Введение в распределенные системы
1.1. Понятие распределенной системы
Такой подход к определению распределенной системы имеет свои недостатки. Например, все используемое в такой распределенной системе программное обеспечение могло бы работать и на одном единственном компьютере, однако с точки зрения приведенного выше определения такая система уже перестанет быть распределенной. Поэтому понятие распределенной системы, вероятно, должно основываться на анализе образующего такую систему программного обеспечения.
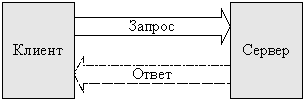
Взаимодействие в рамках модели клиент сервер может быть как синхронным, когда клиент ожидает завершения обработки своего запроса сервером, так и асинхронным, при котором клиент посылает серверу запрос и продолжает свое выполнение без ожидания ответа сервера. Модель клиента и сервера может использоваться как основа описания различных взаимодействий. Для данного курса важно взаимодействие составных частей программного обеспечения, образующего распределенную систему.
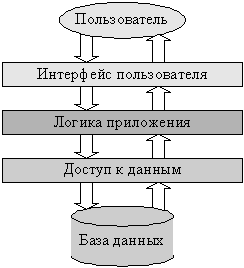
Поскольку на практике разных пользователей системы обычно интересует доступ к одним и тем же данным, наиболее простым разнесением функций такой системы между несколькими компьютерами будет разделение логических уровней приложения между одной серверной частью приложения, отвечающим за доступ к данным, и находящимися на нескольких компьютерах клиентскими частями, реализующими интерфейс пользователя. Логика приложения может быть отнесена к серверу, клиентам, или разделена между ними (рис. 1.3).
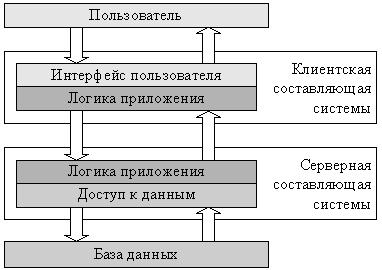
Архитектуру построенных по такому принципу приложений называют клиент серверной или двухзвенной. На практике подобные системы часто не относят к классу распределенных, но формально они могут считаться простейшими представителями распределенных систем.
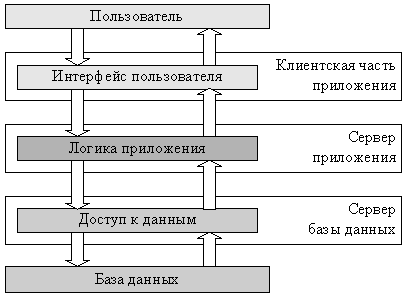
Запрос пользователя в подобных системах последовательно обрабатывается клиентской частью системы, сервером логики приложения и сервером баз данных. Однако обычно под распределенной системой понимают системы с более сложной архитектурой, чем трехзвенная.

Применительно к приложениям автоматизации деятельности предприятия, распределенными обычно называют системы с логикой приложения, распределенной между несколькими компонентами системы, каждая из которых может выполняться на отдельном компьютере. Например, реализация логики приложения системы розничных продаж должна использовать запросы к логике приложения третьих фирм, таких как поставщики товаров, системы электронных платежей или банки, предоставляющие потребительские кредиты (рис. 1.5).
Таким образом, в обиходе под распределенной системой часто подразумевают рост многозвенной архитектуры «в ширину», когда запросы пользователя не проходят последовательно от интерфейса пользователя до единственного сервера баз данных.
В качестве другого примера распределенной системы можно привести сети прямого обмена данными между клиентами ( peer-to-peer networks ). Если предыдущий пример имел «древовидную» архитектуру, то сети прямого обмена организованы более сложным образом, рис. 1.6. Подобные системы являются в настоящий момент, вероятно, одними из крупнейших существующих распределенных систем, объединяющие миллионы компьютеров.
Распределенные системы: определение, особенности и основные принципы
Общее представление о системе

 Вам будет интересно: Терминология. Что такое руина?
Вам будет интересно: Терминология. Что такое руина?
Распределенная система позволяет реализовать совместное использование ресурсов (включая программное обеспечение), подключенных к сети в одно и то же время.
Примеры распространения системы:
Распределенная система позволяет масштабироваться горизонтально и вертикально. Например, единственным способом обработки большего трафика будет обновление оборудования, на котором работает база данных. Это называется масштабированием по вертикали. Масштабирование по вертикали хорошо до определенного предела, после которого даже лучшее оборудование не справляется с обеспечением требуемого трафика.
Масштабирование по горизонтали означает добавление большего количества компьютеров, а не обновление аппаратного обеспечения на одном. Вертикальное масштабирование повышает производительность до новейших возможностей аппаратного обеспечения в распределенных системах. Эти возможности оказываются недостаточными для технологических компаний с умеренной и большой нагрузкой. Самое лучшее в горизонтальном масштабировании состоит в том, что нет ограничений на размер. Когда производительность ухудшается, просто добавляется другая машина, что, в принципе, возможно делать до бесконечности.
 Вам будет интересно: Что такое Камелот: происхождение и история легендарного замка
Вам будет интересно: Что такое Камелот: происхождение и история легендарного замка
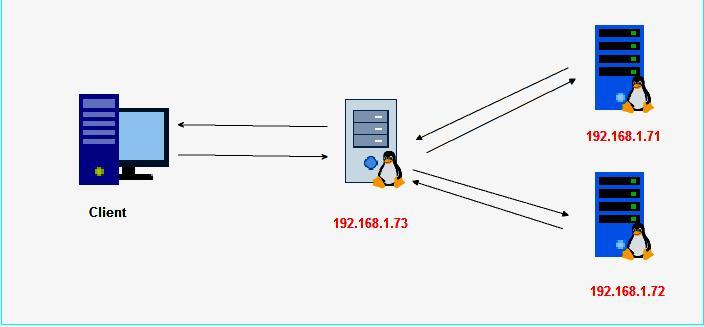
На корпоративном уровне распределенная система управления часто подразумевает выполнение различных шагов. В бизнес-процессах в наиболее эффективных местах сети компьютеров предприятия. Например, в типичном распределении с использованием трехуровневой модели распределенной системы обработки данных выполняется на ПК в месте нахождения пользователя, обработка бизнеса выполняется на удаленном компьютере, а доступ к базе данных и обработка данных осуществляется совершенно на другом компьютере, который обеспечивает централизованный доступ для многих бизнес-процессов. Как правило, этот вид распределенных вычислений использует модель взаимодействия «клиент-сервер».
Основные задачи
К основным задачам распределенной системы управления относятся:
 Вам будет интересно: Если речь косноязычная — это как?
Вам будет интересно: Если речь косноязычная — это как?
К задачам распредсистем относятся:
Распределенная вычислительная среда

(DCE) является широко используемым отраслевым стандартом, поддерживающим подобные распределенные вычисления. В Интернете сторонние поставщики предлагают некоторые обобщенные услуги, которые вписываются в эту модель.
Крупнейшим проектом grid-вычислений является SETI@home, в котором отдельные владельцы компьютеров добровольно выполняют некоторые из своих циклов обработки многозадачности, используя свой компьютер для проекта поиска внеземного интеллекта (SETI). Эта компьютерная проблема использует тысячи компьютеров для загрузки и поиска данных радиотелескопа.
Одним из первых применений grid-вычислений было нарушение криптографического кода группой, которая теперь известна как distributed.net. Эта группа также описывает свою модель как распределенные вычисления.
Масштабирование базы данных

Распространение новой информации от ведущего к ведомому не происходит мгновенно. На самом деле существует временное окно, в котором можно получить устаревшую информацию. Если бы это было не так, производительность записи пострадала бы, так как пришлось бы синхронно ждать распространения данных распределенных систем. Они поставляются с несколькими компромиссами.
Другой метод называется sharding (разделение). С помощью него сервер разбивается на несколько меньших серверов, называемых осколками. Эти осколки имеют разные записи, создаются правила о том, какие записи попадают в какой осколок. Очень важно создать такое правило, чтобы данные распространялись равномерно. Возможным подходом к этому является определение диапазонов в соответствии с некоторой информацией о записи.
 Вам будет интересно: Линейная скорость: формула нахождения
Вам будет интересно: Линейная скорость: формула нахождения
Этот осколочный ключ следует выбирать очень осторожно, так как нагрузка не всегда равна основам произвольных столбцов. Единственный осколок, который получает больше запросов, чем другие, называется горячей точкой, и стараются не допустить ее образования. После разделения данные перекалибровки становятся невероятно дорогими и могут привести к значительному простою.
Алгоритмы консенсуса базы данных

БД сложны для реализации в распределенных системах защиты, поскольку они требуют, чтобы каждый узел согласовывал правильное действие прерывания или фиксации. Это качество известно как консенсус, и он является фундаментальной проблемой в строительстве распредсистемы. Достижение типа соглашения, необходимого для проблемы «фиксации транзакции», является простым, если участвующие процессы и сеть полностью надежны. Тем не менее реальные системы подвержены ряду возможных сбоев процессов разбиения на сети, потерянные, искаженные или дублированные сообщения.
Это создает проблему, и невозможно гарантировать, что правильный консенсус будет достигнут в течение ограниченного периода времени в ненадежной сети. На практике существуют алгоритмы, которые довольно быстро достигают консенсуса в ненадежной сети. Кассандра фактически обеспечивает легкие транзакции посредством использования алгоритма Paxos для распределенного консенсуса.
В настоящее время MapReduce несколько устарела и приносит некоторые проблемы. Появились другие архитектуры, которые решают эти проблемы. А именно, Lambda Architecture для распределенной системы обработки потоков. Достижения в этой области принесли новые инструменты: Kafka Streams, Apache Spark, Apache Storm, Apache Samza.
Файловые системы хранения и тиражирования

Например, Yahoo известна тем, что работает HDFS на более чем 42 000 узлов для хранения 600 петабайт данных, еще с 2011 года. «Википедия» определяет разницу в том, что распределенные файловые системы разрешают доступ к файлам с использованием тех же интерфейсов и семантики, что и локальные файлы, а не через пользовательский API, такой как язык запросов Cassandra (CQL).
NameNodes несет ответственность за сохранение метаданных о кластере, например, какой узел содержит блоки файлов. Они выступают в качестве координаторов сети, выясняя, где лучше хранить и копировать файлы, отслеживая состояние системы. DataNodes просто хранят файлы и выполняют команды, такие как репликация файла, новая запись и другие.
Межпланетная файловая система (IPFS) представляет собой захватывающий новый одноранговый протокол/сеть для распределенной файловой системы. Используя технологию Blockchain, она может похвастаться полностью децентрализованной архитектурой без единого владельца или точки отказа.
IPFS предлагает систему именования (аналогичную DNS), называемую IPNS, и позволяет пользователям легко получать информацию. Она хранит файл через историческое управление версиями, подобно тому, как делает Git. Это позволяет получить доступ ко всем предыдущим состояниям файла. Он все еще переживает тяжелое развитие (v0.4 на момент написания), но уже видел проекты, заинтересованные в его создании (FileCoin).
Система передачи сообщений
Системы обмена сообщениями обеспечивают центральное место для хранения и распространения сообщений внутри общей системы. Они позволяют отделить прикладную логику от непосредственного общения с другими системами.
Проще говоря, платформа обмена сообщениями работает следующим образом:
Есть несколько популярных первоклассных платформ обмена сообщениями.
Приложения по взаимодействию машин
 Вам будет интересно: «Почаще»: слитно или раздельно? Как написание зависит от части речи?
Вам будет интересно: «Почаще»: слитно или раздельно? Как написание зависит от части речи?
Эта распредсистема представляет собой группу компьютеров, работающих вместе, чтобы отображаться как отдельный компьютер для конечного пользователя. Эти машины имеют общее состояние, работают одновременно и могут работать независимо, не влияя на время безотказной работы всей системы.
Если считать базу данных как распределенную, только в том случае, если узлы взаимодействуют друг с другом для координации своих действий. Она является в этом случае чем-то вроде приложения, выполняющего его внутренний код в одноранговой сети, и классифицируется как распределенное приложение.

Примеры таких приложений:
Распределенные регистры можно рассматривать как неизменяемую, доступную только для приложений базу данных, которая реплицируется, синхронизируется и делится на всех узлах распредсети.
Примеры распределенных операционных систем
Типы систем появляются для пользователя, поскольку они являются однопользовательскими системами. Они делят свою память, диск и пользователь не испытывают затруднений при навигации по данным. Пользователь хранит что-то в своем ПК, и файл хранится в нескольких местах, то есть на присоединенных компьютерах, так что потерянные данные могут легко восстановиться.
Примеры распределенных операционных систем:
Если какой-либо компьютер загружается выше, то есть если многие запросы обмениваются между отдельными ПК, так происходит балансировка нагрузки. В этом случае запросы распространяются на соседний ПК. Если в сети становится больше нагрузки, тогда ее можно расширить, добавив в сеть больше систем. В сетевом файле и папках синхронизируются, и соглашения об именах используются таким образом, чтобы при извлечении данных не возникало ошибок.
Кэширование также используется при манипулировании данными. Для наименования файлов на всех компьютерах используется одно пространство имени. Но файловая система действует для каждого компьютера. Если в файле появляются обновления, то он записывается на один компьютер, и изменения передаются на все компьютеры, поэтому файл выглядит таким же.
В процессе чтения / записи происходит блокировка файлов, поэтому между разными компьютерами не происходит взаимоблокировки. Также происходят сеансы, такие как чтение, запись файлов за один сеанс и закрытие сеанса, а затем другой пользователь может сделать то же самое и так далее.
Преимущества использования
Операционная система разработана для облегчения повседневной жизни людей. Для пользовательских преимуществ и потребностей операционная система может быть однопользовательской или распределенной. В системе распределенных ресурсов многие компьютеры связаны друг с другом и совместно используют свои ресурсы.
Преимущества такой работы:
Это кратко о распредсистеме, почему ее используют. Некоторые важные вещи, которые нужно запомнить: они сложны и выбираются по соотношению масштаба и цены, и с ними труднее работать. Данные системы распределены в нескольких категориях хранилищ: вычислительные, файловые и системы обмена сообщениями, регистры, приложения. И все это только очень поверхностно о сложной информационной системе.
Замечания о распределенных системах для начинающих
Пришло время рассказать вам о еще одной книге, которая вызвала у нас неподдельный интерес и серьезные дебаты.
Мы предположили, что и в сфере изучения алгоритмов для распределенных систем краткость — сестра таланта, поэтому проработка книги Уона Фоккинка «Распределенные алгоритмы. Понятный подход» является перспективным и благодарным делом, пусть даже объем книги — всего 248 страниц.

Однако, чтобы участвовать в опросе было интереснее, мы для начала приглашаем вас под кат, где находится перевод интереснейшей статьи Джеффа Ходжеса, описывающей самые разнообразные проблемы, связанные с разработкой распределенных систем.
Я давно думал о том, какие уроки усваивают на работе инженеры по обслуживанию распределенных систем.
Значительная часть таких знаний приобретается, когда мы обжигаемся на собственных ошибках в реальном «боевом» трафике. Эти ожоги хорошо запоминаются, но мне бы хотелось, чтобы как можно больше инженеров не допускали подобных ошибок.
Молодые системные инженеры должны обязательно прочитать «Заблуждения о распределенных вычислениях» и познакомиться с «CAP-теоремой» в порядке самообразования. Но это абстрактные работы без прямых практичных советов — а именно такие советы нужны молодому инженеру, чтобы начать расти. Удивительно, каким скудным контекстом располагает такой инженер, когда только начинает работать.
Ниже приведены некоторые уроки, которые я усвоил, будучи инженером по распределенным системам, и которые хотел бы преподать молодому коллеге. Некоторые уроки неочевидны, другие — удивительны, но большинство из них неоднозначны. Этот список поможет начинающему инженеру по распределенным системам сориентироваться в предметной области, где он вступает на свой профессиональный путь. Список не исчерпывающий, но для начала вполне хорош.
Основной недостаток этого списка — в нем акцентируются технические проблемы, но почти не затрагиваются вопросы социальные, с которыми может столкнуться инженер. Поскольку распределенные системы требуют больше машин и вложений, таким инженерам приходится взаимодействовать с различными командами и большими организациями. Коммуникация — обычно самая сложная часть работы любого программиста, и в особенности это касается как раз разработки распределенных систем.
Наша закваска, образование и опыт подталкивают нас к техническим решениям, даже если существует более приятное и эффективное социальное решение. Давайте постараемся это исправить. Люди не столь капризны, как компьютеры, пусть человеческий интерфейс и хуже стандартизирован.
Особенность распределенных систем — в том, что они часто отказывают
Если спросить, что отличает распределенные системы от других отраслей программирования, молодой специалист наверняка упомянет о задержках, полагая, что именно они осложняют распределенные вычисления. Но это ошибка. Главная особенность распределенных систем – это высокая вероятность отказа и, хуже того, вероятность частичного отказа. Если хорошо написанная разблокировка мьютекса не срабатывает и выдает ошибку, можно предположить, что процесс нестабилен, и завершить его. Но отказ разблокировки распределенного мьютекса должен быть учтен в протоколе блокировок.
Системный инженер, не имевший дел с распределенными вычислениями, может подумать: «ладно, просто пошлю запись на обе машины» или «ладно, буду отсылать запись, пока не сработает». Такие инженеры просто еще не вполне приняли (хотя и осознали интеллектуально) тот факт, что сетевые системы отказывают чаще, чем системы, работающие на отдельных машинах, причем такие отказы обычно частичные, а не тотальные. Одна запись может пройти, а другие — нет; и как нам после этого получить согласованное представление данных? Судить о таких частичных отказах гораздо сложнее, чем о тотальных.
Коммутаторы отключаются, из-за пауз в сборке мусора ведущие диски «исчезают», записи в сокеты, казалось бы, срабатывают, но на самом деле не проходят на другой машине, из-за медленного дисковода на одном компьютере протокол обмена информацией во всем кластере работает с черепашьей скоростью и т.д. Считывание из локальной памяти – просто более стабильный процесс, чем считывание сразу через несколько коммутаторов.
При проектировании учитывайте такие отказы.
Писать отказоустойчивые распределенные системы затратнее, чем надежные одиночные системы
На создание отказоустойчивого распределенного решения нужно больше денег, чем на аналогичную программу для одной машины. Дело в том, что некоторые виды отказов могут происходить только сразу на многих машинах. Виртуальные машины и облачные технологии удешевляют распределенные системы как таковые, но не разработку, реализацию и тестирование подобных систем на уже имеющемся компьютере. Существуют такие условия отказа, которые сложно смоделировать на отдельной машине. Если ситуация может возникать только с гораздо большими множествами данных, чем умещаются на разделяемой машине, либо в условиях, потенциально возможных только в сети датацентра, распределенные системы обычно требуют настоящей, а не сымитированной распределенности – только так можно искоренить их баги. Симуляции, разумеется, также очень полезны.
Надежные распределенные системы с открытым кодом встречаются гораздо реже, чем надежные системы для одиночных машин
Стоимость длительной эксплуатации многочисленных машин — тяжелое бремя для свободных сообществ. Развитие свободных разработок — заслуга энтузиастов и любителей, а у них нет достаточных финансовых ресурсов, чтобы исследовать и исправлять все те многочисленные проблемы, которые возникают в распределенной системе. Энтузиасты пишут открытый код для интереса в свое свободное время, на компьютерах, которые у них уже есть. Такому разработчику гораздо сложнее обзавестись «парком» машин, разгонять и поддерживать их.
Часть этой работы берут на себя программисты, работающие в больших корпорациях. Однако приоритеты организации в таком случае вполне могут не совпадать с вашими.
Хотя некоторые представители свободного сообщества и в курсе этой проблемы, она пока не решена. Это тяжело.
Координация очень сложна
По возможности старайтесь обходиться без координации машин. Такая стратегия часто именуется «горизонтальной масштабируемостью». Основной козырь горизонтальной масштабируемости — независимость. Она позволяет доставлять информацию на машины в таком режиме, что необходимость коммуникации и согласования между этими машинами сводится к минимуму. Каждое дополнительное согласование между машинами усложняет реализацию сервиса. Скорость передачи информации обладает определенным пределом, а сетевая коммуникация более хлипкая, чем вы могли бы подумать. Кроме того, вы, вероятно, не вполне понимаете, что такое «согласование». В данном случае полезно изучить задачи двух генералов и византийских генералов (кстати, еще очень сложен в реализации алгоритм Паксос; здесь старые ворчливые программисты даже не пытаются показать, что они умнее вас).
Если вы можете уместить задачу в памяти, то, она, вероятно, тривиальна
Инженеру по распределенным системам любая задача, которая может быть решена на одной машине, кажется тривиальной. Сложнее будет быстро определить порядок обработки данных, если между вами и этой информацией — несколько коммутаторов, то есть, разыменованием нескольких указателей не обойтись. В распределенных системах не работают старые добрые трюки по повышению эффективности, документированные еще на заре развития информатики. Существует масса литературы и документации по алгоритмам, выполняемым на одиночных машинах – именно потому, что большинство вычислений как раз и делается на одиночных, некоординируемых компьютерах. Подобных книг по распределенным системам значительно меньше. (курсив наш — ph_piter)
«Тормозит» – сложнейшая проблема, отладкой которой вам когда-либо придется заниматься
“Пробуксовка” может означать, что медленно работают одна или несколько систем, вовлеченных в обслуживание пользовательского запроса. Может быть, замедленно работают одно или несколько звеньев конвейера преобразований, распределенного на много машин. «Пробуксовка» — тяжелый случай, отчасти потому, что сама постановка задачи не слишком помогает найти проблему. Частичные отказы — те самые, что обычно не отображаются на графиках, которые вы привыкли просматривать — таятся в укромных уголках. До тех пор, пока деградация не станет совершенно очевидной, вам никто не выделит достаточных ресурсов (времени, денег, инструментов) на решение таких проблем. Именно для борьбы с ними появились инструменты Dapper и Zipkin.
Реализуйте во всей системе контроль обратного потока (backpressure)
Контроль обратного потока – это сигнализация об отказе, поступающая от обслуживающей системы к запрашивающей, а также методы обработки этих отказов со стороны запрашивающей системы, призванные исключить перегрузку как запрашивающей, так и обслуживающей системы. Проектирование с учетом контроля обратного потока подразумевает ограничения на использование ресурсов в периоды перегрузки и при отказе системы. Это один из столпов создания надежных распределенных систем.
Распространенные версии алгоритма включают отбрасывание новых сообщений (с увеличением параметра на единицу), если системные ресурсы уже расписаны до предела; при этом пользователям отсылаются сообщения об ошибках, если система определяет, что обработать запрос в течение заданного периода времени не удастся. Также целесообразно использовать задержки и экспоненциальные отсрочки на соединениях и запросах к другим системам.
Если контроль обратного потока отсутствует, то возрастает риск лавинообразных отказов или непредусмотренной потери сообщений. Если одна система не в состоянии обрабатывать отказы другой, то она обычно распространяет отказы на следующую систему, зависящую от нее.
Изыскивайте пути обеспечения частичной доступности
Частичная доступность — это способность вернуть часть результатов, даже если отдельные узлы системы отказывают.
В данном случае особенно уместен пример, связанный с поиском. В поисковых системах всегда заложен компромисс между точностью выдаваемого результата и длительностью пользовательского ожидания. В типичной поисковой системе устанавливается лимит времени, в течение которого она может вести поиск по документам. Если этот лимит исчерпывается прежде, чем удастся просмотреть весь массив документов, система возвращает все результаты, которые ей удалось найти. В таком случае поиск становится удобнее масштабировать в условиях эпизодической пробуксовки, а ошибки, обусловленные такими отказами, трактуются точно так же, как невозможность выполнить поиск по всем документам. Система допускает возврат пользователю частичных результатов, и гибкость системы возрастает.
Также рассмотрим возможность отправки личных сообщений в веб-приложении. Вполне логично, что если обмен личными сообщениями временно не работает, функция загрузки изображений в аккаунт, вероятно, должна остаться доступной. Что же мешает реализовать возможность частичного отказа в системе обмена сообщениями как таковой? Конечно, здесь придется пошевелить мозгами. Обычно пользователи проще относятся к временному отказу сервиса личных сообщений у них (и, возможно, у других пользователей), чем к тому, что некоторые из их сообщений могут потеряться. Если сервис перегружен, или одна из обслуживающих его машин отказала, то предпочтительнее временно отключить от всей службы небольшую часть пользовательской аудитории, чем потерять данные значительно большей части клиентов. Полезно уметь распознавать подобные компромиссы, связанные с частичной доступностью.
Отслеживайте метрики – иначе с задачей не справиться
Проверка метрик (в частности, перцентилей задержки, увеличения значений счетчиков при определенных действиях, динамики изменений) — единственный способ снивелировать разрыв между вашими предположениями о том, как работает система, и реальностью. Представление о том, чем поведение системы в день 15 отличается от ее же поведения в день 20 — вот что отличает успешную разработку от бесплодных танцев с бубном. Разумеется, метрики необходимы для понимания проблем и поведения системы, но одних лишь метрик недостаточно, чтобы понять, что делать дальше.
Поговорим о логировании. Иметь файлы логов – это хорошо, но они часто врут. Например, очень распространена ситуация, когда всего на несколько классов с ошибками приходится огромное большинство сообщений в файле логов, но на самом деле эти ошибки касаются весьма незначительной доли запросов. Поскольку в большинстве случаев указание успешных операций в файле логов является избыточным (такая масса информации просто взорвала бы диск), и поскольку инженеры часто не угадывают, какие именно барахлящие классы было бы целесообразно выводить в логе, такие файлы переполняются странной всякой всячиной. Организуйте логирование так, как если бы эти файлы должен был читать человек, незнакомый с кодом.
Мне доводилось иметь дело с многочисленными простоями, возникавшими лишь потому, что другой разработчик (или
я сам) придавали слишком большое значение какой-то странности, замеченной в логе, не сверив ее предварительно с метриками. Мне (и коллегам) также доводилось выявлять целый класс ошибочных поведений на основании всего нескольких строчек в логе. Но учтите, что a) такие успехи запоминаются, поскольку они очень редкие и б) никакой Шерлок Холмс не справится с проблемой, если отсутствуют нужные метрики и эксперименты.
Используйте перцентили, а не средние значения
Перцентили (50-й, 99-й, 99.9-й, 99.99-й) точнее и информативнее средних в абсолютном большинстве распределенных систем. Использование среднего означает, что оцениваемая метрика соответствует колоколообразной кривой, но на практике такая кривая описывает очень немногие метрики, которые действительно могут интересовать разработчика. Часто говорят о «средней задержке», но мне никогда не попадалась распределенная система, структура задержек в которой напоминала бы колоколообразную кривую. Если метрика не соответствует этой кривой, работать со средними бессмысленно, это приводит к превратному пониманию ситуации и неверным выводам. Чтобы не увязнуть в таких проблемах, работайте с перцентилями. Если по умолчанию в системе будут применяться перцентили, то вы получите значительно более реалистичное представление о ней.
Учитесь оценивать мощность системы
В таком случае вы узнаете, сколько секунд в сутках. Знание о том, сколько машин потребуется на выполнение задачи — вот что отличает долговечную систему от той, которую потребуется заменить через три месяца с начала эксплуатации. Хуже того, некоторые системы приходится полностью менять еще на этапе разработки.
Поговорим о твитах. Сколько id твитов может уместиться в памяти самой обычной машины? Допустим, на типичной машине 24 Гб памяти, из них 4-5 Гб приходится на ОС, еще пара гигов — на обработку запросов. Размер id твита — 8 байт. Такими ориентировочными расчетами мы занимаемся часто. В данном случае удобно ориентироваться по презентации Джеффа Дина «Числа, которые должен знать каждый».
Инфраструктура выкатывается при помощи переключения свойств
Специальные флаги для попеременного включения свойств — обычный инструмент, при помощи которого разработчики выкатывают новые функции в систему. Как правило, такие флаги связаны с A/B-тестированием на стороне клиента, где они применяются для показа нового варианта дизайна или новой возможности лишь для некоторой части пользовательской аудитории. Но эти же переключатели – мощный механизм для замены инфраструктуры.
Допустим, вы идете от отдельной базы данных до сервиса, скрывающего детали нового хранилища данных. В таком случае сервис должен обертывать унаследованное хранилище и постепенно наращивать в нем операции записи. При обратном заполнении, сравнительных проверках при считывании (другой переключатель) и медленном наращивании операций считывания (еще один переключатель) вы будете чувствовать себя гораздо увереннее и сможете исключить большинство катастроф. Множество проектов пришлось похоронить, так как они претерпели «большое отключение» или серию «больших отключений», и причиной таких простоев стали вынужденные откаты из-за багов, обнаруженных слишком поздно.
Нормальному программисту, воспитанному в духе ООП, либо новичку, стажировавшемуся «как следует», все это переключение функций покажется ужасной путаницей. Работая с переключением возможностей, мы признаем, что обслуживание сразу множества версий инфраструктуры и данных — это норма, а не исключение. Очень показательно. То, что работает на отдельной машине, может давать осечку при решении распределенных задач.
Переключение возможностей лучше всего трактовать как компромисс: мы идем на локальное усложнение (на уровне кода в конкретной системе) ради глобального упрощения и повышения гибкости всей системы.
Разумно выбирайте пространства id. Пространство id, которое вы выберете для вашей системы, задаст контуры всей этой системы. Чем больше id требуется для получения конкретного элемента данных, тем больше вариантов сегментирования этих данных у вас будет. Соответственно, чем меньше id для этого нужно, тем проще будет потреблять вывод вашей системы.
Рассмотрим версию 1 API Twitter. Все операции по получению, созданию и удалению твитов делались с учетом одиночного числового id каждого твита. Id твита — простое 64-разрядное число, не связанное ни с какими другими данными. По мере того, как количество твитов увеличивается, становится ясно, что создание пользовательских лент и лент подписок от других пользователей можно эффективно организовать, если все твиты конкретного пользователя будут храниться на одной и той же машине.
Но общедоступный API требует, чтобы для адресации любого твита было достаточно только его id. Чтобы распределять твиты по пользователям придется создать службу поиска. Такую, которая позволит выяснить, какой пользователь владеет каким id. При необходимости это возможно, но и расходы будут существенными.
Альтернативный API мог бы требовать пользовательский id при каждой операции по поиску твита и просто использовать для хранения информации id твита до тех пор, пока хранилище данных, сегментированное по пользователям, не вышло бы в онлайн. Другой вариант – включать id пользователя в id твита, однако в таком случае id твитов уже не были бы числовыми и не поддавались бы k-сортировке.
Следите за тем, какую информацию вы кодируете в ваших id, явно и неявно. Клиенты могут воспользоваться структурой ваших id для де-анонимизации частной информации, а также индексировать вашу систему непредвиденными для вас способами (автоматическое увеличение id на единицу – типичное больное место), а также делать массу других вещей, которые будут для вас совершенно неожиданными.
Выгодно используйте локализацию данных
Чем ближе локализуются в долговременном хранилище обработка и кэширование ваших данных, тем эффективнее будет такая обработка, и тем проще будет обеспечивать согласованность и скорость кэширования. Сетевые отказы и задержки не сводятся к разыменованию указателей и fread(3).
Разумеется, локализация данных подразумевает определенное расположение не только в пространстве, но и во времени. Если множество пользователей практически одновременно выполняют одинаковые затратные запросы, то, возможно, все эти запросы получится сложить в один. Если множество запросов к схожим данным делаются поблизости друг от друга, то их можно объединить в большой запрос. В таких случаях зачастую удается снизить коммуникационные издержки и становится проще справляться с неисправностями.
Не следует записывать кэшированные данные обратно в долговременное хранилище
Это происходит в различных системах гораздо чаще, чем вы могли бы подумать. Особенно в тех, проектировщики которых не особо подкованы в распределенной разработке. Многие системы, которые вы унаследуете, будут страдать от такого недостатка. Если автор реализации рассказывает о кэшировании по принципу матрешки, то велика вероятность, что вы наткнетесь на очень заметные баги. Этот пункт вполне можно было бы исключить из списка, если бы не моя особая ненависть к таким ошибкам. Наиболее распространенное их проявление заключается в том, что пользовательская информация (ники, электронные адреса и хэшированные пароли) загадочным образом сбрасываются на предыдущее значение.
Компьютеры способны на большее, чем вы от них ожидаете
В наше время существует масса дезинформации о возможностях компьютеров. Ее распространяют практикующие, но сравнительно неопытные специалисты.
По состоянию на конец 2012 года у легкого веб-сервера было 6 и более процессоров, 24 Гб памяти и больше дискового пространства, чем вы в состоянии использовать. Относительно сложное CRUD-приложение в современной языковой среде выполнения на одиночной машине без малейшего труда может выполнять тысячи запросов в секунду (вернее, за сотни миллисекунд). Причем это нижний предел возможностей. Что касается эксплуатационной мощности, обработка тысяч запросов в секунду на одиночной машине в большинстве случаев не представляет собой ничего сверхъестественного.
Несложно достичь и более высокой производительности, особенно если вы хотите профилировать ваше приложение и доработать эффективность на основе проделанных измерений.
Используйте CAP-теорему для критики систем
Из CAP-теоремы систему не выстроишь. Эта теорема не подходит в качестве основного принципа, из которого можно было бы вывести рабочую систему. В чистом виде она имеет крайне общую формулировку, а разброс ее возможных решений слишком велик.
Однако она очень хороша для критики дизайна распределенных систем и для понимания того, на какие компромиссы придется пойти. Если взять дизайн системы и подробно сверить его со всеми ограничениями, накладываемыми теоремой CAP, то в итоге все подсистемы будут спроектированы более качественно. Вот вам домашнее задание: рассмотрите все ограничения теоремы CAP на примере рабочей реализации кэширования по принципу матрешки.
Последнее замечание: из C, A и P нельзя оставить только CA.
Извлекайте сервисы
Термин “сервис” здесь означает “распределенная система, включающая более высокоуровневую логику, чем система-хранилище и обычно имеющая API, работающий по принципу «запрос-отклик»”. Следите за изменениями кода, осуществить которые было бы проще, если бы код работал в отдельном сервисе, а не в вашей системе.
Извлеченный сервис обеспечивает все плюсы инкапсуляции, которые обычно связаны с созданием библиотек. Однако извлекать сервис предпочтительнее, чем создавать библиотеки, поскольку в таком случае любые изменения развертываются быстрее и легче, чем если бы пришлось обновлять библиотеки на клиентских системах. (Разумеется, если сложно развертывать извлеченный сервис, то как раз развертывание клиентских систем упрощается). Такая легкость объясняется тем, что в сравнительно небольшом извлеченном сервисе будет меньше кода и эксплуатационных зависимостей; кроме того, сервис очерчивает четкие границы, не позволяя «срезать углы», что допустимо при работе с библиотеками. Подобные «углы» всегда осложняют перенос внутренних компонентов системы на новые версии.
Когда эксплуатируется сразу множество клиентов, затраты на координацию с использованием сервиса также гораздо ниже, чем при применении разделяемой библиотеки. Обновление библиотеки (даже когда не требуется менять API) требует скоординировать развертывание на всех клиентских машинах. Кроме того, обновление библиотеки требует более активной коммуникации с коллегами, чем развертывание сервиса, если за поддержку клиентских систем отвечают разные организации. Удивительно сложно убедить всех участников в необходимости обновления, так как их приоритеты могут не совпадать с вашими.
Хрестоматийный пример такого рода — необходимость скрыть уровень хранения данных, на котором требуется внести изменения. У извлеченного сервиса есть API, который более удобен в использовании, а также имеет меньшую «поверхность», чем уровень хранения, данных, с которым он стыкуется. При извлечении сервиса клиентским системам не требуется ничего знать о сложностях медленной миграции на новое хранилище, либо о применяемом формате. Баги приходится искать только в новом сервисе – а они определенно будут найдены, учитывая новую компоновку хранилища.
При работе с распределенными системами следует учитывать еще множество эксплуатационных и социальных вопросов. Но это уже тема для другой статьи.



