Что такое базы данных временных рядов (time series database)
Временные ряды – один из наиболее часто встречающихся в аналитической практике объектов. Временной ряд – это статистика серии наблюдений за одним и тем же явлением, параметром какого-либо процесса, на протяжении некоторого времени. Каждому результату наблюдения (измерению) соответствует время, когда это наблюдение было сделано, или его порядковый номер – опять же, по шкале времени. Таким образом, при анализе временных рядов учитываются не только базовые статистические закономерности, но и взаимосвязь измерений со временем.
Что такое базы данных временных рядов и почему потребовалось создавать специализированные БД, если есть достаточное количество серьезных промышленных систем управления базами данных: Oracle, MS SQL Server, Sybase и много других? Чтобы ответить на этот вопрос, необходимо понять, что составляет предмет этих БД.
Такого рода данные требуются и накапливаются при самых разных задачах и для самых разных нужд. Можно привести несколько примеров:
Иными словами, спрос на инструменты для хранения и обработки данных временных рядов достаточно высок (особенно со стороны финансового рынка). Однако пользователи крупных СУБД столкнулись с проблемой: универсальные монстры оказались слабо приспособлены для решения именно таких задач, и проблема вырастала из идеологии (модели данных) наиболее распространенных в то время реляционных баз данных, не позволяющей эффективно работать с упорядоченным множеством элементов временного ряда. Появились разработки специализированного программного обеспечения, оптимизированного под эти задачи.
Базы данных временных рядов (time series database) позволяют пользователям создавать, считать, обновлять и удалять различные временные ряды и организовывать их неким образом. Сервер часто поддерживает ряд основных вычислений, которые работают на ряды в целом, например, умножая, складывая или иным образом комбинируя различные временные ряды в новый временной ряд. Они могут также фильтровать по произвольным образцам, при этом значения одного ряда могу являться фильтром для другого. Простой синтаксис является залогом привлекательности специальных баз данных временных рядов.
Среди специальных TSBD преобладают продукты, основанные на свободной лицензии: Open TSDB, InfluxDB, Geras, Druid и пр. Некоторые из них «заточены» под относительно узкий спектр задач. Так, YAWNDB и SiteWhere позиционируются как инструмент для специалистов в области веб-технологий.
Реализация функционала базы данных временных рядов возможна в обычной реляционной БД на основе SQL при условии, что программное обеспечение базы данных поддерживает одновременно большие двоичные объекты (BLOB) и пользовательские функции. Но эффективность такой системы также будет невысока. Поэтому разработчики крупных баз данных пытаются развить реляционную модель данных до объектно-реляционной, обладающей частью свойств объектно-ориентированной БД, в частности, в поддержке концепции абстрактного типа данных. Например, IBM предлагает оптимизированный продуктом Informix Time Series.
ИТ База знаний
Полезно
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
7 мощных баз данных временных рядов

Базы данных временных рядов полностью настраиваются с данными временных меток, которые индексируются и эффективно записываются таким образом, что можно вставить данные временных рядов. Эти данные временных рядов можно запрашивать гораздо быстрее, чем из реляционной базы данных или базы данных NoSQL.
1. InfluxDB
InfluxDB является одной из самых популярных баз данных временных рядов среди DevOps, которая написана в Go. InfluxDB была разработана с самого начала, с целью обеспечить высокомасштабируемый механизм приема и хранения данных. Он очень эффективен при сборе, хранении, запросе, визуализации и выполнении действий с потоками данных временных рядов, событий и метрик в реальном времени.
Она предоставляет политики понижающей дискретизации и хранения данных для поддержания высокой ценности, высокой точности данных в памяти и более низкой ценности данных на диске. Он построен на основе «облачной» технологии для обеспечения масштабируемости в нескольких топологиях развертывания, включая локальную облачную среду и гибридные среды.
Особенности
Так как это открытый исходный код, вы можете загрузить и поднять его на своем сервере. Тем не менее, они предлагают InfluxDB Cloud на AWS, Azure и GCP.
2. Prometheus
Он плотно интегрируется с Grafana для визуализации.
Особенности
У Prometheus есть сотни экспортеров для экспорта данных из Windows, Linux, Java, базы данных, API, веб-сайта, серверного оборудования, PHP, обмена сообщениями и т.д.
