписывать) строки.
Такой синтаксис приведет к ошибке TypeError :
На самом деле нет особой необходимости изменять строки. Обычно вы можете легко сгенерировать копию исходной строки с необходимыми изменениями. Есть минимум 2 способа сделать это в python. Вот первый:
Есть встроенный метод string.replace(x, y) :
Читайте дальше о встроенных методах строк!
Встроенные методы строк в python
В руководстве по типам переменных в python вы узнали, что Python — это объектно-ориентированный язык. Каждый элемент данных в программе python является объектом.
Вы также знакомы с функциями: самостоятельными блоками кода, которые вы можете вызывать для выполнения определенных задач.
Методы похожи на функции. Метод — специализированный тип вызываемой процедуры, тесно связанный с объектом. Как и функция, метод вызывается для выполнения отдельной задачи, но он вызывается только вместе с определенным объектом и знает о нем во время выполнения.
Синтаксис для вызова метода объекта выглядит следующим образом:
Вы узнаете намного больше об определении и вызове методов позже в статьях про объектно-ориентированное программирование. Сейчас цель усвоить часто используемые встроенные методы, которые есть в python для работы со строками.
В приведенных методах аргументы, указанные в квадратных скобках ( [] ), являются необязательными.
Изменение регистра строки
Методы этой группы выполняют преобразование регистра строки.
string.capitalize() приводит первую букву в верхний регистр, остальные в нижний.
s.capitalize() возвращает копию s с первым символом, преобразованным в верхний регистр, и остальными символами, преобразованными в нижний регистр:
Не алфавитные символы не изменяются:
string.lower() преобразует все буквенные символы в строчные.
s.lower() возвращает копию s со всеми буквенными символами, преобразованными в нижний регистр:
string.swapcase() меняет регистр буквенных символов на противоположный.
s.swapcase() возвращает копию s с заглавными буквенными символами, преобразованными в строчные и наоборот:
string.title() преобразует первые буквы всех слов в заглавные
s.title() возвращает копию, s в которой первая буква каждого слова преобразуется в верхний регистр, а остальные буквы — в нижний регистр:
Этот метод использует довольно простой алгоритм. Он не пытается различить важные и неважные слова и не обрабатывает апострофы, имена или аббревиатуры:
string.upper() преобразует все буквенные символы в заглавные.
s.upper() возвращает копию s со всеми буквенными символами в верхнем регистре:
Найти и заменить подстроку в строке
Эти методы предоставляют различные способы поиска в целевой строке указанной подстроки.
string.count([, [, ]]) подсчитывает количество вхождений подстроки в строку.
s.count() возвращает количество точных вхождений подстроки в s :
Количество вхождений изменится, если указать и :
string.endswith( [, [, ]]) определяет, заканчивается ли строка заданной подстрокой.
s.endswith( ) возвращает, True если s заканчивается указанным и False если нет:
string.find([, [, ]]) ищет в строке заданную подстроку.
s.find() возвращает первый индекс в s который соответствует началу строки :
string.index([, [, ]]) ищет в строке заданную подстроку.
string.rfind([, [, ]]) ищет в строке заданную подстроку, начиная с конца.
string.rindex([, [, ]]) ищет в строке заданную подстроку, начиная с конца.
Классификация строк
Методы в этой группе классифицируют строку на основе символов, которые она содержит.
string.isalnum() определяет, состоит ли строка из букв и цифр.
string.isalpha() определяет, состоит ли строка только из букв.
string.isdigit() определяет, состоит ли строка из цифр (проверка на число).
s.digit() возвращает True когда строка s не пустая и все ее символы являются цифрами, а в False если нет:
string.isidentifier() определяет, является ли строка допустимым идентификатором Python.
string.islower() определяет, являются ли буквенные символы строки строчными.
string.isprintable() определяет, состоит ли строка только из печатаемых символов.
s.isprintable() возвращает, True если строка s пустая или все буквенные символы которые она содержит можно вывести на экран. Возвращает, False если s содержит хотя бы один специальный символ. Не алфавитные символы игнорируются:
string.isspace() определяет, состоит ли строка только из пробельных символов.
Тем не менее есть несколько символов ASCII, которые считаются пробелами. И если учитывать символы Юникода, их еще больше:
‘\f’ и ‘\r’ являются escape-последовательностями для символов ASCII; ‘\u2005’ это escape-последовательность для Unicode.
string.istitle() определяет, начинаются ли слова строки с заглавной буквы.
string.isupper() определяет, являются ли буквенные символы строки заглавными.
Выравнивание строк, отступы
Методы в этой группе влияют на вывод строки.
string.center( [, ]) выравнивает строку по центру.
string.expandtabs(tabsize=8) заменяет табуляции на пробелы
s.expandtabs() заменяет каждый символ табуляции ( ‘\t’ ) пробелами. По умолчанию табуляция заменяются на 8 пробелов:
tabsize необязательный параметр, задающий количество пробелов:
string.ljust( [, ]) выравнивание по левому краю строки в поле.
string.lstrip([ ]) обрезает пробельные символы слева
s.lstrip() возвращает копию s в которой все пробельные символы с левого края удалены:
string.replace(
- , [, ]) заменяет вхождения подстроки в строке.
s.replace(
- , ) возвращает копию s где все вхождения подстроки
- , заменены на :
string.rjust( [, ]) выравнивание по правому краю строки в поле.
string.rstrip([ ]) обрезает пробельные символы справа
s.rstrip() возвращает копию s без пробельных символов, удаленных с правого края:
string.strip([ ]) удаляет символы с левого и правого края строки.
Важно: Когда возвращаемое значение метода является другой строкой, как это часто бывает, методы можно вызывать последовательно:
string.zfill( ) дополняет строку нулями слева.
s.zfill( ) возвращает копию s дополненную ‘0’ слева для достижения длины строки указанной в :
Если s содержит знак перед цифрами, он остается слева строки:
.zfill() наиболее полезен для строковых представлений чисел, но python с удовольствием заполнит строку нулями, даже если в ней нет чисел:
Методы преобразование строки в список
Методы в этой группе преобразовывают строку в другой тип данных и наоборот. Эти методы возвращают или принимают итерируемые объекты — термин Python для последовательного набора объектов.
Многие из этих методов возвращают либо список, либо кортеж. Это два похожих типа данных, которые являются прототипами примеров итераций в python. Список заключен в квадратные скобки ( [] ), а кортеж заключен в простые ( () ).
Теперь давайте посмотрим на последнюю группу строковых методов.
string.join( ) объединяет список в строку.
В результате получается одна строка, состоящая из списка объектов, разделенных запятыми.
В следующем примере указывается как одно строковое значение. Когда строковое значение используется в качестве итерируемого, оно интерпретируется как список отдельных символов строки:
Это можно исправить так:
string.partition( ) делит строку на основе разделителя.
s.rpartition( ) делит строку на основе разделителя, начиная с конца.
string.rsplit(sep=None, maxsplit=-1) делит строку на список из подстрок.
Без аргументов s.rsplit() делит s на подстроки, разделенные любой последовательностью пробелов, и возвращает список:
Если указан, он используется в качестве разделителя:
Это не работает, когда не указан. В этом случае последовательные пробельные символы объединяются в один разделитель, и результирующий список никогда не будет содержать пустых строк:
string.split(sep=None, maxsplit=-1) делит строку на список из подстрок.
string.splitlines([ ]) делит текст на список строк.
s.splitlines() делит s на строки и возвращает их в списке. Любой из следующих символов или последовательностей символов считается границей строки:
| Разделитель | Значение |
|---|---|
| \n | Новая строка |
| \r | Возврат каретки |
| \r\n | Возврат каретки + перевод строки |
| \v или же \x0b | Таблицы строк |
| \f или же \x0c | Подача формы |
| \x1c | Разделитель файлов |
| \x1d | Разделитель групп |
| \x1e | Разделитель записей |
| \x85 | Следующая строка |
| \u2028 | Новая строка (Unicode) |
| \u2029 | Новый абзац (Unicode) |
Вот пример использования нескольких различных разделителей строк:
Если в строке присутствуют последовательные символы границы строки, они появятся в списке результатов, как пустые строки:
Заключение
В этом руководстве было подробно рассмотрено множество различных механизмов, которые Python предоставляет для работы со строками, включая операторы, встроенные функции, индексирование, срезы и встроенные методы.
Python есть другие встроенные типы данных. В этих урока вы изучите два наиболее часто используемых:



