Что такое base64 и зачем он нужен в веб разработке?
Зачем это нужно?
Так исторически сложилось, что многие форматы передачи и хранения данных используют текст вместо бинарных кодов (html, url схемы, xml, email… и тп). Но что, если формат передачи данных текстовый, а передать необходимо бинарные данные (отдельно либо вместе с текстовыми данными). Вот тут на помощь и приходит base64.
Типовое применение в веб разработке
data: URL и base64 data: URL — это определённая стандартом RFC 2397 схема, которая позволяет включать небольшие элементы данных в строку URL, как если бы они были ссылкой на внешний ресурс. Согласно RFC «data: URI» – это фактически «data: URL» (URL — унифицированный указатель ресурса), хотя реально он ни на что не указывает.
Формат data: URL следующий:
Несколько типовых применений на примерах.
Пример использования в HTML:
(Переносы на новую строку осуществлены для облегчения восприятия. Их не должно быть) Все, что следует за data:image/png;base64, – это base64 код небольшого png изображения (красная точка 10×10 px). Этот пример будет выглядеть так –
Пример использования в CSS:
Получение бинарных данных из canvas в виде текстового base64 представления
12 comments on “ Что такое base64 и зачем он нужен в веб разработке? ”
Так а чем лучше такой подход для изображений? Не раскрыта тема, зачем надо такое использовать.
Хорошее замечание 😉 попробуем разобраться.
Такой подход лучше только в тех случаях, когда в зависимости от задачи Вам удобно:
Включение картинки непосредственно в CSS в виде base64, позволит браузеру отобразить ее при первой отрисовке страницы, не делая дополнительных запросов к серверу. Это особенно заметно в медленных мобильных браузерах и при медленном соединении.
Так же можно поступить с подгружаемыми шрифтами. Включая их в CSS в виде base64, вы гарантируете, что кастомный шрифт уже будет правильно отображен во время первой отрисовки страницы, а не спустя некоторое время (которое обычно браузер тратит на подгрузку внешнего шрифта)
Я не советую использовать этот подход везде, но в зависимости от задачи и требований к приложению, иногда такой подход может быть лучше. В целом.. Если пункты a) и b) не критичны для Ваших проектов, то включать изображения в css/html в виде base64 не стоит 🙂
Другие области применения в веб
Отличная статья, спасибо. Особенно актуально для email-писем.
Можно заметить что при малых размерах изображений css, применяя gzip сжатие для файла стилей(и отдачу сжатого файла с сервера) получаем не только устранение запросов но и сокращение объёма(20%-25%).
Мануал по методу кодирования base 16/32/64.
История появления кодировки.
Кодировка base берет свое начало еще с тех времен, когда не было определено сколько бит должно содержаться в одном байте. Сейчас всем известно, что в одном байте содержится 8 бит и с помощью него можно закодировать 256 различных значений, но так было не всегда.
Раньше были популярны кодировки, содержащие 6, 7 или 8 бит в байте. Таким образом, 6 бит позвояло закодировать в одном байте 64 различных значения, а 7-ми битная кодировка 128 значений. Казалось бы, что этого достаточно для того, чтобы закодировать буквенно-цифровой алфавит. Но вскоре была принята кодировка, содержащая 8 бит в одном байте.
Такая кодировка привнесла много проблем. В первую очередь, эти проблемы были связаны с оборудованием, которое уже работало на других кодировках, где байт содержал 6 или 7 бит. Но помимо этого была проблема обрезания 8-го бита в системах электронной почты, т.к. весь сфот был заточен под 7-ми или 6-ти битную кодировку. Как пример, 7-ми битная кодировка могла спокойно обнулить каждый 8-ой бит, что приводило к потери данных.
Тут на помощь пришел base 64. Идея base64 проста — обратимое кодирование, с возможностью восстановления, которое переводит все символы восьмибитной кодовой таблицы в символы, гарантированно сохраняющиеся при передаче данных в любых сетях и между любыми устройствами. В основе алгоритма лежит сведение трех восьмерок битов (24) к четырем шестеркам (тоже 24) и представление этих шестерок в виде символов ASCII. Таким образом получается обратимое шифрование, единственным недостатком которого будет увеличивающийся при кодировании размер — в соотношении 4:3.
Ниже приведена схема смещения битов в base 64
Пример:
Возьмем русский текст «АБВГД». В двоичной форме в кодировке Windows-1251 мы получим 5 байтов: 11000000 11000001 11000010
11000011 11000100 (00000000) — лишний нулевой байт нужен, чтобы общее число бит делилось на 6
Разделим эти биты на группы по 6: 110000 001100 000111 000010
110000 111100 010000 000000
Берем массив символов «ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/» и получившиеся числа переводим в эти символы, используя их, как индексы массива, получаем «wMHCw8Q». Остается только добавить в конце один символ «=», как указание на один лишний нулевой байт, который мы добавляли на первом шаге и получить окончательный результат: «АБВГД»: base64 = «wMHCw8Q=» Возможно и обратное преобразование.
Base 16
Base 32
Base 32 использует 32 символа: A-Z (или a-z), 2-7. Может содержать в конце кодированной последовательности несколько спецсимволов (по аналогии с base64). В данном алгоритме преобразования нам необходимо будет разделять двоичные значения на группы по 5 бит.
Основные отличия кодировок
Base64
Позволяет кодировать информацию, представленную набором байтов, используя всего 64 символа: A-Z, a-z, 0-9, /, +. В конце кодированной последовательности может содержаться несколько спецсимволов (обычно “=”).
Преимущества: Позволяет представить последовательность любых байтов в печатных символах. В сравнении с другими Base-кодировками дает результат, который составляет только 133.(3)% от длины исходных данных.
Недостатки: Регистрозависимая кодировка.
Base32
Использует только 32 символа: A-Z (или a-z), 2-7. Может содержать в конце кодированной последовательности несколько спецсимволов (по аналогии с base64).
Преимущества: Последовательность любых байтов переводит в печатные символы. Регистронезависимая кодировка. Не используются цифры, слишком похожие на буквы (например, 0 похож на О, 1 на l).
Недостатки: Кодированные данные составляют 160% от исходных.
Как закодировать/декодировать base?
В основном в заданиях по ctf вам будет попадаться base 64. Его легко определить, т.к. на конце будет знак «=». Например, мы кодировали строку «АБВГД» в base 64 и у нас получился результат «wMHCw8Q=». Как мы видим, здесь присутсвует знак «=», который говорит нам о том, что строка зашифрована в base 64.
Итак, как же ее декодировать? Все очень просто. Base 16, 32, 64 легко декодировать онлайн-сервисами. Т.е. вбиваете в гугле подобный запрос:»base 64 online decoder» и вам будет выдан большой перечнь ссылок на онлайн декодеры. Берем первый попавшийся, разве что для уточнения стоит воспользоваться сразу несколькимим онлайн декодерами.
Процесс кодирования почти ничем не отличается, разве, что вам нужно вбить в запросе не «decode», а «encrypt». Бывает, что нужно обращать внимание на то, какой кодировкой вы пользуетесь. В русскоязычной версии ОС «Windows» обычно используется кодировка windows-1251.
Практика
Задание 1:
Взгляните на эту строку:
ZmxhZ2lzVzBXdGhpc2lzQkFTRTY0Cg==
На конце мы видим «=», причем двойное, что сразу наводит на мысль, что это base 64. Воспользуемся онлайн-декодером.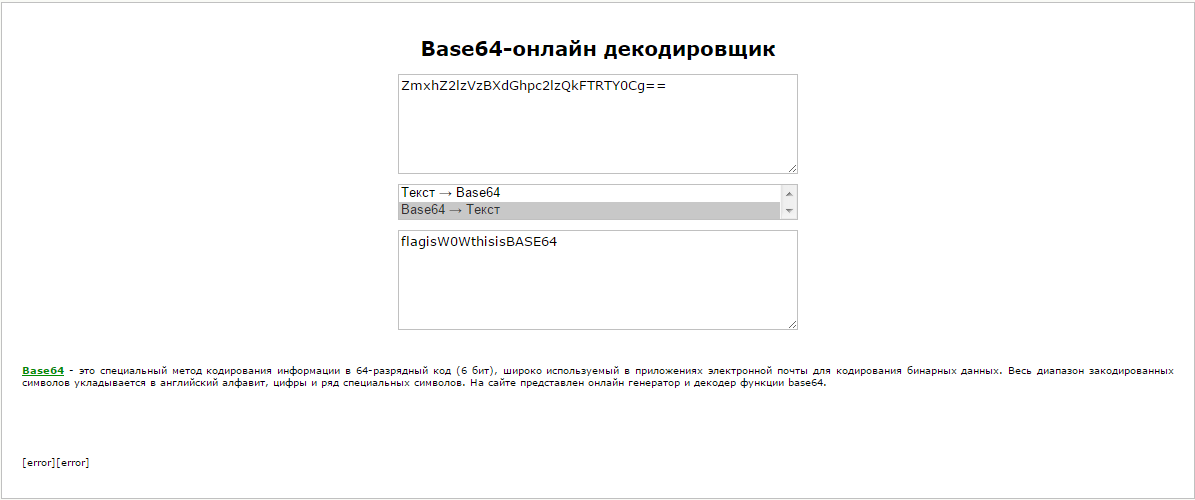
Задание 2:
Посмотрим на эту строку:
MZWGCZ33MJQXGZJTGJ6Q
На конце мы не видим знака «=». На base 16 тоже не похоже, тогда попробуем base 32.
Снова воспользуемся онлайн-декодером.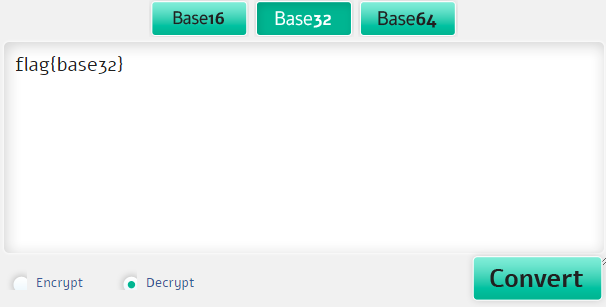
И вот наш флаг: flag
Задание 3:
Была получена такая строка: 666C61677B48656C6C6F2C20576F726C64217D
Здесь нет ни знака «=», алфавит ограниченный. Похоже на base 16 или просто hex.
Как и прежде, пользуемся онлайн-декодером.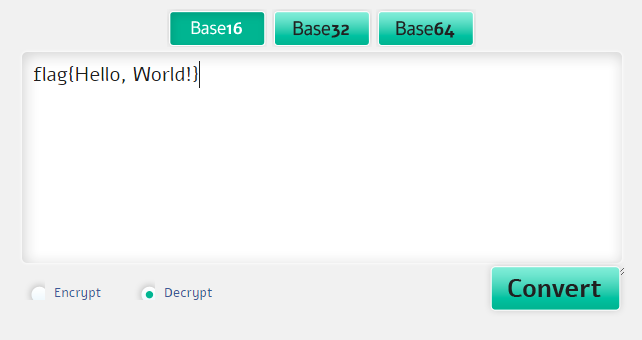
Отлично, у нас есть флаг, но это же задание можно было решить и через hex декодер.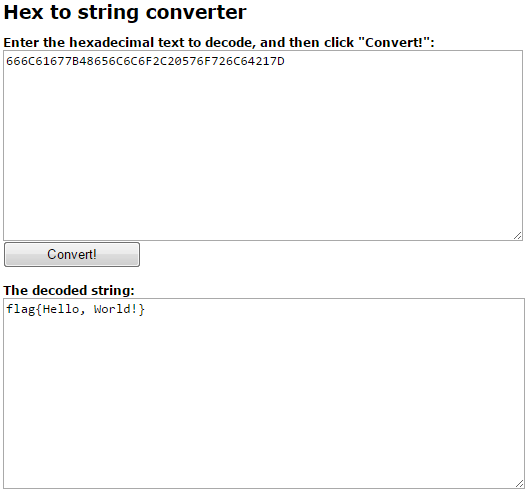
Кодирование и декодирование в формате Base64
Документация
Кодирование Base64 широко используется в случаях, когда требуется перекодировать двоичные данные для передачи по каналу приспособленному для передачи текстовых данных. Это делается с целью защиты двоичных данных от любых возможных повреждений при передаче. Base64 широко используется во многих приложениях, включая электронную почту (MIME), и при сохранении больших объёмов данных в XML.
В языке JavaScript существуют две функции, для кодирования и декодирования данных в/из формат Base64 соответственно:
Функция atob() декодирует Base64-кодированную строку. В противоположность ей, функция btoa() создаёт Base64 кодированную ASCII строку из «строки» бинарных данных.
Tools
Related Topics
The «Unicode Problem»
Since DOMString s are 16-bit-encoded strings, in most browsers calling window.btoa on a Unicode string will cause a Character Out Of Range exception if a character exceeds the range of a 8-bit byte (0x00
0xFF). There are two possible methods to solve this problem:
Here are the two possible methods.
Solution #1 – escaping the string before encoding it
To decode the Base64-encoded value back into a String:
Unibabel implements common conversions using this strategy.
Solution #2 – rewrite the DOMs atob() and btoa() using JavaScript’s TypedArray s and UTF-8
Use a TextEncoder polyfill such as TextEncoding (also includes legacy windows, mac, and ISO encodings), TextEncoderLite, combined with a Buffer and a Base64 implementation such as base64-js.
When a native TextEncoder implementation is not available, the most light-weight solution would be to use TextEncoderLite with base64-js. Use the browser implementation when you can.
The following function implements such a strategy. It assumes base64-js imported as
Base64
Base64 буквально означает — позиционная система счисления с основанием 64. Здесь 64 — это наибольшая степень двойки (2 6 ), которая может быть представлена с использованием печатных символов ASCII. Эта система широко используется в электронной почте для представления бинарных файлов в тексте письма (транспортное кодирование). Все широко известные варианты, известные под названием Base64, используют символы A-Z, a-z и 0-9, что составляет 62 знака, для недостающих двух знаков в разных системах используются различные символы.
Содержание
Схема соответствия «символ ↔ значение» в Base64
| Символ | Значение | Символ | Значение | Символ | Значение | Символ | Значение | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 8 | 16 | 10 | 8 | 16 | 10 | 8 | 16 | 10 | 8 | 16 | ||||
| A | 0 | 00 | 00 | Q | 16 | 20 | 10 | g | 32 | 40 | 20 | w | 48 | 60 | 30 |
| B | 1 | 01 | 01 | R | 17 | 21 | 11 | h | 33 | 41 | 21 | x | 49 | 61 | 31 |
| C | 2 | 02 | 02 | S | 18 | 22 | 12 | i | 34 | 42 | 22 | y | 50 | 62 | 32 |
| D | 3 | 03 | 03 | T | 19 | 23 | 13 | j | 35 | 43 | 23 | z | 51 | 63 | 33 |
| E | 4 | 04 | 04 | U | 20 | 24 | 14 | k | 36 | 44 | 24 | 0 | 52 | 64 | 34 |
| F | 5 | 05 | 05 | V | 21 | 25 | 15 | l | 37 | 45 | 25 | 1 | 53 | 65 | 35 |
| G | 6 | 06 | 06 | W | 22 | 26 | 16 | m | 38 | 46 | 26 | 2 | 54 | 66 | 36 |
| H | 7 | 07 | 07 | X | 23 | 27 | 17 | n | 39 | 47 | 27 | 3 | 55 | 67 | 37 |
| I | 8 | 10 | 08 | Y | 24 | 30 | 18 | o | 40 | 50 | 28 | 4 | 56 | 70 | 38 |
| J | 9 | 11 | 09 | Z | 25 | 31 | 19 | p | 41 | 51 | 29 | 5 | 57 | 71 | 39 |
| K | 10 | 12 | 0A | a | 26 | 32 | 1A | q | 42 | 52 | 2A | 6 | 58 | 72 | 3A |
| L | 11 | 13 | 0B | b | 27 | 33 | 1B | r | 43 | 53 | 2B | 7 | 59 | 73 | 3B |
| M | 12 | 14 | 0C | c | 28 | 34 | 1C | s | 44 | 54 | 2C | 8 | 60 | 74 | 3C |
| N | 13 | 15 | 0D | d | 29 | 35 | 1D | t | 45 | 55 | 2D | 9 | 61 | 75 | 3D |
| O | 14 | 16 | 0E | e | 30 | 36 | 1E | u | 46 | 56 | 2E | + | 62 | 76 | 3E |
| P | 15 | 17 | 0F | f | 31 | 37 | 1F | v | 47 | 57 | 2F | / | 63 | 77 | 3F |
В формате электронной почты MIME base64 — это схема, по которой произвольная последовательность байт преобразуется в последовательность печатных ASCII символов. Это определяет MIME как транспортное кодирование содержимого для использования в электронной почте. Используются только символы латинского алфавита в верхнем и нижнем регистре — символы (A—Z, a—z), цифры (0—9), и символы «+» и «/», с символом «=» в качестве специального кода суффикса.
Полная спецификация этой формы base64 содержится в RFC 1421 и RFC 2045. Эта схема используется для кодирования последовательности октетов (байт). Это соответствует определению файлов почти во всех системах. Результирующие закодированные по base64 данные имеют длину, большую оригинальной в соотношении 4:3, и напоминают по виду случайные символы.
Для того, чтобы преобразовать данные в base64, первый байт помещается в самые старшие восемь бит 24-битного буфера, следующий в средние восемь и третий в младшие значащие восемь бит. Если кодируется менее чем три байта, то соответствующие биты буфера устанавливаются в ноль. Далее каждые шесть бит буфера, начиная с самых старших, используются как индексы строки «ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/» и её символы, на которые указывают индексы, помещаются в выходную строку. Если кодируются только один или два байта, в результате получаются только первые два или три символа строки, а выходная строка дополняется двумя или одним символами «=». Это предотвращает добавление дополнительных битов к восстановленным данным. Процесс повторяется над оставшимися входными данными.
Например, исторический слоган Википедии,
Man is distinguished, not only by his reason, but by this singular passion from other animals, which is a lust of the mind, that by a perseverance of delight in the continued and indefatigable generation of knowledge, exceeds the short vehemence of any carnal pleasure.
будучи закодированным в base64 выглядит следующим образом:
UTF-7 представляет собой систему, называемую Изменённый Base64. Эта схема кодирования данных используется для того, чтобы кодировать UTF-16 как промежуточный формат в UTF-7 в печатных ASCII символах. Этот вариант base64 используется в MIME. UTF-7 предназначен для того, чтобы позволять использовать unicode в e-mail без использования разделения транспортного кодирования содержимого. Главное отличие этого варианта base64 от MIME в том, что символ «=» не используется для дополнения, так как требуется многократное экранирование этого символа. Вместо этого биты октета дополняются нулями.
Изменённый Base64 стандартизирован по RFC 2152, A Mail-Safe Transformation Format of Unicode.
В сервер-сервер протоколе, используемом в IRCu IRC демоном и совместимом программном обеспечении, версия base64 используется для кодирования клиент/серверных числовых и двоичных IP адресов. Клиентские и серверные числовые данные имеют фиксированные размеры, которые точно совпадают с количеством знаков base64, тем самым, нет необходимости в дополнении. Двоичные IP-адреса для соответствия расширяются ведущими нулевыми битами. Набор символов незначительно отличается от MIME использованием [] вместо +/.
Применение в веб-приложениях
Кодирование Base64 может быть полезно, если в окружении HTTP используется информация, длину которой можно точно определить. Hibernate, библиотека, реализующая базу данных-хранилище для Java-объектов, использует Base64 для того, чтобы закодировать относительно большой идентификатор (как правило, 128-битный UUID) в строку, чтобы использовать его как параметр в HTTP-формах или в запросах HTTP GET URL. Также многим приложениям необходимо кодировать двоичные данные, для удобства включения в URL, скрытые поля форм, и здесь Base64 удобно не только для компактного представления, но и относительной нечитаемостью для попытки выяснения случайным человеком-наблюдателем природы данных.
Использование URL-кодировщика над стандартом Base64, несмотря на это, неудобно, так как он преобразует символы ‘/’ и ‘+’ в специальные шестнадцатеричные последовательности. Если позднее эта строка используется вместе с базой данных или через гетерогенные системы, они прекращают работу на символе ‘%’, сгенерированном URL-кодировщиком (потому что символ ‘%’ также используется в ANSI SQL как шаблон).
По причине этого, существует изменённый Base64 для URL,где не используется заполнение символом ‘=’ и символы ‘+’ и ‘/’ соответственно заменяются на ‘*’ и ‘-‘, так, чтобы использование кодеров/декодеров URL перестаёт быть необходимым и не имеет никакого воздействия на длину закодированного значения, оставляя ту же самую закодированную форму, неповреждённую для использования в реляционных базах данных, веб-формах, и идентификаторах объекта вообще. Стандартом Base64-кодирования URL адресов, признается вариант, когда символы ‘+’ и ‘/’ заменяются, соответственно, на ‘-‘ и ‘_’ (RFC3548, раздел 4).
Другой вариант называется изменённый Base64 для регулярных выражений использует ‘!-‘ вместо ‘*-‘ для того, чтобы заменить стандартный Base64 ‘+/’, потому что оба ‘+’ и ‘*’ могут быть зарезервированы для регулярных выражений (отметим, что ‘[]’ используемый выше в IRCu варианте может не работать в этом контексте).
Имеются другие варианты, которые используют ‘_-‘ или ‘._’, если строка Base64 должна быть использована вместе с идентификаторами для программ, или ‘.-‘ для использования в токенах имён XML (Nmtoken), или ‘_:’ в более ограниченных идентификаторах XML (Name).
Radix-64
Radix-64 — разновидность кодирования Base64 двоичных данных в текстовый формат, используемая в PGP. От Base64 отличается тем, что в конец добавляется контрольная сумма в 24 бита.
Другие применения
Существует множество вариантов применения Base64. Например, Thunderbird и Mozilla использовали Base64 для сокрытия паролей в POP3. Base64 часто используется как рациональный метод в безопасности для скрытия секретов без издержек на криптографическое управление ключами.
Сканеры спама, которые не декодируют сообщения в base64, часто пропускают сообщения в Base64, так как они кажутся достаточно случайными, или не содержат ключевые слова в тексте Base64, чтобы быть принятыми за спам. Это используют спамеры для обхода основных антиспамовых инструментов.
Кодирование и декодирование строк Base64 в Python
Кодировка Base64 позволяет нам преобразовывать байты, содержащие двоичные или текстовые данные, в символы ASCII. В этом уроке мы будем кодировать и декодировать строки Base64 в Python.
Кодирование и декодирование строк Base64 в Python
Вступление
Вы когда-нибудь получали PDF-файл или файл изображения от кого-то по электронной почте только для того, чтобы увидеть странные символы, когда вы открываете его? Это может произойти, если ваш почтовый сервер был предназначен только для обработки текстовых данных. Файлы с двоичными данными, байтами, которые представляют нетекстовую информацию, такую как изображения, могут быть легко повреждены при передаче и обработке в текстовые системы.
В этом уроке мы узнаем, как работает кодирование и декодирование Base64 и как его можно использовать. Затем мы будем использовать Python для кодирования и декодирования Base64 как текстовых, так и двоичных данных.
Что такое кодировка Base64?
Кодировка Base64-это тип преобразования байтов в символы ASCII. В математике основа системы счисления относится к тому, сколько различных символов представляют числа. Название этой кодировки происходит непосредственно от математического определения базисов – у нас есть 64 символа, которые представляют числа.
Набор символов Base64 содержит:
Когда компьютер преобразует символы Base64 в двоичные, каждый символ Base64 представляет 6 бит информации.
Примечание: Это не алгоритм шифрования, и его не следует использовать в целях безопасности.
Теперь, когда мы знаем, что такое кодировка Base64 и как она представлена на компьютере, давайте посмотрим глубже, как она работает.
Как Работает Кодировка Base64?
Мы проиллюстрируем, как работает кодировка Base64 путем преобразования текстовых данных, поскольку она более стандартна, чем различные двоичные форматы на выбор. Если бы мы должны были Base64 кодировать строку мы бы выполнили следующие действия:
Давайте посмотрим, как это работает, преобразовав строку “Python” в строку Base64.
Значения ASCII символов P, y, t, h, o, n являются 15, 50, 45, 33, 40, 39 соответственно. Мы можем представить эти значения ASCII в 8-битном двоичном формате следующим образом:
01010000 01111001 01110100 01101000 01101111 01101110
Напомним, что символы Base64 представляют только 6 бит данных. Теперь мы перегруппируем 8-битные двоичные последовательности в блоки по 6 бит. Результирующий двоичный файл будет выглядеть следующим образом:
010100 000111 100101 110100 011010 000110 111101 101110
С нашими данными в группах по 6 бит мы можем получить десятичное значение для каждой группы. Используя наш последний результат, мы получаем следующие десятичные значения:
20 7 37 52 26 6 61 46
Наконец, мы преобразуем эти десятичные дроби в соответствующий символ Base64 с помощью таблицы преобразования Base64:
Чтобы кодировать строку Base64, мы преобразуем ее в двоичные последовательности, затем в десятичные последовательности и, наконец, используем таблицу поиска, чтобы получить строку символов ASCII. С этим более глубоким пониманием того, как это работает, давайте посмотрим, почему мы должны кодировать наши данные Base64.
Зачем использовать кодировку Base64?
В компьютерах все данные различных типов передаются как 1s и 0s. Однако некоторые каналы связи и приложения не в состоянии понять все биты, которые он получает. Это происходит потому, что значение последовательности 1 и 0 зависит от типа данных, которые она представляет. Например, 10110001 должен быть обработан по-другому, если он представляет собой букву или изображение.
Чтобы обойти это ограничение, вы можете кодировать свои данные в текст, повышая вероятность их правильной передачи и обработки. Base64-это популярный метод преобразования двоичных данных в символы ASCII, который широко используется большинством сетей и приложений.
Распространенный реальный сценарий, в котором кодировка Base64 широко используется,-это почтовые серверы. Изначально они были созданы для обработки текстовых данных, но мы также ожидаем, что они будут отправлять изображения и другие носители с сообщением. В этих случаях ваши медиаданные будут закодированы в Base64 при отправке. Затем он будет декодирован Base64, когда будет получен, чтобы приложение могло его использовать. Так, например, изображение в HTML может выглядеть следующим образом:
Понимая, что данные иногда нужно отправлять в виде текста, чтобы они не были повреждены, давайте посмотрим, как мы можем использовать Python для кодирования и декодирования данных Base64.
Кодирование строк с помощью Python
Примечание: Обязательно используйте тот же формат кодировки, что и при преобразовании из строки в байт, и из байта в строку. Это предотвращает повреждение данных.
Запуск этого файла приведет к следующему результату:
Теперь давайте посмотрим, как мы можем декодировать строку Base64 в ее необработанное представление.
Декодирование строк с помощью Python
Декодирование строки Base64, по сути, является обратным процессом кодирования. Мы декодируем строку Base64 в байты некодированных данных. Затем мы преобразуем байтоподобный объект в строку.
Запустите этот файл, чтобы увидеть следующие выходные данные:
Теперь, когда мы можем кодировать и декодировать строковые данные, давайте попробуем кодировать двоичные данные.
Кодирование двоичных данных с помощью Python
Как мы уже упоминали ранее, кодировка Base64 в основном используется для представления двоичных данных в виде текста. В Python нам нужно прочитать двоичный файл, а Base64 кодирует его байты, чтобы мы могли сгенерировать его кодированную строку.
Давайте посмотрим, как мы можем закодировать этот образ:
Создайте новый файл encoding_binary.py и добавить следующее:
Выполнение кода приведет к получению аналогичного результата:
Ваши выходные данные могут варьироваться в зависимости от изображения, которое вы выбрали для кодирования.
Теперь, когда мы знаем, как Bas64 кодирует двоичные данные в Python, давайте перейдем к декодированию двоичных данных Base64.
Декодирование двоичных данных с помощью Python
Двоичное декодирование Base64 аналогично декодированию текстовых данных Base64. Ключевое отличие заключается в том, что после того, как мы декодируем строку Base64, мы сохраняем данные в виде двоичного файла, а не строки.
Вывод
Кодирование Base64-это популярный метод преобразования данных в различных двоичных форматах в строку символов ASCII. Это полезно при передаче данных в сети или приложения, которые не могут обрабатывать необработанные двоичные данные, но легко обрабатывают текст.
С помощью Python мы можем использовать модуль base64 для кодирования и декодирования текстовых и двоичных данных Base64.
Какие приложения вы бы использовали для кодирования и декодирования данных Base64?