3. TimescaleDB

Он может использоваться для мониторинга DevOps, понимания показателей приложений, отслеживания данных с устройств Интернета вещей, понимания финансовых данных и т.д. Можно измерять журналы, события Kubernetes, метрики Prometheus и даже пользовательские метрики.
Владельцы продуктов могут использовать его для понимания производительности продукта с течением времени, что помогает принимать стратегические решения для роста.
Особенности
4. Graphite
Особенности Graphite:
5. QuestDB

Функции QuestDB:
6. AWS Timestream
Как AWS может отсутствовать в списке?
С помощью специализированного механизма запросов можно одновременно запрашивать последние данные и архивные сохраненные данные. Она предоставляет множество встроенных функций для анализа данных временных рядов для поиска полезной информации.

Функции Amazon Timestream:
7. OpenTSDB
Имеет демон временных рядов (TSD) и утилиты командной строки. Демон временных рядов отвечает за хранение данных в HBase или их извлечение из нее. С TSD можно общаться с помощью HTTP API, telnet или простого встроенного графического интерфейса. Для сбора данных из различных источников в OpenTSDB нужны такие инструменты, как flume, collectd, vacuumetrix и т.д.
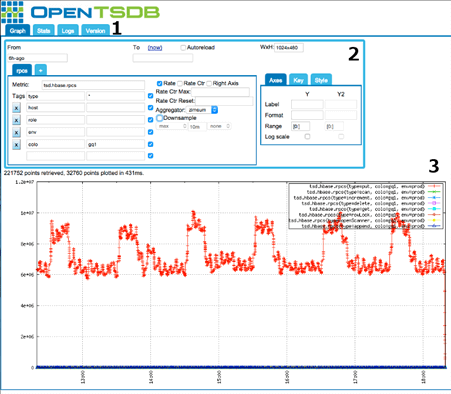
Функции OpenTSBD:
Заключение
Поскольку в наши дни используются все больше и больше IoT или умных устройств, на веб-сайтах с миллионами событий в день в реальном времени генерируется огромный трафик, увеличивается торговля на рынке, что и привело к созданию база данных временных рядов! Базы данных временных рядов являются обязательным элементом производственного стека для мониторинга.
Большая часть вышеперечисленной базы данных временных рядов доступна для бесплатного использования, поэтому получите облачную виртуальную машину и попробуйте посмотреть, что подойдет именно вам.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps
Time Series, метрики и статистика: знакомство с InfluxDB

Введение
Любому системному администратору постоянно приходится иметь дело с данными, представленными в форме временных рядов (time series): статистика скачивания файлов, статистика запросов к серверам, данные об использовании системных и аппаратных ресурсов виртуальными машинами…
Чтобы все это хранить и обрабатывать, нужен адекватный и производительный инструмент.
Для хранения временных рядов часто используются специализированные решения — так называемые time series (темпоральные) базы данных. Об их плюсах и минусах мы уже писали. Пытаясь исправить недостатки имеющихся решений, мы даже разработали собственный продукт — time series базу данных YAWNDB, которая используется в нашей системе мониторинга. Но все time series базы данных являются низкоуровневыми, а возможности их применения весьма ограничены. Во-первых, они не позволяют объединять временные ряды c данными других типов — например, со словарями. Во-вторых, они совершенно не рассчитаны на работу с большими объемами данных. В большинстве темпоральных БД даже нет языка запросов. Поэтому стандартная задача — запросить и получить нужную информацию в любой момент времени — становится очень сложной и нетривиальной. Конечно, её можно решить и без языка запросов, но это под силу только пользователям, обладающим специальными знаниями и недюжинными навыками программирования.
Для хранения временных рядов сегодня всё чаще используются так называемые NoSQL базы данных — как популярные HBase и Cassandra, так и более специализированные решения — например, OpenTSDB, KairosDB и Acunu. Возможно, в некоторых ситуациях такой вариант вполне оправдан, но для решения подавляющего большинства практических задач он вряд ли подойдёт. Все перечисленные выше БД работают на базе инфраструктуры Hadoop, и для их нормального функционирования требуется огромное количество зависимостей. Да и с производительностью у них не всё так гладко, как может показаться на первый взгляд (подробнее об этом см., например, здесь).
Как же решить проблему хранения временных рядов, метрик и статистики? Мы серьезно задумались над этим вопросом, когда подбирали вариант хранения информации о запросах к нашим NS-серверам.
Совершенно неожиданно в обсуждении нашего поста на Хабрахабре один из читателей порекомендовал NoSQL базу данных InfluxDB. Мы попробовали ее — и остались вполне довольны. Своим опытом работы с InfluxDB мы хотели бы поделитьcя в этой статье.
Общая информация
База данных InfluxDB (см. репозиторий на GitHub), написанная на языке Go — продукт новый: первый его релиз состоялся в октябре 2013 года. Она позиционируется как база данных для хранения временных рядов, метрик и информации о событиях.
B качестве низкоуровневого хранилища пар «ключ-значение» в InfluxDB используется база данных LevelDB. Для этой цели можно также использовать RocksDB (по утверждению разработчиков InfluxDB, именно это хранилище показывает наилучшую производительность — см. отчет о тестировании здесь), и LMDB.
Записывать данные в InfluxDB можно различными способами. Во-первых, данные в формате JSON можно передавать через HTTP API. Во-вторых, InfluxDB поддерживает протокол Carbon, используемый в инструменте для обработки и визуализации данных Graphite. В-третьих, данные можно отправлять по протоколу UDP.
InfluxDB может использоваться в качестве бэкенда для Graphite, и благодаря этому можно существенно повысить его производительность. Поддерживается также возможность работы с дашбордом для метрик Grafana (более подробно об этом речь ещё пойдёт ниже).
Несомненным плюсом InfluxDB являются и широкие возможности интеграции с другими программными продуктами — например, инструментом для обработки логов Fluentd, демонами для сбора статистики CollectD и и StatsD, фреймворками для мониторинга Sensu и Shinken.
Установка
Установим Influx DB и посмотрим, как её можно использовать на практике. Процедуры установки и настройки мы будем рассматривать на пример с OC Ubuntu; для других дистрибутивов Linux они могут отличаться (подробности см. в официальной документации).
Выполним следующую команду:
По завершении установки запустим InfluxDB:
По умолчанию InfluxDB использует порты 8083, 8086, 8090 и 8099. Можно использовать и другие порты — для этого потребуется внести соответствующие изменения в конфигурационный файл. Рассмотрим особенности конфигурирования InfluxDB более подробно.
Настройка и конфигурирование
Все настройки InfluxDB хранятся в конфигурационном файле /opt/influxdb/current/config.toml. Они делятся на следующие группы:
[logging] — параметры логгирования (указываются уровень логгирования и имя файла лога);
[admin] — настройки веб-интерфейса (порт, на котором работает внутренний веб-сервер, и путь к файлам веб-интерфейса);
[api] — настройки HTTP API;
[input_plugins] — настройки ввода данных из внешних источников (в InfluxDB можно передавать данные, предназначенные для отправки в Graphite; также в этом разделе можно настроить ввод данных по протоколу UDP).
[raft] — настройки протокола согласования RAFT;
[storage] — общие настройки хранения данных;
[cluster] — настройки работы в кластерном режиме (более подробно они будут описаны ниже;
[wal] — настройки опережающего введения журнала (Write Ahead Logging, WAL).
Создаём базу данных
По завершении установки откроем в браузере страницу localhost:8083. Мы увидим веб-интерфейс для работы с базами данных. Выглядит он так:
Введем теперь логин (root) и пароль (root) (начальные значения можно задать в конфигурационном файле до первого запуска), а затем нажмем на кнопку Connect. Откроется следующее окно:
Графический интерфейс InfluxDB прост и интуитивно понятен. Обратим внимание на некоторые важные моменты, которые следует учитывать при создании первой базы данных.
Чтобы упростить и ускорить чтение данных при запросе, базу лучше разделить на составные части небольшого объема — так называемые шарды (англ. shards) Совокупность шардов, формируемых на основе одного и того же принципа, называется шардовым пространством (англ. shard space).
Создавая базу, нужно указать, какие шардовые пространства будут входить в ее состав. Данные можно делить на шарды, во-первых, по временным отрезкам. Если, например, мы будем хранить в базе информацию о действиях пользователей, то ее удобнее разбивать на временные отрезки — например, данные за каждые 7 дней будут хранится в отдельном шарде. Длина временного отрезка указывается в разделе Duration. В графе Retention указывается срок хранения шарда.
При создании базы данных можно указывать и параметры для работы в кластере. В графе RF (эта аббревиатура означает Replication Factor — фактор репликации) указывается, на скольких узлах должна храниться копия каждого шарда в шардовом пространстве. В графе Split указывается, на сколько шардов нужно делить данные в для конкретного временного промежутка.
Чтобы каждый сервер в кластере был готов к записи «горячих» данных в любой момент времени, значение фактора репликации рекомендуется рассчитывать по следующей формуле:
(RF — фактор репликации, NoS — число серверов)
Алгоритм, лежащий в основе деления данных на шарды, включает следующие шаги:
1. Программа просматривает все шардовые пространства в базе.
2. Затем она проходит все шардовые пространства циклом и ищет пространство, которому соответствуют новые данные.
3. После этого просматриваются все шарды для заданного временного интервала;
4. Если шардов не существует, то будет создано N шардов (N — число, указанное в графе split).
5. Данные записываются в шард с использованием алгоритма hash(series_name) % N.
Рекомендуется устанавливать небольшие размеры шарда по времени (duration).
Если установить для времени хранения шарда (retention) значение inf (т.е. бесконечный), этот шард никогда не будет удалён.
Установив все необходимые настройки, нажмём на кнопку Create Database.
Работа в кластере
В режиме кластера несколько серверов InfluxDB образуют единую систему. Каждый узел кластера может принимать запросы на чтение и запись. Для организации работы в кластере используется протокол согласования RAFT. Понятное и наглядное объяснение принципа его работы представлено в этой презентации.
Согласно официальной документации, в текущем релизе работа в кластере поддерживается лишь в режиме тестирования. Полноценная реализация запланирована на одну из следующих версий (0.9 или 0.10).
В документации ничего не сказано о том, как прописываются настройки кластера в конфигурационном файле, поэтому мы подробно остановимся на этом моменте. Итак, чтобы настроить кластер, нужно:
1. Запустить первый узел InfluxDB со всеми нужными настройками, но без параметра seed-servers в конфигурационном файле (раздел cluster).
2. На втором и всех последующих узлах в качестве значения параметра seed-servers указывается IP-адрес первого сервера, который должен быть запущен самостоятельно:
Если сервер уже был запущен без установки параметра seed-servers, то перед добавлением в кластер нужно удалить с него все данные InfluxDB (путь к данным по умолчанию: /opt/influxdb/shared/data/).
При добавлении нового узла можно указывать IP-адрес любого сервера, уже входящего в состав кластера.
Порт указываем тот же, что и в разделе [raft] (по умолчанию — 8090).
Управление правами пользователей
Возможности управления правами пользователей через графический интерфейс очень ограничены: можно только выполнять простейшие операции добавления и удаления пользователей и разрешать полный (c правами администратора) доступ.
Более тонкие настройки доступа к данным можно устанавливать только через API. Доступ к метрикам реализован в виде регулярных выражений.
В схематичном виде структура запроса выглядит так:
Приведём пример команды для изменения настроек доступа:
Просмотреть текущие правила можно с помощью команды
Из полученного вывода видно, что пользователь grafana может читать все метрики (“*.”), но при этом не может ничего писать (“^$”).
Интеграция с Grafana
Grafana представляет собой удобный дашборд для выборки и визуализации метрик. На русском языке публикаций о нём почти нет, за исключением совсем небольшой заметки на Хабре.
Специально для желающих посмотреть, как работает InfluxDB в связке с Grafana, мы подготовили сценарий (playbook) для Ansible и разместили его на GitHub.
Чтобы осуществить тестовый запуск, клонируйте репозиторий по ссылке выше, в файле hosts укажите IP-адреса машин, которые будут входить в кластер, а затем запустите скрипт run.sh. Обратите внимание, что описание конфигурации Influxdb задаётся в «родном» для Ansible формате YAML, из которого затем генерируется файл в формате TOML.
Заключение
На основании собственного (пусть пока и не очень большого) опыта мы сделали вывод о том, что InfluxDB представляет собой интересное и перспективное решение, которое может быть рекомендовано к практическому использованию. Надеемся, что и у вас по прочтении нашей статьи возникнет желание познакомиться с InfluxDB поближе.
Если кто-то из вас уже использует InfluxDB — приглашаем поделиться опытом в комментариях.
Читателей, которые по тем или иным причинам не имеют возможности оставлять комментарии здесь, приглашаем в наш блог.
Time series database (TSDB) explained
What is a time series database?
A time series database (TSDB) is a database optimized forВ time-stamped or time series data. Time series data are simply measurements or events that are tracked, monitored, downsampled, and aggregated over time. This could be server metrics, application performance monitoring, network data, sensor data, events, clicks, trades in a market, and many other types of analytics data.
A time series database is built specifically for handling metrics and events or measurements that are time-stamped. A TSDB is optimized for measuring change over time. Properties that make time series data very different than other data workloads are data lifecycle management, summarization, and large range scans of many records.
Why is a time series database important now?
Time series databases are not new, but the first-generation time series databases were primarily focused on looking at financial data, the volatility of stock trading, and systems built to solve trading. But financial data is hardly the only application of time series data anymore — in fact, it’s only one among numerous applications across various industries. The fundamental conditions of computing have changed dramatically over the last decade. Everything has become compartmentalized. Monolithic mainframes have vanished, replaced by serverless servers, microservers, and containers.
Today, everything that can be a component is a component. In addition, we are witnessing the instrumentation of every available surface in the material world — streets, cars, factories, power grids, ice caps, satellites, clothing, phones, microwaves, milk containers, planets, human bodies. Everything has, or will have, a sensor. So now, everything inside and outside the company is emitting a relentless stream of metrics and events or time series data.
This means that the underlying platforms need to evolve to support these new workloads — more data points, more data sources, more monitoring, more controls. What we’re witnessing, and what the times demand, is a paradigmatic shift in how we approach our data infrastructure and how we approach building, monitoring, controlling, and managing systems. What we need is a performant, scalable, purpose-built time series database.
What distinguishes the time series workload?
Time series databases have key architectural design properties that make them very different from other databases. These include time-stamp data storage and compression, data lifecycle management, data summarization, ability to handle large time series dependent scans of many records, and time series aware queries.
For example: With a time series database, it is common to request a summary of data over a large time period. This requires going over a range of data points to perform some computation like a percentile increase this month of a metric over the same period in the last six months, summarized by month. This kind of workload is very difficult to optimize for with a distributed key value store. TSDB’s are optimized for exactly this use case giving millisecond level query times over months of data. Another example: With time series databases, it’s common to keep high precision data around for a short period of time. This data is aggregated and downsampled into longer term trend data. This means that for every data point that goes into the database, it will have to be deleted after its period of time is up. This kind of data lifecycle management is difficult for application developers to implement on top of regular databases. They must devise schemes for cheaply evicting large sets of data and constantly summarizing that data at scale. With a time series database, this functionality is provided out of the box.
Independent ranking of top 15 time series databases
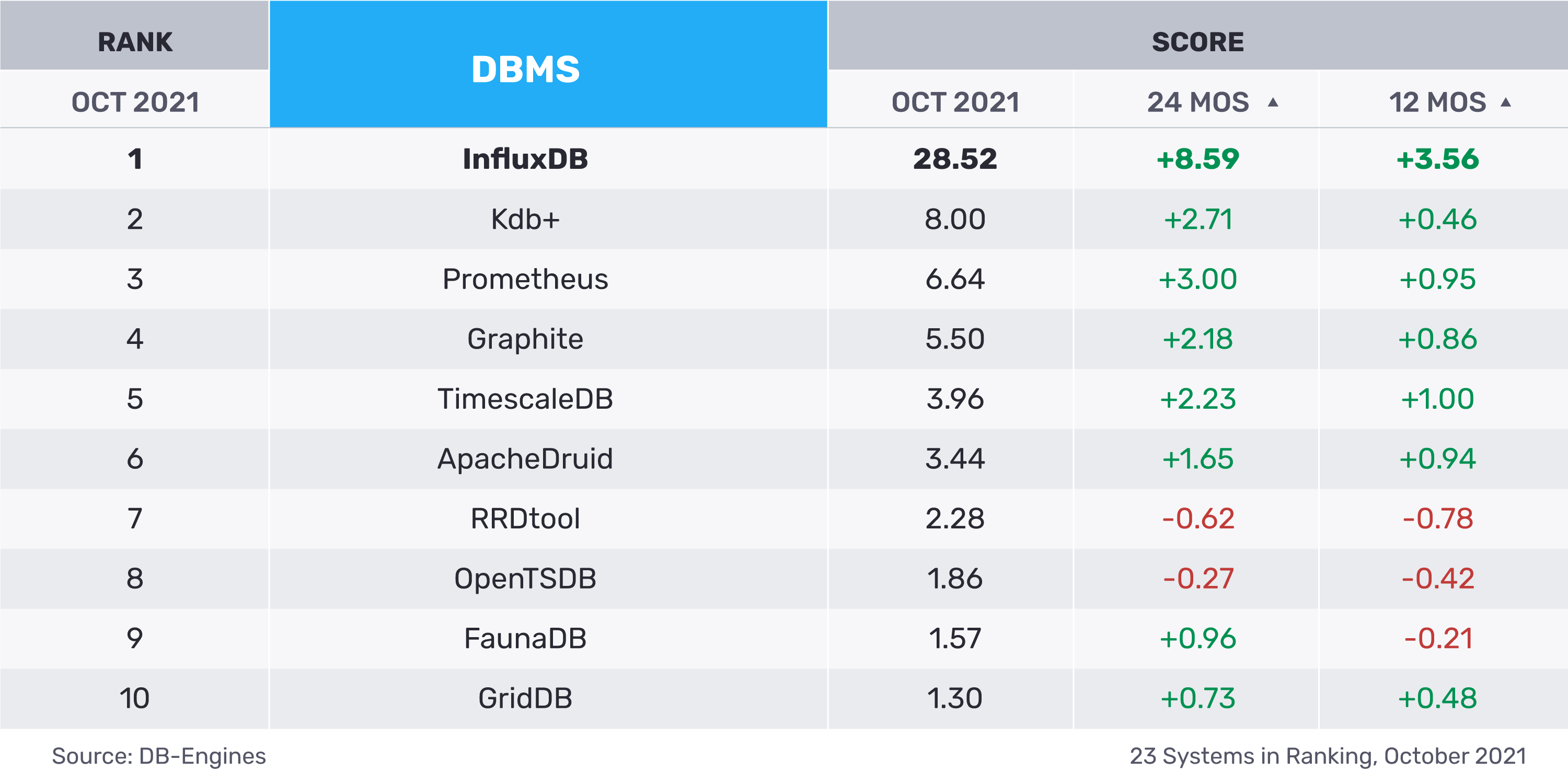
Time series databases are the fastest growing segment in the database industry. But which time series database is the best and most popular? There are many ways of determining popularity, but an independent website,В DB-Engines, ranks databases based on search engine popularity, social media mentions, job postings, and technical discussion volume. (Read their full methodology). Here are the current results:
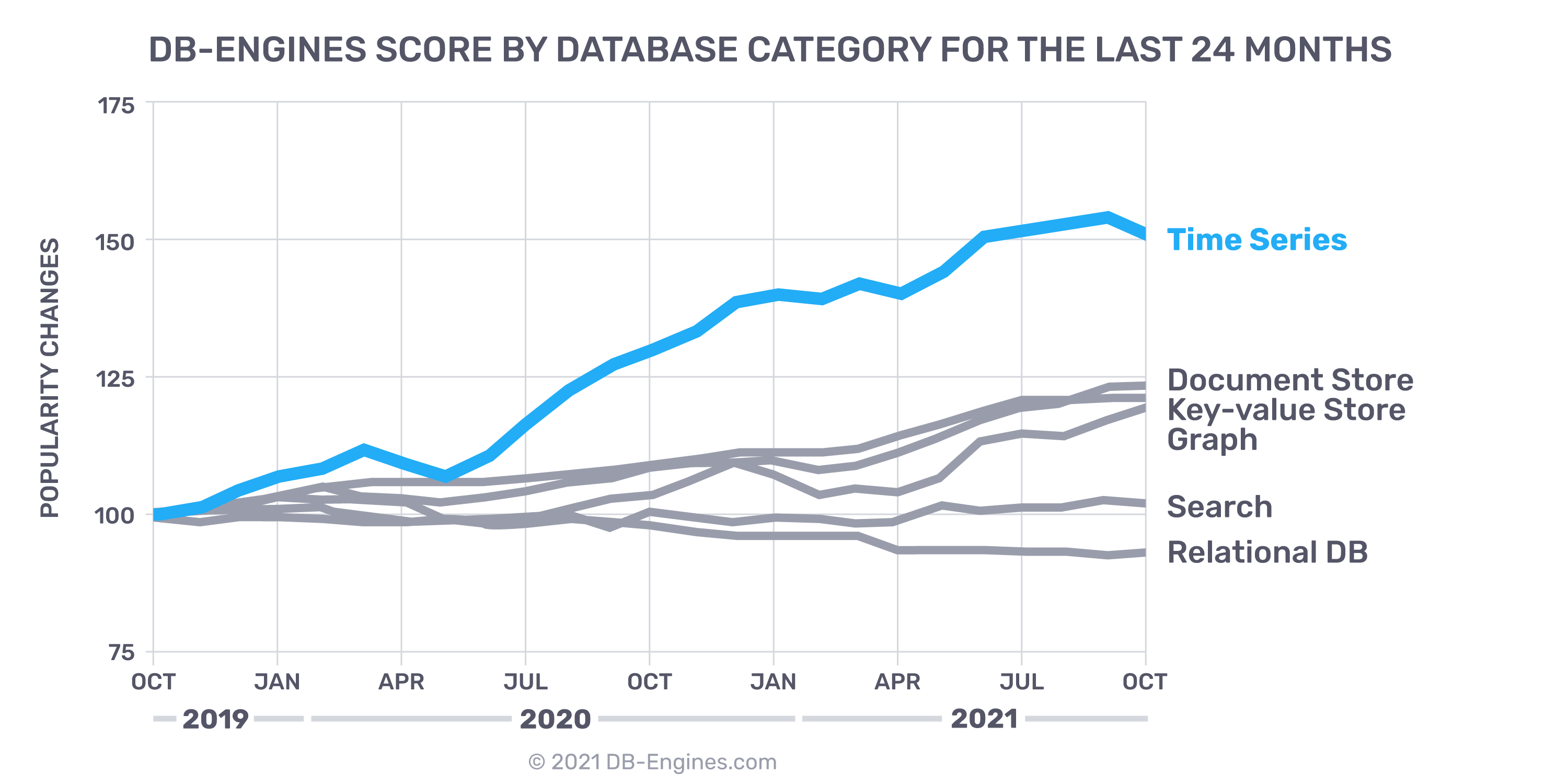
To see trends over time, the following graphic shows the top 10 time series databases and their historical changes:
Time series – the fastest growing database category
DB-Engines also ranks time series database management systems (Time Series DBMS) according to their popularity. Time series databases are theВ fastest growing segmentВ of the database industry over the past year.
What makes InfluxDB time series database unique?
InfluxDB was built from the ground up to be a purpose-built time series database; i.e., it was not repurposed to be time series. Time was built-in from the beginning. InfluxDB is part of a comprehensive platform that supports the collection, storage, monitoring, visualization and alerting of time series data. It’s much more than just a time series database.
Timestamps in InfluxDB can be second, millisecond, microsecond, or nanosecond precision. The micro and nanosecond scales make InfluxDB a good choice for use cases in finance and scientific computing where other solutions would be excluded. Compression is variable depending on the level of precision the user needs. On disk, the data is organized in a columnar style format where contiguous blocks of time are set for the measurement, tagset, field. So, each field is organized sequentially on disk for blocks of time, which make calculating aggregates on a single field a very fast operation. There is no limit to the number of tags and fields that can be used.
InfluxDB doesn’t have this limitation because the InfluxDB data model is designed for time series specifically. It pushes the developer in the right direction to get good performance out of the database by indexing tags and keeping fields unindexed. It’s flexible in that many data types are supported, and the user can have many fields and tags. Because of all these factors, a purpose-built time series database like InfluxDB is the best solution for working with time series data.
Time Series Databases: FAQ
Listed below for quick reference are brief answers to frequently asked questions about time series databases:
What is a time series database?
Here’s a brief time series database definition: A time series database (TSDB) is a database optimized for time-stamped (time series) data and for measuring change over time.
What is the best time series database?
Visit this page to learn about what makes a powerful time series database and which database is best for storing large volumes of time series data.
What are time series data examples?
Visit the What is time series data page to view time series data examples.
Is InfluxDB open source?
InfluxDB is an open source time series database with a large and vibrant community.
Can I use InfluxDB with Grafana?
There are thousands of use cases utilizing InfluxDB and Grafana. Visit our Community Showcase to read about them.
How does InfluxDB compare to other databases?
View InfluxDB benchmarking tests comparing its performance to other databases (such as Cassandra, Elasticsearch, MongoDB, OpenTSDB, Graphite and Splunk) based on parameters such as write throughout, query throughput, and on-disk storage.



