MySQL Distinct
Выражение MySQL DISTINCT используется для выборки уникальных значений из указанных столбцов. В этой статье мы покажем, как применять DISTINCT в MySQL с помощью Workbench и командной строки.
Синтаксис запросов SELECT DISTINCT в MySQL
Базовый синтаксис запросов SELECT DISTINCT :
Мы собираемся использовать данные, приведенные ниже, чтобы объяснить применение ключевого слова DISTINCT в MySQL на конкретном примере:

DISTINCT-запрос к одному столбцу
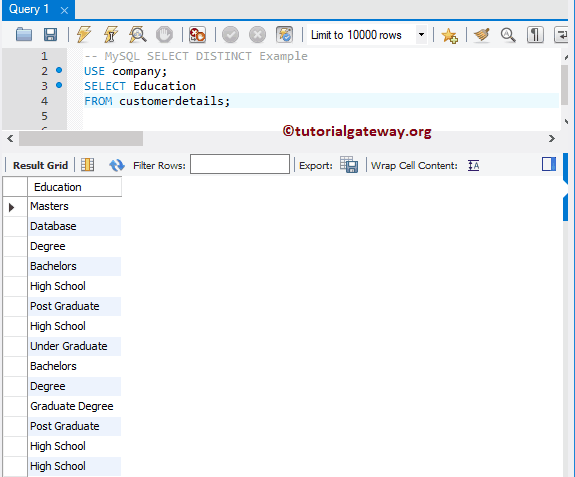
Теперь я использую ключевое слово DISTINCT :

DISTINCT-запрос к нескольким столбцам

Пример DISTINCT-запроса в MySQL – условие WHERE

Замечание : Выражение DISTINCT в MySQL воспринимает NULL как допустимое уникальное значение. Поэтому используйте любое NOT NULL условие или функцию, чтобы избавиться от этих значений.
DISTINCT или GROUP BY в MySQL
Единственное отличие между ними заключается в следующем:

Уберём ключевое слово DISTINCT и используем выражение GROUP BY :
Как видите, запрос возвращает тот же результат, но в другом порядке:

В этом MySQL SELECT DISTINCT примере я использую выражение ORDER BY :
Результат тот же, что и при использовании GROUP BY :

Пример DISTINCT-запроса в MySQL – командная строка
Теперь я покажу, как отобразить уникальные записи с помощью SELECT DISTINCT MySQL в командной строки. В этом случае мы выбираем записи с уникальными значениями столбцов education и profession из таблицы customerdetails :

Пожалуйста, оставляйте свои мнения по текущей теме материала. Мы крайне благодарны вам за ваши комментарии, подписки, отклики, дизлайки, лайки!
Дайте знать, что вы думаете по этой теме статьи в комментариях. За комментарии, дизлайки, лайки, подписки, отклики огромное вам спасибо!
Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
Базы данных
SQL оператор DISTINCT
В этом учебном материале вы узнаете, как использовать SQL оператор DISTINCT с синтаксисом и примерами.
Описание
SQL оператор DISTINCT используется для удаления дубликатов из результирующего набора оператора SELECT.
Синтаксис
Синтаксис для оператора DISTINCT в SQL:
Параметры или аргументы
Примечание
Давайте посмотрим, как использовать оператор DISTINCT для поиска уникальных значений в одном столбце таблицы.
В этом примере у нас есть таблица suppliers со следующими данными:
| supplier_id | supplier_name | city | state |
|---|---|---|---|
| 100 | Yandex | Moscow | Russia |
| 200 | Lansing | Michigan | |
| 300 | Oracle | Redwood City | California |
| 400 | Bing | Redmond | Washington |
| 500 | Yahoo | Sunnyvale | Washington |
| 600 | DuckDuckGo | Paoli | Pennsylvania |
| 700 | Qwant | Paris | Ile de France |
| 800 | Menlo Park | California | |
| 900 | Electronic Arts | San Francisco | California |
Будет выбрано 6 записей. Вот результаты, которые вы должны получить:
| state |
|---|
| Russia |
| Ile de France |
| Pennsylvania |
| California |
| Washington |
| Michigan |
В этом примере возвращаются все уникальные значения состояния из таблицы поставщиков и удаляются все дубликаты из набора результатов. Как видите, штат Калифорния в наборе результатов отображается только один раз, а не четыре раза.
Далее давайте рассмотрим, как использовать SQL DISTINCT для удаления дубликатов из более чем одного поля в операторе SELECT.
Используя ту же таблицу suppliers из предыдущего примера, введите следующий SQL оператор:
Будет выбрано 8 записей. Вот результаты, которые вы получите:
| city | state |
|---|---|
| Moscow | Russian |
| Lansing | Michigan |
| Redwood City | California |
| Redmond | Washington |
| Sunnyvale | Washington |
| Paoli | Pennsylvania |
| Paris | France |
| Menlo Park | California |
В этом примере у нас есть таблица products со следующими данными:
| product_id | product_name | category_id |
|---|---|---|
| 1 | Pear | 50 |
| 2 | Banana | 50 |
| 3 | Orange | 50 |
| 4 | Apple | 50 |
| 5 | Bread | 75 |
| 6 | Sliced Ham | 25 |
| 7 | Kleenex | NULL |
SQL Инструкция SELECT DISTINCT
SQL SELECT DISTINCT
Инструкция SELECT DISTINCT используется для возврата только определенных значений.
Внутри таблицы столбец часто содержит множество повторяющихся значений; иногда требуется только перечислить различные (определенные) значения.
Синтаксис SELECT DISTINCT
Демо базы данных
Ниже приведена выборка из таблицы «клиенты» в базе данных Northwind:
| CustomerID | CustomerName | ContactName | Address | City | PostalCode | Country |
|---|---|---|---|---|---|---|
| 1 |
Выбрать без DISTINCT
Следующая инструкция SQL выбирает все (включая дубликаты) значения из столбца «страна» в таблице «клиенты»:
Пример
Теперь давайте используем ключевое слово DISTINCT с приведенным выше оператором SELECT и посмотрим результат.
Выбрать с DISTINCT
Следующая инструкция SQL выбирает только отдельные значения из столбца «страна» в таблице «клиенты»:
Пример
Следующая инструкция SQL перечисляет количество различных (определенных) стран клиентов:
Пример
Примечание: приведенный выше пример не будет работать в Firefox и Microsoft Edge! Потому что COUNT (DISTINCT column_name) не поддерживается в базах данных Microsoft Access. Firefox и Microsoft Edge используют Microsoft Access в наших примерах.
Предикаты ALL, DISTINCT, DISTINCTROW и TOP
Эти предикаты задают записи, выбираемые с помощью запросов SQL.
Синтаксис
SELECT [ALL | DISTINCT | DISTINCTROW | [TOP n [PERCENT]]]
FROM таблица
Инструкция SELECT, содержащая эти предикаты, состоит из следующих частей:
Используется по умолчанию, если вы не указываете ни один из предикатов. Ядро СУБД Microsoft Access выбирает все записи, которые удовлетворяют условиям в инструкции SQL. Следующие два примера эквивалентны и возвращает все записи из таблицы Employees:
Исключает записи, содержащие повторяющиеся данные в выбранных полях. Для включения в результаты запроса значения каждого из полей, перечисленных в инструкции SELECT, должны быть уникальными. Например, у нескольких сотрудников, перечисленных в таблице Employees, могут быть одинаковые фамилии. Если две записи содержат «Глазков» в поле LastName, следующая инструкция SQL возвращает только одну запись, содержащую значение «Глазков»:
Если опустить DISTINCT, этот запрос возвратит обе записи с фамилией «Глазков».
Если предложение SELECT содержит несколько полей, запись будет включена в результаты только в том случае, если сочетание значений всех таких полей уникально.
Выходные данные запроса, использующего DISTINCT, не является обновляемыми и не отражают изменения, внесенные другими пользователями.
Данные не просто повторяют поля, но и не повторяются. Например, можно создать запрос, который соединяет таблицы Customers и Orders по полю CustomerID. Таблица «Клиенты» не содержит повторяют поля CustomerID, но таблица Orders содержит, так как у каждого клиента может быть множество заказов. В следующей SQL показано, как использовать DISTINCTROW для создания списка компаний, у кого есть хотя бы один заказ, но нет сведений об этих заказах:
Если опустить DISTINCTROW, этот запрос создаст несколько строк для каждой компании, от которой поступало более одного заказа.
DISTINCTROW действует только в том случае, если вы выбираете поля из некоторых (но не всех) таблиц, используемых в запросе. DISTINCTROW игнорируется, если запрос содержит только одну таблицу или вы включаете поля из всех таблиц.
Возвращает записи, относящиеся к верхней или нижней части диапазона, заданного предложением ORDER BY. Предположим, что вы хотите получить имена 25 лучших студентов из группы 1994 г.:
Если не включить предложение ORDER BY, запрос вернет из таблицы Students произвольный набор, включающий 25 записей, которые удовлетворяют предложению WHERE.
Предикат TOP не выбирает между равными значениями. Если в предыдущем примере двадцать пятый и двадцать шестой средний балл совпадают, запрос вернет 26 записей.
Вы также можете использовать зарезервированное слово PERCENT для возвращения определенного процента записей из верхней или нижней части диапазона, заданного предложением ORDER BY. Предположим, что вместо 25 лучших студентов вы хотите получить 10 процентов худших студентов группы:
Предикат ASC позволяет вернуть нижние значения. Значение после TOP должно быть целым числом без знака.
TOP не влияет на возможность обновления запроса.
Имя таблицы, из которой извлекаются записи.
Выбор DISTINCT из (расширения интеллектуального анализа данных)
Возвращает все возможные состояния выбранного столбца модели. Возвращаемые значения зависят от того, какие значения содержит указанный столбец — дискретные, дискретизированные числовые или непрерывные числовые значения.
Синтаксис
Аргументы
n
Необязательный параметр. Целое число, указывающее количество возвращаемых строк.
список выражений
Список связанных идентификаторов столбцов (производных от модели) или выражений.
model
Идентификатор модели.
список условий
Условие ограничения значений, возвращаемых из списка столбцов.
expression
Необязательный элемент. Выражение, возвращающее скалярное значение.
Remarks
Инструкция SELECT DISTINCT FROM работает только с одним столбцом или с набором связанных столбцов. С набором несвязанных столбцов это предложение не работает.
Инструкция SELECT DISTINCT FROM позволяет напрямую ссылаться на столбец внутри вложенной таблицы. Пример:
Результаты инструкции SELECT DISTINCT FROM могут различаться в зависимости от типа столбца. В следующей таблице описаны поддерживаемые типы столбцов и выводимые инструкцией данные.
| Тип столбца | Выходные данные |
|---|---|
| Discrete | Уникальные значения в столбце. |
| Дискретизированный | Средняя точка каждого дискретного сегмента памяти в столбце. |
| С задержкой | Средняя точка для значений столбца. |
Пример дискретного столбца
Для столбцов, содержащих дискретные значения, результаты всегда включают недостающее состояние, показанное как значение NULL.
Пример непрерывного столбца
Следующий образец кода возвращает средний, минимальный и максимальный возраст для всех значений столбца.
| Midpoint Age | Minimum Age | Maximum Age |
|---|---|---|
| 62 | 26 | 97 |
Кроме того, запрос возвращает одну строку значений NULL, которая представляет отсутствующие значения.
Пример дискретизированного столбца
| Bucket Average | Bucket Minimum | Bucket Maximum |
|---|---|---|
| 24610,7 | 10000 | 39221,41 |
| 55115,73 | 39221,41 | 71010,05 |
| 84821,54 | 71010,05 | 98633,04 |
| 111633,9 | 98633,04 | 124634,7 |
| 147317,4 | 124634,7 | 170000 |
Можно увидеть, что значения [Yearly Income] столбца были разбиты на пять контейнеров, а также дополнительную строку значений NULL для представления отсутствующих значений.
Количество десятичных разрядов в результатах зависит от клиента, использованного для выполнения запроса. Здесь они были округлены до двух десятичных разрядов, с одной стороны — для простоты, а с другой — чтобы отразить значения, показанные в среде SQL Server Data Tools (SSDT).
К примеру, если при просмотре модели с помощью средства просмотра дерева решений щелкнуть узел, содержащий сгруппированных по показателю дохода клиентов, во всплывающей подсказке отобразятся следующие свойства узла:



