Основные функции ETL-систем
ETL – аббревиатура от Extract, Transform, Load. Это системы корпоративного класса, которые применяются, чтобы привести к одним справочникам и загрузить в DWH и EPM данные из нескольких разных учетных систем.
Вероятно, большинству интересующихся хорошо знакомы принципы работы ETL, но как таковой статьи, описывающей концепцию ETL без привязки к конкретному продукту, на я Хабре не нашел. Это и послужило поводом написать отдельный текст.
Хочу оговориться, что описание архитектуры отражает мой личный опыт работы с ETL-инструментами и мое личное понимание «нормального» применения ETL – промежуточным слоем между OLTP системами и OLAP системой или корпоративным хранилищем.
Хотя в принципе существуют ETL, который можно поставить между любыми системами, лучше интеграцию между учетными системами решать связкой MDM и ESB. Если же вам для интеграции двух зависимых учетных систем необходим функционал ETL, то это ошибка проектирования, которую надо исправлять доработкой этих систем.
Зачем нужна ETL система
Проблема, из-за которой в принципе родилась необходимость использовать решения ETL, заключается в потребностях бизнеса в получении достоверной отчетности из того бардака, который творится в данных любой ERP-системы.
Как работает ETL система
Все основные функции ETL системы умещаются в следующий процесс:
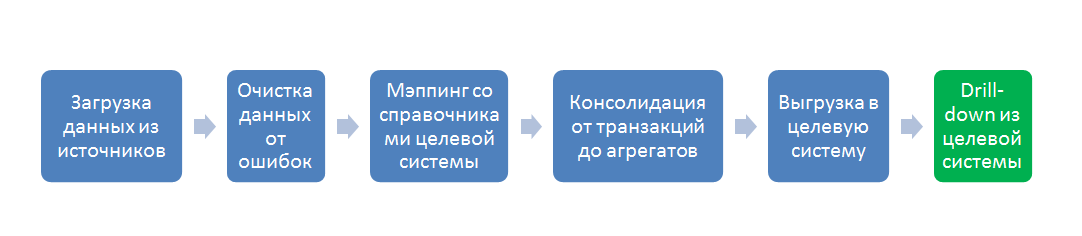
В разрезе потока данных это несколько систем-источников (обычно OLTP) и система приемник (обычно OLAP), а так же пять стадий преобразования между ними:
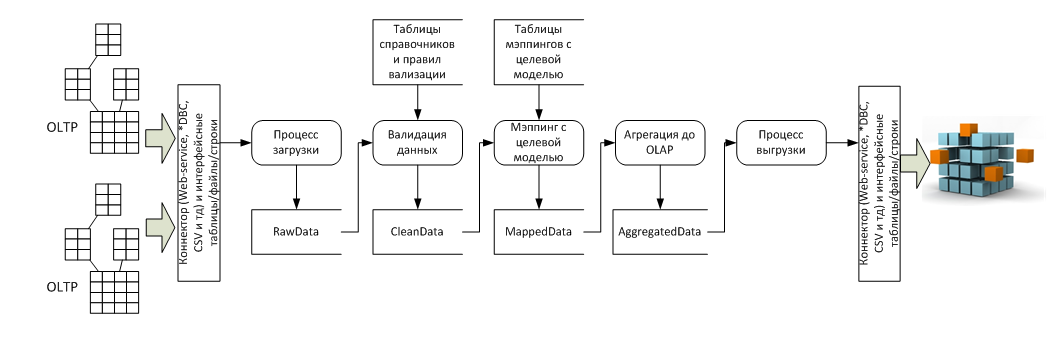
Особенности архитектуры
Реализация процессов 4 и 5 с точки зрения архитектуры тривиальна, все сложности имеют технический характер, а вот реализация процессов 1, 2 и 3 требует дополнительного пояснения.
Процесс загрузки
При проектировании процесса загрузки данных необходимо помнить о том что:
Процесс валидации
Данный процесс отвечает за выявление ошибок и пробелов в данных, переданных в ETL.
Само программирование или настройка формул проверки не вызывает вопросов, главный вопрос – как вычислить возможные виды ошибок в данных, и по каким признакам их идентифицировать?
Возможные виды ошибок в данных зависят от того какого рода шкалы применимы для этих данных. (Ссылка на прекрасный пост, объясняющий, какие существуют виды шкал — http://habrahabr.ru/post/246983/).
Ближе к практике в каждом из передаваемых типов данных в 95% случаев возможны следующие ошибки:
Соответственно проверки на ошибки реализуются либо формулами, либо скриптами в редакторе конкретного ETL-инструмента.
А если вообще по большому счету, то большая часть ваших валидаций будет на соответствие справочников, а это [select * from a where a.field not in (select…) ]
При этом для сохранения аудиторского следа разумно сохранять в системе две отдельные таблицы – rawdata и cleandata с поддержкой связи 1:1 между строками.
Процесс мэппинга
Процесс мэппинга так же реализуется с помощью соответствующих формул и скриптов, есть три хороших правила при его проектировании:
Заключение
В принципе это все архитектурные приемы, которые мне понравились в тех ETL инструментах, которыми я пользовался.
Кроме этого конечно в реальных системах есть еще сервисные процессы — авторизации, разграничения доступа к данным, автоматизированного согласования изменений, и все решения конечно являются компромиссом с требованиями производительности и предельным объемом данных.
Извлечение, преобразование и загрузка (ETL)
Распространенной проблемой, с которой сталкиваются организации, является сбор данных из нескольких источников в нескольких форматах и перемещение их в одно или несколько хранилищ данных. Тип хранилища данных в целевой и исходной средах может отличаться, также как и формат. Иногда данные необходимо форматировать или очистить до загрузки в конечное расположение.
За несколько лет для решения этих проблем было разработано много средств, служб и процессов. Независимо от используемого процесса, существует общая потребность в координации работы и преобразовании данных в конвейере. В следующих разделах описываются распространенные методы, используемые для выполнения этих задач.
Извлечение, преобразование и загрузка (ETL)
Извлечение, преобразование и загрузка (ETL) представляет собой конвейер данных, в рамках которого данные собираются из различных источников, преобразовываются в соответствии с бизнес-правилами и загружаются в целевое хранилище данных. Процесс преобразования в конвейере ETL выполняется в специальной подсистеме. Зачастую для временного хранения данных во время их преобразования и до загрузки в пункт назначения используются промежуточные таблицы.
Обычно в процессе преобразования данных применяются различные операции (например, фильтрация, сортировка, агрегирование, объединение, очистка, дедупликация и проверка данных).

Часто три этапа ETL выполняются параллельно, чтобы сэкономить время. Например, при извлечении данных процесс преобразования может уже обрабатывать полученные данные и подготавливать их для загрузки, а процесс загрузки может начать обрабатывать подготовленные данные, не дожидаясь полного завершения извлечения.
Соответствующие службы Azure:
Извлечение, загрузка и преобразование (ELT)
Конвейер извлечения, загрузки и преобразования (ELT) отличается от ETL исключительно средой выполнения преобразования. В конвейере ELT преобразование происходит в целевом хранилище данных. В этом случае для преобразования данных вместо специальной подсистемы используются средства обработки целевого хранилища данных. Это упрощает архитектуру за счет удаления механизма преобразования из конвейера. Еще одним преимуществом этого подхода является то, что масштабирование целевого хранилища данных также улучшает производительность конвейера ELT. Тем не менее ELT работает надлежащим образом, только если целевая система имеет достаточную производительность для эффективного преобразования данных.

Обычно конвейер ELT применяется для обработки больших объемов данных. К примеру, вы можете извлечь все исходные данные в неструктурированные файлы в масштабируемое хранилище (например, распределенную файловую систему Hadoop (HDFS) или Azure Data Lake Store). Затем для выполнения запроса исходных данных можно использовать такие технологии, как Spark, Hive или PolyBase. Ключевой особенностью ELT является то, что хранилище данных, используемое для выполнения преобразования, — это то же хранилище, в котором данные в конечном счете потребляются. Это хранилище данных считывает данные непосредственно из масштабируемого хранилища, вместо того чтобы загружать их в собственное защищаемое хранилище. Этот подход пропускает этап копирования (присутствующий в ETL), который может занимать много времени при обработке больших наборов данных.
