Что делать с выбросами в данных

Этой публикацией будет завершена серия статей о выбросах. Рассмотрев определение и проблему выбросов, возможные источники и примеры, нам остается лишь вооружить читателя некоторыми рекомендациями при работе с данными, которые выделяются из общей совокупности значений. В этой статье мы разработаем план действий, которым, смею надеяться, будут пользоваться не только участники тренингов шести сигм, но и многие посетители сайта. Обратите внимание: настоящая публикация в своей основе лишь резюмирует изложенную ранее информацию, помогая исследователю прийти к выводу, однако не может быть использована как самостоятельная. Поэтому редакция сайта настоятельно рекомендует начать изучение этой статьи, предварительно ознакомившись с публикациями, ссылки на которые приведены выше.
Следует также отметить, что проблема выбросов была рассмотрена в контексте задач, которые выполняют участники тренинга шести сигм для зеленых поясов. Информация, изложенная в этой и предыдущих публикациях, относится исключительно к работе с данными на этапе измерений цикла DMAIC. Таким образом, мы затронули возможные варианты работы с выбросами в ходе сбора и первичного анализа наблюдений и не затронули идентификацию и статистические критерии оценки выбросов, используемые в регрессионном анализе.
Итак, резюмируя изложенную ранее информацию, можно составить первоочередный план действий по работе с выбросами:
выполнив который можно принимать решение относительно последующих действий.
Обнаружение возможных выбросов осуществляется визуально, с помощью различных графиков. В статье Выбросы. Часть 1: кто это такие и почему они опасны? были рассмотрены некоторые примеры, способные помочь в определении выбросов. На стадии Measure тренинга зеленых поясов в первую очередь используется диаграмма временного ряда (Time Series Plot) и Run Chart. В отличие от гистограмм, ящичных и точечных диаграмм, эти графики не выделяют наблюдения, которые могут являться выбросами. С другой стороны, глядя на поведение процесса во времени, можно определить тренды и сезонные составляющие. С большой долей вероятности эти участки могут послужить источниками выбросов. Другими словами, вместо направленного поиска необычно низких или высоких значений, ищем случаи необычного поведения процесса. Следовательно, анализируем возможные участки появления выбросов.
Следует также вспомнить, что гистограммы и точечные диаграммы подвержены влиянию ширины интервала (bining), которая в некоторых условиях приводит к ошибочной идентификации выбросов или, наоборот, – к их скрытию.
Следующий шаг – расчет описательных статистик, который проводится с помощью функции Graphical Summary (Stat > Basic Statistics > Graphical Summary) в пакете Minitab. Эта функция позволяет рассчитать описательные статистики и одновременно представить их в виде графического отчета:

На этом этапе работы выбросы можно не только визуально идентифицировать, но и оценить их влияние на основные статистические показатели.
В случае наблюдения расчетных показателей, таких как стоимость или % брака, продуктивность, выход годных или уровень отказов, нет необходимости использовать все описательные статистики – достаточно знать среднее арифметическое или медиану, как ключевой показатель текущего состояния процесса. Кроме того, не столь важно согласие распределения переменной с нормальным законом, так как последующая оценка способности процесса будет проведена с помощью эмпирических формул расчета DPU, DPO, DPMO, DPPM и σ-уровня, а не индексов способности.
- Никто же не станет ожидать, что распределение выхода годных изделий будет подчиняться нормальному закону. Во-первых, показатель выхода годных изделий редко держится на стабильном уровне – скорее планомерно растет или падает под влиянием определенных факторов. Во-вторых, этот показатель ограничен естественными пределами – не может быть менее 0 и более 100% выхода годных изделий. В третьих, и это наиболее важный пункт, нет смысла оценивать выход с помощью индексов способности. Показатель выхода сам по себе является характеристикой способности процесса производить качественные изделия. Индексы способности, рассчитанные для выхода годных изделий – это абсурд.
Таким образом, для показателей, которые не измеряются непосредственно, но являются расчетной характеристикой процесса, наличие выбросов не критично и может не влиять на полученный результат. Следовательно, последующий анализ может проходить параллельно с поиском причин выбросов. С другой стороны, необычно высокий уровень брака и низкий уровень выхода, связанный, к примеру, с запуском новой технологии или продуктовой линейки может искусственно ухудшать актуальное состояние процесса. Такие наблюдения следует исключить перед проведением последующего анализа.
Во всех остальных случаях обнаружение выбросов служит стоп-сигналом для исследователя: последующий анализ не проводится до того момента, пока причина возникновения выбросов не будет установлена. Исключение могут составлять опечатки или ошибки ввода, допущенные оператором, которые можно либо восстановить, либо исключить без потери информации, или присутствие незначительного количества выбросов, наличие или исключение которых никоим образом не отразится на расчетных статистиках. В последнем случае, однако, рекомендуется взять повторную выборку, так как наличие небольшого числа неподтвержденных выбросов может означать, что размер выборки не достаточен для того, чтобы представлять свойства всей популяции значений.
В одном из проектов зеленых поясов мы столкнулись с довольно интересным случаем: обнаруженных выбросов было так много, что они могли представлять отдельную популяцию значений. Причина столь необычного поведения процесса в том, что отслеживаемая характеристика заметно менялась в случае возникновения брака. Исключать такие выбросы было бы ошибочно – тем самым способность процесса была бы искусственно завышена. Однако последующая оценка индексов способности процесса привела к ряду уроков, которыми стоит поделиться:

Как вы могли заметить из приведенных примеров, определение причин появления выбросов зачастую приводит исследователя к принятию определенного решения. Таким образом, 4й пункт алгоритма работы с выбросами (после того, как найдена причина появления необычно высокого или низкого значения среди наблюдений) меняется в зависимости от этой причины:
Русские Блоги
Обработка выбросов анализа данных

Всего 198 / Чжан Цзюньхун
В этой статье я расскажу, как определять выбросы и что делать после выявления выбросов.
1. Определите выбросы
1.1 Деловое право
Исходя из вашего понимания бизнеса, установите разумный диапазон для каждого индикатора. Как только он выйдет за пределы этого диапазона, он будет считаться выбросом. Например, доход обычно положительный. Если он меньше 0, он считается выбросом; другим примером является возраст. Нормальный возраст может быть в пределах 100. Если возраст составляет несколько сотен, он также считается выбросом.
1.23σ принцип

При использовании принципа 3σ данные должны в максимальной степени следовать нормальному распределению, потому что только когда нормальное распределение удовлетворяется, возможность данных, отличных от трехкратного стандартного отклонения, считается очень малой, поэтому эта часть будет рассматриваться как выброс.
1.3 Коробчатая диаграмма
Ящичная диаграмма, как показано на рисунке ниже, отображает верхнюю и нижнюю границы, верхний и нижний квартили, медианное значение и среднее значение данных. Мы называем значения, которые превышают верхнюю и нижнюю границы, выбросами. Каждый должен знать, как рассчитать квантиль, но как рассчитываются верхняя и нижняя границы?
Когда k = 1,5, это означает умеренное отклонение от нормы; когда k = 3, это означает сильное отклонение от нормы. По умолчанию k = 1,5 на прямоугольной диаграмме.

2. Обработка выбросов
С помощью описанного выше метода выявления выбросов мы можем обнаружить выбросы в данных.Что нам делать после обнаружения выбросов? Существует несколько методов традиционной обработки выбросов:
Удалите выброс. Например, если возраст человека является выбросом, удалите его из данных;
Заменить выбросы как отсутствующие значения, заменить на 0 или среднее значение
Обнаружение и удаление выбросов в Python – легко понять гид
Здравствуйте, читатели! В нашей серии обработки и анализа данных сегодня мы посмотрим на обнаружение и удаление выбросов в Python.
Здравствуйте, читатели! В нашей серии обработки данных и анализа данных сегодня мы посмотрим на Обнаружение и удаление выбросов в питоне.
Итак, давайте начнем!
Что такое выбросы в Python?
Перед погружением глубоко в концепцию Выбросы Давайте понять происхождение необработанных данных.
Необработанные данные, которые подаются в систему, обычно генерируются от опросов и извлечения данных из действий в реальном времени в Интернете. Это может привести к изменению данных в данных, и существует вероятность ошибки измерения при записи данных.
Это когда выбросы вступают в сцену.
Оформление – это точка или набор точек данных, которые лежат от остальных значений данных набора данных Отказ То есть это точка данных, которые отображаются вдали от общего распределения значений данных в наборе данных.
Выбросы возможны только в непрерывных значениях. Таким образом, обнаружение и удаление выбросов применимы только к значениям регрессии.
В основном, выбросы, по-видимому, расходятся от общего правильного и хорошо структурированного распределения элементов данных. Это можно считать как Ненормальное распределение, которое появляется вдали от класса или население.
Поняв концепцию выбросов, давайте сейчас сосредоточимся на необходимости удаления выбросов в предстоящем разделе.
Почему необходимо удалить выбросы от данных?
Как обсуждалось выше, выбросы являются точками данных, которые лежат вдали от обычного распределения данных и приводит к тому, что ниже воздействие на общее распределение данных:
Из-за вышеуказанных причин необходимо обнаружить и избавиться от выбросов до моделирования набора данных.
Обнаружение выбросов – IQR подход
Выбросы в наборе данных могут быть обнаружены методами ниже:
В этой статье мы реализуем метод IQR для обнаружения и лечения выбросов.
IQR – аббревиатура для межступного диапазона Отказ Он измеряет статистическую дисперсию значений данных как мера общего распространения.
IQR эквивалентен разницей между первым квартилем (Q1) и третьим квартилью (Q3) соответственно.
Здесь Q1 относится к первому квартилю I.e. 25% и Q3 относится к третьему квартилю I.e. 75%.
Мы будем использовать Boxplots для обнаружения и визуализации выбросов, присутствующих в наборе данных.
Коробки изображают распределение данных с точки зрения квартилей и состоит из следующих компонентов
Любая точка данных, которая лежит ниже нижней границы, и над верхней границей рассматривается как выброс.
Давайте теперь будем реализовать BoxPlot для обнаружения выбросов в приведенном ниже примере.
Пример :
Первоначально мы импортировали набор данных в окружающую среду. Вы можете найти набор данных здесь Отказ
Кроме того, мы сегрегировали переменные в числовые и категорические значения.
Мы применяем BoxPlot, используя BoxPlot () Функция на числовых переменных, как показано ниже:
Как видно выше, вариабельная «ветряная скорость» содержит выбросы, которые лежат над нижней границей.
Удаление выбросов
Сейчас самое время лечить выбросы, которые мы обнаружили, используя BoxPlot в предыдущем разделе.
Используя IQR, мы можем следовать приведенному ниже подходу для замены выбросов в нулевое значение:
Таким образом, мы использовали numpy.percentile () Метод Для расчета значений Q1 и Q3. Кроме того, мы заменили выбросы с numpy.nan как нулевые значения.
Заменив выбросы NAN, давайте теперь проверьте сумму нулевых значений или отсутствующих значений, используя код ниже:
Сумма подсчета нулевых значений/выбросов в каждом столбце набора данных:
Теперь мы можем использовать любую из приведенных ниже методов для лечения нулевых значений:
Здесь мы бросили бы нулевые значения, используя Pandas.dataframe.dropna () функция
Обработавшись к выбросам, давайте теперь проверяем наличие отсутствующих или нулевых значений в наборе данных:
Таким образом, все выбросы, присутствующие в наборе данных, были обнаружены и обработаны (удалены).
Заключение
По этому, мы подошли к концу этой темы. Не стесняйтесь комментировать ниже, если вы столкнетесь с любым вопросом.
Моем датасет: руководство по очистке данных в Python

furry.cat

Ни одна модель машинного обучения не выдаст осмысленных результатов, если вы предоставите ей сырые данные. После формирования выборки данных их необходимо очистить.
Определение очень длинное и не очень понятное 🙁
Чтобы детально во всем разобраться, мы разбили это определение на составные части и создали пошаговый гайд по очистке данных на Python. Здесь мы разберем методы поиска и исправления:
Для работы с данными мы использовали Jupyter Notebook и библиотеку Pandas.
Базой для наших экспериментов послужит набор данных по ценам на жилье в России, найденный на Kaggle. Мы не станем очищать всю базу целиком, но разберем на ее основе главные методы и операции.
Прежде чем переходить к процессу очистки, всегда нужно представлять исходный датасет. Давайте быстро взглянем на сами данные:
Этот код покажет нам, что набор данных состоит из 30471 строки и 292 столбцов. Мы увидим, являются ли эти столбцы числовыми или категориальными признаками.
Теперь мы можем пробежаться по чек-листу «грязных» типов данных и очистить их один за другим.

1. Отсутствующие данные
Работа с отсутствующими значениями – одна из самых сложных, но и самых распространенных проблем очистки. Большинство моделей не предполагают пропусков.
1.1. Как обнаружить?
Рассмотрим три метода обнаружения отсутствующих данных в наборе.
1.1.1. Тепловая карта пропущенных значений
Когда признаков в наборе не очень много, визуализируйте пропущенные значения с помощью тепловой карты.
Приведенная ниже карта демонстрирует паттерн пропущенных значений для первых 30 признаков набора. По горизонтальной оси расположены признаки, по вертикальной – количество записей/строк. Желтый цвет соответствует пропускам данных.
Заметно, например, что признак life_sq имеет довольно много пустых строк, а признак floor – напротив, всего парочку – около 7000 строки.
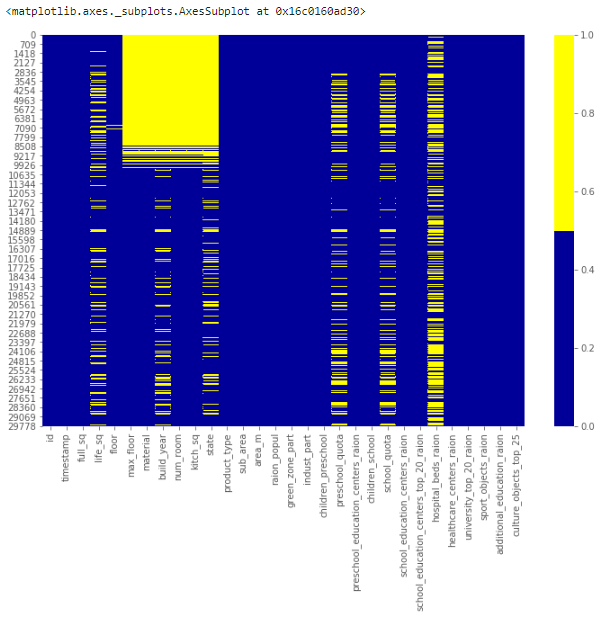 Карта отсутствующих данных
Карта отсутствующих данных
1.1.2. Процентный список пропущенных данных
Если в наборе много признаков и визуализация занимает много времени, можно составить список долей отсутствующих записей для каждого признака.
Такой список для тех же 30 первых признаков выглядит следующим образом:
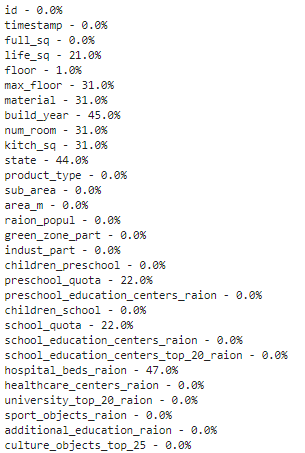 Список недостающих данных % – первые 30 функций
Список недостающих данных % – первые 30 функций
У признака life_sq отсутствует 21% значений, а у floor – только 1%.
Этот список является полезным резюме, которое может отлично дополнить визуализацию тепловой карты.
1.1.3. Гистограмма пропущенных данных
Еще одна хорошая техника визуализации для наборов с большим количеством признаков – построение гистограммы для числа отсутствующих значений в записи.
Отсюда понятно, что из 30 тыс. записей более 6 тыс. строк не имеют ни одного пропущенного значения, а еще около 4 тыс.– всего одно. Такие строки можно использовать в качестве «эталонных» для проверки различных гипотез по дополнению данных.
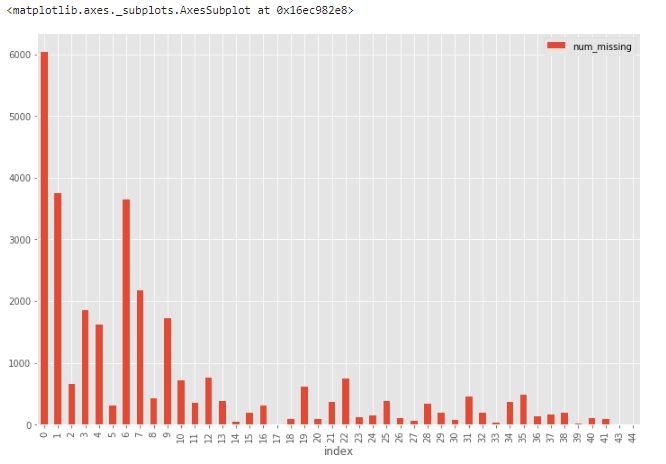 Гистограмма пропущенных значений
Гистограмма пропущенных значений
1.2. Что делать с пропущенными значениями?
Не существует общих решений для проблемы отсутствующих данных. Для каждого конкретного набора приходится искать наиболее подходящие методы или их комбинации.
Разберем четыре самых распространенных техники. Они помогут в простых ситуациях, но, скорее всего, придется проявить творческий подход и поискать нетривиальные решения, например, промоделировать пропуски.
1.2.1. Отбрасывание записей
Первая техника в статистике называется методом удаления по списку и заключается в простом отбрасывании записи, содержащей пропущенные значения. Это решение подходит только в том случае, если недостающие данные не являются информативными.
1.2.2. Отбрасывание признаков
Как и предыдущая техника, отбрасывание признаков может применяться только для неинформативных признаков.
В процентном списке, построенном ранее, мы увидели, что признак hospital_beds_raion имеет высокий процент недостающих значений – 47%. Мы можем полностью отказаться от этого признака:
1.2.3. Внесение недостающих значений
Для численных признаков можно воспользоваться методом принудительного заполнения пропусков. Например, на место пропуска можно записать среднее или медианное значение, полученное из остальных записей.
Для категориальных признаков можно использовать в качестве заполнителя наиболее часто встречающееся значение.
Возьмем для примера признак life_sq и заменим все недостающие значения медианой этого признака:
Одну и ту же стратегию принудительного заполнения можно применить сразу для всех числовых признаков:
К счастью, в нашем наборе не нашлось пропусков в категориальных признаках. Но это не мешает нам продемонстрировать использование той же стратегии:
1.2.4. Замена недостающих значений
Таким образом, мы сохраняем данные о пропущенных значениях, что тоже может быть ценной информацией.
2. Нетипичные данные (выбросы)
Выбросы – это данные, которые существенно отличаются от других наблюдений. Они могут соответствовать реальным отклонениям, но могут быть и просто ошибками.
2.1. Как обнаружить выбросы?
Для численных и категориальных признаков используются разные методы изучения распределения, позволяющие обнаружить выбросы.
2.1.1. Гистограмма/коробчатая диаграмма
Из-за возможных выбросов данные выглядят сильно искаженными.
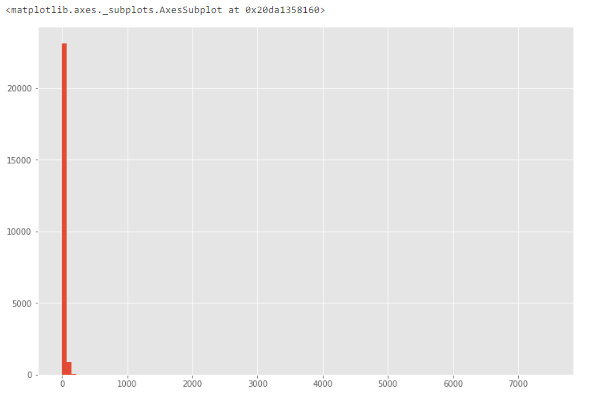 Построение гистограммы для обнаружения выбросов
Построение гистограммы для обнаружения выбросов
Чтобы изучить особенность поближе, построим коробчатую диаграмму.
Видим, что есть выброс со значением более 7000.
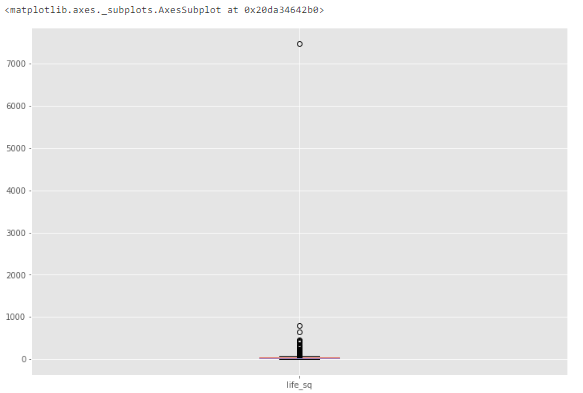 Построение коробчатой диаграммы для обнаружения выбросов
Построение коробчатой диаграммы для обнаружения выбросов
2.1.2. Описательная статистика
Отклонения численных признаков могут быть слишком четкими, чтобы не визуализироваться коробчатой диаграммой. Вместо этого можно проанализировать их описательную статистику.
Например, для признака life_sq видно, что максимальное значение равно 7478, в то время как 75% квартиль равен только 43. Значение 7478 – выброс.
outlier_describe.py 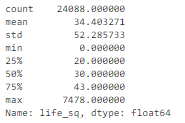
2.1.3. Столбчатая диаграмма
Для категориальных признаков можно построить столбчатую диаграмму – для визуализации данных о категориях и их распределении.
outlier_barchart.py 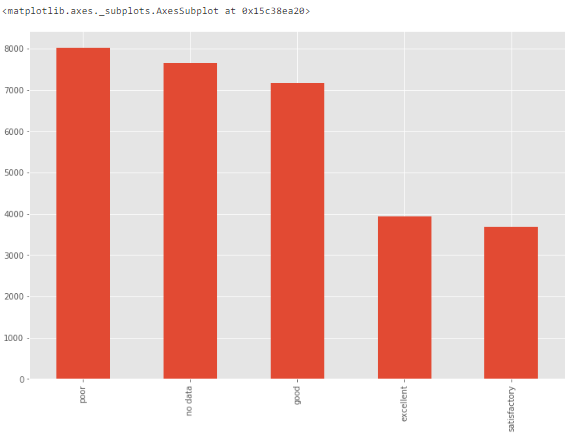 Построение столбчатой диаграммы для обнаружения выбросов
Построение столбчатой диаграммы для обнаружения выбросов
2.1.4. Другие методы
Для обнаружения выбросов можно использовать другие методы, например, построение точечной диаграммы, z-оценку или кластеризацию. В этом руководстве они не рассматриваются.
2.2. Что делать?
Выбросы довольно просто обнаружить, но выбор способа их устранения слишком существенно зависит от специфики набора данных и целей проекта. Их обработка во многом похожа на обработку пропущенных данных, которую мы разбирали в предыдущем разделе. Можно удалить записи или признаки с выбросами, либо скорректировать их, либо оставить без изменений.
Переходим к более простой части очистки данных – удалению мусора.
Вся информация, поступающая в модель, должна служить целям проекта. Если она не добавляет никакой ценности, от нее следует избавиться.
Три основных типа «ненужных» данных:
Рассмотрим работу с каждым типом отдельно.
3. Неинформативные признаки
Если признак имеет слишком много строк с одинаковыми значениями, он не несет полезной информации для проекта.
3.1. Как обнаружить?
Составим список признаков, у которых более 95% строк содержат одно и то же значение.
Теперь можно последовательно перебрать их и определить, несут ли они полезную информацию.
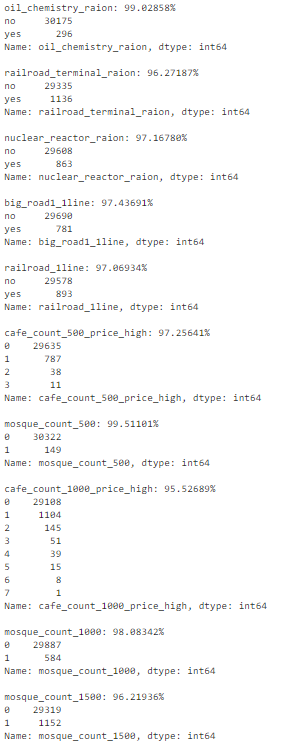 Список признаков с высоким процентом одинаковых значений
Список признаков с высоким процентом одинаковых значений
3.2. Что делать?
4. Нерелевантные признаки
Нерелевантные признаки обнаруживаются ручным отбором и оценкой значимости. Например, признак, регистрирующий температуру воздуха в Торонто точно не имеет никакого отношения к прогнозированию цен на российское жилье. Если признак не имеет значения для проекта, его нужно исключить.
5. Дубликаты записей
Если значения признаков (всех или большинства) в двух разных записях совпадают, эти записи называются дубликатами.
5.1. Как обнаружить повторяющиеся записи?
Получаем в результате 10 отброшенных дубликатов:
 Обнаружение неуникальных записей по идентификатору
Обнаружение неуникальных записей по идентификатору
Другой распространенный способ вычисления дубликатов: по набору ключевых признаков. Например, неуникальными можно считать записи с одной и той же площадью жилья, ценой и годом постройки.
Получаем в результате 16 дублирующихся записей:
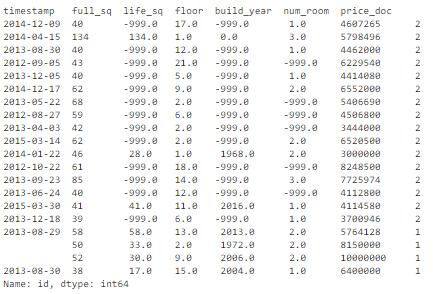 Обнаружение дубликатов по набору ключевых признаков
Обнаружение дубликатов по набору ключевых признаков
5.2. Что делать с дубликатами?
Очевидно, что повторяющиеся записи нам не нужны, значит, их нужно исключить из набора.
Вот так выглядит удаление дубликатов, основанное на наборе ключевых признаков:
В результате новый набор df_dedupped2 стал короче на 16 записей.
 Результат отбрасывания дубликатов записей
Результат отбрасывания дубликатов записей
Большая проблема очистки данных – разные форматы записей. Для корректной работы модели важно, чтобы набор данных соответствовал определенным стандартам – необходимо тщательное исследование с учетом специфики самих данных. Мы рассмотрим четыре самых распространенных несогласованности:
6. Разные регистры символов
Непоследовательное использование разных регистров в категориальных значениях является очень распространенной ошибкой, которая может существенно повлиять на анализ данных.
6.1. Как обнаружить?
Давайте посмотрим на признак sub_area :
В нем содержатся названия населенных пунктов. Все выглядит вполне стандартизированным:
 Записи с разным регистром символов
Записи с разным регистром символов
6.2. Что делать?
Эта проблема легко решается принудительным изменением регистра:
string_lower_case2.py  Приведение всех символов к нижнему регистру
Приведение всех символов к нижнему регистру
7. Разные форматы данных
7.1. Как обнаружить?
Признак timestamp представляет собой строку, хотя является датой:
string_to_datetime1.py 
7.2. Что же делать?
Чтобы было проще анализировать транзакции по годам и месяцам, значения признака timestamp следует преобразовать в удобный формат:
string_to_datetime2.py 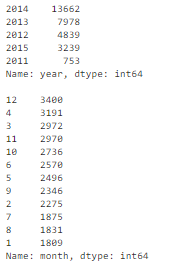 Преобразование строк в даты
Преобразование строк в даты
8. Опечатки
Опечатки в значениях категориальных признаков приводят к таким же проблемам, как и разные регистры символов.
8.1. Как обнаружить?
Простой способ идентификации подобных элементов – нечеткая логика или редактирование расстояния. Суть этого метода заключается в измерении количества букв (расстояния), которые нам нужно изменить, чтобы из одного слова получить другое.
Те слова, в которых содержатся опечатки, имеют меньшее расстояние с правильным словом, так как отличаются всего на пару букв.
fuzzy_logic_distance.py  Вычисление расстояния между словами для обнаружения опечаток
Вычисление расстояния между словами для обнаружения опечаток
8.2. Что делать?
Мы можем установить критерии для преобразования этих опечаток в правильные значения.
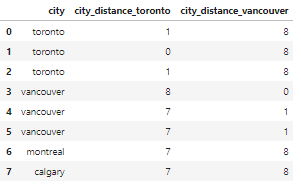 Исправление найденных опечаток
Исправление найденных опечаток
9. Адреса
Адреса – ужасная головная боль для всех аналитиков данных. Ведь мало кто следует стандартному формату, вводя свой адрес в базу данных.
9.1. Как обнаружить?
Проще предположить, что проблема разных форматов адреса точно существует. Даже если визуально вы не обнаружили беспорядка в этом признаке, все равно стоит стандартизировать их для надежности.
В нашем наборе данных по соображениям конфиденциальности отсутствует признак адреса, поэтому создадим новый набор df_add_ex :
Признак адреса здесь загрязнен:
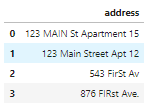 Значения адреса
Значения адреса
9.2. Что делать?
Минимальное форматирование включает следующие операции:
Теперь признак стал намного чище:
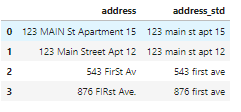 Стандартизация адресов
Стандартизация адресов
Мы сделали это! Это был долгий и трудный путь, но теперь все «грязные» данные очищены и готовы к анализу, а вы стали спецом по чистке данных 😉

У нас есть еще куча полезных статей по Data Science, например, среди недавних:



