Интеграция данных
Содержание
Уровни интеграции данных
Системы интеграции данных могут обеспечивать интеграцию данных на физическом, логическом и семантическом уровне. Интеграция данных на физическом уровне с теоретической точки зрения является наиболее простой задачей и сводится к конверсии данных из различных источников в требуемый единый формат их физического представления. Интеграция данных на логическом уровне предусматривает возможность доступа к данным, содержащимся в различных источниках, в терминах единой глобальной схемы, которая описывает их совместное представление с учетом структурных и, возможно, поведенческих (при использовании объектных моделей) свойств данных. Семантические свойства данных при этом не учитываются. Поддержку единого представления данных с учетом их семантических свойств в контексте единой онтологии предметной области обеспечивает интеграция данных на семантическом уровне. [1]
Процессу интеграции препятствует неоднородность источников данных, в соответствии с уровнем интеграции. Так, при интеграции на физическом уровне в источниках данных могут использоваться различные форматы файлов. На логическом уровне интеграции может иметь место неоднородность используемых моделей данных для различных источников или различаются схемы данных, хотя используется одна и та же модель данных. Одни источники могут быть веб-сайтами, а другие — объектными базами данных и т. д. При интеграции на семантическом уровне различным источникам данных могут соответствовать различные онтологии. Например, возможен случай, когда каждый из источников представляет информационные ресурсы, моделирующие некоторый фрагмент предметной области, которому соответствует своя понятийная система, и эти фрагменты пересекаются.
Возникающие задачи
При создании системы интеграции возникает ряд задач, состав которых зависит от требований к ней и используемого подхода. К ним, в частности, относятся:
Архитектуры систем интеграции
Консолидация
В случае консолидации данные извлекаются из источников, и помещаются в Хранилище данных. Процесс заполнения Хранилища состоит из трех фаз — извлечение, преобразование, загрузка (Extract, Transformation, Loading — ETL). Во многих случаях именно ETL понимают под термином «интеграция данных». Еще одна распространенная технология консолидации данных — управление содержанием корпорации (enterprise content management, сокр. ECM). Большинство решений ECM направлены на консолидацию и управление неструктурированными данными, такими как документы, отчеты и web-страницы.
Консолидация — однонаправленный процесс, то есть данные из нескольких источников сливаются в Хранилище, но не распространяются из него обратно в распределенную систему. Часто консолидированные данные служат основой для приложений бизнес-аналитики (Business Intelligence, BI), OLAP-приложений.
При использовании этого метода обычно существует некоторая задержка между моментом обновления информации в первичных системах и временем, когда данные изменения появляются в конечном месте хранения. Конечные места хранения данных, содержащие данные с большими временами отставания (например, более одного дня), создаются с помощью пакетных приложений интеграции данных, которые извлекают данные из первичных систем с определенными, заранее заданными интервалами. Конечные места хранения данных с небольшим отставанием обновляются с помощью оперативных приложений интеграции данных, которые постоянно отслеживают и передают изменения данных из первичных систем в конечные места хранения.
Федерализация
При использовании медиатора создается общее представление (модель) данных. Медиатор — посредник, поддерживающий единый пользовательский интерфейса на основе глобального представления данных, содержащихся в источниках, а также поддержку отображения между глобальным и локальным представлениями данных. Пользовательский запрос, сформулированный в терминах единого интерфейса, декомпозируется на множество подзапросов, адресованных к нужным локальным источникам данных. На основе результатов их обработки синтезируется полный ответ на запрос. Используются две разновидности архитектуры с посредником — Global as View и Local as View. [1]
Отображение данных из источника в общую модель выполняется при каждом запросе специальной оболочкой (wrapper). Для этого необходима интерпретация запроса к отдельным источникам и последующее отображение полученных данных в единую модель. Сейчас этот способ также относят к федеративным БД. [3]
Интеграция корпоративной информации (Enterprise information integration, сокр. EII) — это пример технологии, которая поддерживает федеративный подход к интеграции данных.
Изучение и профилирование первичных данных, необходимые для федерализации, несильно отличаются от аналогичных процедур, требуемых для консолидации.
Распространение данных
Приложения распространения данных осуществляют копирование данных из одного места в другое. Эти приложения обычно работают в оперативном режиме и производят перемещение данных к местам назначения, то есть зависят от определенных событий. Обновления в первичной системе могут передаваться в конечную систему синхронно или асинхронно. Синхронная передача требует, чтобы обновления в обеих системах происходили во время одной и той же физической транзакции. Независимо от используемого типа синхронизации, метод распространения гарантирует доставку данных в систему назначения. Такая гарантия — это ключевой отличительный признак распространения данных. Большинство технологий синхронного распространения данных поддерживают двусторонний обмен данными между первичными и конечными системами. Примерами технологий, поддерживающих распространение данных, являются интеграция корпоративных приложений (Enterprise application integration, сокр. EAI) и тиражирование корпоративных данных (Еnterprise data replication, сокр. EDR). От фееративных БД этот способ отличает двустороннее распространение данных. [1]
Сервисный подход
Сервисно-ориентированная архитектура SOA (Service Oriented Architecture), успешно применяемая при интеграции приложений, применима и при интеграции данных. Данные также остаются у владельцев и даже местонахождение данных неизвестно. При запросе происходит обращение к определённым сервисам, которые связаны с источниками, где находится информация и ее конкретный адрес.
