Обработка больших данных: первые шаги в понимании Hadoop MapReduce и Spark
Big Data как концепт довольно понятна, но из-за того, что она включает в себя множество процессов, сложно сказать, с чего именно нужно начать изучение. Как хранятся файлы? Или как получать эти файлы? А может, сразу — как анализировать данные? О своём опыте работе с Big Data и почему Spark лучше, чем Hadoop MapReduce в обработке данных, рассказывает Эмилия Межекова, ETL-developer в Luxoft.
Мой первый опыт
До 2020 года я, как и большинство Python-девелоперов, работала с привычным стеком Python+Django+РСУБД. В этом стеке для меня было многое понятно. Транзакции, обработка на стороне бэкенда, вывод его на фронтенд к пользователю, как РСУБД хранит данные, как подчищает от мусора, какие существуют трюки для оптимизации поиска данных и подобные вещи.
В 2020-м я получила должность ETL-девелопера (от англ. Extract, Transform, Load) в Luxoft. Изначально название этой позиции мне ни о чём не говорило, я только знала, что это связано с Big Data. Этот термин мне был лишь немного знаком, я никогда не интересовалась данным направлением, и мне казалось, что там очень много математики, графиков, расчёта вероятности и так далее. Как оказалось, в Big Data не только данные большие, но и инфраструктура, и найдутся места, где можно применить свои знания и без математики.
Сейчас я работаю в проекте, занимающемся количественными хедж-фондами — инвестиционными фондами, ориентированными на максимизацию доходности участников. Мы анализируем много данных из разных источников: соцсети, новости, транзакции и так далее. На их основе формируются «сигналы» для принятия решения о продаже или покупке акций. В основном я взаимодействую с фреймворком Spark, он служит для обработки данных (you must be joking!). Сначала я использовала его для манипулирования небольшими файлами и добавления определённой логики, это было довольно просто и понятно. Но когда меня пустили на прод, и файлы стали размером под сотни гигабайтов, а обработка этих файлов занимала всего несколько минут, мне стало интересно, как же шестерёнки крутятся внутри.
Я изучала всё довольно сумбурно. Так как я работала немного с Pandas, то команды Spark не казались сложными, потому что они в чём-то схожи. Я изначально читала про него, но очень часто авторы ссылались на Hadoop MapReduce и внесённые по сравнению с этой моделью улучшения. Поэтому я начала изучать Hadoop MapReduce. В итоге у меня есть представление о том и другом направлении, поэтому я решила рассказать, что лучше подходит для обработки данных.
Структура Big Data

Выше показана экосистема больших данных и примеры инструментов, которые можно использовать для каждой группы. Выглядит устрашающе, но нам нужно разобраться лишь в том, как именно данные обрабатываются, — вернее, рассмотреть два варианта, как это можно сделать с помощью следующих фреймворков: Hadoop MapReduce и Apache Spark.
Hadoop MapReduce и что его окружает
Apache Hadoop — инфраструктура, упрощающая работу с кластерами. Основные элементы Hadoop — это:
распределённая файловая система (HDFS);
метод крупномасштабного выполнения программ (MapReduce).
HDFS — распределённая файловая система Hadoop для хранения файлов больших размеров с возможностью потокового доступа к информации, поблочно распределённой по узлам вычислительного кластера. Здесь мы храним, читаем, записываем и перекладываем данные.
MapReduce — модель распределённых вычислений, представленная компанией Google, используемая для параллельных вычислений над очень большими, вплоть до нескольких петабайт, наборами данных в компьютерных кластерах.
Алгоритм легко понять по аналогии:
Представьте, что вам предложено подсчитать голоса на национальных выборах. В вашей стране 25 партий, 2500 избирательных участков и 2 миллиона граждан. Как это можно сделать? Можно собрать все избирательные бюллетени со всех участков и подсчитать их самостоятельно, либо приказать каждому избирательному участку подсчитать голосов по каждой из 25 партий и передать вам результат, после чего объединить их по партиям.
Ниже представлена схема выполнения данного алгоритма на примере подсчёта слов в выборке.
Разберём, что происходит, по этапам;
Input — входные данные для обработки;
Splitting — разбивка данных на порционные данные;
Mapping — обработка этих порционных данных воркерами (вычислительными процессами) в формате ключ-значение. Для этого алгоритма ключ — слово, значение — количество вхождений данного слова;
Shuffling — ключи сортируются, чтобы упростить обобщение данных и сделать всю работу в одном воркере, не раскидывая их по разным местам;
Reducing — после того, как мы посчитали количество одинаковых слов на каждом отдельном воркере, объединяем их вместе.
Между этапами происходит запись промежуточных данных на диск, воркеры и данные обособлены друг от друга. Данный алгоритм отлично подходит для кластеров. Подсчёт происходит в разы быстрее, чем на одной машине.
Но есть и недостатки, обусловленные архитектурными особенностями этой вычислительной модели:
недостаточно высокая производительность: классическая технология, в частности, реализованная в ядре Apache Hadoop, обрабатывает данные ациклично в пакетном режиме. При этом функции Reduce не запустятся до завершения всех процессов Map. Все операции проходят по циклу чтение-запись с жёсткого диска, что влечёт задержки в обработке информации;
ограниченность применения: высокие задержки распределённых вычислений, приемлемые в пакетном режиме обработки, не позволяют использовать классический MapReduce для потоковой обработки в режиме реального времени повторяющихся запросов и итеративных алгоритмов на одном и том же датасете, как в задачах машинного обучения. Для решения этой проблемы, свойственной Apache Hadoop, были созданы другие Big Data – фреймворки, в частности Apache Spark;
программисту необходимо прописывать код для этапов Map и Reduce самостоятельно.
Apache Spark
В своей работе мне приходится очень часто писать SQL-запросы и смотреть, какие данные приходят на вход и что внутри них хранится. Для этих целей мне хочется, чтобы инструмент был более интерактивным и не приходилось ждать выполнения запроса часами (но скорость зависит от количества данных, естественно). В этом поможет Spark, он работает намного быстрее Hadoop MapReduce.
Spark — инфраструктура кластерных вычислений, сходная с Hadoop MapReduce. Однако Spark не занимается ни хранением файлов в файловой системе, ни управлением ресурсами. Spark обрабатывает данные ещё быстрее с помощью встроенных коллекций RDD (Resilient Distributed Datasets), которые дают возможность выполнять вычисления в больших кластерах. Благодаря RDD можно совершать такие операции, как map, join, reduce, записывать данные на диск и загружать их.
Добавлю таблицу для сравнения Hadoop MapReduce и Spark.
Но как же достигается данное ускорение? Ниже представлены самые значимые решения в архитектуре Spark.
Промежуточные данные вычислений не записываются на диск, а образуют своего рода общую оперативную память. Это позволяет разным рабочим процессам использовать общие переменные и их состояния.
Отложенные вычисления: Spark приступает к выполнению запроса лишь при непосредственном обращении к нему (вывод на экран, запись конечных данных на диск). В этом случае срабатывает планировщик, соединяя все преобразования, написанные ранее.
Из-за некоторых архитектурных особенностей Hadoop MapReduce уступает по скорости Spark. Для своих задач я выбрала Spark, потому что при моём наборе данных и итерациях он работает быстрее. Мне было интересно посмотреть, что было до инструмента, которым я пользуюсь, и каким образом всё развивалось. Это лишь общее описание работы этих фреймворков, дающее немного понять, как всё внутри обрабатывается. Зная, как работает тот и другой алгоритм, вы теперь можете выбрать для себя подходящий.
Фреймворк Spark: высокоуровневый обзор проекта Apache
Как работает фреймворк Apache Spark? В статье рассмотрим, что прячется под капотом этого инструмента для кластерных вычислений.

В предыдущей статье познакомились с проблемой – обильные, бесконечные потоки данных – и её решением: фреймворк Apache Spark. Здесь, во второй части, сосредоточимся на внутренней архитектуре Spark и структурах данных.
«Первооткрыватели использовали волов для перевозки тяжёлых грузов. И когда вол не мог сдвинуть бревно с места, они не пытались вырастить вола покрупнее. Нам стоит стремиться не к повышению мощности одного компьютера, а к увеличению количества компьютерных систем.» – Грейс Хоппер
Поскольку масштабы данных росли стремительными и зловещими темпами, понадобился способ быстрой обработки вероятных петабайт данных. И невозможно было добиться, чтобы один компьютер обрабатывал такой объём с разумной скоростью. Эта проблема решается путём создания кластера машин для выполнения работы. Но как эти машины работают вместе для решения общей проблемы?
Встречайте фреймворк Spark

Spark – фреймворк для кластерных вычислений и крупномасштабной обработки данных. Spark предлагает набор библиотек на 3 языках (Java, Scala, Python) для унифицированного вычислительного движка. Что на самом деле это означает?
Унифицированный: в Spark нет необходимости собирать приложение из нескольких API или систем. Spark предоставляет встроенные API для выполнения работы.
Вычислительный движок: Spark поддерживает загрузку данных из различных файловых систем и выполняет в них вычисления, но сам не хранит никаких данных постоянно. Spark работает исключительно в памяти, что даёт беспрецедентную производительность и скорость.
Библиотеки: фреймворк Spark состоит из ряда библиотек, которые созданы для решения задач Data Science. Spark включает библиотеки для SQL (SparkSQL), машинного обучения (MLlib), обработки потоковых данных (Spark Streaming и Structured Streaming) и обработки графов (GraphX).
Приложение Spark
Каждое Spark-приложение состоит из управляющего процесса – драйвера (Driver) – и набора распределённых рабочих процессов – исполнителей (Executors).
Spark Driver
Driver запускает метод main() нашего приложения. Здесь создаётся SparkContext. Обязанности Spark Driver:
Spark Executors
Исполнитель (Executor) – распределённый процесс, который отвечает за выполнение задач. У каждого приложения Spark собственный набор исполнителей. Они работают в течение жизненного цикла отдельного приложения Spark.
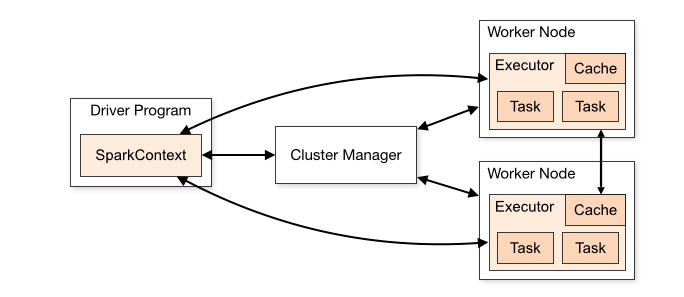
Workflow приложения Spark
Когда отправляем задание в Spark для обработки, многое остаётся за кулисами.
Пересмотр MaxTemperature
Присмотритесь к заданию Spark, которое писали в первой части, для поиска максимальной температуры по стране. Эта абстракция скрывает много кода настройки, включая инициализацию SparkContext, заполним пробелы:
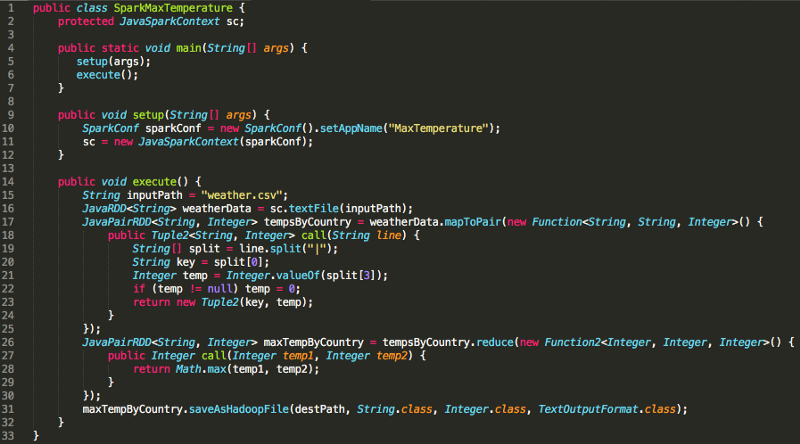 Настройка Spark задания MaxTemperature
Настройка Spark задания MaxTemperature
Помните, что Spark – фреймворк, в этом случае реализованный на Java. И до строки 16 Spark не должен ничего делать. Конечно, до этого мы инициализировали SparkContext, однако загрузка данных в RDD – первый фрагмент кода, который требует отправки работы нашим исполнителям.
К этому времени термин «RDD» встречался многократно, пора дать ему определение.
Обзор архитектуры Spark
Чёткая многоуровневая архитектура Spark со слабосвязанными компонентами основывается на двух главных абстракциях:
Устойчивые распределённые наборы данных
RDD – строительные блоки Spark: всё состоит из них. Даже высокоуровневые Spark API (DataFrames, Datasets) состоят из RDD под капотом. Что значит быть устойчивым распределённым набором данных?
Данные, с которыми мы работаем в Spark, хранятся в той или иной форме в RDD, поэтому понимать их – необходимость.
Spark предлагает API «высшего уровня», разработанные на основе RDD для абстрагирования сложности: DataFrame и Dataset. Если сосредоточиться на циклах «чтение – вычисление – вывод» (REPL), Spark-Submit и Spark-Shell в Scala и Python ориентируются на экспертов по аналитическим данным, которым часто требуется повторный анализ набора данных. Без понимания RDD по-прежнему не обойтись, так как это базовая структура всех данных в Spark.
RDD работают путём разделения данных на несколько разделов (Partition), которые хранятся на каждом узле-исполнителе. Каждый узел выполняет работу только на собственных разделах. В этом и заключается мощь Spark: если исполнитель выходит из строя, или не удаётся выполнить задачу, Spark восстанавливает только необходимые разделы из источника и повторно отправляет задачу для завершения.
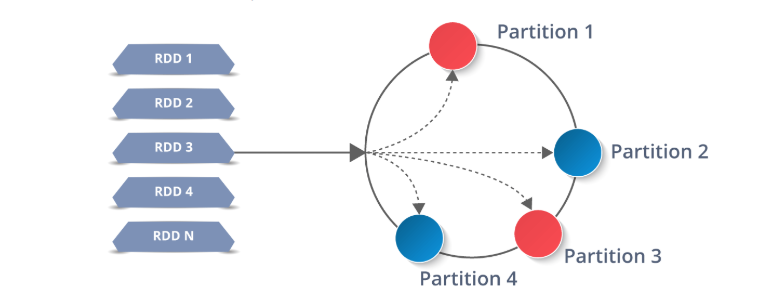 Распределение Spark RDD между исполнителями
Распределение Spark RDD между исполнителями
Операции с RDD
Трансформации создают новый RDD из существующего.
Действия возвращают значение или значения программе-драйверу после выполнения вычисления над RDD.
Например, map-функция weatherData.map() – это трансформация, которая передаёт каждый элемент RDD в функцию.
Reduce – это действие RDD, которое объединяет все элементы RDD с использованием некоторой функции и возвращает конечный результат в программу-драйвер.
Ленивые вычисления
«Я выбираю ленивого человека для выполнения трудной работы. Потому что ленивый человек найдёт простой способ решения задачи.» – Билл Гейтс
Трансформации в Spark «ленивые». Это означает, что когда сообщаем Spark о создании RDD с помощью трансформаций существующего RDD, он не будет генерировать этот набор данных, пока не выполнится действие над ним или его дочерним элементом. Затем Spark выполнит трансформацию и действие, которое её запустило. Поэтому Spark работает намного эффективнее.
Ещё раз рассмотрим объявления функций из нашего предыдущего примера Spark, чтобы определить, какие функции – действия, а какие – трансформации:
Направленный ациклический граф
В приведённом выше примере с MaxTemperatureByCountry граф посложнее:
parallelize → map → mapToPair → reduce → saveAsHadoopFile
С помощью DAG Spark оптимизирует план выполнения и минимизирует перемешивание. Рассмотрение DAG выходит за рамки этого обзора Spark.
Циклы выполнения
Используя наш новый словарь, ещё раз рассмотрим определение проблемы с MapReduce, данное в первой части и приведенное ниже:
«MapReduce справляется с пакетной обработкой данных. Однако отстаёт, когда дело доходит до повторного анализа и небольших циклов обратной связи. Единственный способ повторно использовать данные между вычислениями – записать их во внешнюю систему хранения (например, HDFS).»
«Повторно использовать данные между вычислениями»? Звучит так, будто над RDD совершается несколько действий! Предположим, хотим выполнить два вычисления над фалом «data.txt»:
2. Применяем функцию вычисления длины к каждой строке из lines с помощью map (лямбда-функции используются для краткости)
4. Чтобы вычислить наибольшую длину, применяем reduce к lineLengths
Заключение
К этому моменту мы представили проблему с данными и её решение: фреймворк Apache Spark. Теперь рассмотрели архитектуру и workflow Spark, его главную внутреннюю абстракцию (RDD) и модель выполнения.
Руководство n00bs по Apache Spark
Дата публикации Jun 4, 2017
Я написал это руководство, чтобы помочь себе понять основные базовые функции Spark, где он вписывается в экосистему Hadoop и как он работает в Java и Scala. Я надеюсь, что это поможет вам так же, как и мне.

Что такое Spark?
Контекст искр в среде больших данных
Spark предназначен для работы с внешним менеджером кластера или собственным автономным менеджером. Spark также полагается на распределенную систему хранения данных, из которой он вызывает данные, которые он должен использовать. Поддерживаются следующие системы:
Менеджеры кластеров:
Распределенные системы хранения:
Ради здравого смысла я сосредоточусь только на Spark в контексте экосистемы Hadoop.
Spark Core предоставляет платформу, которая устраняет многие недостатки Hadoop MapReduce, поскольку она позволяет нам отказаться от необходимости разбивать задачи на небольшие задачи, а также от необходимости сталкиваться со сложностью построения решений для разработки распределенных систем.
Spark Core очень универсален и был разработан с учетом экосистемы Hadoop; он может работать вместе с MapReduce или предоставлять альтернативную платформу для PIG, HIVE и SEARCH для работы поверх. Смотрите рисунок 1

Spark Core также привносит в таблицы собственный набор полезных API:
Spark Streaming:Управление живыми микробластами данных из различных источников. Это позволяет вычислять результаты в реальном времени, позволяя использовать ML Lib и Graphx в прямом эфире.
Graphx:Очень мощная библиотека для обработки параллельных графов вычислений. Не путайте это с «графами Power Point», эта библиотека полностью посвящена области математики, называемой теорией графов и моделированием парных отношений между объектами.
ML Lib:Библиотека для запуска алгоритмов машинного обучения для больших наборов данных в собственной распределенной среде. Библиотека все еще находится в зачаточном состоянии по сравнению с более надежными библиотеками машинного обучения, которые можно найти в Python или Matlab.
Spark SQL:Позволяет использовать SQL-карьеры для разработки нереляционных распределенных баз данных.
Spark Steaming, GraphX, MLLib и Spark SQL будут получать свои статьи в свое время, но пока не стесняйтесь искать официальную документацию[1][2][3][4],
Что делает искру, искру?
На самом высоком уровне абстракции Spark состоит из трех компонентов, которые делают его уникальным Spark; Драйвер, Исполнитель и DAG.
Водитель и Исполнитель
Spark использует архитектуру master-slave. Драйвер координирует работу многих распределенных работников для выполнения задач распределенным образом, а менеджер ресурсов занимается распределением ресурсов для выполнения задач.
ВОДИТЕЛЬ
Исполнители выполняют делегированные задачи из драйвера в экземпляре JVM. Исполнители запускаются в начале приложения Spark и обычно работают в течение всего срока службы приложения. Этот метод позволяет сохранять данные в памяти, в то время как различные задачи загружаются и выполняются в течение всего срока службы приложения.
Рабочие среды JVM в Hadoop MapReduce с полной контрастностью отключаются и включаются для каждой задачи Следствием этого является то, что Hadoop должен выполнять чтение и запись на диск в начале и в конце каждой задачи.

СВЯЗЬ ВОДИТЕЛЯ С ИСПОЛНИТЕЛЯМИ
Есть несколько способов, которыми водитель может общаться с исполнителями. Как разработчик или специалист по данным, важно, чтобы вы знали о различных типах коммуникации и их случаях использования.
Системные требования
Spark имеет значительный прирост производительности по сравнению с Hadoop MapReduce, но он также имеет более высокую стоимость эксплуатации, поскольку работает в памяти и требует высокоскоростной сетевой среды (рекомендуется + 10 Гбит / с). Рекомендуется, чтобы объем памяти в кластере Spark был как минимум таким же большим, как объем данных, которые необходимо обработать. Если для работы недостаточно памяти, в Spark есть несколько способов пролить данные на диск.Подробнее о требованиях к оборудованию и рекомендациях.
Посмотрите на рисунок 3. Я расскажу о DAG и о том, как он работает, обсудив его компоненты.

1) ИСТОЧНИК
Источником может быть любой источник данных, поддерживаемый Spark. Вот некоторые из них: HDFS, реляционная база данных, файл CSV и т. Д. Позже вы увидите, что мы определяем это в нашей настройке контекста среды.
2) СДР
СДР в их первоначальном виде не имеют прикрепленной к ним схемы, но их можно расширить с помощью чего-то, называемого DataFrames. DataFrames добавляет функциональность схемы к набору данных, содержащемуся внутри; это очень полезно при работе с реляционными наборами данных.
3) ТРАНСФОРМАЦИЯ
Преобразования превращают СДР в другой СДР. Некоторые примеры преобразований:
4) ДЕЙСТВИЕ
ВЫПОЛНЕНИЕ ДАГ
Спарк делает ленивую оценку. Сам DAG создается Преобразованиями, но ничего не происходит, пока не будет вызвано Действие. Когда действие выполняется, Spark просматривает группу обеспечения доступности баз данных и затем оптимизирует ее в контексте того, какие задания ему необходимо выполнить для достижения шага действия, который ему было предложено выполнить. Когда группа DAG наконец выполняется, драйвер отправляет команды преобразования в исполнители в кластере.
APACHE FLUME API
Apache Flume был разработан с целью позволить разработчикам создавать программы, которые могут работать в распределенных системах, используя тот же код, который будет работать с нераспределенным программированием. Другими словами, Apache Flume позволяет нам писать код, который может без проблем работать на одном потоке и на нескольких потоках. Смысл Apache Flume в том, что теперь мы можем запускать код на нашей локальной машине и отлаживать его, будучи уверенными, что он будет работать на нашем Spark Hadoop Cluster. Дополнительные последствия заключаются в том, что вы можете извлекать данные из кластера и запускать их на локальном компьютере для тестирования и разработки.
Поддерживаются следующие языки:
Чтобы продемонстрировать некоторые внутренние принципы работы Spark, я собираюсь просмотреть пример подсчета слов как в ScalaFlume, так и в JavaFlume.
В Скала

В джаве
Код, выделенный синим цветом, является преобразованием и создает DAG. Что еще более важно, обратите внимание, что по существу каждое преобразование является объектом, который затем отправляется всем распределенным исполнителям. Это также происходит в примере с Scala, но лямбда-выражения скрывают этот уровень взаимодействия от вас. Объекты преобразования не выполняются исполнителями в кластере, пока драйвер не выполнит код действия (выделенный красным) в строке 27.

ВЫВОД
В заключение, я надеюсь, что эта статья помогла вам понять основы того, что делает Spark такой интересной и мощной платформой для обработки и обработки данных.
Выводы из этой статьи должны быть:
Классификация больших объемов данных на Apache Spark с использованием произвольных моделей машинного обучения
Часть 1: Постановка задачи
Привет, Хабр! Я архитектор решений в компании CleverDATA. Сегодня я расскажу про то, как мы классифицируем большие объемы данных с использованием моделей, построенных с применением практически любой доступной библиотеки машинного обучения. В этой серии из двух статей мы рассмотрим следующие вопросы.
В нашей компании CleverDATA есть команда аналитиков данных, которые при помощи широкого набора инструментов (таких, как scikit-learn, facebook fastText, xgboost, tensorFlow и т.д) занимаются тренировкой моделей машинного обучения. Де-факто основным языком программирования, который используют аналитики, является Python. Практически все библиотеки для машинного обучения, даже изначально реализованные на других языках, имеют интерфейс на Python и интегрированы с основными Python-библиотеками (в первую очередь с NumPy).
С другой стороны, для хранения и обработки больших массивов неструктурированных данных широко используется экосистема Hadoop. В ней данные хранятся на файловой системе HDFS в виде распределенных реплицируемых блоков определенного размера (как правило, 128 МБ, но есть возможность настроить). Наиболее эффективные алгоритмы обработки распределенных данных стараются минимизировать сетевое взаимодействие между машинами кластера. Для этого данные нужно обрабатывать на тех же машинах, где они хранятся.
Конечно, во многих случаях сетевого взаимодействия полностью избежать невозможно, но, тем не менее, нужно стараться выполнять все задачи локально и максимально уменьшать объем данных, которые необходимо будет передавать по сети.
Такой принцип обработки распределенных данных называется “перенос вычислений к данным” (move computations close to data). Все основные фреймворки, главным образом, Hadoop MapReduce и Apache Spark, придерживаются этого принципа. Они определяют состав и последовательность конкретных операций, которые нужно будет запускать на машинах, где хранятся нужные блоки данных.
Рисунок 1. Кластер HDFS состоит нескольких машин, одна из которых является Name Node, а остальные – Data Node. На Name Node хранится информация о файлах, входящих в их состав блоках, и о машинах, где они физически расположены. На Data Node хранятся сами блоки, которые реплицируются на несколько машин для повышения надежности. Также на Data Node запускаются задачи по обработке данных. Задачи состоят из главного процесса (Master, M), который координирует запуск рабочих процессов (Worker, W) на машинах, где хранятся нужные блоки данных.
Практически все компоненты экосистемы Hadoop запускаются при помощи виртуальной машины Java (Java Virtual Machine, JVM) и тесно интегрированы между собой. Например, для запуска задач, написанных при помощи Apache Spark для работы с данными, хранящимися на HDFS, не требуется практически никаких дополнительных манипуляций: фреймворк предоставляет данный функционал из коробки.
К сожалению, основная масса библиотек, предназначенных для машинного обучения, предполагает, что данные хранятся и обрабатываются локально. В то же время существуют и такие библиотеки, которые тесно интегрированы с Hadoop-экосистемой, например, Spark ML или Apache Mahout. Однако у них есть ряд существенных недостатков. Во-первых, они предоставляют гораздо меньше реализаций алгоритмов машинного обучения. Во-вторых, далеко не все аналитики данных умеют работать с ними. К преимуществам данных библиотек можно отнести то, что с их помощью можно тренировать модели на больших объемах данных с использованием распределенных вычислений.
Тем не менее, аналитики данных часто используют альтернативные методы для тренировки моделей, в частности, библиотеки, позволяющие задействовать GPU. Рассматривать вопросы тренировки моделей я в этой статье не буду, так как хочу сосредоточиться на применении готовых моделей, построенных при помощи любой доступной библиотеки машинного обучения для классификации больших объемов данных.
Итак, основная задача, которую мы пытаемся здесь решить, – это применение моделей машинного обучения к большим объемам данных, хранящимся на HDFS. Если бы мы могли использовать модуль SparkML из библиотеки Apache Spark, который реализует основные алгоритмы машинного обучения, то классификация больших объемов данных была бы тривиальной задачей:
К сожалению, данный подход работает только для алгоритмов, реализованных в модуле SparkML (полный список можно найти здесь). В случае использования других библиотек, да к тому же реализованных не на JVM, всё становится гораздо сложнее.
Для решения данной задачи мы решили обернуть модель в REST-сервис. Соответственно, при запуске задачи по классификации данных, хранящихся на HDFS, необходимо организовать взаимодействие между машинами, на которых хранятся данные, и машиной (или кластером машин), на которых запущен сервис классификации.
Рисунок 2. Концепция Model as a Service
Описание сервиса классификации на python
Для того, чтобы представить модель в виде сервиса, необходимо решить следующие задачи:
Здесь мы при старте сервиса загружаем модель в память, и затем используем ее при вызове метода классификации. Функция load_model загружает модель из некоторого внешнего источника, будь то файловая система, key-value хранилище и т.д.
Модель представляет собой некий объект, имеющий метод predict. В случае классификации он принимает на вход некоторый feature вектор определенного размера и выдает либо булево значение, показывающее, подходит ли указанный вектор для данной модели, либо некоторое значение от 0 до 1, к которому потом можно применить порог отсечки: все, что выше порога, является положительным результатом классификации, остальное — нет.
Feature-вектор, который нам необходимо проклассифицировать, мы передаем в бинарном виде и десериализуем в numpy array. Было бы накладным делать HTTP-запрос для каждого вектора. Например, в случае 100-размерного вектора и использования для значений типа float32 полный HTTP-запрос, включая заголовки, выглядел бы примерно следующим образом:
Как видим, КПД такого запроса очень низкий (400 байт полезной нагрузки / (133 байта заголовок + 400 байт тело) = 75%). К счастью, почти во всех библиотеках метод predict позволяет принимать на вход не [1 x n] вектор, а [m x n] матрицу, и, соответственно, выдавать результат сразу же для m входных значений.
Кроме того, библиотека numpy оптимизирована для работы с большими матрицами, позволяя эффективно задействовать все доступные ресурсы машины. Таким образом, мы можем отправить в одном запросе не один, а достаточно большое количество feature векторов, десериализовать их в numpy матрицу размером [m x n], проклассифицировать, и вернуть вектор [m x 1] из булевых или float32 значений. В итоге КПД HTTP взаимодействия при использовании матрицы из 1000 строк становится практически равным 100%. Размером HTTP заголовков в данном случае можно пренебречь.
Для тестирования Flask сервиса на локальной машине его можно запустить из командной строки. Однако такой способ совершенно не подходит для промышленной эксплуатации. Дело в том, что Flask является однопоточным и, если мы посмотрим на диаграмму нагрузки процессора во время работы сервиса, то увидим, что одно ядро у нас загружено на 100%, а остальные бездействуют. К счастью, существуют способы задействовать все ядра машины: для этого Flask нужно запускать через сервер веб-приложений uwsgi. Он позволяет оптимально настроить количество процессов и потоков так, чтобы обеспечить равномерную нагрузку на все ядра процессора. Более подробно со всеми опциями по настройке uwsgi можно ознакомится здесь.
В качестве точки входа по HTTP лучше использовать nginx, так как uwsgi в случае высоких нагрузок может работать нестабильно. Nginx же принимает весь входной поток запросов на себя, отфильтровывает некорректные запросы, и дозирует нагрузку на uwsgi. Nginx взаимодействует с uwsgi через linux-сокеты с использованием файла процесса. Примерная конфигурация nginx приведена ниже:
Как мы видим, получилась достаточно непростая конфигурация для одной машины. Если нам нужно проклассифицировать большие объемы данных, на этот сервис будет приходить высокое количество запросов, и он может стать узким местом. Решением данной проблемы является горизонтальное масштабирование.
Для удобства мы упаковываем сервис в Docker контейнер и затем разворачиваем его на требуемом количестве машин. При желании можно использовать средства автоматизированного развёртывания типа Kubernetes. Примерная структура Dockerfile для создания контейнера с сервисом приведена ниже.
Итак, структура сервиса для классификации выглядит следующим образом:
Рисунок 3. Схема сервиса для классификации
Краткое описание работы Apache Spark в экосистеме Hadoop
Теперь рассмотрим процесс обработки данных, хранящихся на HDFS. Как я уже ранее отмечал, для этого используется принцип переноса вычислений к данным. Для запуска задач по обработке необходимо знать, на каких машинах хранятся нужные нам блоки данных, чтобы запускать на них процессы, занимающиеся непосредственно обработкой. Также необходимо координировать запуск этих процессов, перезапускать их в случае возникновения нештатных ситуаций, при необходимости агрегировать результаты выполнения различных подзадач и т.д.
Все эти задачи решаются множеством фреймворков, работающих с экосистемой Hadoop. Одним из самых популярных и удобных является Apache Spark. Главным понятием, вокруг которого строится весь фреймворк, является RDD (Resilient Distributed Dataset). В общем случае RDD можно рассматривать как распределенную коллекцию, устойчивую к падениям. RDD можно получить двумя основными способами:
При запуске терминальной операции Spark на основе итогового RDD строит ациклический граф операций (DAG, Directed Acyclic Graph) и последовательно запускает их на кластере согласно полученному графу. При построении DAG на основе RDD Spark проводит ряд оптимизаций, например, по возможности объединяет несколько последовательных трансформаций в одну операцию.
RDD был основной единицей взаимодействия с API Spark в версиях Spark 1.x. В Spark 2.x разработчики заявили, что теперь основным понятием для взаимодействия является Dataset. Dataset представляет собой надстройку над RDD с поддержкой SQL-like взаимодействия. При использовании Dataset API Spark позволяет задействовать широкий спектр оптимизаций, в том числе достаточно низкоуровневых. Но в целом, основные принципы, применимые к RDD, применимы также и к Dataset.
Более подробно о работе Spark можно ознакомиться в документации на официальном сайте.
Рассмотрим пример простейшей классификации на Spark без использования внешних сервисов. Здесь реализован достаточно бессмысленный алгоритм, считающий долю каждой из латинских букв в тексте, а затем считающий стандартное отклонение. Тут в первую очередь важно обратить внимание непосредственно на основные шаги, используемые при работе со Spark.
В данном примере мы:
При вызове терминальной операции драйвер формирует DAG на основе итогового RDD. Затем драйвер инициирует запуск рабочих процессов, называемых исполнителями (executor), в которых будет производиться непосредственно обработка данных. После запуска рабочих процессов драйвер передает им исполняемый блок, который нужно выполнить, а также указывает, к какой части данных его нужно применить.
Ниже приведен код нашего примера, в котором выделены участки кода, выполняемые на исполнителе (между строками executor part begin и executor part end). Остальной код выполняется на драйвере.
В экосистеме Hadoop все приложения запускаются в контейнерах. Контейнер представляет собой некоторый процесс, запущенный на одной из машин кластера, которому выделено определенное количество ресурсов. Запуском контейнеров занимается менеджер ресурсов YARN. Он определяет, на какой из машин имеется достаточное количество ядер процессора и оперативной памяти, а также имеются ли на ней необходимые блоки данных для обработки.
При запуске Spark-приложения YARN создает и запускает контейнер на одной из машин кластера, в котором запускает драйвер. Затем, когда драйвер подготовит DAG из операций, которые нужно запускать на исполнителях, YARN запускает дополнительные контейнеры на нужных машинах.
Как правило, для драйвера достаточно выделить одно ядро и небольшое количество памяти (если, конечно, потом результат вычислений не будет агрегироваться на драйвере в память). Для исполнителей в целях оптимизации ресурсов и уменьшения общего количества процессов в системе можно выделить и больше одного ядра: в этом случае исполнитель сможет выполнять несколько задач одновременно.
Но тут важно понимать, что в случае падения одной из выполняющихся в контейнере задач или в случае нехватки ресурсов YARN может принять решение остановить контейнер, и тогда все задачи, которые в нем исполнялись, придется перезапускать заново на другом исполнителе. Кроме того, если мы выделяем достаточно большое количество ядер на контейнер, то есть вероятность, что YARN не сможет его запустить. Например, если у нас есть две машины, на которых осталось незадействованными по два ядра, то мы сможем запустить на каждой по контейнеру, требующем два ядра, но не сможем запустить один контейнер, требующий четыре ядра.
Теперь рассмотрим, как код из нашего примера будет выполняться непосредственно на кластере. Представим, что размер исходных данных равен 2 Терабайт. Соответственно, если размер блока на HDFS равен 128 Мегабайт, то всего будет 16384 блоков. Каждый блок реплицируется на несколько машин для обеспечения надежности. Для простоты возьмем фактор репликации, равный двум, то есть всего будет 32768 доступных блоков. Предположим, что для хранения у нас используется кластер из 16 машин. Соответственно, на каждой из машин в случае равномерного распределения будет примерно по 2048 блоков, или 256 Гигабайт на машину. На каждой из машин у нас по 8 ядер процессора и по 64 Гигабайт оперативной памяти.
Для нашей задачи драйверу не требуется много ресурсов, поэтому выделим для него 1 ядро и 1 ГБ памяти. Исполнителям дадим по 2 ядра и 4 ГБ памяти. Предположим, что мы хотим максимально задействовать ресурсы кластера. Таким образом, у нас получается 64 контейнера: один для драйвера, и 63 – для исполнителей.
Рисунок 4. Процессы, запущенные на Data Node и используемые ими ресурсы.
Так как в нашем случае мы используем только операции map, то наш DAG будет состоять из одной операции. Она состоит из следующих действий:
Основные проблемы взаимодействия Apache Spark с внешними сервисами
В случае, если в рамках операции map нам нужно обращаться к некоторому внешнему сервису, задача становится менее тривиальной. Предположим, что за взаимодействие с внешним сервисом отвечает некоторый объект класса ExternalServiceClient. В общем случае, перед началом работы нам необходимо его проинициализировать, а затем вызывать по необходимости:
Обычно инициализация клиента занимает некоторое время, поэтому, как правило, его инициализируют при старте приложения, и затем используют, получая экземпляр клиента из некоторого глобального контекста, либо пула. Поэтому, когда контейнер со Spark исполнителем получает задачу, в которой требуется взаимодействие с внешним сервисом, было бы неплохо получить уже инициализированный клиент перед началом работы над массивом данных, и затем его переиспользовать для каждого элемента.
В Spark это можно сделать двумя способами. Во-первых, если клиент является сериализуемым (сам клиент и все его поля должны расширять интерфейс java.io.Serializable), то его можно проинициализировать на драйвере и затем передать исполнителям через механизм broadcast-переменных.
В случае, если клиент не является сериализуемым, либо инициализация клиента является процессом, зависящим от настроек конкретной машины, на которой он запускается (например, для балансировки запросы с одной части машин должны идти на первую машину сервиса, а для другой – на вторую), то клиент можно инициализировать непосредственно на исполнителе.
Для этого у RDD (и у Dataset) есть операция mapPartitions, которая является обобщенной версией операции map (если посмотреть исходный код класса RDD, то там операция map реализована через mapPartitions). Функция, передаваемая операции mapPartitions, запускается один раз для каждого блока. На вход этой функции подается итератор для данных, которые мы будем читать из блока, а на выходе она должна вернуть итератор для выходных данных, соответствующих входному блоку:
В данном коде клиент к внешнему сервису создается для каждого блока исходных данных. Это, конечно, лучше, чем каждый раз создавать клиент для обработки каждого элемента, и во многих случаях это является вполне приемлемым решением. Однако чуть дальше я покажу, как можно создать объект, который будет инициализироваться один раз при старте контейнера и затем использоваться при запуске всех задач, приходящих в данный контейнер.
Операция обработки результирующего итератора является однопоточной. Напомню, что основной паттерн доступа к структуре типа итератор является последовательный вызов методов hasNext и next:
Если у нас для исполнителя выделено два ядра, то в них будут всего два основных рабочих потока, которые занимаются обработкой данных. Напомню, что если на машине у нас 8 ядер, то YARN не позволит на ней запустить больше 4 процессов исполнителей по 2 ядра, соответственно, у нас будет всего 8 потоков на машину. Для локальных вычислений это является оптимальным выбором, так как это обеспечит максимальную загрузку вычислительных мощностей при минимальных накладных расходах на управление потоками. Однако в случае взаимодействия с внешними сервисами картина меняется.
При использовании внешних сервисов одним из важнейших вопросов является производительность. Простейшим способом реализации является использование синхронного клиента, в котором мы для каждого элемента обращаемся к сервису, и, получив от него ответ, формируем результирующее значение. Однако у этого подхода есть один существенный недостаток: при синхронном взаимодействии поток, синхронно вызывающий внешний сервис, блокируется на время взаимодействия с этим сервисом. Дело в том, что при вызове метода hasNext мы ожидаем получить однозначный ответ на вопрос, есть ли еще элементы для обработки. В случае неопределенности (например, когда мы послали запрос на внешний сервис и не знаем, вернет ли он пустой или непустой ответ) нам не остается ничего другого, как дождаться ответа, заблокировав таким образом поток, который вызвал данный метод. Следовательно, итератор является блокирующей структурой данных.
Рисунок 5. Поэлементная обработка итератора, полученного в результате вызова функции, переданной в mapPartitions, происходит в одном потоке. Как следствие мы получаем крайне неэффективное использование ресурсов.
Как вы помните, мы оптимизировали наш сервис классификации таким образом, чтобы он позволял обрабатывать несколько запросов одновременно. Соответственно, нам нужно из исходного итератора собрать необходимое количество запросов, отправить их в сервис, получить ответ и выдать их результирующему итератору.
Рисунок 6. Синхронное взаимодействие при отправке запроса на классификацию для группы элементов
На самом деле, в этом случае производительность будет ненамного лучше, потому что, во-первых, мы вынуждены держать основной поток в заблокированном состоянии, пока происходит взаимодействие с внешним сервисом, и, во-вторых, внешний сервис бездействует в то время, пока мы работаем с результатом.
Окончательная формулировка задачи
Таким образом, при использовании внешнего сервиса мы должны решить проблему синхронного доступа. В идеале, было бы удобно вынести взаимодействие с внешними сервисами в отдельный пул потоков. В этом случае запросы к внешним сервисам выполнялись бы одновременно с обработкой результатов предыдущих запросов, и таким образом можно было бы более эффективно использовать ресурсы машины. Для взаимодействия между потоками можно было бы использовать блокирующую очередь, которая служила бы коммуникационным буфером. Потоки, отвечающие за взаимодействие с внешними сервисами, клали бы данные в очередь, а поток, занимающийся обработкой результирующего итератора, соответственно, забирал бы их оттуда.
Однако такая асинхронная обработка сопряжена с рядом дополнительных проблем.



