Осваиваем компьютерное зрение — 8 основных шагов
Для тебя уже не является новостью тот факт, что все на себе попробовали маски старения через приложение Face App. В свою очередь для компьютерного зрения есть задачи и поинтереснее этой. Ниже представлю 8 шагов, которые помогут освоить принципы компьютерного зрения.

Прежде, чем начать с этапов давайте поймём, какие задачи мы с вами сможем решать с помощью компьютерного зрения. Примеры задач могут быть следующими:
Минимальные знания, необходимые для освоения компьютерного зрения
Шаг 1 — Базовые методики работы с изображениями
Этот шаг посвящен техническим основам.
Прочтите — третью главу книги Ричарда Шелиски «Компьютерное зрение: Алгоритмы и приложения».

Закрепите знания — попробуйте себя в преобразовании изображений с помощью OpenCV. На сайте есть много пошаговых электронных пособий, руководствуясь которыми можно во всём разобраться.
Шаг 2 — Отслеживание движения и анализ оптического потока
Оптический поток — это последовательность изображений объектов, получаемая в результате перемещения наблюдателя или предметов относительно сцены.
Пройдите курс — курс по компьютерному зрению на Udacity, в особенности урок 6.
Посмотрите — 8-ое видео в YouTube-списке и лекцию об оптическом потоке и трекинге.
Прочтите — разделы 10.5 и 8.4 учебника Шелиски.

В качестве учебного проекта разберитесь с тем, как с помощью OpenCV отслеживать объект в видеофрейме.
Шаг 3 — Базовая сегментация
В компьютерном зрении, сегментация — это процесс разделения цифрового изображения на несколько сегментов (суперпиксели). Цель сегментации заключается в упрощении и/или изменении представления изображения, чтобы его было проще и легче анализировать.
Так, преобразование Хафа позволяет найти круги и линии.
ComputerVision и с чем его едят
Как научить машину видеть?
Машинное зрение относится к Machine Learning, куда входят и семантические анализаторы, и распознаватели звуков, и прочее. Это сложная предметная область, и она требует глубоких знаний математики (в том числе, бррррр, тензорной математики). Существует множество алгоритмов, которые применяются при распознавании образов: VGG16, VGG32, VGG29, ResNet, DenseNet, Inception (V1, V2, V3, V… их сотни!). Наиболее популярными считаются VGG16 и Inception V3 и V4. Самый простой, популярный и больше всего подходящий для быстрого старта — VGG16, поэтому выбираем и ковыряем его. Начнем с названия VGG16 и выясним, что же в нём сакрального и как оно расшифровывается. И тут К.О. подсказывает, что всё просто: VGG — это Visual Geometry Group c факультета инженерных наук Оксфордского университета. Ну а 16 откуда? Тут чуть сложнее и уже напрямую связано с алгоритмом. 16 — число слоёв нейронной сети, которое используется для распознавания образов (наконец-то приступили к интересному, а то всё вокруг да около). И уже пора врубаться в самую суть матана. Сами они используют от 16 до 19 слоев и фильтры 3х3 на каждом уровне нейронной сети. Собственно, причин несколько: наибольшая производительность именно при таком количестве слоёв, точность распознавания (вполне достаточно и этого, ссылки на статьи, раз и два). Следует отметить, что нейронная сеть используется не простая, а улучшенная свёрточная нейронная сеть (Convolutional Neural Network (CNN) и Convolutional Neural Network with Refinement (CNN-R)).
А теперь разберёмся в принципах работы этого самого алгоритма, зачем нужна свёрточная нейронная сеть и с какими параметрами она работает. Ну и, конечно же, лучше сразу делать это на практике. Ассистента в студию!
Вот эта замечательная хаски станет нашим ассистентом, над ней мы и будем ставить эксперименты. Она уже светится от счастья и желает поскорее вникнуть в детали.
Итак, простыми словами: свёрточная нейронная сеть работает с двумя «командами» (сильно утрирую, но так будет понятнее). Первая — выдели фрагмент, вторая — попытайся найти объект целиком. Почему целиком? Имея в наличии набор мельчайших паттернов с контурами целых объектов, нейросети проще в дальнейшем получать характерные признаки и сравнивать их с изображением, которое требуется распознать. И тут нам поможет изображение алгоритма в конечном виде. Кто хочет изучить подробно, с тоннами матана — вот пруфлинк. А мы идём дальше.
Объяснить следующий алгоритм не так сложно. Это полный алгоритм работы свёрточной нейронной сети с модулем улучшения (вот тот самый, который обведён пунктиром и присутствует после каждого шага свёртки).
Первый шаг: пилим изображением пополам (с хаски проделано, но не так эффектно выглядит, как со слонами на рисунке). Потом ещё пополам, потом ещё и ещё, и так доходим до тараканов, в смысле до блока 14х14 и меньше (минимальный размер, как уже было сказано, 3х3). Между шагами — основная магия. А именно — получение маски целого объекта и вероятности нахождения целого объекта на отпиленном куске. После всех этих манипуляций получаем набор кусочков и набор масок к ним. Что теперь с ними делать? Ответ прост: при уменьшении изображения мы получаем деградацию соседних пикселей, что упростит построение маски в упрощённом виде и даст возможность увеличить вероятность различения переходов между объектами.
На основе анализа уменьшенных изображений строятся независимые исходные описания и затем результат усредняется для всех масок. Но следует отметить, что данный вариант не самый лучший при сегментации объекта. Усреднённая маска не всегда может быть применима при небольших различиях цвета между объектами и фоном (вот почему именно такое тестовое изображение было выбрано).
Предложенный подход более-менее работоспособен, но для объектов, которые целиком находятся на изображении и контрастируют с фоном, в то же время разделение двух одинаковых или схожих объектов (далеко за примером ходить не будем: стадо овец, у всех белая шерсть) вызовет значительные затруднения.
Для получения адекватной пиксельной маски и разделения объектов необходимо доводить алгоритм до ума.
И вот теперь настал момент спросить: а зачем нам этот «модуль-улучшайзер» вообще нужен, если вроде как всё и так неплохо?
Мы добавляем на каждом шаге не только построение маски, но и использование всей информации, полученной из низкоуровневых функций совместно со знаниями о высокоуровневых объектах, которые распознаны в верхних слоях нейронной сети. Наряду с получением независимых результатов на каждом шаге производится генерация и грубое распознавание, результатом является семантически полная функциональная мультиканальная карта, в которую интегрируется только положительная информация из ранних слоев.
В чём отличие классической свёрточной нейронной сети и улучшенной свёрточной нейронной сети?
Каждый этап уменьшения исходного изображения позволяет получить кодированную маску, сгенерированную при прохождении от общего изображения к уменьшенному. Вместе с этим в усовершенствованной свёрточной нейронной сети происходит движение от меньшего изображения к большему с получением характерных функций (точек). Итогом является маска, полученная в результате двунаправленного слияния функций и характерных точек.
Звучит достаточно запутанно. Попробуем применить к нашему изображению.
Эффектно. Это называется DeepMask — грубые границы объектов на изображении. Попробуем разобраться, почему так. Начнём с простого — с носа. При деградации изображения контраст очевиден, поэтому нос и выделен как самостоятельный объект. То же самое и с ноздрями: на определённых уровнях свёртки они стали самостоятельными объектами за счёт того, что находились полностью на фрагменте. Кроме того, отдельно обведена морда второй собаки (как, не видите? Да вот же она, прямо перед вами!). Кусок руки был признан фоном. Ну что поделать? С основной частью фона по цвету не контрастирует. Зато переход «рука-футболка» выделен. И погрешность в виде пятна «рука-сетка», и большое пятно, захватывающее фон и голову хаски.
Что ж, результат интересный! Как же можно помочь алгоритму справиться с задачей лучше? Только если поиздеваться над нашим помощником. Для начала попробуем сделать его в градациях серого. Мда… Фото хуже, чем в паспорте. После этого лаборанту уже нечего терять, я только включил один фильтр, и всё завертелось… Сепия, а за ней соляризация, накладывание и вычитание слоёв, размытие фона со сложением изображений — в общем, что видел, то и применял; главное, чтобы объекты становились заметнее на изображении. Как говорится, картинка в фотошопе всё стерпит. Поиздевались, пора бы и посмотреть, как теперь будет распознано изображение.
Нейросеть сказала: «Здесь нет того, кого можно хоть как-то классифицировать». Логично, контрастные только нос и глаза. Не слишком характерно при небольшом наборе для обучения.
Ух, жуть какая (прости, друг)! Но здесь мы серьёзно прибавили контраста объектам на изображении. Как? Берём и дублируем изображение (можно несколько раз). На одном выкручиваем контраст, на другом — яркость, на третьем — пережигаем цвета (делаем их неестественно яркими) и потом всё это складываем. И напоследок попробуем запихнуть многострадальную хаски в обработку.
Надо сказать, что стало лучше. Не прям «ух, как круто», но получше. Уменьшилось число неполных объектов, появился контраст между объектами. Дальнейшие эксперименты с предварительной обработкой дадут больший контраст: объект — объект, объект — фон. Получим 4 сегмента вместо 8. С точки зрения обработки большого потока картинок (150 изображений в минуту) лучше вообще не заморачиваться с предварительной обработкой. Она — так, поиграться на домашнем компьютере.
Идём дальше. SharpMask практически отличаться не будет. А SharpMask — это построение уточнённой маски объектов. Алгоритм с улучшением тот же.
Главная проблема DeepMask в том, что эта модель использует простую сеть прямого распространения, которая успешно создаёт «грубые» маски, но не выполняет сегментацию с точностью до пикселя. Пропускаем пример для этого шага, так как хаски и так нелегко живётся.
Последний шаг — попытка распознать то, что получилось после уточнения маски.
Запускаем быстро собранное демо и получаем результат — целых 70%, что это собака. Неплохо.
Но как машина поняла, что это собака? Вот мы напилили кусков, получили красивые маски, матрицы к ним и наборы признаков. Что дальше-то? А дальше всё просто: у нас есть обученная сеть, у которой есть эталонные наборы признаков, масок и прочее, прочее, прочее. Ну, есть они, и что дальше-то? Вот наша хаски с набором признаков, вот эталонная сферическая собака в вакууме с набором признаков. Тупое сравнение в лоб делать нельзя, потому как недостаток признаков у изображения, которое мы распознаём, приведёт к ошибке. И что же делать? Для этого придумали такой замечательный параметр, как dropout, или рандомный сброс параметров сети. Это значит следующее: берутся оба набора и из каждого из них рандомно удаляются признаки (проще говоря, есть наборы по 10 признаков, dropout = 0.1; по одному признаку отбрасываем, далее сравниваем). А в результате? А в результате — PROFIT.
Cразу отвечу на вопрос, почему вторая собака — не собака, а рука — не человек. Тестовая выборка была всего на 1000 изображений котов и собак. Обучалась всего в два шага эволюции.
Вместо выводов
Итак, мы получили картинку и результат, что это собака (нам очевидно, а для нейросети было не очень). Обучение проводилось всего в два шага и не было эволюции модели (что очень важно). Изображение грузилось как есть, без обработки. В дальнейшем планируется проверить, сможет ли нейросеть распознать собак по минимальному набору признаков.
Как устроено компьютерное зрение?
Мы запускаем камеру на смартфоне, наводим на объект и видим маленькую иконку внизу. Смартфон понимает — что именно мы снимаем. Вы когда-нибудь задумывались, как это работает?
Беспилотные автомобили спокойно объезжают машины и тормозят перед пешеходами, камеры видеонаблюдения на улицах распознают наши лица, а пылесосы отмечают на карте, где лежат тапочки — всё это не чудеса. Это происходит прямо сейчас. И всё благодаря компьютерному зрению.
Поэтому сегодня разберем, как работает компьютерное зрение, чем оно отличается от человеческого и чем может быть полезно нам, людям?
Для того чтобы хорошо ориентироваться в пространстве человеку нужны глаза, чтобы видеть, мозг, чтобы эту информацию обрабатывать, и интеллект, чтобы понимать, что ты видишь. С компьютерным или, даже вернее сказать, машинным зрением, такая же история. Для того, чтобы компьютер понял, что он видит, нужно пройти 3 этапа:
Пройдёмся по всем этапам и проверим, как они реализованы. Сегодня мы будем разбираться, как роботы видят этот мир, и поможет нам в этом робот-пылесос, который напичкан современными технологиями компьютерного зрения.
Этап 1. Получение изображения
В начале компьютеру надо что-то увидеть. Для этого нужны разного рода датчики. Насколько много датчиков и насколько они должны быть сложные зависит от задачи. Для простых задач типа детектора движения или распознавания объектов в кадре достаточно простой камеры или даже инфракрасного сенсора.
В нашем пылесосе есть целых две камеры, они находятся спереди. А вот, например, для ориентации в трехмерном пространстве понадобятся дополнительные сенсоры. В частности 3D-сенсор. Тут он тоже есть и расположен сверху. Но что это за сенсор?
LiDAR
Вообще с названиями 3D-сенсоров есть небольшая путаница, одно и тоже часто называют разными словами.
Эта штука сверху — называется LDS или лазерный датчик расстояния, по-английски — Laser Distance Sensor. Подобные датчики вы наверняка могли заметить на крышах беспилотных беспилотных автомобилей. Это не мигалка, это лазерный датчик расстояния, такой же как на роботе пылесосе.
Вот только в мире беспилотников такой сенсор принято называть лидаром — LIDAR — Light Detection and Ranging. Да-да, как в новых iPhone и iPad Pro.

А вот в Android-смартфонах вместо лидаров используется термин ToF-камера: ToF — Time-of-flight.
Но, как ни называй, все эти сенсоры работают по одному принципу. Они испускают свет и замеряет сколько ему понадобится времени, чтобы вернуться обратно. То есть прямо как радар, только вместо радиоволн используется свет.
Есть небольшие нюансы в типах таких сенсоров, но смысл технологии от этого не меняется. Поэтому мне, чисто из-за созвучия с радаром, больше всего нравится название LiDAR, так и будем называть этот сенсор.
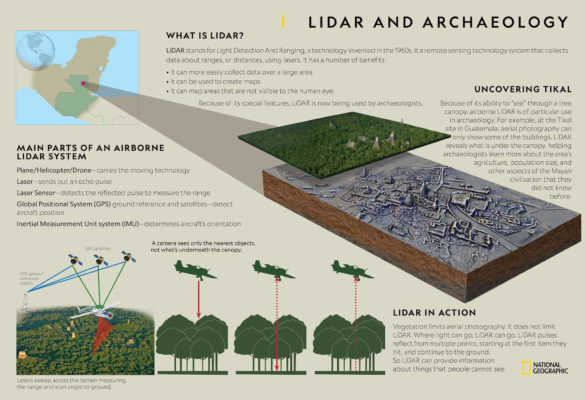
Кстати, лидары использует не только в задачах навигации. Благодаря лидарам сейчас происходит настоящая революция в археологии. Археологи сканируют территорию с самолета при помощи лидара, после чего очищают данные ландшафта от деревьев. И это позволяет находить древние города, скрытые от глаз человека!
Также помимо статических лидаров, направленных в одну сторону, бывают вращающиеся лидары, которые позволяют сканировать пространство вокруг себя на 360 градусов. Такие лидары используется в беспилотных автомобилях, ну и в этом роботе-пылесосе.
Еще 8 лет назад такие сенсоры стоили каких-то невероятных денег, под 100 тысяч долларов. А теперь у вас по дому может спокойно ездить маленький беспилотник.
Лидар в пылесосе
Окей, тут лидар используется для построения карты помещения и это не новая история. Такую технологию мы видели еще года 3-4 назад.
Благодаря лидару и построенной карте, пылесос ездит не рандомно как скринсейвер в Windows, стукаясь об углы, а аккуратно проезжая всю площадь (модели без лидаров обычно катаются странно).
Но внутри пылесоса стоит, на секундочку, восьмиядерный Qualcomm Snapdragon 625 (Qualcomm APQ8053), поэтому у него хватает мозгов не только построить карту, но и ориентироваться по ней.
Более того пылесос может хранить в памяти до четырёх карт и распознаёт этажи. Это существенно ускоряет уборку. Потому при переносе с этажа на этаж пылесос это может понять и не тратит время, чтобы построить карту заново.

Также каждую из 4 карт можно поделить на 10 специальных зон. Для которых можно настроить свои параметры уборки: мощность всасывания (до 2500 Па), количество проходов и прочее. А куда-то можно вообще запретить ездить. Можно даже выбирать сухую и влажную уборку для разных зон. Правда для этого не нужно подключать/отключать отдельный резервуар с водой. И всё это стало возможно благодаря лидару.
Тем не менее у технологии есть некоторые недостатки — очень разреженные данные. Пространство сканируется линиями. В больших автомобильных радарах разрешение — от 64 до 128 линий. Плюс ко всему у лидар есть мертвая зона. Если лидар стоит на крыше — то он не видит, что творится в достаточно большом радиусе вокруг него.
Также в роботе-пылесосе лидар тут сканирует пространство всего одним лучом. Поэтому, всё что он видит — это тонкая линия на высоте где-то 9-10 сантиметров от пола. Это позволяет определять где стены и мебель, но он не видит того, что валяется на полу.
Две камеры
Поэтому, чтобы исправить этот недочет лидаров. как в автомобили, так и в пылесосы ставят дополнительные камеры. Тут камеры сразу две, и они обеспечивают стереоскопическое зрение. Да-да, у пылесоса всё как у людей — два глаза.
Две камеры, во-первых, позволяют убрать мертвую зону впереди пылесоса. А во вторых позволяют достаточно точно определять расстояние до валяющихся на полу предметов.
Это позволяет пылесосу обнаруживать предметы размером не менее 5 см в ширину и 3 см в высоту и объезжать их.
Этап 2. Обработка
Итак, мы получили достаточно данных с различных сенсоров. Поэтому переходим ко второму этапу компьютерного зрения — обработке.
Данные с лидара мы получаем в виде трехмерного облака точек, которые фактически не нуждаются в дополнительной обработке.
Как получить стерео с двух камер тоже понятно — высчитывается разница между изображениями снятыми чуть под разным углом и так строится карта глубины. Это несложно.
Но вот совместить данные с разных сенсоров — это нетривиальная задача.
Например, пылесос на полу обнаружил какой-то предмет. Дальше ему нужно понять где именно он находится на карте построенной при помощи лидара. А также нужно предположить какие у него габариты по проекции с одной стороны. То есть нам нужно поместить предмет в некий объёмный куб правильного размера.

Эту задачу можно решить разными способами. Один из способов называется “усеченная пирамида”. Сначала на камере обнаруживаются предметы. Потом эти предметы помещаются в конус, а объем этого конуса вычисляется нейросетью.
Поэтому даже, казалось бы, такая тривиальная задача требует серьёзных вычислений и решается при помощи нейросетей.
А раз мы заговорили про нейросети, значит мы уже немного зашли на 3-й этап компьютерного зрения — анализ.
Этап 3. Анализ
За распознавание, сегментацию и классификацию объектов на изображении в современном мире в основном отвечают нейросети. Мы даже делали подробный ролик о том как это работает, посмотрите.
Если кратко, нейросеть — это такое большое количество уравнений, связанных между собой. Загружая в нейросеть любые данные — ты обязательно получишь какий-то ответ.
Но, например, если постоянно загружать в нейросеть фотографии кошечек, и указать ей, что ответ должен быть — кошка. В какой-то момент, нейросеть перестает ошибаться на обучающей выборке. И тогда ей начинают показывать новые незнакомые изображения и если на них она тоже безошибочно определяет кошек — нейросеть обучена.
Дальше нейросеть оптимизируется для того, чтобы она стала меньше, быстро работала и не жрала много ресурсов. После этого она готова к использованию.
Что-то похожее происходит с нейронными связями в человеческом мозге. Когда мы чему-то учимся или запоминаем, мы повторяем одно и то же действие несколько раз. Нейронные связи в мозге постепенно укрепляются и потом нам это легко даётся!
Например, в данном пылесосе за работу нейросети отвечает встроенный NPU-модуль. Всё-таки внутри Snapdragon, пылесос может себе такое позволить.
Нейронка предобучена определять различные предметы домашнего обихода: игрушки, тапочки, носки, всякие удлинители, зарядки и даже неожиданности от домашних животных.
Распознавание предметов происходит при помощи гугловской библиотеке Tensorflow. Алгоритм самообучается и умнеет от уборки к уборке.
Практика
В нашем роботе-пылесосе технология распознавания называется Reactive AI. Мы протестировали насколько она хорошо работает на практике.
Кайфовая штука, что все найденные предметы пылесос отмечает не карте. Поэтому теперь, я не обещаю, но такое возможно, вы всё-таки обнаружите логово пропавших носков.
Проследить за тем, что видит пылесос всегда можно через фирменное приложение или Mi Home от Xiaomi. Можно даже просто кататься по дому управляя пылесосом слать на него голосовые сообщения. Управлять пылесосом можно также через Google Ассистента или Алису. Всё на русском языке.
С недавних пор бренд начал официально продаётся в России, поэтому устройства полностью локализованные.
Внутри кстати стоит батарейка на 5200 мАч, которая способна выдержать до 3 часов уборки.
Итоги

Ребят, ну вы сами всё видели. Правда, стоит обратить внимание, что пока корректное распознавание предметов работает только если запускать пылесос через специальное приложение. И это нюанс, поскольку оно пока недоступно в Play Market Россия. Но в течение нескольких месяцев оно появится.
Компьютерное зрение. Ответы экспертов Intel
Две недели назад мы предложили читателям Хабры задать свои вопросы создателям библиотеки компьютерного зрения OpenCV. Вопросов было задано много, причем, интересных — значит, эта тема интересует не только компанию Intel, но и широкие массы разработчиков. Без лишних слов переходим к публикации ответов и приглашаем к их обсуждению. А также объявляем авторов лучших вопросов! В самом конце поста.

Вопрос noonv
Каким вы видите будущее компьютерного зрения? Наблюдая за развитием машинного обучения, какие перспективы вы видите?
Анатолий Бакшеев. Несколько моих мыслей:
Вадим Писаревский. Мое видение достаточно стандартно. Ближайшее будущее (вообще-то уже настоящее) за глубоким/глубинным обучением, причем оно будет применяться все более изощренным и нетривиальным образом, что доказала прошедшая конференция CVPR 2017. 6 лет назад deep learning появился, точнее, возродился после статьи Крыжевского (Alexnet), и тогда он хорошо решал только одну задачу – распознавание класса объекта при условии нахождения одного доминирующего объекта в кадре, без определения его положения. 2 года назад про него уже говорили почти все в нашей области. Придумали первые сетки для детектирования объектов и сетки для семантической сегментации. До этого задача семантической сегментации считалась безнадежной, нерешаемой задачей, как доказательство теоремы Ферма.
Имелась большая проблема со скоростью – все работало очень медленно. Сейчас сетки сжали, реализации оптимизировали, переложили на GPU, специализированное железо на подходе и вопрос скорости по большей части отпал и полностью отпадет в ближайшие пару лет – сетки уже работают в целом так же быстро, как и традиционные подходы, и при этом существенно лучше. Сейчас основные области для исследования:
Вопрос IliaSafonov
Нет ли планов добавить в OpenCV возможность обрабатывать 3D (volumetric) изображения? Работаю с томографическими изображениями размера порядка 4000х4000х4000. Существующие open-source библиотеки для 3D, мягко говоря, бедноваты и медленноваты по сравнению с OpenCV.
Вадим. Базовые поэлементные функции уже могут работать с такими данными. 3х-мерной фильтрации и каких-то других более сложных алгоритмов пока нет. Но, правда, есть глубокие сетки, которые могут делать некоторые преобразования над 3D массивами данных. Если есть список нужных операций, приглашаю подать запрос на расширение функциональности. Если будет хороший детальный запрос с описанием задачи, со ссылками, то, вполне возможно, что это станет одним из наших проектов для следующего Google Summer of Code (лето 2018).
Вопрос MaximKucherenko
Видеокамера висит на мосту, под которым идет поток автомобилей. Для видеокамеры установлено отличное освещение, в нормальную погоду ночью можно даже лица водителей рассматривать. Когда же начинается метель, снимки получаются почти белыми (из-за большого количества мелких движущихся объектов, снежинок). Можете подсказать, как побороть такой «шум»?
Анатолий. Сложно ответить, не имея самих изображений. Можно попробовать сделать CNN которая бы как-то восстанавливала картинку. Посмотрите работы по CNN impainting, где сетка «додумывает» испорченные части изображения. Или CNN debluring, где сетка, по сути, пытается выучить классический Debluring алгоритм. То же можно попробовать сделать и вам.
В вашем случае сетка может быть в каком-то месте рекуррентной, чтобы учитывать предыдущие кадры для синтеза «чистого» изображения.
Вадим. Нужен какой-то вариант temporal filtering с учетом движения машин и камеры – т.е. надо собирать кадры из нескольких, мы говорим про некую вариацию на тему video superresolution, но без повышения разрешения. Берется временная окрестность каждого кадра, вычисляется плотный оптический поток между центральным кадром и соседними по времени, составляется некая функция штрафа для результирующего «улучшенного» изображения – оно одновременно должно быть гладким и похожим на все изображения из окрестности с учетом скомпенсированного движения. Потом запускается итеративный процесс оптимизации. Не уверен что такой алгоритм будет производить чудеса, особенно в экстремальных условиях (метель), но в ситуациях умеренной сложности, возможно, получится улучшить изображение на выходе. Но в самом начале, без такого алгоритма, можно попробовать функцию cv::equalizeHist(), может она что-то даст.
Вопрос uzh13
Какой язык лучше всего подходит для экспериментов с CV? Стоит ли разбираться с Erlang для этого?
Есть ли канонический набор книг или цикл статей, для быстрого старта с техническим зрением? Есть ли с кем пообщаться?
Вадим. В данный момент наиболее предпочтительные варианты:
Анатолий. С++ и Python – это, по-моему классика для быстрого прототипирования и для серьезных решений никуда от этого не деться.
В дополнение к ответу Вадима рекомендую awesome репозитории на github:
Вопрос ChaikaBogdan
Как начать свою карьеру в области CV, если ты не имеешь в нем опыта? Где набраться опыта решения реальных задач и стажа в этой области, который так любят HRы?
Я отучился в ВУЗе, где не было такого направления и, естественно, пошел работать в другую область (программная инженерия, автоматизация). Будь у меня возможность и понимание, насколько потенциально круто работать в области CV, я бы поступил на него пусть даже в другой ВУЗ, но, увы, я узнал о нем слишком поздно. Переучиваться на второе высшее уже как-то непозволительно долго.
По долгу службы попалась задача детектирования с помощью Python+OpenCV, решил кое-как через template match (благо предметная область позволяла). Было весело, ново и вообще всем понравилось, особенно мне.
Начал изучать возможность самообучения, прошел курс Introduction to Computer Vision (Udacity-Georgia Tech) и начал практические от PyImageSearch.
Параллельно смотрел вакансии на Upwork и PyImageSearch Jobs, Fiverr и расстраивался, так как знаний явно не хватает для решения реальных задач (например, почти везде мешают light/shadow/angle conditions). Не уверен, что даже полное прохождение, скажем, Guru курса от PyImageSearch поможет найти достойную работу, ибо примеры уж очень «идеальные» и редко работают, как задумывались в реальных условиях.
На биржах типа Fiverr, Upwork, PyImageJobs большая конкуренция и требуется выполнение задач очень быстро. А хочется чего-то с небольшим порогом вхождения и взлетной learning-curve. Про удаленную работу вообще молчу. Плюс, везде еще хотят deep/machine learning вдогонку.
Бросать основную работу ради того, чтобы не найти себе работу в CV, как-то не хочется. Но и опускать руки тоже. Это же крутая и интересная область, чтобы развиваться профессионально, как ни смотри).
Анатолий. Я думаю, вы на правильном пути.
Вообще, если человек хочет работать в данной области, думаю, любой нормальный руководитель возьмет его к себе даже без навыков. Главное продемострировать желание работать, выраженное в конкретных действиях: показать алгоритмы, которые вы сделали для OpenCV, для caffe/tf/torch, показать ваши проекты на github, показать ваш рейтинг на Kaggle. У меня есть инженер, который ушел с предыдущей скучной не-CV работы, уехал в Тайланд и год нигде не работал. Через полгода ему там стало скучно, и он начал участвовать в Kaggle соревнованиях. Потом когда он пришел ко мне, его хороший рейтинг на Kaggle тоже сыграл свою роль даже без опыта в CV. Сейчас это один из сильнейших моих инженеров.
Вадим. У меня есть для вас «история успеха». Одно время в OpenCV была подана серия патчей с добавлением функциональности по распознаванию лиц. Конечно, сейчас задачу распознавания лиц решают с помощью deep learning, а тогда это были достаточно простые алгоритмы, но не суть. Автор кода был некий человек из Германии по имени Филипп. Он тогда на основной работе занимался скучными проектами, по его собственным словам, программировал DSP. Нашел время после работы заняться распознаванием лиц, подготовил патчи, мы их приняли. Естественно, он там был указан как автор. Через некоторое время он мне написал радостное письмо что в том числе благодаря такому наглядному «резюме» нашел работу, связанную со компьютерным зрением.
Конечно, это далеко не единственный путь. Просто если вам действительно нравится компьютерное зрение, приготовьтесь заниматься им сверхурочно на добровольных началах, нарабатывайте практический опыт. А насчет образования – как вы думаете, сколько человек из команды OpenCV получили образование в этой области? Ноль. Все мы по образованию математики, физики, инженеры. Важны общие навыки (которые развиваются практикой) изучать новый материал, в-основном на английском, программировать, общаться, решать математические и инженерные задачи. А конкретные знания – это преходящее. С появлением deep learning несколько лет назад большая часть наших знаний стала устаревшей, а через несколько лет может и deep learning станет устаревшей технологией.
Вопрос aslepov78
Не кажется ли вам что вы поддались массовой истерии по поводу нейронных сетей, глубинного обучения?
Вадим. Перефразируя Уинстона Черчилля, возможно, [современное] глубинное обучение — это плохой способ решать задачи компьютерного зрения, но все остальные известные нам – еще хуже. Но монополии на исследования нет ни у кого, слава богу, придумывайте свое. И на самом деле люди придумывают. Я сам был большим скептиком этого подхода несколько лет назад, но, во-первых, результаты налицо, а во-вторых, оказалось, что глубинное обучение можно применять не тупо (взял первую попавшуюся архитектуру, набрал миллион тренировочных примеров, запустил кластер и через неделю получил модель или не получил), а можно применять творчески. И тогда это становится поистине волшебной технологией, и начинают решаться задачи, к которым до этого вообще непонятно было, как подступиться. Например определение 3D поз игроков на поле с одной камеры.
Вопрос aslepov78
OpenCV превратился в склад алгоритмов из разных областей (вычислительная геометрия, обработка сигнала, machine learning и т.д.). А между тем, есть более продвинутые библиотеки по той же вычислительной геометрии (не говоря о нейросетях). Выходит, смысл OpenCV только в одном — все зависимости в одном флаконе?
Вадим. Мы делаем инструмент прежде всего для себя и наших коллег, а также интегрируем патчи от сообщества пользователей (не все, правда, но большую часть), т.е. то, что пользователи считают полезным для себя и других. Было бы хорошо, конечно, если бы в C++ была некая общая модель – как писать библиотеки так, чтобы они были друг с другом совместимыми, и их можно было бы легко использовать совместно и не было бы проблем с построением и конвертированием структур данных. Тогда, возможно, OpenCV могла бы быть безболезненно заменена серией более специальных библиотек. Но такой модели пока нет, и, может, и не будет. В Питоне есть подобная модель, построенная вокруг numpy и системы модулей и расширений, и питоновские обертки для OpenCV, как мне кажется, довольно органично туда встроены. Я думаю, если вы практически поработаете в области CV несколько лет, то придет понимание, зачем нужна OpenCV и почему она устроена так, как устроена. Или не придет.
Вопрос aslepov78
Почему так мало готовых решений? Например, если я новичок в CV, и хочу искать черный квадрат на белом фоне, то открыв доку OpenCV, я утону в ней. Вместо этого я бы хотел полистать список наиболее типичных и простых задач и выбрать, или скомбинировать. Т.е. в OpenCV практически нет декларативного подхода.
Вадим. По правде говоря, в OpenCV вообще нет готовых решений. Готовые решения в компьютерном зрении стоят больших денег и пишутся под конкретного заказчика для решения конкретных, очень четко поставленных задач. Процесс создания таких решений отличается от комбинирования блоков примерно так же, как процесс проектирования, строительства и обустройства индивидуального дома под заказ отличается от сборки игрушечного домика из кубиков лего.
Вопрос vlasenkofedor
Анатолий. У нас мало опыта работы с данными устройствами
Вопрос killla
Есть ли небольшие платы (уровня Raspberry Pi с процессором, заточенным под видеообработку OpenCV) и видеокамерой, подключенной напрямую к микропроцессору (микроконтроллеру) без всяких посредников в виде USB и его больших задержек? Чтобы можно было бы взять его и на коленке быстро сделать устройство для подсчета ворон на грядке или устройство для слежения за объектом (простейшая обработка изображения + реакция с минимальными задержками на раздражители).
Вадим. Raspberry Pi, начиная со второго поколения, содержит ARM CPU с векторными инструкциями NEON. OpenCV довольно шустро должна работать на такой железке. Касательно скорости захвата видео – мы как-то из USB 2 выжимали 20-30 кадров/сек, не очень понятно о чем речь.
Вопрос killla
Есть ли готовые дистрибутивы и софт «из коробки» под такие железки, с которым можно сразу начать работать, не допиливая неделями?
Вадим. OpenCV собирается под любой ARM Linux и в значительной степени оптимизирована с использованием NEON. Думаю, на Raspberry Pi стоит смотреть в первую очередь, например, вот опыт энтузиаста.
Вопрос killla
Обобщая, задам вопрос так: можно ли в 2017-2018 году студенту 2-3 курса IT-специальности с базовыми навыками программирования, уложившись в 10000 руб., достать железку уровня 2-3 летнего телефона, на которой за 2-4 недели изучения OpenCV и написания кода создать простейшее устройство: камеру на мотоподвесе с парой осей движения, которая будет висеть на балконе и следить за движением любимой собаки во дворе?
Вадим. По железной части ответа не дам, исследуйте. Насчет слежения за собакой. Радиомаячок решит эту задачу проще, дешевле, надежнее. Если не стоит цель решить задачу, а хочется потренироваться в компьютерном зрении, то пожалуйста. За 2-4 недели можно побаловаться и заодно начать задумываться над вопросами типа:
Вопрос almator
Не работает функция model = cv2.ANN_MLP() на питоне.
Ошибка AttributeError: ‘module’ object has no attribute ‘ANN_MLP’
Вадим. Посмотрите пример letter_recog.py из поставки OpenCV.
Вопрос almator
Как OpenCV будет развиваться в сторону нейросетей, машинного обучения? Где есть простые примеры для начинающих по машинному обучению? Желательно на русском.
Анатолий. В OpenCV не планируется тренировка сетей, только быстрый оптимизированный inference. У нас уже есть CNN Face Detector который может работать больше 100fps на современном Core i5 (правда выложить мы его в публичный доступ не можем). Думаю многие текущие алгоритмы будут постепенно инструментированы небольшими (>5000fps) вспомогательными сеточками, будь то featues или optical flow, или RANSAC, или любой другой алгоритм.
Вадим. OpenCV будет развиваться в сторону глубинного обучения. Обычные нейронные сети являются частным случаем и сейчас нас мало интересуют. На русском ничего посоветовать не могу, но буду признателен, если найдете и сообщите. На английском есть онлайн курсы и книжки в сети, тот же учебник по deep learning, упомянутый выше.
Вопрос almator
Каким алгоритмом лучше искать относительно сложные логотипы на фотографии — например, логотипы различных маркировок, где обычно присутствует и текст, и рисунки, и все вписано в форму? Пробовал через Haar Cascade — этот алгоритм хорошо ищет цельные куски, а такой сложный многосоставной объект, как логотип, не находит. Попробовал MatchTemplate — не ищет, если происходит минимальное несовпадение — уменьшение, поворот относительно исходной картинки. Не подскажете, в каком направлении искать?
Вадим. Глубокие сетки + аугментация тренировочной базы. То есть, вам нужно собрать базу изображений этого логотипа, а потом искусственно расширить ее во много раз. Вот, например, сходу находится через Гугл.
Вопрос WEBMETRICA
Можно ли с помощью компьютерного зрения смоделировать аналоги зрения различных биологических организмов, например, животных и насекомых и создать приложение, дающее возможность увидеть мир глазами других существ?
Анатолий. Я думаю, это произойдет еще не скоро. Более того, не существует метода достоверно сказать, как видят мир другие существа.
Вадим. На CVPR 2017 была интересная статья об использовании считанных с человека сигналов для распознавания образов. Авторы пообещали интересное продолжение. Возможно, скоро и до братьев наших меньших доберутся.
Вопрос WEBMETRICA
Если пойти еще дальше, то можно создать множество моделей зрения различных живых существ, пропустить всё это многообразие через нейросеть и создать нечто новое? Возможен ли синтез зрения различных биологических систем?
Вадим. Возможно все. Нужно идти от конкретной задачи, мне кажется.
Вопрос barabanus
Почему нельзя умножить матрицу на вектор (cv::Vec_) в OpenCV, но при этом можно умножить на точку? (cv::Point_) Получается, что проще манипулировать с точками тогда, когда математически это не точки, а вектора. Например, направление линии легче хранить как точку, а не как вектор — меньше преобразований типов в цепочке операций.
Анатолий. Мне известна эта проблема уже лет 8. Насколько я помню, это невозможно реализовать — можете сами попробовать. Там получается что-то вроде неоднозначности вызова конструктора для служебного промежуточного типа — компилятор не может сам решить, какой конструктор вызывать и выдает ошибку. Вам вручную придется преобразовать в точку через cv::Mat * Point_ (Vec_ ).
Вадим. Предлагаю подать запрос. Возможно, что в данном конкретном случае просто пропустили эту функцию, или намеренно ее отключили, чтобы не запутать C++ компилятор во всем множестве перекрытых операторов ‘*’ – иногда это случается.
Вопрос barabanus
Почему до сих пор в OpenCV нет ни одной реализации Hough Transform, которая возвращала бы аккумулятор. Ведь иногда надо найти, скажем, единственный максимум! Разрешат ли держатели проекта добавить новую реализацию, которая возвращала бы аккумулятор?
Вадим. Да, это было бы полезно. После рецензирования и необходимой доработки, если она понадобится, такой патч можно принять.
Вопрос perfect_genius
Пробует ли Intel создавать аппаратные нейросети для обработки изображений и есть ли результаты?
Анатолий. Аппаратные сети имеют мало смысла, потому что прогресс очень быстро двигается вперед, и такая железка будет устаревать прежде, чем выйдет в продажу. А вот создание ускоряющих инструкций для сетей (а-ля MMX/SSE/AVX) или даже сопроцессоров, по-моему, очень даже логичный шаг. Но мы информацией не владеем.
Вадим. На данном этапе нам известны попытки, и наши коллеги в них принимают активное участие, задействовать имеющееся железо (CPU, GPU) для ускорения выполнения сеток. Попытки довольно успешные. Ускоренные решения для CPU (библиотека MKL-dnn, и скомпилированный с ней Intel Caffe) и для GPU (clDNN) позволяют запускать большое количество популярный сетей, таких как AlexNet, GooLeNet/Inception, Resnet-50 и т.д. в реальном времени на обычном компьютере без мощной дискретной карты, на обычном ноутбуке. Даже OpenCV, хоть она пока и не использует эти оптимизированные библиотеки, позволяет запускать некоторые сетки для классификации, детектирования и семантической сегментации в реальном времени на ноутбуке без дискретной графики. Попробуйте наши примеры и убедитесь в этом сами. Эффективная работа сетей ближе, чем многим кажется.
Вопрос Mikhail063
Пользуюсь OpenCV не первый год, но столкнулся с такой интересной штуковиной. Есть камера, которая передает сигнал, и есть телеметрия, которая принимает сигнал, а еще есть тюнер, который декодирует сигнал в видео на компьютер. Так вот программы по захвату изображения работают на ура, но библиотека OpenCV при попытке вывести на экран изображение выдает черный экран, а при попытке выйти из программы, вываливается синий экран) ВОПРОС Почему это происходит?
Характеристики устройств: TV-тюнер EasyCap USB 2.0, Приемник FPV видеосигнала 5.8ГГц RC832, FPV камера с передатчиком 5.8ГГц 1000TVL.
Вадим. Потому что где-то какая-то ошибка, очевидно 🙂 Надо начать с локализации.
Вопрос KOLANICH
Есть ли смысл в современных реалиях в программах видеоанализа, основанных на фичах, спроектированных человеком, или лучше не морочиться и сразу тренировать нейронную сеть?
Анатолий. Иногда классические фичи могут быть быстрым решением.
Вадим. Для анализа лучше тренировать. Для более простых задач, типа склейки панорам, классические фичи, такие как SIFT, пока конкурентоспособны.
Вопрос vishnerevsky
Я использовал версию OpenCV 3.1.0, пользовался cv2.HOGDescriptor() и .setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector()), остался под хорошим впечатлением. Но я хочу уменьшить количество ложных срабатываний и поэтому хочу узнать, какой набор данных использовался для обучения SVM классификатора и могу ли я получить доступ к этому набору? Также хотелось бы узнать, планируется ли создание модулей OpenCV для распознавания различных объектов на базе YOLO или Semantic Segmentation?
Вадим. Базы брали стандартные, находящиеся в открытом доступе. Сейчас конкретные конфигурационные файлы со списками файлов утеряны, много лет прошло. Патч с добавлением YOLO v.2 висит, к моменту публикации этих ответов, думаю, его уже зальем. Пример с MobileNet_SSD уже есть. Там же можно найти примеры и с сегментацией.
Вопрос iv_kovalyov
«Посоветуйте, как можно распознать штамп слева в изображении справа? Штампы не идентичны, но есть общие элементы.
Пробовал find_obj.py из примеров opencv, но в данной ситуации этот пример не помогает.
Вадим. См. совет выше по поиску логотипов. Только тут, скорее всего, понадобятся две сетки – детектирование и последующее распознавание.
Эксперты Intel признали лучшими вопросы IliaSafonov об использовании OpenCV для 3D объектов и ChaikaBogdan о построении карьеры в области компьютерного зрения для новичка. Авторам этих вопросов достаются призы от Intel. Поздравляем победителей и благодарим Анатолия и Вадима за познавательные ответы!



