В чем польза формальных спецификаций вроде OpenAPI?

В этой статье хочу рассказать, что такое OpenAPI и зачем он может быть нужен.
Ваши покемоны
Ваше положение: у вас два разработчика. Один разрабатывает бекенд вашего продукта, а другой – фронтенд.
У вас есть идея для нового супер-классного приложения и вы хотите реализовать его как можно быстрее, поэтому вы призываете опытного архитектора чтобы он заранее спроектировал идеальный API, под который можно будет одновременно разрабатывать фронтенд и бекенд.

Архитектор разрабатывает идеальный API, описывает его в одном большом документе и выдает разработчикам.
Каждый разработчик берет документ, описывающий API, внимательно его читает, и реализует описанный API.
Пять раз отмерь, один раз отрежь
В конечном итоге мы хотим получить фронтенд и бекенд, каждый из которых будет реализовывать одни и те же запросы (фронтенд отправлять, а бекенд обрабатывать). В идеале, эти запросы должны еще и соответствовать тому, что описал архитектор (хотя это уже не так важно).
Давайте теперь посмотрим, что должно произойти чтобы запросы на фронтенде и бекенде совпадали:
Если хоть в одном из этих пунктов кто-то допустит ошибку, то весь ваш проект будет падать. И это с предположением, что архитектор не допускает ошибок (спойлер: таких нет).
Нужно отдельно отметить, что большая ноша ложится на человеческое понимание и человеческую коммуникацию технических деталей. Человеческое понимание в целом довольно трудно дебажить и тестировать.
Люди – самое слабое звено
Закономерным в сложившейся ситуации кажется желание минимизировать человеческий фактор в разработке API. Хочется не иметь человеческого фактора с того момента, как архитектор описал API в своем документе. (Вообще, хочется и от ошибок архитектора избавиться, но технологии до такого пока не дошли.)
Очевидно, что чтобы такое сделать, нужно чтобы выхлопом архитектора был не человеко-читаемый документ, а компьютеро-читаемый документ – своего рода формальная спецификация конкретного API. Если у нас будет такое описание API, мы можем как минимум попытаться возложить последующие шаги на автоматизацию.
Для каждого языка программирования при использовании какого-то конкретного фреймворка обычно не так много способов сделать «каноничную» реализацию какого-то HTTP API. Обычно в фреймворках не так много способов сделать запрос с JSON объектом в теле, и не так много способов считать целое число из пути запроса.
OpenAPI
Было бы здорово иметь возможность один раз описать свой HTTP API, и из этого описание получить совпадающие каркасы для реализации бекенда и фронтенда, которые, из-за отсутствия человека в цепочке, будут с большей вероятностью совпадать. (При условии, что генерация этих каркасов реализована без ошибок, но это, на самом деле, более простая задача.)
О, чудо! Такое уже придумали! И называется оно OpenAPI!
OpenAPI позволяет формально описывать HTTP API в виде YAML файлов. Довольно обширный пример можно посмотреть на editor.swagger.io. Там можно смотреть исходный YAML и человеко-читаемую HTML страничку одновременно.
Если изначальную спецификацию архитектор опишет в виде OpenAPI спецификации, то все взаимодействие между бекендом и фронтендом можно будет сгенерировать автоматически, и оно будет гарантированно совпадать. Таким образом мы вообще исключаем из цепочки человеческий фактор!
Больше чем просто кодогенерация
Кодогенерация – это лишь одно из применений OpenAPI. OpenAPI – открытый формат описания HTTP API, не завязанный на какую-то конкретную экосистему. Он позволяет обмениваться точным описанием API между системами, которые в иных условиях требовали бы ручной «синхронизации» API.
Есть большое количество инструментов, работающих на базе OpenAPI спецификаций. Хорошим ресурсом таких проектов является openapi.tools. Там представлены такие проекты как: GUI редакторы спецификаций, генераторы тестовых серверов по спецификациям, поиск уязвимостей по спецификации, и многое другое!
Используя OpenAPI можно не только повысить точность описания своих API, но и получить доступ к большому числу инструментов, которые помогут в разработке проекта.
Обзор руководства OpenAPI 3.0
В этом разделе мы углубимся в спецификацию OpenAPI. Мы будем использовать тот же API-интерфейс OpenWeatherMap, который мы использовали в других частях этого курса, в качестве контента для нашего документа OpenAPI. Используя этот API, мы создадим действительный документ спецификации OpenAPI, а затем изобразим его в интерактивной документации используя Swagger UI.
Общие ресурсы для изучения спецификации OpenAPI
Изучение спецификации OpenAPI займет какое-то время. Для изучения планируйте около двух недель погружения, работая с конкретным API в контексте спецификации, прежде чем освоиться с ним. По мере изучения спецификации OpenAPI используйте следующие ресурсы:
Чем отличается руководство по OpenAPI/Swagger Тома Джонсона
Можно найти много учебных пособий по Swagger онлайн. В чем отличие этого руководства? Помимо сквозного пошагового руководства, использующего версию спецификации OpenAPI 3.0 (а не 2.0), и фактического API для контекста, здесь показано, как поля OpenAPI отображаются в пользовательском интерфейсе Swagger. В частности, демонстрируется, как и где каждое из полей OpenAPI отображается в Swagger UI.
Терминология Swagger и OpenAPI
Прежде чем продолжить, уточним некоторые термины для тех, кто может быть незнаком с OpenAPI/Swagger:
Другие определения находятся в Глоссарии API
Другими словами, созданный документ OpenAPI является объектом JSON, но у нас есть возможность выразить JSON с использованием синтаксиса JSON или YAML. YAML более читабелен и является более распространенным форматом (см. Обсуждение API Handyman JSON против YAML), поэтому YAML используется только здесь. Документация спецификации OpenAPI на GitHub всегда показывает синтаксис JSON и YAML при отображении форматов спецификации. (Для более подробного сравнения YAML с JSON см. «Отношение к JSON» в спецификации YAML.)
В JSON это выглядит так:
В спецификации часто используется термин «поле» в заголовках и именах столбцов таблицы при перечислении свойств для конкретного объекта. (Кроме того, идентифицируется два типа полей: объявляются «фиксированные» поля, уникальные имена, а «шаблонные» поля являются выражениями регулярных выражений.) Поля и свойства используются в спецификации OpenAPI как синонимы.
И вот как он выглядит в JSON:
Надеемся, что эти краткие примеры помогут понять терминологию, использованную в руководстве.
Начнем с общего представления
Если вы хотите получить общее представление о спецификации, взгляните на примеры 3.0 здесь, в частности спецификацию Petstore OpenAPI. Поначалу, вероятно, будет много непонятного, но постараемся получить представление о целом, прежде чем мы углубимся в детали. Посмотрим также на некоторые другие примеры в папке v.3.0.
Учебник OpenAPI шаг за шагом
Пошаговое руководство OpenAPI состоит из 8 шагов. Каждый шаг соответствует одному из объектов корневого уровня в документе OpenAPI.
Не обязательно создавать документ спецификации в этом порядке; порядок выбран, чтобы предоставить более конкретный путь и шаги к процессу.
В следующих разделах мы рассмотрим каждый из этих объектов один за другим и задокументируем текущий API OpenWeatherMap. Работа с каждым объектом корневого уровня индивидуально (а не документирование всего сразу) помогает уменьшить сложность спецификации.
С каждым шагом мы будем вставлять объект, над которым работаем, в редактор Swagger. На правой панели редактора Swagger будет отображаться интерфейс Swagger. (Помните, что один документ спецификации ничего не делает с вашим контентом. Для чтения и отображения документа спецификации требуются другие инструменты.)
Позже, когда мы узнаем больше о публикации документации, будет пояснение, как сконфигурировать интерфейс Swagger с нашим документом спецификации в качестве отдельного продукта. Для нашего примера API OpenWeatherMap вы можете увидеть спецификацию OpenAPI, отображаемую интерфейсом Swagger, по следующим ссылкам:
Миграция от OpenAPI 2.0 к 3.0
При наличии существующего документа спецификации, который проверяется на соответствие версии OpenAPI 2.0 и можно конвертировать его в OpenAPI 3.0 (или наоборот), можно использовать APIMATIC’s Transformer для его автоматического преобразования. (Можно использовать APIMATIC для преобразования документа спецификации во многие другие выходные данные, такие как RAML, API Blueprint или Postman.)
Чтобы увидеть разницу между версиями 2.0 и 3.0, можно скопировать примеры кода в отдельные файлы, а затем использовать приложение Diffmerge, чтобы выделить различия. В блоге Readme.io есть хорошая публикация: A Visual Guide to What’s New in Swagger 3.0
Полезные источники
Приступая к созданию файла спецификации OpenAPI, может пригодиться запись презентации Swagger / OpenAPI Питера Грюнбаума, а также его курс на Udemy.
Приготовились! Сейчас начнем узнавать, насколько мы готовы к техническому написанию API.
Разработка REST-серверов на Go. Часть 4: применение OpenAPI и Swagger
Перед вами четвёртый материал о разработке REST-серверов на Go. Здесь мы поговорим о том, как можно воспользоваться OpenAPI и Swagger для реализации стандартизированного подхода к описанию REST API, и о том, как генерировать Go-код на основе спецификации OpenAPI.
Зачем это всё?
В первой части этой серии материалов, когда мы описывали REST API, я говорил о том, что описание этого API создано специально для нашего примера. Это описание представляет собой просто список методов (путей) с комментариями:
Было бы неплохо, если бы существовал стандартный способ описания API. «Стандартным» я называю такое описание, которое могло бы играть роль контракта между серверами и клиентами. Более того, стандартное описание API выглядело бы совершенно понятным для тех разработчиков, которые не знакомы с особенностями конкретного проекта. Такое описание, кроме того, могло бы быть понятным не только людям, но и машинам, что привело бы к возможности автоматизации различных задач, связанных с API.
Swagger и OpenAPI
Проект Swagger появился в 2011 году как IDL (Interface Description Language, язык описания интерфейсов) для описания REST API.
В 2014 году вышла версия Swagger 2.0, а в 2016 множество крупных IT-компаний объединили усилия в деле создании спецификация OpenAPI, жёстко стандартизированного варианта Swagger 3.0.
Официальный сайт Swagger и OpenAPI, https://swagger.io, поддерживает Компания SmartBear Software.
Во всех этих хитросплетениях технологий можно и запутаться. Легче всего разложить сведения о них в голове можно, если помнить о том, что OpenAPI — это современное название спецификации, а словом «Swagger» обычно называют инструменты, построенные на основе этой спецификации (правда, можно ещё столкнуться и с таким понятием, как «спецификация Swagger», особенно — если речь идёт о версиях Swagger, вышедших раньше, чем версия 3.0).
Создание сервиса системы управления задачами с применением OpenAPI
Начнём с повторения нашего любимого упражнения — с переписывания сервиса приложения для управления задачами. В этот раз мы воспользуемся OpenAPI и Swagger.
Для того чтобы это сделать, я почитал документацию OpenAPI 3.0 и воспользовался редактором Swagger для ввода спецификации в формате YAML. Это заняло некоторое время. В результате в моём распоряжении оказался этот файл.
Здесь components/schemas/Task представляет собой ссылку на модель Task :
Это — описание схемы данных. Обратите внимание на то, что мы можем указывать типы для полей данных, что (как минимум — в теории) может пригодиться при автоматическом генерировании кода для валидации этих данных.
Вся эта работа принесла плоды сразу же после её завершения. А именно — она дала мне приятно выглядящую, цветную документацию для API.
Фрагмент документации из редактора Swagger
Это — всего лишь скриншот. В настоящей документации можно щёлкать по её элементам, их можно раскрывать, можно видеть чёткие описания параметров запросов, ответов, JSON-схем и прочего подобного.
Представьте себе, что занимаетесь разработкой API в рамках приложения, предназначенного для управления задачами. На определённом этапе работы принято решение о том, что этот API можно опубликовать для того чтобы к нему можно было бы обращаться с клиентских систем различных видов (это могут быть веб-клиенты, мобильные клиенты и так далее). Если ваш API описан с использованием OpenAPI/Swagger, это значит, что у вас имеется автоматически созданная документация и интерфейс для клиентов, позволяющий им экспериментировать с API. Это вдвойне важно в том случае, если среди пользователей вашего API есть люди, не являющиеся программистами. Например, это могут быть UX-дизайнеры, технические писатели, продакт-менеджеры, которым нужно разобраться в API, но которые не особенно привыкли к самостоятельному написанию скриптов.
