
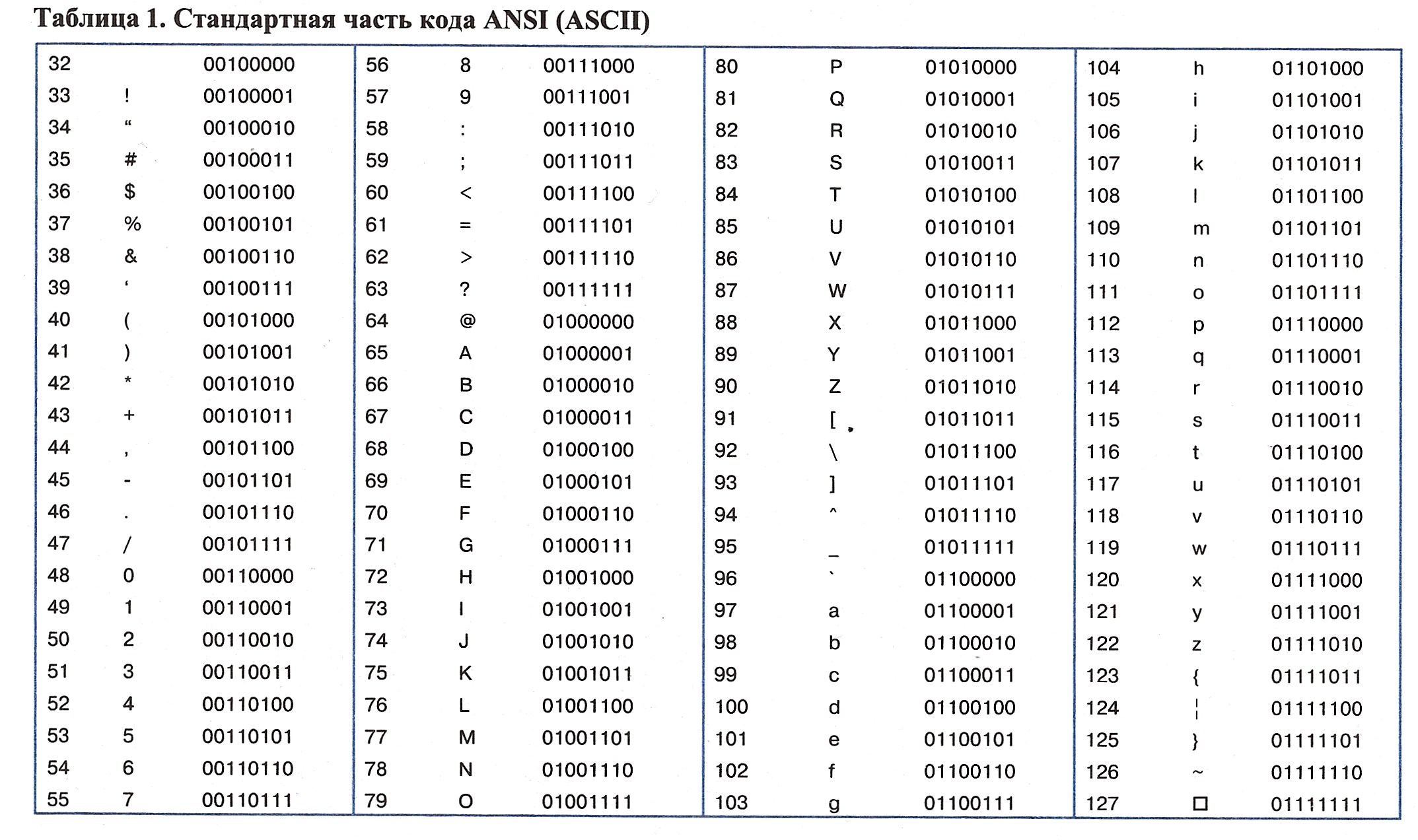
Итак, продолжаем наши уроки Паскаль для начинающих. В прошлом уроке мы разобрали строковый тип данных, но там мы упомянули про символы, поэтому прежде чем глубоко изучать тип данных String, мы узнаем о типе Char. Символьный тип данных Char — тип данных, значениями которого являются одиночные символы. Данный тип может содержать всего один любой символ (Например: «*», «/», «.», «!» и другие). Каждый такой символ занимает 8 бит памяти, всего существует 256 восьмибитовых символов. Все символы, используемые символьным типом Char записаны в таблице символов ASCII (American Standart Code for Information Interchange) или Американский стандарт кода для обмена информацией.
Символьные константы заключаются в апострофы, например ‘.’, ‘*’, ‘7’, ‘s’. Также символьную константу можно записать с помощью символа — «решетки», например #185 — выведет символ под номером 185 из таблицы ASCII (это символ ‘№’).
К символьному типу применимы 5 функций: Ord, Chr, Pred, Succ и Upcase.
Функция Ord преобразовывает символ в её числовой код из таблицы ASCII. Например для символа ‘№’ она возвратит значение 185. Функция Chr обратна функции Ord. Функция Chr преобразует числовой код символа в сам символ, например, если взять числовой код 64, то функция Chr (64) возвратит символ ‘@’.
Пример программы на Паскаль с использованием функции Ord:
Пример программы на Паскаль с использованием функции Chr:
Функция Pred возвращает значение предыдущего символа из таблицы ASCII, например для символа ‘P’ (Pred (P)) эта функция возвратит символ ‘O’. Функция Succ обратная функции Pred. Для символа ‘P’ функция Succ (P) возвратит символ ‘Q’, то есть следующий символ из вышеописанной таблицы ASCII.
Пример программы на Паскаль с использованием функций Pred и Succ:
Функция UpCase применима только для строчных букв английского алфавита. Данная функция преобразует строчные английские буквы в заглавные.
Пример программы на Паскаль с использованием функции UpCase:
На сегодня урок окончен. Помните, что программирование на паскале просто и является основой для многих языков программирования.
Уроки Паскаль
Мы с Вами уже рассмотрели типы данных, которые позволяют хранить и обрабатывать целые числа (integer) и дробные числа (real). Теперь рассмотрим тип данных, позволяющий хранить и обрабатывать различные символы. Символы – это все буквы и значки, которые мы можем увидеть на клавиатуре. Для того чтобы ввести в программу символьные переменные необходимо указать для них символьный тип данных Char.
Строка №4. Записываем переменную «X» и указываем для нее тип данных Char. Char – тип данных, который позволяет хранить символы. В данном случае в переменную «X» мы будем записывать не какие-то числа, а символы.
В строке №7 мы присвоили переменной «X» значение латинской буквы L. Сам символ, который необходимо записать в переменную, обязательно берется в апострофы. Напомню, что когда мы присваиваем переменной числовое значение, то число в апострофы не берется.
В строке №8 выводим на экран значение, которое мы присвоили переменной X, т.е. фактически на экран выведется буква L.
В строке №10 выводим значение переменной «N» (т.е. числовой код буквы «L») на экран.
Строка №11. Функция Chr противоположна функции Ord. Эта функция будет преобразовывать числовой код символа в сам символ. В переменной N у нас записан код буквы «L». C помощью функции Chr мы преобразуем этот код в букву и запишем её в символьную переменную X. Таким образом, в строке №12 на экран выведется буква «L»


Дополнение к материалу.
В приведенном выше примере функция Ord возвращает в качестве значения код переменной «X», которой присвоено значение латинской буквы «L». После записи функции Ord переменная «X» стоит в круглых скобках (строка №9). Вместо записи переменной можно напрямую записать символ, код которого необходимо получить. Этот символ необходимо заключить не только в круглые скобки, но и в апострофы. Таким образом программу можно записать так:
Char Структура
Определение
Некоторые сведения относятся к предварительной версии продукта, в которую до выпуска могут быть внесены существенные изменения. Майкрософт не предоставляет никаких гарантий, явных или подразумеваемых, относительно приведенных здесь сведений.
Представляет символ как кодовую единицу UTF-16.
Примеры
Комментарии
Объекты типа char, символы Юникода и строки
Объект String является упорядоченной коллекцией структур Char, представляющей строку текста. Большинство символов Юникода могут быть представлены одним объектом Char, но знак, который кодируется как базовый символ, суррогатная пара и/или последовательность несамостоятельных знаков представляется с помощью нескольких объектов Char. Поэтому структура Char в объекте String не обязательно эквивалентна одному символу Юникода.
Для представления одного символа Юникода используется несколько 16-разрядных кодовых единиц в следующих случаях:
Глифы, которые могут состоять из одного символа или базового символа со следующими за ним несамостоятельными знаками (одним или более). Например, символ ä представлен объектом Char с кодовой единицей U+0061, за которым следует объект Char с кодовой единицей U+0308. (Символ ä также может быть представлен как один объект Char с кодовой единицей U+00E4.) В следующем примере показано, что символ ä состоит из двух объектов Char.
Символы вне основной многоязыковой плоскости Юникода (BMP). Юникод поддерживает шестнадцать плоскостей помимо BMP, которая представляет плоскость 0. Кодовая точка Юникода в UTF-32 представляется 21-битовым значением, которое содержит плоскость. Например, U+1D160 представляет символ MUSICAL SYMBOL EIGHTH NOTE (музыкальный символ восьмая). Поскольку кодировка UTF-16 имеет только 16 разрядов, символы за пределами BMP в кодировке UTF-16 представляются суррогатными парами. В следующем примере показано, что U+D834 U+DD60 является эквивалентом U+1D160, символа MUSICAL SYMBOL EIGHTH NOTE, в UTF-32. U+D834 является старшим символом-заместителем; старшие символы-заместители находятся в диапазоне от U+D800 до U+DBFF. U+DD60 является младшим символом-заместителем; младшие символы-заместители находятся в диапазоне от U+DC00 до U+DFFF.
Символы и категории символов
Символы и текстовые элементы
Так как один символ может быть представлен несколькими объектами Char, не всегда имеет смысл работать с отдельными объектами Char. Например, в следующем примере кодовые точки Юникода, представляющие эгейские цифры 0–9, преобразуются в кодовые единицы в кодировке UTF-16. Так как в нем объекты Char ошибочно приравниваются к символам, он неточно сообщает, что результирующая строка содержит 20 символов.
Чтобы избежать предположения о том, что Char представляет один символ, можно использовать один из следующих способов.
Можно работать с объектом String целиком, а не с отдельными его символами, при представлении и анализе его лингвистического содержимого.
Можно использовать класс StringInfo для работы с элементами текста вместо отдельных объектов Char. В следующем примере для подсчета количества элементов текста в строке, состоящей из эгейских цифр от нуля до девяти, используется объект StringInfo. Так как он считает суррогатную пару одним символом, он правильно сообщает, что строка содержит десять символов.
Если строка содержит базовый символ с одним или несколькими несамостоятельными знаками, можно вызвать метод String.Normalize для преобразования подстроки в одиночную кодовую единицу в кодировке UTF-16. В следующем примере метод String.Normalize используется для преобразования базового символа U+0061 (LATIN SMALL LETTER A — латинская строчная буква «a») и несамостоятельного знака U+0308 (COMBINING DIAERESIS — комбинируемое надстрочное двоеточие) в U+00E4 (LATIN SMALL LETTER A WITH DIAERESIS — латинская строчная буква «a» с диэризисом).
Типичные операции
Структура Char предоставляет методы для сравнения объектов Char, преобразования значения заданного объекта Char в объект другого типа и определения категории Юникода для объекта Char:
| Требуемое действие | Используйте эти методы System.Char |
|---|---|
| Сравнение Char объектов | CompareTo и Equals |
| Преобразование кодовой точки в строку | ConvertFromUtf32 См. также Rune тип. |
| Преобразовать объект Char или суррогатную пару объектов Char в кодовую точку | Для одного символа: Convert.ToInt32(Char) Для суррогатной пары или символа в строке: Char.ConvertToUtf32 См. также Rune тип. |
| Получение категории Юникода для символа | GetUnicodeCategory См. также раздел Rune.GetUnicodeCategory. |
| Определить, принадлежит ли символ определенной категории Юникода, например: цифры, буквы, знаки препинания, управляющие символы и т. д. | IsControl, IsDigit, IsHighSurrogate, IsLetter, IsLetterOrDigit, IsLower, IsLowSurrogate, IsNumber, IsPunctuation, IsSeparator, IsSurrogate, IsSurrogatePair, IsSymbol, IsUpper и IsWhiteSpace См. также соответствующие методы для Rune типа. |
| Преобразовать объект Char, который представляет число, в значение числового типа | GetNumericValue См. также раздел Rune.GetNumericValue. |
| Преобразует символ в строке в объект Char | Parse и TryParse |
| Преобразовать объект Char в объект | ToString |
| Изменение регистра объекта Char | ToLower, ToLowerInvariant, ToUpper и ToUpperInvariant См. также соответствующие методы для Rune типа. |
Значения Char и взаимодействие
Когда управляемый тип Char, который представляется как кодовая единица в кодировке Юникода UTF-16, передается в неуправляемый код, маршалер взаимодействия по умолчанию преобразует символы в кодировку ANSI. Можно применить атрибут DllImportAttribute к объявлениям вызова неуправляемого кода и атрибут StructLayoutAttribute к объявлениям COM-взаимодействия для управления набором символов, используемым при маршалинге типа Char.
Представляет наибольшее возможное значение типа Char. Это поле является константой.
Представляет минимально допустимое значение типа Char. Это поле является константой.
Методы
Сравнивает данный экземпляр с заданным объектом Char и показывает, расположен ли данный экземпляр перед, после или на той же позиции в порядке сортировки, что и заданный объект Char.
Сравнивает данный экземпляр с заданным объектом и показывает, расположен ли данный экземпляр перед, после или на той же позиции в порядке сортировки, что и заданный объект Object.
Преобразует заданную кодовую точку Юникода в строку в кодировке UTF-16.
Преобразует значение суррогатной пары в кодировке UTF-16 в кодовую точку Юникода.
Преобразует значение символа в кодировке UTF-16 или суррогатную пару в заданной позиции в строке в кодовую точку Юникода.
Возвращает значение, указывающее, равен ли данный экземпляр указанному объекту Char.
Возвращает значение, показывающее, равен ли экземпляр указанному объекту.
Возвращает хэш-код данного экземпляра.
Преобразует указанный числовой символ Юникода в число двойной точности с плавающей запятой.
Преобразует числовой символ Юникода в указанной позиции в указанной строке в число двойной точности с плавающей запятой.
Возвращает TypeCode для типа значения Char.
Относит указанный символ Юникода к группе, определенной одним из значений UnicodeCategory.
Относит символ Юникода в указанной позиции к группе, определенной одним из значений UnicodeCategory.
Возвращает, true Если c является символом ASCII ([U + 0000.. U + 007F]).
Показывает, относится ли указанный символ Юникода к категории управляющих символов.
Показывает, относится ли символ в указанной позиции в указанной строке к категории управляющих символов.
Показывает, относится ли указанный символ Юникода к категории десятичных цифр.
Показывает, относится ли указанный символ Юникода в указанной позиции в указанной строке к категории десятичных цифр.
Определяет, является ли заданный объект Char старшим символом-заместителем.
Определяет, является ли объект Char в заданной позиции в строке старшим символом-заместителем.
Показывает, относится ли указанный символ Юникода к категории букв Юникода.
Показывает, относится ли указанный символ в указанной позиции в указанной строке к категории букв Юникода.
Показывает, относится ли указанный символ Юникода к категории букв или десятичных цифр.
Показывает, относится ли символ в указанной позиции в указанной строке к категории букв или десятичных цифр.
Показывает, относится ли указанный символ Юникода к категории букв нижнего регистра.
Показывает, относится ли указанный символ в указанной позиции в указанной строке к категории букв нижнего регистра.
Определяет, является ли заданный объект Char младшим символом-заместителем.
Определяет, является ли объект Char в заданной позиции в строке младшим символом-заместителем.
Показывает, относится ли указанный символ Юникода к категории цифр.
Показывает, относится ли указанный символ в указанной позиции в указанной строке к категории цифр.
Показывает, относится ли указанный символ Юникода к категории знаков препинания.
Показывает, относится ли указанный символ в указанной позиции в указанной строке к категории знаков препинания.
Показывает, относится ли указанный символ Юникода к категории знаков-разделителей.
Показывает, относится ли указанный символ в указанной позиции в указанной строке к категории знаков-разделителей.
Указывает, имеет ли заданный символ заменяющую кодовую единицу.
Указывает, имеет ли указанный символ в указанной позиции в указанной строке заменяющую кодовую единицу.
Определяет, образуют ли два заданных объекта Char суррогатную пару.
Определяет, образуют ли два смежных объекта Char в заданной позиции в строке суррогатную пару.
Показывает, относится ли указанный символ Юникода к категории символьных знаков.
Показывает, относится ли указанный символ в указанной позиции в указанной строке к категории символьных знаков.
Показывает, относится ли указанный символ Юникода к категории букв верхнего регистра.
Показывает, относится ли указанный символ в указанной позиции в указанной строке к категории букв верхнего регистра.
Показывает, относится ли указанный символ Юникода к категории пробелов.
Показывает, относится ли указанный символ в указанной позиции в указанной строке к категории пробелов.
Преобразует значение указанной строки в эквивалентный символ Юникода.
Преобразует значение символа Юникода в его эквивалент в нижнем регистре.
Преобразует значение указанного символа Юникода в его эквивалент в нижнем регистре, используя указанные сведения о форматировании, связанные с языком и региональными параметрами.
Преобразует значение символа Юникода в его эквивалент в нижнем регистре, используя правила изменения регистра, связанные с инвариантным языком и региональными параметрами.
Преобразует значение этого экземпляра в эквивалентное ему строковое представление.
Преобразует указанный символ Юникода в эквивалентное ему строковое представление.
Преобразует значение этого экземпляра в эквивалентное ему строковое представление с использованием указанных сведений об особенностях форматирования, связанных с языком и региональными параметрами.
Преобразует значение символа Юникода в эквивалентный символ верхнего регистра.
Преобразует значение указанного символа Юникода в его эквивалент в верхнем регистре, используя указанные сведения о форматировании, связанные с языком и региональными параметрами.
Преобразует значение символа Юникода в его эквивалент в верхнем регистре, используя правила изменения регистра, связанные с инвариантным языком и региональными параметрами.
Преобразует значение указанной строки в эквивалентный символ Юникода. Возвращает код, позволяющий определить, успешно ли выполнено преобразование.
Явные реализации интерфейса
Сравнивает текущий экземпляр с другим объектом того же типа и возвращает целое число, которое показывает, расположен ли текущий экземпляр перед, после или на той же позиции в порядке сортировки, что и другой объект.
Возвращает TypeCode для этого экземпляра.
Примечание. Это преобразование не поддерживается. Попытка его выполнения приводит к созданию исключения InvalidCastException.
Описание этого члена см. в разделе ToByte(IFormatProvider).
Описание этого члена см. в разделе ToChar(IFormatProvider).
Примечание. Это преобразование не поддерживается. Попытка его выполнения приводит к созданию исключения InvalidCastException.
Примечание. Это преобразование не поддерживается. Попытка его выполнения приводит к созданию исключения InvalidCastException.
