Запуск игры без AVX — что это такое?
 Приветствую ребята))
Приветствую ребята))
Коротко ответ: запуск игры на процессоре без поддержки AVX-инструкций. Обычно это старые процессоры, в итоге игра может работать, но возможно с меньшей производительностью.
Все современные процессоры поддерживают AVX. Вот например старый i7 2600K (1155 сокет) уже поддерживает AVX, но первую версию, а i7 860 (1156 сокет) — вообще не поддерживает, но правда он еще старее чем i7 2600K. Кстати легендарный процессор Q9650 (775 сокет) разумеется и близко не знает про AVX.
AVX — что это такое? Еще есть AVX2. Это улучшенные версии старых инструкций SSE. Простыми словами — это специальные инструкции, которые помогают процессору работать быстрее с некоторыми вычислениями. Они созданы как для процов Интел, так и для АМД. AVX расшифровывается как Advanced Vector Extensions.
Ну а что делают инструкции AVX? Все просто — процессор без поддержки AVX за один такт сможет сложить 1 пару чисел, а с поддержкой — уже 10. Однако это все нужно не так часто, как нам кажется, по большей части эффект заметен в профессиональных программах, а в играх не так заметно. Возможно современные игры уже больше могут использовать AVX.
Как узнать — поддерживает ли процессор AVX? Очень просто — скачайте бесплатную утилиту CPU-Z, она маленькая, неприхотливая, запустите ее и посмотрите какие инструкции поддерживает ваш проц:

Вот выше на картинке — проц i5 7400, вполне современный, как видим он поддерживает и просто AVX и более новую версию AVX2. Впрочем ничего удивительного — i5 7400 это седьмое поколение, а это 2017 год.
Надеюсь данная информация оказалась полезной. Удачи и добра, до новых встреч друзья!
Исправлено: Ваш процессор поддерживает инструкции, что этот двоичный файл TensorFlow не был скомпилирован для использования AVX2 —
Расширенные векторные расширения (AVX, также известен как Песчаный Мост Новые Расширения) являются расширениями архитектуры набора команд x86 для микропроцессоров от Intel и AMD, предложенной Intel в марте 2008 года и впервые поддержанной Intel с процессором Sandy Bridge, выпущенным в первом квартале 2011 года, а затем AMD — с процессором Bulldozer в третьем квартале 2011 года. AVX предоставляет новые функции, новые инструкции и новую схему кодирования.
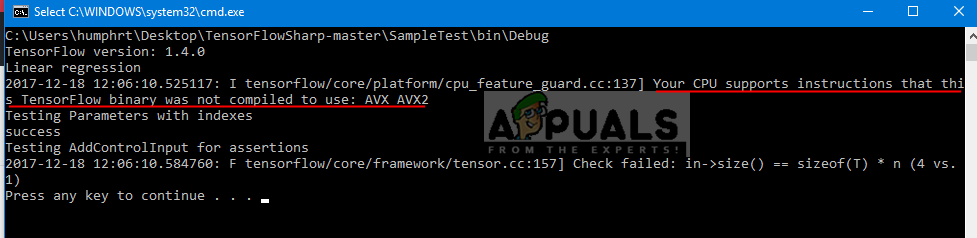 Предупреждение отображается в cmd
Предупреждение отображается в cmd
Это предупреждающее сообщение распечатывается общей библиотекой TensorFlow. Как указано в сообщении, общая библиотека не содержит инструкций, которые ваш процессор может использовать.
Что вызывает это предупреждение?
После TensorFlow 1.6 двоичные файлы теперь используют инструкции AVX, которые могут больше не работать на старых процессорах. Таким образом, старые процессоры не смогут запускать AVX, в то время как для более новых ЦП пользователь должен построить тензорный поток из источника для своего ЦП. Ниже приведена вся информация, которую вам нужно знать об этом конкретном предупреждении. Также есть способ избавления от этого предупреждения для дальнейшего использования.
Что делает AVX?
В частности, AVX представил FMA (Fused multiply-add); которая является операцией умножения-сложения с плавающей точкой, и эта операция выполняется за один шаг. Это помогает ускорить многие операции без каких-либо проблем. Это делает вычисления алгебры более быстрыми и простыми в использовании, а также точечное произведение, умножение матриц, свертку и т. Д. И это все наиболее используемые и основные операции для любого обучения машинному обучению. Процессоры, которые поддерживают AVX и FMA, будут намного быстрее, чем старые. Но в предупреждении говорится, что ваш процессор поддерживает AVX, так что это хороший момент.
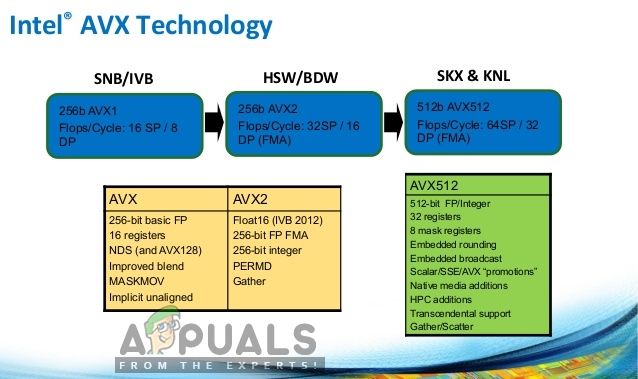 Технология Intel AVX
Технология Intel AVX
Почему он не используется по умолчанию?
Это связано с тем, что дистрибутив по умолчанию TensorFlow создается без расширений ЦП. Из-за расширений ЦП указываются AVX, AVX2, FMA и т. Д. Инструкции, которые вызывают эту проблему, не включены по умолчанию в доступных сборках по умолчанию. Причина, по которой они не включены, состоит в том, чтобы сделать это более совместимым с максимально возможным количеством процессоров. Также, чтобы сравнить эти расширения, они гораздо медленнее в процессоре, чем в графическом процессоре. Процессор используется в маломасштабном машинном обучении, в то время как использование ГПУ ожидается, когда он используется для обучения в среднем или крупномасштабном машинном обучении.
Исправление Предупреждение!
Эти предупреждения — просто сообщения. Целью этих предупреждений является информирование вас о встроенном TensorFlow из источника. Когда вы создаете TensorFlow из исходного кода, он может быть быстрее на машине. Так что все эти предупреждения говорят вам о сборке TensorFlow из исходного кода.
Если на вашем компьютере установлен графический процессор, вы можете игнорировать эти предупреждения от поддержки AVX. Потому что самые дорогие будут отправлены на устройстве с графическим процессором. И если вы хотите больше не видеть эту ошибку, вы можете просто проигнорировать ее, добавив:
импортировать Модуль ОС в коде вашей основной программы, а также установить объект сопоставления для него
Но если вы на Юникс, затем используйте команду экспорта в оболочке bash
Но если у вас нет графического процессора и вы хотите максимально использовать свой процессор, вам следует собрать TensorFlow из источника, оптимизированного для вашего процессора, с включенными здесь AVX, AVX2 и FMA.
Опять AVX инструкции
Как-то раз я постил коммент Дмитрия Бачило, который предлагал фиксить AVX инструкцию для запуска на процессорах, их не поддерживающих. Тогда в комментариях был спор, правда ли эти AVX инструкции не нужны, и не сломают ли они чего. Так вот. Не нужны. Из патчноута нового патча киберпанка:
Поясните мне за AVX, будьте любезны.
Вот тоже интересно. Просто Стар Ситизен их тоже использует, но только там их удалять наоборот не собираются, а добавили в одном из патчей. Зачем они нужны то вообще?
Без avx для, например, сложения 10 пар чисел надо потратить 10 тактов процессора, а с avx это можно сделать примерно за 1 такт, что в 10 раз быстрее.
Любопытно, все еще непонятно, но уже не настолько, спасибо.
Тогда почему и без них все работает?
Может и работает, может просто чуть медленнее
Насколько медленней? Это может критично отразиться на игре?
Может и нет. Секунда, две, три. Хз короче.
Ну вот на это даже я могу дать ответ — в самом пачноуте написано, что есть процессоры их не поддерживающие и на них то и возникают проблемы. Что логично.
Но при этом проблем без авх нет
Ну. да. Как написал чел выше, это ускоряет сложения. если он прав, то AVX ускоряет часть вычислений на процессорах, которые их поддерживают. А на процессорах, которые не поддерживают, случаются баги.
То есть, если они удалены для всех то, вероятно, мы получим некоторое замедление расчётов на поддерживающих AVX процессорах, а на не поддерживающих просто пропадут баги, которые бил только на них.
Опять же, я сейчас базируюсь только на прочитанном выше и ничего наверняка не утверждаю — просто складывают 2 и 2 без AVX инструкций,)
Почему этому поехавшему кто-то уже задонатил более 200k рублей? Чё не так с этим миром? о_О
Использование Intel AVX: пишем программы завтрашнего дня
Введение
Набор команд AVX
Использование AVX в ассемблерном коде
Определение поддержки AVX системой
Использование AVX-инструкций
Тестирование AVX кода
Оценка производительности AVX кода
Некоторое представление о производительности AVX кода можно получить с помощью другой утилиты от Intel — Intel Architecture Code Analyzer (IACA). IACA позволяет оценить время выполнения линейного участка кода (если встречаются команды условных переходов, IACA считает, что переход не происходит). Чтобы использовать IACA, нужно сначала пометить специальными маркерами участки кода, которые вы хотите проанализировать. Маркеры выглядят следующим образом:
; Начало участка кода, который надо проанализировать
%macro IACA_START 0
mov ebx, 111
db 0x64, 0x67, 0x90
%endmacro
Analysis Report
—————
Total Throughput: 2 Cycles; Throughput Bottleneck: FrontEnd, Port2_ALU, Port2_DATA, Port4
Total number of Uops bound to ports: 6
Data Dependency Latency: 14 Cycles; Performance Latency: 15 Cycles
Использование AVX в коде на C/C++
Определение поддержки AVX системой
#define XSTATE_LEGACY_FLOATING_POINT 0
#define XSTATE_LEGACY_SSE 1
#define XSTATE_GSSE 2
#define XSTATE_MASK_LEGACY_FLOATING_POINT (1i64
Нетрудно заметить, что маски XSTATE_MASK_* соответствуют аналогичным битам регистра XFEATURE_ENABLED_MASK.
В дополнение к этому, в Windows DDK есть описание функции RtlGetEnabledExtendedFeatures и констант XSTATE_MASK_XXX, как две капли воды похожих на GetEnabledExtendedFeatures и XSTATE_MASK_* из WinNT.h. Т.о. для определения поддержки AVX со стороны Windows можно воспользоваться следующим кодом:
int isAvxSupportedByWindows() <
const DWORD64 avxFeatureMask = XSTATE_MASK_LEGACY_SSE | XSTATE_MASK_GSSE;
return GetEnabledExtendedFeatures( avxFeatureMask ) == avxFeatureMask;
>
Если ваша программа должна работать не только в Windows 7 и Windows 2008 R2, то функцию GetEnabledExtendedFeatures нужно подгружать динамически из kernel32.dll, т.к. в других версиях Windows этой функции нет.
В Linux, насколько мне известно, нет отдельной функции, чтобы узнать о поддержке AVX со стороны ОС. Но вы можете воспользоваться тем фактом, что поддержка AVX было добавлена в ядро 2.6.30. Тогда остаётся только проверить, что версия ядра не меньше этого значения. Узнать версию ядра можно с помощью функции uname.
Использование AVX-инструкций
Написание AVX-кода с использованием intrinsic-функций не вызовет у вас затруднений, если вы когда-либо использовали MMX или SSE посредством intrinsic’ов. Единственное, о чём нужно позаботиться дополнительно, это вызвать функцию _mm256_zeroupper() в конце подпрограммы (как нетрудно догадаться, эта intrinsic-функция генерирует инструкцию vzeroupper). Например, приведённая выше ассемблерная подпрограмма vec4_dot_avx может быть переписана на intrinsic’ах так:
double vec4_dot_avx( double a[4], double b[4] ) <
// mmA = a
const __m256d mmA = _mm256_loadu_pd( a );
// mmB = b
const __m256d mmB = _mm256_loadu_pd( b );
// mmAB = ( a3 * b3, a2 * b2, a1 * b1, a0 * b0 )
const __m256d mmAB = _mm256_mul_pd( mmA, mmB );
// mmABHigh = ( +0.0, +0.0, a3 * b3, a2 * b2 )
const __m256d mmABHigh = _mm256_permute2f128_pd( mmAB, mmAB, 0x81 );
// mmSubSum = ( +0.0, +0.0, a1 * b1 + a3 * b3, a0 * b0 + a2 * b2 )
const __m128d mmSubSum = _mm_add_pd(
_mm256_castpd256_pd128( mmAB ),
_mm256_castpd256_pd128( mmABHigh )
);
// mmSum = ( +0.0, +0.0, +0.0, a0 * b0 + a1 * b1 + a2 * b2 + a3 * b3 )
const __m128d mmSum = _mm_hadd_pd( mmSubSum, _mm_setzero_pd() );
const double result = _mm_cvtsd_f64( mmSum );
_mm256_zeroupper();
return result;
>
Тестирование AVX кода
Если вы используете набор инструкций AVX посредством intrinsic-функций, то, кроме запуска этого кода под эмулятором SDE, у вас есть ещё одна возможность — использовать специальный заголовочный файл, эмулирующий 256-битные AVX intrinsic-функции через intrinsic-функции SSE1-SSE4.2. В этом случае у вас получится исполняемый файл, который можно запустить на процессорах Nehalem и Westmere, что, конечно, быстрее эмулятора. Однако учтите, что таким методом не получиться обнаружить ошибки генерации AVX-кода компилятором (а они вполне могут быть).
Оценка производительности AVX кода
Использование IACA для анализа производительности AVX кода, созданного C/C++ компилятором из intrinsic-функций почти ничем не отличается от анализа ассемблерного кода. В дистрибутиве IACA можно найти заголовочный файл iacaMarks.h, в котором описаны макросы-маркеры IACA_START и IACA_END. Ими нужно пометить анализируемые участки кода. В коде подпрограммы маркер IACA_END должен находиться до оператора return, иначе компилятор «соптимизирует», выкинув код маркера. Макросы IACA_START/IACA_END используют inline-ассемблер, который не поддерживается Microsoft C/C++ Compiler для Windows x64, поэтому если для него нужно использовать специальные варианты макросов — IACA_VC64_START и IACA_VC64_END.
Заключение
В этой статье было продемонстрировано, как разрабатывать программы с использованием набора инструкций AVX. Надеюсь, что это знание поможет вам радовать своих пользователей программами, которые используют возможности компьютера на все сто процентов!
tensorflow и процессор без AVX

Oct 5, 2019 · 2 min read
Дефолтный пакет tensorflow-gpu собран с инструкциями AVX. То есть, после установки при помощи ‘pip install tensorflow-gpu’ в системе со старым процессором, который про эти инструкции ничего не знает, попытка импорта будет заканчиваться ошибкой:
Illegal instruction (core dumped)
flags : fpu vme de pse tsc msr pae mce cx8 a pic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm sse4_1 sse4_2 popcnt lahf_lm pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid dtherm ida flush_l1d
Как видите, AVX среди них нет.
Единственный способ заставить tf работать на таком процессоре — собрать пакет самостоятельно из исходников. Инструкция на официальном сайте подробно описывает, что потребуется предварительно установить и как правильно запускать сборку, поэтому повторять её нет смысла. Однако, стоит уточнить, что bazel должен быть версии не выше 0.26.1, о чём в инструкции на сайте не сказано, но указано в файле configure.py :
нужно указать флаги:
Затем запустить компиляцию и запастись терпением, потому что на старом процессоре она идёт чудовищно долго. У меня этот процесс занял около восьми часов.
Собранный с этими флагами пакет прекрасно подгружается и работает:



