Директивы Disallow и Allow: как использовать совместно и раздельно
В данной статье речь пойдет о самых популярных директивах Dissalow и Allow в файле robots.txt.
Disallow
Disallow – директива, запрещающая индексирование отдельных страниц, групп страниц, их отдельных файлов и разделов сайта(папок). Это наиболее часто используемая директива, которая исключает из индекса:
Примеры директивы Disallow в robots.txt:
Правило Disallow работает с масками, позволяющими проводить операции с группами файлов или папок.
После данной директивы необходимо ставить пробел, а в конце строки пробел недопустим. В одной строке с Disallow через пробел можно написать комментарий после символа “#”.
Allow
В отличие от Disallow, данное указание разрешает индексацию определенных страниц, разделов или файлов сайта. У директивы Allow схожий синтаксис, что и у Disallow.
Хотя окончательное решение о посещении вашего сайта роботами принимает поисковая система, данное правило дополнительно призывает их это делать.
Примеры Allow в robots.txt:
Для директивы применяются аналогичные правила, что и для Disallow.
Совместная интерпретация директив
Поисковые системы используют Allow и Disallow из одного User-agent блока последовательно, сортируя их по длине префикса URL, начиная от меньшего к большему. Если для конкретной страницы веб-сайта подходит применение нескольких правил, поисковый бот выбирает последний из списка. Поэтому порядок написания директив в robots никак не сказывается на их использовании роботами.
На заметку. Если директивы имеют одинаковую длину префиксов и при этом конфликтуют между собой, то предпочтительнее будет Allow.
Пример robots.txt написанный оптимизатором:
Пример отсортированного файл robots.txt поисковой системой:
Пустые Allow и Disallow
Когда в директивах отсутствуют какие-либо параметры, поисковый бот интерпретирует их так:
Специальные символы в директивах
В параметрах запрещающей директивы Disallow и разрешающей директивы Allow можно применять специальные символы “$” и “*”, чтобы задать конкретные регулярные выражения.
Специальный символ “*” разрешает индексировать все страницы с параметром, указанным в директиве. К примеру, параметр /katalog* значит, что для ботов открыты страницы /katalog, /katalog-tovarov, /katalog-1 и прочие. Спецсимвол означает все возможные последовательности символов, даже пустые.
Примеры:
По стандарту в конце любой инструкции, описанной в Robots, указывается специальный символ “*”, но делать это не обязательно.
Пример:
Для отмены данного спецсимвола в конце директивы применяют другой спецсимвол – “$”.
Пример:
На заметку. Символ “$” не запрещает прописанный в конце “*”.
Пример:
Более сложные примеры:
Примеры совместного применения Allow и Disallow
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Как составить правильный robots.txt для Яндекса и Google [инструкция]
Примеры готового файла robots.txt. Решения для сайтов на WordPress, Битрикс, OpenCart и Joomla.
Вебмастер может направить поисковых ботов на страницы, которые считает обязательными для индексирования, и скрыть те, которых в выдаче быть не должно. Для этого предназначен файл robots.txt. Команда сервиса для анализа сайта PR-CY составила гайд об этом файле: для чего он нужен, из каких команд состоит, как составить его по правилам и проверить.
Зачем нужен robots.txt
С помощью этого файла можно повлиять на поведение ботов Яндекса и Google. Файл robots.txt содержит указания для краулеров, предназначенных для индексирования сайта. Он состоит из списка команд, которые рекомендуют либо просканировать, либо пропустить конкретные страницы или целые разделы сайта. Если боты «прислушаются» к этим пожеланиям, то не будут посещать закрытые страницы или индексировать определенный тип контента.
Закрывают обычно дублирующие страницы, служебные, неинформативные, страницы с GET-параметрами или просто неважные для пользователей.
Как надежно закрыть страницу от ботов
Поисковики не воспринимают robots.txt как список жестких правил, это только рекомендации. Даже если в robots стоит запрет, страница может появиться в выдаче, если на нее ведет внешняя или внутренняя ссылка.