Более того, OpenAPI стандартизирует и такие вещи, как авторизация, что тоже может оказаться очень кстати. Наш подход из первой статьи, когда мы пользовались произвольным описанием API, ни в какое сравнение не идёт с тем, что даёт нам OpenAPI.
После того, как подготовлена спецификация API, можно взглянуть на дополнительные инструменты, имеющиеся в экосистеме Swagger. Например — это Swagger UI и Swagger Inspector. Спецификацию API можно даже использовать в роли вспомогательного инструмента при интеграции REST-сервера в инфраструктуру облачного провайдера. Например, в GCP имеется система управления API Cloud Endpoints, поддерживающая спецификацию OpenAPI. Она, кроме прочего, позволяет настраивать мониторинг и анализ опубликованных API. Описание API предоставляется этой системе с использованием OpenAPI.
Автоматическое генерирование базового кода для Go-сервера
Возможности, которые обещают нам OpenAPI/Swagger, выходят далеко за пределы автоматического создания документации. На основе соответствующих спецификаций можно автоматически генерировать код клиентов и серверов.
В процессе работы я сделал некоторые выводы относительно ограничений такого подхода:
Инструмент swagger-codegen умеет ещё и создавать код клиентов, в том числе и на Go. Иногда это может оказаться очень кстати, но с моей точки зрения подобный код выглядит несколько запутанным. Он, как и в случае с серверным кодом, возможно, может сыграть роль хорошей отправной точки в деле написания собственного клиента, но механизм его автоматического создания вряд ли может стать частью некоего CI/CD-процесса.
Испытание альтернативных генераторов кода
Спецификации OpenAPI представлены в виде YAML (или JSON), их формат хорошо документирован. В результате неудивительно то, что существует далеко не один инструмент, позволяющий генерировать на основе этих спецификаций серверный код. В предыдущем разделе мы рассмотрели «официальный» генератор кода Swagger, но есть и другие подобные инструменты.
В случае с Go популярным инструментом такого рода является go-swagger. В README этого проекта есть следующий раздел:
Чем этот генератор отличается от генератора из swagger-codegen?
tl;dr В настоящий момент его главное отличие заключается в том, что он реально работает.
Проект swagger-codegen генерирует рабочий Go-код лишь для клиента, и даже тут он поддерживает лишь плоские модели. А код Go-сервера, сгенерированный swagger-codegen — это, в основном, нечто вроде кода-заглушки.
Я попробовал сгенерировать код сервера с помощью go-swagger. Так как код, сгенерированный этим средством, достаточно велик, я не привожу тут ссылку на него. Тут я лишь поделюсь впечатлениями от работы с go-swagger.
В первую очередь отмечу, что go-swagger поддерживает лишь спецификацию Swagger 2.0, а не более новую версию OpenAPI 3.0. Это довольно-таки печально, но я нашёл один онлайновый инструмент, который умеет конвертировать описания API, выполненные с использованием спецификации OpenAPI 3.0 в описания формата OpenAPI 2.0 (Swagger). Описание нашего API в формате Swagger 2.0 тоже имеются в репозитории проекта.
В серверном коде, сгенерированном go-swagger, определённо, реализовано больше возможностей, чем в коде, сгенерированном swagger-codegen. Но за всё надо платить. Дополнительные возможности означают привязку к особому фреймворку, разработанному создателями go-swagger. Сгенерированный код имеет множество зависимостей от пакетов из репозиториев go-openapi, в нём код из этих пакетов широко используется для обеспечения работы сервера. Там есть даже код для разбора флагов. Собственно, почему бы ему там не быть?
Если вам нравится фреймворк, используемый в коде, генерируемом go-swagger, то вам вполне может подойти этот код. Но если у вас на этот счёт есть свои идеи — вроде использования Gin или собственного маршрутизатора, то решения разработчиков go-swagger, отразившиеся на готовом коде, могут вас не устроить.
С помощью go-swagger можно сгенерировать и код клиента, который, как и код сервера, отличается хорошим функционалом и отражает точку зрения разработчиков go-swagger на то, каким должен быть такой код. Правда, если нужно всего лишь быстро создать такой код для целей тестирования, то, что он отражает мнение других людей, не будет выглядеть серьёзной проблемой.
После публикации этого материала мне посоветовали попробовать ещё один инструмент для генерирования кода — oapi-codegen. Код нашего сервера, созданный с помощью этого инструмента, можно найти здесь.
Я должен признать, что результаты работы oapi-codegen понравились мне гораздо больше, чем код, созданный другими опробованными мной инструментами. Это — простой и чистый код, при работе с которым легко отделить то, что сгенерировано автоматически, от того, что написано самостоятельно. Средство oapi-codegen даже понимает спецификации OpenAPI 3! Единственное, к чему я могу придраться, это то, что тут используется зависимость от пакета стороннего разработчика лишь для того, чтобы реализовать привязку параметров запроса. Лучше было бы, если бы это можно было как-то настраивать. Например — чтобы имелся бы некий параметр, позволяющий выбрать между использованием кода, входящего в состав сервера, и кода, получаемого из стороннего пакета.
Генерирование спецификаций на основе кода
Что если у вас уже имеется реализация REST-сервера, но вам очень понравилась идея его описания с помощью OpenAPI? Можно ли сгенерировать это описание на основе кода сервера?
Да — можно! Сгенерировать OpenAPI-описание сервера (правда, это снова будет описание в формате спецификации 2.0) можно с помощью специальных комментариев-аннотаций и инструментов наподобие swaggo/swag. Затем с полученным описанием можно поработать, используя различные Swagger-инструменты и, например, создать на его основе документацию.
На самом деле, это выглядит как весьма привлекательная возможность для тех, кто привык писать REST-серверы по-своему и не хочет переходить к новой схеме работы только ради того, чтобы пользоваться Swagger.
Итоги?
Представьте, что у вас имеется приложение, которому необходимо работать с REST API, и при этом вам приходится выбирать между двумя сервисами.
Я с удовольствием опишу мой API в формате OpenAPI и воспользуюсь инструментом для создания документации. А вот в деле автоматического генерирования кода я буду действовать уже более осторожно. Лично я предпочитаю достаточно сильно контролировать мой серверный код. В частности, речь идёт об используемых в нём зависимостях и о его структуре. Я вижу смысл в автоматическом создании серверного кода для целей быстрого прототипирования или для каких-то экспериментов, но я не использовал бы автоматически сгенерированный серверный код как базу для собственного проекта. Конечно, я иначе бы смотрел на этот вопрос, если бы мне надо было бы еженедельно выпускать новую версию REST-сервера. В поисках баланса между использованием чужого кода и кода своего, стоит помнить о том, что преимущества от использования зависимостей обратно пропорциональны усилиям, потраченным на программный проект.
На самом деле, инструменты вроде swaggo/swag могут предложить разработчикам отличный баланс между зависимостями и собственными усилиями. Серверный код пишут с использованием самостоятельно выбранного подхода или фреймворка и оснащают его особыми комментариями, описывающими REST API. После этого соответствующий инструмент генерирует на основе этих комментариев спецификацию OpenAPI. Эту спецификацию можно использовать для создания документации к проекту или чего угодно другого, что можно создать на её основе. При таком подходе у нас появляется дополнительная полезная возможность — наличие единственного источника истины в виде комментариев. Этот источник расположен в максимальной близости к исходному коду, реализующему механизмы, описываемые в комментариях. А такой подход, кстати, всегда полезен в деле разработки программного обеспечения.
Пользуетесь ли вы спецификациями OpenAPI при создании REST-серверов?
Знакомство со спецификациями OpenAPI и Swagger
OpenAPI является спецификацией для описания REST API. Можно рассматривать спецификацию OpenAPI как спецификацию DITA. В DITA существуют определенные элементы XML, используемые для определения компонентов справки, а также требуемый порядок и иерархия для этих элементов. Различные инструменты могут читать DITA и создавать веб-сайт документации на основе информации.
В OpenAPI вместо XML существует набор объектов JSON с определенной схемой, которая определяет их наименование, порядок и содержимое. Этот файл JSON (часто выражается в YAML вместо JSON) описывает каждую часть API. Описывая API в стандартном формате, инструменты публикации могут программно анализировать информацию об API и отображать каждый компонент в стилизованном интерактивном виде.
Взгляд на спецификацию OpenAPI
Чтобы лучше понять спецификацию OpenAPI, давайте взглянем на некоторые выдержки из спецификации. Углубимся в каждый элемент в следующих разделах.
Это формат YAML, взят из Swagger PetStore
Вот что значат объекты в этом коде:
Проверка спецификации
При создании спецификации OpenAPI, вместо того, чтобы работать в текстовом редакторе, можно написать свой код в редакторе Swagger. Редактор Swagger динамически проверяет контент, чтобы определить, является ли созданная спецификация валидной.
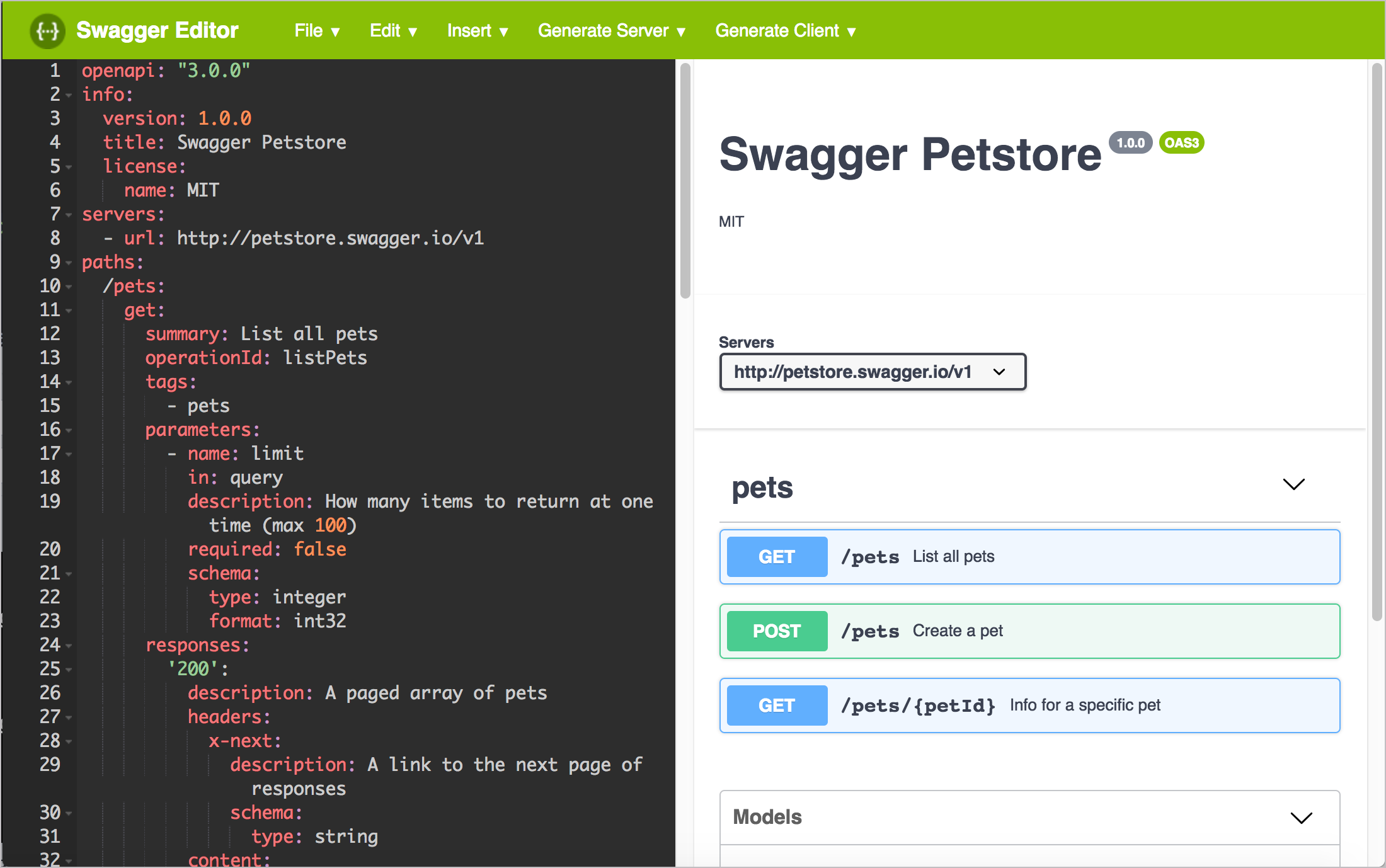
Если допустить ошибку при написании кода в редакторе Swagger, можно быстро исправить ее, прежде чем продолжить, вместо того, чтобы ждать запуска сборки и устранять ошибки.
YAML зависим от пробелов и двоеточий, устанавливающих синтаксис объекта. Такое пространственно-чувствительное форматирование делает код более понятным для человека. Однако, иногда могут возникнуть сложности с расстановкой правильных интервалов.
Автоматическая генерация файла OpenAPI из аннотаций кода
Вместо того, чтобы кодировать документ в спецификации OpenAPI вручную, также можно автоматически сгенерировать его из аннотаций в программном коде. Этот подход, ориентированный на разработчиков, имеет смысл, если есть большое количество API-интерфейсов или если для технических писателей нецелесообразно создавать эту документацию.
Swagger предлагает множество библиотек, которые можно добавлять в свой программный код для создания документа в спецификации. Эти библиотеки Swagger анализируют аннотации, которые добавляют разработчики, и генерируют документ в спецификации OpenAPI. Эти библиотеки считаются частью проекта Swagger Codegen. Методы аннотации различаются в зависимости от языка программирования. Например, вот справочник по аннотированию кода с помощью Swagger для Scalatra. Для получения дополнительной информации о Codegen см. Сравнение инструментов автоматического генерирования кода API для Swagger по API Evangelist. Дополнительные инструменты и библиотеки см. В разделах «Интеграции и инструменты Swagger» и «Интеграция с открытым исходным кодом».
Хотя этот подход и «автоматизирует» генерацию спецификации, нужно еще понимать, какие аннотации добавить и как их добавить (этот процесс не слишком отличается от комментариев и аннотаций Javadoc). Затем нужно написать контент для каждого из значений аннотации (описывая конечную точку, параметры и т. Д.).
Если идти по этому пути, нужно убедиться, что есть доступ к исходному коду для внесения изменений в аннотации. В противном случае разработчики будут писать документацию (что может и хорошо, но часто приводит к плохим результатам).
Подход: разработка по спецификации
 Spec-first development это философия о том, как разрабатывать API более эффективно. Если вы следуете философии «сначала спецификация», вы сначала пишете спецификацию и используете ее в качестве контракта, к которому разработчики пишут код.
Spec-first development это философия о том, как разрабатывать API более эффективно. Если вы следуете философии «сначала спецификация», вы сначала пишете спецификацию и используете ее в качестве контракта, к которому разработчики пишут код.
Другими словами, разработчики обращаются к спецификации, чтобы увидеть, как должны называться имена параметров, каковы должны быть ответы и так далее. После того, как этот «контракт» или «план» был принят, Стоу говорит, можно поместить аннотации в свой код (при желании), чтобы сгенерировать документ спецификации более автоматизированным способом. Но не стоит кодировать без предварительной спецификации.
Слишком часто команды разработчиков быстро переходят к кодированию конечных точек API, параметров и ответов, без пользовательского тестирования или исследования, соответствует ли API тому, что хотят пользователи. Поскольку управление версиями API-интерфейсов чрезвычайно сложно (необходимо поддерживать каждую новую версию в дальнейшем с полной обратной совместимостью с предыдущими версиями), есть желание избежать подхода «быстрый сбой», который так часто отмечают agile энтузиасты. Нет ничего хуже, чем выпустить новую версию вашего API, которая делает недействительными конечные точки или параметры, используемые в предыдущих выпусках. Постоянное версионирование в API может стать кошмаром документации.
Компания Smartbear, которая делает SwaggerHub (платформу для совместной работы команд над спецификациями API Swagger), говорит, что теперь для команд чаще встречается ручное написание спецификации, а не встраивание аннотаций исходного кода в программный код для автоматической генерации. Подход “spec-first development” в первую очередь помогает работать документации среди большего количества членов команды, нежели только инженеров. Определение спецификации перед кодированием также помогает командам создавать лучшие API.
Даже до создания API спецификация может генерировать ложный ответ, добавляя определения ответа в спецификацию. Мок-сервер генерирует ответ, который выглядит так, как будто он исходит от реального сервера, но это просто предопределенный ответ в коде, и кажется динамичным для пользователя.
Роль технического писателя в спецификации
В большинстве проектов Тома Джонсона разработчики были не очень хорошо знакомы с Swagger или OpenAPI, поэтому он обычно создавал документ спецификации OpenAPI вручную. Кроме того, он часто не имел доступа к исходному коду, и для разработчиков английский язык был не родным. Документация была для них сложным делом.
Возможно, и нам будут попадаться инженеры, не знакомые с Swagger или OpenAPI, но заинтересованные в использовании их в качестве подхода к документации API (подход, основанный на схемах, соответствует инженерному мышлению). Таким образом, нам, вероятно, придется взять на себя инициативу, чтобы направлять инженеров к необходимой информации, подходу и другим деталям, которые соответствуют лучшим практикам для создания спецификации.
В этом отношении технические писатели играют ключевую роль в сотрудничестве с командой в разработке спецификации API. Если придерживаться философии разработки, основанной на спецификациях, эта роль (техписателя) может помочь сформировать API до его кодирования и блокировки. Это означает, что может быть возможность влиять на имена конечных точек, консистенцию и шаблоны, простоту и другие факторы, которые влияют на разработку API (на которые, обычно, не влияют технические писатели).
Визуализация спецификации OpenAPI с помощью Swagger UI
После того, как получился действующий документ по спецификации OpenAPI, описывающий API, можно “скормить” эту спецификацию различным инструментам, чтобы проанализировать ее и сгенерировать интерактивную документацию, аналогичную примеру Petstore.
Наиболее распространенным инструментом, используемым для анализа спецификации OpenAPI, является Swagger UI. (Помните, что «Swagger» относится к инструментам API, тогда как «OpenAPI» относится к независимой от поставщика спецификации, не зависящей от инструмента.) После загрузки пользовательского интерфейса Swagger его довольно легко настроить с помощью собственного файла спецификации. Руководство по настройке Swagger UI есть в этом разделе.
Код пользовательского интерфейса Swagger генерирует экран, который выглядит следующим образом:
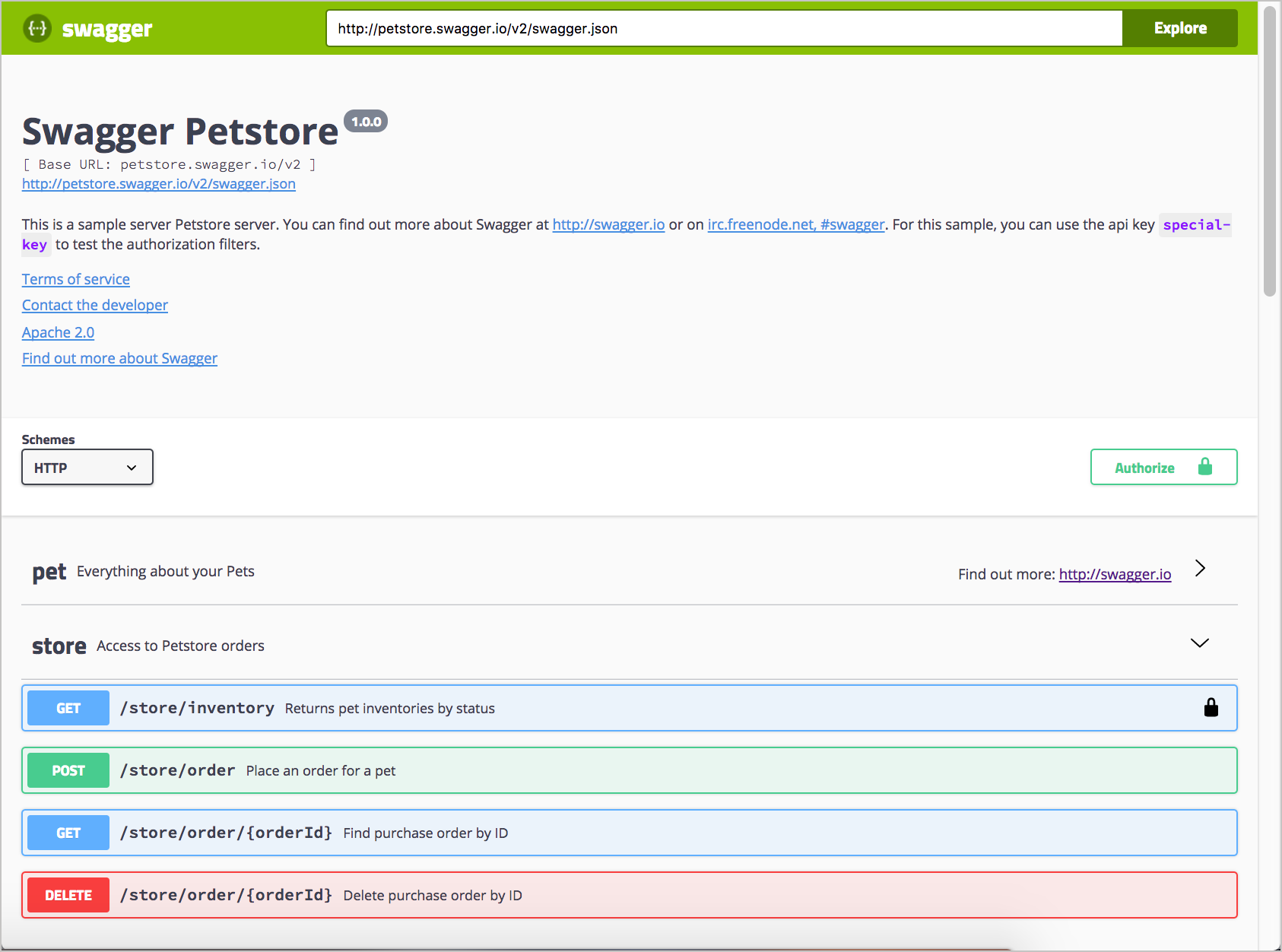 На изображении видно, как Swagger отображает спецификацию Open API
На изображении видно, как Swagger отображает спецификацию Open API
Можно ознакомиться с примером интеграции Swagger UI с примером API сервиса погоды, использованным в качестве примера курса.
Некоторые дизайнеры критикуют выпадающие списки Swagger UI как устаревшие. В то же время разработчики считают одностраничную модель привлекательной и способной уменьшать или увеличивать детали. Объединяя все конечные точки на одной странице в одном представлении, пользователи могут сразу увидеть весь API. Такое отображение дает пользователям представление в целом, что помогает уменьшить сложность и позволяет им начать. Во многих отношениях отображение Swagger UI является кратким справочным руководством по API.
👨💻 Практическое занятие: Исследуем API PetStore в Swagger UI
Давайте познакомимся с пользовательским интерфейсом Swagger, используя Petstore.
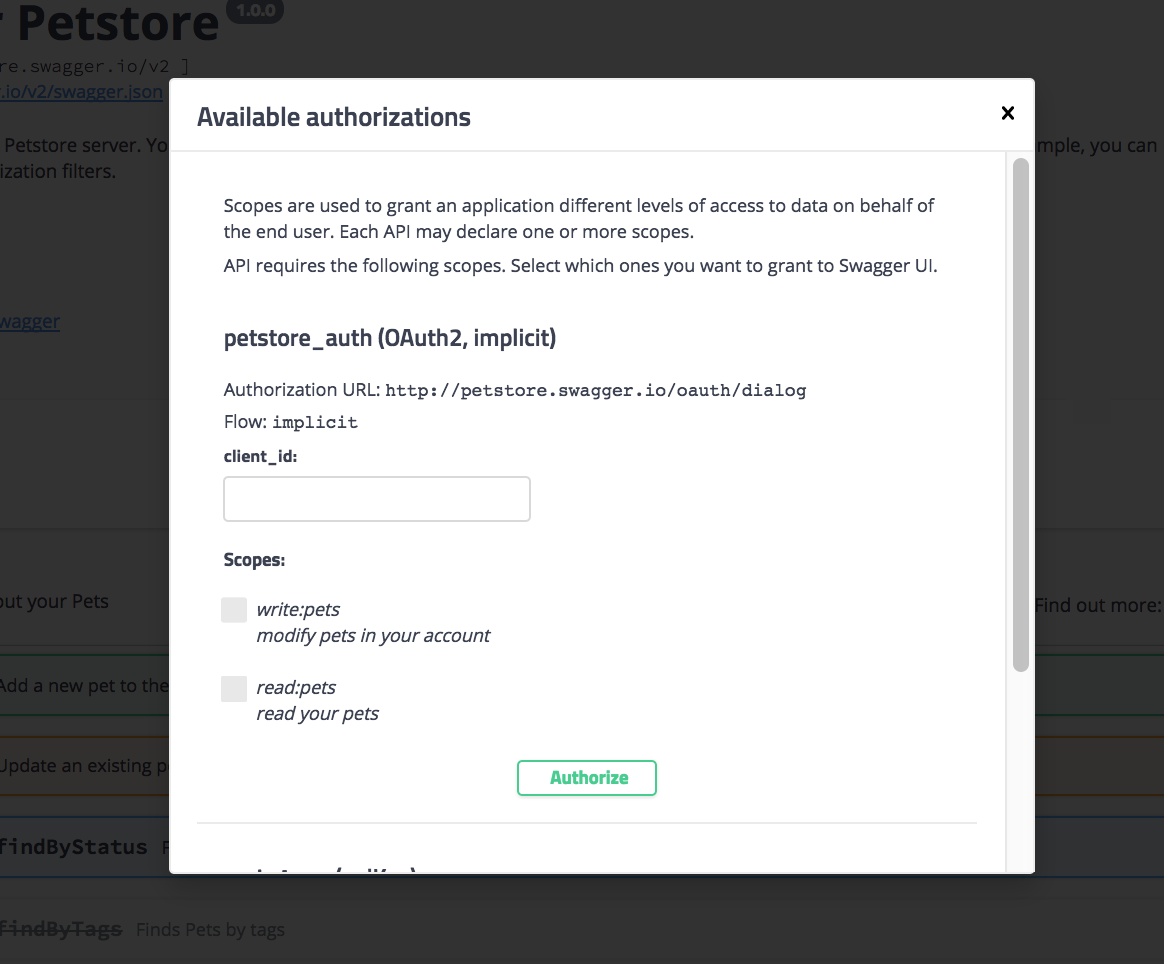 Окно авторизации в Swagger UI
Окно авторизации в Swagger UI
Разворачиваем конечную точку Pet
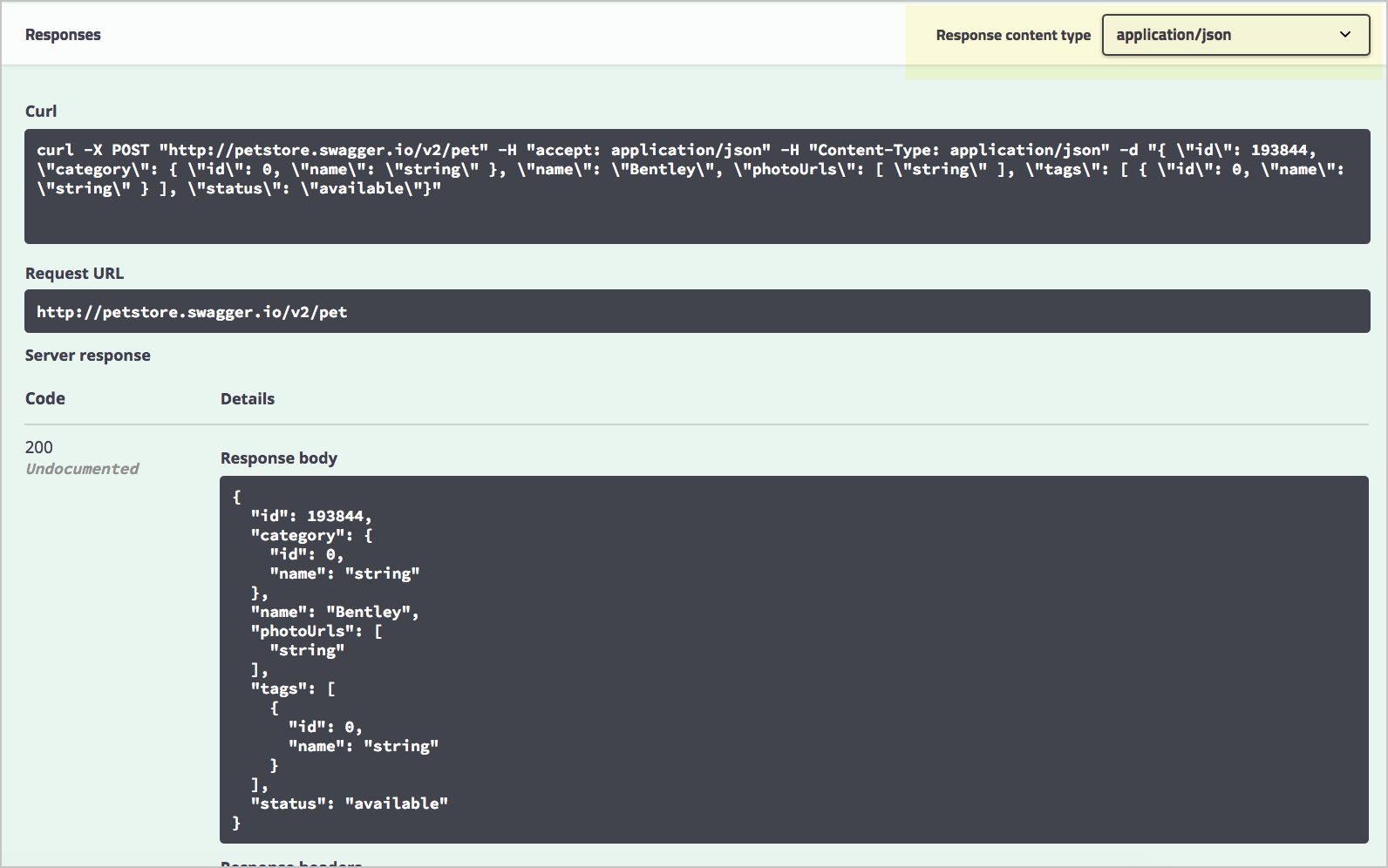
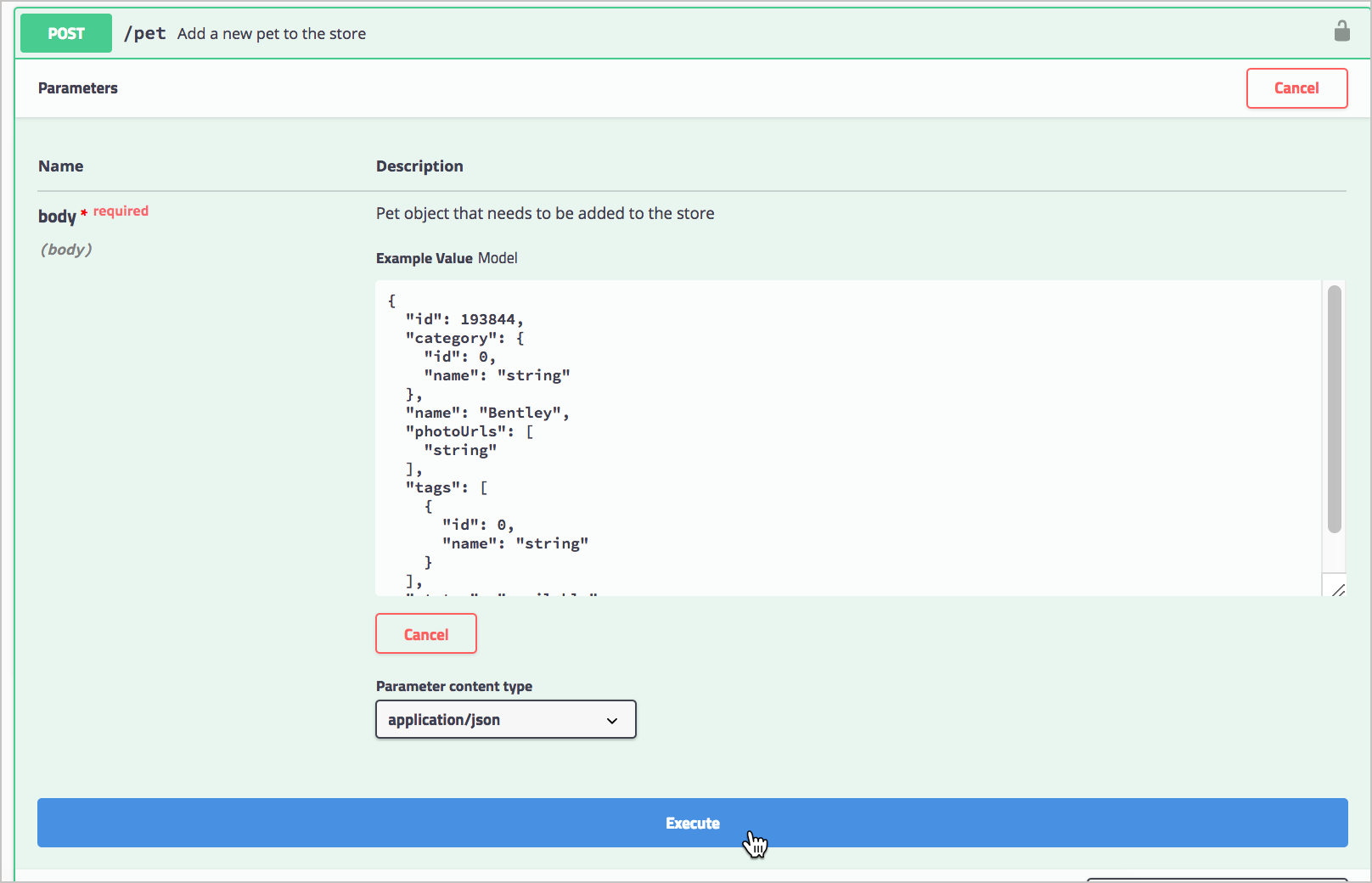 Выполнение примера Petstore запроса
Выполнение примера Petstore запроса
Swagger UI отправляет запрос и показывает отправленный curl. В примере был отправлен curl:
В разделе “Ответы” Swagger UI выдает ответ сервера. По умолчанию ответ возвращает XML:
Если выбрать в выпадающем списке “Response content type” JSON, то в ответе вернется JSON вместо XML.
Другие инструменты визуализации
Помимо Swagger UI есть и другие инструменты, которые могут анализировать нашу документацию OpenAPI. Вот список из нескольких инструментов: Restlet Studio, Apiary, Apigee, Lucybot, Gelato, Readme.io, swagger2postman, отзывчивую тему swagger-ui, Postman Run Buttons и многое другое.
Кастомизация Swagger UI
Однако, помимо этих простых модификаций, потребуется немного мастерства веб-разработчика, чтобы существенно изменить отображение пользовательского интерфейса Swagger. Возможно, понадобятся навыки веб-разработки.
Недостатки OpenAPI и Swagger UI
Несмотря на то, что Swagger обладает интерактивными возможностями апеллировать к желаниям пользователей «дай мне попробовать», у Swagger и OpenAPI есть некоторые недостатки:
Некоторые утешения
Несмотря на недостатки спецификации OpenAPI, он все же настоятельно рекомендуется ее для описания API. OpenAPI быстро становится средством для все большего и большего количества инструментов (от кнопки запуска Postman для почти каждой платформы API), для быстрого получения информации о нашем API и для превращения ее в доступную и интерактивную документацию. С помощью своей спецификации OpenAPI можно портировать свой API на многие платформы и системы, а также автоматически настраивать модульное тестирование и создание прототипов.
Swagger UI обеспечивает определенно хорошую визуальную форму для API. Можно легко увидеть все конечные точки и их параметры (например, краткий справочник). Основываясь на этой структуре, можно помочь пользователям понять основы вашего API.
