Клиент-серверный вариант работы
Клиент-серверный вариант работы — один из вариантов работы системы «1С:Предприятие 8». Клиент-серверный вариант работы предназначен для использования в рабочих группах или в масштабе предприятия. Он реализован на основе трехуровневой архитектуры «клиент-сервер».
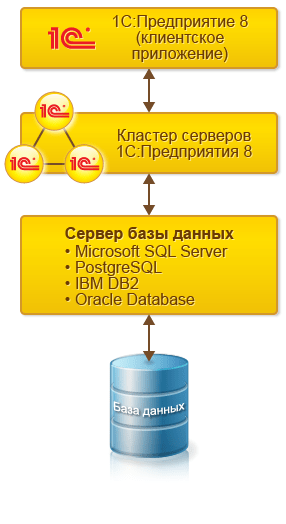
Программа, работающая у пользователя, (клиентское приложение) взаимодействует с кластером серверов «1С:Предприятия 8», а кластер, при необходимости, обращается к серверу баз данных.
При этом физически кластер серверов «1С:Предприятия 8» и сервер баз данных могут располагаться как на одном компьютере, так и на разных. Это позволяет администратору при необходимости распределять нагрузку между серверами.
Использование кластера серверов «1С:Предприятия 8» позволяет сосредоточить на нем выполнение наиболее объемных операций по обработке данных. Например, при выполнении даже весьма сложных запросов программа, работающая у пользователя, будет получать только необходимую ей выборку, а вся промежуточная обработка будет выполняться на сервере. Обычно увеличить мощность кластера серверов гораздо проще, чем обновить весь парк клиентских машин.
Другим важным аспектом использования 3-х уровневой архитектуры является удобство администрирования и упорядочивание доступа пользователей к информационной базе. В этом варианте пользователь не должен знать о физическом расположении конфигурации или базы данных. Весь доступ осуществляется через кластер серверов «1С:Предприятия 8». При обращении к той или иной информационной базе пользователь должен указать только имя кластера и имя информационной базы, а система запрашивает соответственно имя и пароль пользователя.
Развертывание клиент-серверного варианта и его администрирование выполняется довольно просто. Например, создание базы данных производится непосредственно в процессе запуска конфигуратора (так же, как и для файлового варианта).
Клиентские приложения
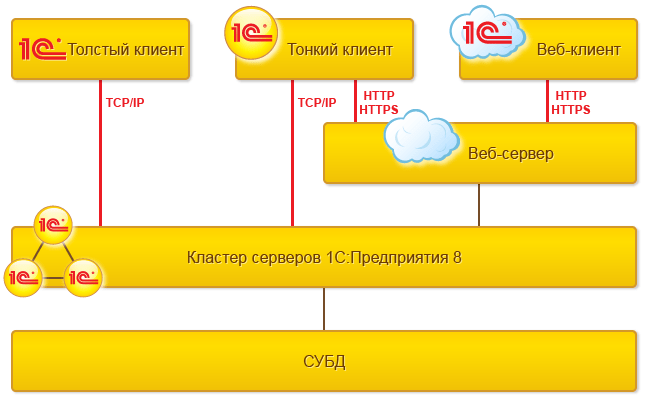
Работа в клиент-серверном варианте возможна как напрямую с кластером, так и через веб-сервер. При этом в случае непосредственного подключения к кластеру толстый клиент и тонкий клиент используют протокол TCP/IP. При подключении через веб-сервер тонкий клиент и веб-клиент используют протокол HTTP или HTTPS.
Кластер серверов
Кластер серверов «1С:Предприятия 8» — основной компонент платформы, обеспечивающий взаимодействие между пользователями и системой управления базами данных в клиент-серверном варианте работы. Наличие кластера позволяет обеспечить бесперебойную, отказоустойчивую, конкурентную работу большого количества пользователей с крупными информационными базами. Подробнее…
Сервер баз данных
Администрирование кластера серверов
В поставку платформы входит набор различных инструментов, позволяющих администратору управлять составом кластера, информационными базами и подключением пользователей. Подробнее…
Выполнение основной функциональности на сервере
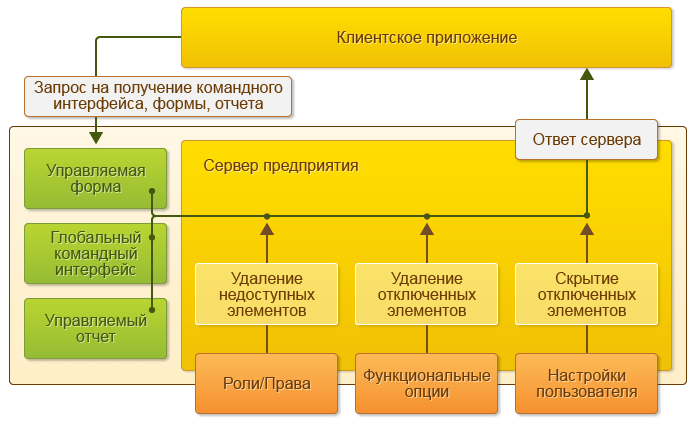
Вся работа с прикладными объектами, чтение и запись базы данных выполняется только на сервере. Функциональность форм и командного интерфейса также реализована на сервере.
На сервере выполняется подготовка данных форм, расположение элементов, запись данных форм после изменения. На клиенте отображается уже подготовленная на сервере форма, выполняется ввод данных и вызовы сервера для записи введенных данных и других необходимых действий.
Аналогично командный интерфейс формируется на сервере и отображается на клиенте. Также и отчеты формируются полностью на сервере и отображаются на клиенте.
При этом механизмы платформы ориентированы на минимизацию объема данных, передаваемых на клиентский компьютер. Например, данные списков, табличных частей и отчетов передаются с сервера не сразу, а по мере просмотра их пользователем.
Использование встроенного языка на клиенте
Управлять функциональностью форм можно не только на сервере, но и на клиенте. На клиенте поддерживается работа встроенного языка. Он используется в тех случаях, когда необходимо провести расчеты, связанные с отображенной на экране формой, например, быстро (без обращения к серверу) подсчитать сумму строки документа на основе цены и количества; задать пользователю вопрос и обработать ответ; прочитать файл из файловой системы компьютера и отправить его на сервер.
Однако работа встроенного языка на клиенте поддерживается в строго ограниченном объеме. Клиентские процедуры в модулях в явном виде отделяются от серверных, и в них используется ограниченный состав объектной модели встроенного языка.

Как видно из названия, главные «действующие лица»:
· клиент – компьютерное устройство, которое отсылает запросы серверу, касающиеся выполнения определенных задач или предоставления конкретной информации.
· сервер – компьютерное устройство, гораздо мощнее обычного ПК.
Система работает по следующему принципу:
1. Клиент отправляет запрос серверной машине.
2. Сервер принимает обращение с требованием выполнить определенное действие и выполняет поставленную задачу.
3. Программно-аппаратный комплекс отправляет клиенту результат выполненной работы, обработанного запроса.
Модель клиент-сервер предоставляет возможность разграничить поставленные задачи и работу над вычислениями между теми, кто заказывает услуги и теми, кто их поставляет.
Основные компоненты системы:
· клиент. Рабочая станция считается входной точкой конечного пользователя в данной системе. Отправляет запросы, получает ответы;
· сервер. Взаимодействует с многочисленными клиентами и решает поставленные ими задачи;
· сеть. Здесь происходит передача данных. Посредством сети можно соединить рабочие машины общими ресурсами;
· приложения. Могут обрабатывать информацию, организовывать физическое распределение данных между сервером и клиентом. Программным обеспечением оснащают серверные устройства для сбора данных, работы с ними и хранения. А также ПО устанавливают на компьютерной станции-клиенте.
О технологии клиент-сервер
Серверное устройство поддерживает многопользовательский режим и обеспечивает одновременно работу с несколькими клиентами. Конечно, машина не может решать в прямом смысле слова одновременно несколько поставленных задач, она выстраивает запросы в очередь по мере поступления, обрабатывает обращения и отправляет результаты работы. Запросы можно выстраивать в списке по приоритетности. Чем важнее запрос, тем быстрей его обрабатывают, даже, если он поступил позже.
Рядовые пользователи сети интернет даже не догадываются о том, как их запросы моментально обслуживаются, чтобы они читали новости, книги, тематические статьи, смотрели интересные видео и фильмы, ходили по форумам, «зависали» в социальных сетях, оплачивали счета, общались с друзьями, оформляли заказы на покупку товаров и т.д. Главное, что ответная реакция быстрая.
Именно технология клиент сервер предоставляет возможность реализовать вышеуказанные многочисленные поставленные задачи. Обычно клиент – это браузер конкретного пользователя. А серверами зачастую выступают:
· любые серверы http;
· наборы серверных машин (например, Denwer);
Обмен информацией между клиентом и сервером происходит благодаря сетевым протоколам в интернете. Каждой услуге соответствует определенный протокол, их предостаточно. Запросы, отсылаемые клиентом, классифицируют как http сообщения. Здесь четко указано, какие сведения нужно предоставить, в каком оформлении. Серверное устройство после анализа и обработки запроса, обычно отвечает html документом – дает свой http ответ.
Сообщение от клиента поступает с дополнительными данными, чтобы серверу было понятно, как с ним работать. Ответ машины также отправляется с кодами помимо полезных запрашиваемых данных, чтобы браузер оценил понятливость аппаратно-программного комплекса при обработке его запроса.
Смотря на каком уровне осуществляется взаимосвязь клиента с сервером, отсылаемые сообщения браузером упаковываются по-разному. Как будто они оборачиваются клиентом в несколько слоем обертки. После того, как послание поступило серверной станции, она приступает к разворачиванию всех этих слоев, проводит анализ информации и сбор данных.
Говоря больше о технологии клиент-сервер, следует уточнить, что браузер первый выходит на контакт и делает запрос серверной машине, которая лишь предоставляет услуги в ответ на сообщения и указывает, какие условия нужно при этом соблюдать. Разные компьютерные устройства используют, чтобы установить программное обеспечение клиента и серверного оборудования. Но есть случаи, когда они работали на одном ПК.
Когда на одном сайте одновременно находятся несколько посетителей, к серверу в один момент обращается много клиентов. Однако одномоментное поступление запросов ограничено мощностью и возможностями серверных устройств, а также характером отправляемых сообщений.
Архитектура клиент-сервер
Благодаря архитектуре клиент и сервер определены позиции взаимной связи между компьютерными машинами лишь в целом. Что же касается нюансов взаимодействия, они определены протоколами. Технология вполне прозрачно намекает на разделение в сети рабочих машин: серверы и клиенты. Рабочий контакт всегда инициирован клиентской машиной. Протокол же описывает, по каким правилам этот контакт установлен и действует.
Архитектура взаимодействия между клиентом и сервером подразделяется на два вида:
· двухзвенная. Сторонние ресурсы не задействованы. Одна машина обрабатывает поступившие сообщения. В этом случае сервер должен быть высокопроизводительным. Несмотря на эти жесткие требования, архитектура очень надежная. Первый уровень – клиент отправляет запрос. Второй уровень – сервером принимается сообщение, обрабатывается и отправляется ответ.
· многоуровневая. Речь идет о любой современной архитектуре СУБД. Принципиальное отличие и особенность: запросом клиента занимаются одновременно несколько серверных устройств. Операции перераспределяются, нагрузка на серверную машину снижена и оптимальная. Единственный минус: низкая надежность по сравнению с предыдущим вариантом.
Многоуровневая клиент-серверная архитектура
Обработкой данных занимаются несколько разных серверов. Благодаря такому подходу возможности серверов и клиентов используются более эффективно за счет разделения функций:
К тому же, систему можно точнее разделить на функциональные блоки для выполнения конкретной роли. Для этого между собой взаимодействуют разнообразные серверы приложений. К примеру, реально выделить сервер, необходимый для выполнения всего функционала по управлению персоналом. При этом реально сделать такую настройку, что пользователи смогут пользоваться только его общедоступным функционалом, а детали реализации серверной машины будут недоступны, так как с ней свяжут отдельную базу данных. Подобные системы легко адаптируются под веб, ведь легче организовать доступ пользователей к конкретному функционалу БД посредством html форм, чем ко всей БД.
На веб-технологию очень просто перевести многоуровневую систему. Заменяют клиентскую часть браузером спецтипа или универсального назначения. При этом дополняют веб-сервером и компактными программными модулями сервер приложений. Многоуровневая архитектура также использует менеджеры транзакций. Обмен информацией одновременно происходит между одной серверной машиной приложений и несколькими серверами БД.
· информация защищена и безопасно хранится. Так как серверная машина БД ведет базы данных, можно независимо от программ пользователя обрабатывать информацию в базе;
· повышенная стойкость к сбоям. Сохранена целостность информационных запросов, они доступны другим пользователям, если во время работы клиента случился сбой;
· масштабируемость. Архитектура адаптируется к увеличению количества пользователей. База данных также расширяется в объеме. Однако при этом не поставлена задача менять ПО. Система наращивает аппаратные средства, так происходит подстройка под меняющиеся факторы;
· повышенная защита данных от взлома и опасных атак;
· один пользователь меньше нагружает сеть, поэтому увеличивается ее пропускная способность. Можно удовлетворить запросы большего количества пользователей;
Преимущества и недостатки архитектуры клиент-сервер
Разделен код программы клиентского и серверного приложения. Это главное преимущество архитектуры. Выбрана локальная сеть. Поэтому плюсы следующие:
· к клиентским рабочим станциям выдвигают низкие запросы;
· преимущественно все вычислительные операции выполняются на серверах;
· реально повысить защиту локальной сети.
Но не все так гладко с клиент-серверной архитектурой, есть и недостатки:
· серверные машины стоят в разы дороже, чем клиентские рабочие станции;
· обслуживание серверов доверяют только квалифицированным и профессионально подготовленным специалистам;
· работа клиентских компьютерных устройств остановлена, если в локальной сети «полетело» серверное оборудование.
Важно понимать, что нет четкого разделения оборудования на клиентское и серверное. Просто архитектура к/с дает возможность перераспределить и оптимизировать загруженность и распределить функциональность между этими рабочими станциями.
Android архитектура клиент-серверного приложения
Клиент-серверные приложения являются самыми распространенными и в то же время самыми сложными в разработке. Проблемы возникают на любом этапе, от выбора средств для выполнения запросов до методов кэширования результата. Если вы хотите узнать, как можно грамотно организовать сложную архитектуру, которая обеспечит стабильную работу вашего приложения, прошу под кат.

Конечно, сейчас уже не 2010 год, когда разработчикам приходилось использовать знаменитые паттерны A/B/C или вообще запускать AsyncTask-и и сильно бить в бубен. Появилось большое количество различных библиотек, которые позволяют вам без особых усилий выполнять запросы, в том числе и асинхронно. Эти библиотеки весьма интересны, и нам тоже стоит начать с выбора подходящей. Но для начала давайте немного вспомним, что у нас уже есть.
Раньше в Android единственным доступным средством для выполнения сетевых запросов был клиент Apache, который на самом деле далек от идеала, и не зря сейчас Google усиленно старается избавиться от него в новых приложениях. Позже плодом стараний разработчиков Google стал класс HttpUrlConnection. Он ситуацию исправил не сильно. По-прежнему не хватало возможности выполнять асинхронные запросы, хотя модель HttpUrlConnection + Loaders уже является более-менее работоспособной.
2013 год стал в этом плане весьма эффективным. Появились замечательные библиотеки Volley и Retrofit. Volley — библиотека более общего плана, предназначенная для работы с сетью, в то время как Retrofit специально создана для работы с REST Api. И именно последняя библиотека стала общепризнанным стандартом при разработке клиент-серверных приложений.
У Retrofit, по сравнению с другими средствами, можно выделить несколько основных преимуществ:
1) Крайне удобный и простой интерфейс, который предоставляет полный функционал для выполнения любых запросов;
2) Гибкая настройка — можно использовать любой клиент для выполнения запроса, любую библиотеку для разбора json и т.д.;
3) Отсутствие необходимости самостоятельно выполнять парсинг json-а — эту работу выполняет библиотека Gson (и уже не только Gson);
4) Удобная обработка результата и ошибок;
5) Поддержка Rx, что тоже является немаловажным фактором сегодня.
Если вы еще не знакомы с библиотекой Retrofit, самое время изучить ее. Но я в любом случае сделаю небольшое введение, а заодно мы немного рассмотрим новые возможности версии 2.0.0 (советую также посмотреть презентацию по Retrofit 2.0.0).
В качестве примера я выбрал API для аэропортов за его максимальную простоту. И мы решаем самую банальную задачу — получение списка ближайших аэропортов.
В первую очередь нам нужно подключить все выбранные библиотеки и требуемые зависимости для Retrofit:
Мы будем получать аэропорты в виде списка объектов определенного класса.
Создаем сервис для запросов:
Примечание про Retrofit 2.0.0
Раньше для выполнения синхронных и асинхронных запросов мы должны были писать разные методы. Теперь при попытке создать сервис, который содержит void метод, вы получите ошибку. В Retrofit 2.0.0 интерфейс Call инкапсулирует запросы и позволяет выполнять их синхронно или асинхронно.
Теперь создадим вспомогательные методы:
Отлично! Подготовка завершена, и теперь мы можем выполнить запрос:
Все кажется очень простым. Мы без особых усилий создали нужные классы, и уже можем делать запросы, получать результат и обрабатывать ошибки, и все это буквально за 10 минут. Что же еще нужно?
Однако такой подход является в корне неверным. Что будет, если во время выполнения запроса пользователь повернет устройство или вообще закроет приложение? С уверенностью можно сказать только то, что нужный результат вам не гарантирован, и мы недалеко ушли от первоначальных проблем. Да и запросы в активити и фрагментах никак не добавляют красоты вашему коду. Поэтому пора, наконец, вернуться к основной теме статьи — построение архитектуры клиент-серверного приложения.
В данной ситуации у нас есть несколько вариантов. Можно воспользоваться любой библиотекой, которая обеспечивает грамотную работу с многопоточностью. Здесь идеально подходит фреймворк Rx, тем более что Retrofit его поддерживает. Однако построить архитектуру с Rx или даже просто использовать функциональное реактивное программирование — это нетривиальные задачи. Мы пойдем по более простому пути: воспользуемся средствами, которые предлагает нам Android из коробки. А именно, лоадерами.
Лоадеры появились в версии API 11 и до сих пор остаются очень мощным средством для параллельного выполнения запросов. Конечно, в лоадерах можно делать вообще что угодно, но обычно их используют либо для чтения данных с базы, либо для выполнения сетевых запросов. И самое важное преимущество лоадеров — через класс LoaderManager они связаны с жизненным циклом Activity и Fragment. Это позволяет использовать их без опасения, что данные будут утрачены при закрытии приложения или результат вернется не в тот коллбэк.
Обычно модель работы с лоадерами подразумевает следующие шаги:
1) Выполняем запрос и получаем результат;
2) Каким-то образом кэшируем результат (чаще всего в базе данных);
3) Возвращаем результат в Activity или Fragment.
Примечание
Такая модель хороша тем, что Activity или Fragment не думают, как именно получаются данные. Например, с сервера может вернуться ошибка, но при этом лоадер вернет закэшированные данные.
Давайте реализуем такую модель. Я опускаю подробности того, как реализована работа с базой данных, при необходимости вы можете посмотреть пример на Github (ссылка в конце статьи). Здесь тоже возможно множество вариаций, и я буду рассматривать их по очереди, все их преимущества и недостатки, пока, наконец, не дойду до модели, которую считаю оптимальной.
Примечание
Все лоадеры должны работать с универсальным типом данных, чтобы можно было использовать интерфейс LoaderCallbacks в одной активити или фрагменте для разных типов загружаемых данных. Первым таким типом, который приходит на ум, является Cursor.
Еще одно примечание
Все модели, связанные с лоадерами, имеют небольшой недостаток: для каждого запроса нужен отдельный лоадер. А это значит, что при изменении архитектуры или, например, переходе на другую базу данных, мы столкнемся с большим рефакторингом, что не слишком хорошо. Чтобы максимально обойти эту проблему, я буду использовать базовый класс для всех лоадеров и именно в нем хранить всю возможную общую логику.
Loader + ContentProvider + асинхронные запросы
Предусловия: есть классы для работы с базой данных SQLite через ContentProvider, есть возможность сохранять сущности в эту базу.
В контексте данной модели крайне сложно вынести какую-то общую логику в базовый класс, поэтому в данном случае это всего лишь лоадер, от которого удобно наследоваться для выполнения асинхронных запросов. Его содержание не относится непосредственно к рассматриваемой архитектуре, поэтому он в спойлере. Однако вы также можете использовать его в своих приложениях:
Тогда лоадер для загрузки аэропортов может выглядеть следующим образом:
И теперь мы наконец можем использовать его в UI классах:
Как видно, здесь нет ничего сложного. Это абсолютно стандартная работа с лоадерами. На мой взгляд, лоадеры предоставляют идеальный уровень абстракции. Мы загружаем нужные данные, но без лишних знаний о том, как именно они загружаются.
Эта модель стабильная, достаточно удобная для использования, но все же имеет недостатки:
1) Каждый новый лоадер содержит свою логику для работы с результатом. Этот недостаток можно исправить, и частично мы сделаем это в следующей модели и полностью — в последней.
2) Второй недостаток намного серьезнее: все операции с базой данных выполняются в главном потоке приложения, а это может приводить к различным негативным последствиям, даже до остановки приложения при очень большом количестве сохраняемых данных. Да и в конце концов, мы же используем лоадеры. Давайте делать все асинхронно!
Loader + ContentProvider + синхронные запросы
Спрашивается, зачем мы выполняли запрос асинхронно с помощью Retrofit-а, когда лоадеры и так позволяют нам работать в background? Исправим это.
Эта модель упрощенная, но основное отличие заключается в том, что асинхронность запроса достигается за счет лоадеров, и работа с базой уже происходит не в основном потоке. Наследники базового класса должны лишь вернуть нам объект типа Cursor. Теперь базовый класс может выглядеть следующим образом:
И тогда реализация абстрактного метода может выглядеть следующим образом:
Работа с лоадером в UI у нас никак не изменилась.
По факту, эта модель является модификацией предыдущей, она частично устраняет ее недостатки. Но на мой взгляд, этого все равно недостаточно. Тут можно снова выделить недостатки:
1) В каждом лоадере присутствует индивидуальная логика сохранения данных.
2) Возможна работа только с базой данных SQLite.
И наконец, давайте полностью устраним эти недостатки и получим универсальную и почти идеальную модель!
Loader + любое хранилище данных + синхронные запросы
Перед рассмотрением конкретных моделей я говорил о том, что для лоадеров мы должны использовать единый тип данных. Кроме Cursor ничего на ум не приходит. Так давайте создадим такой тип! Что должно в нем быть? Естественно, он не должен быть generic-типом (иначе мы не сможем использовать коллбэки лоадера для разных типов данных в одной активити / фрагменте), но в то же время он должен быть контейнером для объекта любого типа. И вот здесь я вижу единственное слабое место в этой модели — мы должны использовать тип Object и выполнять unchecked преобразования. Но все же, это не столь существенный минус. Итоговая версия данного типа выглядит следующим образом:
Данный тип может хранить результат выполнения запроса. Если мы хотим что-то делать для конкретного запроса, нужно унаследоваться от этого класса и переопределить / добавить нужные методы. Например, так:
Отлично! Теперь напишем базовый класс для лоадеров:
Этот класс лоадера является конечной целью данной статьи и, на мой взгляд, отличной, работоспособной и расширяемой моделью. Хотите перейти с SQLite, например, на Realm? Не проблема. Рассмотрим это в качестве следующего примера. Классы лоадеров не изменятся, изменится только модель, которую вы бы в любом случае редактировали. Не удалось выполнить запрос? Не проблема, доработайте в наследнике метод apiCall. Хотите очистить базу данных при ошибке? Переопределите onError и работайте — этот метод выполняется в фоновом потоке.
А любой конкретный лоадер можно представить следующим образом (опять-таки, покажу только реализацию абстрактного метода):
Примечание
При неудачно выполненном запросе будет выброшен Exception, и мы попадем в catch-ветку базового лоадера.
В итоге мы получили следующие результаты:
1) Каждый лоадер зависит исключительно от своего запроса (от параметров и результата), но при этом он не знает, что он делает с полученными данными. То есть он будет меняться только при изменении параметров конкретного запроса.
2) Базовый лоадер управляет всей логикой выполнения запросов и работы с результатами.
3) Более того, сами классы модели тоже не имеют понятия о том, как устроена работа с базой данных и прочее. Все это вынесено в отдельные классы / методы. Я этого нигде не указывал явно, но это можно посмотреть в примере на Github — ссылка в конце статьи.
Вместо заключения
Чуть выше я обещал показать еще один пример — переход с SQLite на Realm — и убедиться, что мы действительно не затронем лоадеры. Давайте сделаем это. На самом деле, кода здесь совсем чуть-чуть, ведь работа с базой у нас сейчас выполняется лишь в одном методе (я не учитываю изменения, связанные со спецификой Realm, а они есть, в частности, правила именования полей и работа с Gson; их можно посмотреть на Github).
И изменим метод save в AirportsResponse:
Вот и все! Мы элементарным образом, не затрагивая классы, которые содержат другую логику, изменили способ хранения данных.
Все-таки заключение
Хочу выделить один достаточно важный момент: мы не рассмотрели вопросы, связанные с использованием закэшированных данных, то есть при отстуствии интернета. Однако стратегия использования закэшированных данных в каждом приложении индивидуальна, и навязывать какой-то определенный подход я не считаю правильным. Да и так статья растянулась.
В итоге мы рассмотрели основные вопросы организации архитектуры клиент-серверных приложений, и я надеюсь, что эта статья помогла вам узнать что-то новое и что вы будете использовать какую-либо из перечисленных моделей в своих проектах. Кроме того, если у вас есть свои идеи, как можно организовать такую архитектуру, — пишите, я буду рад обсудить.
Спасибо, что дочитали до конца. Удачной разработки!