Страница, доступ к которой запретили только в robots.txt, может попасть в выдачу и будет выглядеть так:
 Главная страница сайта в выдаче, но описание бот составить не смог
Главная страница сайта в выдаче, но описание бот составить не смог
Если вы точно не хотите, чтобы страница попала в индекс, недостаточно запретить сканирование в файле robots.txt. Один из вариантов, подходящий для служебных страниц, — запаролить ее. Бот не сможет просканировать содержимое страницы, если она доступна только пользователям, авторизованным через логин и пароль.
Если страницы нельзя закрыть паролем, но не хочется показывать их ботам, есть вариант применить директивы «noindex» и «nofollow». Для этого нужно добавить их в секцию HTML-кода страницы:
Чтобы робот правильно интерпретировал «noindex» и «nofollow» и не добавил страницу в индекс, не закрывайте одновременно доступ к ней в файле robots.txt. Так бот не получит доступа к странице и не увидит запрещающих директив.
Требования поисковых систем к файлу robots.txt
Каким должен быть файл, как его оформить и куда размещать — в этом и Яндекс, и Google солидарны:
Подробные рекомендации для robots.txt от Яндекса читайте здесь, от Google — здесь.
Дальше рассмотрим, каким образом можно давать рекомендации ботам.
Как правильно составить robots.txt
Файл состоит из списка команд (директив) с указанием страниц, на которые они распространяются, и адресатов — имён ботов, к которым команды относятся.
Директиву Clean-param воспринимают только боты Яндекса, а в остальном в 2021 году команды для ботов Google и Яндекса одинаковы.
Основные обозначения файла
User-agent — какой бот должен прореагировать на команду. После двоеточия указывают либо конкретного бота, либо обобщают всех с помощью символа *.
Пример. User-agent: * — все существующие роботы, User-agent: Googlebot — только бот Google.
Disallow — запрет сканирования. После косого слэша указывают, на что распространяется команда запрета.
Пустое поле в Disallow означает разрешение на сканирование всего сайта:
А эта запись запрещает всем роботом сканировать весь сайт:
Если речь идет о новом сайте, проследите, чтобы в файле robots.txt не осталась эта запись, после того как разработчики выложат сайт на рабочий домен.
Эта запись разрешает сканирование боту Google, а всем остальным запрещает:
Отдельно прописывать разрешения необязательно. Доступным считается всё, что вы не закрыли.
В записях важен закрывающий косой слэш, его наличие или отсутствие меняет смысл:
Disallow: /about/ — запись закрывает раздел «О нас», доступный по ссылке https://example.com/about/
Disallow: /about — закрывает все ссылки, которые начинаются с «/about», включая раздел https://example.com/about/, страницу https://example.com/about/company/ и другие.
Каждому запрету соответствует своя строка, нельзя перечислить несколько правил сразу. Вот неправильный вариант записи:
Правильно оформить их раздельно, каждый с новой строки и своим Disallow:
Allow означает разрешение сканирования, с помощью этой команды удобно прописывать исключения. Для примера запись запрещает всем ботам сканировать весь альбом, но делает исключение для одного фото:
А вот и отдельная команда для Яндекса — Clean-param. Директиву используют, чтобы исключить дубли страниц, которые могут появляться из-за GET-параметров или UTM-меток. Clean-param распознают только боты Яндекса. Вместо нее можно использовать Disallow, эту команду понимают в том числе и гуглоботы.
Допустим, на сайте есть страница page=1 и у нее могут быть такие параметры:
Каждый образовавшийся адрес в индексе не нужен, достаточно, чтобы там была общая основная страница. В этом случае в robots нужно задать Clean-param и указать, что ссылки с дополнениями после «sid» в страницах на «/index.php» индексировать не нужно:
Clean-param: sid /index.php
Если параметров несколько, перечислите их через амперсанд:
Clean-param: sid&utm&ref /index.php
Строки не должны быть длиннее 500 символов. Такие длинные строки — редкость, но из-за перечисления параметров такое может случиться. Если указание получилось сложным и длинным, его можно разделить на несколько. Примеры найдете в Справке Яндекса.
Sitemap — ссылка на карту сайта. Если карты сайта нет, запись не нужна. Сама по себе карта не обязательна, но если сайт большой, то лучше ее создать и дать ссылку в robots, чтобы ботам было проще разобраться в структуре.
Обозначим также два важных спецсимвола, которые используются в robots:
* — предполагает любую последовательность символов после этого знака;
$ — указывает на то, что на этом элементе необходимо остановиться.
Пример. Такая запись:
запрещает роботу индексировать страницу site.com/catalog/category1, но не запрещает индексировать страницу site.com/catalog/category1/product1.
Лучше не заниматься сбором команд вручную, для этого есть сервисы, которые работают онлайн и бесплатно. Инструмент для генерации robots.txt бесплатно соберет нужные команды: открыть или закрыть сайт для ботов, указать путь к sitemap, настроить ограничение на посещение избранных страниц, установить задержку посещений.
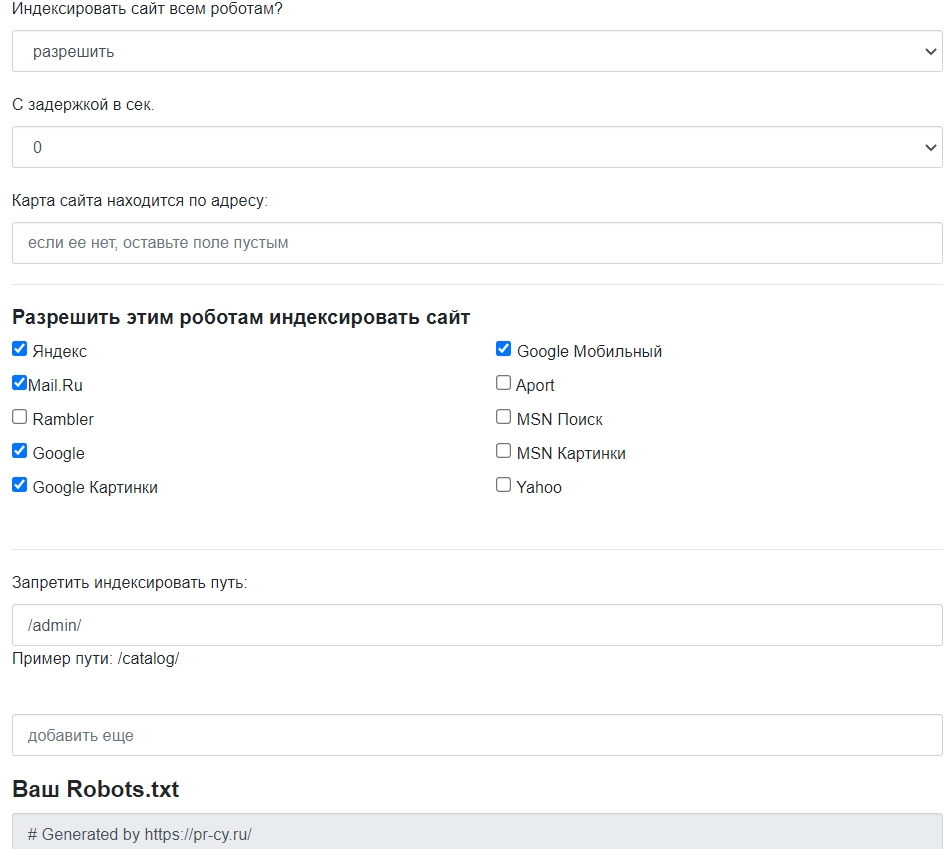 Настройки файла в инструменте
Настройки файла в инструменте
Есть и другие бесплатные генераторы файла, которые позволят быстро создать robots и избежать ошибок. У популярных движков есть плагины, с ними собирать файл еще проще. О них расскажем ниже.
Как проверить правильность robots.txt
После создания файла и добавления в корневой каталог будет не лишним проверить, видят ли его боты и нет ли ошибок в записи. У поисковых систем есть свои инструменты:
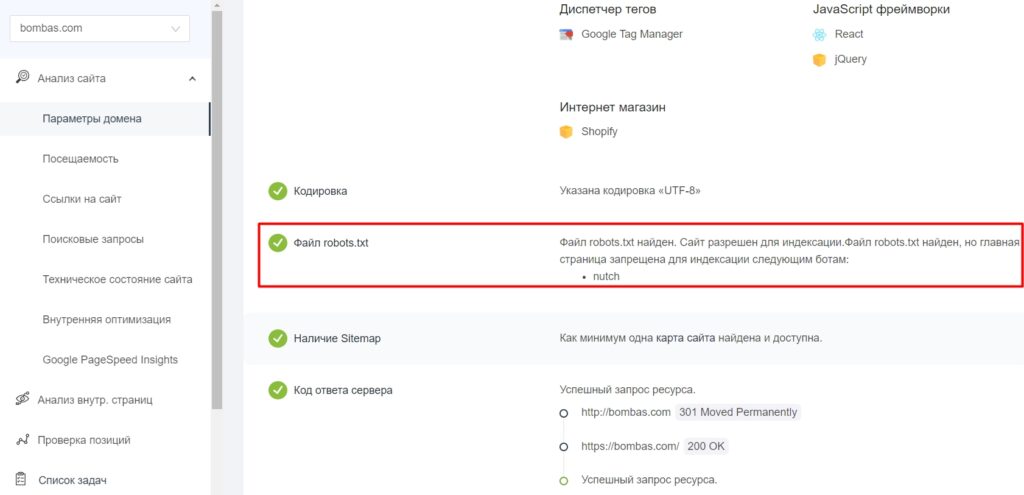 Фрагмент проверки сайта сервисом pr-cy.ru/analysis
Фрагмент проверки сайта сервисом pr-cy.ru/analysis
В «Важных событиях» отобразятся даты изменения файла.
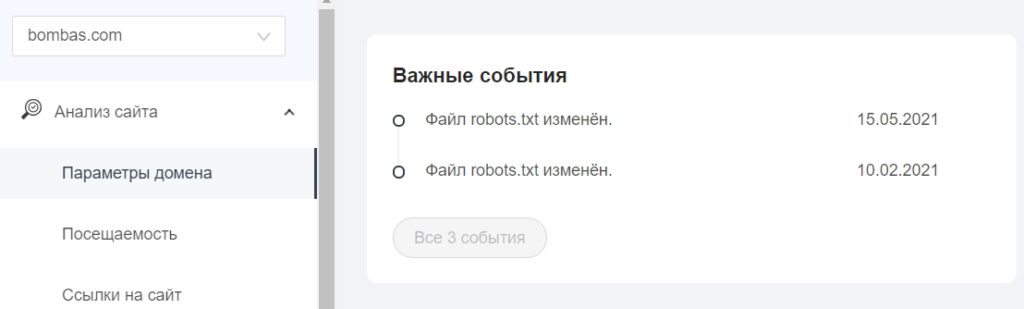 Оповещения в интерфейсе
Оповещения в интерфейсе
Правильный robots.txt для разных CMS: примеры готового файла
Файл robots.txt находится в корневой папке сайта. Чтобы создать или редактировать его, нужно подключиться к сайту по FTP-доступу. Некоторые системы управления (например, Битрикс) предоставляют возможность редактировать файл в административной панели.
Посмотрим, какие возможности для редактирования файла есть в популярных CMS.
WordPress
У WP много бесплатных плагинов, которые формируют robots.txt. Эта опция предусмотрена в составе общих SEO-плагинов Yoast SEO и All in One SEO, но есть и отдельные, которые отвечают за создание и редактирование файла, например:
Пример robots.txt для контентного проекта на WordPress
Это вариант файла для блогов и других проектов без функции личного кабинета и корзины.
User-agent: * # установили общие правила для роботов
Disallow: /cgi-bin # закрыли системную папку, которая находится на хостинге
Disallow: /? # обобщили все параметры запроса на главной странице сайта
Disallow: /wp— # все специальные WordPress-файлы: /wp-json/, /wp-content/plugins, /wp-includes
Disallow: *?s= # здесь и далее перечисление запросов поиска
Disallow: */trackback # закрыли трекбеки — уведомления о появлении ссылки на статью
Disallow: */feed # новостные ленты полностью
Disallow: */rss # rss-ленты
Disallow: */embed # все встраивания
Disallow: /xmlrpc.php # файл API WP
Disallow: *utm*= # все ссылки, у которых прописаны UTM-метки
Disallow: *openstat= # все ссылки, у которых прописаны openstat-метки
Allow: */uploads # открыли доступ к папке с файлами uploads
Allow: /*/*.js # открыли доступ к js-скриптам внутри /wp-, уточнили /*/ для приоритета
Allow: /*/*.css # доступ к css-файлам внутри /wp-, также уточнили /*/ для приоритета
Allow: /wp-*.png # доступ к картинкам в плагинах, папке cache и других в формате png
Allow: /wp-*.jpg # то же самое для формата jpg
Allow: /wp-*.jpeg # для формата jpeg
Allow: /wp-*.gif # и для анимаций в gif
Allow: /wp-admin/admin-ajax.php # открыли доступ к этому файлу, чтобы не блокировать JS и CSS для плагинов
Sitemap: https://example.com/sitemap.xml # указали ссылку на карту сайта (вместо https://example.com нужно подставить сой домен)
Пример robots.txt для интернет-магазина на WordPress
Похожий файл, но со спецификой интернет-магазина на платформе WooCommerce на базе WordPress. Закрываем то же самое, что в предыдущем примере, плюс страницу корзины, а также отдельные страницы добавления в корзину и оформления заказа пользователем.
Продвинутое использование robots.txt без ошибок — руководство для SEO
1 сентября 2019 года Google прекратит поддержку нескольких директив в robots.txt. В список попали: noindex, crawl-delay и nofollow. Вместо них рекомендуется использовать:
404 и 410 коды ответа сервера. В ряде случаев, 410 отрабатывает значительно быстрей для удаления URL из индекса.
Защита паролем. Страницы, требующие авторизации, также обычно удаляются из индекса (важно — именно страницы, полностью скрытые под логином, а не часть контента).
Временное удаление страницы из индекса с помощью инструмента в Search Console.
Disallow в robots.txt.
Тем не менее, robots.txt по-прежнему остаётся одним из главных файлов для SEO-специалиста. Давайте вспомним самые полезные директивы от простых, до менее очевидных.
robots.txt
Это простой текстовый файл, который содержит инструкции для поисковых краулеров — какие страницы сайта не следует посещать, где лежит наш Sitemap.xml и для каких поисковых роботов распространяются правила.
Файл размещается в корневой директории сайта. Например:
Прежде чем начать сканирование сайта, краулеры проверяют наличие robots.txt и находят правила специфичные для их User-Agent, например Googlebot. Если таких нет — следуют общим инструкциям.
Действующие правила robots.txt
User-Agent
У каждой поисковой системы есть свои «агенты пользователя». По сути, это имя краулера, которое помогает дать определённые указания конкретному ему.
Если брать шире, то User-Agent — клиентское приложение на стороне поисковой системы, в некотором смысле имитирующее браузер или, например, мобильное устройство.
User-agent: * — символ астериск используются для обозначения сразу же всех краулеров.
User-agent: Yandex — основной краулер Яндекс-поиска.
User-agent: Google-Image — робот поиска Google по картинкам.
User-agent: AhrefsBot — краулер сервиса Ahrefs.
Важно: если в файле указаны правила для конкретных User-Agent, то роботы будут следовать только своим инструкциям, игнорируя общие правила.
Disallow
Директива, которая позволяет блокировать от индексации полностью весь сайт или определённые разделы.
Может быть полезно для закрытия от сканирования служебных, динамических или временных страниц (символ # отвечает за комментарии в коде и игнорируется краулерами).
Упростить инструкции помогают операторы:
* — любая последовательность символов в URL. По умолчанию к концу каждого правила, описанного в файле robots.txt, приписывается спецсимвол *.
$ — символ в конце URL-адреса, он используется чтобы отменить использование * на конце правила.
Важно: в robots.txt не нужно закрывать JS и CSS-файлы, они понадобятся поисковым роботом для правильного отображения (рендеринга) контента.
Allow
С помощью этой директивы можно, напротив, разрешить каталог или конкретный адрес к индексации. В некоторых случаях проще запретить к сканированию весь сайт и с помощью Allow открыть нужные разделы.
Также Allow можно использовать для отдельных User-Agent.
Crawl-delay
Директива, теряющая актуальность в случае Goolge, но полезная для работы с другими поисковиками.
Позволяет замедлить сканирование, если сервер бывает перегружен. Устанавливает интервал времени для обхода страниц в секундах (для Яндекса). Чем выше значение, тем медленнее краулер ходит по сайту.
Несмотря на то, что Googlebot игнорирует подобные правила, настроить скорость сканирования можно в Google Search Console проекта.
Интересно, что китайский Baidu также не обращает внимание на Crawl-delay в robots.txt, а Bing воспринимает команду как «временное окно», в рамках которого BingBot будет сканировать сайт только один раз.
Важно: если установлено высокое значение Crawl-delay, убедитесь, что ваш сайт своевременно индексируется. В сутках 86 400 секунд, при Crawl-delay: 30 будет просканировано не более 2880 страниц в день, что мало для крупных сайтов.
Sitemap
Одно из ключевых применений robots.txt в SEO — указание на расположение карты сайты. Обратите внимание, используется полный URL-адрес (их может быть несколько).
Нужно иметь в виду:
Директива Sitemap указывается с заглавной S.
Sitemap не зависит от инструкций User-Agent.
Нельзя использовать относительный адрес карты сайта, только полный URL.
Файл XML-карты сайта должен располагаться на том же домене.
Также убедитесь, что ссылка возвращает статус 200 OK без редиректов. Проверить можно с помощью инструмента, определяющего ответ сервера или анализа XML-карты сайта.
Типичный robots.txt
Ниже представлены простые и распространенные шаблоны команд для поисковых роботов.
Разрешить полный доступ
Обратите внимание, правило для Disallow в этом случае не заполняется.
Полная блокировка доступа к хосту
Запрет конкретного раздела сайта
Запрет сканирования определенного файла
Распространенная ошибка
Установка индивидуальных правил для User-Agent без дублирования инструкций Disallow.
Как мы уже выяснили, при указании директивы User-Agent, соответствующий краулер будет следовать только тем правилам, что установлены именно для него. Не забывайте дублировать общие директивы для всех User-Agent.
В примере ниже — слегка измененный robots.txt сайта IMDB. Общие правила Disallow не будут распространяться на бот ScoutJet. А вот Crawl-delay, напротив, установлена только для него.
Противоречия директив
Список распространенных User-Agent
| User-Agent | # |
|---|---|
| Googlebot | Основной краулер Google |
| Googlebot-Image | Робот поиска по картинкам |
| Bing | |
| Bingbot | Основной краулер Bing |
| MSNBot | Старый, но всё ещё использующийся краулер Bing |
| MSNBot-Media | Краулер Bing для изображений |
| BingPreview | Отдельный краулер Bing для Snapshot-изображений |
| Яндекс | |
| YandexBot | Основной индексирующий бот Яндекса |
| YandexImages | Бот Яндеса для поиска по изображениям |
| Baidu | |
| Baiduspider | Главный поисковый робот Baidu |
| Baiduspider-image | Бот Baidu для картинок |
| Applebot | Краулер для Apple. Используется для Siri поиска и Spotlight |
| SEO-инструменты | |
| AhrefsBot | Краулер сервиса Ahrefs |
| MJ12Bot | Краулер сервиса Majestic |
| rogerbot | Краулер сервиса MOZ |
| PixelTools | Краулер «Пиксель Тулс» |
| Другое | |
| DuckDuckBot | Бот поисковой системы DuckDuckGo |
Советы по использованию операторов
1. Заблокировать определённые типы файлов.
Этот приём активно используется, если у проекта настроено ЧПУ для всех страниц и документы с GET-параметрами точно являются дублями.
Заблокировать результаты поиска, но не саму страницу поиска.
Имеет ли значение регистр?
Определённо да. При указании правил Disallow / Allow, URL адреса могут быть относительными, но обязаны сохранять регистр.
Но сами директивы могут объявляться как с заглавной, так и с прописной: Disallow: или disallow: — без разницы. Исключение — Sitemap: всегда указывается с заглавной.
Как проверить robots.txt?
Есть множество сервисов проверки корректности файлов robots.txt, но, пожалуй, самые надёжные: Google Search Console и Яндекс.Вебмастер.
Для мониторинга изменений, как всегда, незаменим «Модуль ведения проектов»:
Контроль индексации на вкладке «Аудит» — динамика сканирования страниц сайта в Яндексе и Google.
Правила написания robots.txt — управляем индексацией сайта
Быстрая навигация по этой странице:
Современная реальность такова, что в Рунете ни один уважающий себя сайт не может обходиться без файла под названием роботс.тхт — даже если вам нечего запрещать от индексации (хотя практически на каждом сайте есть технические страницы и дублирующий контент, требующие закрытия от индексации), то как минимум прописать директиву с www и без www для Яндекса однозначно стоит — для этого и служат правила написания robots.txt, о которых пойдет речь ниже.

Что такое robots.txt?
Свою историю файл с таким названием берет с 1994 года, когда консорциум W3C решил ввести такой стандарт для того, чтобы сайты могли снабжать поисковые системы инструкциями по индексации.
Файл с таким названием должен быть сохранен в корневой директории сайта, размещение его в каких-либо других папках не допускается.
Файл выполняет следующие функции:
Все четыре пункта являются крайне важными для поисковой оптимизации сайта. Запрет на индексацию позволяет закрыть от индексации страницы, которые содержат дублирующий контент — например, страницы тегов, архивов, результаты поиска, страницы с версиями для печати и так далее. Наличие дублирующего контента (когда один и тот же текст, пусть и в размере нескольких предложений, присутствует на двух и более страницах) — это минус для сайта в ранжировании поисковиков, потому дублей должно быть как можно меньше.
Директива allow самостоятельного значения не имеет, так как по умолчанию все страницы и так доступны для индексации. Она работает в связке с disallow — когда, например, какая-то рубрика полностью закрыта от поисковиков, но вы хотели бы открыть в ней ту или отдельно взятную страницу.
Указание на главное зеркало сайта также является одним из самых важных элементов в оптимизации: поисковики рассматривают сайты www.вашсайт.ру и вашсайт.ру как два разных ресурса, если вы им прямо не укажете иное. В результате происходит удвоение контента — появление дублей, уменьшение силы внешних ссылок (внешние ссылки могут ставиться как с www, так и без www) и в результате это может привести к более низкому ранжированию в поисковой выдаче.
Для Google главное зеркало прописывается в инструментах Вебмастера (http://www.google.ru/webmasters/), а вот для Яндекса данные инструкции можно прописать только в том самом роботс.тхт.
Указание на xml-файл с картой сайта (например — sitemap.xml) позволяет поисковикам обнаружить данный файл.
Правила указания User-agent
User-agent в данном случае — это поисковая система. При написании инструкций необходимо указать, будут ли они действовать на все поисковики (тогда проставляется знак звездочки — *) или же они рассчитаны на какой-то отдельный поисковик — например, Яндекс или Google.
Для того, чтобы задать User-agent с указанием на всех роботов, напишите в своем файле следующую строку:
Правила указания disallow и allow
Во-первых, следует отметить, что файл robots.txt для его валидности обязательно должен содержать хотя бы одну директиву disallow. Теперь рассмотрив применение этих директив на конкретных примерах.
Посредством такого кода вы разрешаете индексацию всех страниц сайта:
А посредством такого кода, напротив, все странички будут закрыты:
Для запрета на индексацию конкретной директории под названием folder укажите:
Для запрета на индексацию конкретной директории под названием folder укажите:
Можно использовать также звездочки для подстановки произвольного названия:
Директива allow, как было указано выше, используется для создания исключений в disallow (иначе она не имеет смысла, так как страницы по умолчанию и так открыты).
Например, запретим к индексации страницы в папке archive, но оставим открытой страничку index.html из этой директории:
Указываем хост и карту сайта
Хост — это главное зеркало сайта (то есть название домена плюс www или название домена без этой приставки). Хост указывается только для робота Яндекса (при этом обязательно должна быть хотя бы одна команда disallow).
Для указания host robots.txt должен содержать следующую запись:
Что касается карты сайта, то в robots.txt sitemap указывается простым прописанием полного пути к соответствующему файлу, с указанием доменного имени:
О том, как сделать карту сайта для WordPress, написано тут.
Пример robots.txt для WordPress
Для wordpress инструкции необходимо указывать таким образом, чтобы закрыть к индексации все технические директории (wp-admin, wp-includes и т.д.), а также дубли страниц, создаваемые тегами, файлами rss, комментариями, поиском.
В качестве примера robots.txt для wordpress можете взять файл с нашего сайта:
Скачать файл robots.txt с нашего сайта можно по этой ссылке.
Если по итогам прочтения этой статьи у вас остались какие-либо вопросы — задавайте в комментариях!