Интеграция данных объединяет информацию из нескольких источников таким образом, чтобы ее можно было показать клиенту в виде сервиса. Сервис — это не запрос в традиционном смысле обращения к данным, скорее, это извлечение некоторой бизнес-сущности (или сущностей), которое может быть выполнено сервисом интеграции через серию запросов и других сервисов. Подход SOA концентрируется, в первую очередь, на определении и совместном использовании в форме сервисов относительно ограниченного количества самых важных бизнес-функций в корпорации. Следовательно, сервис-ориентированные интерфейсы в довольно большой степени строятся на ограниченном количестве запросов на необходимую информацию, которую нужно представить потребителю.
Имея соответствующие учетные данные системы безопасности, потребитель может осуществить выборку любых данных из источника через почти неограниченное количество различных запросов SQL. Но для этого потребитель должен иметь представление о модели источника данных и способе создания результата с использованием этой базовой модели. Чем сложнее модель источника данных, тем более сложной может оказаться эта задача. [4]
Кроме того
В [1] описан пример гибридного подхода.
Проблемы интеграции информации
Вне зависимости от выбранных технологии и метода интеграции данных, остаются вопросы, связанные с их смысловой интерпретацией и различиями в представлении одних и тех же вещей. Именно, приходится разрешать несоответствие схем данных [6] и несоответствие самих данных.
Типы несоответствия схем данных
Структурные и семантические конфликты выливаются в следующие проблемы:
Типы несоответствия собственно данных
Интеграция данных
Интеграция данных (англ. — Data integration) — процесс объединения данных из различных источников для получения их согласованного представления, в широком смысле — процесс организации регулярного обмена данными между различными ИС предприятия.
Содержание

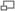
Предпосылки возникновения проблемы
Проблема интеграции данных является неотъемлемым аспектом проблематики развития информационной инфраструктуры предприятия.
Исторические корни проблемы тесно переплетаются с эволюцией подходов к автоматизации бизнеса. Неавтоматизированное хранение данных не предполагало широкой постановки вопроса о их повторном использовании — для использования данных, созданных в процессе деятельности предприятия и зафиксированных в бумажной или ином неэлектронной носителе, повторно на другом участке деятельности требовалось их дублирование в нужной форме.
Первые проекты автоматизации бизнеса, технологически связанные с использованием мэйнфреймов, предполагали автоматизацию конкретных функциональных задач без задела под их расширение и интеграцию в рамках процессов предприятия. Кроме того, решения этого этапа полагались при необходимости на повторный ввод однотипных данных, как за счет доминирования унаследованного от неавтоматизированных процессов работы с данными подходов, так и за счет того, что трудозатраты на повторный ввод в денежном выражении долгое время были несравнимо ниже затрат на организацию хранения данных в машинной памяти. Не была на этом этапе широко осознана и ценность реальных данных о бизнесе, которая в настоящее время иногда оценивается как равная (или превосходящая) ценности алгоритмов их анализа.
По мере возникновения информационных систем, базирующихся аппаратно на миникомпьютерах и, впоследствии, ПК, расширился как круг предприятий, способных позволить себе внедрение таких систем, так и круг задач решаемых такими АИС. Однако, подавляющее превалирование логики разработчиков над логикой бизнеса и доминирующий подход по автоматизации функциональных задач, приводили к тому, что такие АИС становились участками так называемой «лоскутной» автоматизации, не предполагающей осознанного системного подхода к автоматизации бизнеса. При этом уже учитывается необходимость хранения данных конкретных АИС и их резервирования, часть систем реализуется с учетом многопользовательского доступа и на основе клиент-серверной архитектуры. Необходимость «обмена данными» между различными АИС предприятия, однако, практически не принимается в расчёт и по-прежнему в основном снимается за счет повторного ввода с редкими исключениями в виде отдельных специфичных решений.
С разрастанием участков автоматизации начинают в полной мере сказываться недостатки «лоскутной» автоматизации — отсутствие единого подхода к организации АИС, выбору платформы и инструментов, моделям организации данных приводят к нарастанию дублирования однотипных данных в различных АИС в рамках одного предприятия. Примером может служить ситуация, когда пользователь вынужден повторно вводить аналогичные или близкие данные в несколько смежных по функционалу систем. При этом организации взаимодействия систем на программном уровне часто мешает отсутствие Application Programming Interface (API). Помимо собственно роста трудозатрат на повторный ввод и нарастания рассогласованности данных в разных системах и числа ошибок, фрагментарность хранения данных приводит к отсутствию единой картины деятельности предприятия.
С появлением концепции BI и аналитических систем, в том числе, OLAP становится явной необходимость специальной подготовки данных для таких систем, обусловленная как фрагментарностью источников данных для анализа, так и особыми требованиями к организации данных для целей анализа, сформулированными Эдгаром Коддом (Edgar Codd) в рамках 12 правил OLAP, уточненными Найджелом Пендсом (Nigel Pendse) в рамках тестам FASMI и другими.
Подходы к интеграции данных
В настоящее время интеграцию данных принято делить по направлению распространения на три типа — консолидацию, федерализацию и обмен данными.
Консолидация
Консолидация — сбор данных из нескольких источников (обычно — учётных систем) в единое место хранения. Консолидированные данные чаще всего используются для целей анализа или подготовки отчётности, как, например, в случае с организацией хранилищ данных для BI. При этом специфика сбора разнородной информации из нескольких источников обсуловила ряд особенностей консолидации данных, в частности, задержку обновления данных в целевом месте хранения по сравнению с системами-источниками данных. Эта задержка вызвана как необходимостью согласования циклов обновлений в различных системах-источниках данных, так и необходимостью преобразования данных из различных форматов в формат целевого места хранения данных, которое во многих реальных приложениях является нетривиальной задачей. Для классических целей BI-приложений, небольшая задержка в обновлении данных в целевом месте хранения не являлась проблемной, так как аналитика и прогнозирование предполагали оперирование более широкими интервалами времени, нежели учетные системы. Однако, по мере появления требований к увязке бизнес-аналитики с операционным менеджментом, требования к скорости преобразования данных приобретают всё большую важность, предъявляя новые требования к технологиям, использующим консолидацию и заставляя искать альтернативные подходы.
Наиболее часто используемой технологией консолидации данных можно считать ETL (Extract Transform Load), предполагающей извлечение данных из внешних источников, их преобразование в соответствии с требованиями бизнес-модели, загрузку преобразованных данных в целевую систему. При этом современные ETL-системы под преобразованием (transformation) понимают не только техническое преобразование форматов, но и возможности унификации разнородных данных с точки зрения соответствующих регламентов, обеспечение единства применяемых систем кодирования информации, классификаторов и справочников.
Интеграция данных: синтаксис и семантика
Как бы ни были совершенны реляционные и функциональные подходы к консолидации данных, по-существу, они примитивны и опираются на традиционное инженерное мировоззрение, не менявшееся с конца 60-х годов и отделяющее данные от контента. Семантический подход к интеграции позволит более осознанно работать с данными, что существенно упростит поиск, перераспределение между приложениями и интеграцию.
 Долгое время обсуждение темы управления знаниями (Knowledge Management, KM) имело по большей части отвлеченный от практики характер, но в последние годы некоторые реальные признаки KM удается обнаружить в концепциях Web 2.0 и Enterprise 2 – компьютер действительно становится интеллектуальным помощником. До полного решения этой задачи еще далеко, а пока более практичной и насущной является задача сборки воедино сведений из разрозненных источников, создание того, что называют single source of the truth – единый источник истины, методами интеграции данных.
Долгое время обсуждение темы управления знаниями (Knowledge Management, KM) имело по большей части отвлеченный от практики характер, но в последние годы некоторые реальные признаки KM удается обнаружить в концепциях Web 2.0 и Enterprise 2 – компьютер действительно становится интеллектуальным помощником. До полного решения этой задачи еще далеко, а пока более практичной и насущной является задача сборки воедино сведений из разрозненных источников, создание того, что называют single source of the truth – единый источник истины, методами интеграции данных.
К интеграции данных есть два альтернативных подхода: старый – синтаксический и новый – семантический. Первый основывается на внешнем сходстве объединяемых данных, второй на содержательном. Например, если мы, следуя первому, объединяем две обычные таблицы, то предполагаем, что в поле «Температура» значения выражены по одной шкале, а если мы смогли бы каким-то образом организовать семантическое хранение, то тогда могли бы рассчитывать на то, что в поле «Температура» находятся данные и метаданные, то есть запись физической величины и указание на то, по какой шкале она измерена, и смогли бы объединить массивы данных, записанных и по Цельсию, и по Фаренгейту.
Семантическая интеграция основывается на знании и учете природы данных. Разумеется, хранение данных вместе с метаданными создает дополнительные сложности, но обеспечивает большее удобство работы. Понимание этой истины пришло совсем недавно – ему мешало то, что много лет назад создатели первых компьютеров нашли удачное, как им казалось, решение, отделив данные от контекста и получив возможность работы с данными в чистом виде. В итоге сложилось своеобразное компьютерное «раздвоение сознания»: данные – в машине, а контекст – в человеке. Пока данных немного, о нем не стоит и задумываться, но бесконечно долго такое состояние сохраняться не могло, и сегодня держать в уме, что к чему, становится все сложнее. От этой «расщепленности» больше всего страдают бизнес-аналитики, которым нужно видеть не отдельные факты, а картину в целом, поэтому они первыми сформулировали свою потребность в интеграции информации. Так в ИТ возникло направление под названием интеграция информации предприятия (Enterprise Information Integration, EII).
Проблемы интеграции
Начнем с более широкого, чем EII, понятия, с интеграции предприятия. Этот тип интеграции имеет две трактовки в зависимости от того, что является предметом интегрирования: само предприятие с его смежниками и партнерами или же процесс интеграции ограничен стенами предприятия. В первом случае под интеграцией понимают создание электронных коммуникаций между всеми участниками процесса от производства до сбыта, то есть между производителями, сборщиками, поставщиками и потребителями, эти коммуникации обеспечивают взаимодействие между партнерами по всей цепочке продвижения, от сырья до товара. Вторая интерпретация ограничивает область действия Enterprise Integration границами предприятия, средствами для объединения людей, процессов, систем и технологий. Если кратко, то задачу второго типа интеграции можно определить так: нужные люди и нужные процессы должны получать нужную информацию в нужном месте и в нужное время.
Из двух интерпретаций интеграции первая отражает общемировую тенденцию к глобализации, информационные аспекты которой рассматриваются, например, Томасом Фридманом в книге «Плоский Мир: краткая история двадцать первого столетия», бывшей бестселлером несколько лет назад. Автор считает, что нынешний информационный период глобализации является третьим по счету, ему предшествовали колониальный, начавшийся с открытия Америки Колумбом, и капиталистический, растянувшийся с 1800-го по 2000 год. На протяжении первого периода главным действующим лицом было государство, на протяжении второго – корпорации, а сейчас – отдельные личности и относительно небольшие коллективы. Специфические особенности каждого обусловлены в том числе существовавшими на тот период средствами коммуникации. Используя современные компьютерные и коммуникационные технологии, люди могут вступать в партнерские или конкурентные отношения вне зависимости от географических и политических влияний, весь мир превращается в единое производственное пространство, действия в котором подчиняются общим правилам. В этом состоит суть концепции «плоского мира», уплощенного компьютерными и коммуникационными технологиями. Интеграция предприятий – одна из важнейших черт глобализации.
Вторая интерпретация интеграции предприятия относится к двум взаимодополняющим группам технологий: используя EII, можно объединить источники данных, а с помощью интеграции приложений предприятия (Enterprise Application Integration, EAI) объединяются процессы. Эти решения можно назвать двумя подсистемами одного организма, скажем, кровеносной и лимфатической. Технологии EII ориентированы на отчетные и аналитические функции, а EAI – на автоматизацию бизнес-процессов. Странно, но во многих работах их ставят в один ряд и даже сравнивают, что принципиально ошибочно – EII и EAI не альтернативны, они дополняют друг друга, образуя единое целое.
Термин Enterprise Information Integration, предложенный аналитиками Aberdeen Group в мае 2002 года, не несет в себе никакого нового содержания, а просто оказался удобен для использования в качестве некоторого маркетингового зонтичного бренда. Он вытеснил существовавший до этого акроним, полученный от Enterprise Information Interoperability. С тех пор прошло семь лет, однако и сегодня EII довольно расплывчато определяют как технологии, обеспечивающие единообразный доступ к разнородным источникам данных без предварительной загрузки в хранилища с целью представления множества источников в виде единой гомогенной системы. Несмотря на расплывчатость этого определения, EII активно коммерциализуется, и уже вполне можно говорить о возникновении соответствующей интеграционной индустрии.
Чтобы уточнить смысл, вкладываемый сегодня в EII, сделаем небольшое отступление. Появлению EII предшествовало более чем тридцатилетнее существование близкой по смыслу и звучанию дисциплины – интеграция данных (Data Integration). Сам термин определяется как комбинирование данных из разных источников, с тем чтобы создать их целостное представление в так называемый «единый образ истины». Интеграция данных обычно применяется при слиянии нескольких баз в процессе объединения предприятий, причем средства создания композиции данных являются одним из важнейших инструментов. С этим определением спорить нечего, но нельзя согласиться с еще одним утверждением: «В управлении бизнесом интеграцию данных называют Enterprise Information Integration». Тем самым постулируется тождественность двух областей, получается, что интеграция данных и интеграция корпоративной информации одно и то же, что неверно. Попытаемся разобраться в различиях между интеграцией данных и интеграцией информации, учитывая, что сравнение двух групп технологий представляет интерес еще и потому, что в этом контексте явственнее просматриваются различия между самими объектами интеграции.
Классификация и методы синтаксической интеграции данных
Прежде всего уточним использование термина «интеграция» и его отличие от «консолидации» в приложении к данным. В управлении чем угодно, экономикой в том числе, всегда была и остается необходимость консолидировать данные, поступающие из диверсифицированных источников, – аппараты министерств и ведомств столетиями выполняют эту работу, накапливая различного рода архивы. В компьютерную эпоху появилась возможность создавать автоматизированные хранилища данных. Процедуры консолидации данных составляют основу руководящего принципа хранилищ данных, известного как ETL (Extract – Transform – Load). Словари трактуют консолидацию как объединение отдельных дифференцированных частей в целое. При работе с данными требуются разные методы, однако применение более простых методов консолидации ограничено уровнем сложности данных. Обычно консолидации достаточно, когда работа с данными ограничена составлением отчетов и нет потребности в применении серьезных аналитических методов. Собственно, развитие различных аналитических методов и стало основной причиной повышенного внимания к интеграции данных. Интеграция отличается тем, что она представляет пользователю единообразный взгляд на разнородные источники данных, что предполагает общую модель и общее отношение к семантике, с тем чтобы обеспечить возможность для доступа к данным, а в случае необходимости разрешать конфликтные ситуации.
Задача технологий интеграции данных состоит в преодолении многочисленных проявлений неоднородности, присущей информационным системам, которые создавались и создаются, руководствуясь чем угодно, но не унифицированным отношением к данным. Системы имеют разную функциональность, используют различные типы данных (алфавитно-цифровые и медийные, структурированные и неструктурированные), их компоненты различаются по автономности, имеют различную производительность. Системы строятся на разных аппаратных платформах, имеют разные средства управления данными, разное ПО промежуточного слоя, модели данных, пользовательские интерфейсы и многое другое.
Лет десять назад исследователь из Цюрихского университета Клаус Диттрих предложил схему классификации технологий интеграции данных из шести уровней (рис. 1).
Common Data Storage (Общие системы хранения). Осуществляется за счет слияния данных из разных систем хранения данных в одну общую. Сегодня мы бы объединили эти два уровня в один и назвали бы его виртуализацией систем хранения.
Uniform Data Access (Унифицированный доступ к данным). На этом уровне осуществляется логическая интеграция данных, различные приложения получают единообразное видение физически распределенных данных. Такая виртуализация данных имеет свои несомненные достоинства, но гомогенизация данных в процессе работы с ними требует значительных ресурсов.
Integration by Middleware (Интеграция средствами ПО промежуточного слоя). ПО этого слоя играет посредническую роль, его составляющие способны к выполнению отдельных предписанных им функций, в полном объеме интеграционная задача решается во взаимодействии с приложениями.
Integration by Applications (Интеграция средствами приложений). Обеспечивает доступ к разным источникам данных и возвращает пользователю обобщенные результаты. Сложность интеграции на этом уровне объясняется большим разнообразием интерфейсов и форматов данных.
Common User Interface (Общий пользовательский интерфейс). Дает возможность единообразного доступа к данным, например, с помощью браузера, но при этом данные остаются неинтегрированными и неоднородными.
Manual Integration (Интеграция вручную). Пользователь сам объединяет данные, применяя различные типы интерфейсов и языки запросов.
Схема Диттриха интересна и удобна тем, что позволяет связать вместе интеграцию данных с интеграцией информации – по мере продвижения снизу вверх простые атомарные данные обретают семантику, становятся доступными пониманию человеком и превращаются в полезную информацию, представленную в удобной форме. Соотнесем эту классификацию с известными технологиями интеграции данных.
Интеграция данных на уровне общих данных может быть реализована с помощью хранилищ, в которых данные, поступающие из разных систем оперативной обработки транзакций (OLTP), извлекаются, трансформируются и загружаются (Extract – Transform – Load, ETL) в хранилище данных, а затем используются в аналитике. С точки зрения интеграции данных близким примером интеграции на нижнем уровне служат операционные хранилища (Operational Data Store, ODS), которые создаются для хранения «атомарных» данных в течение относительно короткого срока для работы в реальном времени. Они меньше, чем классические хранилища по Биллу Инмону, создаваемые для долговременного хранения, и их иногда называют «хранилищами со свежими данными» (warehouse with fresh data).
Примером решения на уровне унифицированного доступа к данным могут быть федеративные СУБД, объединяющие, как следует из названия, отдельные базы с использованием аппарата метаданных. Входящие в федерацию базы могут быть географически распределены и связаны компьютерными сетями. Иногда такие СУБД называют виртуальными, поскольку они обеспечивают доступ к различным базам, для этой цели федеративная система управления базами данных выполняет декомпозицию обращенного к ней запроса на запросы, передаваемые в базы, входящие в состав федерации.
Примером интеграции данных средствами ПО промежуточного слоя может служить выпущенный в 2008 году пакет Oracle Data Integration Suite из состава Oracle Fusion Middleware. Пакет включает в себя необходимые компоненты для перемещения данных, оценки их качества и предварительного анализа (profiling), а также средства для работы с метаданными. Oracle Data Integration дает возможность создавать решения, привязанные к сервисной архитектуре и ориентированные на приложения бизнес-аналитики.
Приложения, предназначенные для интеграции данных, выпускает несколько компаний, наиболее типичным является продукт MapForce компании Altova. Он позволяет объединять данные, представленные в разных форматах, включая XML, различные базы данных, текстовые файлы, электронные таблицы и др. MapForce можно рассматривать в качестве связующего ПО для распределенных приложений, как в пределах предприятия, так и в облачных инфраструктурах. Для взаимодействия с пользователем MapForce имеет удобный графический интерфейс, с его помощью можно выбрать из библиотеки нужные функциональные фильтры и собрать процесс преобразования и интеграции данных. На этом же уровне модели находятся системы управления потоками работ (Workflow Management System, WFMS), интеграционная функция которых состоит в том, что они связывают отдельные работы, выполняемые пользователями или приложениями, в единый поток. Обычно системы WFMS поддерживают моделирование, выполнение и управление сложными процессами взаимодействия человека с приложениями.
Типичным примером реализации общего пользовательского интерфейса служат различного рода порталы, например iGoogle или My Yahoo, «вылавливающие» данные из разных источников, но не обеспечивающие их единообразного представления.
Интеграция вручную – это в чистом виде работа пользователя с информацией, этот подход имеет смысл, когда никакие автоматизированные методы интеграции невозможны.
Приведенная классификация показывает, что ни о какой реальной интеграции информации речи пока быть не может: все, что мы видим сегодня, сводится лишь к консолидации данных на том или ином уровне абстракции. В этом случае можно остановиться на следующем определении: «Интеграцией корпоративной информации обычно называют консолидацию на корпоративном уровне данных из разных источников. EII дает возможность людям (администраторам, разработчикам, конечным пользователям) и приложениям интерпретировать разнообразные данные как данные из одной базы или поставляемые одним сервисом».
Интеграции в комплексе
Рынок технологий интеграции данных представлен сегодня тремя группами компаний. Крупные производители: IBM, Informatica, SAP/BusinessObjects и Microsoft; небольшие компании, интересные своими специфическими решениями: Ab Initio, iWay Software, Syncsort, DMExpress, Embarcadero Technologies, Sunopsis; стартапы.
На протяжении последних нескольких лет Informatica не покидала позиции лидера по классификации аналитиков Gartner, что вполне объяснимо: компания специализируется на интеграции данных, причем ее деятельность распространяется как на внутрикорпоративный уровень, так и на уровень межкорпоративного взаимодействия. Общее направление деятельности Informatica было задано в 1993 году, когда компанию создали два выходца из Индии – Гаурав Дхиллон и Диаз Низамони. Уже тогда они поняли, что ручным технологиям загрузки нужно противопоставить простые и удобные средства для автоматизированной загрузки данных в хранилища. С тех пор Informatica предлагает классическую ETL-платформу интеграции данных Informatica PowerCenter, позволяющую организациям независимо от их размера получать доступ и проводить интеграцию данных произвольных форматов из различных источников. Этот флагманский продукт компании включает в себя различные опции, например менеджер метаданных Metadata Manager, анализаторы данных Data Analyzer и Data Profiler. Посредством Informatica PowerExchange можно подключаться к различным СУБД, а с помощью продукта Informatica Data Quality обеспечивается проверка и очистка данных, выявление дубликатов и взаимосвязей, исправление отдельных строк и т.д. Платформа имеет высокие показатели отказоустойчивости и масштабируемости.
Для взаимосвязи с внешними организациями служит подсистема Informatica B2B Data Exchange, но внешняя среда небезопасна, поэтому выход в нее невозможен без персонального контроля – эту функцию выполняет Informatica Identity Resolution. Компания отдала должное технологиям облачных вычислений, выпустив продукт Informatica Cloud, позволяющий создавать приложения, построенные на принципах SaaS.
На пути к семантической интеграции
И все же, как бы ни были совершенны с технической точки зрения реляционные и функциональные подходы к консолидации данных, по своей сути они примитивны. Все они имеют в основе традиционное инженерное мировоззрение, сложившееся на протяжении всех лет существования ИТ и не менявшееся с конца 60-х годов, «данные – отдельно, контент – отдельно». Их общая слабость в том, что данные рассматриваются как примитивное сырье, как наборы битов и байтов, а их семантика никоим образом не учитывается. Более того, нет даже внятного определения, что такое данные, а есть лишь аморфные высказывания вроде «данные – это представление фактов и идей в формализованном виде, пригодном для передачи и обработки в некотором информационном процессе» или «данные – это то, что находится на нижнем уровне в иерархии данные – информация – знание». Все это странно, как с таким пониманием предмета можно было создавать, например, базы данных? Невольно возникает вопрос – а это базы чего?
Первые серьезные попытки изменить существующее положение были связаны с созданием в 80-е годы систем, состоящих из множества баз данных, за ними последовали СУБД с агентами, выступающими в качестве «посредников при доступе к данным» (mediators agent). Эти работы позволили понять, что причина сложности при интеграции данных, содержащихся в классических базах, кроется в жесткой связанности баз и единственности используемой в них схемы хранения. Эти работы остались на уровне академических или университетских исследований и к тому же не предложили решения проблемы интеграции гетерогенных данных, проблемы, которая обострилась в связи с широким распространением неструктурированных или квазиструктурированных данных. Общая причина неудач заключается в том, что проблемы интеграции не являются чисто техническими – совсем не сложно объединить различные реляционные базы, используя интерфейсы Open Database Connectivity (ODBC) или Java Database Connectivity (JDBC), но сложнее интегрировать данные, поступающие из источников, имеющих разные модели или, что хуже, имеющих различную семантику, то есть интерпретирующих одни и те же данные по-разному. Для автоматизации работы с данными семантика должна быть явным образом выражена и включена в эти данные. Здесь можно провести параллель с тем, как человек обобщает данные в своей повседневной жизни, основываясь на понимании окружающего мира, семантика которого уже в нем заключена. Компьютер интеллектом не обладает, а интеграционные программы знания о семантике не имеют, поэтому есть единственный выход: данные должны содержать в себе описания собственной семантики. Если это будет так, то станет возможен переход на следующий уровень интеграции, который можно назвать семантическим. Семантическая интеграция сможет обеспечить объединение только тех данных, которые соответствуют или наиболее близки одним и тем же сущностям в окружающем мире. Первые попытки создания систем с семантической интеграцией датируются началом 90-х годов. Тогда впервые стали использовать понятие онтологиий в приложении к компьютерным данным. Онтологии здесь рассматриваются как способы формального описания концепций и их взаимосвязей, им соответствуют словники, содержащие основные понятия.
Онтологии позволяют создавать модели, более точно соответствующие реальности, чем другие способы классификации. В то же время использование онтологий для создания запросов и анализа не сложнее традиционных методов прежде всего потому, что онтологический граф или карта отражают отношения между самими сущностями, а не их идентификаторами. Несмотря на все эти достоинства, семантические методы не выходили за рамки исследовательских проектов до тех пор, пока в мае 2001 года Тим Бернерс-Ли вместе с Джеймсом Хендлером и Орой Лассилой не опубликовали в журнале Scientific American Magazine статью The Semantic Web. В ней они раскрыли концепцию семантической паутины, разрабатывавшуюся ими в W3C с 1996 года. От обычной Web семантическая паутина отличается тем, что в ней широко используются метаданные, способствующие ее превращению в универсальный носитель для данных, информации и знаний. С тех пор и поныне Semantic Web все еще находится в процессе становления, будет ли она реализована, и, если да, то как именно, пока не ясно, но идеи, разработанные консорциумом W3C, стандарты и языки уже активно прилагаются к корпоративным системам. В каком-то смысле история повторяется, происходящее сейчас с Semantic Web можно сравнить с тем, что было с Web-сервисами несколько лет назад. Сервисная идея, протоколы SOAP, UDDI, WSDL и другие зародились в Web, но их очень быстро приспособили к корпоративным системам, и родилась сервисная архитектура. Как следствие, сервисы, используемые в SOA, долгое время называли исключительно Web-сервисами, хотя с Web их роднило лишь использование общего стека стандартов. Постепенно сервисы отпочковались от Web и стали самостоятельной основой SOA.
Подход Semantic Web добавляет новое качество, позволяя пользоваться данными не «вслепую», а осознанно, определяя и связывая их таким образом, чтобы упростить поиск, автоматизировать работу с ними, перераспределять между приложениями и интегрировать. То, как данные представляются в Semantic Web, можно рассматривать как новый шаг в управлении данными, и вполне естественно воспользоваться этими преимуществами в корпоративных информационных системах. Нетрудно заметить, что единство всем компонентам информационной инфраструктуры (SOA, базы данных, бизнес-процессы, программное обеспечение) придает общий для них набор терминов и соглашений. Именно они связывают отдельные фрагменты в общую картину, то есть они семантически едины, они уже есть, но существуют неявно. Этот факт обычно упускали из виду, поэтому формальные интеграционные решения оказывались сложными, дорогими и часто провальными.
В большинстве своем семантические модели строятся на основе одного из направлений в логике первого порядка (исчисления предикатов), на так называемых дескрипционных логиках, которые представляют собой семейство языков, позволяющих формально и однозначно описывать понятия в какой-либо предметной области. Каждый класс («концепт») может быть соотнесен с другим подобным ему концептом путем добавления тэгов метаданных, указывающих на свойства, общие черты, различия и т.д. Расширение моделей тэгами позволяет создавать такие структуры, которых раньше не могло быть. В семантической модели любая информационная единица представляется графом, что упрощает ее модернизацию; например, слияние двух моделей сводится к объединению их графов. Информационная единица может быть представлена идентификатором Uniform Resource Identifier (URI), посредством которого могут быть установлены отношения между двумя или большим числом информационных единиц. Семантические модели, они же онтологии, могут быть написаны с использованием Resource Description Framework (RDF) модели для представления данных, разработанной W3C на языке Web Ontology Language (OWL).
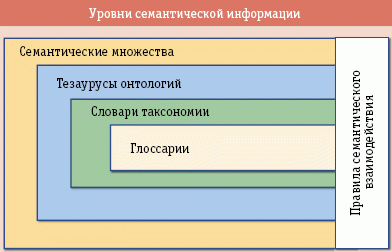
Рис. 2. Семантическая модель представления информации
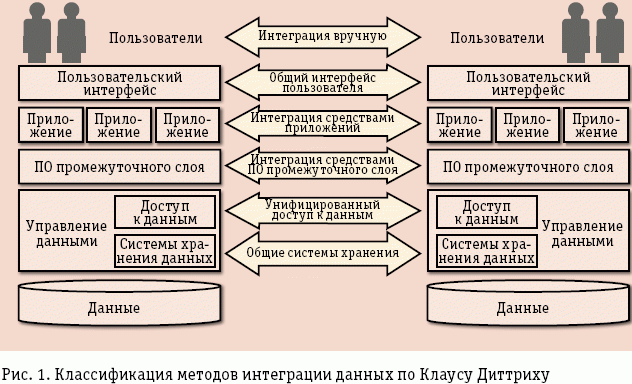
На рис. 2 показана семантическая модель информации. На нижнем, атомарном уровне представления данных располагается глоссарий, далее идут таксономии, представляющие собой аналог схемы (design paradigm), в отличие от глоссария, образованного простой иерархией элементов данных. Каждый элемент контента должен представлять свою принадлежность к определенной таксономии. Следующий уровень – онтология (глоссарий и таксономия), представляет собой структуру, выражающую одновременно иерархию и набор отношений между элементами словника в этой иерархии. Семантическое множество объединяет онтологии, таксономии и глоссарии, входящие в состав корпоративной системы.
Для того чтобы компьютерные технологии можно было с полным правом называть информационными, они должны хотя бы научиться работать с ин формацией.
В терминологии Semantic Web разобраться довольно сложно по той причине, что большинство слов уже используются в других контекстах, где они имеют иной, обычно более широкий смысл. Скажем, онтологией всегда называли раздел философии, изучающий бытие, а в компьютерной науке онтология – это формализации некоторой области знаний с помощью концептуальной схемы. Информационные онтологии еще проще, они состоят из экземпляров, понятий, атрибутов и отношений и должны иметь формат, который компьютер сможет обработать ( рис. 3 ).
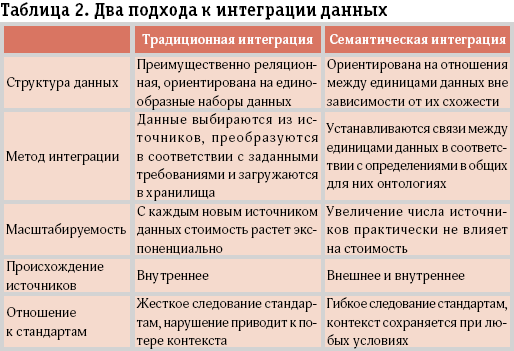
Не углубляясь в языки Semantic Web, ограничимся представлением стека существующих и разрабатываемых стандартов ( таблица 1 ). В таблице 2 приведено сравнение традиционного и семантического подхода к интеграции данных.

При положительном исходе, вероятно, можно будет говорить о семантическом предприятии (Semantic Enterprise), где информационные технологии будут прочно увязаны с семантическими. Скорее всего, все это будет объединено с архитектурой предприятия (Enterprise Architecture, EA), использующей такие метамодели, как UML, DoDAF, FEAF, ToGAF и Zachman, но это в неблизком будущем. Однако уже сегодня на рынке имеется ряд продуктов, в которых, пусть и частично, реализованы методы семантической интеграции. Раньше других (в конце 2006 года) выпустила семантический интегратор DataXtend Semantic Integrator компания Progress Software, а сегодня DataXtend существует в виде семейства продуктов, активно продвигаемых на рынке. Элементы семантической интеграции есть в продуктах компании DataFlux, входящей в состав SAS. А опция Oracle Spatial 11g, входящая в состав Oracle Database 11g, интересна тем, что поддерживает, в частности, стандарты RDF, RDFS и OWL.
Новый язык OWL поможет запустить автоматизированные инструменты для глобальной сети нового поколения, предлагая услуги точного Web-поиска, интеллектуальные программные агенты и управление знаниями.
Квазиструктурированные данные и Report Mining
В своем блоге Билл Инмон оставил весьма любопытную запись: «Структурированные и неструктурированные данные, наведение мостов», в которой пишет о том, что большинство нынешних информационных систем выросли вокруг структурированных данных с их строгими правилами, форматами, полями, строками, колонками и индексами, однако сегодня основная часть накапливаемых данных относится к категории неструктурированных, для которых нет никаких правил и форматов.
Сейчас эти два мира данных существуют изолированно, но между ними могут быть наведены мосты, и Инмон смотрит на эти мосты через призму реляционного сознания, считая, что значительная часть неструктурированных может быть интегрирована, если их структурировать. Инмон убежден, что это возможно, если избавить тексты от игнорируемых слов (stop words), различным образом редуцировать текст, сгруппировать и классифицировать слова. После этого к текстам можно будет применить те же методы анализа, которые применяются для структурированных данных. Инмон замечает, что этот подход не исключает использование семантических методов, основанных на онтологиях, глоссариях и таксономиях.
Но существует еще один способ сближения двух миров данных – через промежуточный класс квазиструктурированных данных (semi-structured). Очень многие документы, используемые в бизнесе, нельзя признать полностью свободными от структурирования, но их структуры не являются таким строгими, как базы данных. При том, что отчеты и им подобные документы предназначены для чтения человеком, они достаточно формальны, при анализе можно обнаружить принятую в делопроизводстве форму, например, часть данных содержит метаданные. Такими особенностями отличаются отчеты, создаваемые системами типа ERP, CRM и HR. Распознавание, синтаксический разбор и преобразование отчетов составляют новое направление, получившее название Report Mining – разработка отчетов.



