ZooKeeper Java Example
A Simple Watch Client
To introduce you to the ZooKeeper Java API, we develop here a very simple watch client. This ZooKeeper client watches a ZooKeeper node for changes and responds to by starting or stopping a program.
Requirements
The client has four requirements:
It takes as parameters:
the address of the ZooKeeper service
an executable with arguments.
It fetches the data associated with the znode and starts the executable.
If the znode changes, the client refetches the contents and restarts the executable.
If the znode disappears, the client kills the executable.
Program Design
Conventionally, ZooKeeper applications are broken into two units, one which maintains the connection, and the other which monitors data. In this application, the class called the Executor maintains the ZooKeeper connection, and the class called the DataMonitor monitors the data in the ZooKeeper tree. Also, Executor contains the main thread and contains the execution logic. It is responsible for what little user interaction there is, as well as interaction with the exectuable program you pass in as an argument and which the sample (per the requirements) shuts down and restarts, according to the state of the znode.
The Executor Class
The Executor object is the primary container of the sample application. It contains both the ZooKeeper object, DataMonitor, as described above in Program Design.
Recall that the Executor’s job is to starts and stop the executable whose name you pass in on the command line. It does this in response to events fired by the ZooKeeper object. As you can see in the code above, the Executor passes a reference to itself as the Watcher argument in the ZooKeeper constructor. It also passes a reference to itself as DataMonitorListener argument to the DataMonitor constructor. Per the Executor’s definition, it implements both these interfaces:
The DataMonitorListener interface, on the other hand, is not part of the the ZooKeeper API. It is a completely custom interface, designed for this sample application. The DataMonitor object uses it to communicate back to its container, which is also the the Executor object.The DataMonitorListener interface looks like this:
This interface is defined in the DataMonitor class and implemented in the Executor class. When Executor.exists() is invoked, the Executor decides whether to start up or shut down per the requirements. Recall that the requires say to kill the executable when the znode ceases to exist.
When Executor.closing() is invoked, the Executor decides whether or not to shut itself down in response to the ZooKeeper connection permanently disappearing.
As you might have guessed, DataMonitor is the object that invokes these methods, in response to changes in ZooKeeper’s state.
Here are Executor’s implementation of DataMonitorListener.exists() and DataMonitorListener.closing :
The DataMonitor Class
The DataMonitor class has the meat of the ZooKeeper logic. It is mostly asynchronous and event driven. DataMonitor kicks things off in the constructor with:
The call to ZooKeeper.exists() checks for the existence of the znode, sets a watch, and passes a reference to itself ( this ) as the completion callback object. In this sense, it kicks things off, since the real processing happens when the watch is triggered.
Don’t confuse the completion callback with the watch callback. The ZooKeeper.exists() completion callback, which happens to be the method StatCallback.processResult() implemented in the DataMonitor object, is invoked when the asynchronous setting of the watch operation (by ZooKeeper.exists() ) completes on the server.
The triggering of the watch, on the other hand, sends an event to the Executor object, since the Executor registered as the Watcher of the ZooKeeper object.
As an aside, you might note that the DataMonitor could also register itself as the Watcher for this particular watch event. This is new to ZooKeeper 3.0.0 (the support of multiple Watchers). In this example, however, DataMonitor does not register as the Watcher.
When the ZooKeeper.exists() operation completes on the server, the ZooKeeper API invokes this completion callback on the client:
Finally, notice how DataMonitor processes watch events:
Незаслуженно забытый ZooKeeper
Несмотря на наличие работающего решения немалой части распределенных проблем о нем мало пишут и создается впечатление, что это что-то устаревшее и не заслуживающее внимания.
Это не так. Начинать новый проект с Зукипером или встраивать его в существующий проект в 2021 году можно и нужно.
Зукипер просто работает
Он на самом деле умеет работать с несколькими датацентрами, вам не надо думать кто там сейчас мастер, не надо что-то делать если одна из нод исчезла, вообще не надо ни о чем заботится. Его даже не надо как-то по-особенному конфигурить, вам скорее всего подойдет конфигурация из коробки. Да, она будет держать вашу нагрузку. Вы записали данные и сможете их прочитать пока работает хотя бы одна из нод. При включении новой ноды она сама загрузит актуальное состояние и продолжит работать.
Производительность
Зукипер держит большой RPS. О производительности, как правило, можно не думать. С большой вероятностью ее вам хватит для любого разумного применения.
Зукипер это дерево
Вы можете легко на одном кластере держать все ваши микросерсивисы и операции. Просто аккуратно разложите их по разным поддеревьям. Об этом лучше подумать сразу и организовать хранение так что любой сервис живет только в своем поддереве.
Конкретные примеры использования Зукипера
Все примеры написанны с помощью Apache Curator Framework. Большая часть взята прямо с https://curator.apache.org/curator-recipes/index.html
Код всех примеров подразумевает что вы его запускаете на нескольких нодах. Минимум две ноды, практика говорит что три ноды надежнее.
Выбор мастера
Иногда встречаются master-slave системы. В них есть 2-3 ноды. Одна из них мастер и работает, остальные ждут пока мастер станет недоступен. При недоступности мастера проходят выборы и одна из slave нод становится новым мастером. Шардирование обычно лучше, но иногда оно просто не нужно. Одного работающего мастера хватает на все про все с запасом.
Очередь
Отлично подходит для случая когда вам нужна распределенная отказоустойчивая очередь, но использование полноценных решений вроде Кафки выглядит оверкилом. Например, у вас немного данных в очереди и поток событий небольшой.
И простейшие данные для примера
Распределенные семафоры
К вам пришли из соседней команды и поругались на пиковую нагрузку от вас. И вы теперь не хотите со всех 100 ваших нод одновременно ходить в соседний сервис за данными, которые вам нужны не очень срочно. А хотите ходить не более чем с 10 нод одновременно.
Метаинформация
Вам надо хранить метаинформацию о каких-то ваших объектах. Чтобы она была доступна другим инстансам вашего сервиса. Допустим информацию о пачке данных которую вы сейчас обрабатываете. Записи много, чтения много, данных не очень много. Обычные SQL БД такой паттерн нагрузки не любят.
Просто запишите в Зукипер. И используйте в любой админке для показа, управления или любых других действий. Иметь возможность наблюдать за распределенной обработкой это очень хорошая практика. Без наблюдения системы иногда переходят в непонятное состояние, куда бежать смотреть что где происходит непонятно.
Распределенный счетчик
Регулярно бывает нужна самая обычная последовательность интов с автоинкрементом. Сиквенсы из БД по какой-либо причине не подходят. И как обычно есть кучка инстансов вашего сервиса, которые должны быть согласованы.
Например, простой счетчик вызовов внешнего сервиса нужный для мониторинга и отчетов. Графана такие счетчики хорошо рисует на графиках и по ним можно наблюдать за активность использования внешнего сервиса вами. Сиквенс из БД не очень хорошо подходит, а счетчик хочется. Как обычно, просто возьмите Зукипер.
Конфиги
В Зукипере можно хранить ваши конфиги.
Минусы: Конфиги сложно наблюдаемы и нетривиально редактируемы.
Плюсы: Ваше приложение подписывается на изменение и получает новые значения без рестарта. И, как обычно, никакого специального кода для этого писать не нужно.
Получается что в Зукипере есть смысл хранить ту часть конфига которую надо применять в риалтайме без рестарта приложения. Например, настройки рейт лимитера. Может быть их придется крутить в момент максимальной нагрузки когда рестартовать ноды совсем не хочется. Пока кеши прогреются, пока код правильно прогреется. Да и при старте приложение может подтягивать много данных и это может занимать значимое время. Лучше бы без рестартов в момент пиковой нагрузки жить.
Пример подписки на события изменения данных:
Транзакции
При построении конвейера обработки данных хочется иметь возможность обрабатывать данные транзакционно. В идеале exactly once. И как обычно писать сложный код не хочется. Такие вещи сложно отлаживать и поддерживать. Да и баги в них постоянно встречаются.
Как и в других случах Зукипер вам поможет. Просто прочитайте данные, обработайте их, переложите дальше по конвейеру и закомитьте изменение атомарно.
Стоит следить за записываемыми в сторонние БД данными. Если processData() из примера что-то куда-то пишет, то это что-то должно быть удалено даже при откате транзакции Зукипера. Базы с поддержкой TTL зарекомендовали себя лучше всего. Данные удалят сами себя. Если у вас не такая, то нужно придумать как-то другой механизм для очистки неконсистентных данных.
Мониторинг, как обычно, обязателен. По TTL можно случайно удалить нужные данные, стоит это мониторить и избегать такого.
Особенности использования Зукипера
У зукипера есть не только плюсы. Есть и особенности о которых надо знать перед как вводить его в продакшен системы.
Зукипер не риалтайм
Можно прочитать не то что записали. Не прочитать только что записанные данные это абсолютно нормальная ситуация. Системы надо строить с учетом этого.
Если очень надо, то можно попробовать записать в ту же ноду что-то. При провале этого действия мы будем точно знать что нода существует, несмотря на то что она не прочиталась. И можно попробовать снова ее прочитать через небольшое время. Disclamer: Так не стоит делать, это один из рецептов на крайний случай. Когда код уже в проде и надо срочно доделать чтобы работало.
Зукипер не база данных
Зукипер хорошо работает с базой размером в единицы гигабайт. Не надо в нем хранить ваши данные. Храните их в БД, или в S3, или в любом другом предназначенном для хранения данных месте которое вам нравится. А в Зукипер пишите метаинформацию и указатель на ваши данные.
Зукипер не самое лучшее kv хранилище
Зукипер можно использовать в роли kv хранилища. Обычно это горячий кеш.
Но лучше посмотреть в сторону более специализированного софта. Redis/Tarantul удобнее для использования в этой роли и более эффективно утилизируют железо при чистой kv нагрузке.
zxcid
zxcid это внутренний 32 битный счетчик операций Зукипера. Когда он переполняется кластер разваливается на время единиц секунд до десятков минут. Надо быть к этому готовым и мониторить текущее значение zxcid. Хорошее решение будет в версии 3.8.0 https://issues.apache.org/jira/browse/ZOOKEEPER-2789 Ждем, верим, надеемся.
Переходить на новую версию сразу после ее выхода не стоит. Выждите хотя бы квартал.
Забытые данные
В древовидной структуре можно легко насоздавать сотни тысяч и даже миллионы нод в далеком и заброшенном узле дерева. И забыть их удалить. Чтобы этого избегать стоит писать код без багов(шутка) и мониторить размер базы Зукипера и общее число нод в нем. Если эти цифры начали подозрительно расти, то стоит что-то с этим сделать.
Софт изначально стоит проектировать так что любая созданная нода точно удалится.
Никогда неудаляемые ноды (например конфиг) стоит создавать очень аккуратно и ни в коем случае не массово.
Ноды со сложным жизненным циклом стоит покрыть отдельными мониторингами.
Например: одно приложение создает неудаляемую автоматически ноду, а второе ее читает обрабатывает и удаляет потом. Стоит сделать мониторинг на общее количество и на самую старую ноду. Тогда в случае любых проблем вы сразу это увидите.
Типовые удобства 2021 года
Все, как полагается.
WEB-UI чтобы быстренько что-то посмотреть или поправить пару значений есть на любой вкус. Можно выбрать вот отсюда или просто из Гугла по своему вкусу. Мне нравится старенький и похоже что мертвый zk-web, но это дело вкуса. Поставить любой UI очень рекомендую. Они помогают решить множество мелких и регулярных проблем.
Клиенты для всех распространенных языков тут
Национальная библиотека им. Н. Э. Баумана
Bauman National Library
Персональные инструменты
Apache ZooKeeper
Содержание
Описание
Обозначим сначала свойства Zookeeper:
Прежде чем углубляться в работу ZooKeeper, стоит взглянуть на фундаментальные понятия:
Архитектура


Каждый компонент, являющийся частью архитектуры (см. рисунок 1, рисунок 2) ZooKeeper, описывается в таблице:
Иерархическое пространство имен
Следующая диаграмма показывает древовидную структуру файловой системы ZooKeeper, используемую для представления памяти (см. рисунок 3). Узел ZooKeeper называется znode. Каждый znode идентифицируется по имени и разделяется последовательностью пути (/).

Каждый znode в модели данных ZooKeeper содержит структуру stat. Stat просто предоставляет метаданные znode. Состоит из номера версии, список управляющих действий, меток, длины данных.
Сессии
Сессии очень важны для операций над ZooKeeper. Запросы в сессию исполняются в порядке очередности FIFO. Как только клиент подключился к серверу, будет создана сессия и id сессии будет присвоен клиенту.
Клиент посылает «сердцебиения» в конкретный временной интервал для валидности сессии. Если ансамбль ZooKeeper не получает «сердцебиения» от клиента более чем за период (таймаут сессии), определенный в начале обслуживания, это означает, что клиент умер.
Таймауты сессии обычно представляются в миллисекундах. Когда сессия заканчивается по какой либо причине, эфемерные (недолговечные) znodes, созданные во время этой сессии, также удалятся.
Наблюдатели
Для чего же нужен ZooKeeper?
Особенности ZooKeeper
Выгоды использования
Выгоды использования ZooKeeper (см. рисунок 4):

Поддерживаемые операции
Узел дерева ZooKeeper называется znode. В связи с этим ZooKeeper API предоставляет следующие операции:
|
Эти операции можно разделить по следующим группам:
|
Callback — read-only-операции, к которым можно указать callback’и. Callback сработает, когда запрашиваемая сущность изменит ся. Callback сработает не более одного раза. В случае, когда нужно постоянно отслеживать значение, в обработчике события нужно постоянно переподписываться. CAS — write-запросы. Проблема конкурентного доступа в ZooKeeper’е решена через compare-and-swap: с каждым znode хранится его версия, при изменении её нужно указывать. Если znode уже был изменен, то версия не совпадает, и клиент получит соответственное исключение. Операции из этой группы требуют указания версии изменяемого объекта. Create — создает новый znode (пару ключ/значение) и возвращает ключ. Кажется странным, что возвращается ключ, если он указывается как аргумент, но дело в том, что ZooKeeper’у в качестве ключа можно указать префикс и сказать, что znode последовательный, тогда к префиксу добавится выровненное число, и результат будет использоваться в качестве ключа. Гарантируется, что создавая последовательные znode с одним и тем же префиксом, ключи будут образовывать возрастающую (в лексико-графическом смысле) последовательность.
Sync — синхронизует узел кластера, к которому подсоединен клиент, с мастером. Вызываться не должен, так как синхронизация происходит быстро и автоматически.
Система распределенных блокировок
На основе последовательных эфемерных znode и подписках на их удаление можно создать систему распределенных блокировок. Опишем алгоритм блокировки:
1) Создается эфемерный последовательный znode, используя в качестве префикса «_locknode_/guid-lock-«, где _locknode_ — имя ресурса, который блокируют, а guid — свежесгенерированный гуид; 2) Получают список детей _locknode_ без подписки на событие; 3) Если созданный на первом шаге znode в ключе имеет минимальный числовой суффикс, выход из алгоритма — ресурс захвачен; 4) Иначе сортируется список детей по суффиксу и вызывается exists с коллбеком на znode, который в полученном списке находится перед тем, что создан на шаге 1; 5) Если получили false, переход на шаг 2, иначе ждать события и переход на шаг 2.
Так как в случае падения любой операции при работе ZooKeeper пользователь не может узнать, прошла операция или нет, ему нужно выносить эту проверку на уровень приложения. Guid нужен как раз для этого: зная его и запросив детей, пользователь может легко определить, создал ли он новый узел или нет, и операцию стоит повторить. Для вычисления суффикса для последовательного znode используется не уникальная последовательность на префикс, а уникальная последовательность на родителя, в котором будет создан znode. [Источник 5]
Производительность
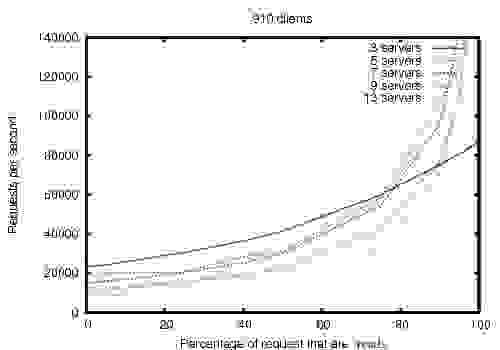
ZooKeeper создан для высокой производительности. Результаты исследований команды разработчиков ZooKeeper в Yahoo! (см. рисунок 5) показывают, что особенно высокую производительность продукт демонстрирует в приложениях, где число операций чтения превышает количество записей, поскольку записи включают синхронизацию состояния всех серверов. (Количество операций чтения превышает количество записей, как правило, для служб координации.) [1]

Показатель пропускной способности ZooKeeper в зависимости от коэффициента чтения-записи рассмотрен для версии 3.2, работающей на серверах с двумя 2 ГГц Xeon и двумя дисками SATA 15K RPM. Один диск использовался в качестве выделенного лог-устройства ZooKeeper. Снимки были записаны на диск ОС. Запросы на запись и на чтение было сделано по 1 тысяче. Примерно 30 других серверов были использованы для моделирования клиентов. Ансамбль ZooKeeper был настроен так, что лидеры не допускают подключения от клиентов. Тесты также показывают, что это тоже надежно. Надежность в присутствии ошибок показывает, как развертывание реагирует на различные сбои. События, отмеченные на рисунке, следующие:
Надежность
Чтобы показать поведение системы с течением времени при возникновении сбоев, был запущен сервис ZooKeeper, состоящий из 7 машин (см. рисунок 6). Выполнялся тот же тест насыщенности, что и раньше, но на этот раз мы сохранили процент записи на постоянном уровне 30%, что является консервативным соотношением наших ожидаемых рабочих нагрузок.

Вот несколько важных наблюдений из этого графика:
Преимущества и недостатки
Порядок установки
ZooKeeper или пишем сервис распределенных блокировок
disclaimer Так получилось, что последний месяц я разбираюсь с ZooKeeper, и у меня возникло желание систематизировать то, что я узнал, собственно пост об этом, а не о сервисе блокировок, как можно было подумать исходя из названия. Поехали!
При переходе от многопоточного программирования к программированию распределенных систем многие стандартные техники перестают работать. Одной из таких техник являются блокировки (synchronized), так как область их действия ограничена одним процессом, следовательно, они не только не работают на разных узлах распределенной системы, но так же не между разными экземплярами приложения на одной машине; получается, что нужен отдельный механизм для блокировок.
Поддерживаемые операции
| exists | проверяет существование znode и возвращает его метаданные |
| create | создает znode |
| delete | удаляет znode |
| getData | получает данные ассоциированные с znode |
| setData | ассоциирует новые данные с znode |
| getChildren | получает детей указанного znode |
| sync | дожидается синхронизации узла кластера, к которому мы подсоединены, и мастера. |
Эти операции можно разделить по следующим группам
| callback | CAS |
| exists | delete |
| getData | setData |
| getChildren | create |
| sync |
Callback — read-only операции, к которым можно указать коллбеки, коллбек сработает, когда запрашиваемая сущность измениться. Коллбек сработает не более одного раза, в случае, когда нужно постоянно мониторить значение, в обработчике события нужно постоянно переподписываться.
CAS — write запросы. Проблема конкурентного доступа в ZooKeeper’е решена через compare-and-swap: с каждым znode храниться его версия, при изменении её нужно указывать, если znode уже был изменен, то версия не совпадает и клиент получит соответственное исключение. Операции из этой группы требуют указания версии изменяемого объекта.
create — создает новый znode (пару ключ/значение) и возвращает ключ. Кажется странным, что возвращается ключ, если он указывается как аргумент, но дело в том, что ZooKeeper’у в качестве ключа можно указать префикс и сказать, что znode последовательный, тогда к префиксу добавиться выровненное число и результат будет использоваться в качестве ключа. Гарантируется, что создавая последовательные znode с одним и тем же префиксом, ключи будут образовывать возрастающую (в лексико-графическом смысле) последовательность.
Помимо последовательных znode, можно создать эфемерные znode, которые будут удалены, как только клиент их создавший отсоединиться (напоминаю, что соединение между кластером и клиентом в ZooKeeper держится открытым долго). Эфемерные znode не могут иметь детей.
Znode может одновременно быть и эфемерным, и последовательным.
sync — синхронизует узел кластера, к которому подсоединен клиент, с мастером. По хорошему не должен вызываться, так как синхронизация происходит быстро и автоматически. О том, когда её вызывать, будет написано ниже.
На основе последовательных эфемерных znode и подписках на их удаление можно без проблем создать систему распределенных блокировок.
Система распределенных блокировок
На самом деле все придумано до нас — идем на сайт ZooKeeper в раздел рецептов и ищем там алгоритм блокировки:
Для проверки усвоения материала попробуйте понять самостоятельно, по убыванию или по возрастанию нужно сортировать список в шаге 4.
Так как, в случае падения любой операции при работе ZooKeeper мы не можем узнать прошла операция или нет, нам нужно выносить эту проверку на уровень приложения. Guid нужен как раз для этого: зная его и запросив детей, мы можем легко определить создали мы новый узел или нет и операцию стоит повторить.
Кстати я не говорил, но думаю вы уже догадались, что для вычисления суффикса для последовательного znode используется не уникальная последовательность на префикс, а уникальная последовательность на родителя, в котором будет создан znode.
В теории можно было бы и закончить, но как показала практика, начинается самое интересное — wtf‘ки. Под wtf‘ами я имею ввиду расхождение моих интуитивных представлений о системе с её реальном поведением, внимание, wtf не несет оценочного суждения, кроме того я прекрасно понимаю, почему создатели ZooKeeper’а пошли на такие архитектурные решения.
WTF #1 — выворачиваем код на изнанку
Любой метод API может кинуть checked exception и обязать вас его обработать. Это не привычно, но правильно, так как первое правило распределенных систем — сеть не надежна. Одно из исключений, которое может полететь — пропажа соединения (моргание сети). Не стоит путать пропажу соединения с узлом кластера (CONNECTIONLOSS), при который клиент сам его восстановит с сохраненной сессией и коллбеками (подключится к другому или будет ждать), и принудительное закрытие соединения со стороны кластера и потерей всех коллбеков (SESSIONEXPIRED), в данном случае задача по восстановлению контекста ложится на плечи программиста. Но мы отошли от темы…
Как обрабатывать подмигивания? На самом деле при открытии соединения с кластером мы указываем коллбек, который вызывается многократно, а не только раз, как остальные, и который доставляет события о потери соединения и его восстановлении. Получается при потери соединения нужно приостановить вычисления и продолжить их, когда придет нужное событие.
Вам это ничего не напоминает? C одной стороны — события, с другой — необходимость «играть» с потоком выполнения программы, по-моему где-то рядом continuation и монады.
В общем, я оформил шаги программы в виде:
Добавив нужные комбинаторы можно строить следующие программы, где-то используя идемпотентность шагов, где-то явно подчищая мусор:

WTF #2 — сервер главный
Можно сказать, что в ZooKeeper сервер (кластер) является главным, а у клиентов практически нет прав. Иногда это доходит до абсолюта, например… В конфигурации ZooKeeper есть такой параметр как session timeout, он определяет на сколько максимум может пропадать связь между кластером и клиентом, если максимум превышен, то сессия этого клиента будет закрыта и все эфемерные znode этого клиента удаляться; если связь все-таки восстановиться — клиент получит событие SESSIONEXPIRED. Так вот, клиент при пропажи соединения (CONNECTIONLOSS) и превышении session timeout тупо ждет и нечего не делает, хотя, по идеи он мог догадаться о том, что сессия сдохла и сам своим обработчикам кинуть SESSIONEXPIRED.
Из-за такого поведения разработчик в какие-то моменты рвать на себе волосы, допустим вы подняли сервер ZooKeeper и пытаетесь к нему подключиться, но ошиблись в конфиге и стучитесь не по тому адресу, или не по тому порту, тогда, согласно описанному выше поведению, вы просто будете ждать, когда клиент перейдет в состояние CONNECTED и не получите никакого сообщения об ошибке, как это было бы в случае с MySQL или чем-нибудь подобным.
WTF #3 — переполняется int
Допустим вы реализовали блокировки согласно описанному выше алгоритме и запустили это дело в highload продакшен, где, допустим вы берете 10MM блокировок в день. Где-то через год вы обнаружите, что попали в ад — блокировки перестанут работать. Дело в том, что через год у znode _locknode_ счетчик cversion переполниться и нарушиться принцип монотонно возрастающей последовательности имен последовательных znode, а на этом принципе основана наша реализация блокировок.
Что делать? Нужно периодически удалять/создавать заново _locknode_ — при этом счетчик ассоциированный с ним сброситься и принцип монотонной последовательности снова нарушится, но дело в том, что znode можно удалить только когда у него нет детей, а теперь сами догадайтесь, почему сброс cversion у _locknode_, когда в нем нет детей не влияет на алгоритм блокировки.
WTF #4 — quorum write, но не read
Когда ZooKeeper вернул ОК на запрос записи это означает что данные записались на кворум (большинство машин в кластере, в случае 3х машин, кворум состоит из 2х), но при чтении пользователь получает данные с той машины, к которой он подключился. То есть возможна ситуация, когда пользователь получает старые данные.
В случае, когда клиенты не общаются иначе как только через ZooKeeper это не составляет проблемы, так как все операции в ZooKeeper строго упорядочены и тогда нет возможности узнать о том, что событие произошло кроме, как дождаться его. Догадайтесь сами, почему из того следует, что все хорошо. На самом деле, клиент может знать, что данные обновились, даже если никто ему не сказал — в случае, когда он сам произвел изменения, но ZooKeeper поддерживает read your writes consistency, так что и это не проблема.
Но все-же, если один клиент узнал об изменении части данных через канал связи все ZooKeeper, ему может помочь принудительная синхронизация — именно для этого нужна команда sync.
Производительность
Большинство распределенных key/value хранилищ используют распределенность для хранения большого объема данных. Как я уже писал, данные которые хранит в себе ZooKeeper не должны превышать размер оперативной памяти, спрашивается, зачем ему распределенность — она используется для обеспечения надежности. Вспоминая про необходимость набрать кворум на запись, не удивительно падение производительности на 15% при использовании кластера из трех машин, по сравнению с одной машиной.
Другая особенность ZooKeeper состоит в том, что он обеспечивает персистентность — за неё тоже нужно так как во время обработки запроса включено время записи на диск.
Тестировал я на локальном ноуте, да-да это сильно напоминает:
 DevOps Borat | Big Data Analytic is show 90% of devops which are use word ‘benchmark’ in sentence are also use word ‘laptop’ in same sentence. |
но очевидно, что ZooKeeper лучше всего себя показывает в в конфигурации из одной ноды, с быстрым диском и на небольшом кол-ве данных, поэтому мой X220 c SSD и i7 идеально для этого подходил. Тестировал я преимущественно запросы на запись.
Потолок по производительности был где-то около 10K операций в секунду при интенсивной записи, на запись уходит от 1ms, следовательно, с точки зрения одного клиента, сервер может работать не быстрее 1K операций в секунду.
Что это значит? В условиях, когда мы не упираемся в диск (утилизация ssd на уровне 10%, для верности попробовал так же разместить данные в памяти через ramfs — получил небольшой прирост в производительности), мы упираемся в cpu. Итого, у меня получилось, что ZooKeeper всего в 2 раза медленнее, чем те числа, которые указали на сайте его создатели, что не плохо, если учесть, что они знают, как из него выжать все.
Резюме
Не смотря на все, что я здесь написал, ZooKeeper не так плох, как может показаться. Мне нравится его лаконичность (всего 7 команд), мне нравиться то, как он подталкивает и направляет своим API программиста к правильному подходу при разработке распределенных систем, а именно, в любой момент все может упасть, потому каждая операция должна оставлять систему в консистентном состоянии. Но это мои впечатления, они не так важны, как то, что ZooKeeeper хорошо решает задачи, для которых он был создан, среди которых: хранение конфигов кластера, мониторинг состояние кластера (кол-во подключенных нод, статус нод), синхронизация нод (блокировки, барьеры) и коммуникация узлов распределенной системы (a-la jabber).
О распределенных блокировках
Возвращаясь к алгоритму блокировки, описанному выше, могу сказать, что он не работает, точнее работает ровно до тех пор, пока действия внутри критической секции происходят над тем же и только тем же кластером ZooKeeper, что используется для блокировки. Почему так? — Попробуйте догадаться сами. А в следующей статье я напишу как сделать распределенные блокировки более честными и расширить класс операций внутри критической секции на любое key/value хранилище с поддержкой CAS.



