От монолита к микросервисам
Цель статьи — в общих чертах обрисовать поэтапный процесс миграции от монолитной легаси системы к микросервисной архитектуре.
Что такое легаси-монолит?
Когда стоит задуматься о модернизации?
Отвлекитесь от текучки, мириад багов и бессонных релизных ночей и посмотрите на свои системы со стороны:
Если для системы справедливы пункты 1-3 — срочно модернизировать, 4-5 — еще какое-то время проживет, но уже пора строить стратегию модернизации/перехода.
Суть подхода
Для крупных легаси систем наиболее безболезненным является постепенный переход от монолита к микросервисной по следующим причинам:
Объект исследования
Рассмотрим самый тяжелый вариант, в котором сильные и запутанные связи распространяются и на FrontEnd и на BackEnd и на базу данных.
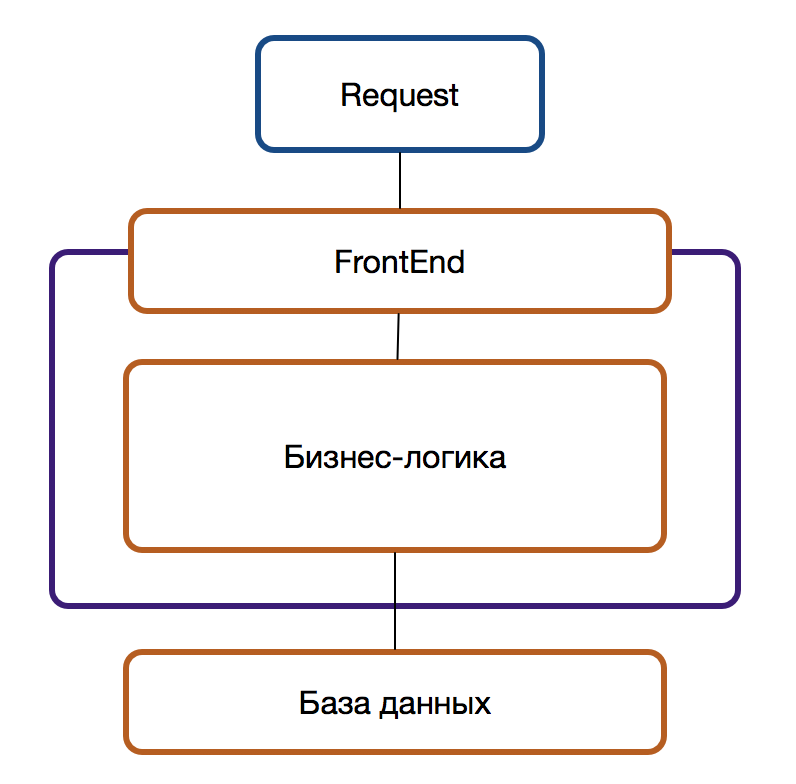
Новому — новое
Первое, что стоит сделать — перестать кормить монстра начать разрабатывать новую функциональность вне легаси системы. Для этого ставим между клиентом и нами прокси (например на API Gateway) и все обращения, связанные с новой функциональностью направляем на новый сервис (подробнее в статье о проксировании запросов). Так как в легаси системах редко кто задумывается о чистоте предметной области, а для реализации новой функциональности может понадобиться часть логики из легаси системы (которую можно запросить через обращение по API), следует на стороне нового сервиса ввести Anti Corruption Layer — он возьмет объекты старой предметной области легаси системы и переведет в новую, спроектированную по правилам предметно-ориентированного проектирования, сохранив тем самым новую модель чистой. Одновременно с вводом Anti Corruption Layer фиксируется технический долг об его вычленении из сервиса в будущем, когда необходимость отпадёт.
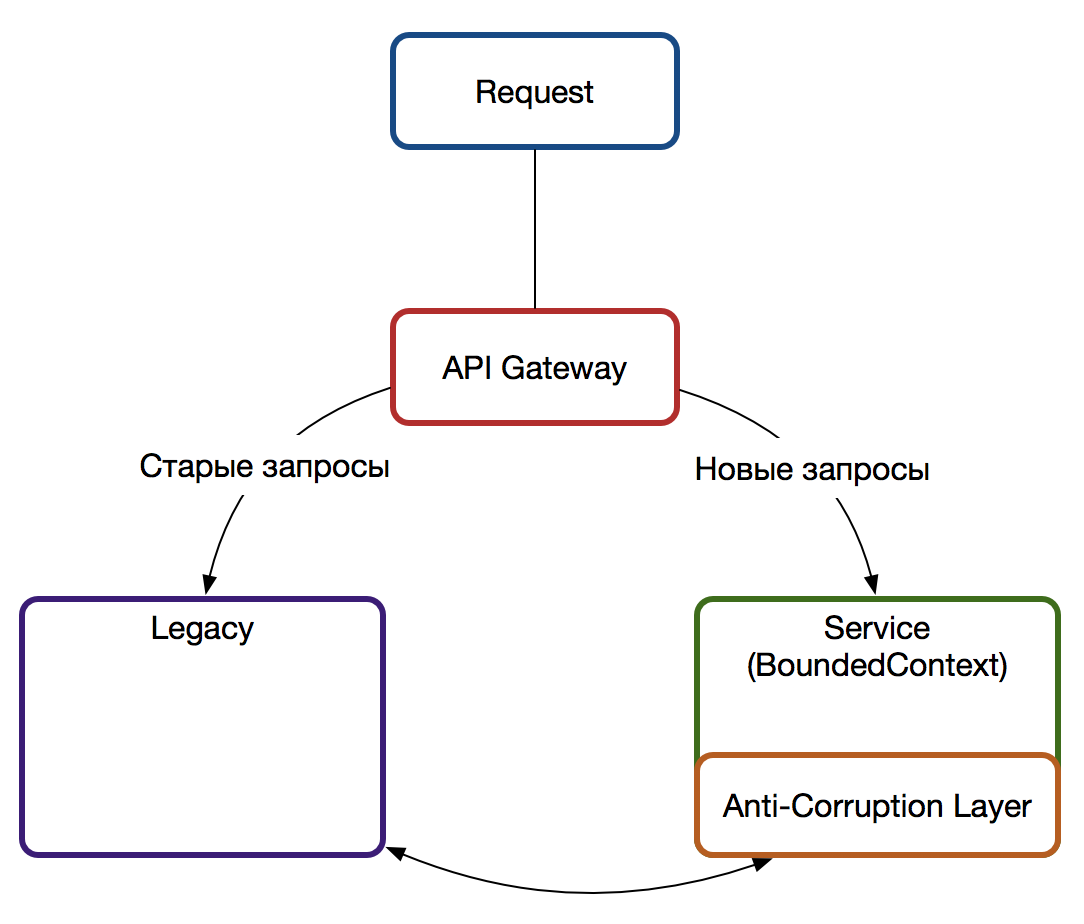
Раскол
В легаси системах обычно сосредоточено огромное количество логики и накопленных за много лет знаний, которые нередко нигде, кроме как в коде и не зафиксированы. Начав рядом разрабатывать тот же функционал мы сильно рискуем потерять, не учесть, забыть, не подумать и…
Таким образом, параллельно с разработкой сервисов под новую функциональность будет полезным вернуть контроль над легаси системой и самое простое, что мы можем для этого сделать, — это отделить фронт от бизнес-логики и бизнес-логику от базы. Этот процесс — постепенный и отделение следует проводить в рамках текущей работы, то есть: если изменяется логика расчета скидок и их отображение, то именно в рамках этой области проводится отделение.
Можно запланировать разделение не затрагиваемых текущей разработкой областей в рамках отдельных технических задач. В таком случае важно, чтобы эти активности были видимы и понятны всем участникам процесса и должна учитываться при планировании предстоящей работы.
Разделение дает следующие преимущества:
Огранка
Следуя принципу единственной ответственности применительно к пакетам/модулям и постепенно перенося функциональность, относящуюся к определенному контексту (BoundedContext) в рамки такого пакета мы неминуемо повышаем модульность и гибкость системы в целом. Такие пакеты становятся прекрасными кандидатами на роль микросервиса в будущем, но не стоит торопиться: до тех пор, пока углубляется понимание о предметной области, сущности могут мигрировать из одного контекста в другой и это проще проводить в рамках единой кодовой базы, чем между различными микросервисами в разных репозиториях.
На этом этапе у пакетов все еще может быть единый внешний API и единый слой доступа к данным, однако уже стоит озаботиться рефакторингом — пусть пакет и один, но постепенно необходимо идти к тому, чтобы отдельные пакеты не использовали один и тот же метод, а тем более класс, для доступа к требуемым данным.
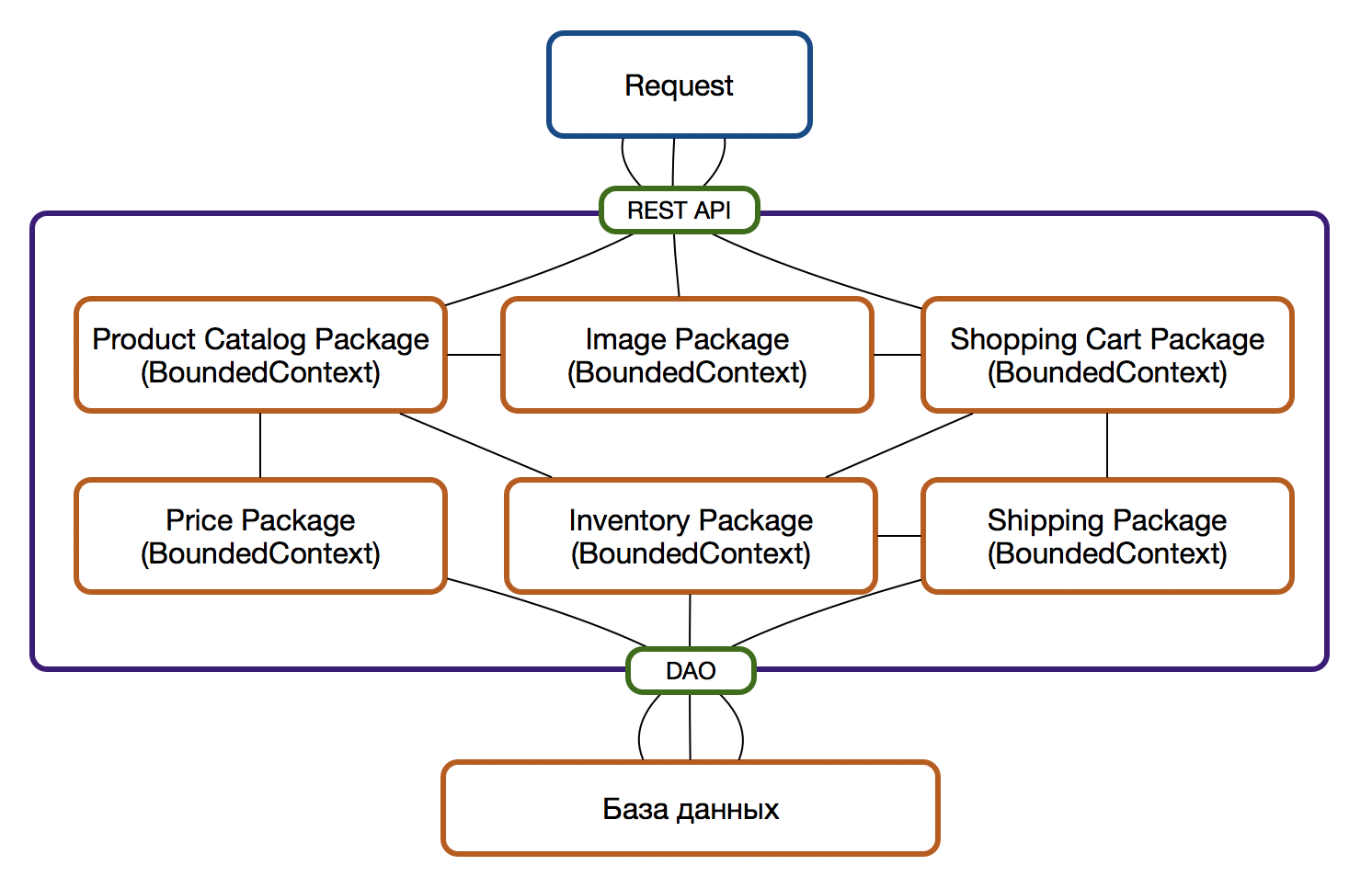
Если отчетливо видно, что двум пакетам требуются данные из одного Dao-интерфейса, то возможны следующие ситуации:
Теперь контекст включает в себя и логику доступа к данным и логику отображения данных и свои собственный API для предоставления данных и четко определенный интерфейс для взаимодействия с другими модулями системы. Последнее — важно. Не должно быть зависимостей между пакетами на уроне реализации, только через публичный интерфейсы, за которыми скрывается вся реализация пакета.
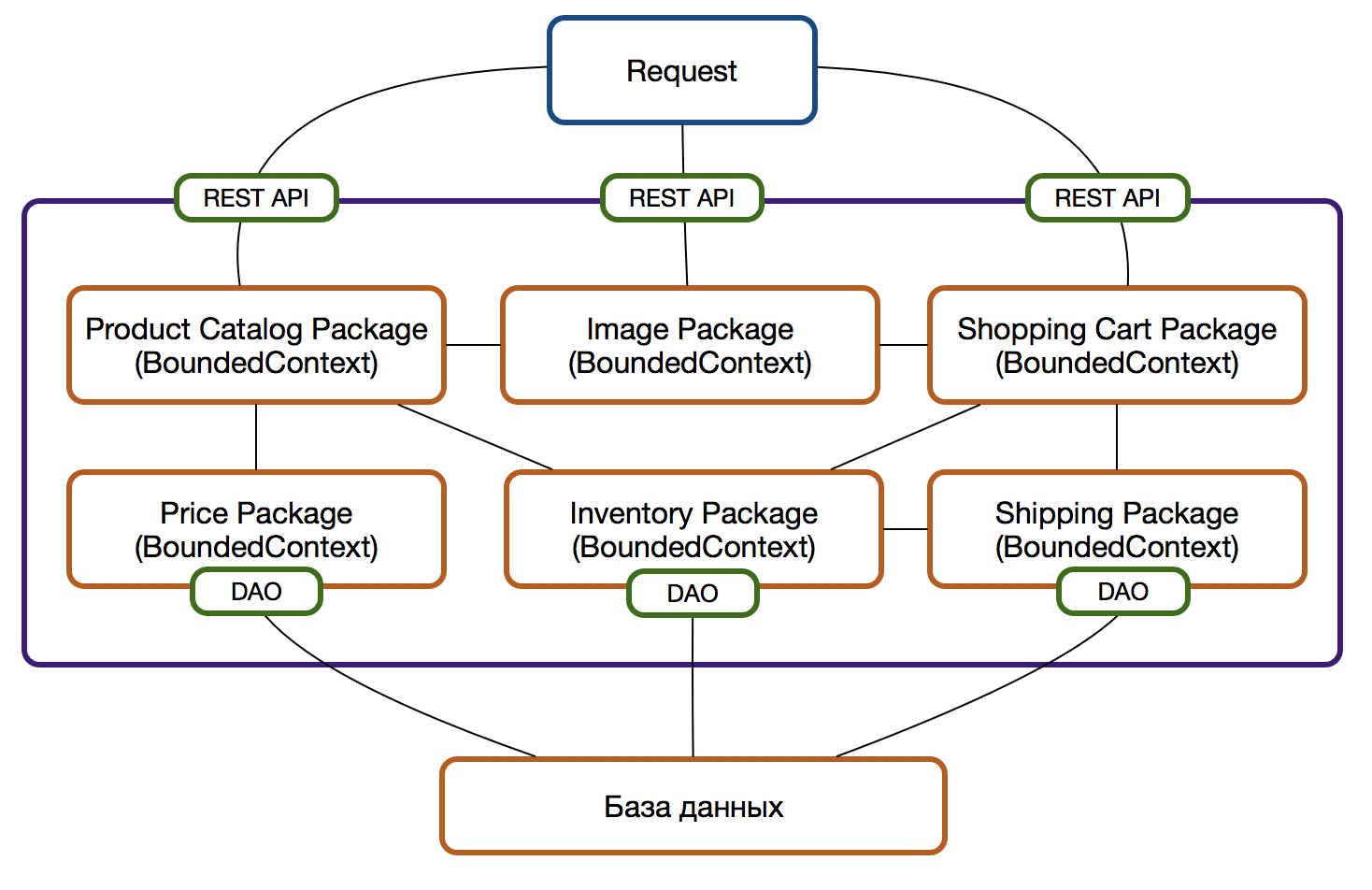
На уровне пакетов это выглядит следующим образом:
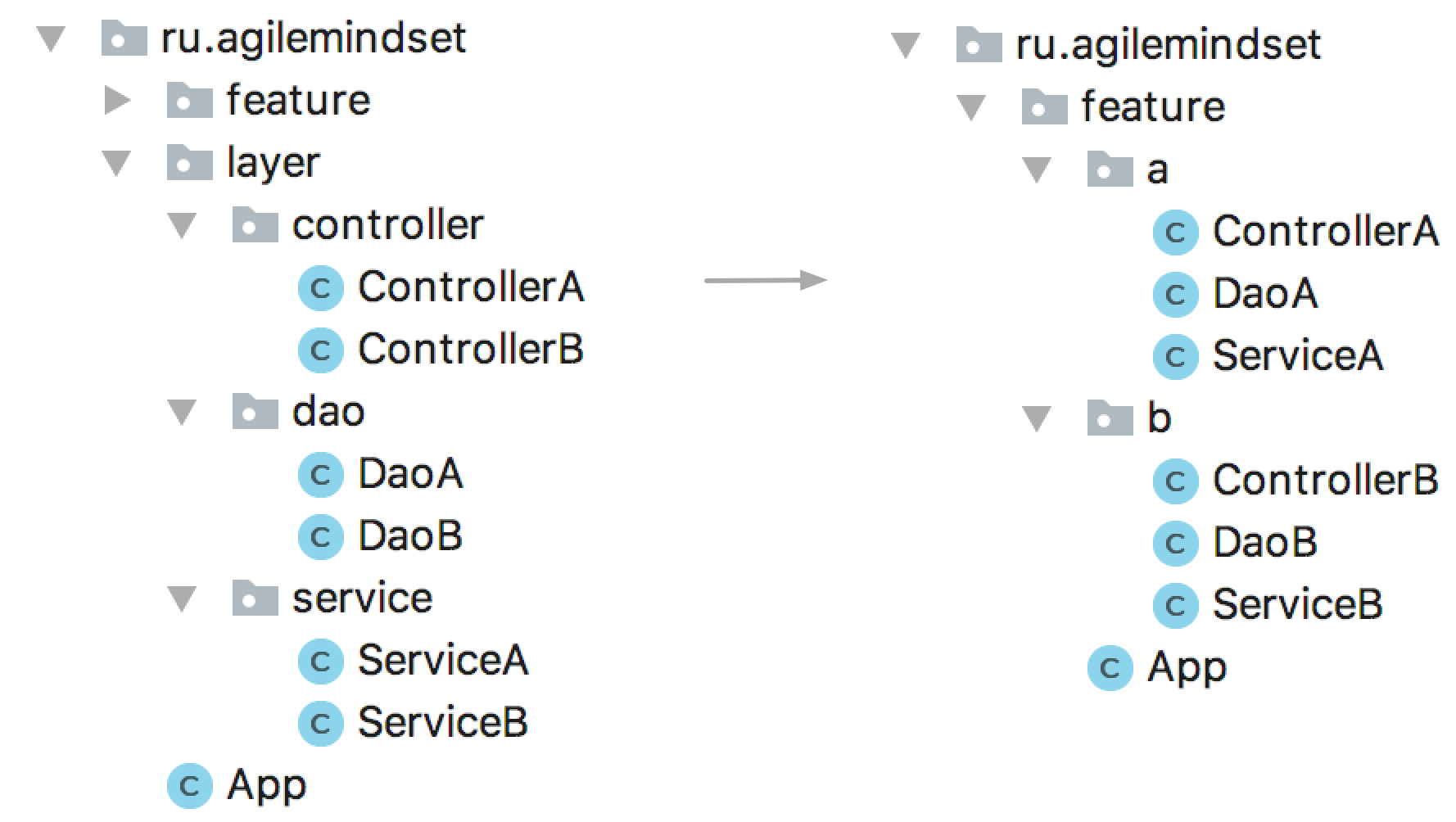
Покидая родную обитель
Все, кроме базы данных, готово к выделению пакетов в отдельные микросервисы. По мере необходимости, разумеется.