Кроме того, изучение спецификации OpenAPI и описание своего API с его объектами и свойствами поможет расширить свой собственный словарь API. Например, станет понятно, что существует четыре основных типа параметров: параметры «пути», параметры «заголовка», параметры «запроса» и параметры «тела запроса». Типы данных параметров в REST: «Boolean», «number», «integer» или «string». В ответах содержатся «objects», содержащие «strings» или «arrays».
Короче говоря, реализация спецификации даст еще и представление о терминологии API, которая, в свою очередь, поможет описать различные компоненты своего API достоверными способами.
OpenAPI может не подходить для каждого API, но если API имеет довольно простые параметры, без большого количества взаимозависимостей между конечными точками, и если нет проблем исследовать API с данными пользователя, OpenAPI и Swagger UI могут быть мощным дополнением к документации. Можно давать пользователям возможность опробовать запросы и ответы.
С таким интерактивным элементом документация становится больше, чем просто информация. С помощью OpenAPI и Swagger UI мы создаем пространство для пользователей, которые одновременно могут читать нашу документацию и экспериментировать с нашим API. Эта комбинация имеет тенденцию предоставлять мощный опыт обучения для пользователей.
Ресурсы для дальнейшего чтения
Вот источники для получения дополнительной информации об OpenAPI и Swagger:



