Яндекс.Танк и автоматизация нагрузочного тестирования
 В ходе тестирования некоторых продуктов компании Positive Technologies возникла необходимость проведения быстрых стресс-тестов одного веб-сервиса. Эти тесты должны были быть простыми и быстрыми в разработке, нетребовательными к аппаратным ресурсам и одновременно с этим давать значительную нагрузку однотипными HTTP-запросами, а также предоставлять статистические данные для анализа системы под нагрузкой.
В ходе тестирования некоторых продуктов компании Positive Technologies возникла необходимость проведения быстрых стресс-тестов одного веб-сервиса. Эти тесты должны были быть простыми и быстрыми в разработке, нетребовательными к аппаратным ресурсам и одновременно с этим давать значительную нагрузку однотипными HTTP-запросами, а также предоставлять статистические данные для анализа системы под нагрузкой.
Для их реализации мы исследовали и опробовали некоторое количество инструментов, среди которых были Apache JMeter и написанный нами на Python скрипт LogSniper, который выполнял реплей заранее подготовленных серверных логов с HTTP-запросами на цель.
От использования JMeter было решено отказаться из-за значительной сложности подготовки и проведения тестов, высоких требований к производительности нагрузочного стенда и довольно малых мощностей нагрузки, хотя эти недостатки и компенсировались высокой информативностью собираемой статистики. LogSniper был отклонен из-за малой мощности генерируемой нагрузки и здесь даже простота подготовки нагрузочных HTTP-пакетов не смогла перевесить. Другие известные инструменты нам по тем или иным причинам тоже не подошли.
В итоге мы остановились на инструменте Яндекс.Танк, о котором узнали, побывав на конференции YAC-2013 и пообщавшись со специалистами Яндекса. Этот инструмент полностью отвечал всем нашим требованиям к простоте подготовки теста и к генерируемой нагрузке.
Что это
Яндекс.Танк — инструмент для проведения нагрузочного тестирования, разрабатываемый в компании Яндекс и распространяемый по лицензии LGPL. В основе инструмента лежит высокопроизводительный асинхронный генератор нагрузки phantom: он был переделан из одноименного веб-сервера, который «научили» работать в режиме клиента. При помощи phantom можно генерировать десятки и сотни тысяч HTTP-запросов в секунду (http-requests per second, http-rps).
В процессе своей работы Танк сохраняет полученные результаты в обычных текстовых журналах, сгруппированных по директориям для отдельных тестов. Во время теста специальный модуль организует вывод результатов в консольный интерфейс в виде таблиц. Одновременно запускается локальный веб-сервер, позволяющий видеть те же самые результаты на информативных графиках. По окончании теста возможно автоматическое сохранение результатов на сервисе Loadosophia.org. Также имеется модуль загрузки результатов в хранилище Graphite.
Некоторые полезные ссылки:
Сравнение производительности двух аналогичных веб-сервисов
В ходе работы нам потребовалось сравнить характеристики двух веб-сервисов, работу которых можно примерно описать как «прозрачные HTTP-прокси, перенаправляющие входящие запросы на backend-приложение».
Общую схему работы можно изобразить следующим образом:
На стенде с Танком использовался генератор нагрузки phantom с включенным монитором производительности.
В качестве стенда web-proxy на схеме использовались два тестируемых веб-сервиса, с которых при помощи агента Танка снимались показатели производительности. Условно назовем их Эталонный веб-сервис и Испытуемый веб-сервис. Нам требовалось понять, соответствует ли производительность испытуемого веб-сервиса эталонному.
Для backend использовалось небольшое веб-приложение, запущенное под Nginx и возвращающее одну простую HTML-страничку.
Выявленные ограничения
Перед началом работ мы собрали информацию об ограничениях виртуальных стендов, на которых была построена вся тестовая инфраструктура.
Характеристики стенда backend-приложения:
25 000 http-rps, но и при нагрузке выше 25k http-rps работа стенда не была нарушена.
Стенд Танка с характеристиками 16 vCPU, 8 GB, 10 Gb/s позволил реализовать нагрузку до 300 000 http-rps.
Пропускная способность виртуальной среды ESXi, определенная с помощью Iperf, составила 8 Gb/s в одну сторону, 4 Gb/s при двухсторонней нагрузке между двумя виртуальными машинами.
Метрики и критерии сравнения
Перед началом работы для дальнейшего измерения мы определили следующие метрики каждого профиля нагрузки:
В данном случае мы решили выбрать следующие критерии для сравнения работы веб-сервисов под нагрузкой:
Тестовые HTTP-запросы
Для одного из профилей нагрузочных тестов нам требовалось создать смешанный HTTP-трафик из GET- и POST-запросов с линейным возрастанием нагрузки до 10k http-rps в течение 10 минут.
Чтобы упростить подготовку патрона для такого смешанного трафика, мы сделали скрипты, аналогичные perl-скриптам, предлагаемым на форуме.
Сбор данных и анализ результатов
После подготовки запросов мы просто запустили Танк стандартным образом и выполнили нагрузочный тест со смешанным трафиком для обоих тестируемых веб-сервисов.
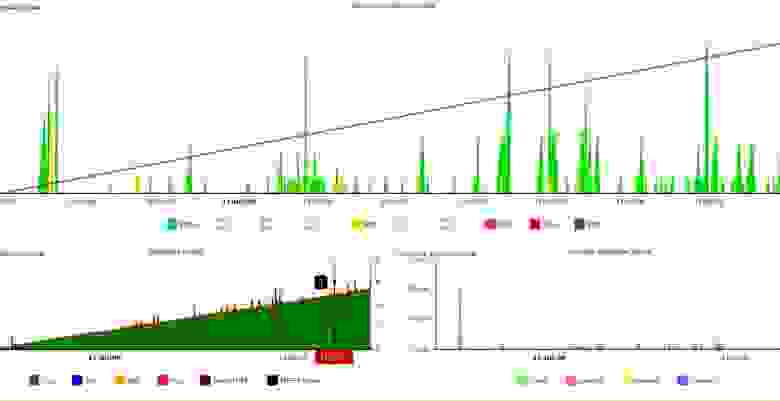
Результаты для эталонного веб-сервиса
Информация веб-монитора Танка:
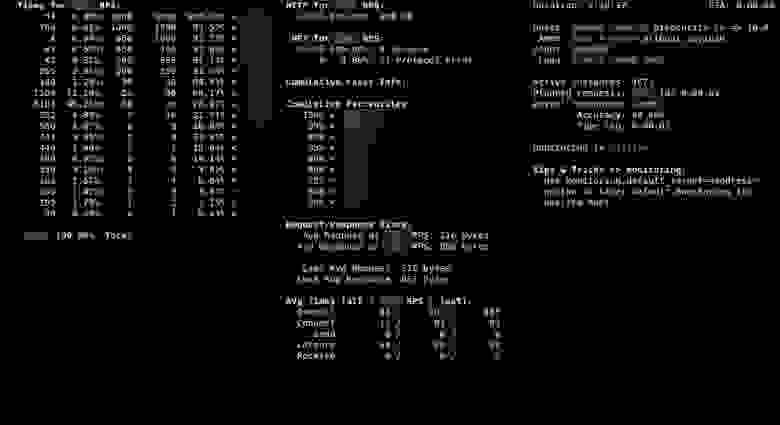
Информация консоли Танка:
Результаты для испытуемого веб-сервиса
Информация веб-монитора Танка:

Информация консоли Танка:

Даже судя по графикам, испытуемый сервис показывал результаты не хуже, чем эталонный. Проверив все три формально определенных выше критерия, мы в этом убедились.
Выводы
По результатам работы с Яндекс.Танком можно с полной ответственностью заявить, что этот инструмент отлично подходит в тех случаях, когда требуется быстро провести нагрузочное тестирование веб-приложений без их сложной подготовки и при этом получить множество полезных статистических данных для анализа производительности.
Кроме того, он хорошо внедряется в имеющиеся системы автоматизации. Например, для упрощения работы со стендом Танка — управления, запуска, подготовки патронов для лент, контроля за процессом тестирования и сбором результатов — мы без особых усилий написали класс-обвязку на Python, который подключается к стенду по SSH и выполняет все перечисленные действия. Затем этот класс был встроен в нашу существующую систему авто-тестирования.
Дополнительно вы можете посмотреть, как подключить и использовать высокопроизводительную систему Graphit для анализа большого числа графиков (о ней рассказывалось в одной из презентаций на конференции YAC-2013). Ее также можно приспособить для нужд нагрузочного тестирования с использованием Яндекс.Танка.
Выражаю благодарность моему коллеге Олегу Каштанову за техническую поддержку.
Тестирование производительности веб-сервиса в рамках Continuous Integration. Опыт Яндекса
Почти всех новых сотрудников Яндекса поражают масштабы нагрузок, которые испытывают наши продукты. Тысячи хостов с сотнями тысяч запросов в секунду. И это только один из сервисов. При этом отвечать на запросы мы должны за доли секунды. Даже незначительное изменение в продукте может оказать существенное влияние на производительность, поэтому важно тестировать и оценивать влияние своего кода на сервис.
В нашем сервисе рекламных технологий тестирование работает в рамках методологии Continuous integration, более подробно об организации которой мы расскажем 25 октября на мероприятии Яндекс изнутри, а сегодня мы поделимся с читателями Хабра опытом автоматизации оценки важных продуктовых метрик, связанных с производительностью сервиса. Вы узнаете, как доверить анализ машине, а не следить за ними на графиках. Поехали!

Речь не пойдет о том, как протестировать сайт. Для этого есть немало онлайн-инструментов. Сегодня мы поговорим о высоконагруженном внутреннем бэкенд-сервисе, который является частью большой системы и готовит информацию для внешнего сервиса. В нашем случае – для страниц поисковой выдачи и сайтов партнеров. Если наш компонент не успевает отвечать, то информацию от него просто не отдадут пользователю. А значит, компания потеряет деньги. Поэтому очень важно отвечать вовремя.
Какие важные показатели сервера можно выделить?
Итак, давайте по порядку.
Request per second
Наш разработчик, который долгое время занимался вопросами нагрузочного тестирования, любит говорить про критический ресурс системы. Давайте разберемся, что это такое.
У каждой системы есть свои конфигурационные характеристики, которые определяют работу. Например, длина очереди, время ожидания ответа, threads-worker pool и т.д. И вот может так случиться, что ёмкость вашего сервиса упирается в какой-то из этих ресурсов. Можно провести эксперимент. Увеличивать по очереди каждый ресурс. Ресурс, увеличение которого повысит ёмкость вашего сервиса, и будет для вас критическим. В хорошо сконфигурированной системе, чтобы поднять ёмкость, придется увеличить не один ресурс, а несколько. Но такой всё равно можно «нащупать». Будет отлично, если вы сможете настроить свою систему так, чтобы все ресурсы работали в полную силу, а сервис укладывался в заданные ему временные рамки.
Чтобы оценить, сколько запросов в секунду выдержит ваш сервер, нужно направить в него поток запросов. Так как у нас этот процесс встроен в CI-систему, мы используем очень простую «пушку», с ограниченной функциональностью. Но из открытого ПО для этой задачи отлично подойдет Яндекс.Танк. У него есть подробная документация. В подарок к Танку идёт сервис для просмотра результатов.
Небольшой офтоп. У Яндекс.Танка достаточно богатая функциональность, не ограниченная автоматизацией обстрела запросами. Он также поможет собрать метрики вашего сервиса, построить графики и прикрутить модуль с нужной вам логикой. В общем, очень рекомендуем познакомиться с ним.
Ёмкость можно измерять двумя способами.
Открытая модель нагрузки (стресс-тестирование)
Сделать «пользователей», то есть несколько потоков, которые будут отправлять запрос в вашу систему. Нагрузку мы будем давать не постоянную, а наращивать или даже подавать её волнами. Тогда это приблизит нас к реальной жизни. Наращиваем RPS и ловим точку, в которой обстреливаемый сервис “пробьёт” SLA. Таким образом можно найти пределы работы системы.
Для расчета количества пользователей можно воспользоваться формулой Литтла (о ней можно почитать тут). Опуская теорию, формула выглядит так:
RPS = 1000 / T * workers, где
• T – среднее время обработки запроса (в миллисекундах);
• workers – количество потоков;
• 1000 / T запросов в секунду – такое значение выдаст однопоточный генератор.
Закрытая модель нагрузки (нагрузочное тестирование)
Берём фиксированное количество “пользователей”. Нужно настроить так, чтобы входная очередь, соответствующая конфигурации вашего сервиса, была всегда забита. При этом делать число потоков больше, чем лимит очереди, бессмысленно, так как мы будем упираться в это число, а остальные запросы будут отбрасываться сервером с 5xx ошибкой. Cмотрим, сколько запросов в секунду конструкция сможет выдать. Такая схема в общем случае не похожа на реальный поток запросов, но она поможет показать поведение системы при максимальной нагрузке и оценить её пропускную способность на текущий момент.
Для подавляющего большинства систем (где критический ресурс не имеет отношения к обработке соединений) результат будет одинаковый. При этом у закрытой модели шум меньше, потому что система всё время теста находится в интересующей нас области нагрузки.
Мы при тестировании нашего сервиса используем закрытую модель. После отстрела пушка выдает нам, сколько запросов в секунду наш сервис смог выдать. Яндекс.Танк этот показатель тоже легко подскажет.
Time per request
Если вернуться к предыдущему пункту, то становится очевидно, что при такой схеме оценивать время ответа на запрос не имеет никакого смысла. Чем сильнее мы нагрузим систему, тем сильнее она будет деградировать и тем дольше будет отвечать. Поэтому для тестирования времени ответа подход должен быть другим.
Для получения среднего времени ответа воспользуемся тем же Яндекс.Танком. Только теперь зададим RPS, соответствующий среднему показателю вашей системы в продакшене. После обстрела получим времена ответов каждого запроса. По собранным данным можно посчитать процентили времен ответов.
Дальше нужно понять, какой процентиль мы считаем важным. Например, мы отталкиваемся от продакшена. Мы можем оставить 1% запросов на ошибки, неответы, дебажные запросы, которые отрабатывают долго, проблемы с сетью и т.п. Поэтому мы считаем значимым время ответа, в которое вмещается 99% запросов.
Resident set size
Непосредственно наш сервер работает с файлами через mmap. Измеряя показатель RSS, мы хотим знать, сколько памяти программа забрала у операционной системы за время работы.
В Linux пишется файл /proc/PID/smaps – это расширение, основанное на картах, показывающее потребление памяти для каждого из отображений процесса. Если вы ваш процесс использует tmpfs, то в smaps попадёт как анонимная, так и неанонимная память. В неанонимную память входят, например, файлы, подгруженные в память. Вот пример записи в smaps. Указан конкретный файл, а его параметр Anonymous = 0kB.
А это пример анонимного выделения памяти. Когда процесс (тот же mmap) делает запрос в операционную систему на выделение определенного размера памяти, ему выделяется адрес. Пока процесс занимает только виртуальную память. В этот момент мы ещё не знаем какой физический кусок памяти выделится. Мы видим безымянную запись. Это пример выделения анонимной памяти. У системы запросили размер 24572 kB, но им не воспользовались и фактически заняли только RSS = 4 kB.
Так как выделенная неанонимная память никуда не денется после остановки процесса, файл не удалится, то такой RSS нас не интересует.
HTTP-ошибки
Не забывайте следить за кодами ответов, которые во время тестирования возвращает сервис. Если что-то в настройке теста или окружения пошло не так, и вам на все запросы сервер вернул 5хх и 4хх ошибки, то смысла в таком тесте было не много. Мы следим за долей плохих ответов. Если ошибок много, то тест считается невалидным.
Немного о точности измерений
А теперь самое важное. Давайте вернёмся к предыдущим пунктам. Абсолютные величины посчитанных нами метрик, оказывается, не так уж нам и важны. Нет, конечно же, вы можете добиваться стабильности показателей, учтя все факторы, погрешности и флуктуации. Параллельно написать научную работу на эту тему (кстати, если кто искал себе такую, эта может быть неплохим вариантом). Но это не то, что нас интересует.
Нам важно влияние конкретного коммита на код относительно предыдущего состояния системы. То есть важна разница метрик от коммита к коммиту. И вот тут необходимо настроить процесс, который будет сравнивать эту разницу и при этом обеспечит стабильность абсолютной величины на этом интервале.
Окружение, запросы, данные, состояние сервиса – все доступные нам факторы должны быть зафиксированы. Вот эта система и работает у нас в рамках Continuous integration, обеспечивая нас информацией о всевозможных изменениях, которые произошли в рамках каждого коммита. Несмотря на это, всё зафиксировать не удастся, останется шум. Уменьшить шум мы можем, очевидно, увеличив выборку, то есть произвести несколько итераций отстрела. Далее, после отстрела, скажем, 15 итераций, можно посчитать медиану получившейся выборки. Кроме того, необходимо найти баланс между шумом и длительностью отстрела. Мы, например, остановились на погрешности в 1%. Если вы хотите выбрать более сложный и точный статистический метод в соответствии со своими требованиями, рекомендуем книгу, в которой перечислены варианты с описанием, когда и какой применяется.
Что ещё можно сделать с шумом?
Отметим, что немаловажную роль в таком тестировании занимает среда, в которой вы проводите тесты. Тестовый стенд должен быть надежным, на нём не должны быть запущены другие программы, так как они могут приводить к деградации вашего сервиса. Кроме того, результаты могут и будут зависеть от профиля нагрузки, окружения, базы данных и от различных “магнитных бурь”.
Мы в рамках одного теста коммита проводим несколько итераций на разных хостах. Во-первых, если вы пользуетесь облаком, то там может происходить что угодно. Даже если облако специализированное, как наше, всё равно там работают служебные процессы. Поэтому полагаться на результат от одного хоста нельзя. А если хост у вас железный, где нет, как в облаке, стандартного механизма поднятия окружения, то его можно вообще один раз случайно сломать и так и оставить. И врать он будет вам всегда. Поэтому мы гоняем наши тесты в облаке.
Из этого, правда, вытекает другой вопрос. Если ваши измерения производятся каждый раз на разных хостах, то результаты могут немного шуметь и из-за этого в том числе. Тогда можно нормировать показания на хост. То есть по историческим данным собрать “коэффициент хоста” и учитывать его при анализе результатов.
Анализ исторических данных показывает, что «железо» у нас разное. В слово «железо» тут входят версия ядра и последствия uptime (по-видимому, не перемещаемые объекты ядра в памяти).
Таким образом, каждому «хосту» (при перезагрузке хост «умирает» и появляется «новый») ставим в соответствие поправку, на которую умножаем RPS перед агрегацией.
Поправки считаем и обновляем крайне топорным способом, подозрительно напоминающим некоторый вариант обучения с подкреплением.
Для заданного вектора похостовых поправок считаем целевую функцию:
Дальше одну поправку (для хоста, у которого сумма этих весов наибольшая) фиксируем в 1.0 и ищем значения всех остальных поправок, дающие минимум целевой функции.
Чтобы провалидировать результаты на исторических данных, считаем поправки на старых данных, считаем поправленный результат на свежих, сравниваем с неисправленным.
Ещё один вариант корректировки результатов и уменьшения шума – это нормировка на «синтетику». Перед запуском трестируемого сервиса запустить на хосте “синтетическую программу”, по работе которой можно оценить состояние хоста и рассчитать поправочный коэффициент. Но в нашем случае мы используем поправки по хостам, а эта идея так и осталась идеей. Возможно, кому-то из вас она приглянется.
Несмотря на автоматизацию и все её плюсы, не забывайте о динамике ваших показателей. Важно следить, чтобы сервис не деградировал во времени. Маленькие просадки можно не заметить, они могут накопиться, и на большом временном промежутке ваши показатели могут просесть. Вот пример наших графиков, по которым мы смотрим на RPS. Он показывает относительное значение на каждом проверенном коммите, его номер и возможность посмотреть откуда был отведен релиз.
Если вы дочитали статью, значит, вам точно будет интересно посмотреть доклад про Яндекс.Танк и анализ результатов нагрузочного тестирования.
Также напоминаем, что более подробно об организации Continuous integration мы расскажем 25 октября на мероприятии Яндекс изнутри. Приходите в гости!
Как провести нагрузочное тестирование интернет-магазина на Битрикс

Зачем проводить нагрузочное тестирование сайта
Цели и задачи нагрузочного тестирования
Тестировать стойкость к нагрузке нужно, чтобы сервер не «лег» при запуске сайта или из-за увеличения количества посещений. Процедура не застрахует от некорректной работы при нагрузках, но поможет понять реальную пропускную способность сайта.
Цели нагрузочного тестирования — не просто «положить» сайт, а понять, как именно он ведет себя под нагрузкой, определить запас прочности сервера и выявить слабые места с точки зрения производительности. Если выполнять проверку своевременно, у вас будет возможность подготовить сайт к будущим нагрузкам — сделать техническую переработку функционала и оптимизацию серверов.
Когда проводить нагрузочное тестирование интернет-магазина
Нагрузочное тестирование — это плановая процедура, но особенно важно проводить его перед масштабными маркетинговыми кампаниями — например, перед праздничными распродажами, когда ожидается наплыв пользователей. Если интернет-магазин перестанет корректно работать и отвечать на запросы пользователей, пострадает его репутация в глазах посетителей и поисковых систем.
Стоит проводить нагрузочное тестирование при разных сценариях — и при запуске новых проектов или затрагивающих функционал доработках старого сайта.
Виды нагрузочного тестирования
Существует две модели нагрузочного тестирования:
Инструменты нагрузочного тестирования
Инструменты могут воспроизводить любой сценарий поведения пользователя в интернет-магазине и собирать метрики для отчета о нагрузочном тестировании.
В качестве инструмента для нагрузочного тестирования мы обычно используем Яндекс Танк (Yandex Tank) — нагрузочный фреймворк для анализа производительности сайтов. В основе инструмента Яндекс Танк — система генерации нагрузки Phantom, позволяющая производить десятки и сотни тысяч HTTP-запросов в секунду.
Преимущества Яндекс Танк для нагрузочного тестирования
Как провести нагрузочное тестирование сайта на примере кейса KISLOROD
К нам обратился крупный интернет-магазин верхней одежды и аксессуаров со следующей проблемой.
Клиенту другой разработчик собрал новый сайт. Чтобы проверить, какую нагрузку он выдерживает, направили часть трафика со старого сайта на новый. Сайт «лег». Перед клиентом встал вопрос — «чинить» новый сайт или «хоронить», и разработать ещё один на фреймворке.
Мы предложили провести нагрузочное тестирование интернет-магазина и технический аудит сайта — так как была вероятность, что проблему получится решить рефакторингом компонентов и настройкой серверного окружения.
Постановка целей и задач
Мы хотели проверить максимальную производительность интернет-магазина — чтобы клиент понял, что можно получить на текущем оборудовании, а мы увидели перспективы масштабирования проекта.
Цель теста: выяснить предельное количество хитов в секунду, которое может выдержать текущая конфигурация «сервер плюс сайт» и определить самые «тяжелые» страницы для последующей оптимизации.
Определение условий и инструментов нагрузочного тестирования
Подготовка к нагрузочному тестированию
Важно грамотно определить сценарии нагрузочного тестирования. Не всегда понятно, на что более всего тратятся серверные ресурсы — куда направлять ботов. Направив нагрузку не на проблемные места сайта, можно получить хорошие, но ложные результаты. Поэтому нужно как можно точнее смоделировать действия пользователей.
Чтобы определить сценарии, мы выгрузили список страниц сайта и сформировали перечень из примерно 1000 страниц с примерным соотношением:
Определение предела теста
Были выставлены лимиты, при достижении любого из которых стресс-тест автоматически останавливается:
Запуск и анализ результатов нагрузочного тестирования
Этапы тестирования
Проведение тестов и анализ результатов нагрузочного тестирования
Мы провели несколько тестов и получили результаты, которыми поделимся ниже.
RPS (request per second) — число запросов в секунду на страницы сайта, которые производили при нагрузочном тестировании. Показывает примерное количество запросов, после которого был прерван тест — либо из-за отсутствия ответа по сети, либо из-за ошибок в HTTP запросах.
Условия: запущен тест примерно на 1000 страниц, отсортированных по типам и по алфавиту. Кэш на сайте не сбрасывали.
Результат можно посмотреть здесь. RPS=256. В этот раз сайт также выдержал нагрузку, и нагрузка на сервер составила не более 30%. Нагрузка на базу данных была мизерной. LoadAverage не превышал трех. Тест прервался по причине сетевой недоступности из-за повышенной нагрузки на канал связи.

Условия: был сброшен кэш. Тест запущен по большому списку отсортированных страниц.
Результат можно посмотреть здесь. RPS=11.


Условия: тестирование сайта по прежнему списку при «прогретом» кэше.
Результат можно посмотреть здесь. RPS=250.


Условия: тестирование демо-сайта на чистом Битриксе при пустом кэше с базой на локальном сервере.
Результат можно посмотреть здесь. При RPS=168 нагрузка на процессор выросла до 100%.

Условия: Тестирование демо сайта с шаблоном готового решения Aspro Next, на котором базировался код тестируемого сайта при пустом кэше с базой на локальном сервере.
Результат: При RPS=128 нагрузка на процессор выросла до 100%.