Нужно четко понимать, с какой целью и в каком порядке стоит выносить сервисы за пределы теперь уже хорошо организованного, модульного, монолита.
Что дальше?
Статья написана на основе собственного опыта, книг, статей, опыта сообщества. В ней не так много технических деталей, не рассмотрены вопросы декомпозиции баз данных, подходы к интеграции, тестированию, развертыванию, безопасности, мониторингу, шаблоны микросервисов, подходы к моделированию микросервисов.
Обо всем этом в следующих статьях.
Что почитать?
Перевод статьи Мартина Фаулера «Микросервисы» (оригинал)
У Вас проблемы с legacy — значит, Вам повезло! Распил монолита на PHP
Вступление
Причины появления legacy
Есть две основные причины появления legacy-кода.
У продуктов есть жизненный цикл, период большого спроса на популярные товары длится три-четыре месяца. Все лучшее конкуренты скопируют и сделают еще лучше, поэтому компании вынуждены регулярно выпускать новинки. Чтобы поддерживать объем выручки, новые продукты и новые версии выпускают каждые несколько месяцев, так продажи нового цикла компенсируют снижение продаж по товарам в конце цикла. По три-четыре крупных релиза в год делают и Apple, и Marvel, и в Oracle на рынке enterprise SAAS тоже квартальный релизный цикл. При этом, рецепта успеха не существует. 97% стартапов выкидывают наработки по своему продукту, и пробуют делать что-то новое, прежде чем найдут такой продукт, который у них покупают. Поэтому затраты на разработку MVP в стартапах максимально сокращают.
Проблемы?
Не всегда плохой код создает проблемы. Например, знаменитый пакет WordPress написан очень плохим кодом, но на его основе работает 38% интернет-сайтов. Стандартные работы выполняют специалисты на аутсорсинге по прайс-листу, а обновления устанавливаются по нажатию кнопки. Проблемы с WordPress начинаются, когда в него добавляют нестандартный код, и автоматическое обновление становится невозможно.
Что делать тем, кому повезло?
Начинать надо с тестирования
Серьезные изменения кода всегда приводят к неожиданным проблемам. Без надежного тестирования сбои приложения приведут к потере выручки и снижению продаж.
Перед началом доработки приложения надо подготовить план тестирования и отработать механизм релиза новых версий с возможностью отката к предыдущей. API и работу основной логики лучше проверять автоматическими приемочными тестами. Если автоматического приемочного тестирования в проекте нет, надо начинать обновление с обучения тестировщиков и составления плана тестирования.
Обновление версии языка
Через несколько лет после написания код становится несовместимым с актуальной версией языка, и это приводит к вороху проблем.
Для разработки новых продуктов нужны сторонние библиотеки, которые требуют современную версию платформы. Еще в старых версиях не исправляются проблемы. В проект на устаревшей версии языка сложнее найти разработчиков. Как следствие, растет и цена решения задач на основе существующего ПО, и усилия на поддержку работоспособности.
Составить список проблемы совместимости с новой версией PHP помогут утилиты статического анализа.
Rector поможет решить простые случаи несовместимости с новой версией, автоматически обновив часть кода.
Exakat поможет сделать анализ совместимости кода по версиям PHP, покажет список используемых расширений, проблемных участков кода, и поможет составить список задач на доработку.
Phan показывает использование в коде лексических конструкций, которые убраны из новых версий PHP.
Если для новой версии языка нет расширения, которое используется в приложении, участки кода с вызовами отсутствующих расширений придется переписать.
Обновление версии платформы или языка в таком случае выполняется достаточно быстро. Автор был инициатором обновления PHP с 5-ой версии на 7-ую для приложения с очень большим объемом кода, и эта задача была успешно выполнена командой за три недели.
Переход от монолита к сервисной архитектуре
Иногда проекты вырастают. Продукты стали успешными на рынке, и регулярно выпускаются. По законам Лемана сложность ПО растёт, функциональное содержание расширяется, вместе с ними штат разработчиков и объем кода постоянно увеличиваются. Замена устаревшего ПО в бюджет разработки не закладывается, чтобы улучшить финансовые результаты, поэтому качество программ ухудшается. Размер git-репозитория может исчисляться гигабайтами. Постепенно скорость разработки уменьшается, и когда разработчики перестают успевать выпускать ПО для новых продуктов, монолит решают разделять.
Перенос кода в пакеты открывает ряд возможностей:
можно сократить размер репозитория приложения,
разработчикам из разных команд можно предоставить только публичный API пакетов, и ограничить вызовы внутренних классов,
можно описать зависимости между своими модулями и использовать composer для управления зависимостями и версиями своих пакетов,
у каждого модуля может быть независимый цикл разработки, и работу над проектом можно масштабировать,
можно выпускать разные версии пакетов, и согласовать изменения API.
Разделение приложения на пакеты
Допустим, есть приложение на PHP, которое предоставляет клиентский API. Начинать любые изменения надо с процедур тестирования и релиза, которые включают план отката. Эти процедуры называют “release, control, validation” и “DevOps”. В активно развивающихся проектах тестирование и выкладка отработаны. В этом случае надо начинать разделять приложение с определения таких ограниченных контекстов, которые логично выделить в отдельные модули и сервисы.
Как пример, из приложения можно выделять обработку фотографий, аутентификацию пользователей, обработку платежей.
скопировать в модуль старый код и инвертировать в коде модуля зависимости через границу модуля, без рефакторинга или переписывания всего кода;
заменить в коде приложения прямые обращения к старому коду на вызовы сервиса из нового модуля; Для решения этой задачи используется две технологии: IoC-контейнер и менеджер зависимостей.
Когда в модуль перенесен код для реализации всех запланированных функциональных требований, можно удалить этот код из приложения.
Начать создавать пакеты можно в локальном каталоге, а для полноценной сборки и развертывания стоит создать собственный репозиторий пакетов, такой, как Packeton, и перенести код модулей в собственные git-репозитории. Так же, можно использовать платный репозиторий Private Packagist.
Как создать composer-пакет в приложении и зарегистрировать его как сервис в IoC-контейнере, можно посмотреть здесь: до изменений, после изменений, diff.
В примерах используется composer для управления зависимостями пакетов и Symfony Dependency Injection как IoC-контейнер для сервисов. У Вас может быть другой контейнер. Если в приложении нет IoC-контейнера, придется делать рефакторинг и реализовать внедрение зависимостей. Простейший пример добавления IoC-контейнера в приложение.
Решение проблем со связанностью кода
Есть два типа связанности:
а) код будущего модуля содержит вызовы структур, которые описаны в других частях приложения
б) код других частей приложения содержит описания структур, которые используются в будущем модуле.
Рассмотрим случаи связанности кода, и варианты выделения модулей в пакеты без трудоемкого рефакторинга.
1. Расширение классов, реализация интерфейсов, использование трейтов, когда декларация структур используется “через границу” будущего модуля.
Посмотрите пример связанности при наследовании: родительский и дочерний классы вызывают методы друг друга. После этого можно посмотреть решение: результат рефакторинга, diff коммита.
Основные алгоритмы расцепления связанности:
Сторонние библиотеки, которые используются в коде пакета, можно указать в зависимостях пакета.
Для интерфейсов, которые используются и в пакете, и в приложении, надо создать пакет контрактов, и указывать его в зависимостях.
Наследование от внешних классов с зависимостями надо превратить в композицию с помощью адаптеров, которые внедряются как сервисы.
Для защищенных свойств, которые используются в дочернем классе, надо сделать getter-методы, а для защищенных методов надо создать прокси-методы.
Наследование классов приложения от классов модуля стоит инвертировать в композицию с сервисом, который предоставляется новым пакетом.
2. Статические вызовы.
Синтаксис PHP допускает вызов статических методов у объектов как методов класса (пример). Если Вы выносите в пакет или обычную функцию или класс, у которого есть статический метод, эти функции/методы нужно добавить в публичное API пакета (пример, diff).
Аналогично, статические вызовы из пакета к методам классов приложения можно заменить статическими вызовами сервисов. Это будет реализация паттерна “мост”.
Ссылки: пример прямого статического вызова, пример инверсии зависимости статического вызова через внедрение сервиса, diff коммита.
Если несколько методов из разных классов используются вместе, для них можно создать сервис-фасад.
Аналогично, статические вызовы тех классов и функций, которые переносятся в модуль, нужно заменить обращениями к объекту сервиса-адаптера или фасада.
Если есть несколько независимых классов-“хелперов” (пример) или обычных пользовательских функций, которые используются одновременно и в приложении, и в новом модуле, из них можно создать отдельный composer-пакет, и указать его в зависимостях приложения и других пакетов.
5. Использование глобальных констант и констант классов.
6. Динамическое разрешение имен через строковые операции.
Такой алгоритм встречается внутри некоторых фреймворков. Однако, в коде приложения такой код создает большие сложности, и ясного алгоритма решения проблемы связанности здесь нет.
Эту конструкцию можно попробовать переписать в switch-структуру со статическим списком классов. К счастью, в приложениях подобный код встречается редко.
Оптимизация
В больших приложениях количество сервисов в IoC-контейнере бывает очень большим. Если в пакет выносится большой объем кода, у него могут быть десятки зависимостей. При обработке клиентских вызовов обычно создается только небольшая часть сервисов. Однако, при передаче зависимостей в конструктор класса контейнер будет создавать все перечисленные сервисы.
Есть несколько способов решения этой задачи:
Сервисы, которые передаются в пакет, можно объявить как lazy.
Объект API пакета можно объявить как Service Subscriber.
Разделить API пакета на несколько сервисов.
Service-Oriented Architecture
Хорошо, разделили код на пакеты, но при выкладке все собирается в одно приложение, и работает в одном процессе, как монолит. А где же сервис-ориентированная архитектура? До нее еще долгий путь.
При создании отдельных внутренних приложений-сервисов надо решить две задачи:
Детальное протоколирование вызовов всех сервисов. Каждому клиентскому запросу надо присваивать уникальный ID вызова, который передается во все сервисы при вызовах внутренних API, и каждый вызов сервиса надо протоколировать. Надо иметь возможность отследить вызовы сервисов по цепочке.
Гарантировать единственный результат выполнения запроса при сбое одного из сервисов, когда запрос к сервису передан заново. Пример: клиентский запрос на платеж с его счета на другой счет. При сбое внутреннего выделенного сервиса, который выполняет запись результатов транзакции и пересчитывает баланс на счетах пользователей, повторный запрос к нему не должен привести к двум денежным переводам с одного счета на другой.
Заключение
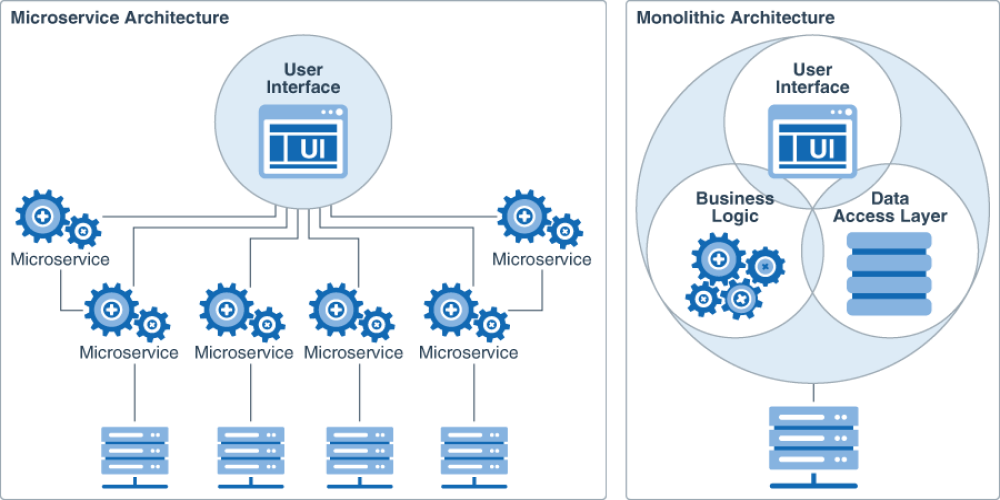
Монолитная vs Микросервисная архитектура

Что такое монолитная архитектура?
Монолитное приложение (назовем его монолит) представляет собой приложение, доставляемое через единое развертывание. Таким является приложение, доставленное в виде одной WAR или приложение Node с одной точкой входа.
Пример
Давайте представим классический интернет-магазин. Стандартные модули: UI, бизнес-логика и дата-слой. Возможны способы взаимодействия с сервисом: API REST и веб-интерфейс.
При построении монолита все эти вещи будут управляться внутри одного и того же модуля. Я не написал «один и тот же процесс», так как это было бы неверно для сценариев, в которых несколько экземпляров нашего модуля будут работать для более высоких нагрузок.
Рассмотрите пример на следующем рисунке, где все части находятся в одном и том же модуле развертывания:
Достоинства
Большим преимуществом монолита является то, что его легче реализовать. В монолитной архитектуре вы можете быстро начать реализовывать свою бизнес-логику, вместо того чтобы тратить время на размышления о межпроцессном взаимодействие.
Еще одна вещь — это сквозные (E2E) тесты. В монолитной архитектуре их легче выполнить.
Говоря об операциях, важно сказать, что монолит прост в развертывании и легко масштабируется. Для развертывания вы можете использовать скрипт, загружающий ваш модуль и запускающий приложение. Масштабирование достигается путем размещения Loadbalancer перед несколькими экземплярами вашего приложения. Как вы можете видеть, монолит довольно прост в эксплуатации.
Теперь давайте рассмотрим негативный аспект монолитной архитектуры.
Недостатки
Монолиты, как правило, перерождаются из своего чистого состояния в так называемый «большой шарик грязи». Вкратце это описывается как состояние, возникшее, потому что архитектурные правила были нарушены и со временем компоненты срослись.
Это перерождение замедляет процесс разработки: каждую будущую функцию будет сложнее развивать. Из-за того что компоненты растут вместе, их также необходимо менять вместе. Создание новой функции может означать прикосновение к 5 различным местам: 5 мест, в которых вам нужно написать тесты; 5 мест, которые могут иметь нежелательные побочные эффекты для существующих функций.
Ранее я говорил, что в монолите легко масштабировать. Это действительно так до тех пор, пока он не перерастёт в «большой шарик грязи», как упоминалось ранее. Масштабирование может быть проблематичным, когда только одной части системы требуются дополнительные ресурсы, ведь в монолитной архитектуре вы не можете масштабировать отдельные части вашей системы.
В монолите практически нет изоляции. Проблема или ошибка в модуле может замедлить или разрушить все приложение.
Строительство монолита часто протекает с помощью выбора основы. Отключение или обновление вашего первоначального выбора может быть затруднительным, потому что это должно быть сделано сразу и для всех частей вашей системы.
Что такое микросервисная архитектура?
В микросервисной архитектуре слабо связанные сервисы взаимодействуют друг с другом для выполнения задач, относящихся к их бизнес-возможностям.
Микросервисы в значительной степени получили свое название из-за того, что сервисы здесь меньше, чем в монолитной среде. Тем не менее, микро — о бизнес-возможностях, а не о размере.
По сравнению с монолитом в микросервисах у вас есть несколько единиц развертывания. Каждый сервис развертывается самостоятельно.
Пример
Давайте вновь рассмотрим в качестве примера Интернет-магазин.
Как и раньше, у нас есть: UI, бизнес-логика и дата-слой.
Здесь отличие от монолита состоит в том, что у всех вышеперечисленных есть свой сервис и своя база данных. Они слабо связаны и могут взаимодействовать с различными протоколами (например, REST, gRPC, обмен сообщениями) через свои границы.
На следующем рисунке показан тот же пример, что и раньше, но с разложением на микроуслуги.
Каковы преимущества и недостатки этого варианта?
Достоинства
Микросервисы легче держать модульными. Технически это обеспечивается жесткими границами между отдельными сервисами.
В больших компаниях разные сервисы могут принадлежать разным командам. Услуги могут быть повторно использованы всей компанией. Это также позволяет командам работать над услугами в основном самостоятельно. Нет необходимости координировать развертывание между командами. Развивать сервисы лучше с увеличением количества команд.
Микросервисы меньше, и благодаря этому их легче понять и проверить.
Меньшие размеры помогают, когда речь идет о времени компиляции, времени запуска и времени, необходимом для выполнения тестов. Все эти факторы влияют на производительность разработчика, так как позволяют затрачивать меньше времени на ожидание на каждом этапе разработки.
Более короткое время запуска и возможность развертывания микросервисов независимо друг от друга действительно выгодны для CI / CD. По сравнению с обычным монолитом он намного плавнее.
Микросервисы не привязаны к технологии, используемой в других сервисах. Значит мы можем использовать лучшие технологии подгонки. Старые сервисы могут быть быстро переписаны для использования новых технологий.
В микросервисах изолируемые разломы лучше по сравнению с монолитным подходом. Хорошо спроектированная распределенная система переживет сбой одного сервиса.
Недостатки
Все звучит довольно хорошо, но есть и недостатки.
Распределенная система имеет свою сложность: в ней вам приходится иметь дело с частичным отказом, более затруднительным взаимодействием при тестировании (тесты E2E), а также с более высокой сложностью при реализации взаимодействия между сервисами.
Транзакции легче проводить в монолите. Решением этой проблемы на микросервисах является Saga Pattern. Хорошее решение, но все же слишком громоздкое для реализации на практике.
Существуют эксплуатационные накладные расходы, а множество микросервисов сложнее в эксплуатации, чем несколько экземпляров сигнального монолита.
Помимо вышеперечисленных сложностей, для микросервисов также может потребоваться больше оборудования, чем для традиционных монолитов. Иногда микросервисы могут превзойти один монолит, если есть его части, которые требуют масштабирования до предела.
Изменения, затрагивающие несколько сервисов, должны координироваться между несколькими командами, а это может быть сложно, если команды еще не имели контактов.
Заключение
Все зависит от вашей организационной структуры. У вас есть 6 команд, которые будут работать над одним продуктом? Микросервисы могут подойти.
У вас есть команда из 3 разработчиков? Вероятно, они будут хорошо строить и поддерживать монолит.
Другими факторами являются скорость изменения и сложность. Высокие темпы изменений и высокая сложность могут быть факторами, которые заставляют выбрать архитектуру микросервиса.
Напротив, когда вы не очень хорошо знакомы с предметной областью, начать с монолита может быть полезно. Просто сделайте себе одолжение и постарайтесь сохранить его модульным. Это облегчит задачу, если вы когда-нибудь решите разделить свой монолит на несколько сервисов.
Микросервисы vs. Монолит
В начале ноября на ютуб-канале Яндекс.Практикума прошли дебаты «Микросервисы, Монолит и Зомби». Ведущие дебатов — наставник курса «Мидл Python-разработчик» Руслан Юлдашев и техлид курса Савва Демиденко — разобрали архитектуры двух систем, прошлись по реальным задачам и ошибкам из своей рабочей практики и по очереди защищали свои позиции.
Обсуждение растянулось на 100 минут, поэтому мы публикуем сокращённую текстовую расшифровку.

Этот материал будет полезен разработчикам, которые хотят научиться делать хорошо масштабируемые продукты и задумываются про архитектурные проблемы в разработке, а также для тех, кто принимает архитектурные решения в проектах.
Вы узнаете, как врачи регионов России не получали зарплату из-за микросервисов и сколько монолитов можно запустить, пока согласовывается интерфейс между сервисами.
Определение микросервиса и монолита
Понятно, что ставить вопрос, что лучше — микросервисы или монолит, не совсем уместно. Такой уровень архитектуры зависит от кучи факторов, и мы попробуем разложить некоторые из них.

Савва Демиденко — выступает за микросервисы
Занимаюсь разработкой в Avito, делаю программу курса «Мидл Python-разработчик» в Яндекс.Практикуме. Закончил Бауманку и Технопарк@mail.ru. Разрабатываю на Python и Golang. Люблю решать архитектурные задачи в веб-программировании.
Исходя из моей практики, монолитом называют то приложение, которое во время разработки сложно запустить на локальной машине.
Пример из последнего, с чем я сталкивался: в компании Avito есть легаси на PHP и продуктовые задачи, которые нужно решать этим кодом, чтобы двигать бизнес и зарабатывать больше денег. Но эта кодовая база старая — возможно, ей больше 5 лет. Её сложно поддерживать. Чтобы сделать продуктовую фичу, нужно много времени. Поэтому в Avito мы начали распиливать монолит в сторону микросервисов.
Микросервисом можно назвать тот продукт, который вмещается в голову одного разработчика. Микросервис — это фреймворк, хранилище, кэширующая система и 3—5 эндпойнтов.
В других компаниях я сталкивался с более широким понятием микросервиса. Например, сервис авторизации, у которого явно больше 3—5 API-интерфейсов: он регистрирует юзера, выдаёт токены JWT и реализует механизм одноразовых ключей. У него большая кодовая база, но он всё равно считается микросервисом.
Если разбираться, то микросервис — случай двух приложений с небольшой кодовой базой, которые взаимодействуют друг с другом по различным протоколам, например, HTTP. К тому же каждый из микросервисов работает с одной сущностью или одним бизнес-процессом и не пытается решить сразу несколько бизнес-задач в рамках одного приложения.
Итак, микросервис — это небольшой сервис, который использует одно хранилище, один key–value storage для кэша и не больше 10 эндпойнтов. Это удобно тем, что на знакомство с продуктом уходит пара дней: тебе дают задачу, ты изучаешь сервис и готов дальше с ним работать.

Руслан Юлдашев — выступает за монолит
Пишу код и запускаю веб-сервисы от Ташкента до Сан-Франциско. Наставник Яндекс.Практикума. Самоучка. Люблю, когда код облегчает жизни людей.
У меня задача попроще, потому что большинство проектов в мире — монолиты. Обычно это один репозиторий, где находится весь код проекта, включая пользователей, бизнес-логику, отправку нотификаций — всё, что делает приложение, хранится в одной большой кодовой базе.
Эти сервисы могут масштабироваться и работать под нагрузкой. Как правило, всё написано на одном языке. Возможно разделение языка для фронта и бэкэнда.
Если у вас нет message bus или queue и прочих характерных для микросервисов инструментов, то наверняка у вас монолит.
Общая архитектура
Постановка задачи
Мы будем говорить про различия в подходах на примере проекта онлайн-кинотеатра — аналога Netflix или Кинопоиска. Примерно такой проект делается на курсе «Мидл Python-разработчик» в Практикуме.
Весь курс строится следующим образом: после начала обучения студент проходит маленькое испытание, в котором решает задачи. У студента есть артефакт в виде SQLite, в котором заранее подготовлено 999 фильмов. Студент пишет немного кода, чтобы создать pipeline перекачки данных из этого хранилища в Elasticsearch.
Попутно в курсе мы рассказываем, почему мы используем SQLite, зачем нам нужен Elasticsearch. Вокруг этого хранилища мы создаём обвязку в виде Flask и обстреливаем тестами end-to-end.
Так мы проверяем уровень студента. Наш курс не рассчитан на новичков: наши студенты не «нулевые», а с каким-то опытом. Такое испытание важно, потому что в будущем мы будем решать задачу создания онлайн-кинотеатра из большого количества модулей.
По условиям задачи мы ожидаем большую нагрузку, собираемся делать супервзрывной большой проект, будем двигать всех в Рунете — это стартап. У нас есть примерно полгода, чтобы его запустить. Для успеха нужно проектировать архитектуру и выбрать монолитом или на микросервисах.

В процессе дебатов мы откроем голосование про то, какая архитектура тут лучше подойдет. В конце обсуждения мы посмотрим на его результаты.
Архитектура модулей
Вернёмся к архитектуре. У нас есть вот такая схема будущего онлайн-кинотеатра.
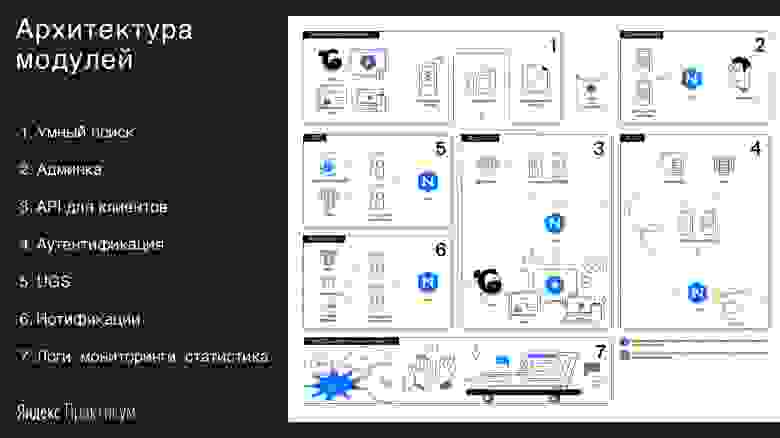
Савва: Схема годится одновременно и для микросервисной, и монолитной архитектур. Но в случае микросервисов нас зажимают в рамки основных постулатов работы с ними: отдельный репозиторий, только одно хранилище.
Пункты со второго по шестой — это доменные области. Похожим образом их можно выделить и в монолите.
Сразу рассмотрим третий блок — это будет gateway нашей системы. Все запросы от любых клиентов — телевизоров, планшетов — будут попадать сюда, в нашу точку входа. Её задача проста: она принимает и обрабатывает все запросы от юзеров, агрегирует и отдаёт данные.
В четвертом блоке мы будем заниматься вопросами безопасности: как нужно хранить пароли, нужно ли хэшить и солить. Это сервис аутентификации и авторизации. Напишем брутфорсер и проверим, насколько хорошо мы защищаем данные пользователей.
Сервис UGC будет заниматься хранением пользовательских данных: комментарии, лайки, история просмотров. Мы предоставим студенту возможность самостоятельно выбрать хранилище, оцениваем классическое реляционное решение или рассматриваем то, что лучше решает задачу вертикального или горизонтального масштабирования. Здесь же мы говорим об event sourcing и задачах для него.
Сервис нотификации уведомляет пользователя о чём-то новом: вышел фильм из закладок, кто-то оставил комментарий и вообще любые новости. Это решается с помощью большого числа технологий: рассылки очередями данных, пуши на веб-устройства с помощью вебсокетов. Ещё в онлайн-курсе мы немного затрагиваем тему пушей в мобильных устройствах на iOS и Android.
Руслан: Если я буду делать кинотеатр через монолит, то модули мне понадобятся такие же, как и здесь: админка, аутентификация, нотификации. Однако, всё это будет в одном репозитории. Скажем, я буду использовать Django, который решает большую часть из указанных задач. Останется Elasticsearch, чтобы сделать умный поиск, но это будет не отдельный сервис — я буду слать запросы напрямую из Django.
Схема в чём-то останется такой же, но с точки зрения кодовой базы набор технологий будет меньше. Большинством задач будут заправлять Django и Elasticsearch.
Особенности для команды
Мы разобрались, какими могут оказаться микросервисная и монолитная архитектуры. Теперь посмотрим, на что нужно обратить внимание при реализации сервиса.
Вне зависимости от архитектуры нужно смотреть на уровень команды, потянет ли она микросервисы, какие есть требования к отказоустойчивости, точности требований и так далее.
Савва: В микросервисах мы практически бесплатно получаем неплохую отказоустойчивость.
Микросервисы — не серебряная пуля. Они добавляют оверхеда и издержек на согласование контрактов между сервисом gateway и сервисом авторизации. Контракты — это различные схемы, например, JSON или спрятанная документация.
В случае с монолитом всё просто: мы делаем родительский класс, у которого есть функции и параметры, за которые отвечает сам язык. В случае с микросервисами всё более гибко и не так явно. По умолчанию мы не можем проверить, насколько согласованы контракты сервисов.
Руслан: Можно посмотреть примеры монолитов в больших компаниях. В чате пишут, что ivi сделан на Django — видимо, имеют в виду, что на монолитной архитектуре. Я знаю, что Instagram долгое время успешно работал на Django. Среди примеров также Basecamp и Shopify. Есть крупные монолитные приложения с крутой технической командой, которую невозможно обвинить в том, что они не умеют делать микросервисы. И они всё равно выбирают свой монолитный путь.
Наверняка будут такие же примеры с микросервисами.
Савва: Давай зацепимся за названное. У того же Instagram был суперпростой сервис: ты заходишь, заливаешь картинку, её лайкают. Причина выбора Django понятна — нужно было быстро проверить гипотезу, что люди будут этим пользоваться.
Возможно, основатели Instagram и сами в него не верили. Зачем он, когда есть Facebook и куча других сайтов, которые решают ту же самую задачу? Но Instagram заметили, люди стали заходить. В нём не важна инфраструктура, он не предлагает тебе очень классный алгоритм — он ценен из-за контента, который и приносит деньги.
Instagram просто заливает всё деньгами. Сотрудники оценили, сколько уйдёт на горизонтальное масштабирование, сколько — на переписывание. На данный момент им проще докупить тачек в Amazon и жить с этим.
С точки зрения сроков, монолит — самое классное решение. Если нужно опробовать продуктовую гипотезу — берите Django, DRF (Django REST framework) и пишите модели.
Когда приходят пользователи и деньги, можно подумать, распиливать ли монолит. Таких кейсов много: тот же Avito, почта в mail.ru, большое количество зарубежных историй, например, Booking.com.
Микросервисы помогут, когда уже есть сформировавшийся продукт с тенденцией к росту. Например, часть команды пишет на Java, но Java-разработчики дорогие, их сложно искать по рынку. А если есть несколько микросервисов на Java и несколько на Golang, то получится одновременно закрывать вопрос по найму и одной части команды, и другой.
Руслан: Согласен, это плюс, что получается сочетать языки. Я это использую в команде, где есть абсолютно монолитный проект, по большей части написанный на PHP. Когда мне понадобилось добавить нестандартную логику, написанную в мобильном приложении, то оказалось проще быстренько рядом поднять один сервис на Python, подключить Redis и дать все доступы нужным разработчикам.
Савва: Однако, когда ты просишь человека добавить фичу в большой монолит, он может испугаться. Он видит кодовую базу на 10 тысяч строк кода и думает, где начать — порог входа выше.
В случае микросервисов один маленький компонент читается за день—два. Разработчик быстро погрузился, сделал продуктовую задачу, протестировал, выкатил в продакшн.
А еще если ты пишешь на микросервисах, проще искать проблемы. Они сразу локализуются: ты видишь, что у тебя выросло время ответа, и откатываешься на предыдущую версию.
Руслан: Здесь я не соглашусь. Это тот пункт, который в монолите часто намного безопасней: везде есть typechecking и одна структура данных, а не десять пользователей в десяти микросервисах, в каждом из которых по чуть-чуть данных. Вот он один, на него есть тесты и типизирование. Пройдя по стектрейсу, связанному коду и вызовам функции, ты соберёшь картинку того, с чем работаешь.
Но я знаю, что SOLID и Go структурируют разработку и добавляют дисциплины. В отличие от монолита микросервисы выстраивают правила взаимодействия с продуктом.
Савва: Да, в новом коллективе разработчиков мы часто сталкиваемся с тем, что у всех очень разный уровень. Кто-то знает паттерны, тот же SOLID, DRY, KISS, а кто-то впервые о них слышит.
Паттерн SOLID можно спроецировать и на монолит — он говорит, что один класс должен реализовывать одну фичу. Но если у тебя мало опыта в продуктовой разработке, микросервисы подходят лучше.
Здесь можно провести параллель с языком Golang и Python. Python — сильный язык, в котором возможны классы и метаклассы, он тебя никак не сковывает. Уровень кода джуна, мидла и сеньора кардинально различаются. Golang проще в освоении, но накладывает ограничения. В этом случае и мидл, и сеньор пишут схожий код. Это одновременно и хорошо, и плохо. Язык пытается защитить тебя от ошибки. К примеру, Golang пропагандирует идею наличия интерфейсов, и для написания тестов нужно «мочить» эти интерфейсы — иначе качественных тестов не будет.
В этой аналогии монолиты чем-то похожи на Python, а микросервисы на Golang.
Особенности микросервисов
Рассмотрим проблемы микросервисов, которые затрудняют их использование.
Распределенные транзакции
Это задача, которую часто задают на собеседованиях. Она звучит примерно так: есть два дата-центра — один в Санкт-Петербурге, другой в Москве. Нужно сделать транзакцию из одного хранилища в другое.
Это типичный кейс, на котором объясняют транзакции. У Васи нужно снять деньги и перевести Пете.
Савва: В случае транзакционной модели реляционных баз данных всё просто: открываем транзакцию, списываем, добавляем, закрываем транзакцию. К сожалению, в микросервисных и распределённых системах задача не такая тривиальная. Пока мы списывали деньги у Васи и внезапно попросили добавить Пете, может что-то сломаться. То есть у Васи снимем, а Пете не добавим.
Поэтому мы используем очереди. Мы списываем у Васи деньги и кладём это сообщение в очередь. Затем мы ждём сообщения, что задача выполнена и можно идти дальше. После этого мы добавляем в очередь сообщение, что Пете деньги нужно добавить. Даже если задача падает, мы её повторяем. И так до тех пор, пока Петя не получит деньги, и задача не будет закрыта.
В рабочей среде микросервисы обрастают своими паттернами, которые нужно знать, когда приступаешь к решению технических и продуктовых задач.
Савва: Да, это круто, но что ты будешь делать, когда твоё хранилище перестанет влезать на один сервер или в один дата-центр? Тогда ты захочешь распределённое хранилище. Хорошо, если Django умеет поддерживать транзакционный механизм с распределённым хранилищем. Если нет, начнутся проблемы.
Согласование контрактов и версионирование API
Руслан: Ещё одна из микросервисных проблем — согласование контрактов. Если мы делаем много сервисов, то у нас уже не поддерживается статическое типизирование языка, нет подсказок IDE о том, как вызывать методы, и вообще общих методов может не оказаться.