Примечание. Это преобразование не поддерживается. Попытка его выполнения приводит к созданию исключения InvalidCastException.
Описание этого члена см. в разделе ToInt16(IFormatProvider).
Описание этого члена см. в разделе ToInt32(IFormatProvider).
Описание этого члена см. в разделе ToInt64(IFormatProvider).
Описание этого члена см. в разделе ToSByte(IFormatProvider).
Примечание. Это преобразование не поддерживается. Попытка его выполнения приводит к созданию исключения InvalidCastException.
Преобразует значение этого экземпляра в эквивалентную строку с использованием указанных сведений о форматировании для указанного языка и региональных параметров.
Описание этого члена см. в разделе ToType(Type, IFormatProvider).
Описание этого члена см. в разделе ToUInt16(IFormatProvider).
Описание этого члена см. в разделе ToUInt32(IFormatProvider).
Описание этого члена см. в разделе ToUInt64(IFormatProvider).
Форматирует значение текущего экземпляра, используя указанный формат.
Пытается отформатировать значение текущего экземпляра в указанный диапазон символов.
Применяется к
Потокобезопасность
Все члены этого типа являются потокобезопасными. Члены, которые могут изменить состояние экземпляра, в действительности возвращают новый экземпляр, инициализированный новым значением. Как с любым другим типом, чтение и запись общей переменной, которая содержит экземпляр этого типа, должны быть защищены блокировкой для обеспечения потокобезопасности.
4.11 – Символы
На данный момент базовые типы данных, которые мы рассмотрели, использовались для хранения чисел (целые числа и числа с плавающей запятой) или значений истина/ложь (логические значения). Но что, если мы хотим хранить буквы?
ASCII расшифровывается как American Standard Code for Information Interchange (Американский стандартный код для обмена информацией) и определяет конкретный способ представления английских символов (плюс несколько других символов) в виде чисел от 0 до 127 (называемых кодом ASCII или кодовым обозначением). Например, код ASCII 97 интерпретируется как символ ‘ а ‘.
Символьные литералы всегда помещаются в одинарные кавычки (например, ‘ g ‘, ‘ 1 ‘, ‘ ‘).
Ниже приведена полная таблица символов ASCII:
| Code | Symbol | Code | Symbol | Code | Symbol | Code | Symbol |
|---|---|---|---|---|---|---|---|
| 0 | NUL (null) | 32 | (space) | 64 | @ | 96 | ` |
| 1 | SOH (start of header, начало «заголовка») | 33 | ! | 65 | A | 97 | a |
| 2 | STX (start of text, начало «текста») | 34 | ” | 66 | B | 98 | b |
| 3 | ETX (end of text, конец «текста») | 35 | # | 67 | C | 99 | c |
| 4 | EOT (end of transmission, конец передачи) | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ (enquiry, «Прошу подтверждения!») | 37 | % | 69 | E | 101 | e |
| 6 | ACK (acknowledge, «Подтверждаю!») | 38 | & | 70 | F | 102 | f |
| 7 | BEL (bell, звуковой сигнал: звонок) | 39 | ’ | 71 | G | 103 | g |
| 8 | BS (backspace, возврат на один символ) | 40 | ( | 72 | H | 104 | h |
| 9 | HT (horizontal tab, горизонтальная табуляция) | 41 | ) | 73 | I | 105 | i |
| 10 | LF (line feed/new line, перевод строки) | 42 | * | 74 | J | 106 | j |
| 11 | VT (vertical tab, вертикальная табуляция) | 43 | + | 75 | K | 107 | k |
| 12 | FF (form feed / new page, «прогон страницы», новая страница) | 44 | , | 76 | L | 108 | l |
| 13 | CR (carriage return, возврат каретки) | 45 | — | 77 | M | 109 | m |
| 14 | SO (shift out, «Переключиться на другую ленту (кодировку)») | 46 | . | 78 | N | 110 | n |
| 15 | SI (shift in, «Переключиться на исходную ленту (кодировку)») | 47 | / | 79 | O | 111 | o |
| 16 | DLE (data link escape, «Экранирование канала данных») | 48 | 0 | 80 | P | 112 | p |
| 17 | DC1 (data control 1, первый символ управления устройством) | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 (data control 2, второй символ управления устройством) | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 (data control 3, третий символ управления устройством) | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 (data control 4, четвертый символ управления устройством) | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK (negative acknowledge, «Не подтверждаю!») | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN (synchronous idle) | 54 | 6 | 86 | V | 118 | v |
| 23 | ETB (end of transmission block, конец текстового блока) | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN (cancel, «Отмена») | 56 | 8 | 88 | X | 120 | x |
| 25 | EM (end of medium, «Конец носителя») | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB (substitute, «Подставить») | 58 | : | 90 | Z | 122 | z |
| 27 | ESC (escape) | 59 | ; | 91 | [ | 123 | < |
| 28 | FS (file separator, разделитель файлов) | 60 | 94 | ^ | 126 | ||
| 31 | US (unit separator, разделитель юнитов) | 63 | ? | 95 | _ | 127 | DEL (delete, стереть последний символ) |
Коды 0–31 называются непечатаемыми символами и в основном используются для форматирования и управления принтерами. Большинство из них сейчас устарели.
Коды 32–127 называются печатными символами и представляют собой буквы, цифры и знаки препинания, которые большинство компьютеров используют для отображения основного английского текста.
Инициализация переменных char
Вы также можете инициализировать переменные типа char целыми числами, но этого, если возможно, следует избегать.
Предупреждение
Будьте осторожны, чтобы не перепутать символы чисел с целыми числами. Следующие две инициализации не эквивалентны:
Символы чисел предназначены для использования, когда мы хотим представить числа в виде текста, а не в виде чисел и применения к ним математических операций.
Печать переменных типа char
Данная программа дает следующий результат:
Мы также можем напрямую выводить символьные литералы:
В результате это дает:
Напоминание
Печать переменных char как целых чисел через приведение типов
Однако это довольно коряво. Лучше использовать приведение типа. Приведение типа создает значение одного типа из значения другого типа. Для преобразования между базовыми типами данных (например, из char в int или наоборот) мы используем приведение типа, называемое статическим приведением.
Синтаксис статического приведения выглядит немного забавным:
Ключевые выводы
Всякий раз, когда вы видите синтаксис C++ (за исключением препроцессора), в котором используются угловые скобки, то, что между угловыми скобками, скорее всего, будет типом. Обычно C++ работает с концепциями, которым нужен параметризуемый тип.
Ниже показан пример использования статического приведения для создания целочисленного значения из нашего значения char :
Эта программа дает следующий вывод:
Важно отметить, что параметр static_cast вычисляется как выражение. Когда мы передаем переменную, эта переменная вычисляется для получения ее значения, которое затем преобразуется в новый тип. На переменную не влияет приведение ее значения к новому типу. В приведенном выше случае переменная ch по-прежнему является char и сохраняет то же значение.
О статическом приведении типов и других типах приведения мы поговорим подробнее в следующем уроке (8.5 – Явное преобразование типов (приведение) и static_cast ).
Ввод символов
Следующая программа просит пользователя ввести символ, а затем печатает его как символ и его код ASCII:
Ниже показан результат одного запуска:
Вы можете увидеть это поведение в следующем примере:
Размер, диапазон и символ по умолчанию у переменных char
char определяется C++ всегда размером 1 байт. По умолчанию char может быть со знаком или без знака (хотя обычно он со знаком). Если вы используете переменные char для хранения символов ASCII, вам не нужно указывать знак (поскольку переменные char со знаком и без знака могут содержать значения от 0 до 127).
Экранированные последовательности
В C++ есть некоторые символы, которые имеют особое значение. Эти символы называются экранированными последовательностями (управляющими последовательностями, escape-последовательностями). Экранированная последовательность начинается с символа ‘\’ (обратный слеш), за которым следует буква или цифра.
Вы уже видели наиболее распространенную экранированную последовательность: ‘ \n ‘, которую можно использовать для вставки символа новой строки в текстовую строку:
Эта программа выдает:
Еще одна часто используемая экранированная последовательность – ‘ \t ‘, которая включает горизонтальную табуляцию:
Три других примечательных экранированных последовательности:
Ниже приведена таблица всех экранированных последовательностей:
| Название | Символ | Назначение |
|---|---|---|
| Предупреждение | \a | Выдает предупреждение, например звуковой сигнал |
| Backspace | \b | Перемещает курсор на одну позицию назад |
| Перевод страницы | \f | Перемещает курсор на следующую логическую страницу |
| Новая строка | \n | Перемещает курсор на следующую строку |
| Возврат каретки | \r | Перемещает курсор в начало строки |
| Горизонтальная табуляция | \t | Печать горизонтальной табуляции |
| Вертикальная табуляция | \v | Печатает вертикальную табуляцию |
| Одинарная кавычка | \’ | Печать одинарной кавычки |
| Двойная кавычка | \» | Печать двойной кавычки |
| Обратная косая черта | \\ | Печатает обратный слеш |
| Вопросительный знак | \? | Печатает вопросительный знак Больше не актуально. Вы можете использовать вопросительные знаки без экранирования. |
| Восьмеричное число | \(число) | Преобразуется в символ, представленный восьмеричным числом |
| Шестнадцатеричное число | \x(число) | Преобразуется в символ, представленный шестнадцатеричным числом |
Вот несколько примеров:
Эта программа напечатает:
Новая строка ( \n ) против std::endl
В чем разница между заключением символов в одинарные и двойные кавычки?
Отдельные символы всегда заключаются в одинарные кавычки (например, ‘a’, ‘+’, ‘5’). char может представлять только один символ (например, букву а, знак плюса, цифру 5). Что-то вроде этого некорректно:
Текст, заключенный в двойные кавычки (например, «Hello, world!»), называется строкой. Строка – это набор последовательных символов (и, таким образом, строка может содержать несколько символов).
Пока вы можете использовать строковые литералы в своем коде:
Мы обсудим строки в следующем уроке (4.12 – Знакомство с std::string ).
Правило
Всегда помещайте отдельные символы в одинарные кавычки (например, ‘ t ‘ или ‘ \n ‘, а не » t » или » \n «). Это помогает компилятору более эффективно выполнять оптимизацию.
wchar_t следует избегать почти во всех случаях (за исключением взаимодействия с Windows API). Его размер определяется реализацией и не является надежным. Он не рекомендуется для использования.
В качестве отступления.
Англоязычный термин «deprecated» (не рекомендуется) означает «всё еще поддерживается, но больше не рекомендуется для использования, потому что он был заменен чем-то лучшим или больше не считается безопасным».
Подобно тому, как ASCII сопоставляет целые числа 0–127 с символами английского алфавита, существуют и другие стандарты кодировки символов для сопоставления целых чисел (разного размера) с символами других языков. Наиболее известной кодировкой за пределами диапазона ASCII является стандарт Unicode (Юникод), который сопоставляет более 110 000 целых чисел с символами на многих языках. Поскольку Unicode содержит очень много кодовых обозначений, то для одного кодового обозначения, чтобы представить один символ, Unicode требуется 32 бита (кодировка UTF-32). Однако символы Unicode также могут быть закодированы с использованием 16-ти или 8-ми битов (кодировки UTF-16 и UTF-8 соответственно).
char16_t и char32_t были добавлены в C++11 для обеспечения явной поддержки 16-битных и 32-битных символов Unicode. char8_t был добавлен в C++20.
А пока при работе с символами (и строками) вы должны использовать только символы ASCII. Использование символов из других наборов символов может привести к неправильному отображению ваших символов.



