Краткое введение в BPF и eBPF
Привет, Хабр! Сообщаем, что у нас готовится к выходу книга «Linux Observability with BPF».

Поскольку виртуальная машина BPF продолжает эволюционировать и активно применяется на практике, мы перевели для вас статью, описывающую ее основные возможности и состояние на настоящее время.
В последние годы стали набирать популярность инструментарии для программирования и приемы, призванные компенсировать ограничения ядра Linux в случаях, когда требуется высокопроизводительная обработка пакетов. Один из наиболее популярных приемов такого рода называется обход ядра (kernel bypass) и позволяет, пропуская сетевой уровень ядра, выполнять всю обработку пакетов из пользовательского пространства. Обход ядра также предполагает управление сетевой картой из пользовательского пространства. Иными словами, при работе с сетевой картой мы полагаемся на драйвер пользовательского пространства.
Передавая полный контроль над сетевой картой программе из пользовательского пространства, мы сокращаем издержки, обусловленные работой ядра (переключение контекста, обработка сетевого уровня, прерывания, т.д.), что достаточно важно при работе на скоростях 10Гб/с или выше. Обход ядра плюс комбинация других возможностей (пакетная обработка) и аккуратная настройка производительности (учет NUMA, изоляция CPU, т.д.) соответствуют основам высокопроизводительной сетевой обработки в пользовательском пространстве. Возможно, образцовый пример такого нового подхода к обработке пакетов – это DPDK от Intel (Data Plane Development Kit), хотя, существуют и другие широко известные инструментарии и приемы, среди которых VPP от Cisco (Vector Packet Processing), Netmap и, конечно же, Snabb.
У организации сетевых взаимодействий в пользовательском пространстве есть ряд недостатков:
Несмотря на не вполне понятное название BPF (Фильтрация пакетов, Беркли) – это, фактически, модель виртуальной машины. Данная виртуальная машина исходно проектировалась для обработки фильтрации пакетов, отсюда и название.
Вот что, в принципе, делает вышеприведенная программа:
Поддержка BPF реализована в ядре Linux в версии v2.5 и выше, добавлена в основном усилиями Джея Шуллиста. Код BPF оставался без серьезных изменений вплоть до 2011 года, когда Эрик Думазет переделал интерпретатор BPF для работы в режиме JIT (Источник: JIT для пакетных фильтров). После этого ядро вместо интерпретации байт-кода BPF могло напрямую преобразовывать программы BPF под целевую архитектуру: x86, ARM, MIPS, т.д.
Позже, в 2014 году, Алексей Старовойтов предложил новый JIT-механизм для BPF. Фактически этот новый JIT стал новой архитектурой на основе BPF и получил название eBPF. Думаю, в течение некоторого времени обе виртуальные машины сосуществовали, но в настоящее время фильтрация пакетов реализуется на основе eBPF. Фактически, во многих образцах современной документации под BPF понимается eBPF, а классическая BPF сегодня известна как cBPF.
eBPF в нескольких отношениях расширяет классическую виртуальную машину BPF:
В исходниках ядра Linux есть несколько примеров для eBPF. Они доступны по адресу samples/bpf/. Чтобы скомпилировать эти примеры, просто введите:
$ sudo make samples/bpf/
Вообще, каждый из примеров в samples/bpf/ состоит из двух файлов. В данном случае:
Выше я упоминал, что одной из наиболее интересных фич eBPF являются карты. tracex4_kern определяет одну карту:
Если я выведу дамп секций объектного файла, то должен увидеть, что эти новые секции уже определены:
tracex4_kern.o: file format elf64-little
$ sudo cat /sys/kernel/debug/tracing/kprobe_events
p:kprobes/kmem_cache_free kmem_cache_free
r:kprobes/kmem_cache_alloc_node kmem_cache_alloc_node
Все остальные программы в sample/bpf/ структурированы сходим образом. В них всегда по два файла:
В этой статье в общих чертах были рассмотрены BPF и eBPF. Я знаю, что сегодня очень много информации и ресурсов об eBPF, поэтому порекомендую еще несколько материалов для дальнейшего изучения
BPF для самых маленьких, часть нулевая: classic BPF
Berkeley Packet Filters (BPF) — это технология ядра Linux, которая не сходит с первых полос англоязычных технических изданий вот уже несколько лет подряд. Конференции забиты докладами про использование и разработку BPF. David Miller, мантейнер сетевой подсистемы Linux, называет свой доклад на Linux Plumbers 2018 «This talk is not about XDP» (XDP – это один из вариантов использования BPF). Brendan Gregg читает доклады под названием Linux BPF Superpowers. Toke Høiland-Jørgensen смеется, что ядро это теперь microkernel. Thomas Graf рекламирует идею о том, что BPF — это javascript для ядра.
Разработка BPF контролируется сетевым сообществом Linux, основные существующие применения BPF связаны с сетями и поэтому, с позволения @eucariot, я назвал серию «BPF для самых маленьких», в честь великой серии «Сети для самых маленьких».
Краткий курс истории BPF(c)
В конце восьмидесятых годов прошлого века инженеры из знаменитой Lawrence Berkeley Laboratory заинтересовались вопросом о том, как правильно фильтровать сетевые пакеты на современном для конца восьмидесятых годов прошлого века железе. Базовая идея фильтрации, реализованная изначально в технологии CSPF (CMU/Stanford Packet Filter), состояла в том, чтобы фильтровать лишние пакеты как можно раньше, т.е. в пространстве ядра, так как это позволяет не копировать лишние данные в пространство пользователя. Чтобы обеспечить безопасность времени выполнения для запуска пользовательского кода в пространстве ядра, использовалась виртуальная машина — песочница.
Однако виртуальные машины для существовавших фильтров были спроектированы для запуска на машинах со стековой архитектурой и на новых RISC машинах работали не так эффективно. В итоге усилиями инженеров из Berkeley Labs была разработана новая технология BPF (Berkeley Packet Filters), архитектура виртуальной машины которой была спроектирована на основе процессора Motorola 6502 — рабочей лошадки таких известных продуктов как Apple II или NES. Новая виртуальная машина увеличивала производительность фильтров в десятки раз по сравнению с существовавшими решениями.
Архитектура машины BPF
Общая схема запуска машины следующая. Пользователь создает программу для архитектуры BPF и, при помощи какого-то механизма ядра (например, системного вызова), загружает и подключает программу к какому-то генератору событий в ядре (например, событие — это приход очередного пакета на сетевую карту). При возникновении события ядро запускает программу (например, в интерпретаторе), при этом память машины соответствует какому-то региону памяти ядра (например, данным пришедшего пакета).
tcpdump
Пример: наблюдаем IPv6 пакеты

Пример посложнее: смотрим на TCP пакеты по порту назначения
Посмотрим как выглядит фильтр, который копирует все TCP пакеты с портом назначения 666. Мы рассмотрим случай IPv4, так как случай IPv6 проще. После изучения данного примера, вы можете в качестве упражнения самостоятельно изучить фильтр для IPv6 ( ip6 and tcp dst port 666 ) и фильтр для общего случая ( tcp dst port 666 ). Итак, интересующий нас фильтр выглядит следующим образом:
Что делают строчки 0 и 1 мы уже знаем. На строке 2 мы уже проверили, что это IPv4 пакет (Ether Type = 0x800 ) и загружаем в регистр A 24-й байт пакета. Наш пакет выглядит как
а значит мы загружаем в регистр A поле Protocol заголовка IP, что логично, ведь мы же хотим копировать только TCP пакеты. Мы сравниваем Protocol с 0x6 ( IPPROTO_TCP ) на строке 3.
На строках 4 и 5 мы загружаем полслова, находящиеся по адресу 20, и при помощи команды jset проверяем, не выставлен ли один из трех флагов — в маске выданной jset очищены три старшие бита. Два бита из трех говорят нам, является ли пакет частью фрагментированного IP пакета, и если да, то является ли он последним фрагментом. Третий бит зарезервирован и должен быть равен нулю. Мы не хотим проверять ни нецелые ни битые пакеты, поэтому и проверяем все три бита.
Наконец, на строке 8 мы сравниваем порт назначения с искомым значением и на строчках 9 или 10 возвращаем результат — копировать пакет или нет.
Tcpdump: загрузка
Для того, чтобы посмотреть как функция pcap_setfilter реализована в Linux, мы используем strace (некоторые строчки были удалены):
Стоит отметить, что в классическом BPF загрузка и подсоединение фильтра всегда происходит как атомарная операция, а в новой версии BPF загрузка программы и привязка ее к генератору событий разделены по времени.
Чуть более полная версия вывода выглядит так:
Как было сказано выше, мы загружаем и подсоединяем к сокету наш фильтр на строке 5, но что происходит на строчках 3 и 4? Оказывается, это libpcap заботится о нас — для того, чтобы в вывод нашего фильтра не попали пакеты, ему не удовлетворяющие, библиотека подсоединяет фиктивный фильтр ret #0 (дропнуть все пакеты), переводит сокет в неблокирующий режим и пытается вычитать все пакеты, которые могли остаться от прошлых фильтров.
Интересно, что фильтр можно присоединять к любому сокету, не только к raw. Вот пример программы, которая отрезает все, кроме двух первых байт у всех входящих UDP датаграмм. (Комментарии я добавил в коде, чтобы не загромождать статью.)
Подробнее про использование setsockopt для подсоединения фильтров см. в socket(7), а про написание своих фильтров вида struct sock_fprog без помощи tcpdump мы поговорим в разделе Программируем BPF при помощи собственных рук.
Классический BPF и XXI век
BPF был включен в Linux в 1997 году и долгое время оставался рабочей лошадкой libpcap без особых изменений (Linux-специфичные изменения, конечно, были, но они не меняли глобальной картины). Первые серьезные признаки того, что BPF будет эволюционировать появились в 2011 году, когда Eric Dumazet предложил патч, добавляющий в ядро Just In Time Compiler — транслятор для перевода байткода BPF в нативный x86_64 код.
Мы скоро рассмотрим все эти примеры подробнее, однако сначала нам будет полезно научиться писать и компилировать произвольные программы для BPF, так как возможности, предоставляемые библиотекой libpcap ограничены (простой пример: фильтр, сгенерированный libpcap может вернуть только два значения — 0 или 0x40000) или вообще, как в случае seccomp, неприменимы.
Программируем BPF при помощи собственных рук
Познакомимся с бинарным форматом инструкций BPF, он очень простой:
а целая программа — в виде структуры
Таким образом, мы уже можем писать программы (коды инструкций мы, допустим, знаем из [1]). Вот так будет выглядеть фильтр ip6 из нашего первого примера:
Программу prog мы можем легально использовать в вызове
Однако, и такой вариант не очень-то удобен. Так рассудили и программисты ядра Linux и поэтому в директории tools/bpf ядра можно найти ассемблер и дебагер для работы с классическим BPF.
Для удобства C программистов можно использовать другой формат вывода:
Расширения Linux и netsniff-ng
seccomp
Итак, мы уже умеем писать BPF программы произвольной сложности и готовы посмотреть на новые примеры, первый из которых — это технология seccomp, позволяющая при помощи фильтров BPF управлять множеством и набором аргументов системных вызовов, доступных данному процессу и его потомкам.
Отметим, что на хабре уже были статьи про использование seccomp, может кому-то захочется прочитать их до (или вместо) чтения следующих подразделов. В статье Контейнеры и безопасность: seccomp приведены примеры использования seccomp, как версии 2007 года, так и версии с использованием BPF (фильтры генерируются при помощи libseccomp), рассказывается про связь seccomp с Docker, а также приведено много полезных ссылок. В статье Изолируем демоны с systemd или «вам не нужен Docker для этого!» рассказывается, в частности, о том, как добавлять черные или белые списки системных вызовов для демонов под управлением systemd.
Пишем и загружаем фильтры для seccomp
Мы уже умеем писать BPF программы и поэтому посмотрим сначала на программный интерфейс seccomp. Установить фильтр можно на уровне процесса, при этом все дочерние процессы будут ограничения наследовать. Делается это при помощи системного вызова seccomp(2) :
Чем же отличаются программы для seccomp от программ для сокетов? Передаваемым контекстом. В случае сокетов, нам передавалась область памяти, содержащая пакет, а в случае seccomp нам передается структура вида
Здесь nr — это номер запускаемого системного вызова, arch — текущая архитектура (об этом ниже), args — до шести аргументов системного вызова, а instruction_pointer — это указатель на инструкцию в пространстве пользователя, которая сделала данный системный вызов. Таким образом, например, чтобы загрузить номер системного вызова в регистр A мы должны сказать
В принципе, мы уже знаем все, чтобы писать и читать seccomp программы. Обычно логика программы устроена как белый или черный список системных вызовов, например программа
проверяет черный список из четырех системных вызовов под номерами 304, 176, 239, 279. Что же это за системные вызовы? Мы не можем сказать точно, так как мы не знаем для какой архитектуры писалась программа. Поэтому авторы seccomp предлагают начинать все программы с проверки архитектуры (текущая архитектура указывается в контексте как поле arch структуры struct seccomp_data ). С проверкой архитектуры начало примера выглядело бы как:
и тогда наши номера системных вызовов получили бы определенные значения.
Пишем и загружаем фильтры для seccomp при помощи libseccomp
Написание фильтров в машинных кодах или для ассемблера BPF позволяет получить полный контроль над результатом, но в то же время иногда предпочтительнее иметь переносимый и/или читаемый код. В этом нам поможет библиотека libseccomp, предоставляющая стандартный интерфейс для написания черных или белых фильтров.
Давайте, например, напишем программу, которая запускает бинарный файл по выбору пользователя, установив, предварительно, черный список системных вызовов из вышеупомянутой статьи (программа упрощена для большей читаемости, полный вариант можно найти тут):
Пример успешного запуска:
Пример заблокированного системного вызова:
Если хотите посмотреть как устроены фильтры с бинарным поиском, то взгляните на простой скрипт, генерирующий такие программы на ассемблере BPF по набору номеров системных вызовов, например:
Ничего существенно более быстрое написать не получится, так как программы BPF не могут совершать переходы по отступу (мы не можем сделать, например, jmp A или jmp [label+X] ) и поэтому все переходы статические.
seccomp и strace
отрабатывают за примерно одно и то же время, хотя во втором случае мы хотим трейсить только один системный вызов.
Чуть больше подробностей о том как именно strace работает с seccomp можно узнать из недавнего доклада. Для нас же наиболее интересным фактом является то, что классический BPF в лице seccomp находит применения до сих пор.
xt_bpf
Отправимся теперь обратно в мир сетей.
Предыстория: давным-давно, в 2007 году, в ядро был добавлен модуль xt_u32 для netfilter. Он был написан по аналогии с еще более древним классификатором трафика cls_u32 и позволял писать произвольные бинарные правила для iptables при помощи следующих простых операций: загрузить 32 бита из пакета и проделать с ними набор арифметических операций. Например,
Загружает 32 бита заголовка IP, начиная с отступа 6, и применяет к ним маску 0xFF (взять младший байт). Это — поле protocol заголовка IP и мы его сравниваем с 1 (ICMP). В одном правиле можно комбинировать много проверок, а еще можно выполнять оператор @ — перейти на X байт вправо. Например, правило
здесь — это код в формате вывода ассемблера bpf_asm по-умолчанию, например,
Понятно, что модуль xt_bpf поддерживает более сложные фильтры, чем в примере выше. Давайте посмотрим на настоящие примеры от компании Cloudfare. До недавнего времени они использовали модуль xt_bpf для защиты от DDoS атак. В статье Introducing the BPF Tools они рассказывают как (и почему) они генерируют BPF фильтры и публикуют ссылки на набор утилит для создания таких фильтров. Например, при помощи утилиты bpfgen можно создать BPF программу, которая матчит DNS-запрос на имя habr.com :
В программе мы сначала загружаем в регистр X адрес начала строки \x04habr\x03com\x00 внутри UDP-датаграммы и потом проверяем запрос: 0x04686162 «\x04hab» и т.д.
cls_bpf
Еще одна причина не рассказывать об использовании классического BPF c cls_bpf заключается в том, что по сравнению с Extended BPF в этом случае кардинально сужается область применимости: классические программы не могут менять содержимое пакетов и не могут сохранять состояние между вызовами.
Так что пришло время попрощаться с классическим BPF и заглянуть в будущее.
Прощание с classic BPF
Мы посмотрели на то, как технология BPF, разработанная в начале девяностых успешно прожила четверть века и до конца находила новые применения. Однако, подобно переходу со стековых машин на RISC, послужившему толчком к разработке классического BPF, в двухтысячные случился переход с 32-битных на 64-битные машины и классический BPF стал устаревать. Кроме этого, возможности классического BPF сильно ограничены и помимо устаревшей архитектуры — у нас нет возможности сохранять состояние между вызовами BPF программ, нет возможности прямого взаимодействия с пользователем, нет возможности взаимодействия с ядром, кроме чтения ограниченного количества полей структуры sk_buff и запуска простейших функций-помощников, нельзя изменять содержимое пакетов и переадресовывать их.
На самом деле, в настоящее время от классического BPF в Linux остался только API интерфейс, а внутри ядра все классические программы, будь то фильтры сокетов или фильтры seccomp, автоматически транслируются в новый формат, Extended BPF. (Мы расскажем про то как именно это происходит в следующей статье.)
Переход на новую архитектуру начался в 2013 году, когда Алексей Старовойтов предложил схему обновления BPF. В 2014 году соответствующие патчи стали появляться в ядре. Насколько я понимаю, изначально планировалось лишь оптимизировать архитектуру и JIT-compiler для более эффективной работы на 64-битных машинах, но вместо этого эти оптимизации положили начало новой главе в разработке Linux.
Дальнейшие статьи в этой серии расскажут об архитектуре и применениях новой технологии, изначально известной как internal BPF, затем extended BPF, а теперь как просто BPF.
BPF для самых маленьких, часть нулевая: classic BPF
Категории
Свежие записи
Наши услуги
Краткий курс истории BPF(c)
В конце восьмидесятых годов прошлого века инженеры из знаменитой Lawrence Berkeley Laboratory заинтересовались вопросом о том, как правильно фильтровать сетевые пакеты на современном для конца восьмидесятых годов прошлого века железе. Базовая идея фильтрации, реализованная изначально в технологии CSPF (CMU/Stanford Packet Filter), состояла в том, чтобы фильтровать лишние пакеты как можно раньше, т.е. в пространстве ядра, так как это позволяет не копировать лишние данные в пространство пользователя. Чтобы обеспечить безопасность времени выполнения для запуска пользовательского кода в пространстве ядра, использовалась виртуальная машина — песочница.
Архитектура машины BPF
Общая схема запуска машины следующая. Пользователь создает программу для архитектуры BPF и, при помощи какого-то механизма ядра (например, системного вызова), загружает и подключает программу к какому-то генератору событий в ядре (например, событие — это приход очередного пакета на сетевую карту). При возникновении события ядро запускает программу (например, в интерпретаторе), при этом память машины соответствует какому-то региону памяти ядра (например, данным пришедшего пакета).
tcpdump
Пример: наблюдаем IPv6 пакеты
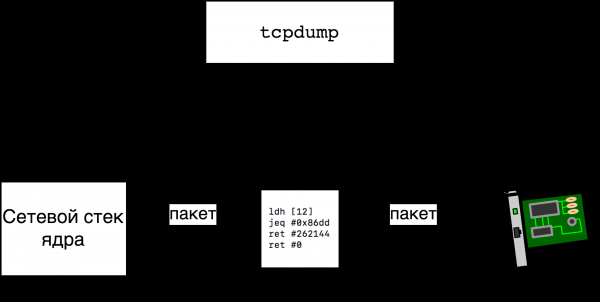
Пример посложнее: смотрим на TCP пакеты по порту назначения
Посмотрим как выглядит фильтр, который копирует все TCP пакеты с портом назначения 666. Мы рассмотрим случай IPv4, так как случай IPv6 проще. После изучения данного примера, вы можете в качестве упражнения самостоятельно изучить фильтр для IPv6 ( ip6 and tcp dst port 666 ) и фильтр для общего случая ( tcp dst port 666 ). Итак, интересующий нас фильтр выглядит следующим образом:
Что делают строчки 0 и 1 мы уже знаем. На строке 2 мы уже проверили, что это IPv4 пакет (Ether Type = 0x800 ) и загружаем в регистр A 24-й байт пакета. Наш пакет выглядит как
а значит мы загружаем в регистр A поле Protocol заголовка IP, что логично, ведь мы же хотим копировать только TCP пакеты. Мы сравниваем Protocol с 0x6 ( IPPROTO_TCP ) на строке 3.
На строках 4 и 5 мы загружаем полслова, находящиеся по адресу 20, и при помощи команды jset проверяем, не выставлен ли один из трех флагов — в маске выданной jset очищены три старшие бита. Два бита из трех говорят нам, является ли пакет частью фрагментированного IP пакета, и если да, то является ли он последним фрагментом. Третий бит зарезервирован и должен быть равен нулю. Мы не хотим проверять ни нецелые ни битые пакеты, поэтому и проверяем все три бита.
Наконец, на строке 8 мы сравниваем порт назначения с искомым значением и на строчках 9 или 10 возвращаем результат — копировать пакет или нет.
Tcpdump: загрузка
Для того, чтобы посмотреть как функция pcap_setfilter реализована в Linux, мы используем strace (некоторые строчки были удалены):
Стоит отметить, что в классическом BPF загрузка и подсоединение фильтра всегда происходит как атомарная операция, а в новой версии BPF загрузка программы и привязка ее к генератору событий разделены по времени.
Чуть более полная версия вывода выглядит так:
Как было сказано выше, мы загружаем и подсоединяем к сокету наш фильтр на строке 5, но что происходит на строчках 3 и 4? Оказывается, это libpcap заботится о нас — для того, чтобы в вывод нашего фильтра не попали пакеты, ему не удовлетворяющие, библиотека подсоединяет фиктивный фильтр ret #0 (дропнуть все пакеты), переводит сокет в неблокирующий режим и пытается вычитать все пакеты, которые могли остаться от прошлых фильтров.
Интересно, что фильтр можно присоединять к любому сокету, не только к raw. Вот пример программы, которая отрезает все, кроме двух первых байт у всех входящих UDP датаграмм. (Комментарии я добавил в коде, чтобы не загромождать статью.)
Классический BPF и XXI век
Мы скоро рассмотрим все эти примеры подробнее, однако сначала нам будет полезно научиться писать и компилировать произвольные программы для BPF, так как возможности, предоставляемые библиотекой libpcap ограничены (простой пример: фильтр, сгенерированный libpcap может вернуть только два значения — 0 или 0x40000) или вообще, как в случае seccomp, неприменимы.
Программируем BPF при помощи собственных рук
Познакомимся с бинарным форматом инструкций BPF, он очень простой:
а целая программа — в виде структуры
Таким образом, мы уже можем писать программы (коды инструкций мы, допустим, знаем из [1] ). Вот так будет выглядеть фильтр ip6 из нашего первого примера :
Программу prog мы можем легально использовать в вызове
Однако, и такой вариант не очень-то удобен. Так рассудили и программисты ядра Linux и поэтому в директории tools/bpf ядра можно найти ассемблер и дебагер для работы с классическим BPF.
Для удобства C программистов можно использовать другой формат вывода:
Расширения Linux и netsniff-ng
seccomp
Итак, мы уже умеем писать BPF программы произвольной сложности и готовы посмотреть на новые примеры, первый из которых — это технология seccomp, позволяющая при помощи фильтров BPF управлять множеством и набором аргументов системных вызовов, доступных данному процессу и его потомкам.
Отметим, что на хабре уже были статьи про использование seccomp, может кому-то захочется прочитать их до (или вместо) чтения следующих подразделов. В статье Контейнеры и безопасность: seccomp приведены примеры использования seccomp, как версии 2007 года, так и версии с использованием BPF (фильтры генерируются при помощи libseccomp), рассказывается про связь seccomp с Docker, а также приведено много полезных ссылок. В статье Изолируем демоны с systemd или «вам не нужен Docker для этого!» рассказывается, в частности, о том, как добавлять черные или белые списки системных вызовов для демонов под управлением systemd.
Пишем и загружаем фильтры для seccomp
Мы уже умеем писать BPF программы и поэтому посмотрим сначала на программный интерфейс seccomp. Установить фильтр можно на уровне процесса, при этом все дочерние процессы будут ограничения наследовать. Делается это при помощи системного вызова seccomp(2) :
Чем же отличаются программы для seccomp от программ для сокетов? Передаваемым контекстом. В случае сокетов, нам передавалась область памяти, содержащая пакет, а в случае seccomp нам передается структура вида
Здесь nr — это номер запускаемого системного вызова, arch — текущая архитектура (об этом ниже), args — до шести аргументов системного вызова, а instruction_pointer — это указатель на инструкцию в пространстве пользователя, которая сделала данный системный вызов. Таким образом, например, чтобы загрузить номер системного вызова в регистр A мы должны сказать
В принципе, мы уже знаем все, чтобы писать и читать seccomp программы. Обычно логика программы устроена как белый или черный список системных вызовов, например программа
проверяет черный список из четырех системных вызовов под номерами 304, 176, 239, 279. Что же это за системные вызовы? Мы не можем сказать точно, так как мы не знаем для какой архитектуры писалась программа. Поэтому авторы seccomp предлагают начинать все программы с проверки архитектуры (текущая архитектура указывается в контексте как поле arch структуры struct seccomp_data ). С проверкой архитектуры начало примера выглядело бы как:
и тогда наши номера системных вызовов получили бы определенные значения.
Пишем и загружаем фильтры для seccomp при помощи libseccomp
Давайте, например, напишем программу, которая запускает бинарный файл по выбору пользователя, установив, предварительно, черный список системных вызовов из вышеупомянутой статьи (программа упрощена для большей читаемости, полный вариант можно найти тут ):
Пример успешного запуска:
Пример заблокированного системного вызова:
Ничего существенно более быстрое написать не получится, так как программы BPF не могут совершать переходы по отступу (мы не можем сделать, например, jmp A или jmp [label+X] ) и поэтому все переходы статические.
seccomp и strace
отрабатывают за примерно одно и то же время, хотя во втором случае мы хотим трейсить только один системный вызов.


xt_bpf
Отправимся теперь обратно в мир сетей.
Предыстория: давным-давно, в 2007 году, в ядро был добавлен модуль xt_u32 для netfilter. Он был написан по аналогии с еще более древним классификатором трафика cls_u32 и позволял писать произвольные бинарные правила для iptables при помощи следующих простых операций: загрузить 32 бита из пакета и проделать с ними набор арифметических операций. Например,
Загружает 32 бита заголовка IP, начиная с отступа 6, и применяет к ним маску 0xFF (взять младший байт). Это — поле protocol заголовка IP и мы его сравниваем с 1 (ICMP). В одном правиле можно комбинировать много проверок, а еще можно выполнять оператор @ — перейти на X байт вправо. Например, правило
здесь — это код в формате вывода ассемблера bpf_asm по-умолчанию, например,
Понятно, что модуль xt_bpf поддерживает более сложные фильтры, чем в примере выше. Давайте посмотрим на настоящие примеры от компании Cloudfare. До недавнего времени они использовали модуль xt_bpf для защиты от DDoS атак. В статье Introducing the BPF Tools они рассказывают как (и почему) они генерируют BPF фильтры и публикуют ссылки на набор утилит для создания таких фильтров. Например, при помощи утилиты bpfgen можно создать BPF программу, которая матчит DNS-запрос на имя habr.com :
В программе мы сначала загружаем в регистр X адрес начала строки x04habrx03comx00 внутри UDP-датаграммы и потом проверяем запрос: 0x04686162 «x04hab» и т.д.
cls_bpf
Еще одна причина не рассказывать об использовании классического BPF c cls_bpf заключается в том, что по сравнению с Extended BPF в этом случае кардинально сужается область применимости: классические программы не могут менять содержимое пакетов и не могут сохранять состояние между вызовами.
Так что пришло время попрощаться с классическим BPF и заглянуть в будущее.
Прощание с classic BPF
Мы посмотрели на то, как технология BPF, разработанная в начале девяностых успешно прожила четверть века и до конца находила новые применения. Однако, подобно переходу со стековых машин на RISC, послужившему толчком к разработке классического BPF, в двухтысячные случился переход с 32-битных на 64-битные машины и классический BPF стал устаревать. Кроме этого, возможности классического BPF сильно ограничены и помимо устаревшей архитектуры — у нас нет возможности сохранять состояние между вызовами BPF программ, нет возможности прямого взаимодействия с пользователем, нет возможности взаимодействия с ядром, кроме чтения ограниченного количества полей структуры sk_buff и запуска простейших функций-помощников, нельзя изменять содержимое пакетов и переадресовывать их.
На самом деле, в настоящее время от классического BPF в Linux остался только API интерфейс, а внутри ядра все классические программы, будь то фильтры сокетов или фильтры seccomp, автоматически транслируются в новый формат, Extended BPF. (Мы расскажем про то как именно это происходит в следующей статье.)
Переход на новую архитектуру начался в 2013 году, когда Алексей Старовойтов предложил схему обновления BPF. В 2014 году соответствующие патчи стали появляться в ядре. Насколько я понимаю, изначально планировалось лишь оптимизировать архитектуру и JIT-compiler для более эффективной работы на 64-битных машинах, но вместо этого эти оптимизации положили начало новой главе в разработке Linux.
Дальнейшие статьи в этой серии расскажут об архитектуре и применениях новой технологии, изначально известной как internal BPF, затем extended BPF, а теперь как просто BPF.
Ссылки
Добавить комментарий Отменить ответ
Для отправки комментария вам необходимо авторизоваться.