Хранилище данных управляет только схемой данных и применяет ее при чтении. Например, кластер Hadoop, использующий Hive, описывает таблицу Hive, где источником данных является фактический путь к набору файлов в HDFS. В Azure синапсе Polybase может добиться того же результата, — создавая таблицу для данных, хранимых извне, в саму базу данных. Когда исходные данные загружены, данные, имеющиеся во внешних таблицах, можно обрабатывать, используя возможности хранилища данных. В сценариях с большими данными это означает, что хранилище данных должно поддерживать массовую параллельную обработку (MPP), когда данные разбиваются на более мелкие фрагменты, а обработка этих фрагментов распределяется сразу между несколькими компьютерами в параллельном режиме.
Последний этап конвейера ELT обычно заключается в преобразовании исходных данных в окончательный формат, более эффективный для тех типов запросов, которые необходимо поддерживать. Например, данные могут быть секционированы. Кроме того, ELT может использовать оптимизированные форматы хранения, такие как Parquet, которые хранят данные, ориентированные на строки, в один столбец и обеспечивают оптимизированное индексирование.
Соответствующие службы Azure:
Поток данных и поток управления
В контексте конвейеров данных поток управления обеспечивает обработку набора задач в правильном порядке. Для этого используется управление очередностью. Эти ограничения можно рассматривать как соединители на схеме рабочего процесса, показанной ниже. Каждая задача имеет результат (успешное завершение, сбой или завершение). Все последующие задачи начинают обработку данных, только когда предыдущая задача завершена с одним из этих результатов.
Потоки управления выполняют потоки данных в качестве задачи. В рамках задачи потока данных данные извлекаются из источника, преобразовываются и загружаются в хранилище данных. Выходные данные одной задачи потока данных могут быть входными данными для следующей задачи потока данных, а потоки данных могут выполняться параллельно. В отличие от потоков управления, вы не можете добавить ограничения между задачами в потоке данных. Однако вы можете добавить средство просмотра данных для наблюдения за данными по мере их обрабатывания каждой задачей.

На приведенной выше схеме показано несколько задач в потоке управления, одна из которых является задачей потока данных. Одна из задач вложена в контейнер. Контейнеры можно использовать для обеспечения структуры задач, тем самым формируя единицу работы. Одним из примеров является повторение элементов в коллекции (например, файлы в папке или инструкции базы данных).
Соответствующие службы Azure:
Выбор технологий
Дальнейшие действия
На следующей схеме эталонной архитектуры представлены сквозные конвейеры ELT в Azure:
ETL: качественные данные для принятия управленческих решений
Организационные изменения, рано или поздно происходящие в жизни любой компании, чаще всего влекут за собой необходимость интеграции различных информационных систем. Для чего нужна интеграция? Она необходима для того, чтобы разные системы могли использовать единое информационное пространство, осуществлять обмен данными, хранить, анализировать и обрабатывать их для последующего принятия управленческих и оперативных решений. Если принимать решения на основании данных, полученных только из одной системы, рано или поздно возникнет хаос, прежде всего по причине разнородного представления и детализации одних и тех же данных в различных системах, наличия ошибок, вызванных человеческим фактором и т.д. Как показывает опыт, наиболее эффективным способом хранения информации для ее последующего анализа и обработки, являются аналитические хранилища с витринами данных, на основе которых пользователь может осуществлять любые аналитические запросы и получать те или иные необходимые показатели.

Интеграционные методы: плюсы и минусы
Существуют различные методы интеграции информационных систем. У каждого из них свои преимущества и недостатки. Так, метод федерализации не предусматривает транспортировку данных, они остаются у владельцев, а доступ к ним осуществляется по запросу. Однако у этого подхода есть и существенные ограничения. Все федеративно распределенные базы, служащие источниками, данных должны находиться в формате одного приложения или СУБД, или требуется специальное ПО для интеграции гетерогенных сред. Кроме того, все источники должны находиться в постоянной доступности, а это не всегда осуществимо. Если обмен данными с одним из источников происходит на низкой скорости, это отразится на работе всего интеграционного механизма. Одновременный обмен данными с двумя различными источниками в момент пользовательского запроса должен осуществляться “на лету”. Это сопряжено с достаточно высокими накладными расходами, поскольку требует загрузки достаточно большого объема информации.
Другой метод интеграции, с применением универсальной шины данных (Universal Serial Bus), также имеет ряд функциональных ограничений. Это, прежде всего, пропускная способность, поскольку шина представляет собой сервис со встроенным механизмом регистрации гарантированной доставки. Если необходимо передать мегабайты данных или осуществить обмен мастер-данными, периодически синхронизировать отдельные документы, то применение универсальной шины будет целесообразно и удобно. Но когда речь идет о постоянном потоке данных, в том числе, генерируемом умными устройствами, пропускной способности шины будет явно недостаточно. К примеру, в реализованном компанией RedSys проекте по развертыванию инфраструктуры для скоростных трамваев в Санкт-Петербурге, с помощью универсальной шины данных осуществляется передача мастер-данных, а также передается информация о сотрудниках из кадровой системы в систему управления движением транспорта.
Свои ограничения накладывает и интеграционный метод на основе репликации. В первую очередь, это требование наличия единой платформы от одного и того же вендора. Для репликации в гетерогенной среде необходимо наличие специального инструментария, выбор которого зависит от используемых в организации СУБД. Разумеется, это не может не отразиться на конечной себестоимости интеграционного проекта.
Мы сегодня живем и работаем в эпоху больших данных, которые генерируют не только информационные системы, с которыми работают люди, но и умные устройства и датчики Интернета вещей, а также множество других неодушевленных машин. Для получения и обработки таких объемов данных лучше всего подходит метод интеграции ETL (Extract, Transform, Load). Он позволяет получать данные, проверять их, унифицировать, сохранять для последующей подготовки на их основе аналитической информации.
В механизме ETL-интеграции источник данных может выступать как в качестве клиента, так и в качестве сервера. Во втором случае целесообразным будет применение модулей извлечения измененных данных CDC (Change Data Capture). В тех случаях, когда источник данных одновременно занят решением других задач, либо с ним работают пользователи, использование CDC позволяет избежать дополнительных нагрузок. Источник данных может быть назначен и в качестве клиента. В этом случае система, которая служит источником данных сама переводит данные в CSV, XML или другой универсальный промышленный формат, а ETL периодически забирает эти файлы для дальнейшей обработки.
Метод ETL-интеграции характеризуется глубоким преобразованием данных. Она осуществляется в хранилище данных, которое включает в себя, в классической модели, три слоя. Первый слой представляет собой копии источников данных с добавлением специальных ключей, обеспечивающих уникальность и историчность информации. Второй слой отвечает за логическую обработку и унификацию. Он формирует из данных объектную модель в аналитическом разрезе. Третий слой осуществляет загрузку витрин данных для анализа, с приведением всех показателей к нужным разрезам, всеми необходимыми расчетами и т.д.
Когда речь идет о нескольких обширных несинхронизированных источниках данных, разрозненных справочниках НСИ, эти данные необходимо привести в унифицированный вид. Здесь на помощь приходят MDM-системы. В разветвленных холдинговых структурах, где могут работать десятки систем от различных производителей, без MDM порой очень сложно, например, подсчитать доходы и расходы по тем или иным статьям доходов и расходов. Некачественные данные способны существенно сузить ценность BI-информации, на основании анализа которой принимаются управленческие решения. Для дальнейшей поддержки качества данных необходима связь с источником, благодаря которой можно было бы передавать информацию для исправления. Также может быть сформирована специальная витрина или “корзина” низкокачественных данных, которые были по тем или иным причинам отвергнуты. Обнаружить такие данные помогают механизмы ETL.
Инструментарий и специалисты
Что касается инструментов для ETL-интеграции, то здесь достаточно широкое поле для выбора. Существуют как специализированные решения для конкретных СУБД, разработанные чаще всего их же разработчиками (Oracle Data Integrator, IBM DataStage, Informatica PC, Integration Services (SSIS) в составе MS SQL Server), а есть универсальные продукты. Лидером “магического квадранта” Gartner в сегменте решений для ETL-интеграции считается компания Informatica с ее продуктами. Все это системы промышленного уровня, которые умеют динамически распределять нагрузку между источниками и BI-хранилищем, поддерживают параллелизм выполнения операций и обладают целым рядом других функций. Как правило, платформа хранилища данных у заказчика уже определена, поэтому целесообразно будет использовать ETL-решение от разработчика платформы, используемой в хранилище. Решения компании Informatica весьма дорогостоящие, однако по техническим возможностям они же и являются наиболее продвинутыми, наиболее производительными и масштабируемыми. Их можно применять интегрировать с хранилищем данных на любой платформе.
В основе реализованного компанией RedSys проекта по построению хранилища данных в Пенсионном Фонде РФ лежат решения компании IBM, а в качестве ETL-инструментария используется IBM DataStage. Для поддержки интеграционных ETL-проектов в организации необходимо наличие трех категорий специалистов: архитекторов, в чьи обязанности входит проектирование хранилища данных; аналитики, как бизнес, так и системные, компетенции которых заключаются в сборе данных и требований бизнеса, составлении спецификаций, а также программисты, занимающиеся отладкой ETL-процессов.
Выгоды для бизнеса
Что дает ETL-интеграция бизнесу? Выгоду можно охарактеризовать двумя словами: “дорого, но эффективно”. Конечно, это весьма затратная составляющая комплексного проекта по построению аналитического хранилища данных. Поэтому все преимущества нужно рассматривать именно в разрезе наличия или отсутствия единого BI-хранилища в компании. Его отсутствие ведет к тому, что бизнес просто не получит оперативно ответы на стратегически важные вопросы. Единый взгляд на картину производства и продажи продуктов и услуг, их доходность и себестоимость, позволяет, в том числе минимизировать разногласия между производственными и финансовыми подразделениями компании, а в случае необходимости — перераспределить ресурсы в пользу более выгодных и эффективных направлений. Нельзя забывать и о снижении затрат. Вместо отдельных департаментов и сотрудников, собирающих данные в рамках своих бизнес-единиц, данные собираются в автоматизированном режиме и гораздо быстрее, при этом их качество несравнимо выше. Наконец, использование ETL-интеграции позволяет заказчику сосредоточить усилия на организационной, а не технической составляющей BI-проекта.
Чернобровов Алексей Аналитик
ETL: что такое, зачем и для кого

В статье рассмотрено одно из ключевых BI-понятий (Business Intelligence) – ETL-технологии: определение, история возникновения, основные принципы работы, примеры реализации и типовые варианты использования (use cases). Также отмечены некоторые проблемы применения ETL и способы их решения с помощью программных инструментов обработки больших данных (Big Data).
Что такое ETL и зачем это нужно
Начнем с определения: ETL (Extract, Transform, Load) – это совокупность процессов управления хранилищами данных, включая [1]:
Понятие ETL возникло в результате появления множества корпоративных информационных систем, которые необходимо интегрировать друг с другом с целью унификации и анализа хранимых в них данных. Реляционная модель представления данных, подходящая для потребностей транзакционных систем, оказалась неэффективной для комплексной обработки и анализа информации. Поиск унифицированного решения привел к развитию хранилищ и витрин данных – самостоятельных систем хранения консолидированной информации в виде измерений и показателей, что считается оптимальным для формирования аналитических запросов [2].
Прикладное назначение ETL состоит в том, чтобы организовать такую структуру данных с помощью интеграции различных информационных систем. Учитывая, что BI-технологии позиционируются как «концепции и методы для улучшения принятия бизнес-решений с использованием систем на основе бизнес-данных» [3], можно сделать вывод о прямой принадлежность ETL к этому технологическому стеку.
Как устроена ETL-система: архитектура и принцип работы
Независимо от особенностей построения и функционирования ETL-система должна обеспечивать выполнение трех основных этапов процесса ETL-процесса (рис.1) [4]:
 Рис. 1. Обобщенная структура процесса ETL
Рис. 1. Обобщенная структура процесса ETL
Таким образом, ETL-процесс представляет собой перемещение информации (потока данных) от источника к получателю через промежуточную область, содержащую вспомогательные таблицы, которые создаются временно и исключительно для организации процесса выгрузки (рис. 2) [1]. Требования к организации потока данных описывает аналитик. Поэтому ETL – это не только процесс переноса данных из одного приложения в другое, но и инструмент подготовки данных к анализу.
 Рис. 2. Потоки данных между компонентами ETL
Рис. 2. Потоки данных между компонентами ETL
Для подобных запросов предназначены OLAP-системы. OLAP (Online Analytical Processing) – это интерактивная аналитическая обработка, подготовка суммарной (агрегированной) информации на основе больших массивов данных, структурированных по многомерному принципу. При этом строится сложная структура данных – OLAP-куб, включающий таблицу фактов, по которым делаются ключевые запросы и таблицы агрегатов (измерений), показывающие, как могут анализироваться агрегированные данные. Например, группировка продуктов по городам, производителям, потребителям и другие сложные запросы, которые могут понадобиться аналитику. Куб потенциально содержит всю информацию, нужную для ответов на любые количественные и пространственно-временные вопросы. При огромном количестве агрегатов зачастую полный расчёт происходит только для некоторых измерений, для остальных же производится «по требованию» [6].
Таким образом, основные функции ETL-системы можно представить в виде последовательности операций по передаче данных из OLTP в OLAP (рис. 3) [7]:
 Рис. 3. ETL-процесс по передаче данных от OLTP в OLAP
Рис. 3. ETL-процесс по передаче данных от OLTP в OLAP
Немного про хранилища и витрины данных
ETL часто рассматривают как средство переноса данных из различных источников в централизованное КХД. Однако КХД не связано с решением какой-то конкретной аналитической задачи, его цель — обеспечивать надежный и быстрый доступ к данным, поддерживая их хронологию, целостность и непротиворечивость. Чтобы понять, каким образом КХД связаны с аналитическими задачами и ETL, для начала обратимся к определению.
Корпоративное хранилище данных (КХД, DWH – Data Warehouse) – это предметно-ориентированная информационная база данных, специально разработанная и предназначенная для подготовки отчётов и бизнес-анализа с целью поддержки принятия решений в организации. Информация в КХД, как правило, доступна только для чтения. Данные из OLTP-системы копируются в КХД таким образом, чтобы при построении отчётов и OLAP-анализе не использовались ресурсы транзакционной системы и не нарушалась её стабильность. Есть два варианта обновления данных в хранилище [8]:
ETL-процесс позволяет реализовать оба этих способа. Отметим основные принципы организации КХД [8]:
Витрина данных (Data Mart) представляет собой срез КХД в виде массива тематической, узконаправленной информации, ориентированного, например, на пользователей одной рабочей группы или департамента. Витрина данных, аналогично дэшборд-панели, позволяет аналитику увидеть агрегированную информацию в определенном временном или тематическом разрезе, а также сформировать и распечатать отчетные данные в виде шаблонизированного документа [9].
При проектировании хранилищ и витрин данных аналитику следует ориентироваться на возможности их прикладного использования и с учетом этого разрабатывать ETL-процессы. Например, если известно, что информация, поступающая из определенных подразделений, является самой важной и полезной, а также наиболее часто анализируется, то в регламент переноса данных в хранилище стоит внести соответствующие приоритеты. Это позволит ускорить работу с информацией, что особенно важно для data-driven организаций со сложной многоуровневой филиальной структурой и большим количеством подразделений [4].
Прикладные кейсы использования ETL-технологий
Рассмотрим пару типовых примеров использования ETL-систем [10].
Кейс 1. Прием нового сотрудника на работу, когда требуется завести учетную карточку во множестве корпоративных систем. В реальности в средних и крупных организациях этим занимаются специалисты разных подразделений, не скоординировав задачу между собой. Поэтому на практике часто возникают ситуации, когда принятый на работу сотрудник подолгу не может получить банковскую карту, потому что его учетная запись не была вовремя заведёна в бухгалтерии, а уже уволенные сотрудники имеют доступ к корпоративной почте и приложениям, т.к. их аккаунты не заблокированы в домене. ETL поможет быстро наладить взаимодействие между всеми корпоративными информационными системами.
Аналогичным образом ETL-технологии помогут автоматизировать удаление аккаунтов сотрудника из всех корпоративных систем в случае увольнения. В частности, как только в HR-систему попадут данные о дате окончания карьеры сотрудника на этом месте работы, информация о необходимости блокировки его записи поступит контроллеру домена, его корпоративная почта автоматически архивируется, а почтовый ящик блокируется. Также возможен полуавтоматический режим с созданием заявки на блокировку в службу технической поддержки, например, Help Desk.
Кейс 2. Разноска платежей, когда при взаимодействии со множеством контрагентов необходимо сопоставить информацию в виде платёжных документов, с деньгами, поступившими на расчетный счёт. В реальности это два независимых потока данных, которые сотрудники бухгалтерии или операционисты связывают вручную. Далеко не все корпоративные финансовые системы имеют функцию автоматической привязки платежей.
Итак, информация о платежах поступает от платежной сети в зашифрованном виде, т.к. содержит персональные данные. Вторым потоком данных являются файлы в формате DBF, содержащие информацию о банках-контрагентах, которая требуется для геолокации платежа. Наконец, с минимальной задержкой в три банковских дня, приходят деньги и выписка с платежами, проведёнными через банк-партнёр. Отметим, что в реальности прямой связи между всеми этими данными нет: номера документов, указанные в реестрах от платёжной системы и банка, не совпадают, а из-за особенностей работы банка дата платежа, которая значится в выписке, может не соответствовать дате реальной оплаты, которая содержится в зашифрованном файле реестра.
Расшифровку данных можно включить в ETL-процесс, в результате чего получится текстовый файл сложной структуры, содержащий ФИО, телефон, паспортные данные плательщика, сумму и дату платежа, а также дополнительные технические данных, идентифицирующие транзакцию. Это как раз позволит связать платёж с данными из банковской выписки. Данные из реестра обогащаются информацией о банках-контрагентах (филиалах, подразделениях, городах и адресах отделений), после этого осуществляются их соответствие (мэппинг) к конкретным полям таблиц корпоративных информационных систем и загрузка в КХД. Обогащение уже очищенных данных происходит в рамках реляционной модели с использованием внешних ключей.
После прихода банковской выписки запускается ещё один ETL-процесс, задача которого состоит в сопоставлении ранее полученной информации о платежах с реально пришедшими деньгами. Поскольку выписки приходят из банка в текстовом формате, первым шагом трансформации является разбор файла, затем идет процесс автоматической привязки платежей с использованием информации, ранее загруженной в корпоративную систему из реестров платежей и банков. В процессе привязки происходит сравнение не только ключей, идентифицирующих транзакцию, но и суммы и ФИО плательщика, а также отделения банка. Также решается задача исправления неверной даты платежа, указанной в банковской выписке, на реальную дату его совершения.
В результате нескольких ETL-процессов получилась система автоматической привязки платежей, при этом основные затраты были связаны с не с разработкой программного обеспечения, а с проектированием и изучением форматов файлов. В редких случаях ручной привязки обогащение данных с помощью ETL-технологии существенно облегчает эту процедуру. В частности, наличие телефонного номера плательщика позволяет уточнить данные о платеже лично у него, а геолокация платежа даёт информацию для аналитических отчётов и позволяет более эффективно отслеживать переводы от партнёров-брокеров (рис. 4).
 Рис. 4. Организация разноски платежей с помощью ETL
Рис. 4. Организация разноски платежей с помощью ETL
Современный рынок ETL-систем и особенности выбора
Существует множество готовых ETL-систем, реализующих функции загрузки данных в КХД. Среди коммерческих решений наиболее популярными считаются следующие [11]:
К категории условно бесплатных можно отнести [11]:
При выборе готовой ETL-системы необходимо, в первую очередь, руководствоваться не бюджетом ее покупки или стоимостью использования, а следующими функциональными критериями:
Многие из современных промышленных решений представляют собой технологические платформы, позволяющие масштабировать ETL-процессы с поддержкой параллелизма выполнения операций, перераспределением нагрузки по обработке информации между источниками и самой системой, а также другими функциями в области интеграции данных. Поэтому выбор ETL-средства – это своего рода компромисс между конкретным проектным решением, текущими и будущими перспективами использования ETL-инструментария, а также стоимостью разработки и поддержания в актуальном состоянии всех используемых функций ETL-процесса [2].
Некоторые проблемы ETL-технологий и способы их решения
Как правило, ETL-системы самостоятельно справляются с проблемами подготовки данных к агрегированию и анализу, выполняя операции очистки данных. При этом устраняются проблемы качества данных: проверка на корректность форматов и типов, приведение значений к нужному диапазону, заполнение пропусков, удаление дубликатов, противоречий и нарушений структуры. Однако, кроме очистки данных, можно выделить еще пару трудоемких задач, которые не решаются автоматически:
значимость данных с точки зрения анализа; сложность получения данных из источников; возможное нарушение целостности и достоверности данных; объем данных в источнике.
На практике часто приходится искать компромисс между этими факторами. Например, данные могут представлять несомненную ценность для анализа, но сложность их извлечения или очистки может свести на нет все преимущества от использования [4].
Таким образом, Big Data инструменты пакетной и потоковой обработки позволяют дополнить типовые ETL-системы, предоставляя бизнес-пользователям более широкие возможности по работе с корпоративной информацией. Однако, в этом случае временные, трудовые и финансовые затраты на аналитику данных существенно возрастут, т.к. понадобятся дорогие специалисты: Data Engineer, который выстроит конвейер данных (pipeline), а также Data Scientist, который разработает программное приложение для онлайн-аналитики, включая оригинальные ML-алгоритмы. Впрочем, такие инвестиции будут оправданы, если предприятие достигло хотя бы 3-го уровня управленческой зрелости по модели CMMI, обладает большим количеством разных данных с высоким потенциалом для аналитики и стремится стать настоящей data-driven компанией. Однако, чтобы эти вложения принесли выгоду, а не превратились в пустые траты, стоит адекватно оценить свои потребности и возможности, возможно, с привлечением внешнего консультанта по аналитике данных.
Стоит отметить, что разработчики многих ETL-систем учитывают потребность аналитики больших данных с помощью своих продуктов и потому включают в их возможности работы с Apache Hadoop и Spark, как, например, Pentaho Business Analytics Platform [14]. В этом случае не придется самостоятельно разрабатывать средства интеграции ETL-системы с распределенными решениями сбора и обработки больших данных, а можно воспользоваться готовыми коннекторами и API-интерфейсами. Впрочем, это не отменяет необходимость предварительной аналитической работы по проектированию и реализации ETL-процесса. Организация сбора информации в хранилище данных может достигать до 80% трудозатрат по проекту. Учет различных аспектов ETL-процессов с прицелом на будущее позволит тщательно спланировать необходимые работы, избежать увеличения общего времени реализации и стоимости проекта, а также обеспечить BI-систему надежными и актуальными данными для анализа [2].