Ещё хуже — когда всё согласовали, всё работает, а потом в одном из сервисов сторонняя команда взяла и что-то изменила. И теперь нужно пройтись по всем сервисам и всё обновить.
Савва: Согласование контрактов — это и правда боль. Это оверхед на «сходить в команду» и выработать формат. Зато за 15 минут на встрече мы договариваемся, какие данные я буду отсылать и как ты на них ответишь — и уйдем писать код.
Возможно, ты завязан на вызове моего API. Я ухожу, делаю за час мок каких-то жёстко заданных параметров, развязываю тебя, чтобы ты мог начать реализовывать свою логику. Вот и всё, проблема решена.
Ситуация со сменой имени API возможна где угодно, в том числе в монолите. Например, бывает, что монолит общается с интернетом и к нему получает доступ мобильное приложение. Задача решается версионированием API. При смене формата API версия повышается, например, из 2 в 3. При минорных изменениях, когда добавляется новое поле, ничего не сломается. Но нужно помнить об обратной совместимости.
Распределенные данные
Руслан: Что насчёт JOIN? Как это решается на уровне микросервисов, если мне нужно собрать данные из двух сервисов?
Савва: Как и в монолите: делаем несколько запросов в различные источники данных. С микросервисами нам помогает асинхронное программирование. Мы много говорим про это в нашем курсе, этому посвящён даже целый спринт. Мы сравниваем асинхронное программирование в разных языках — Kotlin, Golang, Python.
Роль JOIN будет выполнять gateway. Когда нода приходит с запросом, нам нужно сходить в сервис пользовательских данных, в сервис авторизации и аутентификации, подтянуть его комментарии, историю просмотров — и отдать. Вместо JOIN мы выполняем какое-то число HTTP-вызовов. Эти вызовы должны быть дешёвыми по ресурсам, для чего используется асинхронное программирование.
Аналитика и логи
Руслан: Хорошо, разобрались с данными, транзакциями и контрактами. Есть ещё одна проблема микросервисов, с которой я сталкивался в одном из проектов. Мы запускали онлайн-соревнование: студенты решали задачки. При этом для нас было важно собрать данные, откуда они приходят. У нас был модуль, который проверял по IP, из какой страны и региона приходит участник, а также сравнивал результаты — мы хотели узнать, где лучше знают математику. Мы написали микросервис, который собирал эти данные и генерировал отчёт. Но когда конкурс прошёл, в отчёте все студенты оказались из Москвы.
Так получилось, потому что данные пробрасывались от одного микросервиса к другому и на продакшн-реализации IP терялся. В тестовом окружении всё было окей. Мы потратили выходные, чтобы через AWK и grep связать логи Nginx одной машины с логами запросов от другой.
Савва: Такие проблемы на уровне микросервисов встречается часто. Обычно это задача решается через юнит, который настраивает ELK-схему для Docker. Скорее всего, если у тебя настроены микросервисы, то у тебя есть Kubernetes, а в нём — Docker, и они пишут под себя логи в формате JSON. Logstash собирает эти логи и перекладывает в Elasticsearch, к нему прикручивается GUI в виде Kibana. Все логи агрегируются в одно большое хранилище.
В монолите они бы лежали под ногами, а здесь с ними идет работа через красивый GUI. Из минусов — это дороже с точки зрения настройки: тебе нужен человек, который это сделает и будет поддерживать.
Руслан: А лучше пять человек. Потому что если у тебя Kubernetes, то меньше пяти девопсов один Kubernetes не настроят.
Савва: На самом деле это правда. Исходя из моего опыта, обычно одна команда занималась инфраструктурой. Её ресурса не хватало, появлялась ещё одна. Kubernetes тяжело готовить, но и объём сервисов был большой — порядка 300—400.
В монолите мы бы столкнулись с похожей ситуацией. Представь, что у тебя есть команда, которая делает один сервис — у неё будет девопс. И так будет с каждой командой, которая пишет свой маленький монолитик.
Руслан: Ещё один бедовый кейс из моей практики. В одном стартапе настраивали Kubernetes около года — у них был один девопс, который не так много с этим работал. И когда уже всё настроили, достигли автоматического горизонтального и вертикального масштабирования, кончились деньги и команда расформировалась.
Если у вас нет практики, опыта и денег, чтобы делать эту структуру, и вообще уверенности в достижении этой высокой нагрузки, то в микросервисы идти рановато.
Савва: Соглашусь, микросервисы будут дороже с точки зрения их создания и поддержки. Но и преимуществ будет больше: выше масштабируемость и ниже порог вхождения.
Доступность приложения — Graceful degradation
Рассмотрим этот термин на примере нашего кинотеатра. Когда мы заходим на главную страницу, там есть страница входа и контент. Если аутентификация и авторизация отвалятся на 10 минут, то в случае монолита весь сайт будет «пятисотить» — выдавать сообщение об ошибке сервера. С микросервисами разработчик понимает, что делает запрос по сети, а это нестабильная штука: таймауты, сервис подвис, перезагружается, и он может отдать пустую информацию.
Graceful degradation — это подход, когда мы понимаем, что сервис может не ответить или отдать плохие данные, и вместо этого мы отдаём заглушку. Пользователь получает статус анонимного пользователя, и онлайн-кинотеатр работает дальше.
Если что-то ломается, нужно ставить заглушки. Этот паттерн может быть реализован и в микросервисах, и в монолитах. Но в монолитах об этом думают меньше.
Особенности монолитов
Перейдём к особенностям и проблемам монолитов.
Высокая связность
Савва: Высокая связность — это как раз то, с чем редко сталкиваются в микросервисной архитектуре. При проектировании микросервиса мы понимаем, что ему будет сложно взаимодействовать с другими компонентами системы.
В случае с монолитом помогает тот же SOLID, который говорит: контролируйте связность между вашими компонентами, выделяйте блоки и делите на доменные области.
Руслан: Если мы говорим про плюсы микросервисов, то многое из этого можно получить и в монолите. Если речь идёт про уменьшение связности, то модели из разных приложений имеют минимум связей друг с другом. И чаще всего это не перекрёстные связи, а в одну сторону.
Хороший маркер, что архитектура на уровне БД сделана хорошо — можно ли поднять его с нуля, то есть прогнать миграции и запустить проект. Часто бывает, что в каждом апликейшне по 60 миграций или больше. Если попытаться поднять проект с нуля миграций, он всё время будет валиться.
Также помогает локально отключить какой-нибудь из апликейшнов и посмотреть, как много проблем получится. Если всего в 2—3 местах появились заглушки, и всё работает, то скорее всего, модуль отделился успешно.
Сложно горизонтально масштабировать
Прежде, чем пытаться «переписать всё на микросервисы», стоит начать с шардинга и оптимизации кода.
В случае оптимизации с помощью трассировки запроса и профайлинга отслеживаются медленные участки. В большинстве проектов есть избыточные вызовы в циклах. У систем continuous integration есть плагины с анализаторами кода. Они обнаруживают фрагменты, которые можно вынести из цикла или исправить другие проблемы в кодовой базе.
Например, если где-то подтормаживает база, нужно проверить, нет ли запросов в цикле с помощью Django Debug Toolbar (если это Django) или другим способом. В случае PostgreSQL необходимо включить логирование медленных запросов дольше 0,1 секунды и скормить этот лог анализаторам. Если распарсить топ медленных запросов и топ самых частых запросов и починить эти случаи, то наверняка можно ускорить любую систему. Далеко не обязательно для этого переписывать всё с нуля.
Сложно тестировать
Одна из проблем — то, что много тестов, всё медленно запускается. Другая часть проблемы — тестировать сложно, потому что большая связность всех компонентов.
Есть один из вариантов решения, который мы использовали сами: распилить сервис на либы. Это тоже своего рода микросервисный подход. При этом мы не создаём оверхед на HTTP-запросы и не теряем связность компонентов. В нашем приложении мы можем устанавливать себе не только внешние, но и собственные либы от других отделов. Таким образом мы вынесем слой данных и будем параллельно разрабатывать каждый из них.
В чём-то это сильно повторяет подход микросервисов. Даже трудно сказать, микросервис это или монолит.
Обычно про микросервисы говорят, что это HTTP-запросы. При этом возможен параллельный изолированный репозиторий со своими тестами. Сохраняются все плюсы, которые есть в связном монолитном коде, работает подсветка в IDE, можно провалиться в код микросервиса другой либы и изучить его. Скорость разработки остается монолитной. При этом мы имеем те искусственные ограничения, которые нас дисциплинируют.
Единственное — нужно не забыть про версионирование. Это особенно важно, если использовать общие либы, допустим, слой данных Django-модели или Pydantic-модели. Хорошо решает проблему SemVer — соглашение о том, как версионировать библиотеки
Работать становится проще, когда мы придерживаемся SemVer-версионирования, в requirements.txt записаны не только внешние модули, но и модули команды проекта, и мы разделили части приложения на либы. Это создает проект низкой связности, который при этом имеет много преимуществ монолита.
Сложный найм
Савва: По поводу многоязыковости. Пусть мы пишем монолит на Java. Как ты считаешь, хорошо это или плохо?
Руслан: Не могу дать однозначного ответа. Я уже рассказывал про случай, когда PHP-разработчики были максимально заняты, а свободный питонист быстро поднял рядом микросервис. Это было классно. В то же время понятна проблема монотехнологичности. Если у меня проект на Java или каком-нибудь Rust, то искать новых специалистов тяжело.
Я однажды попробовал такой подход: в вакансии на поиск разработчика я описал задачу и дал 5—6 языков на выбор. Мне действительно было без разницы, пишет разработчик на PHP, Python или Node.JS. Задача привлекла внимание — она отличалась от других. Обычно ищут на определённый язык, а здесь пиши на чём хочешь.
Отозвалось много людей. Тут возник затык: я не знал, как их сравнивать. Сложно проводить собеседование, потому что все 5 языков я не знал, поэтому пришлось искать дополнительные ресурсы на аутсорсе или в другом отделе.
Вторая проблема: в разных языках разные подходы к решению одних и тех же задач. Договариваться между командами становится сложнее и дольше.
Савва: Пока ты говорил, я придумал ещё один плюс. Если у нас монокоманда с одним языком, то в идеальных условиях экспертиза самого опытного сотрудника будет растекаться ко всем остальным. Он будет тянуть всех вверх.
Наверное, это можно проецировать и на микросервисную архитектуру. Если в микросервисе три человека, а лид круто пишет на Rust, он подтянет знания остальных. Но в огромном монолите на триста человек образовательная история будет сильнее.
Руслан: Можно даже школу открывать — мы так и делали. Когда-то я тогда писал на PHP, и мне что-то нравилось, что-то нет. В то время одна компания в Казани организовывала бесплатные курсы по Python, и я вписался. После курсов они меня взяли. Внутри была построена хорошая вертикаль роста сотрудников.
Когда я только пришел в эту компанию, я потерял в зарплате в два раза. Менее чем через два года после найма зарплата выросла в три раза. Навыки выросли благодаря этой вертикали, когда более сильный разработчик подхватывает других. Не представляю, как бы это сработало с большим количеством языков и технологий.
Но это история десятилетней давности. Сейчас софт пишется по-другому. Это заметно даже на примере нашего курса в Практикуме: сегодня много задач решается через API, а не через код. Интернет работал медленнее, и ещё не было таких крутых инструментов, как Postman, GraphQL или JSON Schema.
Сейчас без этого вообще не живется. Появились мобильные приложения, которые ставят высокие требования к API, частично поменялась конъюнктура, писать сервисы стало проще. Мы не привязаны сильно к языку.
На нашем курсе мы качаем людей от джуниоров к мидлам и чуть-чуть выше. Но большая часть курса посвящена не особенностям Python, а особенностям Elastic, брокеру очередей, отказоустойчивости, логированию, Nginx. И это не наша выдумка — это требования тех вакансий, которые на рынке. Если посмотреть, кого сегодня хотят разные компании и как делаются сервисы, там действительно меньше требований к языку и больше к инфраструктуре и «насмотренности».
Сложность локального развертывания
Савва: Последний пункт в твоём списке меня пугает больше всего. Монолиты тяжело разворачивать и программировать локально. Чтобы поднять монолит, может не хватить 16 ГБ ОЗУ. Приходится искать хаки или что-то выключать.
Круто, что в разработке монолита можно проваливаться в классы, смотреть реализацию интерфейса. Но неприятен тот момент, когда монолит перестает запускаться на твоей локальной тачке, и ты через боль начинаешь его программировать.
Руслан: Здесь легко парировать. В некоторых микросервисных командах на то, чтобы заставить микросервис работать, может уйти неделя.
Часть сложностей локального развёртывания на монолите решаются с помощью упаковывания в Docker, часть — с помощью конфигурации. Некоторые компоненты делаются отключаемыми или в виде моков. В таком случае разворачивается с «живыми» данными только та часть приложения, с которой нужно работать.
Савва: Отвечая на твой вопрос о том, как запуститься, если микросервисов много. Это решается просто.
В компании наверняка есть staging. После запуска микросервис ходит в стейджинговое окружение и получает данные. Если не получается обнаружить проблему в рамках сервиса, и ты знаешь, что она в другом месте, ты берёшь эту часть системы и поднимаешь локально. У тебя два микросервиса — всё остальное в стейджинге. Это тоже заметно экономит время.
Вопросы зрителей
Были ли случаи, когда микросервис объединяли в монолит?
Руслан: У меня есть такая история.
Проект разрабатывали около года. Его специфика — софт для больниц и частных клиник, который считал, сколько должны заплатить страховые компании. Был большой объем данных, потому что в каждом регионе России в среднем около 4 миллионов людей обращаются в больницы. Каждое обращение учитывалось в этой системе. На выходе требовался отчет, сколько заплатить конкретной больнице.
Мы сразу решили делать микросервисы: модуль авторизации, модуль подсчёта, модуль приёма данных, модуль выгрузки данных и так далее. Была даже шина данных на Erlang.
На тестах все работало классно. Но когда запустили систему в продакшн с большим количеством информации на входе начала всплывать несогласованность данных. То есть один микросервис посылал во второй данные, а тот был либо более старой версии, либо данные от первого второму не доехали, а второй микросервис уже переслал что-то в третий. В итоге у нас получилась рассогласованная структура базы.
Где-то автоматически происходил перерасчет, запускались новые таски через RabbitMQ Salary. На скриншоте видно количество необработанных задач, хотя они должны были проходить за долю секунды. Их там несколько миллионов.

Они копились, потому что считались неправильно. Что-то с этим сделать было тяжело. У меня тут показан один из серверов, который был под завязку загружен и не справлялся.
В этом хаосе мы пытались что-то править, получалось плохо. Мы поменяли структуру данных в одном сервисе, а в другом микросервисе этого не сделали. Или сделали, но там уже были запущенные процессы, которые не остановились, у нас это всё обрабатывается через message bus. Или где-то потерялись сообщения из очереди: то есть сервис нахватал задач из RabbitMQ и вместе с ними скончался. После этого задачи по одной из причин не вернулись обратно в очередь.
В итоге руководство спросило, что происходит и что мы собираемся делать. Как технари мы думали, что сейчас оптимизируем индексы, добавим новые распределенные транзакции или что-то еще. Но нас спросили, есть ли какое-то простое, быстрое решение. Мы поняли, что большая часть наших проблем — из-за микросервисов. Недостаток ресурсов возникал из-за микросервисных проблем, а не сложных вычислений или бизнес-логики.
За три дня мы объединили все микросервисы в один здоровенный монолит, поставили нормальные транзакции с единой структурой данных. Сразу система не завелась, но в течение недели мы стабилизировали ситуацию. Всё стало работать нормально.
Для меня это была эмоциональная история. Люди действительно не получали зарплату из-за нашей реализации микросервисов. Я вынес для себя урок, что к микросервисам нужно приходить, а не начинать с них.
У нас много микросервисов. Как лучше всего реализовать логирование?
Руслан: Классика для этой задачи — ELK. Из каждого микросервиса мы кидаем запрос в Elasticsearch, собираем логи с помощью Logstash, а потом смотрим с помощью Kibana. Также здесь хорошо подходит Grafana. Единственное, что нужно помнить — нельзя терять пользователя. Чтобы отследить его путь, прибегают к fingerprint.
Можно ли выделить разбиение на микросервисы для фронта?
Руслан: Да, сейчас есть понятие «микрофронт». Здесь уже речь не про нагрузку, а распределённость и разный стек. Кажется, что и у этого есть свои преимущества, хотя в нашем курсе это не затронуто.
Выводы
Савва: Подведём итоги. Если нужно быстро протестировать гипотезу, вполне подходит монолит. Скорее всего, первые полгода единственное, во что вы будете упираться — это в базу: индексов не хватает, натюнено не так и прочие радости. Если база данных оптимизирована и «тормоза» остаются, если вы упираетесь в бизнес-логику, вам помогут микросервисы.
Руслан: В больших компаниях уровня Яндекса или Тинькофф требования могут быть известны сразу. В таких случаях можно сразу начинать с микросервиса. Если у вас молодая команда и стартап с неясными требованиями, рекомендую начать с монолита и дальше постепенно его распиливать.
Часто разработчики просто хотят что-то модное и клёвое, ещё не выжав всё из существующего монолита — тогда и начинается разговор про микросервисы. Но если определять профессионализм разработчика, само использование микросервиса — не показатель. Умение выжать максимум из того «железа» и софта, что у вас есть — вот показатель.
При достижении низкой связности, при оптимизации кода и при правильном использовании существующих инструментов, переход на микросервисы случится в некотором смысле автоматически, легко и естественно. Возможно, монолит не придётся распиливать — просто рядом будут появляться микросервисы.
Савва: Кстати, я не выбирал какую-то сторону для себя. Я стараюсь сохранять холодную голову и брать не ту технологию, которую хочу, а которая лучше подходит для продукта. Также я задумываюсь над тем, что вокруг компании, продукта и разработчиков.
Подведу черту. Нет никакой идеальной архитектуры. Как и c языком программирования, мы всегда выбираем архитектуру в зависимости от задачи.
Подведем итоги голосования: с большим отрывом победили микросервисы. Однако, на любой технический вопрос есть только один правильный ответ — it depends, то есть выбор зависит от кучи факторов.



