Обзор методов решения проблемы ограниченного объёма обучающей выборки в нейросетевом моделировании
Исследователи, занимающиеся нейросетевым моделированием, зачастую сталкиваются с проблемой ограниченного набора обучающих данных. Как решить данную проблему рассмотрим в статье.
Исследователи, занимающиеся нейросетевым моделированием, зачастую сталкиваются с проблемой ограниченного набора обучающих данных. Это может быть связано как с проблемами поиска источника этих данных, так и с большой размерностью входных и выходных переменных решаемой задачи. Возникает дилемма: либо использовать в своей работе нейронную сеть с заведомо более сложной структурой, в результате чего она скорее всего будет просто воспроизводить запомненные данные, но не обобщать их, либо отказаться от нейросетевого моделирования вовсе и искать другие методы решения.
Если всё же принято решения использовать в работе нейронную сеть, современные исследователи предлагают несколько путей решения проблемы и, соответственно, методы, их реализующие:
Основные методы
– уменьшение объёма или отказ от тестовой выборки;
– псевдослучайная генерация новых примеров;
– структурные изменения нейронной сети или нейросетевой модели.
Полный отказ от использования тестовой выборки – наиболее часто используемый, но наименее эффективный метод решения проблемы. Его главное преимущества – простота реализации и экономия времени. Однако, каким может быть эффект от такого решения, сложно предугадать. Если закономерности, связывающие входные и выходные переменные, достаточно просты, полученная нейросетевая модель может оказаться достаточно адекватной, однако возможность проверить это появится уже только на стадии практической эксплуатации, когда цена решения, принятого на основе результатов интерпретации выходных данных, несоизмеримо повышается. В случае же сложных или плохо изученных закономерностей лучше вообще сразу отказаться от такого подхода.
В статье [1] предлагается метод перекрёстной вариации. Суть его в том, что из выборки поочерёдно исключается один пример, без которого нейронная сеть обучается заново на оставшихся примерах. После обучения считается единственное значение ошибки для исключённого примера. Аналогично поступают со всеми остальными примерами, исключая из выборки и возвращая в неё предыдущие. Таким образом, каждый пример может считаться как обучающим, так и тестовым и, зная ошибки всех тестовых примеров, можно их усреднить.
Данный метод даёт гораздо более точную оценку тестирования нейронной сети, чем прямое использование для тестирования, выборки, только что использованной для обучения. Недостатки данного подхода заключаются в необходимости многократного повторения обучающей процедуры и в возможной неточности оценок отдельных ошибок тестовых примеров из-за влияния стохастической составляющей процесса обучения.
В статье [1] также приводится еще один метод оценки качества работы нейронной сети в случае малой выборки, который носит название бутстрэп (bootstrap). Данный метод предусматривает многократное формирование различных обучающих выборок на основе базовой обучающей выборки небольшого объёма. При этом примеры базовой выборки могут быть задействованы различное количество раз, а некоторые не использоваться вовсе. Для каждой из сформированных таким образом выборок осуществляется независимый процесс обучения нейронной сети и оценки её ошибок, после чего полученные данные обобщаются.
В статье [2] в качестве решения поставленной проблемы предлагается использовать теорию и методы нечёткой логики и нечётких множеств для решения проблемы малого объёма обучающих данных в диффузионных нейронных сетях. Данные сети имеют большое количество входных параметров, и, как следствие, очень насыщенную структуру. Подход предполагает составление нечётких «если–то» правил для описания связей между различными параметрами, которые позволяют преодолеть проблему противоречивости и недостатка данных. С использованием этих правил и методов дефаззификации получаются новые примеры, за счёт которых расширяется имеющаяся обучающая выборка.
В работе [3] предложен ещё один подход к решению проблемы малого объёма обучающих данных, заключающийся в разделении входных и выходных переменных на небольшие группы, применении к этим группам структурно гораздо более простых искусственных нейронных сетей – однослойных перцептронов, для обучения которых оказывается достаточно имеющегося объёма данных, и последующем объединении перцептронов в единую структуру перцептронного комплекса. Подробнее данный подход описан в статье: «Перцептронные комплексы для нейросетевого моделирования при малых объёмах обучающих выборок».
Выбор метода решения проблемы недостаточности обучающих данных остаётся за исследователем. У каждого из них есть свои плюсы и минусы. Однако не следует забывать, что всё же самый лучший способ улучшить адекватность нейросетевой модели – получить недостающие данные из первоисточника.
Статья подготовлена по материалам публикаций:
1. Коробкова С. В. Проблемы эффективной аппроксимации многомерных функций с помощью нейронных сетей/ Известия Южного федерального университета. Технические науки. – 2006. – Т. 58, № 3. – С. 121–127.
2. Huang C., Moraga C. A Diffusion-Neural-Network for Learning from Small Samples/ International Journal of Approximate Reasoning. – 2004. – V. 35 P. 137–161.
3. Дударов С. П. Нейросетевое моделирование на основе перцептронных комплексов при малых объемах обучающих выборок/ С. П. Дударов, А. Н. Диев. – Математические методы в технике и технологиях – ММТТ-26: сб. трудов XXVI Междунар. науч. конф. Секции 6, 7, 8, 9. – Нижний Новгород: Нижегород. гос. техн. ун-т, 2013. – с. 114–116.
Чувствительность методов ML к размеру обучающей выборки. Part 6.

В прошлом тексте я пробовал «помочь», нейросете уменьшив число рандомных фичей. Сейчас попробую помочь увеличив число примеров. Может наша сверточная сеть покажет что то вменяемое если увеличить число примеров до миллиона? Это задача на моем компьютере требует совершенно других затрат времени, так что я вчера запустил машинку обучаться, а сам пошел спать. Обучался на 50 эпохах, увеличивая данные от 10 тысяч до 50 тысяч (увеличивая обьем на 10 тысяч), и от 100 тысяч до 900 тысяч (с шагом +100 тысяч).
Результаты порадовали. Я не буду в 5 раз пересказывать логику «исследования», но убрав week=5 мы должны (ну как должны!? вообще то нам никто ничего не должен) получить равновероятный прогноз события 1 и события 0. Ниже на графике эту норму в 50% изображает серая линия. Красная это прогноз события=1, синяя событие=0, ось Х число примеров на обучающей выборке в тысячах.
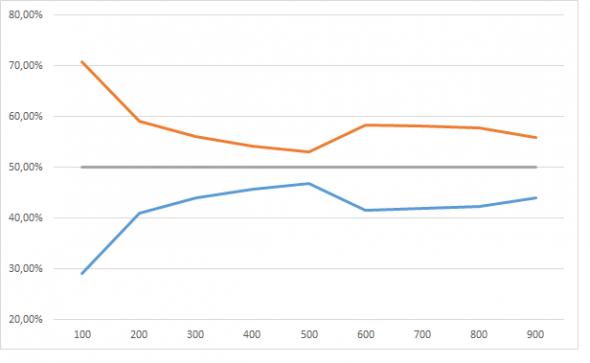
И пусть девочка кинет в меня камне если тут нет сходимости.
Но это динамика при увеличении обучающей выборки от 100 тысяч до 900 тысяч, а вот если сюда присовокупить от 10 тысяч до 50, тут все не так очевидно:
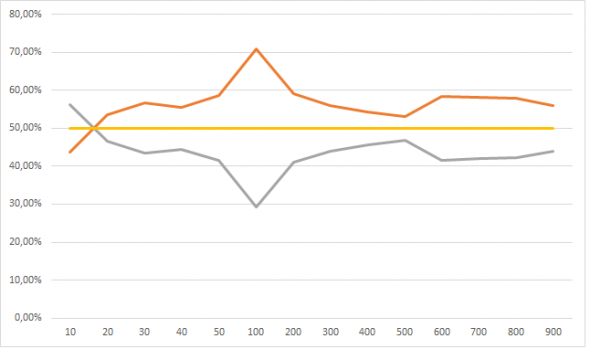
У меня следующее обьяснение: нейросеть большая фантазерка, в том смысле что способна найти в числах даже то чего там и нет. Но с другой стороны нельзя сложить из букв «п», «ж», «о», «а» слово вечность, поэтому когда обучающая выборка очень маленькая фантазии нейросети ограниченны. По мере роста обучающей выборки, нейросеть начинает находить все больше и больше черных кошек в черной комнате, которых там нет, и так до размера выборки в 100 тысяч примеров. По мере дальнейшего размера выборки фантазию нейросети начинает ограничивать реальность-сложно аппроксимировать 101 фичей данные размером в сотни тысяч. Ну это ИМХО.
Поставив week = 5 мы должны получить другой тип сходимости. Пробую обьяснить-если нейросеть правильно все разобрала, а именно поняла что единственная значимая фиxа это week и именно при week = 5, то число событий 1 она должна как можно чаще закидывать в week = 5. Смотрим:
Для GB я тоже потестил при обучении от 100 до 900 тысяч примеров и сравнил с нейросеткой:
| GB | Нейросеть | |||
| 0 | 1 | 1 | 0 | |
| 100 | ||||
| 1 | 53,75% | 46,25% | 43,43% | 56,57% |
| 2 | 53,76% | 46,24% | 64,38% | 35,62% |
| 3 | 53,54% | 46,46% | 82,30% | 17,70% |
| 4 | 54,05% | 45,95% | 92,54% | 7,46% |
| 5 | 0,79% | 99,21% | 97,20% | 2,80% |
| 200 | ||||
| 1 | 49,93% | 50,07% | 36,74% | 63,26% |
| 2 | 52,58% | 47,42% | 52,03% | 47,97% |
| 3 | 54,95% | 45,05% | 66,08% | 33,92% |
| 4 | 55,23% | 44,77% | 81,28% | 18,72% |
| 5 | 0,09% | 99,91% | 98,82% | 1,18% |
| 300 | ||||
| 1 | 46,79% | 53,21% | 40,75% | 59,25% |
| 2 | 47,83% | 52,17% | 50,54% | 49,46% |
| 3 | 53,59% | 46,41% | 60,13% | 39,87% |
| 4 | 54,02% | 45,98% | 72,65% | 27,35% |
| 5 | 0,00% | 100,00% | 97,86% | 2,14% |
| 400 | ||||
| 1 | 50,10% | 49,90% | 40,17% | 59,83% |
| 2 | 52,51% | 47,49% | 48,50% | 51,50% |
| 3 | 52,31% | 47,69% | 58,78% | 41,22% |
| 4 | 48,34% | 51,66% | 69,53% | 30,47% |
| 5 | 0,00% | 100,00% | 97,36% | 2,64% |
| 500 | ||||
| 1 | 48,49% | 51,51% | 39,28% | 60,72% |
| 2 | 50,79% | 49,21% | 47,34% | 52,66% |
| 3 | 52,02% | 47,98% | 57,25% | 42,75% |
| 4 | 52,11% | 47,89% | 68,84% | 31,16% |
| 5 | 0,00% | 100,00% | 97,35% | 2,65% |
| 600 | ||||
| 1 | 47,69% | 52,31% | 44,24% | 55,76% |
| 2 | 47,64% | 52,36% | 53,09% | 46,91% |
| 3 | 48,49% | 51,51% | 62,79% | 37,21% |
| 4 | 47,60% | 52,40% | 73,60% | 26,40% |
| 5 | 0,00% | 100,00% | 98,43% | 1,57% |
| 700 | ||||
| 1 | 47,09% | 52,91% | 43,58% | 56,42% |
| 2 | 47,52% | 52,48% | 52,16% | 47,84% |
| 3 | 49,31% | 50,69% | 62,25% | 37,75% |
| 4 | 48,82% | 51,18% | 74,11% | 25,89% |
| 5 | 0,00% | 100,00% | 98,57% | 1,43% |
| 800 | ||||
| 1 | 44,25% | 55,75% | 45,19% | 54,81% |
| 2 | 46,73% | 53,27% | 52,02% | 47,98% |
| 3 | 46,67% | 53,33% | 60,71% | 39,29% |
| 4 | 46,94% | 53,06% | 73,27% | 26,73% |
| 5 | 0,00% | 100,00% | 98,92% | 1,08% |
| 900 | ||||
| 1 | 48,62% | 51,38% | 40,78% | 59,22% |
| 2 | 49,66% | 50,34% | 48,14% | 51,86% |
| 3 | 48,69% | 51,31% | 60,06% | 39,94% |
| 4 | 49,75% | 50,25% | 74,76% | 25,24% |
| 5 | 0,00% | 100,00% | 99,31% | 0,69% |
Ну тут все понятно. GB начиная с выборки в 300 тысяч примеров показывает 100% результат: все события 1 кидает в week=5, а для всех остальных раскидывает события поровну, в то время как нейросетка чего то пытается нащупать.
Таки дела
Мы продолжаем знакомиться с теоретическими вопросами обучения НС, без которых невозможно их качественное построение. И это занятие начнем с очень важной темы – переобучения. Что это такое и чем это чревато? Давайте представим, что у нас есть два класса линейно-разделимых образов:

И из предыдущих занятий мы уже знаем, что для их различения достаточно одного нейрона. Но, что будет, если мы выберем сеть с большим числом нейронов, для решения этой же задачи?

В процессе обучения она способна формировать уже более сложную разделяющую линию, например, провести ее вот так:

Если мы продолжим увеличивать число нейронов скрытого слоя, то будем получать все более сложную закономерность разделения двух классов:

К чему это в итоге приведет? Да, на обучающем множестве все будет отлично, но в процессе эксплуатации такой сети будем получать массу ошибок:

Этот эффект и называется переобучением, когда разделяющая плоскость слишком точно описывает классы из обучающей выборки, и в результате теряется обобщающая способность НС.
Это можно сравнить с ленивым, но способным студентом (с прекрасной памятью), сдающим экзамен, допустим, по вышке, где предполагается решение экзаменационных задач. Ему проще выучить ход их решения не особо погружаясь в детали. Тогда, выбрав одну из них, он сможет быстренько вспомнить решение и записать его. А другой, не обладая хорошей памятью, но достаточно усидчивый, чтобы понять ход решения и запомнить их принцип, будет способен решать не только экзаменационные задачи, но и любые другие, сходные с ними. То есть, у него будет лучшая обобщающая способность.


Такой вывод может показаться несколько неожиданным. Казалось бы, чем больше нейронов в НС, тем качественнее она должна работать. Но на практике имеем обратный эффект: избыток нейронов ухудшает обобщающие способности. В идеале, число нейронов должно быть ровно столько, сколько необходимо для решения поставленной задачи. Но как определить, сколько их нужно? Здесь, опять же, нет универсального алгоритма. Это определяется опытным путем, подбирая минимальное число нейронов, при котором получается приемлемое качество решения задачи.
Рекомендация обучения №6:
Использовать минимальное необходимое число нейронов в нейронной сети.
Однако, мы все же можем контролировать этот эффект в процессе обучения. Для этого обучающая выборка разбивается на два множества: обучающее и валидации (проверочное):

На вход НС подаются наблюдения из обучающей выборки по схеме, которую мы рассматривали на предыдущем занятии. А, затем, после каждой эпохи, вычисляется критерий качества работы сети для обоих множеств: обучающего и проверочного. Получаем два графика:

Если с какой-то итерации графики начинают расходиться, то делается вывод, что НС переобучается и процесс обучения следует прервать. В этом случае, лучшие весовые коэффициенты соответствуют границе переобучения.
Здесь у вас может возникнуть вопрос: зачем мы разбиваем обучающую выборку, а не используем в качестве проверочного множества тестовое? Тестовое – это то, на котором как раз и проверяется качество работы сети:

Дело в том, что как только какая-либо выборка прямо или косвенно участвует в обучении, то она влияет на состояние весов НС. В результате выборка валидации тоже, отчасти, становится обучающей и нейросеть подстраивается и под нее. Поэтому для объективной проверки качества необходима третья выборка – тестовая. Отсюда получаем:
Рекомендация обучения №7:
Разбивать все множество наблюдений на три выборки: обучающую, валидации и тестовую.
Вот такие основные подходы существуют для предотвращения переобучения НС.
Критерии останова процесса обучения

Конечно, критерии останова могут быть и другими. Я здесь привел лишь распространенные варианты, которые чаще всего используются на практике. Но, в каждой конкретной ситуации могут быть сформулированы свои критерии останова обучения сети.
Видео по теме

Нейронные сети: краткая история триумфа

Структура и принцип работы полносвязных нейронных сетей | #1 нейросети на Python



Ускорение обучения, начальные веса, стандартизация, подготовка выборки | #4 нейросети на Python


Функции активации, критерии качества работы НС | #6 нейросети на Python



Как нейронная сеть распознает цифры | #9 нейросети на Python

Оптимизаторы в Keras, формирование выборки валидации | #10 нейросети на Python


Batch Normalization (батч-нормализация) что это такое? | #12 нейросети на Python

Как работают сверточные нейронные сети | #13 нейросети на Python

Делаем сверточную нейронную сеть в Keras | #14 нейросети на Python

Примеры архитектур сверточных сетей VGG-16 и VGG-19 | #15 нейросети на Python

Теория стилизации изображений (Neural Style Transfer) | #16 нейросети на Python

Делаем перенос стилей изображений с помощью Keras и Tensorflow | #17 нейросети на Python

Как нейронная сеть раскрашивает изображения | #18 нейросети на Python

Введение в рекуррентные нейронные сети | #19 нейросети на Python

Как рекуррентная нейронная сеть прогнозирует символы | #20 нейросети на Python

Делаем прогноз слов рекуррентной сетью Embedding слой | #21 нейросети на Python

Как работают RNN. Глубокие рекуррентные нейросети | #22 нейросети на Python


Как делать сентимент-анализ рекуррентной LSTM сетью | #24 нейросети на Python

Рекуррентные блоки GRU. Пример их реализации в задаче сентимент-анализа | #25 нейросети на Python

Двунаправленные (bidirectional) рекуррентные нейронные сети | #26 нейросети на Python

Автоэнкодеры. Что это и как работают | #27 нейросети на Python

Вариационные автоэнкодеры (VAE). Что это такое? | #28 нейросети на Python

Делаем вариационный автоэнкодер (VAE) в Keras | #29 нейросети на Python

Расширенный вариационный автоэнкодер (CVAE) | #30 нейросети на Python

Что такое генеративно-состязательные сети (GAN) | #31 нейросети на Python

Делаем генеративно-состязательную сеть в Keras и Tensorflow | #32 нейросети на Python
© 2021 Частичное или полное копирование информации с данного сайта для распространения на других ресурсах, в том числе и бумажных, строго запрещено. Все тексты и изображения являются собственностью сайта



