Секреты observability. Часть 2: алерты

Фото Ricardo Gomez Angel, Unsplash.com
Используем метрики для отправки уведомлений через Slack
В предыдущей статье мы задеплоили оператор Prometheus с помощью helm-чарта и на примере набора сервисов увидели, как можно собирать метрики через prom-client и экспортеры. Как вы помните, цель observability (наблюдаемости) — узнать статус системы, поэтому нужные люди должны получать уведомления, когда значения метрик выходят за установленные пределы. Для этого надо настроить алерты.
Система алертов в Prometheus состоит из двух частей. В самом Prometheus мы создаем правила алертов, которые определяют условие для срабатывания алертов. Когда алерты срабатывают, Prometheus отправляет их в AlertManager, который может их подавлять, объединять или отправлять на разные платформы.
В этой статье мы создадим несколько правил алертов и отправим уведомления на их основе через Slack. Все ресурсы, которые мы используем в этой статье, можно скачать из репозитория.
Правила алертов
Чтобы создать правило алертов с помощью оператора Prometheus, используем кастомный ресурс PrometheusRule. В PrometheusRule нужно указать следующее:
Groups: коллекция алертов, которые оцениваются последовательно.
Rules: имя, условие срабатывания, период ожидания, метки и аннотации с дополнительной информацией.
Условное выражение алерта основано на выражениях Prometheus. Можно использовать Prometheus expression builder, чтобы проверить условие, прежде чем создавать его. В следующем примере у нас есть группа правил database.rules с одним правилом, которое срабатывает, когда метрика mysql_up отсутствует минимум 1 минуту.

Алерт Prometheus MysqlDown
Чтобы протестировать это правило, уменьшаем количество реплик деплоя MySQL:
Где-то через минуту сработает алерт:
Сработавший алерт Prometheus MysqlDown
Нам не придется создавать все самим — в helm-чарте Kube Prometheus уже есть много полезных алертов для метрик Kubernetes. На основе этих алертов можно создавать собственные.
Что происходит, когда в системе возникает серьезный сбой? Приложения отказывают одно за другим, а команда получает вал уведомлений. Чтобы этого избежать, можно использовать AlertManager, который группирует похожие алерты в одно уведомление.
Посмотрим, как это работает, создав простой алерт, который срабатывает, если у деплоя остается меньше двух реплик контейнера. Но сначала настроим Slack.
Подготовка Slack
Давайте подготовимся к тому, чтобы отправлять все алерты в Slack. Для начала создадим канал Slack.
Окно создания канала в Slack
Создаем приложение в рабочем пространстве. Включаем Incoming Webhooks (входящие вебхуки) для приложения и добавляем новый вебхук в рабочее пространство. Скопируем URL вебхука — он понадобится позже.
Включение входящих вебхуков в Slack
Настройка AlertManager
Чтобы настроить AlertManager, нужно создать кастомный ресурс с именем AlertmanagerConfig. Для этого мы должны настроить хотя бы один receiver (платформу, которая будет принимать сообщения) и маршрут ко всем receiver-ам.
Для маршрута нужно указать несколько параметров группирования:
У Receiver-а Slack есть несколько параметров (см. здесь).
В следующем коде все алерты с одинаковым именем, сработавшие за 30 секунд, будут объединены в одно уведомление Slack.
Переходим на страницу статуса AlertManager и видим все настроенные маршруты. Маршрут, который мы настроили, изменился — у него появилось другое имя и параметр match. Параметр match указывает метки, которые нужны алерту, чтобы его можно было отправить в receiver. По умолчанию каждый настроенный маршрут будет изменен — в него будет добавлена метка неймспейса в параметре match, даже если мы включили другие метки.
Чтобы проверить, что алерт будет направлен в нужный receiver, используем routing tree editor. Скопируем конфигурацию AlertManager со страницы статуса и протестируем метки алертов.
Routing Tree Editor
Шаблоны
Prometheus поддерживает определение шаблонов для уведомлений. С помощью шаблонов мы можем стандартизировать текст уведомлений для всех алертов.
Пример шаблона Prometheus
Ключевое слово define обозначает многоразовый фрагмент кода. В коде три многоразовых фрагмента: __title, alert_title и alert_description.
__title — просматривает сработавшие и разрешенные алерты и выводит имя алерта.
alert_title — выводит статус в верхнем регистре в квадратных скобках, а также число сработавших алертов. Также включает содержимое __title, если сработавший или разрешенный алерт всего один.
alert_description — если алерт всего один, выводит описание и уровень серьезности алерта, а еще ссылку на URL графика в Prometheus. Если алертов несколько, выводит их список.
Чтобы включить файл шаблона в Prometheus с оператором, нужно обновить кастомный ресурс AlertManager. Для этого можно передать кастомные значения в helm-чарт. Раз нам нужно изменить только файлы шаблонов, следующего файла будет достаточно.
Можно обновить деплоймент helm следующей командой:
Тестирование уведомлений
Чтобы получить уведомление Slack, нам нужен алерт. Давайте уменьшим количество реплик MySQL, чтобы получить уведомление по одному алерту:
Переходим в канал Slack, чтобы посмотреть уведомление.
Уведомления Prometheus в Slack
Наконец, нужно протестировать объединение алертов в одно уведомление.
Уменьшим количество реплик Node.js:
Через пару минут увеличим:
Возвращаемся в Slack и сравниваем результаты.
Объединенные алерты Prometheus в Slack
Как видите, алерты объединены в одно уведомление. В этом случае они входят в одну группу, потому что у них одинаковое имя. Конфигурацию группы можно изменить, добавив дополнительные метки.
Алерты с одинаковым именем
Заключение
Уведомления — это удобный способ сообщить команде о том, что происходит в системе. Используйте шаблоны, чтобы повысить точность сообщений — это позволит быстрее решать проблемы. Не забывайте объединять алерты, чтобы не устать от уведомлений.
10 лет on-call. Чему мы научились? (обзор и видео доклада)
Осенью прошлого года на конференции DevOops 2019 прозвучал доклад «10 лет on-call. Чему мы научились?». В нём рассказывается о том, почему мы отказались от внутреннего «акселератора» по развитию дежурных до DevOps-инженеров, как эволюционировала наша служба технической поддержки и система обработки инцидентов в целом.

63 минуты, гораздо информативнее статьи) и основную выжимку из него в текстовом виде. Поехали!
Введение
Начнём с определения той области, о которой пойдёт речь. Есть множество способов мониторить что-либо (на слайде не представлен и 1 % из них). Все они отправляют нечто, что нужно обработать (алерты), причём сделать это по-настоящему качественно (как условный Нео из «Матрицы»):
Доклад о том, какие инструменты нам — компании «Флант», имеющей достаточно специфичный контекст, — пришлось придумать, чтобы приблизиться к возможностям Нео.
80 % выступления посвящено тому, как летят алерты и что мы делаем, чтобы с ними справиться. Остальные 20 % — про культурные и организационные моменты, которые нам пришлось применять за историю существования компании.
Повторюсь, что у нас достаточно специфичный случай: мы берём ответственность за чужую инфраструктуру, переделывая её и отвечая за её доступность. Поэтому обработка инцидентов — один из ключевых вопросов для нас, к которому мы постоянно возвращались на протяжении всей жизни компании.
Предыстория
Что у нас было 10-11 лет назад? В компании работало несколько человек. Все алерты приходили на мой мобильный телефон, я их просматривал и уходил чинить то, что требовало внимания.
В действительности всё было не так плохо, потому что мы не пытались отправлять алерты по любому поводу (вроде закончившегося места на диске). Мониторинг работал для бизнес-показателей высокого уровня: грубо говоря, были cron-скрипты, которые проверяли, что что-то важное для бизнеса точно работает, и отправляли SMS в случае проблем. Система очень примитивная, но на тот момент она устраивала.
Шло время, росло число инцидентов. В какой-то момент я осознал, что страшно просыпаться утром: ведь в телефоне можно увидеть, например, 600 непрочитанных сообщений. Тогда мы решили ситуацию так: «Давайте я не буду это делать один. Давайте все по очереди». В компании было 5-6 человек: когда подобное дежурство происходит раз в неделю, всё уже не так плохо.
Шло время, росло количество проектов и сотрудников. Мы дошли до состояния: «Давайте не будем сами смотреть SMS’ки [именно так мы по-прежнему называли алерты], а попросим делать это кого-нибудь ещё». И сделали первую линию поддержку, хотя ещё тогда понимали, что это неправильно.
К слову, такие изменения в организации требовали и изменений в технике. Когда дежуришь один, всё отправляется в одну точку, а здесь уже требуется возможность определения многих мест и переключения между ними. У нас даже была «мощнейшая» система под названием «Журнал SMS»: в ней были все записи (алерты), которые специальный человек просматривал. Если какие-то из алертов часто появлялись, он звонил дежурному и указывал на эту проблему.
Всё это по-прежнему ужасно, но до какого-то момента решало наши задачи. Когда сотрудников стало около 30, несмотря на наличие выделенной группы L1, ситуация была проблемной с обеих сторон:
Очевидное об алертах
Алерты разделяются на два типа:
Таким образом, у алерта может быть состояние. И обязательно использовать протокол, который понимает такие состояния.
Ещё одна популярная проблема — «мигание» алерта, когда он то загорается, то пропадает. Благодаря тому, что набор лейблов — уникальный идентификатор алерта, мы можем делать дедупликацию, объединяя такие алерты в серии. Каждая серия — группа событий, с которой удобно работать (вместо того, чтобы проводить такое объединение каждый раз мысленно).
Вот как это автоматическое склеивание выглядит у нас в интерфейсе. В верхней части — инцидент, а ниже — набор из алертов (всего их 7, но в экран на скриншоте поместились только 2).
Если у алерта есть статус (горит/не горит), то инциденты уже практически становятся тикетами, у которых есть рабочий процесс. В его основе — триаж (медицинская сортировка) и последующая «неотложка» или «надо делать» (или же просто сразу закрыть). У нас процесс чуть более сложный, но подробно останавливаться на нём не буду:
Ключевая же идея в том, что, если вы начали всерьёз подходить к обработке инцидентов, то каждый инцидент должен стать тикетом, который имеет свой рабочий процесс, соответствующий вашим требованиям и особенностям.
Однако ни одна система тикетов не рассчитана на то, чтобы обеспечить гарантию доставки. Если кто-то завёл тикет, а его увидели не сразу, то ничего страшного, как правило, не произошло. У этих решений попросту нет первичной важности в таком вопросе. А для нас критично, чтобы в течение десятков секунд дежурные на L1 увидели алерт, чтобы в течение минуты подтвердили это (не вникли в него, не приняли решение, но уже увидели, начали им заниматься).
Когда вы меняете исполнителя в тикете, он подтверждает, что согласен с этим изменением? В нашем случае такое подтверждение обязано быть — это как эстафетная палочка, передаваемая между инженерами.
Менее очевидные особенности
Когда мы всё это сделали, жизнь стала сильно лучше: мы перестали что-либо упускать, заметно (раз в 5) выросла пропускная способность в обработке инцидентов.
Однако через 2-3 года мы столкнулись со старой проблемой: наша техподдержка, которая теперь уже состояла из двух линий (L1 и L2), не успевала диагностировать инциденты. Её работа преимущественно сводилась к тому, чтобы либо сразу кому-то звонить об инциденте, либо ожидать, что он «сам пройдёт».
Культурно-организационная проблема, лежащая в основе, никуда не делась. Однако перед тем, как перейти к разным организационным схемам, которые мы успели попробовать, поделюсь ещё несколькими менее очевидными соображениями про технологии для работы с инцидентами.
Слово «инцидент» вызывает эмоции, схожие со словом «пожар». Однако в случае с пожаром всем понятно, что надо взять огнетушитель и тушить до тех пор, пока он не будет полностью ликвидирован, и останавливаться до этого времени недопустимо. С инцидентом же возможен случай, когда он «наполовину потушен»: первые меры были приняты, а дальше от нас ничего не зависит.
Например, сервер с одной из реплик сломался и ему надо заказать новый диск. Диск заказали, а поскольку это лишь одна из реплик, которая может быть недоступна несколько дней, пока диск едет, мы не будем исправлять алерты во всех используемых системах мониторинга — это трудозатратно. В результате, у нас висит инцидент, но каких-либо действий сейчас он не требует.
А представьте себе, что три таких инцидента горят, хотя на самом деле они не горят. Когда появится четвёртый, отношение к нему уже будет такое: «Ещё одна вещь, которая горит… Ну и что?» Чтобы избавиться от подобного психологического эффекта, «полупотушенные» инциденты надо попросту убрать, но сделать это правильно. Я называю это умный игнор, а его идея сводится к операции «отложить инцидент»:
Однако тут есть важный момент: если алерт был отложен, но каких-то ошибок (например, 500-х кодов у страницы веб-приложения) сначала было мало (0,1%), а потом стало много (20%), эту ситуацию можно упустить. Поэтому мы делаем разные уровни severity у алертов на разную частоту ошибок: если уровень меняется, такое изменение считается существенным, поэтому отложенный алерт снова всплывает и требует принятия решения.
В мониторинге в целом есть сложная проблема: мониторинг мониторинга. Правильный подход в его реализации по сути сводится к тому, что каждый источник алертов должен постоянно отправлять специальные сообщения «Я всё ещё жив», а система, принимающая алерты, — отслеживать наличие таких сообщений и поднимать тревогу в случае их отсутствия. Ещё одна полезная необходимость здесь — это отслеживать все алерты, отправляемые в некорректном формате (иначе они будут потеряны, а вы об этом даже не узнаете).
Следующая проблема — поиск. Поскольку всё сделано на лейблах, сходу получился понятный язык (MQL) для поиска алертов и инцидентов:
Наличие языка запросов принесло и другое важное удобство. С помощью маршрутизации алертов инженер, выполняющий какие-то временные работы, может в той же единой системе зафиксировать себя как ответственное лицо для конкретных алертов. Так дежурный будет сразу знать, к кому обращаться, если возникает проблема, попадающая под определённые условия:
Когда обработкой алертов занимаются много сотрудников, вам потребуется очень много времени, чтобы узнать о каком-либо надоедливом алерте, что случается каждый день, но один раз. Решению этой проблемы способствует горячая аналитика. Возле каждого инцидента мы показываем другие «подобные». Можно увидеть их количество, увидеть их полный список, кем они обрабатывались, когда и за какое время. А после этого поднять проблему на очередной встрече:
Организационная структура и зоны ответственности
Теперь я расскажу о вариантах организации работы, через которые мы прошли:
Но начать стоит с объяснения, почему L1 в нашем случае не работает в принципе. У меня есть несколько связанных примеров:
В контексте алертов: инженер понимает, что этот алерт куда-то там придёт (к дежурному), там с ним разберутся, поэтому нормально можно не делать. Мы решим проблему людьми (дежурными). А со временем, когда таких алертов становится всё больше, случается уже описанная проблема: дежурные на L1 страдают, что вообще не успевают ничего делать из-за количества алертов, а инженеры тоже недовольны: им казалось, что на L1 ничего не делают.
Наша попытка исправить это была такова:
Однако закончилось всё плачевно. На L1 и L2 люди исполняли свои обязанности с чувством, что это временно, а в целом они такой работой заниматься не хотят (потому что хотят быть инженерами). Итог: ни первая, ни вторая цели не были достигнуты.
К чему мы пришли? Всех дежурных убрали, а на обработке инцидентов работают люди, которые отвечают только за две функции: 1) эскалация, 2) коммуникация. Они ничего не знают о том, что это за инцидент и что с ним (технически) делать. А сами проблемы разбирают те же инженеры из команд, которые создавали алерты и отвечают за соответствующую инфраструктуру.
Документация
Вернёмся к общей схеме:
В компаниях, где часто что-то меняется, весьма актуальна ещё одна проблема: документация. У вас 10 человек, которые дежурят по очереди. Пришёл очередной алерт: кто его сделал и чего от меня здесь хотят? И каждое изменение в ответе на этот вопрос нужно доносить до всех дежурных. Очевидное решение: документирование всего, что не входит в сам алерт, в отдельной системе, где с помощью уже упомянутого языка запросов (MQL) описаны алерты, к которым инструкции относятся.
Эта документация показывается при открытии алерта, у неё есть кнопка «Прочитал(а)». Если при следующем срабатывании алерта что-то в документации изменилось, дежурному будет показан соответствующий diff.
Что мониторить?
Остался главный вопрос, о котором говорили уже миллионы раз… Вот три основных варианта ответов:
Если мы используем внутренние показатели, у нас появляется очень много «шума». А если мы смотрим на показатели доступности или бизнес-метрики, то узнаём об аварии только тогда, когда она уже произошла. Эта дилемма — в основе всего вопроса, что же мониторить. Как мы попытались ответить на такой вопрос (для себя).
У каждого есть своё представление том, чему соответствуют разные уровни severity и priority, и каждый по-своему прав:
Мы пришли к тому, что определяем severity в двух координатах (влияние и вероятность):
Например, закончилось место на диске:
В контексте необходимости отделения окружения мы пошли дальше и ввели для себя уровни обслуживания (service level). При поступлении алерта требуется ответить на вопрос: надо ли нам его обрабатывать? Если да, то как срочно?
Отправляя множество алертов, мы на них по сути вручную не реагируем — спасибо автоматизации разбора. Часть алертов не требует быстрого вмешательства: о них мы вспомним во время ретроспективы. Другая часть собирается в группы, которые обрабатываются в обычное рабочее время — пачками, что гораздо удобнее. В результате, алертов, требующих обработки сразу, остаётся не так много:
Когда вы создаёте алерт, то указываете некое пороговое значение и период. Например: «если у меня load average больше такого порога на протяжении такого периода». С этим периодом есть дилемма. С одной стороны, 20 минут для того же load average — много, потому что всё уже умрёт. С другой стороны — о всплесках в 2 минуты можно ничего не узнать, а если поставить порог в 1 минуту, то дежурного завалит сообщениями.
Мы для себя решили ставить периоды очень маленькими и всегда слать алерты в систему. Но алерты приходят в статусе «pending» и для них определяется то время, которое они должны гореть, чтобы стать «настоящими». Таким образом, мы перенесли pending из источников мониторинга в центральную систему. Благодаря этому, если алерт так и не стал «настоящим», он себя не проявил для дежурного, однако в системе остался — его можно увидеть при ретроспективе.
С появлением Kubernetes стали актуальными два момента:
Итоги
Немного статистики, показывающей, к чему мы пришли:
На графике алерты — это не отдельные алерты, а их серии. События — когда что-то сломалось, починилось, сломалось, починилось… Благодаря имеющейся автоматике, огромное количество сообщений (миллионы в день!) сокращается до такого числа, которое по-прежнему реально обрабатывать каждый день.
Вам это нужно?
Раскрутка канала на Twitch. Основные настройки, виджеты и помощники (Часть 5)
Доброго времени суток. В прошлой части мы затронули аспект общей медийности киберспортивной организации. Сегодня же хотелось бы более детально углубиться в данную тематику и добавить больше конкретики. Так как Youtube канал Apei Gaming все еще находится в стадии разработки и анализа нишевых секторов, которые впоследствии можно занять, мы обратимся к разбору площадки Twitch.
Оговорюсь сразу, что данный блог пришлось разбить на две части, так как материал получился достаточно объемным, и в случае написания одним блоком, воспринимался бы достаточно сложно. Поэтому в этой части мы поговорим о самых базовых настройках, оставив более сложные и узкоспециализированные «фишки» на вторую часть “для продвинутых” юзеров.

На организацию первой трансляции, как я и говорил, у нас ушло около двух недель. Сам принцип запуска трансляций очень простой, первоначальная настройка занимает не более 20 мин, но амбиции и цели организации Apei Gaming находятся гораздо выше, именно поэтому на всю подготовку ушло столько времени. Сейчас, уже имея определенный опыт в этой области, могу с уверенностью заявить, что это было излишним и можно было начинать “стримить” раньше, имея к сегодняшнему дню на 100-200 подписчиков больше. Но давайте обо всем по порядку.
Аудитория данного портала достаточно обширна, поэтому считаю нужным начать с самых азов и хотя бы кратко описать процесс настройки всех узлов и программ, дабы не возвращаться к этому вопросу в будущем. Одна из причин такой долгой подготовки является отсутствие достаточного количества информации в сети. Честно говоря меня это немного шокировало. На Twitch ежедневно ведут трансляции десятки тысяч стримеров и при этом найти действительно полезную информацию очень проблематично.
Перечитав огромное количество как русской, так и зарубежной литературы, пересмотрев кучу обучающих видеоуроков, удалось собрать в голове алгоритмы подключения сервисов, оптимальных начальных настроек и получить хоть какое-то понимание, как организовать достойный канал и не упасть “лицом в грязь” на первой же трансляции. Некоторые же выводы и заметки пришли уже по ходу первых прямых эфиров, и описание оных я не нашел нигде.
Вообще, по сути, “стримить” можно начать и с простенького ноутбука, но сейчас мы говорим о качественных прямых трансляциях и об общих тенденциях мирового “стриминга” в целом. Ведение канала на Twitch это такая же работа, как и все остальные, и “нахрапом” стать популярным не получится. Нужно иметь определенную харизму и какую-то идею, отличную от остальных, чтобы выделяться из “серой” массы.
Для качественного “стрима” вам понадобится:
Если вышеперечисленная аппаратная часть в той или иной конфигурации у вас имеется, можно переходить к настройке “стриминговой” программы OBS (Open Broadcaster Software). Подобных программ кодеров для “стриминга” видео достаточно много, но мы остановимся на OBS, как на самой простой, популярной и абсолютно бесплатной.
Стандарт транcляций на Twitch это разрешение 720р, так как все устройства нашего времени поддерживают это качество, и оно, в данный момент, является оптимальным выбором. Так же стоит учитывать трансляции с большим разрешением 1080р, но в этом случае это может доставить проблемы некоторым из ваших зрителей.
Другая очень важная тема — поток отдачи (bitrate). На 720р стандарт “битрейта” — 2000. На 1080р лучше повысить его до значения 3000-3200. Так же стоит обратить внимание на варианты обработки, всего их 2 вида — процессорно x264 CPU и Nvenc (процессор + видеокарта Nvidea). В процессорном типе настройка будет зависеть от мощности вашего компьютера. Если «железо» мощное, то можно выставить более низкий параметр и качество возрастёт за счёт производительности и картинка будет более хорошей и качественной, нежели в варианте с Nvenc (опять же есть возможность добиться и обратного эффекта, но тогда нужно будет серьезно “повозиться” с настройками для каждого устройства).
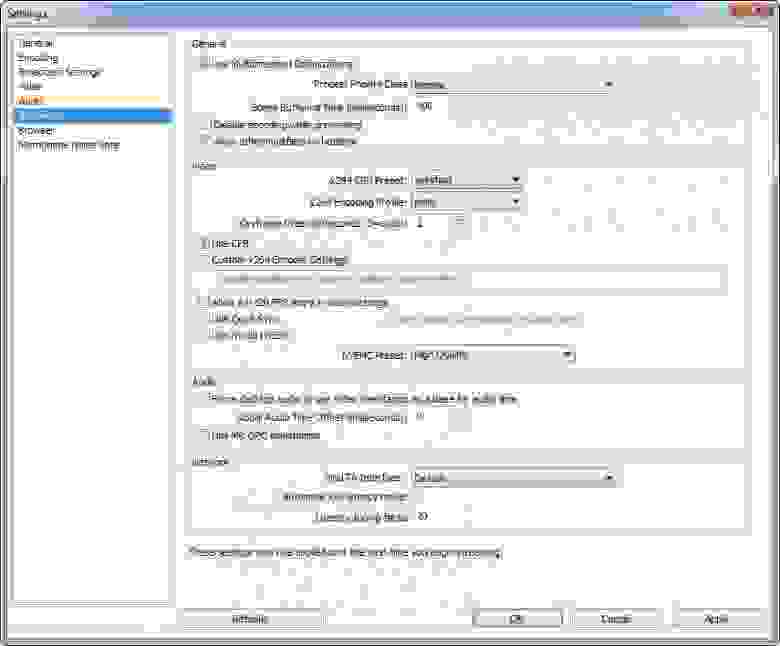
Вся эта информация в том или ином виде уже присутствует в интернете, но дальше начальных настроек блоггеры обычно не уходят. Причиной может служить то, что многие после первого “стрима” (с кричащей цифрой 0 в списке “онлайн зрителей”), благополучно “забивают” на идею порабощения интернет пространства.
Каждый канал и каждая трансляция на Twitch должна строиться, в идеале, по канонам ТВ шоу. Человеку, смотрящему видео в прямом эфире, должно быть постоянно интересно, и ради этого он будет готов возвращаться на “стрим” снова и снова, желая получить новую порцию полезных знаний, “фана” или каких-то бонусов от стримера. Поэтому ни один “стрим”, как я считаю, не может обойтись без специальных сервисов и ботов, которые могут разнообразить жизнь вашего канала, и не дать зрителям заскучать после 1-2 часов просмотра.

Первый, так сказать “must have” бот, который подключен практически к любому каналу это Twitch Alerts. В нем нас в основном интересуют виджеты: Alert Box, Chat Box и Event List.
Alert Box — я думаю всем хорошо известен — это виджет, который запускается после того как на ваш канал подпишется новый человек. Может быть как статичной картинкой, так и *.gif изображением, добавляющим немного динамики в происходящее. Подобных “алертов” можно сделать сколько угодно штук, выставив частоту появления, размеры и типы текста, длину проигрывание как самого виджета, так и музыки его сопровождающей. На нашем канале мы настроили 9 разных виджетов, чтобы разнообразить события на “стриме” и подтолкнуть “фоловеров” подписываться на канал, чтобы увидеть какой же будет дальше виджет.
Сhat Box — дополнительный виджет чата, который вы можете поместить на стрим. Он выполняет несколько ролей:
Далее мы переходим к боту Donation Alerts (http://www.donationalerts.ru/), куда же без него. Как следует из названия, данный портал позволяет зрителям жертвовать деньги стримеру, помогая ему собрать средства на новое железо, машину, квартиру или просто так из чувства сопереживания, так как для профессиональных блоггеров, “стримы” являются основной статьей доходов, и делая качественный контент для своего зрителя, им бы хотелось получать за этого какие-то дивиденды. К слову так же хотелось бы сказать, что в первом боте (http://www.twitchalerts.com/) тоже есть виджет донатов, но к сожалению к нему можно подключить только кошелек PayPal, который не имеет широкого распространения среди “Ру” комьюнити. Тут же мы получаем работу со всем уже привычным QIWI или Webmoney в удобной для СНГ валюте.
При настройке виджета стоит так же обратить внимание на несколько деталей. Во вкладе “Оповещения” мы настраиваем анимацию и звук “алерта”. Так как донаты по своей сути имеют для блоггера определяющие значение, то и подходить к выбору заставки следует предельно внимательно. Основной целью является выделить человека, который что-то пожертвовал (даже 1 рубль), сделав заставку или необычной, или “пафосной”, или располагающей. Так же у мецената есть возможность написать любой текст в сообщении к прилагаемой сумме. В этой части кроется еще одна маркетинговая “фишка” — синтез речи. Цель данной функции, дать возможность жертвующему человеку не только разместить текст, но и зачитать его человеческим голосом во всеуслышание. Для этой опции возможно установить другую сумму доната, чем активно и пользуются многие “стримеры”, вынуждая закидывать не 1 руб., а допустим, 15 руб., чтобы сообщение зачиталось вслух, и на него обратил внимание как сам ведущий, так и зрители стрима.
Следующий полезный виджет в рамках данного портала — внитристримовая статистика. Здесь мы можем настроить выведение как общего списка “топ” донатеров, так и визуально показать последнего из них. Казалось бы мелочь? Отнюдь. Подобные баннеры стоят у 100% “стримеров”, выказывая уважения к своим постоянным фанатам. Так же у особо богатых зрителей всегда есть возможность “застолбить” место в зале славы определенного “стримера” и высвечиваться в “топ” листе на каждом из его “стримов”. В таком ключе по сути можно и рекламировать услуги и товары, зарегистрировав имя “Печенье Молочное”, можно перевести несколько десятков тысяч рублей на счет стримера и гарантированно застолбить себе на долгий срок рекламное место. Проблема только в том, что все это делается на добровольных началах и владелец канала может в любой момент выключить виджет или отключить конкретно ваш донат, поэтому, я думаю, этот способ рекламы не стал достаточно популярным.
Последним, но не менее важным является раздел “сбор средств”. В нем вы можете поставить определенную цель и собирать деньги на определенные материальные, движимые или недвижимые блага. Чисто психологически человеку гораздо проще растаться с деньгами, когда он знает, что они пойдут на улучшение качества стрима или жизненных условий любимого блоггера. Поэтому данная “фишка” достаточно успешно работает у всех крупных “стримеров”.
На этом можно считать настройку “для новичка” завершенной. В следующей части я расскажу о менее известных и более сложных ботах и выскажу свои умозаключения касательно самой раскрутки канала на Twitch. Так же хочу поблагодарить стримера организации Irokez за помощь в написании этого гайда.



